
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Fisher succeeded early on in redefining Student’s t-distribution in geometrical terms on a central hypersphere. Intriguingly, a noncentral analytical extension for this fundamental Fisher–Student’s central hypersphere h-distribution does not exist. We therefore set to derive the noncentral h-distribution and use it to graphically illustrate the limitations of the Neyman–Pearson null hypothesis significance testing framework and the strengths of the Bayesian statistical hypothesis analysis framework on the hypersphere polar axis, a compact nontrivial one-dimensional parameter space. Using a geometrically meaningful maximal entropy prior, we requalify the apparent failure of an important psychological science reproducibility project. We proceed to show that the Bayes factor appropriately models the two-sample t-test p-value density of a gene expression profile produced by the high-throughput genomic-scale microarray technology, and provides a simple expression for a local false discovery rate addressing the multiple hypothesis testing problem brought about by such a technology.
1. Introduction
The statistical analysis literature is replete with words of caution on the use and misuse of various statistical hypothesis testing methods, the contrasted discourse about a much used but heavily criticized Neyman–Pearson null hypothesis significance testing (NHST) framework and a powerful but yet to be fully embraced Bayesian hypothesis testing framework being particularly notorious. See, for example, Greenland et al. (Citation2016), Rothman (Citation2016), Wasserstein and Lazar (Citation2016), and references therein for an all encompassing scope. See also Goodman (Citation1999a, Citation1999b) for a more restricted point of view on medical statistics. Our contribution to this debate is meant to be modest and focused: we shall recast the classical two-sample t-test in an intuitive geometrical setting so as to allow the reader to assess the respective strengths and weaknesses of the NHST and Bayesian frameworks through informative graphical representations on a compact nontrivial one-dimensional parameter space. The practical examples chosen will be drawn from the biomedical research realm which is undergoing major conceptual shifts in data analysis, partly in response to the creation of genomic-scale high-throughput technologies, partly in response to a science reproducibility problem.
Many authors have commented on the elegance and simplicity of geometrical approaches to statistics. In their paper entitled ‘The geometry of estimation’, Durbin and Kendall (Citation1951) state:
“In the ultimate analysis geometrical ‘proofs’ in more than three dimensions are only restatements of analytical results in a special language; but they are nevertheless very useful, partly because of their elegance and partly because they carry a greater degree of conviction and understanding, to some minds at least, than the analytical approach. They also suggest generalizations (...).”
Sir Ronald Fisher was among those advocating early on a geometrical approach to statistics. Historical accounts narrate how he cleanly redefined Student’s t-distribution on a hypersphere (Gorroochurn Citation2016). It is therefore intriguing that one cannot find any trace in the literature of a noncentral analytical extension for the fundamental Fisher–Student’s central hypersphere distribution, as such an extension could ease illustration of the strengths of the Bayesian framework on the hypersphere polar axis, a compact nontrivial one-dimensional parametric space. Instead, one still has to rely on an unwieldy noncentral t-distribution which has obfuscated such an endeavour till now.
The geometrical framework herein advocated will allow us to: reexpress Student’s t-distribution as the Fisher–Student’s central hypersphere h-distribution, derive its analytical noncentral extension, and compare the analytical noncentral h-distribution to the unwieldy noncentral t-distribution in Section 2; graphically compare over compact domains the NHST and Bayesian hypothesis testing frameworks in Sections 3 and 4; explore graphically how the Bayesian framework interprets the apparent failure of an important psychological science reproducibility project, fares when analyzing a gene expression profile microarray dataset, and provides a simple expression for a local false discovery rate addressing the multiple hypothesis testing problem in Section 5.
In order not to distract the reader, our argumentation will mostly consist of statements without extensive proofs. The reader is referred to the Appendices for details.
2. Noncentral Hypersphere h-distribution
Consider an experiment consisting of measuring one continuous outcome in two different experimental conditions, n1 times for the first condition, n2 for the second condition. The result of such an experiment can be collated into an observation vector of length N = n1 + n2. The observation vector o can be projected on the overall center-of-mass C, the between-class variance hyperplane B, and the within-class variance hyperplane W using the matrix projectors PC, PB, and PW defined in Appendix A. In both projection and trigonometric terms, the two-sample t-statistic is defined as the signed squared root of the variance ratio
(1)
(1) For the two-sample case, the matrix projector PB has rank one and can be expanded as PB = TBTtB, where the relevant eigenvector
(2)
(2) allows computation to within a constant of the difference of means between the two experimental conditions. In the following, TB will be referred to as the unit polar axis of the hypersphere under consideration. When the random observation vector o distributes according to a maximal entropy equiprobability distribution on the unit radius hypersphere
—arguably one of the most important continuous distributions in probability theory—its projection cos θ = TtBo on the polar axis distributes according to the Fisher–Student’s central h-distribution
(3)
(3) (Fisher et al. Citation1925). This distribution will stand hereafter for the null hypothesis Ho. The central h-distribution is symmetrical upon reflection across the equatorial midline at cos θ = 0, and its width narrows as ν increases, an intrinsic geometrical property of high-dimensional hyperspheres which pack most of their surface on their equatorial bulge. The null index in the parameter set (ν, δ = 0) refers to the fact that, for a central distribution, the noncentrality parameter δ—to be formally introduced below—is zero. Poincaré’s lemma states that ρ(ν, 0)(θ) converges to the normal distribution as ν goes to infinity (Mazliak Citation2015). Computation of the cumulative distribution functions and, consequently, of p-values for the central hypersphere distribution (Equation3
(3)
(3) ) can be carried out analytically: see Appendix D.
Figure 1. Translated and noncentral hypersphere distribution. The silhouetted hypersphere is translated by a normalized effect size
— re-expressed in geometrical terms as
— along the horizontal polar axis. All experimental measurements are expressed in terms of the polar angle θ, which relates to the null hypothesis Ho hypersphere ρ(ν, δ = 0)(θ) centered on the origin. The angle Θ for its part relates to measurements which can be made in the intrinsic reference system centered on the round dashed translated hypersphere. As the angle Θ rotates from 0 to π, the translated symmetrical hypersphere is mapped vertically above the observation’s projection cos θo on the unsymmetrical noncentral h-distribution
of interest.
