Figures & data
Figure 1. 1000 high-income (>2× the poverty level) earners (red) and 1000 low-income earners (blue) selected from the distributed population weighted by county-level data.
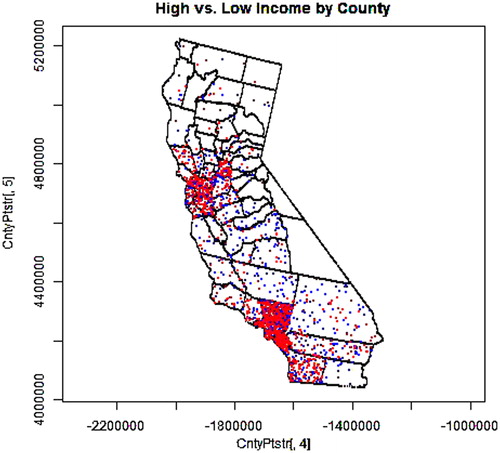
Figure 2. Two independent sets of 1000 high-income earners; one representing cases (red) and the other representing controls (blue) selected from the distributed population weighted by county-level data.
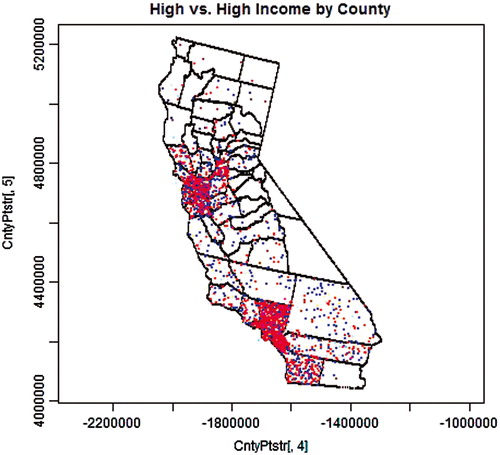
Figure 3. 1000 high-income (> 2× the poverty level) earners (red) and 1000 low-income earners (blue) selected from the distributed population weighted by census-tract-level data.
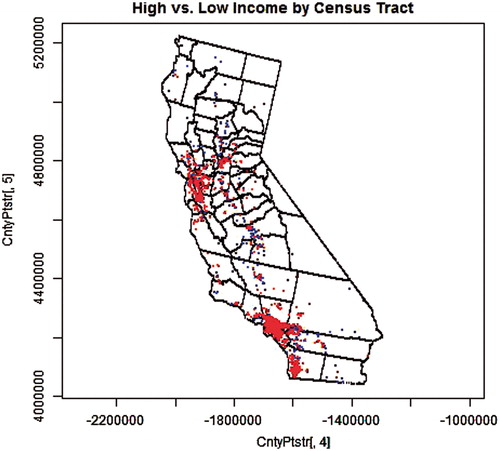
Figure 4. Two independent sets of 1000 high-income earners; one representing cases (red) and the other representing controls (blue) selected from the distributed population weighted by census-tract-level data.
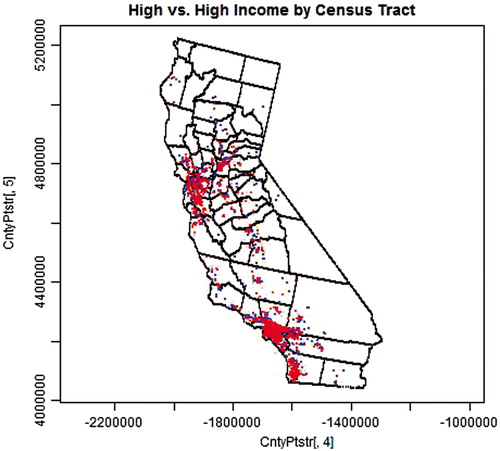
Table 1. Results of logistic regression comparing ORs for cases versus controls to proximity to ultramafic deposits in California*.
Table 2. Estimates of ORs, intercepts and frequencies for cases versus controls regressed against sets of random sources (county-level data)*.
Table 3. Estimates of ORs, intercepts and frequencies for cases versus controls regressed against distance to random sources (tract-level data)*.
Table 4. Results from simulating the distribution of population characteristics within census tracts to evaluate associations with proximity to ultramafic rock*.
Table 5. Observed ratios of “Cases” versus “Controls” for indicated characteristics among the 7049 census tracts and 58 counties in California*.
