
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Content based image retrieval (CBIR) systems work by retrieving images which are related to the query image (QI) from huge databases. The available CBIR systems extract limited feature sets which confine the retrieval efficacy. In this work, extensive robust and important features were extracted from the images database and then stored in the feature repository. This feature set is composed of color signature with the shape and color texture features. Where, features are extracted from the given QI in the similar fashion. Consequently, a novel similarity evaluation using a meta-heuristic algorithm called a memetic algorithm (genetic algorithm with great deluge) is achieved between the features of the QI and the features of the database images. Our proposed CBIR system is assessed by inquiring number of images (from the test dataset) and the efficiency of the system is evaluated by calculating precision-recall value for the results. The results were superior to other state-of-the-art CBIR systems in regard to precision.
1 Introduction
Recently enormous number of images database are available worldwide [Citation1Citation[2]–Citation3] . In order to utilize these databases an effective and robust retrieval and search approach is required. The traditional process for image retrieval is performed by describing every image with a text annotation and retrieving images by searching the keywords. This process has become very laborious and ambiguous because of the rapid increase in the number of images and the diversity of the image contents. Herby the content based image retrieval (CBIR) received a lot of attention [Citation4]. A handful number of researches in the past decade were working on retrieving images from the huge repositories by analyzing image contents [Citation5], since the beginning of 1990s CBIR was an active field for multimedia community research [Citation6].
The aim of a CBIR algorithm is to determine the images that are related to the QI from the database [Citation7]. CBIR can retrieve images that are similar to the query input image using the “query by example” technique which requires the user to input any description about the query image. The system of CBIR works mainly by extracting features from the query image, then searching for these extracted features. These extracted features are used to calculate feature vector for the query image, CBIR represents every image in the database with a vector, after inputting the QI, the CBIR system computes its feature vector then compares it with the vectors stored for every image in the database. CBIR system returns the images that are similar in features to the QI.
Das et al. [Citation8] described a method for extraction of features through binarization of images to enhance images retrieval and identification using content based image recognition. The authors tested their system using two public datasets with a sum of 3688 images. This method reduced the size of features to 12 regardless of the dimensions of image. The statistical measures (based on precision and recall results) were adopted for the evaluation purpose. One disadvantage of this method is the misclassification of query images which would affect the performance of the retrieval compared to other existing approaches.
Ashraf et al. [Citation9] proposed a technique for representation of image and feature extraction using bandelet transform, this approach consistently returns the main (core) objects’ information that are contained in an image. The artificial neural networks were used for image retrieval, the system performance and achievement was assessed using 3 public data sets namely: Coil, Corel, and Caltech 101, the precision and recall values were used for the retrieval efficiency evaluation
Seetharaman and Selvaraj [Citation10] proposed a method for image retrieval using statistical tests, such as Welch’s t-tests and F-ratio. Both of the structured or textured input query images were examined. In the experiment, the entire image is considered in the textured image, while in the structured image, the shape is separated into various regions based on its nature. The first step of the foresaid test is applying F-ratio test and the passed images proceeded to the energy spectrum testing. Then if images succeeded the two tests it was decided that these images are similar. Else, they are different. For validation and verification of the performance Mean Average Precision score was used.
Feng et al. [Citation11] proposed an image descriptor (Global Correlation Descriptor) for texture and color feature extraction respectively so that they had the same influence on CBIR. Global Correlation Vector and Directional Global Correlation Vector were also proposed, they integrated the benefits of structure element correlation and statistics of histogram to describe texture and color features. Corel-10 K and Corel-5 K datasets were used for validation, and the recall and precision were used for the efficiency evaluation.
In Zeng [Citation12] a local structure descriptor is proposed for image retrieval. Local structure descriptor is created based on the local structures underlying colors; it has combined the color, shape and texture as a one unit for retrieval of images. In addition, they proposed an algorithm for feature extraction which is able to extract local structure histogram using local structure descriptor.
Madhavi et al. [Citation13] proposed an approach known as image retrieval using interactive genetic algorithm for calculating a high number of selective features then comparing of related images for these features. The approach was tested on a group of 10,000 general images to prove the efficiency of the proposed approach.
