
Abstract
Energy consumption has become a key concern for manufacturing sector because of negative environmental impact of operations. We develop constructive heuristics and multi-objective genetic algorithms (MOGA) for a two-machine sequence-dependent permutation flowshop problem to address the trade-off between energy consumption as a measure of sustainability and makespan as a measure of service level. We leverage the variable speed of operations to develop energy-efficient schedules that minimize total energy consumption and makespan. As minimization of energy consumption and minimization of makespan are conflicting objectives, the solutions to this problem constitute a Pareto frontier. We compare the performance of constructive heuristics and MOGAs with CPLEX and random search in a wide range of problem instances. The results show that MOGAs hybridized with constructive heuristics outperform regular MOGA and heuristics alone in terms of quality and cardinality of Pareto frontier. We provide production planners with new and scalable solution techniques that will enable them to make informed decisions considering energy consumption together with service objectives in shop floor scheduling.
after two revisions
The online version of this article is available Open Access
1. Introduction
A significant proportion of energy used in manufacturing is currently generated through fossil fuels (CitationRahimifard et al, 2010). Therefore in the foreseeable future, energy efficiency will become the main focus in manufacturing because of both scarce resources and increasing greenhouse gases from production processes. In terms of energy-efficient manufacturing, minimization of energy use, recovery of parts, transformation of wastes into key resources are required to align the manufacturing processes with principles of sustainable production and resource efficiency.
The manufacturing sector uses massive amounts of energy and contributes to 36% of global CO2 emissions (CitationOECD-IEA, 2007). In the United Kingdom, industry electricity consumption accounts for 31% of the total. This is equivalent to 69 million metric tonnes of CO2, which approximates to annual greenhouse gas emissions from more than 14.3 million passenger vehicles (calculation obtained from CitationEPA, 2013). This has obliged manufacturing companies to put more efforts into reducing their environmental impact and take proactive measures to consider likely energy shortages in their operations. One way to do this is by using energy-efficient operations (CitationDuflou et al, 2012) such as selectively shutting down machines during idle time (CitationMouzon et al, 2007; CitationMouzon and Yildirim, 2008) or operating them at speeds allowed by the set service level targets.
Manufacturing scheduling has traditionally been influenced by performance-oriented metrics such as makespan, float time, and tardiness. Minimizing carbon footprint on the shop floor involves multifaceted challenges that necessitate a multi-objective approach because of conflicting objectives of, for example, makespan and energy consumption. It entails complex decision making and trade-off analysis by the operations managers. As one of the first attempts in this field, CitationMansouri et al (2016) addressed a bi-criteria two-machine flowshop scheduling problem to minimize total energy consumption and makespan. They showed the conflict between the two objectives and developed an O(n3) heuristic to solve large size problems. Two-machine flowshop scheduling problems have attracted significant attention from practitioners and researchers. There are many real world problems that involve scheduling of two machines. These include applications for instance in printed circuit board (CitationSabouni and Logendran, 2013), shampoo production (CitationBelaid et al, 2012), and metalworking (CitationUruk et al, 2013). In this paper, we extend the work of CitationMansouri et al (2016) by developing a new O(n2) heuristic and multi-objective genetic algorithms (MOGAs) for a sequence-dependent two-machine permutation flowshop scheduling problem to extend applicability of the concept of green scheduling in real life applications. In particular, we examine the effect of hybridizing the MOGA with the constructive heuristics to improve the efficiency and the effectiveness of the search. We validate the performance of the developed solution techniques through comprehensive experiments based on three performance metrics, namely, quality (distance with the lower bound to the problem), diversity (number of unique sequences in the solution set), and cardinality (size of the solution set) of the Pareto frontiers.
The remainder of the paper is organized as follows. Section 2 reviews the literature. Section 3 introduces the mathematical model. Solution techniques including the new constructive heuristic and MOGAs are described in Section 4. The experimental set-up and results are presented in Section 5. Finally, Section 6 discusses the results, concludes the paper, and identifies future research directions.
2. Literature review
Research on incorporating energy considerations into manufacturing scheduling is rather limited. Previous work focused on minimizing energy consumption and total completion time on a single machine with multi-objective mathematical programming models used for job scheduling where energy savings were achieved by turning machines off during idle time but not by considering energy used during machine operation (CitationMouzon et al, 2007).
Processing time and energy consumption of computer numerically control machines can vary significantly by changing cutting speed, feed rate, depth of cut, and nose radius (CitationAhilan et al, 2013). It is possible to explore opportunities for saving energy by relaxing the fixed processing times assumption. For example, CitationFang et al (2011) developed a multi-objective mixed integer linear programming (MOMILP) model to minimize completion time and energy by varying operation speed on a single machine. In this work, decisions on operation speed affected peak load and energy consumption. Although they analysed a flowshop environment with two machines, they did not consider set-up times, which have a direct impact on the completion time.
Machining time dictates the energy demand and the specific energy consumption of a machine tool is affected by the processing speed (CitationDiaz et al, 2011). Not surprisingly, in the computing field, energy consumed increases with higher execution speeds of processors (CitationFang and Lin, 2013) and jobs executed at a higher machine speed for time savings incur a greater energy consumption.
It is possible to build mathematical models to predict power consumption based on machining parameters. One such work by CitationAhilan et al (2013) reports the use of neural networks to examine the effect of turning parameters such as cutting speed, feed rate, depth of cut, and nose radius on power consumption and surface roughness. The authors develop a non-linear parametric equation that estimates power consumption based on various levels of machining parameters and report a positive relationship between power consumption and turning parameters. It is then possible to use this estimate of power consumption in scheduling problems that consider power consumption explicitly, such as those studied by CitationMouzon et al (2007), CitationFang et al (2011), CitationLiu et al (2013), or this study.