Figure 5. 1000 Cases (red) and 1000 Controls (blue) sampled from a set of 500 simulated “municipalities” of randomly varying sizes and locations with a randomly selected half weighted to favor cases (70%/30%) and the other half favoring controls (70%/30%).
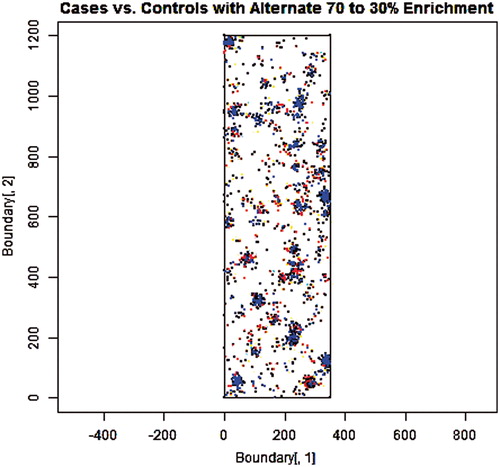
Figure 6. 1000 Cases (red) and 1000 Controls (blue) sampled from a set of 500 simulated “municipalities” of randomly varying sizes and locations with each weighted equally (50%/50%), neither favoring cases or controls.
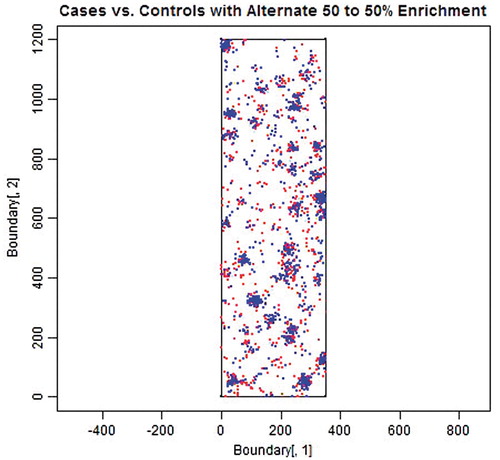
Table 6. Summary results of four sets of 2500 regressions conducted to test a hypothetical mechanism underlying the excessive numbers of false-positive (non-causal) associations observed among California demographic data*.
Table 7. Distribution of results from sets of regressions conducted to test a hypothetical mechanism underlying the excessive numbers of false-positive associations observed among California demographic data*.
Figure 7. 2500 source locations uniformly distributed around the stylized state.
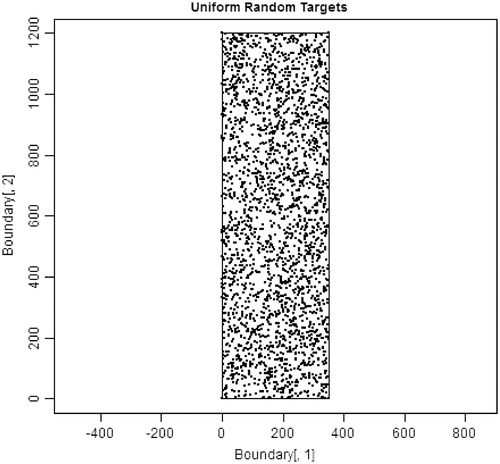
Figure 8. 100 source locations distributed non-uniformly along two vertical lines that are each 50 km inward from the north-south boundaries of the stylized state. Note that the number of locations was reduced from 2500, so that the random nature of the distribution along each vertical line could be easily observed.
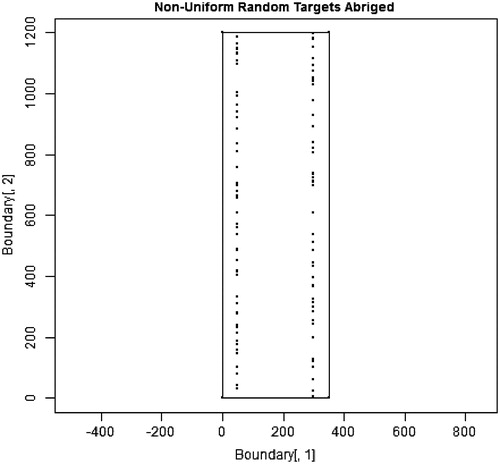
Table 8. Distribution of results from sets of regressions conducted to test a hypothetical mechanism underlying the excessive numbers of false-positive associations observed among California demographic data and highly non-uniform target locations*.