Ali et al. [Citation14] Presented a CBIR approach using integration of Speeded-Up Robust Features (SURF) and Scale Invariant Feature Transform (SIFT). The representations of these local features are used for retrieval because SIFT is robust to rotation and scale change, and SURF is more robust to illumination changes. The integration of SURF and SIFT enhances the effectiveness of CBIR. The comparisons and evaluation were conducted on Corel-1500, Corel-2000, and Corel-1000.
One of the most commonly used meta-heuristics in optimization problems is the genetic algorithm. Genetic algorithm (GA) is a search algorithm which stimulates the heredity in the living things [Citation15]. GA is very effective in finding the optimum solution from the search space [Citation16].
In order to enhance the performance of a meta-heuristic such as GA, a local search algorithm is needed to help the GA for exploiting the solution space rather than just concentrating on exploring the search space. One excellent local search is the great deluge algorithm. The great deluge algorithm (GDA) was presented by Dueck [Citation17] as a local search algorithm. The main idea of this algorithm came from the analogy that someone is climbing a hill and trying to move in any direction to find a way up for keeping his feet dry and the water level is raising through a great deluge. The great deluge algorithm when inserted in the genetic algorithm was an effective way to yield a good solution instead of using the genetic algorithm alone [Citation18].
Based on the abovementioned revision and discussion, this work utilizes a memetic algorithm (MA) to find the images that has the highest similarity with the QI from a database. During the CBIR process every image in the database is indicated by chromosome, from the QI the color signature, shape and color texture are extracted and also from the chromosomes that were generated. The next step is calculating fitness function for every chromosome using similarity difference equation. After that MA processes like crossover, mutation, great deluge local search and selection of the highest fitness chromosome are applied on the chromosomes; the CBIR retrieves the most relevant images to the QI from the images database.
2 Materials and methods
2.1 Feature extraction
The CBIR system proposed in this work determines the features in the image utilizing its optical contents such as color signature, shape and color texture. represents the block diagram of the proposed method and the details of each process will be illustrated in the following sections.
Fig. 1 The proposed method block diagram.
2.2 Color features extraction
Color feature is an essential component for image retrieval. For huge image databases, image retrieval using the color feature is very successful and effective. Although color feature is not a persistent parameter, because it is subjected to many non-surface characteristics for example, the taking conditions such as illumination, characteristics of the device, the device view point [Citation1,Citation19,Citation20] . The steps of the color feature extraction are shown below:
| 1. | Color planes values RGB are separated into individual matrices namely; Red, Green and Blue matrices. | ||||
| 2. | For each color matrix color histogram is calculated. | ||||
| 3. | Variance and median of color histogram are calculated. | ||||
| 4. | The summation of all row variances and medians is calculated. | ||||
| 5. | The calculated features of all matrixes (R, G and B) are combined as feature vector. | ||||
| 6. | The feature vectors are stored in the features database. | ||||
2.3 Shape features extraction
The shape feature extraction mainly aims to capture the properties of the shape of the image items. This eases the process of shape storing, transmitting, comparing against, and recognizing. The shape features should be free of rotation, translation, and scaling [Citation1,Citation21,Citation22] .
To store, transmit, or recognize shape, an efficient way to find the shape features is investigated. The selected features are independent from any mathematical transformation. A colored image has three values per each pixel, to extract the features we convert the color image into one two-dimensional array, and that made according to Craig, formula as follows [Citation1,Citation23] :
(1)
(1)
Where is the combined 2D matrix,
are the color components which construct the colored image.
