Figures & data
Fig. 1 Initial conditions and their evolutions with the linear advection–diffusion equation: (a) flat top-hat (FTH), (b) quadratic top-hat (QTH), (c) window sinusoid (WS), and (d) squared-exponential (SE). The first two initial conditions (a, b) exhibit sparse representation in the wavelet domain while the next two (c, d) show nearly sparse representation in the discrete cosine domain (DCT). Initial conditions are evolved under the linear advection–diffusion eq. (15) with and a=1[L/T]. The broken lines show the time instants where the low-resolution and noisy observations are available in the assimilation interval.
![Fig. 1 Initial conditions and their evolutions with the linear advection–diffusion equation: (a) flat top-hat (FTH), (b) quadratic top-hat (QTH), (c) window sinusoid (WS), and (d) squared-exponential (SE). The first two initial conditions (a, b) exhibit sparse representation in the wavelet domain while the next two (c, d) show nearly sparse representation in the discrete cosine domain (DCT). Initial conditions are evolved under the linear advection–diffusion eq. (15) with and a=1[L/T]. The broken lines show the time instants where the low-resolution and noisy observations are available in the assimilation interval.](/cms/asset/ca6be971-31d4-4186-abf2-ce8011886556/zela_a_11817030_f0001_ob.jpg)
Fig. 2 A sample representation of the available low-resolution (solid lines) and noisy observations (broken lines with circles) in every 125 [T] time-steps in the assimilation window for the flat top-hat (FTH) initial condition. Here, the observation error covariance is set to with σ
r
=0.08 equivalent to
.
![Fig. 2 A sample representation of the available low-resolution (solid lines) and noisy observations (broken lines with circles) in every 125 [T] time-steps in the assimilation window for the flat top-hat (FTH) initial condition. Here, the observation error covariance is set to with σ r =0.08 equivalent to .](/cms/asset/65f4cb3c-90c1-4278-9b02-13be7863f32d/zela_a_11817030_f0002_ob.jpg)
Fig. 3 Empirical condition numbers of the background error covariance matrices as a function of parameter α and problem dimension (m) for the AR(1) in (a) and AR(2) in (b). The parameter α varies along the x-axis and m varies along the different curves of the condition numbers with values between 4 and 1024. We recall that is the ratio between the largest and smallest singular values of B. In (a) the covariance matrix is
and in (b)
,
. It is seen that the condition numbers of the AR(2) model are significantly larger than those of the AR(1) model for the same values of the parameter α.
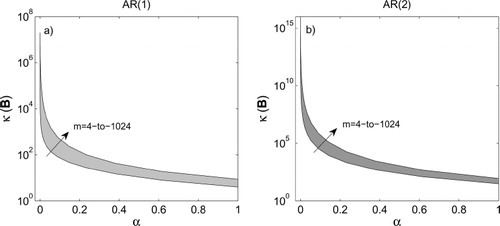
Fig. 4 Sample paths of the used correlated background error: (a) the sample path for the AR(1) covariance matrix with α
−1=150, and (b) the sample path for the AR(2) covariance matrix with α
−1=25. The paths are generated by multiplying a standard white Gaussian noise from the left by the lower triangular matrix L, obtained by Cholesky factorisation of the background error covariance matrix, that is B=LL
T. It is seen that for small α, the sample paths exhibit large-scale oscillatory behaviour that can potentially corrupt low-frequency components of the underlying state.
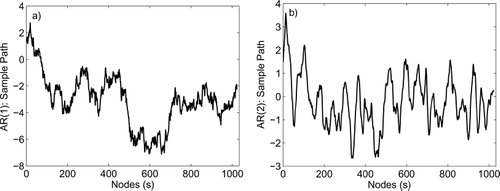
Fig. 5 The results of the classic 4D-Var (left panel) versus the results of -norm R4D-Var (right panel) for the tested initial conditions in a white Gaussian error environment. The solid lines are the true initial conditions and the crosses represent the recovered initial states or the analysis. In general, the results of the classic 4D-Var suffer from overfitting while the background and observation errors are suppressed and the sharp transitions and peaks are effectively recovered in the regularised analysis.
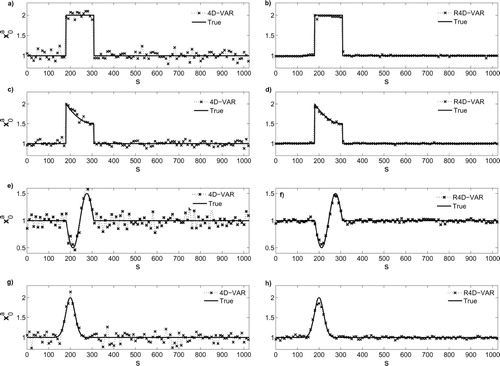
Table 1. Expected values of the MSE r , MAE r , and BIAS r , defined in eq. (20), for 30 independent runs
Fig. 6 Comparison of the results of the classic 4D-Var (b, ; e) and -norm R4D-Var (c, ; f) for the top-hat (left panel) and window sinusoid (right panel) initial conditions. The background states in (a) and (d) are defined by adding correlated errors using an AR(1) covariance model of
, where α=1/250. The results show that the
-norm R4D-Var improves recovery of sharp jumps and peaks and results in a more stable solution compared to the classic 4D-Var; see for quantitative results.
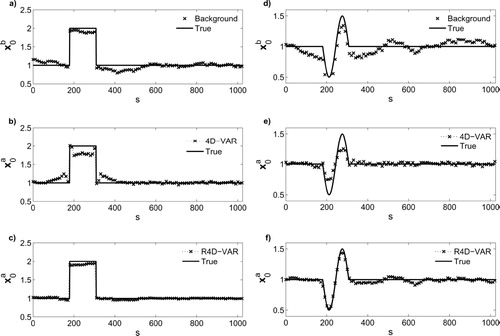
Fig. 7 Comparison of the results of the proposed -norm R4D-Var (solid lines) and the classic 4D-Var (broken lines) under the AR(1) background error for different correlation characteristic length scales (α
−1). Top panel: (a–c) the chosen quality metrics for the top-hat initial condition (FTH); Bottom panel: (d–f) the metrics for the window sinusoid initial condition (WS). These results, averaged over 30 independent runs, demonstrate significant improvements in recovering the analysis state by the proposed
-norm R4D-Var compared to the classic 4D-Var.
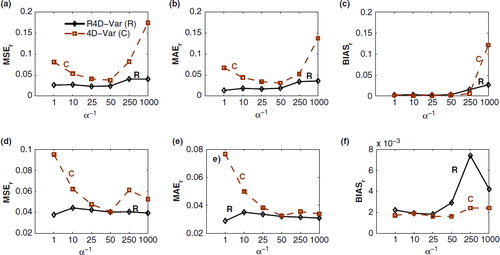
Table 2. Expected values of the MSE r , MAE r , and BIAS r , defined in (20), for 30 independent runs
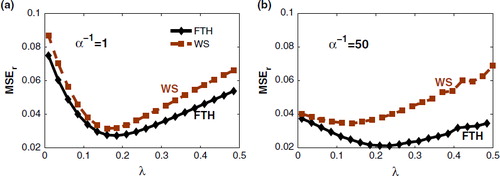
Fig. 8 The relative mean squared error versus the regularisation parameter obtained for the AR(1) background error for different characteristic correlation length (a) α −1=1, and (b) α −1=50. FTH and WS denote the flat top-hat (FTH) and window sinusoid initial conditions, respectively.