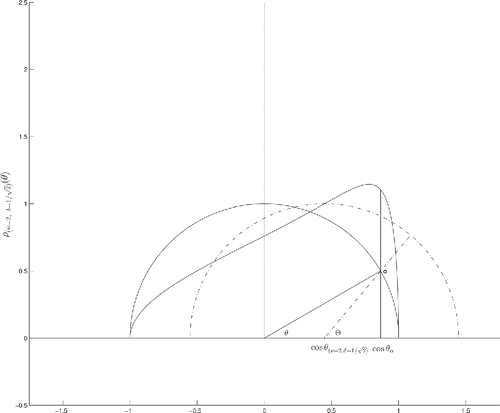
We now extend the Fisher–Student’s central h-distribution (Equation3(3)
(3) ) to that of a noncentral h-distribution with center-of-mass shifted away from the origin of the referential system by the value of the noncentrality parameter δ. In geometric terms, the t-like noncentrality parameter δ defines the angle
which imparts to the hypersphere the translation given by
(4)
(4) on the finite cosine range − 1 ⩽ cos θ ⩽ 1 along the polar axis TB defined in equation (Equation2
(2)
(2) ). As represented in , angular measurements are affected by the translation. In the referential system centered on the translated hypersphere, the cotangent of the polar angle is given by
reminiscent of the z-score (x − μ)/σ for a normal distribution with non-vanishing mean μ, from which one computes the transformation angle
(5)
(5) In the translated referential system, the central h-distribution provided by equation (Equation3
(3)
(3) ) holds, not unlike the shape of a normal distribution left unchanged by a simple translation as graphically represented in . In the original referential system, the noncentral h-distribution transforms according to the change of variable (Equation5
(5)
(5) ): one finds
(6)
(6) where the transformation’s Jacobian is given by
The various terms of the h-distribution (Equation6
(6)
(6) ) can be regrouped such that the noncentral h-distribution simply reads
(7)
(7) where the multiplicative function
—readily interpreted as the likelihood ratio between the noncentral ρh(ν, δ) and central ρ(ν, 0) h-distributions—is given by
(8)
(8) Since the hypersphere dimensional parameter ν is usually prespecified by the experimental setup, the noncentral h-distribution is essentially parameterized by the noncentrality parameter δ as reexpressed in geometrical terms in Equation (Equation4
(4)
(4) ). Compare with Gönen et al. (Citation2005) and Wang and Liu (Citation2016). When δ = 0, cos θ(ν, δ) = 0, and ρh(ν, δ = 0)(θ) simplifies to the Fisher–Student’s central h-distribution ρ(ν, 0)(θ), as expected. From its definition in Equation (Equation6
(6)
(6) ), integration of the noncentral h-distribution ρh(ν, δ)(θ) between any integration bounds is given by
that is, integration of the noncentral h-distribution between the integration bounds [θ1, θ2] simply boils down to integration of Student’s distribution (Equation3
(3)
(3) ) between the transformed integration bounds [Θ(ν, δ)(θ1), Θ(ν, δ)(θ2)] provided by Equation (Equation5
(5)
(5) ). All the relevant integrations have been carried out analytically and the results are provided in Appendix D. For the sake of completeness, we state without proof that the noncentral t-distribution function—formally derived through introduction of the ratio of a random variable distributing according to a normal distribution
over a random variable distributing according to a χν distribution—can similarly be rewritten
where the likelihood ratio
is given by
after expansion of the exponential and use of the gamma function definition. The likelihood ratio
thus involves a cumbersome sum over an infinite number of terms. When δ = 0,
and the noncentral t-distribution ρt(ν, δ)(θ) simplifies to on the Fisher–Student’s central h-distribution ρ(ν, 0)(θ), as expected.
To summarize, the noncentral h-distribution ρh(ν, δ)(θ) is obtained by translating the Fisher–Student’s central h-distribution (Equation3(3)
(3) ) along the polar axis TB, while the noncentral t-distribution ρt(ν, δ)(θ) is obtained as the marginal of the joint probability of a normal distribution
times a χ2ν distribution: the noncentral h-distribution is thus both conceptually and analytically simpler. Furthermore, while both noncentral h- and t-distributions simplify to the Fisher–Student’s central h-distribution when δ = 0, it can be graphically ascertained that, for a nonvanishing value of δ, ρh(ν, δ)(θ) and ρt(ν, δ)(θ) are almost superposable, as graphically demonstrated in . We are thus justified to use the closed analytical form (Equation7
(7)
(7) ) for noncentral h-distribution ρh(ν, δ)(θ)—with its analytical and readily factorized likelihood ratio (Equation8
(8)
(8) )—in order to exploit the Bayesian framework to its fullest in the following. Finally, a most instructive generalization to the noncentral F-distribution is to be found in Appendix C.
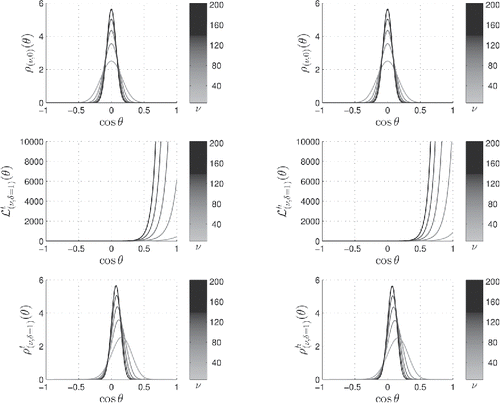
Figure 2. Noncentral t-distributions on the left and h-distributions on the right for a varying number of degrees of freedom—or, equivalently, hypersphere dimension—ν which can be deduced from the grayscale colorbars. The Fisher–Student’s central hypersphere distribution is given in duplicate in the upper panels. The likelihood ratios and
for δ = 1 are given in the middle left and right panels, respectively. The noncentral ρt(ν, δ)(θ) and ρh(ν, δ)(θ) distributions, products of the two functions above them, are given in the lower left and right panels, respectively. The resulting distributions are almost superposable.