is represented as the grey level combined image. As a preprocessing step: noise reduced by using median filter. Median filter is beneficial to reduce salt and pepper noise and speckle noise [Citation24]. Also, median filter has edge-preserving property it is used where blurring of edges is undesirable [Citation24]. Median filter with width w and length l algorithm is as follows:
| 1. | Around each pixel collect all pixels with length l/2 and width w/2 around it. | ||||
| 2. | Sort all collected pixels. | ||||
| 3. | Update the pixel value by the pixel value in the middle order in the previous list. | ||||
After applying the median filter, the image becomes almost without noise data. Then the neutrosophic clustering algorithm is applied to separate pixels with very near values and to ignore indeterminate pixels from the gray image [Citation25,Citation26] . The algorithm is as follows:
| 1. | Select k centroids pixel values. | ||||
| 2. | For each pixel assign random membership value to each centroid. | ||||
| 3. | Assign T, N values with the image I and F value with the inverse of T. | ||||
| 4. | Calculate the new centroid value as the weighted mean of the pixel values, where the weight is the member ship value to that centroid but the weight magnitude if it the pixel is not indeterminate and tininess if it is indeterminate. | ||||
| 5. | Update the membership values as one over the ratio of the overall differences between the centroid and the pixels’ values, and the differences between the pixel values and all other centroid values. | ||||
| 6. | Update the image I by applying the mean filter over pixels with significant values. | ||||
| 7. | If the updated membership values are almost equal to it before update then stop otherwise go to step 3 again. | ||||
Finally apply the canny algorithm to find the edges around the similar pixels (grouped pixels) [Citation1]. In this work Canny edge detection method was used for shape features extraction, edge based shape representation was used, which gives a numerical information about image, these information is constant, even the size, direction, and position of the objects in the image are changed. After applying canny edge detection method different shapes can be obtained which exists in the image and then the shaped content indices are extracted and stored in the database in form of feature vector.
2.4 Color texture features
Color texture features classification is an essential step for image segmentation using CBIR. Thus, this work proposes an approach that is based on texture analysis to classify color texture instead of segmentation alone.
2.5 Grey-level co-occurrence matrix (GLCM)
The GLCM is a robust image statistical analysis technique [Citation27Citation[28]Citation[29]–Citation30] . GLCM can be defined as a matrix of two dimensions of joint probabilities between pixels pairs, with a distance d between them in a given direction θ [Citation30]. Haralick [Citation31] extracted and defined 14 feature from the GLCM for the texture features classification. But these 14 features are highly correlated, so in our research we avoided this problem by using five features for the comparison. The Steps of the color texture features extraction is shown below:
| 1. | Filtering the input image using the 5 × 5 Gaussian Filter. | ||||
| 2. | Filtered image is divided into 4 × 4 blocks. | ||||
| 3. | For each block Standard Deviation, Homogeneity, mean value, Contrast and Energy are calculated using GLCM, these features were calculated based on four directions as diagonally (45° and 135°), vertically (0°) and horizontally (90°). | ||||
| 4. | The extracted features are stored in the feature database. | ||||
3 Proposed memetic algorithm
Initially, the proposed memetic algorithm (genetic algorithm and great deluge algorithm) generates chromosomes, the genes in the chromosomes indicates the images of the database. The chromosome can’t contain repeated genes and the genes values depend on the number of database images that will be queried. The features extracted from every image are gathered as a feature set and the set of features from the query image also are extracted. Then each chromosome is subjected to the crossover, mutation (genetic operators) and great deluge algorithm local search in order to generate new chromosome. Moreover; the parameter settings of the proposed MA were determined experimentally.
3.1 Solution representation
In this study, the proposed memetic algorithm (GA and GDA) uses a direct representation for each candidate solution (chromosomes) in the population, which consists of information on the number of images in the database and the number of matches in a binary form.
3.2 The initial population
Initially, a number of chromosomes are generated randomly; the number of chromosomes is the population size (pop_size). The number of required images which are related to the input query image will determine the number of genes in each chromosome. shows how the chromosome is generated.
Fig. 2 Chromosome form.
Generally, the GA starts by computing the fitness of each candidate solution in the initial population. While stopping criterion is not met, the following processes are employed: (i) Select a solution for reproduction using some selection mechanisms (e.g. roulette wheel). (ii) Generate offsprings using crossover and mutation operators. (iii) Compute new generations until either an optimal solution is found or the maximum number of generations is reached.
