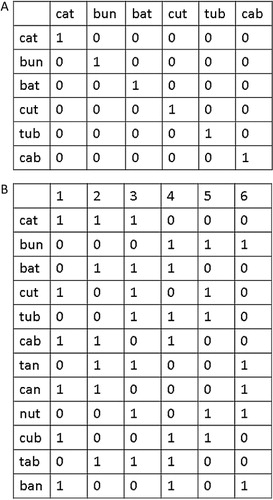
Figure 1. A schematic representation of activation of units encoding (a) localist representations and (b) distributed representations. In (a) representation of six words requires six units. In (b) representation of twelve words also requires six units. In (b) the representations are distributed at the word level but localist at the letter level for the purposes of exposition. A fully distributed scheme would have the capacity to represent many more words.
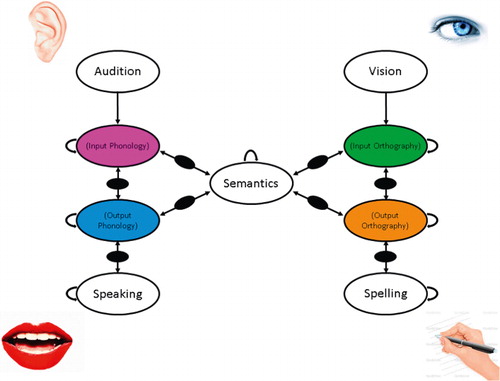
Figure 2. A schematic diagram of a model of visual and auditory word recognition and production showing the location of hidden unit layers that could house distributed functional lexical representations in the form of attractors. Note bidirectional connections in all cases bar those from input. Additional hidden layers are shown in black. Within level connections are shown with U-shaped arrows.
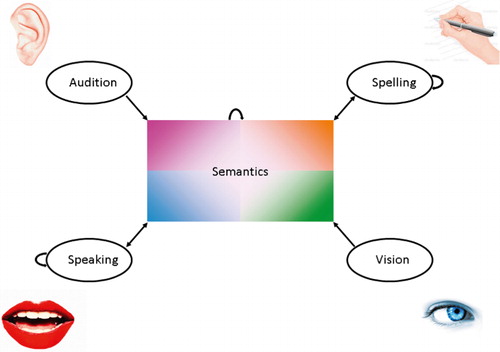
Figure 3. A version of the previous model of visual and auditory word recognition and production containing one large set of hidden units. Learning in the network occurs under a topographic bias that favours short connections. This allows graded modality specificity to emerge in the network, such that units close to a particular input or output participate more in tasks involving them, while units close to the centre are increasingly amodal.