3. Null Hypothesis Significance Testing Framework
We shall refer in the following to δ as the normalized effect size, and to Δ as the sampling distribution noncentrality parameter. The latter is determined in Appendix B in geometric terms. We shall abide with the convention of using the Greek letters δ or Δ to designate the distributions’ noncentrality parameters, and the roman letters d or D to designate their respective estimates (Cumming and Finch Citation2001).
The Neyman–Pearson NHST framework calls for rejection of the null hypothesis δ = 0 whenever the observed p-value established with respect to the central hypersphere distribution ρ(ν, 0)(θ) is less than or equal to a pre-chosen Type I error (false positive) level α. For the hypersphere distribution of interest, the NHST prescription requires specification of the statistical test specificity at Type I error (false positive) level α
in terms of the central h-distribution (Equation3
(3)
(3) ), equation which determines the one-tail statistical critical angle
reciprocally related to the sensitivity (power to detect the effect size) at type II error (false negative) level β
in terms of the noncentral h-distribution (Equation7
(7)
(7) ). graphically summarizes these concepts on the finite polar axis. In the frequentist framework, the t-statistic (Equation1
(1)
(1) ) provides a maximum likelihood estimate D for Δ. Similarly, the correlation-like projection cos θ = TtBo provides a maximum likelihood estimate for
(9)
(9) See Appendix B for various relationships between Δ, δ, ν and the two-sample sizes (n1, n2). In order to compute a confidence interval (CI) for the estimate cos θ(ν, D), one needs to be able to express θ in terms of Θ. Solving a quadratic equation, one finds
Using the latter, the two-tail confidence interval for cos θ(ν, D) is found to be given by
(10)
(10) which simplifies to the expected ± cos θα/2 when cos θ(ν, D) = 0. This confidence interval is verified to concur with the usual noncentral t-distribution effect size confidence interval definition (Cumming and Finch Citation2001). We have plotted in the upper panel of the frequentist two-tail confidence interval cos θ(ν, D) CI1 − α for the continuum of estimates cos θ(ν, D) at confidence level α = .05 and for various two-sample equal size n1 = n2 = n. Note that the null hypothesis Ho neatly stands on the vertical line at cos θ = 0. The lower panel in the same figure provides the corresponding statistical test sensitivity (power). It can be readily verified that lower bound of the confidence interval for cos θ(ν, D) is still negative when the latter reaches the critical angle cos θα/2. Thus, when applied to the central and noncentral h-distributions, the Neyman–Pearson prescription fails to produce a significant confidence interval at the critical p-value. In fact, Equation (Equation10
(10)
(10) ) indicates that such a significant confidence interval is achieved at a greater estimate
—or, equivalently, lesser
value—again as illustrated in . Now recall that, at confidence level α, the frequentist confidence interval
is defined such that, on repeated samplings, 1 − α such intervals are expected to contain the true population parameter cos θ(ν, Δ). For an experiment that barely crosses the significance threshold, the estimates on repeat samplings will fall on either side of the threshold, with
values and confidence intervals declared significant or not, accordingly. When subjected to such statistical fluctuations, statistical significance thus becomes a “fickle” notion (Nuzzo Citation2014; Colquhoun Citation2014; Burnham and Anderson Citation2014; Halsey et al. Citation2015; Wasserstein and Lazar Citation2016).
Figure 3. Null hypothesis significance testing. Type I error at level α and power 1 − β for type II error at level β are represented as intercepts of the cumulative distribution functions of the central and noncentral h-distributions with the critical line at cos θα, respectively. Abbreviations: (n)chpdf — (non)central hypersphere probability distribution function; (n)chcdf — (non)central hypersphere cumulative distribution function.
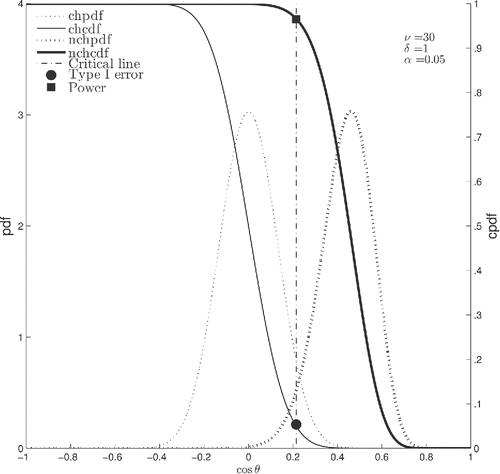
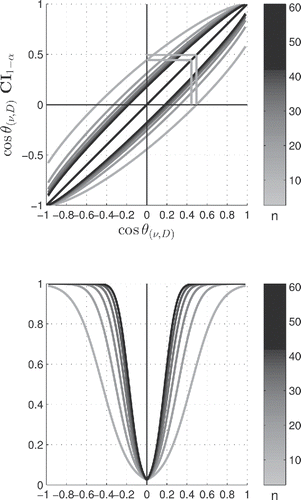
Figure 4. Two-tail frequentist confidence intervals at α = .05 for the continuum of two-sample, equal size n1 = n2 = n, cos θ(ν, D) estimates are plotted in the upper panel. The null hypothesis Ho neatly stands on the vertical line at cos θ(ν, D) = 0, from which one can draw critical values horizontally to the diagonal first and vertically to the horizontal polar axis thereafter. The frequentist CI lower bound is still negative when the estimate cos θ(ν, D) reaches the critical angle cos θα/2, as exemplified by the inner wedge. The Neyman–Pearson prescription thus fails to produce a significant confidence interval at the critical p-value when applied to the central and noncentral h-distributions. The CI lower bound crosses the zero threshold upward at a larger estimate —or, equivalently, lesser
value—as exemplified by the outer wedge. For an experiment that barely crosses the significance threshold, the estimates on repeat samplings will fall on either side of the threshold, with
values and confidence intervals declared significant or not, accordingly. When subjected to such statistical fluctuations, statistical significance thus becomes a “fickle” notion. Lower panel: corresponding power curves.
