
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
This article outlines a Bayesian methodology to estimate and test the Kendall rank correlation coefficient τ. The nonparametric nature of rank data implies the absence of a generative model and the lack of an explicit likelihood function. These challenges can be overcome by modeling test statistics rather than data. We also introduce a method for obtaining a default prior distribution. The combined result is an inferential methodology that yields a posterior distribution for Kendall’s τ.
1. Introduction
One of the most widely used nonparametric tests of dependence between two variables is the rank correlation known as Kendall’s τ (Kendall Citation1938). Compared to Pearson’s ρ, Kendall’s τ is robust to outliers and violations of normality (Kendall and Gibbons Citation1990). Moreover, Kendall’s τ expresses dependence in terms of monotonicity instead of linearity and is therefore invariant under rank-preserving transformations of the measurement scale (Kruskal Citation1958; Wasserman Citation2006). As expressed by Harold Jeffreys (Citation1961, p. 231): “[...] it seems to me that the chief merit of the method of ranks is that it eliminates departure from linearity, and with it a large part of the uncertainty arising from the fact that we do not know any form of the law connecting X and Y.” Here, we apply the Bayesian inferential paradigm to Kendall’s τ. Specifically, we define a default prior distribution on Kendall’s τ, obtain the associated posterior distribution, and use the Savage–Dickey density ratio to obtain a Bayes factor hypothesis test (Jeffreys Citation1961; Dickey and Lientz Citation1970; Kass and Raftery Citation1995).
1.1. Kendall’s τ
Let X = (x1, …, xn) and Y = (y1, …, yn) be two data vectors each containing measurements of the same n units. For example, consider the association between French and math grades in a class of n = 3 children: Tina, Bob, and Jim; let X = (8, 7, 5) be their grades for a French exam and Y = (9, 6, 7) be their grades for a math exam. For 1 ⩽ i < j ⩽ n, each pair (i, j) is defined to be a pair of differences (xi − xj) and (yi − yj). A pair is considered to be concordant if (xi − xj) and (yi − yj) share the same sign, and discordant when they do not. In our data example, Tina has higher grades on both exams than Bob, which means that Tina and Bob are a concordant pair. Conversely, Bob has a higher score for French, but a lower score for math than Jim, which means Bob and Jim are a discordant pair. The observed value of Kendall’s τ, denoted τobs, is defined as the difference between the number of concordant and discordant pairs, expressed as proportion of the total number of pairs
(1)
(1) where the denominator is the total number of pairs and Q is the concordance indicator function
(2)
(2)
illustrates the calculation for our small data example. Applying Equation (Equation1(1)
(1) ) gives τobs = 1/3, an indication of a positive correlation between French and math grades.
Table 1. The pairs (i, j) for 1 ⩽ i < j ⩽ n and the concordance indicator function Q for the data example where X = (8, 7, 5) and Y = (9, 6, 7).
When τobs = 1, all pairs of observations are concordant, and when τobs = −1, all pairs are discordant. Kruskal (Citation1958) provided the following interpretation of Kendall’s τ: in the case of n = 2, suppose we bet that y1 < y2 whenever x1 < x2, and that y1 > y2 whenever x1 > x2; winning $1 after a correct prediction and losing $1 after an incorrect prediction, the expected outcome of the bet equals τ. Furthermore, Griffin (Citation1958) had illustrated that when the ordered rank-converted values of X are placed above the rank-converted values of Y and lines are drawn between the same numbers, Kendall’s τobs is given by the formula: , where Z is the number of line intersections; see for an illustration of this method using our example data of French and math grades. These tools make for a straightforward and intuitive calculation and interpretation of Kendall’s τ.
Figure 1. A visual interpretation of Kendall’s τobs through the formula: , where z is the number of intersections of the lines. In this case, n = 3, z = 1, and τobs = 1/3.