Another work that should be noted is by CitationHe et al (2005), who developed a bi-objective job-shop scheduling model to optimize both the energy consumption and the makespan, where energy consumption was calculated as a function of the unload power of the machine and the machining time. The authors used a heuristic algorithm based on tabu search to solve this problem.
On the other hand, energy consumption can be analysed separately during machine operation and idling. CitationLiu et al (2013) addressed this problem and developed a branch-and-bound algorithm based on the NEH heuristic (CitationNawaz et al, 1983) to solve the permutation flowshop problem with idle energy minimization. Their objective was to minimize the total wasted energy consumption as the weighted sum of idle times on each machine.
Considering the extant work published in this field, scheduling with set-up times received relatively lower attention, probably because of the complexity of the problems. On scheduling with set-up times, CitationGharbi et al (2013) developed lower bounds for the two-machine flowshop scheduling with sequence-independent set-up times based on waiting time-based relaxation, the single machine-based relaxation, and the Lagrangian relaxation, and recommended hybridizing the single machine-based and the Lagrangian relaxation-based lower bounds for sequence-dependent problems.
Some factors such as peak and off-peak times set by energy providers affect energy consumed on the shop floor and associated costs; yet they are outside the decision space of the manufacturer. Nevertheless, it is possible to incorporate such factors into the scheduling models. For example, CitationLuo et al (2013) studied machine electricity consumption costs in a hybrid metalworking flowshop and used constant power/speed ratios to optimize the electricity consumption during peak and off-peak hours. They recommended combining fast and slow operating machines to achieve higher energy efficiency.
Not only cost minimization goals but also environmental sustainability concerns call for minimizing energy consumption in manufacturing operations. There is usually a trade-off for the manufacturer between green and regular production technologies. CitationGong and Zhou (2013) analysed this trade-off from the perspective of emissions trading and observed that such a trade-off is governed by the relationship between the additional cost per energy consumption allowance saved and the trading prices.
In relation to the mathematical formulation of scheduling problems with set-up times, CitationAllahverdi et al (2008) have produced a detailed review and in terms of solution approaches CitationYenisey and Yagmahan (2014) report on the use of heuristic algorithms in permutation flowshop scheduling problems. Both works can serve as a good starting point for the reader who wish to deepen their knowledge in this field.
To summarize, machining parameters, specifics of operations, the nature of the problem at hand, and external variables have a role to play in minimizing energy consumption in manufacturing. With the advancement of manufacturing technologies, machines can now be operated at variable speeds accompanied with a corresponding energy consumption profile. However, the research on including energy consumption with variable speeds is yet to grow. Continuing on a previous work by CitationMansouri et al (2016) that analyzes the trade-off between minimizing makespan, a measure of service level and minimizing total energy consumption, an indicator of environmental sustainability, we are aiming to address this gap by furthering the modelling of energy consumption explicitly in scheduling and developing heuristic and metaheuristic algorithms to solve this problem.
3. Problem formulation
We address a two-machine permutation flowshop scheduling problem with sequence-dependent set-up times where machines have variable speed. Following from CitationIbrahimov et al (2014) we build a model with a high degree of fidelity, with reasonable assumptions and approximations. The general flowshop scheduling problem consists of n jobs that are to be processed in m machines with fixed, non-negative processing time for all jobs (CitationTiwari et al, 2015). Similar to the bi-criteria problem addressed by CitationLu and Logendran (2012), a set-up is required for processing each job on each machine, and its duration depends on both the current and the immediately preceding job. Set-up times are anticipatory, that is, a set-up can be started before the corresponding job becomes available on the machine. We adapt Graham’s three-field notation (α|β|γ) (CitationGraham et al, 1979) for scheduling problems (CitationT'kindt and Billaut, 2006) where α field describes the shop (machine) environment, β field describes the set-up information, other shop conditions, and details of the processing characteristics and γ field describes the objective to be minimized.
The two-machine flowshop scheduling problem to minimize total energy consumption (TEC) and makespan (or Cmax) with sequence-dependent set-up times is denoted as F2|STsd|TEC,Cmax. We refer to this problem as Problem P, which is a multi-objective optimization problem (MOP). introduces the indexes, parameters, and variables used in the mathematical modelling of Problem P.
Table 1 Indexes, parameters, and variables of the mathematical model
Problem P is NP-hard because the single objective problem F2|STsd|Cmax is known to be NP-hard (CitationGupta and Darrow, 1986). Among the most common approaches to solve MOPs are sequential optimization, weighting method, ε-constraint method, goal programming, goal attainment, and distance-based and direction-based methods (CitationCollette and Siarry, 2004). Readers are referred to CitationT'kindt and Billaut (2006) for a comprehensive survey on the theory and applications of multi-objective scheduling. In the following, we provide basic definitions of the MOP, which are needed to describe the solution techniques.
