
Figures & data
Figure 1. Illustration of the Linear Chirplet Transform with three main steps. In step 1, the blue line is rotated by an angle θ, then becomes the green line. In step
2, the green line is shifted by
to be the red line. At the final step, the red line is transformed with STFT.
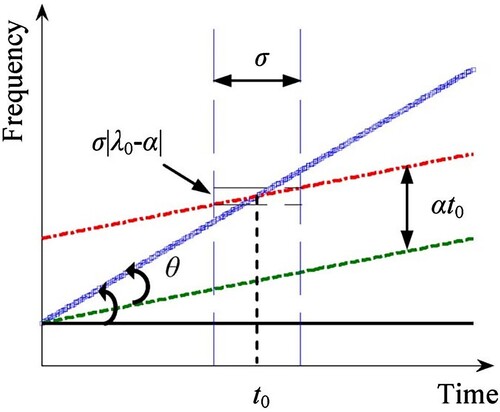
Figure 2. Linear Chirplet Transform with chirp rate . In this case, LCT performs equivalent with the Fourier transform.
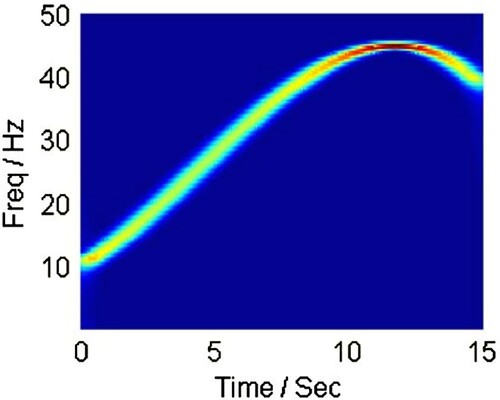
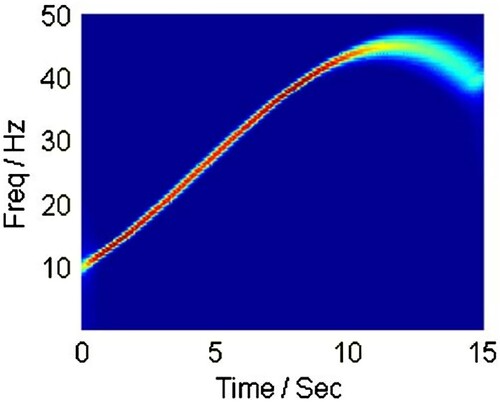
Figure 3. Linear Chirplet Transform with positive chirp rate . In the TF plane, the signal is highlighted with red color when the frequency achieving high energy increases over time.
Algorithm 1. Speech feature extraction using Linear Chirplet Transform
Figure 4. Illustration of 3D time-frequency representation returned by Linear Chirplet Transform for input audio with the content ‘There was a change now’, said a woman.
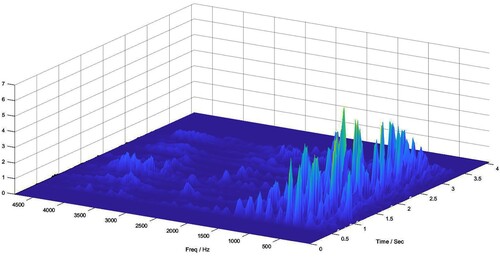
Table 1. Some statistics in TIMIT and VIVOS.
Table 2. Some statistics in LibriSpeech.
Table 3. Speaker gender recognition in TIMIT and VIVOS.
Table 4. Speaker dialect recognition in TIMIT and VIVOS.
Table 5. Speech recognition with different features for English (E) in LibriSpeech and Vietnamese (V) in VIVOS.