
Figures & data
Figure 1. The GAN architecture. The Attention 3D U-Net in the generator encodes the low-resolution input into an implicit feature grid. The ‘imnet’ decodes the implicit feature grid at each coordinate into the values of the original physical variables to construct the high-resolution predicted values. The predicted values are compared with the ground truth, and a regression loss is determined. Simultaneously, the predicted values are input into a discriminator to obtain an adversarial loss. Furthermore, the PDE loss is constructed by incorporating physical constraints represented by partial differential equations. This completes one cycle of adversarial training.
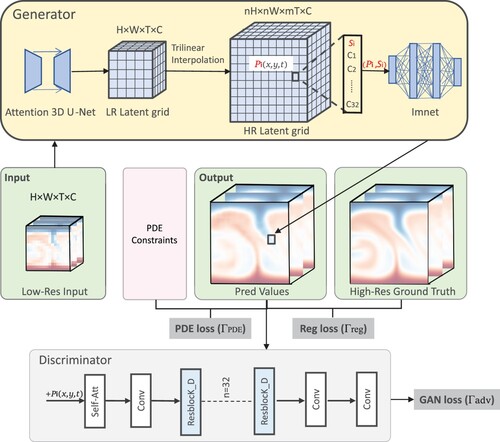
Figure 2. The generator structure. The generator integrates the attention gate modules and residual blocks and incorporates decoding networks related to physical constraints to enhance the reliability and accuracy of super-resolution predictions of the original physical quantities.
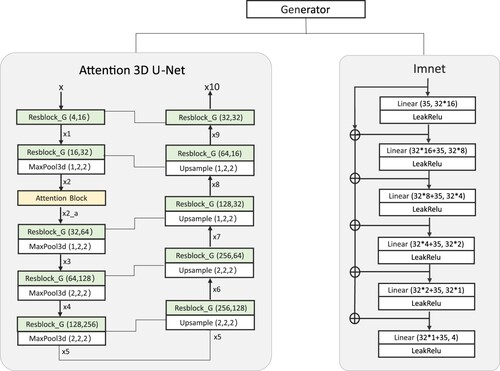
Table 1. The design details of the Attention 3D U-Net.
Figure 3. Basic blocks in the generator and discriminator.
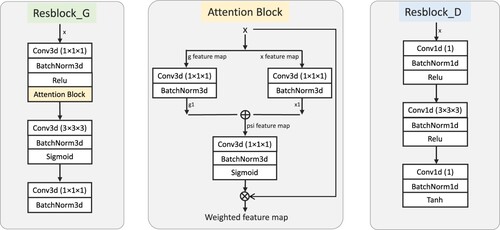
Figure 4. The discriminator network architecture.
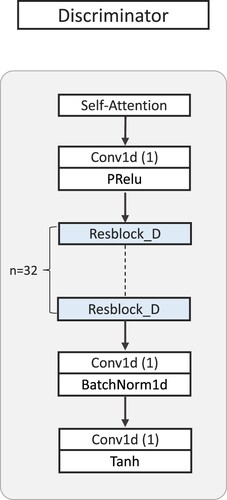
Figure 5. The visualization of salinity at t = 167 T of the ISWs in the South China Sea predicted by AttGAN. Each grid on the axis represents 71 km. The red dashed box in (c) indicates the more prominent waveform features of the ISWs. (a) Ground Truth. (b) Low-resolution input and (c) AttGAN (ours).
