
Figures & data
Figure 1. Representative samples with different characteristics of transmission wires in high-resolution optical remote sensing images.

Figure 2. Flowchart of the Swin-Unet-M model for wire segmentation.
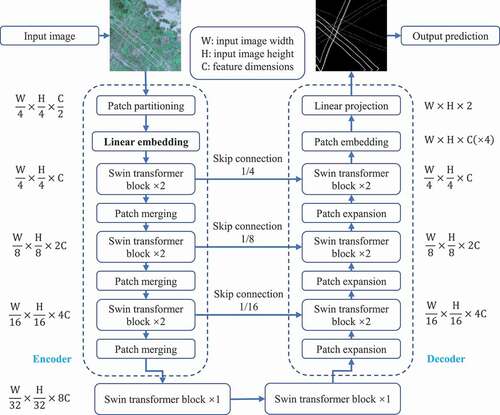
Table 1. The differences between Swin-Unet and Swin-Unet-M in ‘Linear Embedding’ module. Conv means the convolutional layer, means the kernel size,
means the stride,
means the padding size. Maxpool denotes the maxpooling layer.
means the batch size.
denotes the feature dimension (
in this study).
Figure 3. Flow chart of the proposed synthetic wire sample generation.
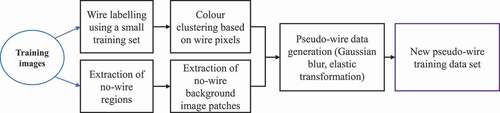
Figure 4. Visualization of segmentation results on synthetic test set. The images from left to right of each row are: original image, ground truth, the results obtained using FCN-Unet, Deeplab-Unet, PSP-Unet, Swin-Unet, and Swin-Unet-M.

Table 2. Wire segmentation performance of three typical U-Net architectures with three different patch sizes (i.e., ,
, and
pixels).
Table 3. Wire segmentation performance of the Swin-Unet and Swin-Unet-M with different learning rates (LR). The bold numbers mean the best result.
Figure 5. Visualization of segmentation results on four real images. The images from left to right of each row are: original image and the results obtained using FCN-Unet, Deeplab-Unet, PSP-Unet, Swin-Unet and the proposed Swin-Unet-M, respectively.