A MOP seeks to determine a vector of decision variables within a feasible region to minimize a vector of objective functions that usually conflict with each other. Without the loss of generality, an MOP can take the following form: subject to
, where
is the vector of decision variables and Θ is the set of feasible solutions to m objectives. A decision vector
is said to dominate a decision vector
(also written as
) if and only if
and
for a problem with all objectives to be minimized. All feasible solutions that are not dominated by any other feasible solution are called non-dominated or Pareto-optimal. These are solutions for which no objective can be improved without at least one other objective being deteriorated. Problem P can be formulated as a MOMILP problem as follows:
Constraint 2 ensures that the completion time of the first job on Machine 2 is delayed by taking into account the set-up offset, which allows for the set-up on the second machine to start before the first job is completed on the first machine because of the nature of anticipatory set-up assumption in the problem definition. Constraints 3 and 4 specify the earliest completion time of jobs on Machines 1 and 2, respectively. Constraint 5 ensures that set-up changeovers and completion times of the preceding jobs are taken into account in determining completion times of successive jobs. Constraints 6 and 7 specify the sequence of jobs as a tour in travelling salesman problem in which the last job is paired with the first job. Note that the decision variable zj sets the first job in the tour and subsequently all the completion times are calculated accordingly. The subtour issue is handled by Constraint 5, which is only binding for consecutive jobs as defined by xjk decision variables. For non-consecutive jobs, this constraint will be non-binding because of the presence of the big M. In this way, completion time of the last job (which is paired with the first job) will not be affected because of the big M in Constraint 5. Constraint 8 warrants that there is only one first job. Constraint 9 guarantees that exactly one speed factor is selected for each job. Machines’ idle times are calculated by Constraint 10. Finally, Constraints 11 and 12 compute TEC and Cmax, respectively.
4. Solution techniques
To address the computational complexity of the constructive heuristic developed by CitationMansouri et al (2016), which is an O(n3) algorithm (called CH1 in this paper), we first introduce a novel constructive heuristic (CH2) with the reduced complexity O(n2). Subsequently, we develop regular and hybrid MOGAs (denoted by R-MOGA and H-MOGA, respectively) to further improve the effectiveness and efficiency of search for the Pareto frontier of Problem P. Finally, we introduce an ε-constraint method run on CPLEX and random search as two widely used benchmark approaches to assess performance of search heuristics.
4.1. Constructive heuristic 2 (CH2)
The CH2 includes a scheduling module (SM). For this module, we extended the idea of the dominance rules proposed by CitationGupta and Darrow (1986) for single speed two-machine sequence-dependent flowshop scheduling to minimize Cmax to account for variable speed problem defined in Section 3. A local search is carried out at the end to improve quality of the solution. Details of the SM are presented in Algorithm 1. As detailed in Algorithm 1, the SM routine is implemented in three steps. The search parameters are first initialized in Step 0. Subsequently, the jobs are sequenced in Step 1 by using the speed vector , where δij denotes the processing speed factor of job j on machine i; δij∈{v1, v2, v3} representing fast, normal, and slow speeds, respectively. As detailed in Algorithm 1, σ1 and σ2 are two partial sequences and ω is the set of jobs, which are not included in σ1 and σ2. These sets are initialized in Step 0 by setting σ1=σ2=∅ and ω={1, 2, …, n}. During the sequencing routine in Step 1, jobs are taken one by one from ω and added to the end of σ1 or the beginning of σ2. This process continues until n−1 jobs are sequenced in either σ1 or σ2 and there is only one job left in ω. The final complete sequence σ is then formed by placing σ1 at the beginning, ω in the middle, and σ2 at the end: σ=σ1ωσ2. In Step 2, the jobs are scheduled according to the sequence σ and speed vector
. Accordingly, the start and finish times for all jobs on both machines are calculated. Finally, a local search is carried out to improve the quality of the solution. The local search begins by examining jobs one by one to see if removing them from their position and inserting them in subsequent positions could improve Cmax. In this way, the first job is examined for insertion in (n−1) subsequent positions. It is then inserted in the position that yields the maximum reduction in Cmax or left in its current position if no such Cmax-improving move can be found. The second job in the sequence is then examined for insertion in the following (n−2) positions and so on and so forth. On the basis of a given vector of processing speed factors, Algorithm 1 schedules the jobs and calculates Cmax and TEC.
By using this schedule as a starting point, the CH2 (Algorithm 2) seeks for energy-efficient schedules in an iterative loop. It starts with an initial sequence in which all jobs are run at fast speed (ie, v1). In an iterative procedure, the processing speeds of operations are decreased iteratively while keeping the same sequence. The central idea in this procedure is removing idle times on either machine by slowing down machining operations that affect the idle time the most. The idle times are identified by comparing completion times of jobs on Machine 1 (denoted by c1[k]) and their ready times on Machine 2 (represented by r2[k]). The job with maximum |c1[k]−r2[k]| is considered the most promising job (denoted by ξ) for energy saving by reducing machining speed of its respective operations on either machine. If the job is completed on Machine 1 after Machine 2 is ready to process it (ie, c1[ξ]>r2[ξ]), then the speed of respective operation on Machine 2 (ie, δ2[ξ]) is slowed down by one level if not currently run at slow speed. Alternatively, if the reverse situation holds (ie, r2[ξ]>c1[ξ]), the speed of respective operation on Machine 1 (ie, δ1[ξ]) is reduced by one level. In the event that there is no idle time on either machine (except for the first job), the operation with minimum processing time (ie, min pi[k]/δi[k]) is chosen for speed reduction. The resultant schedule is added to Pareto frontier (Ω) if it is not dominated by current members of the frontier. This process continues until all operations are run at slow speed v3.
It is clear that the new algorithm has a complexity of O(n2). Compared with the constructive algorithm of CitationMansouri et al (2016) with complexity of O(n3) (which is referred to as CH1 here), the new algorithm has less computational complexity. This time efficiency has been achieved at the expense of wider exploration of job sequences. Unlike CH1, CH2 does not change the job sequence after alteration of speed levels. As a result, all solutions of the resultant Pareto frontier from CH2 have the same job sequence.


