Abstract
The focus of this article is specific: we propose a metric for evaluating crises that start in or require the response of control rooms of major critical infrastructures. Rather than addressing the vexed issue of how to evaluate crisis management in terms of success or failure, we focus on a subset of crises that carry with them a standard for evaluating how they are managed.
We begin with a central focus in research on high reliability management, namely, critical control room processes. The skills of control operators do not disappear when crises beset critical infrastructures they manage and we discuss the role of control operators in crisis management. A “crisis cycle” is described for control operators and we conclude with its use as a proposed standard for describing high reliability in crisis performance and for evaluating the degree of success or failure of such crisis management. This metric has implications for evaluating the role of crisis leadership and evaluating the role of Incident Command Systems in crisis management.
We do not argue that our proposed approach to evaluating crisis management in terms of control room performance is appropriate for all types of crises, all types of crisis management, all types of high reliability organizations, or even all types of critical infrastructures.
1 Introduction
We write to promote the convergence of two separate strains of research that could mutually benefit from a closer connection. High reliability organization (HRO) and high reliability management (HRM) research have focused on the requirements for providing and maintaining critical public services, while precluding catastrophic events from occurring which could threaten public health and safety (CitationLaPorte, 1996; LaPorte & Consolini, 1991; Roberts, 1993; Roe & Schulman, 2008; Schulman, 1993). For its part, research into crisis management has focused on how organizations cope with catastrophic events once they have occurred, including the identification and analysis of strategies necessary for resilience and successful recovery (CitationBoin, t’Hart, Stern, & Sundelius, 2005; Boin, McConnell, & t’Hart, 2008; Hermann, 1972; Hillyard, 2000; Lagadec, 1997; Mitroff, 2003; Rosenthat, Boin, & Comfort, 2001; Weick & Sutcliffe, 2002).
With their contrasting concerns in preventing versus responding to crises, these two schools of research might seem logically incommensurate. Organizing for prevention entails planning, anticipation and control; responding to crises requires flexibility and, at times, improvisation. Resources committed up front to forestall a crisis are not available for use subsequently when crises occur.
Yet the schools have more conceptual and empirical overlap than is first expected and we argue that recognizing the overlapping issues enhances the approaches of both fields. High reliability management (HRM) research provides an important bridge between the two fields. HRM uncovers the dynamics of organizations managing critical infrastructures successfully within performance bandwidths, where “high reliability” is defined as the safe and continuous provision of a critical service, even (especially) during turbulent or peak demand times (CitationRoe & Schulman, 2008). Crises can and do occur with respect to these performance bandwidths but are managed on less than catastrophic scales by the critical infrastructures concerned. Instead of few major crises – the subject of much of the crisis management literature – HRM presents many cases of lesser failure but of major import to infrastructure managers. The existence of more cases allows HRM research to surmount a significant problem in conventional HRO and crisis research, namely, too many variables in relation to too few cases. In fact, quantitative research has been done on fluctuations in crisis management capacities in HRM settings (CitationRoe & Schulman, 2008).
2 Control rooms
A significant connection between high reliability and crisis management lies in control rooms. HRO and particularly HRM research highlight their importance in the promotion of reliability and the management of complex infrastructures within bandwidths. Control rooms are one of the few institutional frameworks that have evolved to promote high reliability repetitively in the management of complex systems in real-time and over time. They are found in air traffic control, power plants, electrical grids, large water systems, rail networks, telecommunications networks as well as in NASA's spaceflight operations and in nuclear missile and air defense command operations. Control rooms are key to infrastructure management.
Control rooms and their operators are central to the reliable operation of many services that define modern society – electricity, water supply, air and rail transportation, and telecommunications, including cell phones and the Internet. We take these services so much for granted that we order our lives around them, scheduling daily activities and planning our futures in light of these capacities. They are core to much of our economic activity, from production to distribution to sales, not to mention financial deals and transactions that fuel this activity. Thus, many events, such as earthquakes, tsunamis or hurricanes, cause crises precisely because they destroy infrastructures and critical services. Consequently, control operators are not only critically important in recovery from crises; they are instrumental in preventing crises in ways the public never hears about.
