
Figures & data
Figure 1. The overall architecture of the MC-Net. The image encoder with multi-scale feature extraction and feature aggregating module is used to extract visual features, and the description decoder with visual-text alignment LSTM is used to generate description sentences.
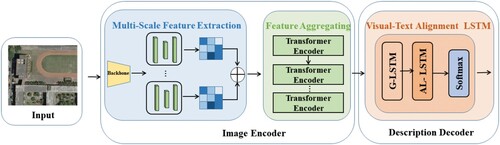
Figure 2. Outline of multi-scale visual feature extraction module.
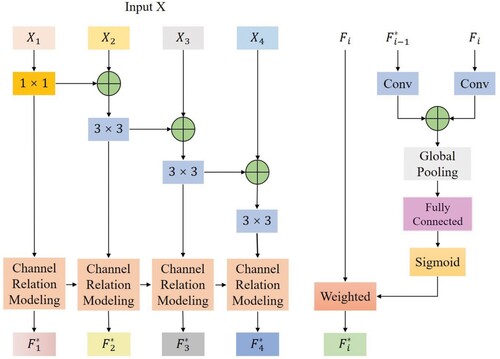
Figure 3. The process of local modeling of images.
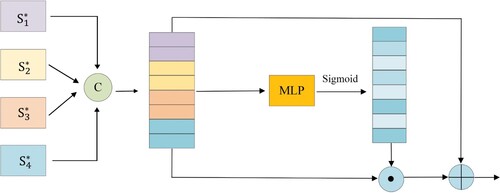
Figure 4. The process of global modeling of images.
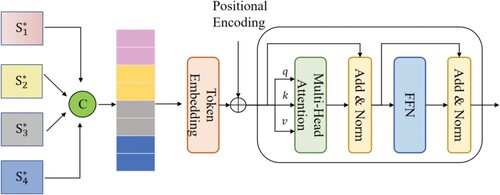
Table 1. Settings and results of ablation experiments on the UCM-Captions.
Table 2. Settings and results of ablation experiments on the Sydney-Captions.
Table 3. Settings and results of ablation experiments on the RSICD.
Table 4. Settings and results of ablation experiments on the NWPU-Captions.
Table 5. Comparative results of MC-Net on the UCM-Captions.
Table 6. Comparative results of MC-Net on the Sydney-Captions.
Table 7. Comparative results of MC-Net on the RSICD.
Table 8. Comparative results of MC-Net on the NWPU-Captions.
Figure 5. Captions results by MC-Net on four datasets. The first to the fourth columns are selected examples from UCM-Captions, Sydney-Captions, RSICD, and NWPU-Captions, respectively.
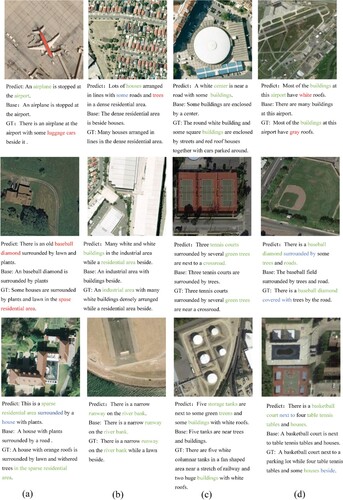
Table 9. Captioning performance Comparision with different multi-heads(H) values on the UCM-Captions.
Table 10. Comparison of our methods in terms of inference speed (images per second), MACs and parameters. All results are reported based on the UCM-Captions.
Table 11. The comparison results with different scale of contextual information on the UCM-Captions.
Data availability statement
The data that support the findings of this study are available from the corresponding author, upon reasonable request.