3.3 Crossover operation
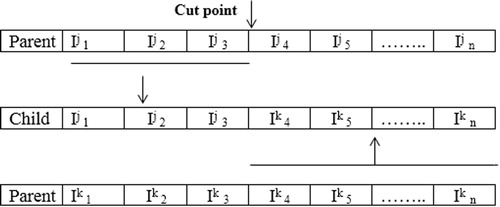
Crossover is the main operator in the genetic algorithm. Crossover generates a new generation (chromosomes) from two parents using single cut point [Citation16]. Where, this operation works by determining single crossover point on both selected parent chromosomes, a random number between 1 and 1c-1 is selected, 1c is the chromosome length. At the selected crossover point the parent chromosomes are cut, and the components after that point is exchanged between the parent chromosomes. shows the generated offspring using the operation of crossover.
Fig. 3 Crossover operation.
3.4 Mutation operation
The mutation operator produces random changes in solutions, which provides a chance for lost solutions from the population. Mutation operation is performed using bit-by-bit method. The mutation operator will be executed if the ratio of mutation (Pm) is verified. In this work, Pm equals 0.02 and the point that will be mutated is randomly selected. shows the offspring that was generated by the mutation operator.
Fig. 4 Mutation operation.

3.5 Great deluge algorithm
Before moving to the next generation, a local search algorithm is applied to improve a solution (chromosome) obtained from the genetic algorithm after the genetic operators are performed. This process makes the convergence of genetic algorithm faster. We then re-insert the resulted solution from the local search back to the genetic algorithm for the next generation. Then the process will proceed to the next generation and updates the population of chromosomes.
This work uses the Great Deluge Algorithm (GDA) for increasing the quality of solution (weight) through increasing the fitness number, which helps in enhancing the process of exploitation during the searching process. GDA is incorporated as a local search algorithm into the employed genetic search process to improve the exploitation process rather than the exploration process. A local search attempts to improve the quality of a solution while working as a perturbation operator.
The GDA is introduced by Dueck in 1993 [Citation28]. It mimics a flood, where the “water level” (WL) is continuously rising and the candidate solution must lie above the “surface” in order to survive [Citation28]. GDA is different from other local search algorithm (e.g. hill climbing or simulated annealing) in the acceptance method of a candidate solution from a neighborhood. For example, it accepts all solutions with fitness function (solution quality) values less than or equal to the current boundary value.
During the run process, the GDA may accept a worse solution than the current best solution in hand. First step, choose an initial configuration. Second step, modify the old configuration into a new one. Third step, compare the quality values of the two configurations. Fourth step, decide whether the new configuration is “acceptable” or not. If the new configuration is acceptable, then it serves as the old configuration for the next step. If the new configuration is not acceptable, the algorithm will proceed with a new modification of the old configuration. The crucial parameter is the “rain speed”, which controls convergence towards better solutions. A worse solution will be accepted if its fitness value is larger than of WL, this is considered as the control parameter. shows a generic pseudo code for the GDA.
Fig. 5 A generic pseudo code of the GDA [Citation38].

The WL is initialized with the value WLinitial. The WLinitial will increase in every iteration by the “rain speed” (Up). As suggested by Bykov [Citation32], we use parameter Up. Where, the GDA is robust to this parameter. It is calculated by Eq. Equation(2)(2)
(2) , below:
(2)
(2) Where, f(x’) is the goal value, and N is the number of iterations. This goal value can be estimated either by hill climbing algorithm or by previous results. The WLinitial is set to the lower boundary of the obtained results. Generally, in order to control the search space, the GDA uses a lower water level for a maximization approach. The GDA increases the water level with a fixed positive value. Where, GDA initializes WLinitial and set it to the quality of the initial solution S, then it calculates the increasing rate ‘β’ using Eq. Equation(3)
(3)
(3) .
(3)
(3)
In our proposed algorithm, solutions with higher fitness values are always accepted, while solutions with fitness values equal to the best solution’s fitness value are accepted if they have a smaller number of matching features. The GDA terminates when a solution reaches the estimated quality of the final solution (an improved solution in term of quality). The search continues until reaching the lower limit (estimated quality). shows the parameters setting of the proposed MA. shows the pseudo code of the proposed MA.