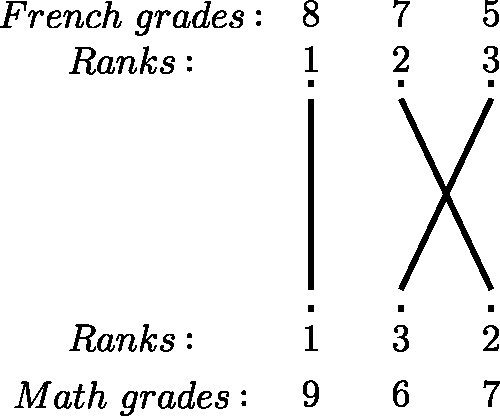
Despite these appealing properties and the overall popularity of Kendall’s τ, a default Bayesian inferential paradigm is still lacking because the application of Bayesian inference to nonparametric data analysis is not trivial. The main challenge in obtaining posterior distributions and Bayes factors for nonparametric tests is that there is no generative model and no explicit likelihood function. In addition, Bayesian model specification requires the specification of a prior distribution, and this is especially important for Bayes factor hypothesis testing; however, for nonparametric tests it can be challenging to define a sensible default prior. Though recent developments have been made in two-sample nonparametric Bayesian hypothesis testing with Dirichlet process priors (Borgwardt and Ghahramani Citation2009; Labadi, Masuadi, and Zarepour Citation2014) and Pòlya tree priors (Chen and Hanson Citation2014; Holmes et al. Citation2015), this article will outline a different approach, one that permits an intuitive and direct interpretation.
1.2. Modeling Test Statistics
To compute Bayes factors for Kendall’s τ, we start with the approach pioneered by Johnson (Citation2005) and Yuan and Johnson (Citation2008). These authors established bounds for Bayes factors based on the sampling distribution of the standardized value of τ, denoted by T*, which will be formally defined in Section 2.1. Using the Pitman translation alternative, where a noncentrality parameter is used to distinguish between the null and alternative hypotheses (Randles and Wolfe Citation1979), Johnson and colleagues specified the following hypotheses
(3)
(3)
(4)
(4) where θ is the true underlying value of Kendall’s τ, θ0 is the value of Kendall’s τ under the null hypothesis, and Δ serves as the noncentrality parameter that can be assigned a prior distribution. The limiting distribution of T* under both hypotheses is normal (Hotelling and Pabs Citation1936; Noether Citation1955; Chernoff and Savage Citation1958), with likelihoods
The prior on Δ is specified by Yuan and Johnson as
where κ is used to specify the expectation about the size of the departure from the null-value of Δ. This leads to the following Bayes factor
(5)
(5)
Next, Yuan and Johnson calculated an upper bound on (i.e., a lower bound on
) by maximizing over the parameter κ.
1.3. Challenges
Although innovative and compelling, the approach advocated by Yuan and Johnson (Citation2008) does have a number of non-Bayesian elements, most notably the data-dependent maximization over the parameter κ that results in a data-dependent prior distribution. Moreover, the definition of depends on n: as n → ∞,
and
become indistinguishable and lead to an inconsistent inferential framework.
Our approach, motivated by the earlier work by Johnson and colleagues, sought to eliminate κ not by maximization but by a method we call “parametric yoking” (i.e., matching with a prior distribution for a parametric alternative). In addition, we redefined such that its definition does not depend on sample size. As such, Δ becomes synonymous with the true underlying value of Kendall’s τ when θ0 = 0.
2. Methods
2.1. Defining T*
As mentioned earlier, Yuan and Johnson (Citation2008) used the standardized version of τobs, denoted T* (Kendall Citation1938), which is defined as follows
(6)
(6)
Here the numerator contains the concordance indicator function Q. Thus, T* is not necessarily situated between the traditional bounds [−1,1] for a correlation; instead, T* has a maximum of and a minimum of
. This definition of T* enables the asymptotic normal approximation to the sampling distribution of the test statistic (Kendall and Gibbons Citation1990).