4.2. Multi-objective genetic algorithms
Genetic algorithms (GAs) are adaptive search methods that have been shown to be robust for a variety of combinatorial optimization problems (CitationJog et al, 1991). GAs have successfully been applied to solve a wide range of complex MOPs (CitationCoello et al, 2002). In a typical GA, a set of solutions (called population) are improved (or evolved) over a number of iterations (called generations) using a combination of operators (named genetic operators) such as reproduction, crossover, and mutation (CitationGoldberg, 2006). In this section we provide details of the MOGAs that we have developed to solve Problem P.
4.2.1. Chromosome structure
To represent solutions for Problem P, we use a two-dimensional chromosome structure, including three rows and n columns. illustrates the solution structure for given sequence J1 to Jn.
Figure 1 The chromosome structure for the sequence J1, …, Jn.

4.2.2. Fitness assignment
Fitness of solutions are calculated according to the concept of non-dominated sorting (CitationDeb and Sinha, 2009). To assign appropriate fitness to the individuals in a population taking into account both objectives, we selected the non-dominated sorting method proposed by CitationSrinivas and Deb (1994), which is one of the most commonly used methods for multi-objective optimization using GAs. In this procedure, the population is ranked based on individuals’ level of non-domination. The non-dominated individuals of the population are first identified and assumed to constitute the first non-dominated frontier. These individuals are assigned a large dummy fitness value. To maintain diversity in the population, these dummy fitness values are then shared with solutions in their close neighbourhood, called their niche. In this way, the dummy fitness of an individual is divided by the number of solutions in its niche. The niche dimensions in a given population is calculated using the concept of niche cubicle proposed by CitationHyun et al (1998). The niche size is calculated at every generation. A solution in a less dense cubicle will have a higher chance to survive in the next generation. After sharing, these non-dominated individuals are ignored and the same process is implemented to identify individuals for the second non-dominated frontier. These non-dominated solutions are then assigned a new dummy fitness value, which is smaller than the minimum shared dummy fitness of the previous frontier. The dummy fitness values are then shared and this process is repeated until the whole population is classified into several frontiers and individuals are assigned fitness values.
4.2.3. Selection
An elitist strategy is used to preserve non-dominated solutions found over generations in an archive called Elite Set. The Elite Set is updated at the end of each iteration by adding non-dominated solutions of the current generation and eliminating dominated solutions from the set. Selected solutions from each population are copied into the mating pool. To give fitter solutions more chance to contribute to the next generation, the expected number of each solution is set proportionate to their fitness. For a given solution x with fitness fx, the expected number of copies is calculated as follows: , where PopSize denotes Population Size. Integer parts of E[.] will determine the number of chromosomes to be copied into the mating pool. The remainder of mating pool is filled by randomly selected solutions from the Elite Set.
4.2.4. Genetic operators
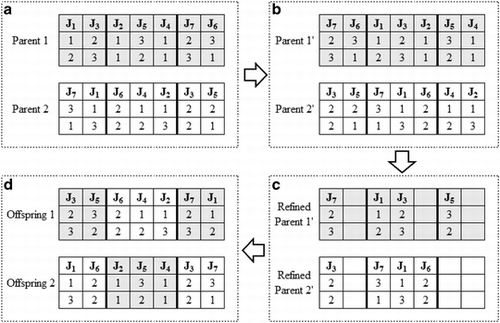
Order crossover (CitationMichalewicz, 1996) is used for recombination. represents an example of recombination using Order Crossover in a problem with seven jobs. The bold lines in designate the segment of the sequences that will remain intact and form part of the offspring. This segment is selected randomly for each crossover operation. A new parent is then created by moving all the genes appearing to the right of this segment (of the original parent) to the beginning of the sequence (). Subsequently, the characters that match the characters between the bold lines of the other original parent are removed (). Finally, the sequence between the bold lines of the original parent and this shortened list from the other parent is used to generate an offspring ().
Figure 2 An example of recombination using Order Crossover in a problem with seven jobs.
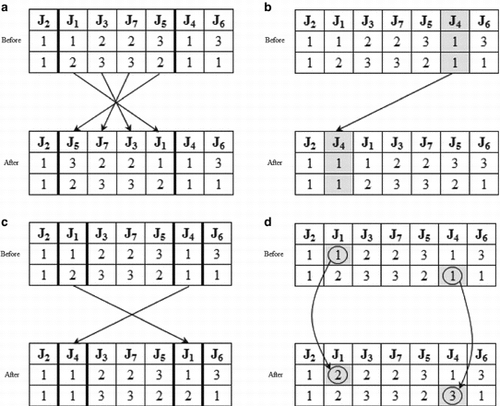
To further diversify the population, a small proportion of the chromosomes will be mutated. Four strategies are used for mutating selected solutions. These include: Inversion, Insertion, Swap, and Speed Alteration. The four mutation strategies are demonstrated in . Inversion simply reverses the order of genes in a randomly selected segment of the chromosome (). Through Insertion, a single gene is taken out from a random position along the chromosome and is inserted in another random position (). Swap operator exchanges the position of two randomly selected genes (). Finally, Speed Alteration changes the speed factors of randomly chosen genes on either machines from one value to another ().
Figure 3 Four mutation strategies. (a) Inversion; (b) Insertion; (c) Swap; (d) Alteration.
