
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Adversarial Risk Analysis (ARA) allows for much more realistic modeling of game theoretical decision problems than Bayesian game theory. While ARA solutions for various applications have been discussed in the literature, we have not encountered a manuscript that assesses ARA in a real-life case study involving actual decision-makers. In this study, we present an ARA solution for the Parole Board decision problem. To elicit the Parole Board’s probabilities and utilities regarding the convict’s choices and resulting consequences, as well as their own subjective beliefs about such probabilities and utilities, we conducted a detailed interview with two current members of the New Zealand Parole Board, using a realistic case report. Subsequently, we derived the optimal ARA decision for different scenarios. This study highlights the advantages and challenges of the ARA methodology for real-life decision-making in the presence of an adversary.
1 Introduction
Most individuals who go to prison return to the community, sooner or later. In many jurisdictions, people may be released from prison before completing their given sentence. However, once back in the community, they are subject to a period of formal oversight and supervision, and must comply with various release conditions, such as residing at a specific address or attending alcohol and drug treatment programs. A Parole Board is responsible for determining both the convict’s release date and the conditions imposed during their time in the community. In this article, we demonstrate the novel application of Adversarial Risk Analysis (ARA)—a Bayesian statistical approach that combines elements of game theory with statistical risk analysis to create a realistic and strategic risk analysis tool—and explore ARA’s potential to support Parole Board decision-making.
Parole is a controversial concept. On the one hand, some may perceive offenders as “getting off lightly” when they return to the community before serving the full sentence imposed by the court. Early release might be seen as a clandestine way of undermining the sentencing judge’s decision, as it reduces the effective prison term through a less transparent process than the original public sentencing hearing. On the other hand, parole is argued to benefit community safety: it offers a chance to mitigate the risk of recidivism by mandating a structured transition into community life, rather than simply releasing individuals at the end of their sentence without any support.
Parole can be mandatory or discretionary. With mandatory parole, the convict is released at a predetermined sentence milestone, meaning they serve an unvarying proportion of the sentence. On the other hand, discretionary parole refers to the process by which a parole-granting authority determines both the date and circumstances of release. Each eligible convict’s characteristics, history, current presentation, and proposed release circumstances at the time of assessment are taken into account (Gobeil and Serin 2010). Parole Boards are thus tasked with carrying out a series of complex cognitive steps that involve integrating information from a wide range of sources to make judgments about the current and future risk of overall criminal offending or specific, serious types of future offenses. They also need to consider whether available resources and restrictions can adequately mitigate those risks, whether additional preparation in prison is necessary, and so on.
The complexities of this process can be further enhanced by a political context in which there are often too few resources (Serin et al. Citation2016), and significant pressure not to make what is known as a “false negative” error, where a convict is released based on assessed safety and later caught for re-offending. Increases in risk aversion are believed to have permeated parole decision-making, as they have in other aspects of Western criminal justice systems (Buglar Citation2016). Such pressure can increase dramatically following sentinel events that cause widespread public concern, regardless of whether such events could reasonably have been foreseen (Polaschek and Yesberg Citation2018). Alongside predictive accuracy, transparency—particularly concerning the information considered and its evaluation—is essential in external reviews of decisions, especially when there has been a subsequent sentinel event. However, it is also crucial for individuals; a mismatch between the bases for decisions and people’s understanding of what is relevant can lead to issues with institutional morale and safety (Caplan Citation2007).
The quality of Parole Board decision-making (PBDM) depends on several components, including how effectively the decision-makers obtain and consider relevant information (e.g., information associated with subsequent recidivism) and how they combine that information to form an overall assessment of current risk and potential mitigation in order to reach a decision. Recent research has highlighted that some Parole Board members may feel overwhelmed by the amount of information presented to them (Ruhland Citation2020). Decisions to grant parole may sometimes give disproportionate weight to factors that may not be good predictors of subsequent recidivism, such as the nature or severity of the offense for which the convict is on sentence (Vîlcicc˘ 2018), their gender (Buglar Citation2016), or even victim-based retributive concerns (Roberts Citation2009). Although several parole authorities have guidelines on decision-making (Roberts Citation2009; Canada Citation2019) it does not necessarily guarantee that they will adhere to them (Caplan Citation2007; Gobeil and Serin 2010), and members of the same board have been noted to differ in which factors they consider most important (Ruhland Citation2020). The weights assigned to factors and the manner in which they are defined or perceived by each member are often influenced by their personal or professional experiences and biases (Ruhland Citation2020).