Table 1 Shows the parameters setting of the MA.
Fig. 6 The pseudo code of the MA [Citation39].

3.6 Fitness function
Using a selected fitness function, the algorithm evaluates all candidate solutions from the entire population. The fitness function indicates how good a candidate solution is. Mainly, the algorithm’s performance and the solution of the optimization problem depend on the fitness function. Therefore, the way to select a fitness function is very important in the algorithm design phase.
The next step is to determine fitness value (quality) for the generated new chromosomes. Fitness depends on the match between the image to be queried and the feature sets of the newly generated chromosomes. The best chromosome is the chromosome which has the minimum similarity difference compared with the input query image. Genes of the optimal obtained chromosome indicates the most related images to the input query image. The following is the equation of the similarity difference, see Eq. Equation(4)(4)
(4) .
(4)
(4)
In the proposed algorithm, the similarity of the two images is measured as: The difference between of the total query image features (denote as ) and database image features (
). The difference must be less than or equal to 0.005 (e.g. similarity difference ≤ 0.005) to consider that the two images are similar. The similarity difference of the proposed fitness function was determined experimentally.
3.7 Selection of chromosomes
Selection is the process that guides the algorithm towards an optimal solution by preferring chromosomes with high fitness. In this study, a roulette wheel is used as the selection mechanism of best retrieved images from the database based on the amount of features matches. The process is repeated until the maximum number of iterations is reached, then the best chromosomes that have the highest fitness number are selected from the set of chromosomes that are previously obtained. These optimum chromosomes were utilized for retrieving the related images from the image database. This means, the similar images that will be retrieved effectively are the images with the indices which are represented with the genes of the best chromosomes. illustrates the steps of similarity measure based on MA for the proposed CBIR technique.
Fig. 7 Similarity measure based on Memetic algorithm for the proposed CBIR technique.

4 Image dataset
Corel dataset was used in our experiments; the Corel dataset consists of 10,908 different images with the size of 256 * 384 or 384 * 256 for each image. Therefore; the results were reported using ten semantic sets, each set has 100 images. These groups of datasets are Buses, Mountains, Beach, Elephants, Food, Flowers Africa, Horses, Dinosaurs and Buildings. The results were reported using these groups because most of the remarkable researches [Citation9,Citation13,Citation33Citation[34]Citation[35]Citation[36]–Citation37] used these groups to show the effectiveness of their CBIR methods. Thus; a clear results comparison can be conducted in using the reported results. The steps for the proposed CBIR technique using the MA is shown in .
5 Results and discussion
The proposed CBIR system was tested with number of QIs and the similar images were retrieved from the corel image database. In order to achieve this, the features including color histogram, shape and color texture were extracted from each image in the database. shows the original butterfly image, gray scale butterfly image, the filtered grayscale butterfly image using median filter, edge detected butterfly image using the canny algorithm. – shows some retrieved images and their query images.
Fig. 8 Shape features extraction steps

Fig. 9 a. QI b. Some retrieved images.

Fig. 10 a. QI b. Some retrieved images.

Fig. 11 a. QI b. Some retrieved images.

Color signature was used to compute the features of color histogram in terms of Variance and median, canny edge detection method was used to calculate and compute the shape features, color texture was used to compute the features of GLCM in terms of standard deviation, homogeneity, mean value, contrast and energy. All the features extracted from color signature, shape and color texture grouped and combined with each other in the created feature set and after the feature set is extracted from the database images, the feature set is compared with the input query image’s feature set using the GA in order to retrieve the similar images from the stored images in the database. After completing the process of feature extraction, MA was used for measuring the similarity.
The GA generates random chromosomes (pop_size) with a length of n, the number of required images that are related to the QI will determine the number of genes in each chromosome. The feature extraction is done for the chromosomes that were generated and for the query image. The chromosomes are then subjected to the mutation and crossover operations, and great deluge local search and selection mechanism in order to find the optimum chromosome. After crossover, mutation and great deluge local search operations were completed the chromosomes that have the optimal values are selected. These selected chromosomes are the indices of the images that are relevant to the query image. This procedure is repeated till reaching the maximum number of iterations Itermax = 1000.
