Figures & data
Figure 1. An example of neuron activity during the free and clamped phases with adjusted adaptation. For visual clarity, only one representative neuron from the top layer is shown. The time steps for free and clamped phases are 120, and teaching signals are given after 12 steps. The adjusted adaptation steps are 20. After 120 steps at the clamped phase, additional 20 steps for the adaptation are applied using EquationEq. 8(8)
(8) .
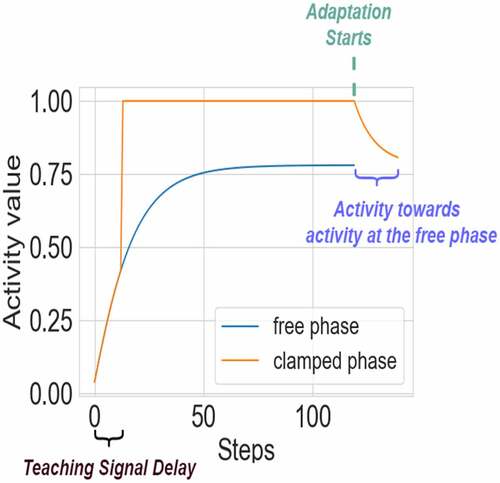

Figure 2. The learning curves for the models (parameters: 782-50-10) with the adjusted adaptation (MLP-ADP) and without the adjusted adaptation (MLP) on MNIST.
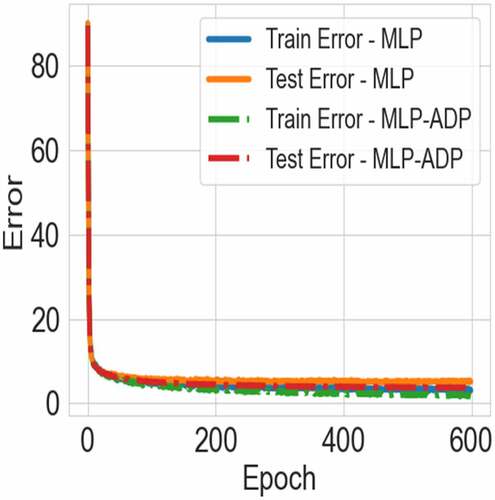
Figure 3. The learning curves for the models with the adjusted adaptation (CNN-ADP) and without the adjusted adaptation (CNN) on CIFAR-10.
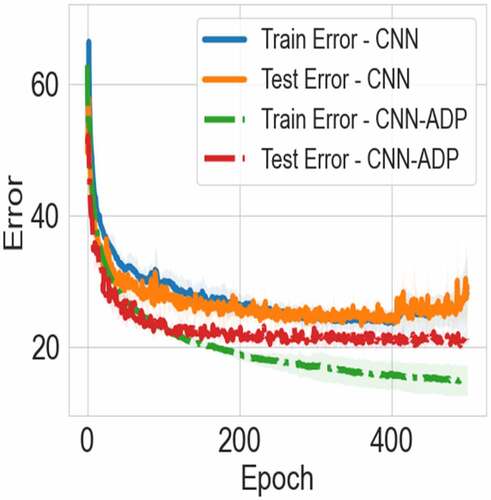
Table 1. Training results on MNIST and CIFAR-10 with EP and the adaptation/no adaptation. For MNIST, we trained MLP with CHL. For CIFAR-10, we trained CNNs with EP. For laterl1, the lateral connections are only in the hidden layer. For lateral2, the lateral connections are in both hidden and output layers. We trained each network six times to calculate average and ±the standard deviation. Numbers in bold denote smallest test error.
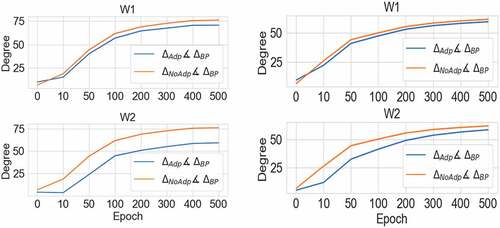
Figure 4. Mean angle between weight gradients calculated using BP and CHL (left: 6 neurons a hidden layer, right: 12 neurons in a hidden layer). Blue line shows the angle calculated for CHL with adaptation, and orange for CHL without adaptation. “W1” means the gradients for the weights between the input and hidden layers, and “W2” means the gradients for the weights between the hidden and output layers. The angle between the gradients with the adaptation and BP is denoted as ∆Adp∡∆BP . The angle between the gradients without the adaptation and BP is denoted as ∆NoAdp∡∆BP . Note that the blue line is consistently closer to 0, which demonstrates that CHL with adaptation provides weights updates more similar to BP gradients.