PBDM is often made under time pressure, fostering the use of cognitive shortcuts or heuristics in balancing evidence and reaching decisions (Gobeil and Serin Citation2009). Such opaque processes make it challenging to evaluate sources of (in)accuracy. Even if members of parole authorities do follow decision-making guidelines, the actual process by which they combine information to reach decisions is unclear. For example, how do they combine pre-sentence information, information on behavior in prison (including apparent positive change), and details about the quality of the release plan and available resources for mitigating areas of future uncertainty?
Decision support tools can aid in achieving more consistent, accurate, and defensible parole decisions. Similar to psychological assessments of offender risk, these approaches shift the field’s reliance from unstructured judgment—which has been linked to low levels of accuracy and lacks clarity regarding the information considered and its influence on the decision—to a more structured professional judgment approach.
Serin and Gobeil (Citation2014) and Serin et al. (Citation2016) provide a recent example of a decision support tool, initially with the Canadian parole authority. This tool, called the Structured Parole Decision-making framework (SPDMF) is anchored in a statistical risk estimate for each offender. When this tool is well-validated for use with the current case, these estimates are the most accurate method we have for forecasting recidivism from custody. At the same time, parole legislation and natural justice concerns require that such estimates be viewed as a starting point, to be adjusted with the addition of relevant, case-specific information.
The SPDMF was developed to reduce apparent inconsistency in decision-making by: (a) directing Parole Board members to consider a limited number of additional domains supported by previous research; (b) limiting the consideration of irrelevant factors that could lead to erroneous decisions; (c) demonstrating that information distinct to this offender can be meaningfully incorporated. The approach also needed to prove itself as easy to use by board members without extensive additional training or an increase in the time needed to make a decision, and serve as support rather than prescribing decisions or hampering perceptions of autonomy (Serin et al. Citation2016).
Once a static-risk (in this context, static-risk refers to factors that are not changeable such as prior criminal history) estimate is determined for the offender, the next step is to consider seven general domains that can be understood as aggravating, neutral, or mitigating. This step involves evaluating factors such as prison behavior, program participation, and behavioral changes, along with any relevant case-specific factors and the quality of the release plan. Subsequently, information from the parole hearing, such as the convict’s behavior during the interview, can be incorporated, and any discordant information is discussed. Finally, the decision and its justification are documented for release (Serin et al. Citation2016).
The SPDMF has been implemented in both Canada and New Zealand, with evidence indicating that its use is associated with a reduction in decision errors (Gobeil and Serin 2010). The framework was also evaluated through a retrospective application to cases in three US states (Serin and Gobeil Citation2014), with beneficial preliminary effects on decision quality noted, although the results regarding accuracy were somewhat inconclusive.
Parole Board Decision Making in New Zealand
In New Zealand, most people who have been sentenced to more than two years of imprisonment become eligible for parole after serving one-third of their sentence, according to the Parole Act, 2002. The most recent available data show that, on average, they serve 78% of their sentence (Factsheet Citation2018). Once eligible for parole, convicts may appear before a panel of 2–5 members of the Parole Board to apply for release. In 2021–2022, the New Zealand Parole Board conducted 5716 hearings and approved 28% of these.
There is limited external research on the decision-making processes of the New Zealand Parole Board. An online vignette study with nine New Zealand Parole Board members found variation among members in the decisions made and in the extent to which participants accessed additional information, with supplementary information related to recidivism being accessed more than less recidivism-relevant information (e.g., mental health status; Gobeil and Serin Citation2009). A study of factors predicting release for 300 high-risk violent male convicts suggested that once estimated static risk was controlled for, the most directly relevant factor in release decisions was the quality of the release plan (Polaschek and Yesberg Citation2018). Finally, using the same dataset, Polaschek, Yesberg, and Chauhan (Citation2018) showed that those released by the board immediately following intensive rehabilitation had lower dynamic risk scores (in this context, dynamic risk refers to factors that are potentially changeable such as substance abuse) than those who were not immediately released. Those whose release was delayed had comparable scores at the time of their eventual release to those released soon after the program, and had therefore made significantly more changes to reach their prerelease level. Both of these studies suggest that the board is attending to risk-relevant information in making decisions, including information specific to the case at hand (e.g., current dynamic risk, personal release plan).