Control rooms have special properties that distinguish them from many organizations typically described in organization research.Footnote1 For the purposes of this article, we focus on their capacities to manage in the face of turbulent conditions. Because of component complexity and variety in large technical systems and the variety of external factors that affect them (unpredictable weather and the economy, among others), control operators in critical infrastructures are unavoidably confronted with unusual, varied and unexpected challenges in their operations. It is not surprising, then, that such large networked systems require their own kind of management.
In unitary-organizational, high-reliability settings, low output variance in operations (the high reliability) is maintained by controlling inputs. Thus, guns, gates and guards stabilize the physical environment of nuclear power plants. The plants are treated as base load generators so they are not subject to fluctuating electricity demand. Nuclear power operating regulations (required of all plants) buffer plants and their owner utilities from competitive market pressures. Low and controlled input variance then allows low output variance to occur by means of low process variance – that is, standardized rules, procedures, routines and anticipatory planning.
But in the highly networked settings faced by the control rooms with which we are familiar, it is harder to control inputs. Fires or weather at a distance can confront grid management control rooms with unpredictable generator or line outages. Demand for power can fluctuate dramatically over and throughout the day, building to peak load periods and dropping off swiftly as night approaches and businesses close. With high input fluctuation comes a greater managerial challenge to produce low output variance.
While control variables in conventional organizations (policies, rules and procedures) impose relatively persisting behavioral constraints, operators in control rooms can and must change the values of their control variables quite rapidly and flexibly – one instruction can relatively quickly undo another. Policies, rules and procedures in contrast can be “sticky” – indeed their persistence is an important feature for the control of organizational behavior. Yet air traffic controllers can order a rapid series of adjustments in airspeed, direction and altitude of planes in their sectors. Generation dispatchers can order increases or decreases in generation among operating plants, they can order reserve generators on or off-line, they can make adjustments in the frequency of current across transmission lines and reroute power to avoid line congestion.
Operational reliability under these conditions lies in maintaining the match between operator skills and tasks by managing the high state (or input) variance they confront and transforming it into stable and closely bounded performance (output) variance. Operators endeavor to manipulate control variables to keep system operations within de jure and de facto bounded bandwidths of safe and continuous conditions (CitationRoe, Schulman, van Eeten, & de Bruijne, 2005). Transforming high input into low output variance requires high process variance – flexibility in operator strategies and options – to achieve a “requisite variety” of responses to match the variety of input conditions.Footnote2 Its pursuit leads to a distinctive cognitive approach by control room operators. Much of their cognitive approach to real time is described in the “recognition-primed” model of decisionmaking (CitationKahneman & Klein, 2009; Klein, 1999) as well as in elements of human-factors approaches by others (e.g., CitationCraik, 1947; Woods & Hollnagel, 2006).
In our terminology, successful control operators excel in recognizing patterns and in formulating and storing an inventory of contingent scenarios to guide action across a range of situations. They do this by developing a domain of attention and competence that lies between seeing the infrastructure primarily from the perspective of formal deductive design principles and seeing it only on the basis of prior experience. The scope of their competence lies between the entire infrastructure as a whole and the narrow specificity of a single failure or case.
In addition to this domain of competence and attention, control operators frequently rely on a set of complementary performance modes within and across which they can operate depending on conditions in their infrastructure. In the control rooms we’ve observed, these can range from anticipatory exploration of options (“just-in-case”) when operations are routine and many control strategies and options are available, to a real-time (“just-in-time”) invention of options or improvisation of strategies when conditions are unstable (i.e., adding to variety) operators may operate in a high-risk mode (“just-for-now”) when stability is low and options are few and may also be able, in emergencies when options have dwindled, to impose onto all network participants a single emergency scenario (“just-this-way”) in order to stabilize a situation. These alternate but related performance modes are again part of a requisite variety of responses needed to match the full range of input variance operators can encounter in their systems.
3 Control rooms and crisis management
The special organizational features of control rooms described above, and the skills and competencies of control operators that promote the high reliability management of critical infrastructures, do not disappear when crises beset the infrastructures. If they are ignored or dismissed in emergency response situations, there is a distinct hazard of diminishing high reliability management, thereby accentuating a crisis. Analyzing crises and crisis management from the perspective of control operators raises some surprising and pressing issues in what follows.