The chromosome produced by mutation will be compared with the original chromosome and will replace the original if it dominates it. However, a dominated offspring will still have a chance to replace its parent. Probability of such degrading moves will be high at the beginning and decreases as the search converges to final solution. The probability of accepting a dominated offspring, starting from 1.0, will be decreased exponentially over generations. The probability of accepting a dominated offspring resulted by mutation at a given time t is denoted by Pa(t) and is calculated as follows:
where tmax represents the maximum execution (CPU) time.
4.2.5. The search procedure and hybridization
The overall structure of the MOGAs is represented in Algorithm 3. We develop three variants of MOGAs in this paper, including a regular (R-MOGA) and two hybrid MOGAs (or H-MOGAs). Performance of GAs can often be improved through hybridization with local search and heuristic approaches (CitationCosta et al, 2012). The main difference between regular and hybrid MOGAs in this research are in the initiation of the Elite Set. The initial Elite Set of the R-MOGA is generated randomly whereas in the H-MOGAs, the Elite Set is initiated by the outputs of the two constructive heuristics, namely CH1 and CH2. The resultant hybrid methods are denoted by H-MOGA1 and H-MOGA2, respectively. This will give the H-MOGAs an initial advantage in terms of better starting points. Moreover, the solutions found by the constructive heuristics will have the chance to contribute to the generation of offspring.

4.3. Other benchmark methods
To have baselines for comparing performance of the above search methods, we use an ε-constraint method implemented in CPLEX and a random search (RS). Using CPLEX provides the opportunity to examine the practicality of existing optimization tools in solving Problem P. Comparisons with RS on the other hand, will serve as a sanity check to ensure that the performance of the guided search methods is not just a result of computational power of the hardware used to implement them.
5. Experiments and results
5.1. Performance metrics
In this research, we have used three metrics to compare the performance of the solution techniques. These include distance with the lower bound (DLB) as a measure of quality, diversity (DVR) as a measure of the variety of the solution set, and cardinality (CRD) as a measure of the size of the solution set of the final Pareto frontier found by each algorithm. The accuracy of the Pareto frontier Ω is measured by its distance with the lower bound, denoted by DLBΩ and calculated as follows:
where and TECLB are lower bounds for Cmax and TEC, respectively, as defined in CitationMansouri et al (2016). In short,
and TECLB are calculated by solving a sequence-independent variant of Problem P (defined in Section 3), in which the minimum set-up changeovers from all other jobs are considered as the required set-up for any given job irrespective of their position in the sequence. The Cmax of the sequence-independent problem can be found in polynomial time using the algorithm of CitationYoshida and Hitomi (1979). CitationMansouri et al (2016) proved that Cmax of the sequence-independent problem is a lower bound for Cmax of Problem P when all operations are run at slow speed. Moreover, they showed that TEC of the sequence-independent problem is lower bound for TEC of Problem P when operations are executed at slow speed and under some non-restrictive conditions. The diversity of the Pareto frontier Ω is denoted by DVRΩ and it represents the number of unique sequences in the final frontier. It should be mentioned that the objective values of a solution are primarily defined by two factors: the sequence of jobs and speed of operations. As such, a single sequence of jobs may lead to different Cmax and TEC values depending on speed factors of operations on the two machines. Considering n jobs and three speed levels for every operations, there are (n3)2=n6 possible combinations of speed factors for any sequence of jobs. The DVR metric captures the number of unique sequences regardless of speed in the Pareto frontier, which serve as an indicator of flexibility in production planning. The more diverse is the Pareto frontier, the more flexibility production planners will have in job sequencing. Finally, the total number of solutions in the frontier is the cardinality of the Pareto frontier Ω and denoted by CRDΩ, which reflects the total number of solutions in the Pareto frontier regardless of the uniqueness of sequences.
5.2. Experimental design
We used a full factorial design of experiments for a F2|STsd|Cmax,TEC problem with 480 problem instances (30 for each combination of factors) based on the number of jobs (n) set-up to processing time ratio (sijk) generated using the experimental setting given in . Then we solved these problem instances using seven algorithms: CPLEX, CH1, CH2, H-MOGA1, H-MOGA2, R-MOGA, and RS.
Table 2 Summary of experimental design
In , we based the number of jobs in our experiments on previous flowshop scheduling research by CitationNaderi et al (2009). Following from the classical problem introduced by CitationTaillard (1990) and revisited by CitationRuiz et al (2005) we used uniformly distributed processing times in the experiments. In order to gain insights about the impact of set-up times, we followed the set-up to processing time ratio investigated by CitationRuiz and Stützle (2008). We took the idle time energy consumption parameter from CitationMouzon et al (2007). The work of CitationAhilan et al (2013) was instrumental to estimating processing speed and energy conversion rate. We obtained energy conversion rate distribution from CitationAhilan et al (2013) and drew this parameter from the given distributions for each problem set. In accordance with the work of CitationAhilan et al (2013) and CitationMouzon et al (2007), each problem instance in the data set satisfied the condition: min{(λ1−λ2) and (λ2−λ3)}⩾max(ϕ1, ϕ2).
5.2.1. Setting up the search methods
Parameters of the MOGAs were tuned empirically on a number of test problems in comparison with true Pareto frontiers found by CPLEX. The following are the set of parameters used for the MOGAs: Population Size=n; Crossover Rate=0.70; Inversion Rate=0.10; Swap Rate=0.10; Insertion Rate=0.08; Speed Alteration Rate=0.10; and tmax=n seconds.