4. Bayesian Hypothesis Testing Framework
In this section, the Bayesian hypothesis testing framework will be applied to the noncentral h-distribution (Equation7(7)
(7) ) considered as a δ-parameterized continuum of hypotheses H1, with the noncentral parameter δ re-expressed in geometric terms in equation (Equation4
(4)
(4) ). The Fisher–Student’s central h-distribution (Equation3
(3)
(3) ) will considered as H0. In a Bayesian model selection framework, one is interested in the Bayes factor defined as the ratio of conditional probabilities
(11)
(11) where
is the data observed. Since the central distribution (Equation3
(3)
(3) ) is easily factored out of the analytical expression for the noncentral hypersphere distribution (Equation7
(7)
(7) ), the Bayes factor of interest can be (numerically) computed via the integral
(12)
(12) in terms of the likelihood ratio
defined in (Equation8
(8)
(8) ) and of a prior Prν(θ1) to be specified. The relevant posterior probability will then be given by
(13)
(13) It has been abundantly argued in the literature that the choice of prior can have a definitive influence on the Bayes factors and posterior probabilities. Instead of debating the relative merits of various kind of priors, we shall restrain our attention to the following two priors: (1) the proper geometry-naive uniform prior Prν(θ1) = 1 which should reproduce results stemming from the frequentist framework, and (2) the proper maximal entropy (maxent) prior Prν(θ1) = ρ(ν, 0)(θ1) specified by the Fisher–Student’s central h-distribution (Equation3
(3)
(3) ) itself (Jaynes Citation1968). The latter choice of maxent prior naturally arises in the present geometrical setting as it meaningfully apportions most of the weight of evidence for H1 on the equatorial band of a high-dimensional hypersphere where lies the bulk of its density. The latter observation is most pertinent for the biomedical research realm in which “empirical evidence suggests that most medical intervention effects are small or modest” (Pereira, Horwitz, and Ioannidis Citation2012). This maxent prior avoids Bartlett’s and the information paradoxes (Wang and Liu Citation2016). The equal-tail Bayesian credible interval
for the posteriors is given by the integration limits for the integrand (Equation13
(13)
(13) ) which leave out α/2 of the integrand on each tail. We have plotted in the upper panels of the posteriors Pν(cos θ1|cos θ) credible intervals for both priors. As expected, the credible interval for the geometry-naive uniform prior recapitulates the results of the frequentist framework: the credible interval straddles the diagonal without correction to the parameter estimate. More interesting is the effect of the maxent prior (Equation3
(3)
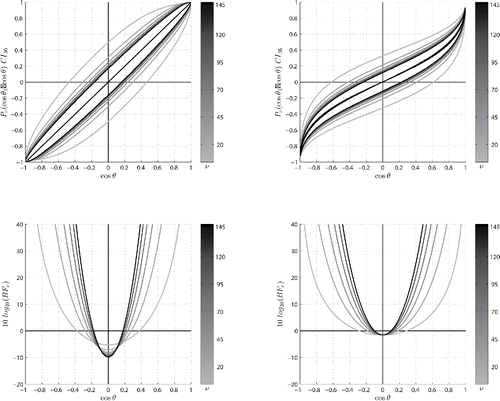
(3) ) which conservatively brings down the Bayesian credible interval below the diagonal. Although the Bayesian statistical hypothesis testing framework is not supposed to be discussed in terms of thresholds, it is interesting to note that the lower bounds of the Bayesian credible intervals in the positive upper quadrants of the upper panels cross the zero threshold upward when the Bayes factor reaches about two and six decibans in the left and right lower panels, at which level the Bayesian evidence is declared barely worth mentioning and substantial, respectively, according to Jeffreys (Citation1998). Finally, recall that the Bayesian credible interval CI1 − α for the parameter cos θ1 is defined such that, given the observed data, there is 1 − α chance that the true parameter lies in it.
Figure 5. Left panels: geometry-naive uniform prior. Right panels: central hypersphere maxent prior. Upper panels: Bayesian credible intervals CI0.95 for the posterior Pν(cos θ1|cos θ), together with their 0.5 quantiles. Lower panels: corresponding Bayes factors in decibans. The number of degrees of freedom or, equivalently, the hypersphere dimension ν can be deduced from the grayscale colorbars. The Bayesian credible intervals for the geometry-naive uniform prior recapitulate results of the frequentist framework. The central hypersphere maxent prior conservatively brings down the Bayesian credible intervals below the diagonal. Note that the lower bounds of the Bayesian credible intervals in the positive upper quadrants of the upper panels cross the zero threshold upward when the Bayes factor reaches about two and six decibans in the left and right lower panels, at which level the Bayesian evidence is declared barely worth mentioning and substantial, respectively.
5. Applications
When discussing Bayesian analyses in this section, it shall be understood that the analyses will pertain solely to the maxent prior Prν(θ1) = ρ(ν, 0)(θ1) specified by the Fisher–Student’s central h-distribution (Equation3(3)
(3) ).