No argument is made below that control room are a sufficient condition for reliability or that once established, reliability springs forth automatically. Nor do we argue that a control-room approach to high reliability crisis management is appropriate for all types of crisis, all types of crisis management, all types of high reliability organizations or even all types of critical infrastructures. Our focus is specific only to critical infrastructures with control rooms whose service provision is managed under a set of legal and regulatory reliability mandates.
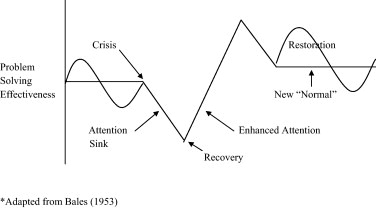
Fig. 1. High reliability management: a nominal crisis cycle. Adapted from Bales (1953).
3.1 Control operators and prospective reliability
Control room operators are frequently the true first responders to events that precipitate crises. This is because high reliability managers in general have a prospective, not retrospective, approach to reliability. For operators, their control room is only as reliable as the first failure that lays ahead, not the many successful performances in the past.Footnote3 Therefore, control operators are alert to conditions that may or do presage trouble, in particular trouble that would undermine the effectiveness of their own cognitive skills.Footnote4 Operators in our experience are quite sensitive to conditions that threaten their skill base.
Starting with this prospective orientation, it is clear much of the present crisis management literature defines a crisis at a point later than control operators see it. For example, the public sees a major storm hit their area, with major flooding; what they do not see are the unexpected problems the state flood control center may have had with its forecasting models or early warning systems in the five days running up to the storm. When these earlier problems damage the later response capacity, it is difficult to say the former are “control room crises” and the later are “the public's real crisis.”
3.2 Control rooms and their crisis cycle
Our research on control rooms suggests that high reliability management progresses through a cycle with respect to a crisis. A full crisis cycle can be schematically depicted in .
Starting from the left side of , control operators “routinely” attempt to maintain operations within a bandwidth of reliable system and cognitive performance. They enter a crisis condition when they confront or anticipate conditions that threaten their cognitive skills to understand a situation by recognizing patterns and formulating action scenarios that they can translate into reliable services.
In other words, the crisis starts for control operators when they are pushed to operate at the edge of or beyond their domain of competence where skills and tasks are matched.Footnote5 This crisis awareness might not correspond to an actual catastrophic failure or loss of service; it may well precede it. In either case, it gets the full attention of operators, as one would expect given their prospective rather than retrospective orientation to reliability. As such, the time period for the crisis cycle among operators may well be advanced in every phase over public perceptions and even the perceptions of organizational or political leaders.
As just noted, outsiders frequently think of a crisis as beginning with the “zero-point” of service, when that service disappears. But for control operators, the crisis began earlier in the cognitive uncertainties surrounding the then normal level of service (up to the “crisis” point in ). In terms of performance modes, what the public sees as confirmation of a crisis – a “just-this-way” emergency declaration – could be a crisis that began for operators well before that declaration with just-for-now band-aids, quick fixes and firefighting operators had to undertake in order to fight off system failure (again, think of system crashes, server problems, and software glitches that affect forecasting software and/or warning systems).
In short, from a high reliability management perspective, there may be two zero points during a crisis: for the public it is the loss of service, for reliability professionals it is the loss of management options. By the time the public sees its zero point, the control operators may well be on their way to recovering their options for subsequent infrastructure restoration and ongoing management.
Recovery of infrastructure performance entails intense and extraordinary problem-solving activity on the part of operators. In a recovery simulation we observed, operators expanded their normal domain of competence to bring basic design principles down to the level of a single issue or case. As one shift manager recounted: “I never stared so hard at such a small piece of [electrical transmission] line before.” It is intense work and team support is crucial. It is important then to understand two simultaneous conditions in : the attention sink of the public to the interruption of service and the reliability professionals’ enhanced attention to increasing options at the same time.Footnote6
In recovery, control operators seek to return to their domain of competence and activity level, with management performance again within bounded bandwidths. The end of the crisis cycle may leave operators in a new “normal” with scenarios added to their inventory and new patterns in their collective experience. This “new normal” may be go completely unnoticed by the public with the end of its crisis, the resumption of service.