5.1 Evaluation of the retrieval (precision/recall)
Precision (specificity) is a measure of the system ability in retrieving only the similar images to the query image. The Recall rate which is known as true positive rate or sensitivity, measures the ability of CBIR systems in terms of number of similar image retrieved with their similar images in the database. To elaborate the results, precision and recall were computed based on number of query images (from the test dataset) and the similar images that were retrieved from the corel image database.
(5)
(5)
(6)
(6)
Eqs. Equation(5)(5)
(5) and Equation(6)
(6)
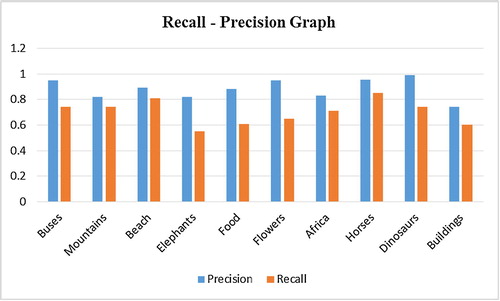
(6) compute the precision and recall for the query image [Citation1]. shows recall-precision that was computed for some QI and their retrieved images. shows the graph of the same precision-recall for our CBIR system. The graph shows that our CBIR system is highly effective and robust for the retrieval of images. Experimentally, when the number of similar images retrieved is increased, the precision and recall will be improved. The reported results using the combination of extracted features and MA techniques show very promising improvements in terms of efficiency and accuracy of the CBIR overall process.
Table 2 Recall-Precision measurements.
Fig. 12 Recall and Precision graph.
5.2 Evaluation on Corel image set
The proposed CBIR system was compared with some of the recent CBIR systems [Citation9,Citation13,Citation33Citation[34]Citation[35]Citation[36]–Citation37] , in order to measure the usability of the proposed method. The motivation for this selection to compare with these methods is that the results of these methods were reported using a common denomination of ten semantic sets, each set has 100 images of Corel dataset. Thus; a clear results comparison can be conducted using the reported results. Hence, the performance comparison can be conducted. shows the comparison of the average precision for each group of the proposed system with other comparative systems. The results indicate that the proposed system obtained better performance in term of precision than other systems. shows the comparison of the average recall rates for each group of the proposed system with the same comparative systems, the recall results of the proposed system obtained the best recall rates. illustrates the precision performance of proposed system with other recent systems. illustrates the comparison of the recall rates performance with the same comparative systems. As illustrated in , the proposed system obtained the best recall rates.
Table 3 Comparison results of the proposed method against other retrieval standard methods based on average precision.
Table 4 Comparison results of the proposed method against other retrieval standard methods based on average recall.
Fig. 13 Comparison results of the proposed method against other retrieval standard methods based on precision.
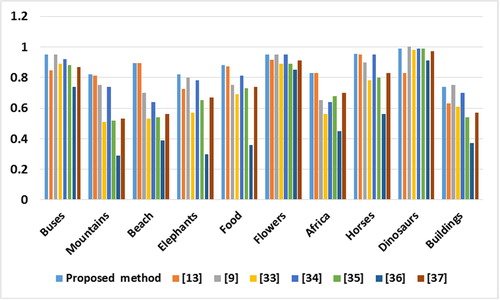
Fig. 14 Comparison results of the proposed method against other retrieval standard methods based on recall.