2.2. Prior Distribution through Parametric Yoking
To derive a Bayes factor for τ, we first determine a default prior for τ through what we term parametric yoking. In this procedure, a default prior distribution is constructed by comparison to a parametric alternative. In this case, a convenient parametric alternative is given by Pearson’s correlation for bivariate normal data. Ly, Verhagen, and Wagenmakers (Citation2016) used a symmetric beta prior distribution (α = β) on the domain [−1,1], that is,
(7)
(7) where
is the beta function. For bivariate normal data, Kendall’s τ is related to Pearson’s ρ by Greiner’s relation (Greiner Citation1909; Kruskal Citation1958)
(8)
(8)
We can use this relationship to transform the beta prior in (Equation7(7)
(7) ) on ρ to a prior on τ given by
(9)
(9) In the absence of strong prior beliefs, Jeffreys (Citation1961) proposed a uniform distribution on ρ, that is, a stretched beta with α = β = 1. This induces a nonuniform distribution on τ, that is,
(10)
(10) Values of α ≠ 1 can be specified to induce different prior distributions on τ. In general, values of α > 1 increase the prior mass near τ = 0, whereas values of α < 1 decrease the prior mass near τ = 0. When the focus is on parameter estimation instead of hypothesis testing, we may follow Jeffreys (Citation1961) and use a stretched beta prior on ρ with
. As is easily confirmed by entering these values in (Equation9
(9)
(9) ), this choice induces a uniform prior distribution for Kendall’s τ. (Additional examples and figures of the stretched beta prior, including cases where α ≠ β, are available online at https://osf.io/b9qhj/.) The parametric yoking framework can be extended to other prior distributions that exist for Pearson’s ρ (e.g., the inverse Wishart distribution; Gelman et al. Citation2003; Berger and Sun Citation2008), by transforming ρ with the inverse of the expression given in (Equation8
(8)
(8) ):
2.3. Posterior Distribution and Bayes Factor
Removing from the specification of
by substituting
for Δ, the likelihood function under
equals a normal density with mean
and standard deviation σ = 1:
(11)
(11) Combining this normal likelihood function with the prior from (Equation9
(9)
(9) ) yields the posterior distribution for Kendall’s τ. Next, Bayes factors can be computed as the ratio of the prior and posterior ordinate at the point under test (i.e., the Savage-Dickey density ratio, Dickey and Lientz Citation1970; Wagenmakers et al. Citation2010). In the case of testing independence, the point under test is τ = 0, leading to the following ratio:
, which is analogous to
(12)
(12) and in the case of Kendall’s τ translates to
(13)
(13)
2.4. Verifying the Asymptotic Normality of T*
Our method relies on the asymptotic normality of T*, a property established mathematically by Hoeffding (Citation1948). For practical purposes, however, it is insightful to assess the extent to which this distributional assumption is appropriate for realistic sample sizes. By considering all possible permutations of the data, deriving the exact cumulative density of T*, and comparing the densities to those of a standard normal distribution, Ferguson, Genest, and Hallin (Citation2000) concluded that the normal approximation holds under when n ⩾ 10. But what if
is false?
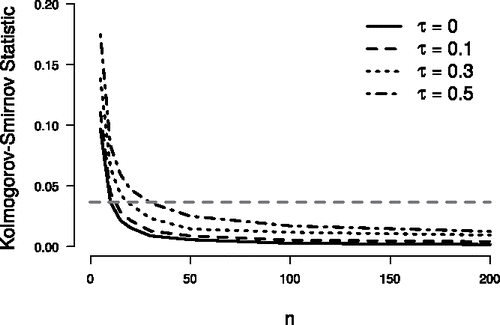
Here, we report a simulation study designed to assess the quality of the normal approximation to the sampling distribution of T* when is true. With the use of copulas, 100,000 synthetic datasets were created for each of several combinations of Kendall’s τ and sample size n. (For more information on copulas see Nelsen (Citation2006), Genest and Favre (Citation2007), and Colonius (Citation2016).) For each simulated dataset, the Kolmogorov–Smirnov statistic was used to quantify the fit of the normal approximation to the sampling distribution of T*. (R code, plots, and further details are available online at https://osf.io/b9qhj/.) shows the Kolmogorov–Smirnov statistic as a function of n, for various values of τ when datasets were generated from a bivariate normal distribution (i.e., the normal copula). Similar results were obtained using Frank, Clayton, and Gumbel copulas. As is the case under
(e.g., Kendall and Gibbons Citation1990; Ferguson, Genest, and Hallin Citation2000), the quality of the normal approximation increases exponentially with n. Furthermore, larger values of τ necessitate larger values of n to achieve the same quality of approximation.