3.3 Departures from the nominal
It would be wrong to read the nominal crisis cycle in as implying that crisis phases are smooth and regular. Nothing could be further from what we have observed in our study and reading of control rooms. Setbacks during the attention sink and enhanced attention phases have occurred and should be expected (CitationRoe, 2009). These setbacks are often invisible to the public, yet can become real-time crises of their own in the control room. Learning from setbacks can also be important for the patterns and scenarios they add to control operators’ domain of competence. Senior leaders of the critical infrastructures in which these control room setbacks occur may only know about them after the fact, if simply because control room operators have to deal with them when they suddenly occur without recourse to consulting with those “in the front office.”
To summarize, from a high reliability perspective on crisis management, the starting assumption cannot be that a crisis happens “to” an infrastructure in an organizational vacuum. A crisis need not be a disaster suddenly imposed from only one direction, namely, from the outside in. The crisis can take place from the inside out when the prospective orientation of the control room is disrupted and operator skills in pattern recognition and scenario formulation become attenuated. This inside crisis may coincide, precede or lag the outside disaster. If this analysis is correct, a major challenge of crisis management involving critical infrastructures is recognizing and preserving the cognitive skills of control operators in all the phases of crises.
4 A metric for high reliability crisis management?
The high reliability perspective on crisis management allows us to consider a new way to evaluate and compare crisis responses from the standpoint of critical infrastructures. Currently many crisis management evaluations center on output or outcome measures of effectiveness – speed of emergency service delivery in natural disasters such as floods or earthquakes; acres burned and lives lost or property destroyed in fire management, for example. But these output or outcome measures do not allow comparability in management standards or assessments because each disaster and its challenges are so different. Even individual fires are difficult to compare, let alone crisis responses across fires, floods or earthquakes.
But assessing high reliability crisis management from the standpoint of control room processes actually enables a form of comparative evaluation. The standard here would be maintaining the integrity of key cognitive processes and their organizational requirements among control operators surrounding the interruption and resumption of services. Do the actions of leaders track the crisis cycle by making control operations in infrastructures worse or better? The degree to which leaders in crises fail to maintain key cognitive processes across control rooms affected is the degree to which this form of crisis management fails.
Evidence for the preservation of control room capacities can be found first in the functional integrity of communication channels between the control room and other parts of the infrastructure under management, as well as communication between key control room personnel and emergency management personnel, including political leaders in Emergency Operations Centers. Post hoc interviews can provide information concerning internal team communication and cohesion, and formal indicators of problem-solving effectiveness can be and have been formulated from data routinely kept on control actions and consequences.Footnote7 But the most important evidence for high reliability crisis management would be that available in real-time, as a crisis cycle is unfolding. The best way for crisis leaders to gather this evidence, while they can still act on it, is to talk to control room operators and managers.
It is important to clarify the nature of this high reliability standard. We are not suggesting that safeguarding key control room processes is the only important dimension of crisis management. Nor does our analysis indicate that doing well on this metric is sufficient to guarantee successful crisis outcomes. But we do suggest that a failure to recognize the stages of a crisis cycle within control rooms, and failing to support the problem-solving resources that control operators can bring to managing crises can undermine the chances for successful outcomes.
The high reliability standard has implications for crisis leadership relative to infrastructures. Political leaders are often tempted both to clarify and simplify the problem definition of a crisis at a time significantly delayed relative to the appreciation of the crisis by control operators (CitationPreston, 2008). In addition, leaders may attempt to organize tasks and provide motivational support when control operators are already on the upward trajectory of their recovery period. In one crisis, the 1989 earthquake in San Francisco, widespread losses in electrical service beset the major electrical utility, the Pacific Gas and Electric Company (PG&E). The distribution unit, which is responsible for consumer power service, mounted a major service recovery effort organized largely by line crews, switching station personnel and dispatchers. When asked about the factors leading to this successful recovery, the director of the unit replied: “mainly we supervisors just stayed the hell out of the way.”
By not recognizing phase differences along the cycle, leaders have the potential to unknowingly inject risk into disaster response and recovery. Premature closure on a complex problem can undermine the pattern recognition, scenario formulation and performance mode flexibility of operators. Moreover, these problems in leadership can persist into the “new normal.”
As indicated, control rooms have low friction in control variables – their values often need to be quickly adjusted and new instructions undone by later ones. Control rooms are embedded in network relationships in which these adjustments are accepted. But institutional controls are “sticky” – decisions, policies and rules by leaders can carry momentum and become routinized and rigidified. This is, to repeat, an important foundation of organizational authority.
