
Figures & data
Fig. 1 (a) The contour plots of the three subpopulations given the label of the observations generated under the distribution scheme of Example 1. (b) The clusters obtained by the K-means. (c) The clusters obtained by the GMM. (d) The clusters obtained by the proposed algorithm.
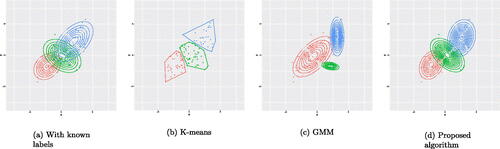
Fig. 2 (a) The contour plots of the three subpopulations given the label of the observations generated under the distribution scheme of Example 2. (b) The clusters obtained by the K-means. (c) The clusters obtained by the GMM. (d) The clusters obtained by the proposed algorithm.
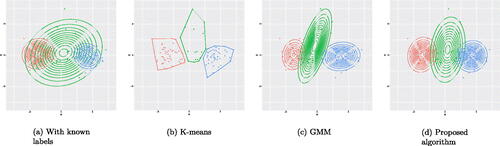
Fig. 3 (a) The contour plots of the three subpopulations given the label of the observations generated under the distribution scheme of Example 3. (b) The clusters obtained by the K-means. (c) The clusters obtained by the GMM. (d) The clusters obtained by the proposed algorithm.
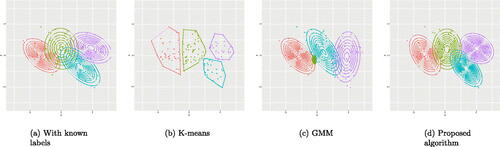
Fig. 4 (a) The scatterplot of the three subpopulations given the label of the observations generated under the distribution scheme of Example 1. (b) A rejected data partition. (c) A not-rejected data partition. (d) The kernel density plot for the observed data. (e) The kernel density plot for the rejected artificial data set generated using the partition presented in subfigure (b). (f) The kernel density plot for the not-rejected artificial data set generated using the partition presented in subfigure (c).
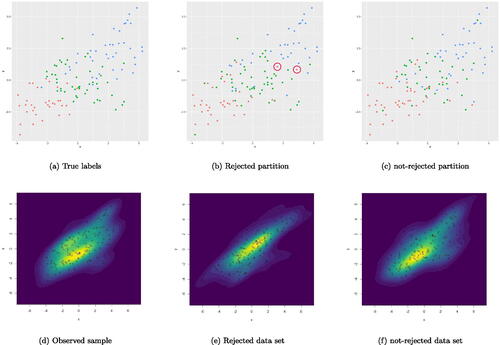
Table 1 Summary results (Mean values-upper tabular, standard deviations-second tabular, and performance evaluation metrics-two bottom tabular) for the 1000 simulated samples from Scenario 1.
Table 2 Summary results (Mean values-upper tabular, standard deviations-second tabular, and performance evaluation metrics-two bottom tabular) for the 1000 simulated samples from Scenario 2.
Table 3 Summary results (Mean values-upper tabular, standard deviations-second tabular, and performance evaluation metrics-two bottom tabular) for the 1000 simulated samples from Scenario 3 with equal cluster sizes.
Table 4 Summary results (Mean values-upper tabular, standard deviations-second tabular, and performance evaluation metrics-two bottom tabular) for the 1000 simulated samples from Scenario 3 with non-equal cluster sizes.
Fig. 5 (a) The contour plots of the three subpopulations given the labels of the observations for the Flea Beetle data set. (b) The clusters obtained by the K-means. (c) The clusters obtained by the GMM. (d) The clusters obtained by the proposed algorithm.
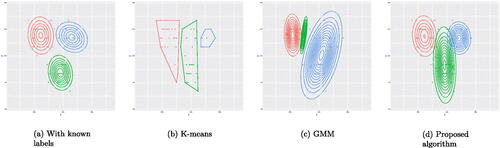
Table 5 Confusion tables for the flea beetle data set using the three clustering algorithms.
Table 6 Descriptive statistics for the three identified clusters by the used clustering algorithms.