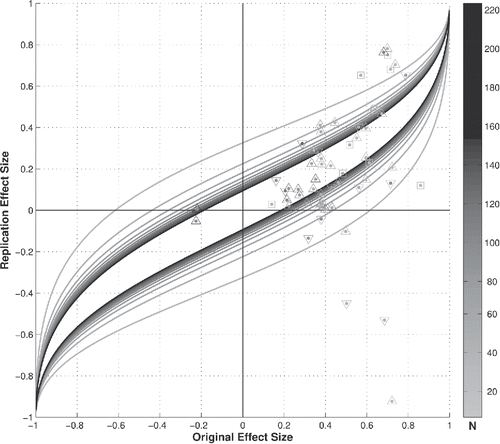
The Open Science Collaboration project (Collaboration et al. Citation2015) estimated the reproducibility of psychological science to be weak: only 36% of 100 replication attempts produced statistically significant results in terms of the Neyman–Pearson NHST framework p-values, and only 47% of the original effect sizes were within the frequentist CI0.95 confidence interval of the replication effect size. Etz and Vandekerckhove (Citation2016) argued that the failure of the Reproducibility Project could be attributed to overestimation of the original effect sizes and weak Bayesian evidence in the original studies. Considering the same 72 univariate test-based studies retained by Etz and Vandekerckhove (Citation2016), using the inferential t-statistics they provided in their Supporting Information, and further filtering down—for graphical purposes—to the 60 studies with sample size N less than 220, we have plotted in their original and replication empirical effect sizes against the posteriors’ Bayesian credible intervals. As the posteriors’ Bayesian credible intervals lay under the frequentist diagonal, a now very substantial 75% of the replication effect sizes fall within their respective original effect size posteriors’ credible intervals, indicating that the replication effort was not a failure from a Bayesian perspective. But since 60% of the original credible intervals’ lower bound are found to be negative, it has to be concluded that there was weak Bayesian evidence for the effect sizes in the original studies, in full accord with the conclusions of Etz and Vandekerckhove (Citation2016). shows thus a graphical illustration of the strength of the Bayesian framework: the central h-distribution maxent prior effects an appropriate weighing down of original overestimated effect sizes. In that respect, Ioannidis (Citation2008) has argued that “if priors assume that small effects are plausible but large effects are implausible, Bayes Factors become most promising for small effects,” which is indeed the case here.
Figure 6. The Open Science Collaboration Project original and replication effect sizes plotted against the posteriors’ Bayesian credible intervals. Since 75% of the replication effect sizes fall within their original posteriors’ credible intervals, the replication project cannot be called a failure from a Bayesian perspective. Nevertheless, 60% of the original credible intervals’ lower bounds are found to be negative, indicating weak Bayesian evidence for the original effects. The sample sizes can be deduced from the grayscale colorbar: the dot color refer to the initial sample size; an upward (downward) pointing triangle indicates that the replication sample size was bigger (smaller) than the original sample size, while a square indicates that the replication and original sample sizes were identical.
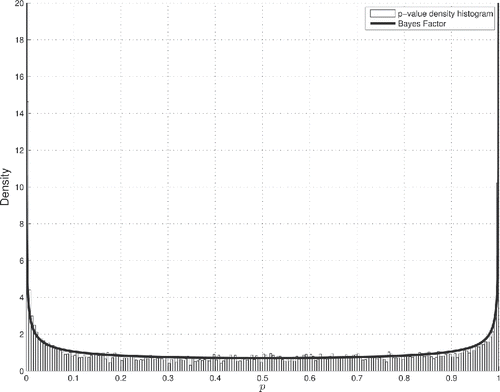
The microarray technology allows for interrogation of the cellular expression of thousands of genes (Schulze and Downward Citation2001). For illustrative purposes, we have: accessed the NCBI Gene Expression Omnibus head and neck squamous cell carcinoma dataset GSE6631 (Kuriakose et al. Citation2007b) produced by Kuriakose et al. (Citation2004a) and pertaining to 22 paired samples of normal versus cancerous tissue; extracted the gene probe signals using the Robust Multiarray Analysis (RMA) algorithm (Irizarry et al. Citation2003); and, finally, filtered out 10% of weakly expressed genes with lowest variances. In , the Bayes factor —defined by Equation (Equation12
(12)
(12) ) but reparameterized in terms of p(θ) as provided by Equation (Equation40
(40)
(40) ) in Appendix D—is plotted against the empirical p-value density histogram for 11,302 gene differential expression t-tests. It is seen that the Bayes factor fits extremely well the empirical p-value density, both in the middle of the graph where Bayesian evidence favors Ho, and at critical p-values at both ends of the range where Bayesian evidence favors H1. Recall that the Fisher–Student’s central h-distribution p-value density is the uniform density U(0, 1) on the range 0 ⩽ p ⩽ 1, a restatement of the probability transform theorem which stipulates that the distribution of p-values under the null hypothesis is uniform. On this p-range, the Bayes factor defined in Equation (Equation11
(11)
(11) ) simply reads
as the denominator simplifies to
More precisely, we prove in Appendix E that the Bayes factor BFν(p) is a bona fide probability distribution, modeling the H1-associated nonuniform p-value density in lieu of the Ho-associated uniform p-value density U(0, 1).
Figure 7. Bayes factor against a microarray empirical p-value density histogram. The Bayes factor
is plotted against the p-value density histogram for 11,302 gene differential expression t-tests of the GEO dataset with accession number GSE6631. On the range 0 ⩽ p ⩽ 1, the Fisher–Student’s central h-distribution p-value density simplifies to the uniform density U(0, 1). On this range, the Bayes factor therefore simply reads
The Bayes factor fits extremely well the empirical p-value density, both in the middle of the graph where Bayesian evidence favors Ho, and at critical p-values where Bayesian evidence favors H1.
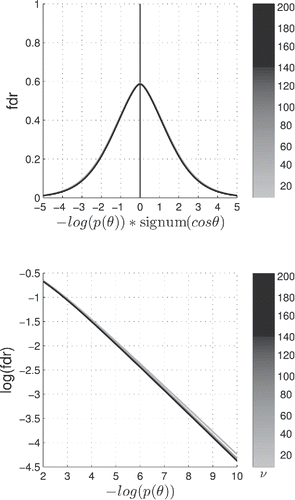
Since the microarray technology simultaneously interrogates the cellular expression of thousands of genes, one is readily confronted with the multiple hypothesis testing problem within the frequentist NHST framework (Dudoit, Shaffer, and Boldrick Citation2003). Efron (Citation2008) proposed a local false discovery rate (fdr) in terms of a two-group mixture density model of “null genes” and “nonnull genes” to address this problem. The present Bayesian approach affords a very economical definition of a local fdr in terms of the Bayes factor BFν(p):(14)
(14) We have, in the upper panel of plotted the local fdr on a p-value log-scale, while the lower panel can be used to assess the local fdr for vanishing p-values on a log-log scale. It is interesting to note that the curves for the local fdr are independent of the corresponding hypersphere number of degrees of
freedom ν and are essentially linear on a log–log scale in the relevant subdomain of vanishing values, a fact which attributes a degree of universality to the present Bayesian hypothesis testing framework based on the noncentral h-distribution (Equation7
(7)
(7) ) with the central Fisher–Student’s h-distribution (Equation3
(3)
(3) ) as geometrically meaningful maxent prior.