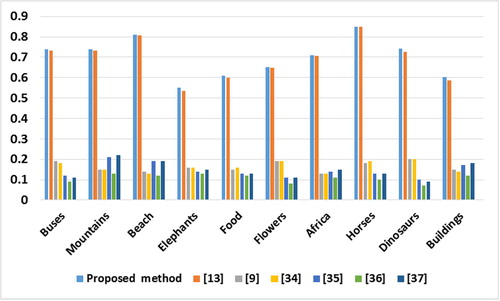
In conclusion, the above comparison results indicates that the proposed system improved the precision and recall rates and outperformed the other state-of-the-art methods [Citation9,Citation13,Citation33Citation[34]Citation[35]Citation[36]–Citation37] in terms of precision and recall rates, where the average precision and recall rates were 0.882 and 0.7002 respectively. This is because the authors in [Citation9,Citation13,Citation33Citation[34]Citation[35]Citation[36]–Citation37] developed CBIR systems that extract a limited number of feature sets, which limit the efficiency of retrieval. While this work extracted robust and extensive set of features utilizing color signature using color histogram technique, shape using neutrosophic clustering algorithm and canny algorithm, and color texture using GLCM. Moreover; this work used the meta-heuristic techniques to optimize the precision of the retrieved images. Where, incorporating GD algorithm with the GA increased the quality of solution (weight) through increasing the fitness number, which helped in enhancing the process of exploitation during the searching process. The experimental results obviously show that the meta-heuristic techniques help to retrieve the highest number of the relevant images compared with the query image.
6 Conclusion
This work proposed an effective CBIR system using MA to retrieve images from databases. Once the user inputted a query image, the proposed CBIR extracted image features like color signature, shape and texture color from the image. Then, using the MA based similarity measure; images that are relevant to the QI were retrieved efficiently. The conducted experiments based on the Corel image database indicate that the proposed MA algorithm has strong capability to discriminate color, shape and color texture features. Incorporating GD algorithm with the GA increased the quality of solution (weight) through increasing the fitness number, which helped in enhancing the process of exploitation during the searching process. Our proposed CBIR system was evaluated by different images query. The execution results presented the success of the proposed method in retrieving the similar images from the images database and outperformed the other CBIR systems in terms of average precision and recall rates. This can be represented from the precision and recall values calculated from the results of retrieval where the average precision and recall rates were 0.882 and 0.7002 respectively. In the future, filtering techniques will be employed to get more accurate results in the content based image retrieval system.
References
- B.SyamY.RaoAn effective similarity measure via genetic algorithm for content based image retrieval with extensive featuresInt Arab J Info Technol (IAJIT)1022013
- Sumana I J, Islam M M, Zhang D and Lu G. Content based image retrieval using curvelet transform. In Multimedia Signal Processing, 2008 IEEE 10th Workshop on, pp. 11–16.
- Kanimozhi T, Latha K. A Meta-Heuristic Optimization Approach for Content Based Image Retrieval using Relevance Feedback Method. In Proceedings of the World Congress on Engineering 2013 London, U.K.
- Jaime-Castillo S, Medina J M, Sánchez D. A system to perform cbir on x-ray images using soft computing techniques. In Fuzzy Systems, 2009. FUZZ-IEEE 2009. IEEE International Conference on, pp. 1314–1319.
- Shashank J, Kowshik P, Srinathan K, Jawahar C. Private content based image retrieval. In Computer Vision and Pattern Recognition, 2008. CVPR 2008. IEEE Conference on, pp. 1–8.
- A.A.RadwanB.A.A.LatefA.M.A.AliO.A.SadekUsing genetic algorithm to improve information retrieval systemsWorld Acad Sci Eng Technol1722006613
- Carneiro G, Chan A B, Moreno P J and Vasconcelos N. Supervised learning of semantic classes for image annotation and retrieval. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 2007; 29(3): 394-410
- R.DasS.ThepadeS.BhattacharyaS.GhoshRetrieval architecture with classified query for content based image recognitionAppl Comput Intell Soft Comput201620162
- R.AshrafK.BashirA.IrtazaM.T.MahmoodContent based image retrieval using embedded neural networks with bandletized regionsEntropy176201535523580
- K.SeetharamanS.SelvarajStatistical tests of hypothesis based color image retrievalJ Data Anal Info Process402201690
- L.FengJ.WuS.LiuH.ZhangGlobal correlation descriptor: a novel image representation for image retrievalJ Vis Commun Image Represent332015104114
- Z.ZengA novel local structure descriptor for color image retrievalInformation7120169
- K.V.MadhaviR.TamilkodiK.J.SudhaAn innovative method for retrieving relevant images by getting the top-ranked images first using interactive genetic algorithmProc Comput Sci792016254261
- N.AliK.B.BajwaR.SablatnigS.A.ChatzichristofisZ.IqbalM.Rashidet al.A novel image retrieval based on visual words integration of SIFT and SURFPLoS ONE1162016e0157428
- D.E.GoldbergGenetic algorithms in search, optimization and machine learning1989 372
- U.A.BadawiM.K.S.AlsmadiA hybrid memetic algorithm (genetic algorithm and great deluge local search) with back-propagation classifier for fish recognitionInt J Comput Sci Issues1022013348356
- G.DueckNew Optimization HeuristicsJ Comput Phys104119938692
- Foutsitzi G A, Gogos C G, Hadjigeorgiou E P, Stavroulakis G E. Actuator location and voltages optimization for shape control of smart beams using genetic algorithms. In Actuators, pp. 111–128.