For a fair comparison, we ran CPLEX under ε-constraint approach for the same time (n seconds) as other search heuristics. To allow for the formation of frontier and to avoid spending too much time at any ε level, we set a limit for 10% of the total time for each ε level before proceeding with the reduced ε value. Incidentally, in deciding on the time spent at each stage, there is a trade-off among the three performance metrics, that is, accuracy, diversity, and cardinality. More time at any given ε level would allow CPLEX to improve accuracy but at the expense of less iterations and hence lower cardinality and diversity. We examined a number of problem instances and observed that 10% provides a fair opportunity for exploration and exploitation of the search space at the same time. The best solution found at each stage is archived and ultimately refined by removing dominated solutions to obtain the set Ω. All algorithms were coded in C++ and run on an Intel Xeon CPU 3.50 GHz with 32.0 GB RAM under Windows 7 Enterprise. Moreover, we used CPLEX 12.5 in Concert Technology to code the MILP model in C++. Statistical analyses were done on IBM SPSS Version 20.
5.3. Results
The LB we defined is very conservative. For each job, it takes the shortest set-up time from job k to job j. Then, it uses the CitationYoshida and Hitomi’s (1979) algorithm to find Cmax. When the ratio of set-up to processing time is low, the LB is closer to the optimal solution. So for problem sets with larger set-up to processing time ratio the LB becomes much farther away from the optimal solution. Part of the gap is because of the looseness of the LB and part of it is because of the factors that affect problem complexity. As our goal was to improve the constructive heuristic developed in CitationMansouri et al (2016), we initially checked how well CH2 performed against CH1 in terms of CPU time and the three performance metrics we defined in Section 5.1. As it can be seen from , CH2 outperforms CH1 in CPU time required for the algorithm, the distance with the lower bound and the number of non-dominated solutions in the Pareto frontier, but not diversity. So when the production planner is looking for quick solutions to his scheduling problem, he may prefer CH2 over CH1 unless the diversity of solutions does not have priority over other performance metrics.
Table 3 Paired comparison of the performance of CH1 and CH2
shows the performance of algorithms with respect to DLB. CPLEX is outperformed by even the random search, where the difference between CPLEX and algorithms that employ a GA (H-MOGA1, H-MOGA2, R-MOGA) are about 10%. There is no difference between CH1 and CH2 in terms of the DLB and both are outperformed by all algorithms that employ a GA. Both CH1 and CH2 perform better than CPLEX and RS. There is no statistically significant difference between the performance of H-MOGA1 and H-MOGA2 in terms of the DLB. As expected, H-MOGA1 and H-MOGA2 perform better than R-MOGA and RS.
Table 4 Comparison of algorithms with respect to DLB
In , it is clear that CH1 outperforms all the rest of the algorithms with respect to diversity. Following CH1, hybrid MOGAs are second best performers. Between the two hybrid MOGAs, H-MOGA1 performs better than H-MOGA2. Interestingly, RS performs better than R-MOGA. One possible explanation for this result is the fact that quality of the solution is not a criteria for assessing diversity performance and random search has an inherent ability to explore a wider search space, and therefore finds more unique sequences than R-MOGA. Finally, the worst performers in terms of diversity are CPLEX and CH2. Although CPLEX found more solutions than CH2, the difference in the number of unique solutions is not statistically significant.
Table 5 Comparison of algorithms with respect to DVR
shows the mean differences between algorithms with respect to the number of solutions they found in the Pareto frontier. CH2 produced the largest number of solutions on the Pareto frontier. As can be seen in CPLEX is outperformed by all algorithms where a constructive heuristic is used. There is no statistically significant difference between CPLEX and the MOGA starting with random search (R-MOGA) and the random search (RS). CH2 and H-MOGA2 outperform CH1 in terms of the number of solutions on the Pareto frontier; however, as it is highlighted in the previous section on diversity, all these solutions represent only a single unique sequence. CH1 performs better than its counterpart with GA (H-MOGA1) and random solutions (R-MOGA and RS).
Table 6 Comparison of algorithms with respect to CRD
5.3.1. An illustrative example
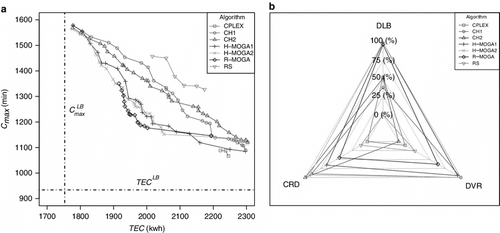
We show here, on a single problem instance with 20 jobs and set-up to processing time ratio=25%, how the Pareto frontier and the performance of the algorithms compare with each other. In we display the Pareto frontier of each algorithm and the lower bounds for Cmax and TEC. A few interesting observations can be made: Random search (RS) has a frontier that is inferior compared with all other frontiers except that of CPLEX. There are solutions found by RS with TEC lower than that of CPLEX. Another observation is that the frontier found CH1 for this problem instance is inferior to the frontier by H-MOGA1. A similar comment can be made for CH2 and H-MOGA2 pair. This in fact shows the level of improvement achieved by hybrid MOGAs since H-MOGA1 and H-MOGA2 start from the solutions found by CH1 and CH2, respectively. Hybrid MOGAs cannot be considered superior to R-MOGA; however, the frontier found by R-MOGA is much more compact than the frontiers found by hybrid MOGAs. R-MOGA has performed better than other search techniques in the middle section of the frontier but performed worse than some of the other methods in other areas. shows normalized performance matrix of these algorithms in a radar chart. We normalized the performance metrics DLB, CRD, and DVR given this problem so that the best performer has a score 100% and the worst performer has a score 0%. Considering the three performance measures, we cannot say there is an algorithm that is absolutely inferior. It is clear that none of the algorithms outperform the others in all three dimensions. H-MOGA1 and H-MOGA2 have the best performance in terms of DLB. CH2 has the best performance in terms of CRD. When it comes to DVR, CH1 and H-MOGA2 have the best performance. On the other hand, RS is inferior to CPLEX when it comes to DLB; however, it has more solutions than CPLEX and its diversity considering the unique sequences of solutions is higher than that of CPLEX. Apart from CH2 and CPLEX, the RS is inferior to the rest of the algorithms when considering all three performance measures.