Figure 8. Local false discovery rate in terms of the Bayes factor
where ν is the hypersphere dimension which can be deduced from the grayscale colorbar. Upper panel: two-tail local fdr. Note the signed log-scale on the horizontal axis. Lower panel: blow-up and extension of the right-hand tail of the upper panel on a log–log scale. The local fdr curves are independent of the hypersphere number of degrees of freedom ν and are essentially linear on a log–log scale in the subdomain covered in the latter panel, a fact which attributes a degree of universality to the Bayesian hypothesis testing framework based on the noncentral h-distribution, with the central Fisher–Student’s h-distribution as geometrically meaningful maxent prior.
6. Conclusion
Using simple geometric concepts such as vectors, matrix projectors and trigonometric quantities, we have derived an analytical noncentral extension to the Fisher–Student’s central hypersphere distribution. Characterized by the single noncentrality parameter δ, this analytical noncentral h-distribution has allowed us to graphically assess the limitations of the Neyman–Pearson null hypothesis significance testing framework and the strengths of the Bayesian hypothesis analysis framework on a nontrivial one-dimensional compact parametric space. The central Fisher–Student’s hypersphere h-distribution has been geometrically argued to be an appropriate maxent prior. The corresponding Bayes factor and posteriors have been demonstrated to remedy in part to the vexing question of the reproducibility of science, by modulating down overestimated size effects that a frequentist analysis would inevitably produce. The Bayes factor has been shown to adequately model the empirical p-value density of a multiple hypothesis testing dataset produced by the microarray technology, and to provide easy assessment of a local false discovery rate. The noncentral h-distribution has thus allowed us to address all the intricacies of both the Neyman–Pearson null hypothesis significance testing framework and the Bayesian hypothesis analysis framework while avoiding use of the unwieldy noncentral t-distribution or problems arising from working in higher-dimensional parametric spaces. As such, the noncentral hypersphere h-distribution has relevance both as a practical tool and as a pedagogical tool for a broad audience.
References
- Baharev, A., Schichl, H., and Rév, E. (2017), “Computing the Noncentral-f Distribution and the Power of the F-test with Guaranteed Accuracy,” Computational Statistics 32, 763–779.
- Burnham, K. P., and Anderson, D. (2014), “P values are Only an Index to Evidence: 20th vs. 21st-century Statistical Science,” Ecology, 95, 627–630.
- Chance, W. A. (1986), “A Geometric Derivation of the Distribution of the Correlation Coefficient |r| when ρ= 0,” American Mathematical Monthly, 93, 94–98.
- Collaboration, O. S. et al. (2015), “Estimating the Reproducibility of Psychological Science,” Science, 349, aac4716.
- Colquhoun, D. (2014), “An Investigation of the False Discovery Rate and the Misinterpretation of p-values,” Royal Society Open Science, 1, 140216.
- Cumming, G., and Finch, S. (2001), “A Primer on the Understanding, use, and Calculation of Confidence Intervals that are Based on Central and Noncentral Distributions,” Educational and Psychological Measurement, 61, 532–574.
- Dudoit, S., Shaffer, J. P., and Boldrick, J. C. (2003), “Multiple Hypothesis Testing in Microarray Experiments,” Statistical Science, 18, 71–103.
- Durbin, J., and Kendall, M. G. (1951), “The Geometry of Estimation,” Biometrika, 38, 150–158.
- Efron, B. (2008), “Microarrays, Empirical Bayes and the Two-groups Model,” Statistical Science, 23, 1–22.
- Ellis, P. D. (2010), The Essential Guide to Effect Sizes: Statistical Power, Meta-analysis, and the Interpretation of Research Results, Cambridge, UK: Cambridge University Press.
- Etz, A., and Vandekerckhove, J. (2016), “A Bayesian Perspective on the Reproducibility Project: Psychology,” PloS One, 11, e0149794.
- Fisher, R. A., et al. (1925), “Applications of Student Distribution,” Metron, 5, 90–104.
- Gönen, M., Johnson, W. O., Lu, Y., and Westfall, P. H. (2005), “The Bayesian Two-Sample t Test,” The American Statistician, 59, 252–257.
- Goodman, S. N. (1999a), “Toward Evidence-based Medical Statistics. 1: The p Value Fallacy,” Annals of Internal Medicine, 130, 995–1004.
- Goodman, S. N. (1999b), “Toward Evidence-based Medical Statistics. 2: The Bayes Factor,” Annals of Internal Medicine, 130, 1005–1013.
- Gorroochurn, P. (2016), Classic Topics on the History of Modern Mathematical Statistics: From Laplace to More Recent Times. New York: Wiley.
- Greenland, S., Senn, S. J., Rothman, K. J., Carlin, J. B., Poole, C., Goodman, S. N., and Altman, D. G. (2016), “Statistical Tests, p Values, Confidence Intervals, and Power: A Guide to Misinterpretations,” European Journal of Epidemiology, 31, 337–350.
- Halsey, L. G., Curran-Everett, D., Vowler, S. L., and Drummond, G. B. (2015), “The Fickle p Value Generates Irreproducible Results.“ Nature Methods, 12, 179–185.
- Ioannidis, J. P. (2008), “Why Most Discovered True Associations are Inflated,” Epidemiology, 19, 640–648.
- Irizarry, R. A., Bolstad, B. M., Collin, F., Cope, L. M., Hobbs, B., and Speed, T. P. (2003), “Summaries of Affymetrix Genechip Probe Level Data,” Nucleic Acids Research, 31, e15–e15.
- Jaynes, E. T. (1968). “Prior Probabilities,” IEEE Transactions on Systems Science and Cybernetics, 4, 227–241.