The purpose of this article is to demonstrate the application of ARA as an approach to supporting PBDM. As we noted earlier, PBDM requires a challenging array of cognitive tasks. One feature of the process is arguably the ability of board members to project themselves into the minds and future lifestyles of the convicts they are considering. Are they genuinely committed to avoiding new offending on parole? How likely are they to desist? What circumstances could make desistance more likely to “stick”? If they do re-offend, what type of offending is it likely to be? What might be the circumstances that make new offending more likely? What is the probability that the convict has been strategic in displaying desirable behavior just to be released on parole but actually has no intention of rehabilitating? And so on. PBDM represents decision-making under uncertainty and, possibly, in the presence of a strategic adversary. ARA offers a systematic way of quantifying the various uncertainties and utilities and provides a mathematical framework to collate and process all this information in a logically consistent manner. ARA can potentially be a valuable aid in PBDM. In this article, we aim to demonstrate why and how.
The structure of this article is as follows. In Section 2, we introduce the basic ideas and principles behind ARA and describe how ARA can be used to find the optimal action in a typical two-player defend-attack-defend game. In Section 3, we illustrate how ARA can be applied to PBDM. In Section 4, we demonstrate the workings of ARA for PBDM using a realistic case study. Finally, in Section 5, we summarize and discuss the challenges and further work.
2 Adversarial Risk Analysis
Adversarial Risk Analysis (ARA) (Ríos Insua, Rios, and Banks Citation2009; Banks, Rios, and Ríos Insua Citation2015) combines statistical risk analysis with Game Theory. The idea behind ARA is to improve Game Theory by departing from two often unrealistic assumptions central to it: common knowledge and the minimax equilibrium solution concept. ARA models the problem from the perspective of just one of the players (typically, the defender) and finds an optimal solution for that player alone. A positive implication of this is that a solution almost always exists, and often finding a Monte Carlo solution is relatively straightforward. Instead of assuming common knowledge, it incorporates the uncertainty around prior information about the adversary, their choices, preferences, etc., using Bayesian methods to solve the problem. ARA can model the human thought process and incorporate various forms of information, including prior or incomplete knowledge, uncertainties, and preferences/utilities. It enables one to model the thinking of an adversary and is therefore ideally suited for problems in which intelligent actors with conflicting interests make interdependent decisions under uncertain conditions, as is common in security, counter-terrorism, cybersecurity, and warfare.
Decision-making under uncertainty is challenging. When faced with uncertainty, part of a rational decision-making process involves attempting to assess the likelihood of possible outcomes and evaluate their favorability before making a decision. In a real-life decision-making process, the perceived probabilities and utilities (indicating favorability) are subjective. Hence, two individuals, presented with the same decision, possessing the same information, and following the same rational decision-making process, may still arrive at different decisions due to their differing perceived probabilities and utilities.
Furthermore, when dealing with a strategic opponent, one must try to anticipate their thinking and predict their actions to prepare for countering them. What makes this process challenging is not only the coherent quantification of various uncertainties (such as the choices and preferences of the adversary and the possible outcomes) and utilities but also the collation and logically consistent processing of all this information. The human brain is known to have limitations in handling this aspect effectively.
Since its introduction in 2009, ARA has been used to model a variety of problems, including network routing for insurgency (Wang and Banks Citation2011), international piracy (Sevillano, Ríos Insua, and Rios Citation2012), counter-terrorism (Rios and Ríos Insua Citation2012), autonomous social agents (Esteban and Ríos Insua Citation2014), urban security resource allocation (Gil, Ríos Insua, and Rios Citation2016), airport security (Cano et al. Citation2016a, Citation2016b), countering unmanned aerial vehicle (UAV) threats (Roponen, Ríos Insua, and Salo Citation2020), developing a framework for cybersecurity, including cyber insurance (Rios Insua et al. Citation2021), and addressing insider threats (Joshi, Aliaga, and Insua Citation2020). ARA has also found applications in adversarial classification for spam detection problems (Naveiro et al. Citation2019), as well as non-security domains, such as auctions (Banks, Rios, and Ríos Insua Citation2015; Ejaz, Joe, and Joshi Citation2021; Ejaz, Joshi, and Joe Citation2021, 2022).
2.1 The Sequential Defend-Attack-Defend model
A Sequential Defend-Attack-Defend (D-A-D) model (see, for instance, Brown et al. (Citation2006) and Parnell, Smith, and Moxley (Citation2010)) can be applied to several real-life situations where a defensive measure is pre-deployed either to deter, prevent or neutralize a possible attack. In this model, the Defender deploys defensive resources first. The Attacker then observes these defensive measures and proceeds with an attack. Finally, the Defender tries to recover from the attack as best as she can. Access control measures at important installations and standard security checks at airports are examples where preventative defensive measures are already deployed. Despite D-A-D being a very realistic template, very few game and Bayesian game theoretical models have been proposed using this template. This is because finding a unique equilibrium solution for a D-A-D problem is much more difficult. However, ARA does not suffer from this drawback and an ARA solution for a D-A-D game can be derived (Joshi, Aliaga, and Insua Citation2020). Additionally, as stated before, ARA does not assume common knowledge.