- M.AlsmadiK.OmarFish classification: fish classification using memetic algorithms with back propagation classifier2012
- M.K.AlsmadiK.B.OmarS.A.NoahFish classification based on robust features extraction from color signature using back-propagation classifierJ Comput Sci71201152
- M.AlsmadiK.B.OmarS.A.NoahI.AlmarashdehFish recognition based on robust features extraction from size and shape measurements using neural networkJ Comput Sci610201010881094
- U.A.BadawiM.K.AlsmadiA general fish classification methodology using meta-heuristic algorithm with back propagation classifierJ Theoret Appl Info Technol6632014
- G.JyothiC.SushmaD.S.S.VeereshLuminance based conversion of gray scale image to RGB imageInt J Comput Sci Info Technol Res332015279283
- Shanmugavadivu P, Shanthasheela A. Feature Variance Based Filter For Speckle Noise Removal. IOSR J, 1(16): 15–19.
- Alsmadi M K. A hybrid Fuzzy C-Means and Neutrosophic for jaw lesions segmentation. Ain Shams Eng J.
- Y.GuoA.SengurNCM: neutrosophic c-means clustering algorithmPattern Recogn488201527102724
- M.BencoR.HudecP.KamencayM.ZachariasovaS.MatuskaAn advanced approach to extraction of colour texture features based on GLCMInt J Adv Rob Syst112014
- M.K.AlsmadiK.B.OmarS.A.NoahI.AlmarashdehFish recognition based on robust features extraction from color texture measurements using back-propagation classifierJ Theoret Appl Info Technol1812010
- R.M.HaralickStatistical and structural approaches to textureProc IEEE6751979786804
- Nikoo H, Talebi H, Mirzaei A. A supervised method for determining displacement of gray level co-occurrence matrix. In Machine Vision and Image Processing (MVIP), 2011 7th Iranian, pp. 1–5.
- R.M.HaralickK.ShanmugamTextural features for image classificationIEEE Trans Syst Man Cybernet61973610621
- Y.BykovTime-predefined and trajectory-based search: single and multiobjective approaches to exam timetabling2003University of NottinghamNottingham
- M.B.RaoB.P.RaoA.GovardhanCTDCIRS: content based image retrieval system based on dominant color and texture featuresInt J Comput Appl18620114046
- S.M.YoussefICTEDCT-CBIR: Integrating curvelet transform with enhanced dominant colors extraction and texture analysis for efficient content-based image retrievalComput Electr Eng385201213581376
- C.-H.LinR.-T.ChenY.-K.ChanA smart content-based image retrieval system based on color and texture featureImage Vis Comput2762009658665
- N.JhanwarS.ChaudhuriG.SeetharamanB.ZavidoviqueContent based image retrieval using motif cooccurrence matrixImage Vis Comput2214200412111220
- M.E.ElAlamiA novel image retrieval model based on the most relevant featuresKnowl-Based Syst24120112332
- W FSaccoC R Ede oliveiraC M N APereiraTwo stochastic optimization algorithms applied to nuclear reactor core designProg Nucl Energy4862006525539
- P.MoscatoMemetic algorithms: a short introductionC.DavidD.MarcoG.FredD.DipankarM.PabloP.RiccardoV PKennethNew ideas in optimization1999McGraw-Hill Ltd.UK219234