Figure 2. Quality of the normal approximation to the sampling distribution of T*, as assessed by the Kolmogorov–Smirnov statistic. As n grows, the quality of the normal approximation increases exponentially. Larger values of τ necessitate larger values of n to achieve the same quality of approximation. The gray horizontal line corresponds to a Kolmogorov–Smirnov statistic of 0.038 (obtained when τ = 0 and n = 10), for which Ferguson, Genest, and Hallin (Citation2000, p. 589) deemed the quality of the normal approximation to be “sufficiently precise for practical purposes.”
The means of the normal distributions fit to the sampling distribution of T* are situated at the point . The datasets from this simulation can also be used to examine the variance of the normal approximation. Under
(i.e., τ = 0), the variance of these normal distributions equals 1. As the population correlation grows (i.e., |τ| → 1), the number of permissible rank permutations decreases and so does the variance of T*. The upper bound of the sampling variance of T* is a function of the population value for τ (Kendall and Gibbons Citation1990):
(14)
(14) As shown in the online appendix, our simulation results provide specific values for the variance, which respect this upper bound. This result has ramifications for the Bayes factor. As the test statistic moves away from 0, the variance falls below 1, and the posterior distribution will be more peaked on the value of the test statistic than when the variance is assumed to equal 1. This results in increased evidence in favor of
, so that our proposed procedure is somewhat conservative. However, for n ⩾ 20, the changes in variance will only surface in cases where there already exists substantial evidence for
(i.e.,
).
3. Results
3.1. Bayes Factor Behavior
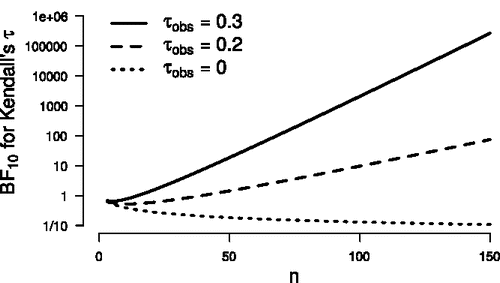
Now that we have determined a default prior for τ and combined it with the specified Gaussian likelihood function, computation of the posterior distribution and the Bayes factor becomes feasible. For an uninformative prior on τ (i.e., α = β = 1), illustrates as a function of n, for three values of τobs. The lines for τobs = 0.2 and τobs = 0.3 show that
for a true
increases exponentially with n, as is generally the case. For τobs = 0, the Bayes factor decreases as n increases.
Figure 3. Relation between and sample size (3 ⩽ n ⩽ 150) for three values of Kendall’s τ.
3.2. Comparison to Pearson’s ρ
To put the result in perspective, the Bayes factors for Kendall’s tau (i.e., ) can be compared to those for Pearson’s ρ (i.e.,
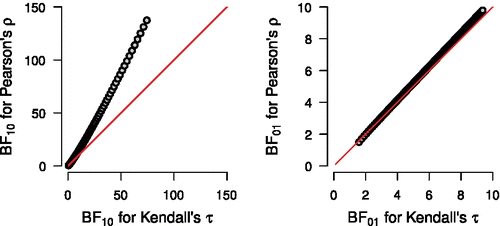
). The Bayes factors for Pearson’s ρ are based on Jeffreys (Citation1961, see also Ly, Verhagen, and Wagenmakers Citation2016), who used the uniform prior on ρ. shows that the relationship between
and
for normal data is approximately linear as a function of sample size. In addition, and as one would expect due to the loss of information when continuous values are converted to coarser ranks,
in the case of evidence in favor of
(left panel of ). When evidence is in favor of
, that is, τ = 0,
perform similarly (right panel of ).
Figure 4. Relation between the Bayes factors for Pearsons ρ and Kendall’s τ = 0.2 (left) and Kendall’s τ = 0 (right) as a function of sample size (i.e., 3 ⩽ n ⩽ 150). The data are normally distributed. Note that the left panel shows and the right panel shows
. The diagonal line indicates equivalence.