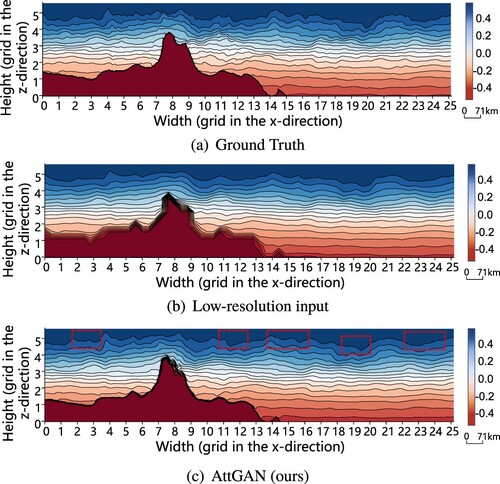
Figure 6. The visualization results of temperature at any point in time in the observation of the ISWs predicted by the proposed AttGAN model. The red dashed box in (c) indicates the more prominent waveform features of the ISWs, which are missing from the low-resolution input. (a) Low-resolution input of temperature channel. (b) Ground Truth and (c) AttGAN (ours).
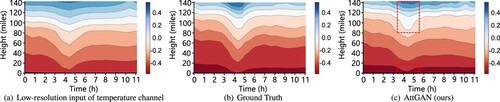
Figure 7. Low-resolution input of temperature channel. Each grid on the axis represents 4 m.
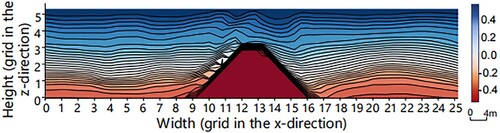
Table 2. Quantitative comparisons of different methods on ISWs.
Figure 8. Visual comparisons of different methods for the temperature at t = 82 T, including the ground truth, the proposed model's result, the MeshFreeFlowNet model's result, and the TransFlowNet model's result. Each grid on the axis represents 3 km. The red dashed box reveals differences in the restored waveform features between the three models. The proposed model's result was the closest to the ground truth, followed by the MeshFreeFlowNet model. (a) Ground Truth. (b) AttGAN (ours). (c) MessFreeFlowNet and (d) TransFlowNet.
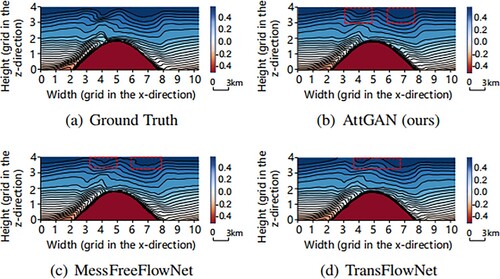
Figure 9. Low-resolution input of temperature channel. Each grid on the axis represents 80 m.
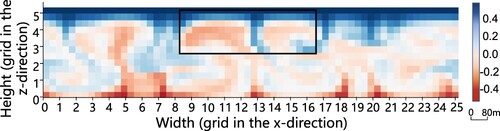
Figure 10. Visual comparison results of different methods for the temperature component at T. Each grid on the axis represents 6 m. Compared to the ground truth, the result of the MessFreeFlowNet exhibited noticeable biases (particularly in the lower center of the vortex on the left). The TransFlowNet introduced some grid-like artifacts, and the proposed AttGAN achieved the best result among all the models. (a) Ground Truth. (b) AttGAN (ours). (c) MessFreeFlowNet and (d) TransFlowNet.
Table 3. Quantitative comparisons of different methods on Rayleigh–Bénard.
Table 4. Ablation study results of AttGAN using the ISWs dataset.
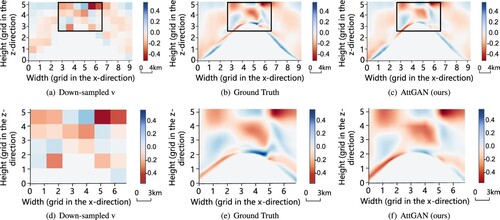
Figure 11. Visualization results of slices of velocity component v () at t = 41 T predicted by the proposed AttGAN. In (a)–(c), each grid on the axis represents 4 km; in (d)–(f), each grid on the axis represents 3 km. The result predicted by the proposed model was close to the ground truth. (a) Down-sampled v. (b) Ground Truth. (c) AttGAN (ours). (d) Down-sampled v. (e) Ground Truth and (f) AttGAN (ours).
Data availability statement
The data that support the findings of this study are openly available in Zenodo at https://doi.org/10.5281/zenodo.10472771
.