- Jeffreys, H. (1998). The Theory of Probability. Oxford, UK: Oxford University Press.
- Kuriakose, M., Chen, W., He, Z., Sikora, A., Zhang, P., Zhang, Z., Qiu, W., Hsu, D., McMunn-Coffran, C., Brown, S. et al. (2007b, January), “Expression Data from Head and Neck squamous Cell Carcinoma,” available at https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE6631.
- Kuriakose, M., Chen, W., He, Z., Sikora, A., Zhang, P., Zhang, Z., Qiu, W., Hsu, D., McMunn-Coffran, C., Brown, S. et al. (2004a), “Selection and Validation of Differentially Expressed Genes in Head and Neck Cancer,” Cellular and Molecular Life Sciences, 61, 1372–1383.
- Mazliak, L. (2015). “Poincarés Odds,” in Henri Poincaré, 1912–2012. eds. B. Duplantier and V. Rivasseau, Berlin: Springer, pp. 151–192.
- Nuzzo, R. (2014), “Statistical Errors,” Nature, 506, 150–152.
- Pereira, T. V., Horwitz, R. I., and Ioannidis, J. P. (2012), “Empirical Evaluation of Very Large Treatment Effects of Medical Interventions,” Jama, 308, 1676–1684.
- Rothman, K. J. (2016), “Disengaging from Statistical Significance,” European Journal of Epidemiology, 31, 443–444.
- Schulze, A., and Downward, J. (2001), “Navigating Gene Expression Using Microarrays: A Technology review,” Nature Cell Biology, 3, E190–E195.
- Walck, C. (2007), Handbook on Statistical Distributions for Experimentalists, Stockholm: University of Stockholm.
- Wang, M., and Liu, G. (2016), “A Simple Two-sample Bayesian t-test for Hypothesis Testing,” The American Statistician, 70, 195–201.
- Wasserstein, R. L., and Lazar, N. A. (2016), “The asa’s Statement on p-values: Context, Process, and Purpose,” American Statistical, 70, 129–133.
A. Projector Matrices
The N × N matrix projectors PC, PB and PW, which respectively project the observation N-vector o on the overall center-of-mass, the between-class variance hyperplane and the within-class variance hyperplane, are given by the matrices
(15)
(15) where
partitions the total of N = ∑ν1 + 1i = 1ni observations composing the observation N-vector o into ν1 + 1 respective class cardinalities. The projectors obey the identity resolution
(16)
(16) with IN the identity matrix. Recall that a matrix projector obeys the defining property P2 = P, with eigenvalue equation λ(λ − 1) = 0: its eigenvalues are thus restricted to the values {0, 1}, and its rank is provided by the cardinality of the set of its non-vanishing unit eigenvalues. The projectors PC, PB and PW have ranks 1, ν1 and ν2 = N − ν1 − 1, respectively. The two-sample case corresponds to ν1 = 1.
B. Determination of the Sampling Distribution
Using the matrix resolution of the identity (Equation16(16)
(16) ), consider the situation when the within-class uniform centered vector
(17)
(17) along the unit polar axis TB is added to an observation vector drawn from a population with null noncentrality parameter. In the two group comparison context, this will impart the nonvanishing normalized effect size δ1 to the first subpopulation, and the nonvanishing normalized effect size δ2 to the second subpopulation. Under these circumstances, the two-sample t-statistic (Equation1
(1)
(1) ) will distribute according to the noncentral h-distribution ρ(ν, Δ)(θ), with noncentrality parameter Δ given by the factor multiplying TB above, that is,
(18)
(18) The quantity
(19)
(19) is needed to determine the noncentrality parameter
(20)
(20) as reexpressed in trigonometric terms. We have carried out the latter tedious enumeration of square root factors because they are often introduced summarily in the literature with no reference to their simple geometric origin. See, e.g., Ellis (Citation2010).
C. Noncentral Hypersphere F-distribution
The F-statistic is defined in both projection and geometrical terms via the variance ratio
(21)
(21) where ν1 and ν2 are the dimensions of the between-class and within-class variance hyperplanes, respectively. The matrix projector PB and PW are defined in Appendix A. Geometrically, θ is the angle between the observation vector o and the between-class variance hyperplane, and π/2 − θ the angle between o and the orthogonal pooled within-class variance hyperplane. When the observation o has uniform class-independent isotropic distribution on the central unit radius hypersphere
F distributes according to the central (Λ = 0) Fisher–Snedecor F-distribution
(22)
(22) The NHST p-value is obtained by computing the probability of having an observation with angular distance θ′ ⩽ θ to the between-class variance hyperplane: it is given by
(23)
(23) the integration of which can be carried out analytically: see Appendix D. We shall find convenient in the following to effect the change of variable R = cos θ in order to reexpress the central Fisher–Snedecor F-distribution (Equation22
(22)
(22) ) as
(24)
(24) with R a correlation-like parameter. Consider now the projection of the observation vector o on the between-class variance hyperplane. Since PB is a projector operator of rank ν1, it is invariant under rotation within the corresponding unit-eigenvalue eigenspace. This eigenspace degeneracy will allow us to perform the noncentral hypersphere cosine translation
(25)
(25) expressed in terms of the noncentrality parameter Λ for the noncentral F-distribution along a unit vector
of our choosing in this eigenspace. In the coordinate system centered on the hypersphere, we thus define the polar coordinates
(26)
(26) The 3-vector
is easily argued to distribute according to the joint distribution
(27)
(27) where
is the Fisher–Student’s central
distribution (Equation3
(3)
(3) ). When the noncentrality parameter Λ is nonvanishing, the observation vector as assessed in the observation coordinate system shall similarly read
with its polar coordinates r and ψ both function of the noncentral parameter (Equation25
(25)
(25) ). Indeed, when the latter 3-vector is recentered on the translated hypersphere and renormalized, it reads
(28)
(28) which leads us to consider the polar coordinate transformation
(29)
(29) The transformation Jacobian is given by
(30)
(30) where the denominator term
is noted to vanish at the center of the translated hypersphere, that is, at
Introducing the transformation (Equation29
(29)
(29) ) into the joint distribution (Equation27
(27)
(27) ) and regrouping the various terms, we find that
(31)
(31) where
is the central Fisher–Snedecor F-distribution (Equation24
(24)
(24) ), and where the likelihood function
is given by
(32)
(32) with neat cancelation of all singular terms. When Λ = 0, we have that
ψ = ϕ, r = R, and
simplifies to the central Fisher–Snedecor
distribution
defined by equation (Equation27
(27)
(27) ). The density
can be drawn on a two-dimensional half-circle as in , with the polar coordinates (r, ψ) summarizing the between-class variance hyperplane coordinates. We are ultimately interested in the distribution of
parameterized by the correlation-like parameter r only. The desired distribution function is obtained by computing the marginal distribution of (Equation31
(31)
(31) ), that is, by integrating it with respect to polar coordinate angle ψ, as is graphically illustrated in . We thus have that
distributes according to
(33)
(33) with
(34)
(34)
Figure 9. Left upper panel: central Fisher–Snedecor F-distribution plotted on the between-class variance hyperplane summarized by the polar coordinates (r, ψ). Right upper panel: noncentral h-distribution
similarly plotted on the between-class variance hyperplane. Left lower panel: central Fisher–Snedecor F-distribution
as plotted along the correlation-like r axis: it is the marginal distribution of the distribution above it, graphically obtained by circularly sweeping the distribution radar-like from ψ = −π to ψ = 0 and projecting the sweep result on the positive axis of the lower panel. Right lower panel: noncentral h-distribution
as plotted along the correlation-like r axis: again, it is the marginal distribution of the distribution above it.