Yet in the context of control rooms, this persistence can undermine the flexibility of control operators to invent options and shift performance modes, and thus degrade their capacities in the “new normal” that concludes a crisis cycle.Footnote8 It is not uncommon that at the conclusion of a crisis, in the rush to affix accountability and convey reassurance to the public, new regulatory rules and restrictions can be imposed on infrastructures. Some of these can have significant impact on control operators – restricting options or limiting their performance modes.Footnote9 We have drawn the “new normal” in above prior levels of performance; it could just as well be lower and unintentionally so because of counterproductive crisis leadership.
What then is the role of leadership from a high reliability crisis management perspective? It is to recognize that effective leadership means knowing when to step out of the way of the control rooms. Leadership means ensuring that all those better practices identified in the crisis management literature (CitationBarton, 2007; Boin et al., 2005, 2008; Rosenthat et al., 2001) meet the test of supporting rather than undermining the cognitive skills and processes of control operators. Leadership includes recognizing and reinforcing the learning ability of control operators as they operationally revise strategies to make them more reliable before, during and after a crisis. Such issues are particularly important with respect to Incident Command Systems, which are now frequently mandated for the management of major crises and disasters (CitationFEMA, 2008). These disaster management structures and the “all hazards” approach (also mandated for many of them) should be carefully assessed in relation to the control room process reliability requirements introduced here.Footnote10
In conclusion, we suggest in this article that the convergence of HRO/HRM perspectives with crisis management approaches identifies a new way to evaluate the role of leadership through the entire cycle of a crisis, namely, how responsive are leaders to reliability requirements in a crisis throughout its phases? This could ultimately be an advance for both crisis research and leadership practice.
Notes
* In writing this article, Roe was supported by the National Science Foundation (NSF) under EFRI Grant no. 0836047.
1 While control rooms are one of the few institutional frameworks that successfully promote high reliability in task performance and operational outputs, they are under-researched in organization theory. True, a great deal has been written about them in terms of their physical design and technology, and they have been analyzed from the standpoint of human factors research (CitationIvergard & Hunt, 2008; Noyes & Barnsby, 2002; Stanton, Salmon, Jenkins, & Walker, 2009). But organizational analyses remain scarce (CitationKlein, 1999; Perrin, 2006; Sanne, 2000; Woods & Hollnagel, 2006).
2 The concept of requisite variety in relation to control systems was first described by Ross CitationAshby (1966). It has been applied to organizations more recently by Karl CitationWeick (1999).
3 This prospective approach can be contrasted with a retrospective approach to assessing reliability based on successful past performances. This latter approach is seldom associated with high reliability organizations (CitationBoin & Schulman, 2008).
4 In an insightful analysis CitationKahneman and Klein (2009) argue for the importance of “high validity environments” which feature stable relationships between cues, patterns and objective conditions, for effective application of the skills of control operators. The deterioration of these conditions – the loss of the applicability of learning – is itself a signal of crisis for control operators.
5 More formally, when operators are compelled to operate at the edge or beyond their domain of competence, they no longer are able to estimate risk by either pattern recognition or worst-case scenario formulation. Instead, they now operate where the hazard is precisely that of being unable to calculate or estimate risks. When this happens, the crisis in the control room can progress from operating under risk to operating under uncertainty (i.e., the magnitude of the hazard or its probabilities cannot be estimated) to operating under ignorance where the hazards – and thus worst-case scenarios – are unknown.
6 A longer article would detail the role of the Incident Command System in recovery after a major disaster. Such details would not alter the point here about the role of control rooms in the restoration of services of their own infrastructures.
7 For an example of such indicators see CitationRoe and Schulman (2008).
8 For an early and insightful analysis of this and other “pathologies” that can afflict crisis management organizations see CitationSmart and Vertinsky (1977).
9 During the “electricity crisis” in California as emergency controls were imposed by grid control operators forcing load reductions leading to rolling blackouts throughout the state, the California Public Utilities Commission considered a policy change which would have given the Commission itself the authority to declare a “state of emergency” rather than the control room. Control operators we spoke to all believed this to be a threat to their “just this way” performance mode, with the potential loss of critical options. The policy was not enacted.