3.3. Real Data Example
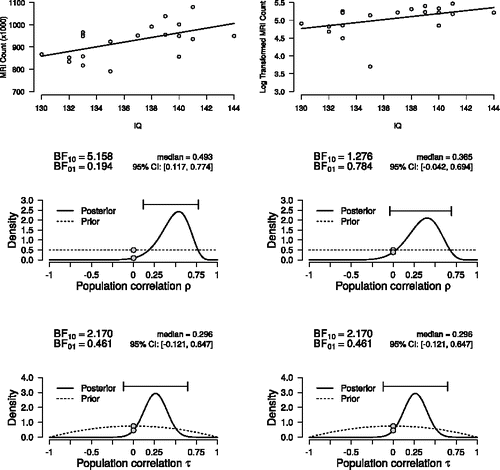
Willerman et al. (Citation1991) set out to uncover the relation between brain size and IQ. Across 20 participants, the authors observed a Pearson’s correlation coefficient of r = 0.51 between IQ and brain size, measured in MRI count of gray matter pixels. The data are presented in the top left panel of . Bayes factor hypothesis testing of Pearson’s ρ yields , which is illustrated in the middle left panel. This means the data are 5.16 times as likely to occur under
than under
. When applying a log-transformation on the MRI counts (after subtracting the minimum value minus 1), however, the linear relation between IQ and brain size is less strong. The top right panel of presents the effect of this monotonic transformation on the data. The middle right panel illustrates how the transformation decreases
to 1.28. The bottom left panel presents our Bayesian analysis on Kendall’s τ, which yields a
of 2.17. Furthermore, the bottom right panel shows the same analysis on the transformed data, illustrating the invariance of Kendall’s τ against monotonic transformations: the inference remains unchanged, which highlights one of Kendall’s τ most appealing features.
Figure 5. Bayesian inference for Kendall’s τ illustrated with data on IQ and brain size (Willerman et al. Citation1991). The left column presents the relation between brain size and IQ, analyzed using Pearson’s ρ (middle panel) and Kendall’s τ (bottom panel). The right column presents the results after a log transformation of brain size. Note that the transformation affects inference for Pearson’s ρ, but does not affect inference for Kendall’s τ.
4. Concluding Comments
This manuscript outlined a nonparametric Bayesian framework for inference about Kendall’s tau. The framework is based on modeling test statistics and assigning a prior by means of a parametric yoking procedure. The framework produces a posterior distribution for Kendall’s tau, and—via the Savage-Dickey density ratio test—also yields a Bayes factor that quantifies the evidence for the absence of a correlation.
Our general procedure (i.e., modeling test statistics and assigning a prior through parametric yoking) is relatively general and may be used to facilitate Bayesian inference for other nonparametric tests as well. For instance, Serfling (Citation1980) offered a range of test statistics with asymptotic normality to which our framework may be expanded, whereas Johnson (Citation2005) had explored the modeling of test statistics that have non-Gaussian limiting distributions.
Supplementary Materials
An online appendix, with more information on the different prior options, as well as the simulation study to assess the normality of Kendall's τ, is available online at https://osf.io/b9qhj/. This repository also contains R-code for Bayesian inference on Kendall's τ, as well as for the simulation study.
Additional information
Funding
Related Research Data
References
- Berger, J. O., and Sun, D. (2008), “Objective Priors for the Bivariate Normal Model,” The Annals of Statistics, 36, 963–982.
- Borgwardt, K. M., and Ghahramani, Z. (2009), “Bayesian Two-Sample Tests,” arXiv preprint arXiv:0906.4032.
- Chen, Y., and Hanson, T. E. (2014), “Bayesian Nonparametric k-Sample Tests for Censored and Uncensored Data,” Computational Statistics & Data Analysis, 71, 335–346.
- Chernoff, H., and Savage, R. (1958), “Asymptotic Normality and Efficiency of Certain Nonparametric Test Statistics,” The Annals of Statistics, 29, 972–994.
- Colonius, H. (2016), “An Invitation to Coupling and Copulas: With Applications to Multisensory Modeling,” Journal ofMathematical Psychology, 74, 2–10.
