
Figures & data
Table 1. The characteristics of included studies in this meta-analysis
Figure 1. Systematic review flowchart for this meta-analysis
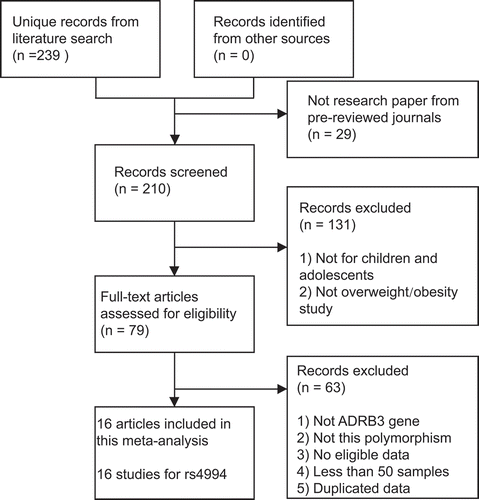
Table 2. Results of overall and subgroup analyses for the ADRB3 rs4994 polymorphism and risk of childhood and adolescent overweight/obesity
Figure 2. Forest plot showing the association between the ADRB3 rs4994 polymorphism and risk of childhood and adolescent overweight/obesity. Odds ratio (OR) and 95% confidence interval (95% CI) were calculated under the dominant model. The random effects model was used to assess the pooled estimates. The included studies were stratified according to geographical regions. The grey squares represent the weight of the sample size under the random effects model. The black dot in the square represented the OR for each included study. The black horizontal lines showed the corresponding 95% CI. The black solid vertical line showed the null effect (OR = 1). The red dashed vertical line showed the pooled estimate. The hollow diamonds at the bottom represented the ORs and 95% CIs for the overall population and subgroups. The data sets drawn from ref[23] and ref[30] were not included because they did not provide genotype data for the dominant model
![Figure 2. Forest plot showing the association between the ADRB3 rs4994 polymorphism and risk of childhood and adolescent overweight/obesity. Odds ratio (OR) and 95% confidence interval (95% CI) were calculated under the dominant model. The random effects model was used to assess the pooled estimates. The included studies were stratified according to geographical regions. The grey squares represent the weight of the sample size under the random effects model. The black dot in the square represented the OR for each included study. The black horizontal lines showed the corresponding 95% CI. The black solid vertical line showed the null effect (OR = 1). The red dashed vertical line showed the pooled estimate. The hollow diamonds at the bottom represented the ORs and 95% CIs for the overall population and subgroups. The data sets drawn from ref[23] and ref[30] were not included because they did not provide genotype data for the dominant model](/cms/asset/de3fe136-ba7a-44cd-810f-645b4e19d895/kadi_a_1722549_f0002_oc.jpg)
Figure 3. Filled funnel plot with imputed studies under the dominant model. Using the ‘trim-and-fill’ method, the pooled estimates are adjusted for possible missing data sets (squared circles) amongst published studies (hollow circles). The log odds ratio (OR) stands for the natural logarithm transferred OR of individual data sets. The standard error of the log OR represents the standard error of the natural logarithm transferred OR of individual data sets. The data sets drawn from ref[23] and ref[30] were not included because they did not provide genotype data for the dominant model
![Figure 3. Filled funnel plot with imputed studies under the dominant model. Using the ‘trim-and-fill’ method, the pooled estimates are adjusted for possible missing data sets (squared circles) amongst published studies (hollow circles). The log odds ratio (OR) stands for the natural logarithm transferred OR of individual data sets. The standard error of the log OR represents the standard error of the natural logarithm transferred OR of individual data sets. The data sets drawn from ref[23] and ref[30] were not included because they did not provide genotype data for the dominant model](/cms/asset/b09348f1-6ce3-46bf-8e10-6266ffe81493/kadi_a_1722549_f0003_b.gif)
Figure 4. Sensitivity analysis for the pooled estimates under the dominant model. For each omitted data set listed on the left, summary statistics for the resulting pooled estimates are presented as odds ratio (OR, hollow circle) with 95% confidence interval (CI, horizontal line). The random effects model was used to assess pooled estimates. The data sets drawn from ref[23] and ref[30] were not included because they did not provide genotype data for the dominant model
![Figure 4. Sensitivity analysis for the pooled estimates under the dominant model. For each omitted data set listed on the left, summary statistics for the resulting pooled estimates are presented as odds ratio (OR, hollow circle) with 95% confidence interval (CI, horizontal line). The random effects model was used to assess pooled estimates. The data sets drawn from ref[23] and ref[30] were not included because they did not provide genotype data for the dominant model](/cms/asset/9ca36905-cefa-461a-b573-9b075191b9f8/kadi_a_1722549_f0004_b.gif)