
Figures & data
Figure 1. The proposed encoder-decoder architecture. The solid and the dotted lines denote forward propagation and skip connections, respectively. The purple lines signify the output left and right disparity maps generated at 4 scales, each increasing hierarchically with a scale factor of 2.
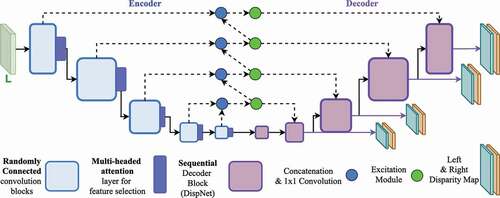
Figure 2. The process of generating a randomly connected deep-learning architecture. The red and the grey nodes are the input and the output nodes of the block, respectively. The black nodes are the convolution operations. The purple module is a multi-head self-attention module.
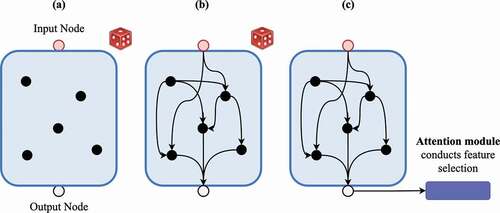
Figure 3. Showing the proposed learn-able skip connections methodology. is the network topology of a standard U-Net and
is the proposed new network topology. Solid lines and dotted lines denote forward propagation and skip connections, respectively.
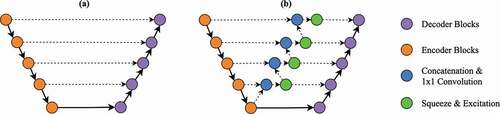
Figure 4. Discriminator model. The solid black lines and the dotted lines denote forward propagation and skip connections, respectively. The skip connection inputs are concatenated with the forward propagating feature map prior to being processed by the next layer. The pink lines show the extraction of multi-scale feature maps.
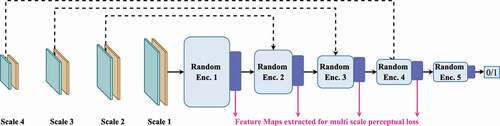
Figure 5. Depth maps generated by the proposed model on the SCARED and Hamlyn test splits shown in rows and
, respectively. Inclusion of
signifies presence of learn-able skip connections and
without. All models were trained with the standard
loss (EquationEquation 1
(1)
(1) ) unless
is specified, which signifies training with the proposed loss function (EquationEquation 5
(5)
(5) ). The colour bar displays the depth range in mm.
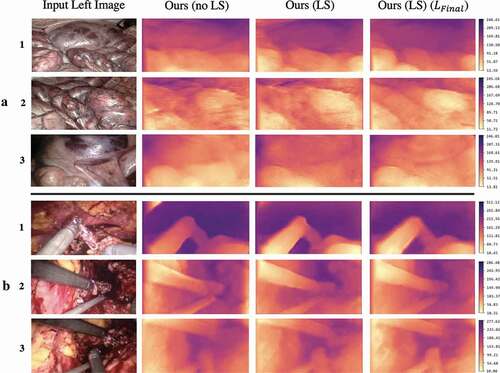
Figure 6. Comparison of depth maps generated by our model with Godard et al. (Citation2017) and Pilzer et al. (Citation2018) on the Hamlyn test split. The last column re-displays the depth produced by our proposed method (column 2), with the green boxes highlighting the key areas where more details are visible in our depth maps. The colour bar displays the depth range in mm.
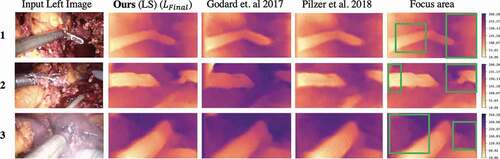
Table 1. Showing the mean absolute depth error in mm for test dataset 1 from SCARED. The compared methods are the self-supervised methods submitted to this challenge. (M) signifies Monodepth method and (S) Stereodepth. The presence of denotes the type of loss function used for training, and presence of (no LS) implies no learn-able skip connections were used in the model. Best results are highlighted in bold
Table 2. Showing the mean absolute depth error in mm for test dataset 2 from SCARED. The compared methods are the self-supervised methods submitted to this challenge. Where (M) signifies Monodepth method and (S) Stereodepth. The presence of denotes the type of loss function used for training, and presence of (no LS) implies no Learn-able skip connections were used in the model. Best results are highlighted in bold
Table 3. SSIM index on the reconstructed images generated via the estimated disparity maps on the Hamlyn test dataset. Higher value indicates better performance. Where (M) signifies Monodepth method and (S) Stereodepth. The M in parameter count signifies a million parameters. Methods ,
,
,
and
are Geiger et al. (Citation2010), Yamaguchi et al. (Citation2014), Ye et al. (Citation2017), Godard et al. (Citation2017) and Pilzer et al. (Citation2018), respectively