- Dickey, J. M., and Lientz, B. P. (1970), “The Weighted Likelihood Ratio, Sharp Hypotheses about Chances, the Order of a Markov Chain,” The Annals of Mathematical Statistics, 41, 214–226.
- Ferguson, T. S., Genest, C., and Hallin, M. (2000), “Kendall’s Tau for Serial Dependence,” Canadian Journal of Statistics, 28, 587–604.
- Gelman, A., Carlin, J., Stern, H., Dunson, D., Vehtari, A., and Rubin, D. (2003), Bayesian Data Analysis (2nd ed.), London: Chapman & Hall/CRC.
- Genest, C., and Favre, A.-C. (2007), “Everything You Always Wanted to Know About Copula Modeling but Were Afraid to Ask,” Journal of Hydrologic Engineering, 12, 347–368.
- Greiner, R. (1909), “Über das Fehlersystem der Kollektivmasslehre,” Zeitschift für Mathematik undPhysik, 57, 121–158.
- Griffin, H. (1958), “Graphic Computation of Tau as a Coefficient of Disarray,” Journal of the American Statistical Association, 53, 441–447.
- Hoeffding, W. (1948), “A Class of Statistics with Asymptotically Normal Distribution,” Annals of Mathematical Statistics, 19, 293–325.
- Holmes, C. C., Caron, F., Griffin, J. E., and Stephens, D. A. (2015), “Two-Sample Bayesian Nonparametric Hypothesis Testing,” Bayesian Analysis, 10, 297–320.
- Hotelling, H., and Pabs, M. (1936), “Rank Correlation and Tests of Significance Involving no Assumption of Normality,” Annals of Mathematical Statistics, 7, 29–43.
- Jeffreys, H. (1961), Theory of Probability (3rd ed.), Oxford, UK: Oxford University Press.
- Johnson, V. E. (2005), “Bayes Factors Based on Test Statistics,” Journal of the Royal Statistical Society, Series B, 67, 689–701.
- Kass, R. E., and Raftery, A. E. (1995), “Bayes Factors,” Journal of the American Statistical Association, 90, 773–795.
- Kendall, M. (1938), “A new Measure of Rank Correlation,” Biometrika, 30, 81–93.
- Kendall, M., and Gibbons, J. D. (1990), Rank Correlation Methods, New York: Oxford University Press.
- Kruskal, W. (1958), “Ordinal Measures of Association,” Journal of the American Statistical Association, 53, 814–861.
- Labadi, L. A., Masuadi, E., and Zarepour, M. (2014), “Two-Sample Bayesian Nonparametric Goodness-of-Fit Test,” arXiv preprintarXiv:1411.3427.
- Ly, A., Verhagen, A. J., and Wagenmakers, E.-J. (2016), “Harold Jeffreys’s Default Bayes Factor Hypothesis Tests: Explanation, Extension, and Application in Psychology,” Journal of Mathematical Psychology, 72, 19–32.
- Nelsen, R. (2006), An Introduction to Copulas (2nd ed.), New York: Springer-Verlag.
- Noether, G. E. (1955), “On a Theorem of Pitman,” Annals of Mathematical Statistics, 26, 64–68.
- Randles, R. H., and Wolfe, D. A. (1979), Introduction to the Theory of Nonparametric Statistics (Springer Texts in Statistics), New York: Wiley.
- Serfling, R. J. (1980), Approximation Theorems of Mathematical Statistics, New York: Wiley.
- Wagenmakers, E.-J., Lodewyckx, T., Kuriyal, H., and Grasman, R. (2010), “Bayesian Hypothesis Testing for Psychologists: A Tutorial on the Savage–Dickey Method,” Cognitive Psychology, 60, 158–189.
- Wasserman, L. (2006), All of Nonparametric Statistics (Springer Texts in Statistics), New York: Springer Science and Business Media.
- Willerman, L., Schultz, R., Rutledge, J. N., and Bigler, E. D. (1991), “In Vivo Brain Size and Intelligence,” Intelligence, 15, 223–228.
- Yuan, Y., and Johnson, V. E. (2008), “Bayesian Hypothesis Tests using Nonparametric Statistics,” Statistica Sinica, 18, 1185–1200.