Figure 4 Comparison of algorithms on an illustrative problem instance. (a) Pareto frontiers; (b) Performance metrics.
6. Discussion and conclusion
Manufacturers are under pressure to incorporate greener practices in their operations. In this paper we addressed a complex two-machine sequence-dependent permutation flowshop scheduling problem to minimize energy consumption and makespan. Our research contributes to the literature on green scheduling by developing a new heuristic and GAs for finding the Pareto optimal frontiers. We compared performance of the heuristics and GAs against each other and also with truncated CPLEX (ie, time constrained) and random search. More specifically, we developed a new O(n2) heuristic (named CH2) and compared its performance against an existing O(n3) heuristic (called CH1). Our experiments show that CH2 takes much less time than CH1 to run, which depends on the problem size. On average, CH2 takes one-third of the time it takes CH1 to solve a problem. In terms of the distance of the resultant Pareto frontiers with the lower bounds, although statistically significant, the difference between the two heuristics is marginal. With regard to diversity, CH1 is able to produce much more diverse set of sequences, while CH2 produces only one sequence. This is indeed the main reason for faster implementation of CH2. While CH2 produces more solutions on the Pareto frontier, CH1 produces many more unique sequences, which provides higher flexibility to production planners.
Our results show that hybrid GAs perform better than regular GAs. In terms of diversity, CH1 showed the best performance in producing unique sequences, followed by H-MOGA1. In this respect, the poorest performance is shown by CH2. This, however, is mainly because of the way that CH2 was designed based on time efficiency rather than solution quality or diversity. In terms of cardinality, CH2 produces the largest number of solutions. It should be noted that these solutions are produced for one sequence with different speed vectors.
On ths basis of the results, it could be concluded that if time is not an important criterion, CH1 is the preferred solution method for small- and medium-sized problems. For large-sized problems, hybrid GAs are recommended. However, in situations where diversity of Pareto frontier is more important, H-MOGA1 is preferred. If cardinality is more important regardless of the number of unique sequences, then CH2 is preferable. Finally, if the distance with the lower bound and diversity are more important, then H-MOGA2 is preferable, followed by H-MOGA1 and CH1.
The current research could be extended in a number of directions. New mathematical models for green scheduling of manufacturing operation need to be developed. This includes new models for general m-machine flowshop, job-shop, and open-shop problems including other energy- and power-related objectives alongside performance-oriented metrics. As an example, minimizing maximum power and makespan in general job-shop environment has interesting applications for manufacturing companies to reduce their need to peak power while maintaining their service level. Majority of research in this field have been conducted at machine level, focusing on optimizing energy consumption considering various machining parameters. Future research could look into integrating this line of research with factory-level optimization of energy consumption. By optimizing individual components of a system, one does not necessarily optimize the entire system. Such an integration would allow for wider energy savings at system level.
References
- AhilanCKumananSSivakumaranNDhasJERModeling and prediction of machining quality in CNC turning process using intelligent hybrid decision making toolsApplied Soft Computing20131331543155110.1016/j.asoc.2012.03.071
- AllahverdiANgCChengTKovalyovMYA survey of scheduling problems with setup times or costsEuropean Journal of Operational Research20081873985103210.1016/j.ejor.2006.06.060
- BelaidRTkindtVEssweinCScheduling batches in flowshop with limited buffers in the shampoo industryEuropean Journal of Operational Research2012223256057210.1016/j.ejor.2012.06.035
- Brooks R (2012). High-performance cutting of hard aero-alloys, http://americanmachinist.com/machining-cutting/high-performance-cutting-hard-aero-alloys, accessed 20 November 2014.
- CoelloCACVan VeldhuizenDALamontGBEvolutionary Algorithms for Solving Multi-Objective Problems2002
- ColletteYSiarryPMultiobjective Optimization: Principles and Case Studies2004
- CostaLEspirito SantoIAFernandesEMA hybrid genetic pattern search augmented Lagrangian method for constrained global optimizationApplied Mathematics and Computation2012218189415942610.1016/j.amc.2012.03.025
- DebKSinhaASolving bilevel multi-objective optimization problems using evolutionary algorithmsEvolutionary Multi-Criterion Optimization2009110124
- DiazNRedelsheimerEDornfeldDEnergy consumption characterization and reduction strategies for milling machine tool useGlocalized Solutions for Sustainability in Manufacturing2011263267
- DuflouJRTowards energy and resource efficient manufacturing: A processes and systems approachCIRP Annals-Manufacturing Technology201261258760910.1016/j.cirp.2012.05.002
- EPA (2013). Greenhouse gas equivalencies calculator, http://www.epa.gov/cleanenergy/energy-resources/calculator.html, accessed 8 November 2013.