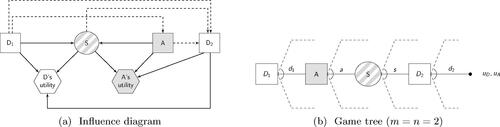
(a) illustrates the influence diagram for the Sequential D-A-D model, with the corresponding game tree represented in (b) (Shachter Citation1986) The Defender’s initial and subsequent decisions are denoted by nodes and
, respectively, while node A represents the Attacker’s decision. The shared uncertainty node is S. The choices made are
,
, and
. The sets
,
, and
, which can be discrete or continuous, could represent various possibilities, such as defense policies, policy levels, defensive resource allocations, or plans, the attack levels/resources, among others. We assume that the only relevant uncertainty is the success level S of the attack, probabilistically dependent on
. The consequences for both the Defender and the Attacker, modeled through their corresponding utility functions, depend respectively on
—which represents the effort in implementing protective and recovery actions and the mitigated result of the attack—and on
, accounting for the endeavor in executing the attack and its outcome, attenuated by the Defender’s recovery action.
Figure 1: The Defend-Attack-Defend model.
2.2 ARA Solution for the Sequential D-A-D Model
We now provide the ARA solution for the Sequential Defend-Attack-Defend model introduced in Section 2.1. In this scenario, D initially chooses a defensive action from a set of possible options
, where
represent individual defensive actions available to her. A can observe
and then decides to launch an attack A from a set of available attacks
. The attack A results in one of the outcomes from the set
. Subsequently, D observes A and S and proceeds to take a follow-up defensive action
from the set
, which represents her available follow-up actions.
Let us consider a shoplifting problem to illustrate this scenario. Here, D is the shop owner and can choose from the following set of deterrence measures Let us say she decides to install security cameras, that is,
The shoplifter A observes
and can subsequently choose one of the following actions
The possible outcomes are
Depending on A and S, one of the following follow-up defensive actions is possible:
no action taken, A is caught but not referred to the police, A is caught and referred to the police, A is not caught, and the matter is referred to the police
. In this case, let us suppose that A decided to steal a little and was not caught, that is,
Therefore, the set of follow-up actions available to D is reduced to
no action taken, A is not caught, and the matter is referred to the police
.
We approach this problem from the defender’s perspective. We begin by defining the utility function , which considers the costs, benefits, gains, and losses associated with each of her actions, as well as any impacts caused by the attacker’s actions and the resulting outcomes. The goal is to identify the optimal actions
and
that maximize the expected utility for
If A is strategic, we can also establish a similar utility function
for A. This function helps us determine the likely optimal action
for A and subsequently find the corresponding optimal actions
and
.
2.2.1 Solving the Defender’s Problem
ARA typically seeks a solution that maximizes the defender’s expected utility. This involves finding the optimal defensive actions that take into account her uncertainties regarding the attacker’s actions and their potential outcomes. To achieve this, the defender’s first task is to determine her utility function . Additionally, D must quantify her uncertainties about: (a) the outcome of S given
and a, using a conditional probability distribution
, and (b) the action A given
, using a conditional probability distribution
. The ARA solution can be obtained through the Backward Induction algorithm (see, e.g., Ríos Insua, Rios, and Banks Citation2009; Banks, Rios, and Ríos Insua Citation2015). Starting from the final node,
, we work backward to reach the first node, obtaining the action
that maximizes the utility function
, assuming the defender has already made her decision
and observed the outcome s
(1)
(1)
Next, with the knowledge of the optimal action and considering the uncertainty in the outcome s, we calculate the expected utility
for each combination of
and a as follows:
(2)
(2)
Here, the defender elicits based on her subjective beliefs. For instance, she may believe that if
then the probability of A being caught is very high (say, 0.9). This leads to
and, consequently,
Afterward, we address the uncertainty in the attacker’s action a and determine the expected utility for each
(3)
(3)
Finally, we find the action that maximizes the expected utility,
(4)
(4)
Thus, the optimal course of action for D would be to first choose and then, having observed a and s, choose
. Note that in this discussion, the sets
,
,
, and
are discrete and finite. But some or all of these could be infinite sets representing the state space of a continuous variable, where need be. For instance, if
and
were infinite sets then the summations in (2) and (3) would be replaced by corresponding integrals.