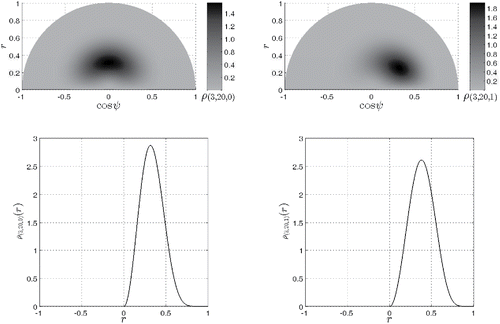
The special case ν1 = 1 is given by
(35)
(35) where
is the noncentral h-distribution (Equation7
(7)
(7) ) reexpressed in terms of the correlation-like r parameter:
(36)
(36) For the sake of comparison, we state without proof that the noncentral F-distribution can be expressed as
(37)
(37) with the likelihood function
defined by the cumbersome infinite sum of terms (Walck (Citation2007))
Equations (Equation33
(33)
(33) ) and (Equation37
(37)
(37) ) are graphically compared in . The latter distribution is known to generate numerical instabilities. Indeed, Baharev, Schichl, and Rév (Citation2017) state that “computations involving the noncentral F-distribution are notoriously difficult to implement properly in floating-point arithmetic: catastrophic loss of precision, floating-point underflow and overflow, drastically increasing computation time and program hang-ups, and instability due to numerical cancellation have all been reported.” The simpler analytical expression (Equation33
(33)
(33) ) for the noncentral hypersphere distribution should help avoiding such numerical instabilities, while allowing easier exploitation of the Bayesian hypothesis testing framework as was carried out in Section 4. Finally, note that definitions of the noncentrality parameter Λ vary in the literature: numerical computations as carried in indicates that equation (Equation25
(25)
(25) ) refers to the parameter λ (herein Λ) used by Walck (Citation2007).
Figure 10. Left panels: probability density curves for the noncentral hypersphere distribution for the parameters (Λ, ν1) stated in the legend and ν2 which can be deduced from the grayscale colorbar. Right panels: probability density curves for the noncentral F-distribution
for the same parameter set. The noncentral hypersphere distribution
offers a very economical analytic alternative to the noncentral F-distribution
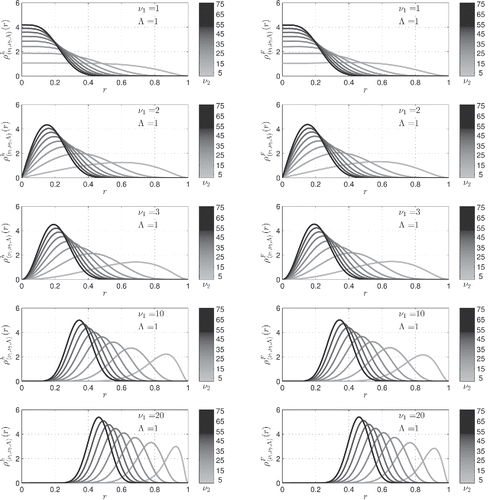
D. Analytic Expressions for the Cumulative Distribution Functions (p-values)
Cumulative distribution functions, thus p-values,
(38)
(38) for the central Fisher–Student t-distribution (Equation3
(3)
(3) ) can be computed analytically in trigonometric terms. One finds for ν2 odd
(39)
(39) where only the first term should be retained for ν2 = 1, the first two terms for ν2 = 3, etc.; and for ν2 even
(40)
(40) where only the first two terms should be retained for ν2 = 2, the first three terms for ν2 = 4, etc. As expected, p(θ) = 0, 1/2 and 1 for θ = 0, π/2 and π, respectively. See also Chance (Citation1986). Similarly, cumulative distribution functions, thus p-values,
(41)
(41) for the central Fisher–Snedecor F-distribution (Equation22
(22)
(22) ) can be computed analytically in trigonometric terms. We find for ν1 even
for ν2 even
while, for ν1 and ν2 simultaneously odd,
where
and
See also Walck (Citation2007). All of the above formulae have been extensively verified to reproduce numerical outputs from softwares with statistical subroutines such as R or MATLAB.
E. BFν(p) as normalized p-value distribution
When the Bayes factor BFν(θ) is reparameterized in terms of p(θ) as computed in Appendix D, we have that
which demonstrates that BFν(p) is a normalized p-value density as long as the prior Prν(θ1) is itself a normalized probability density.