- FangKUhanNZhaoFSutherlandJWA new approach to scheduling in manufacturing for power consumption and carbon footprint reductionJournal of Manufacturing Systems201130423424010.1016/j.jmsy.2011.08.004
- FangK-TLinBMParallel-machine scheduling to minimize tardiness penalty and power costComputers & Industrial Engineering201364122423410.1016/j.cie.2012.10.002
- GharbiALadhariTMsakniMKSerairiMThe two-machine flowshop scheduling problem with sequence-independent setup times: New lower bounding strategiesEuropean Journal of Operational Research20132311697810.1016/j.ejor.2013.05.031
- GoldbergDEGenetic Algorithms2006
- GongXZhouSXOptimal production planning with emissions tradingOperations Research201361490892410.1287/opre.2013.1189
- GrahamRLLawlerELLenstraJKKanAOptimization and approximation in deterministic sequencing and scheduling: A surveyAnnals of Discrete Mathematics1979528732610.1016/S0167-5060(08)70356-X
- GuptaJNDarrowWPThe two-machine sequence dependent flowshop scheduling problemEuropean Journal of Operational Research198624343944610.1016/0377-2217(86)90037-8
- HeYLiuFCaoH-jLiC-bA bi-objective model for job-shop scheduling problem to minimize both energy consumption and makespanJournal of Central South University of Technology200512216717110.1007/s11771-005-0033-x
- Heidenhain (2011). Aspects of energy efficiency in machine tools, http://www.heidenhain.us/enews/stories_1011/MTmain.php, accessed 20 November 2014.
- HyunCJKimYKimYKA genetic algorithm for multiple objective sequencing problems in mixed model assembly linesComputers & Operations Research199825767569010.1016/S0305-0548(98)00026-4
- IbrahimovMMohaisASchellenbergSMichalewiczZScheduling in iron ore open-pit miningThe International Journal of Advanced Manufacturing Technology2014725–81021103710.1007/s00170-014-5619-8
- JogPSuhJYVan GuchtDParallel genetic algorithms applied to the traveling salesman problemSIAM Journal on Optimization19911451552910.1137/0801031
- LiuG-SZhangB-XYangH-DChenXHuangGQA branch-and-bound algorithm for minimizing the energy consumption in the PFS problemMathematical Problems in Engineering2013201316
- LuDLogendranRBi-criteria group scheduling with sequence-dependent setup time in a flow shopJournal of the Operational Research Society201264453054610.1057/jors.2012.61
- LuoHDuBHuangGQChenHLiXHybrid flow shop scheduling considering machine electricity consumption costInternational Journal of Production Economics2013146242343910.1016/j.ijpe.2013.01.028
- MansouriSAAktasEBesikciUGreen scheduling of a two-machine flowshop: Trade-off between makespan and energy consumptionEuropean Journal of Operational Research2016248377278810.1016/j.ejor.2015.08.064
- MichalewiczZGenetic Algorithms+Data Structures=Evolution Programs1996
- MouzonGYildirimMBA framework to minimise total energy consumption and total tardiness on a single machineInternational Journal of Sustainable Engineering20081210511610.1080/19397030802257236
- MouzonGYildirimMBTwomeyJOperational methods for minimization of energy consumption of manufacturing equipmentInternational Journal of Production Research20074518–194247427110.1080/00207540701450013
- NaderiBZandiehMRoshanaeiVScheduling hybrid flowshops with sequence dependent setup times to minimize makespan and maximum tardinessThe International Journal of Advanced Manufacturing Technology20094111–121186119810.1007/s00170-008-1569-3
- NawazMEnscoreEEJrHamIA heuristic algorithm for the m-machine, n-job flow-shop sequencing problemOmega1983111919510.1016/0305-0483(83)90088-9
- OECD-IEA (2007). Tracking industrial energy efficiency and CO2 emissions. Technical Report International Energy Agency.
- RahimifardSSeowYChildsTMinimising embodied product energy to support energy efficient manufacturingCIRP Annals—Manufacturing Technology2010591252810.1016/j.cirp.2010.03.048
- RuizRMarotoCAlcarazJSolving the flowshop scheduling problem with sequence dependent setup times using advanced metaheuristicsEuropean Journal of Operational Research20051651345410.1016/j.ejor.2004.01.022
- RuizRStützleTAn iterated greedy heuristic for the sequence dependent setup times flowshop problem with makespan and weighted tardiness objectivesEuropean Journal of Operational Research200818731143115910.1016/j.ejor.2006.07.029
- SabouniMYLogendranRCarryover sequence-dependent group scheduling with the integration of internal and external setup timesEuropean Journal of Operational Research2013224182210.1016/j.ejor.2012.07.013
- SrinivasNDebKMuiltiobjective optimization using nondominated sorting in genetic algorithmsEvolutionary Computation19942322124810.1162/evco.1994.2.3.221
- TaillardESome efficient heuristic methods for the flow shop sequencing problemEuropean Journal of Operational Research1990471657410.1016/0377-2217(90)90090-X
- TiwariAChangP-CTiwariMKollanoorNJA Pareto block-based estimation and distribution algorithm for multi-objective permutation flow shop scheduling problemInternational Journal of Production Research201553379383410.1080/00207543.2014.933273
- T'kindtVBillautJ-CMulticriteria Scheduling. Theory, Models and Algorithms2006
- UrukZGultekinHAkturkMSTwo-machine flowshop scheduling with flexible operations and controllable processing timesComputers & Operations Research201340263965310.1016/j.cor.2012.09.001
- YeniseyMMYagmahanBMulti-objective permutation flow shop scheduling problem: Literature review, classification and current trendsOmega20144511913510.1016/j.omega.2013.07.004
- YoshidaTHitomiKOptimal two-stage production scheduling with setup times separatedAIIE Transactions197911326126310.1080/05695557908974469