10 One recent assessment framework from a different reliability perspective can be found in a recent RAND analysis (CitationJackson et al., 2010).
References
- W.R. Ashby . Design For A Brain. 1966; Chapman and Hall: London
- R. Bales . The equilibrium problem in small groups. T. Parsons , R. Bales , E. Shils . Working papers in the theory of action. 1953; Free Press: New York 111–161.
- L. Barton . Crisis leadership now. 2007; McGraw-Hill: New York
- A. Boin , P. t’Hart , P. Stern , B. Sundelius . The politics of crisis management: Public leadership under pressure. 2005; Cambridge University Press: Cambridge
- A. Boin , A. McConnell , P. t’Hart . Governing after crisis. 2008; Cambridge University Press: Cambridge
- A. Boin , P. Schulman . Assessing NASA's safety culture: The limits and possibilities of high reliability theory. Public Administration Review. 68 2008; 1050–1062.
- K.J.W. Craik . Theory of the human operator in control systems. British Journal of Psychology. 38(56–61): 1947; 142–148.
- FEMA, 2008 Federal Emergency Management Agency . National incident management system. 2008; US Government Printing Office: Washington
- C.F. Hermann . International crises. 1972; Free Press: New York
- M. Hillyard . Public crisis management. 2000; iUniverse: New York
- T. Ivergard , B. Hunt . Handbook of Control Room Design and Ergonomics. 2008; CRC Press: Boca Raton, FL
- B. Jackson , K. Faith , H. Willis . Evaluating the reliability of emergency response systems for large-scale incident operations. 2010; The RAND Corporation: Santa Monica, CA
- D. Kahneman , G. Klein . Conditions for intuitive expertise. American Psychologist. 64 2009; 515–526.
- G. Klein . Sources of power: How people make decisions. 1999; MIT Press: Cambridge
- P. Lagadec . Learning processes for crisis management in complex organizations. Journal of Contingencies and Crisis Management. 12 1997; 160–169.
- T.R. LaPorte . High reliability organizations: Unlikely, demanding and at risk. Journal of Contingencies and Crisis Management. 4 1996; 60–71.
- T. LaPorte , P. Consolini . Working in practice not in theory: Theoretical challenges of high reliability organizations. Public Administration Research and Theory. 1 1991; 19047.
- I. Mitroff . Crisis leadership: Planning for the unthinkable. 2003; Wiley: New York
- J. Noyes , M. Barnsby . People in control. 2002; IEE: London
- C. Perrin . Shouldering risk: The culture of control in the nuclear power industry. 2006; Princeton University Press: Princeton, NJ
- T. Preston . Weathering the politics of responsibility and blame: The Bush Administration and its response to Hurricane Katrina. A. Boin , A. McConnell , P. t’Hart . Governing after crisis. 2008; Cambridge University Press: Cambridge 33–61.
- K. Roberts . New challenges to understanding organizations. 1993; Macmillan: New York
- E. Roe , P. Schulman . High reliability management. 2008; Stanford University Press: Stanford
- E. Roe , P. Schulman , M. van Eeten , M. de Bruijne . High reliability bandwidth management in large technical systems. Journal of Public Administration Research and Theory. 15 2005; 263–280.
- E. Roe . Preventing transboundary crises: The management and regulation of setbacks. Review of Policy Research. 26(4): 2009
- U. Rosenthat , A. Boin , L. Comfort . Managing crises. 2001; Charles C. Thomas: Springfield, IL
- J.M. Sanne . Creating Safety in Air Traffic Control. 2000; Arkiv Forlag: Sweden
- P. Schulman . The negotiated order of organizational reliability. Administration and Society. 25 1993; 353–372.
- C. Smart , I. Vertinsky . Designs for crisis decision units. Administrative Science Quarterly. December (22) 1977; 640–657.
- N. Stanton , P. Salmon , D. Jenkins , G. Walker . Human factors in the design and evaluation of central control room operations. 2009; CRC Press: Boca Raton, FL
- K. Weick . Sensemaking in organizations. 1999; Sage Publications: New York
- K. Weick , K. Sutcliffe . Managing the unexpected. 2002; Jossey-Bass: San Francisco
- D. Woods , E. Hollnagel . Joint cognitive systems. 2006; CRC Press: Boca Raton