2.2.2 Eliciting the Utility Function and the Probabilities
Since ARA follows a Bayesian statistical approach, utilities and probabilities are elicited subjectively, meaning there is no fixed “correct” elicitation of such quantities. The defender elicits her utility function and the conditional probability distributions using her own judgment, analysis, and beliefs. Elicitation of and
is typically considered to be relatively straightforward. This is because they are quantities that relate to the defender’s own assessment. For example, eliciting
could require calculating monetary benefits/losses, which can, in most cases, be estimated. It could also include quantification of factors such as gain/loss of reputation or trust, etc., and while there is typically no exact science to calculate these, it should be possible for the defender to quantify their own subjective beliefs about them. Similarly, the elicitation of
is based on the defender’s analysis or beliefs, and in some cases, there could even be past data to base these judgments on.
On the other hand, the elicitation of is concerned with the probabilities associated with the actions of the attacker given the defensive action(s) in place. It could therefore be less straightforward because the defender could never be sure about the attacker’s beliefs, preferences, or line of thinking, and would only be able to make educated guesses about them. In some cases, there could be past data available (e.g., the attacks chosen by similar attackers in the past), and in such cases, this probability could be elicited using prior historical information. The defender can also choose to elicit this probability subjectively using her own beliefs.
If A is considered to be strategic, then we could also attempt to imitate his solution concept (thinking process) to estimate these probabilities. ARA can solve the problem for a number of different mathematical solution concepts for the attacker (Rios Insua, Banks, and Rios Citation2016). Thus, can be derived assuming that the attacker is nonstrategic, or is trying to find a Nash equilibrium solution, or employs level-k thinking, and so on. In this case, we derive
, assuming that the attacker is an expected utility maximizer. That is, we assume that the attacker is likely to choose the action which will give him the highest utility when taking into account his uncertainties about the outcome and about the follow-up defensive action that he thinks the defender will take.
2.2.3 Modeling the Attacker’s Strategic Thinking
Under the assumption that the attacker is an expected utility maximizer, we can elicit by essentially following the same backward induction process as in Section 2.2.1, but using the attacker’s utilities and probabilities. However, in ARA, we solve the problem from the point of view of the defender, using the information available to her. Since the defender will not know
exactly, she could quantify her uncertainty about
by eliciting a random utility function (probability distribution)
and sampling
from it. Similarly, the defender will not know the attacker’s probabilities
and
exactly, but she could quantify her uncertainty about these by eliciting random probabilities
and
instead.
First, the defender would start by finding the attacker’s random expected utility after taking into account his uncertainty about ,
(5)
(5)
Next, she would find the attacker’s random expected utility after taking into account his uncertainty about s,
(6)
(6)
Next, she would find the random optimal action that will maximize his expected utility given
,
(7)
(7)
Finally, once the defender assesses , she is able to solve her decision problem. The desired predictive distribution by the defender about the attack chosen by the attacker, given the initial defense
, is
(8)
(8) which is typically obtained using Monte Carlo simulations by sampling from the random utility function and the random probabilities a large number of times.
3 Applying ARA to Parole Board decisions
In real-life cases, the decision-making and administering of parole may involve multiple agencies alongside the Parole Board. For example, in New Zealand, The Department of Corrections, New Zealand Police, and other government agencies may be involved depending on individual case circumstances. For simplicity, in this study, we focus on a two-player game between the Parole Board and a convict who has completed the non-parole portion of the sentence, making them eligible for discretionary release onto parole. The Parole Board aims to release convicts when they believe the risk of parole violation is low and aim to minimize potential risks to the community after release.
Additionally, we assume that offenders are at least somewhat rational, and thus, they may choose not to re-offend unless they expect the benefits to outweigh the costs. To model this scenario, we use a sequential defend-attack-defend game, as discussed in Section 2.1, where the Parole Board acts as the defender making an initial decision about releasing the convict on parole or not. The convict, in response, takes one or more actions referred to as “attacks,” and the board must respond with follow-up actions to defend against these responses. The ARA solution for this problem can be obtained as outlined in Section 2.2. In this study, we focus on defining the action and outcome sets for this problem and discuss how to elicit the required probabilities.
3.1 Defining the Outcome Sets
To apply the ARA approach to solve this problem, we will begin by defining sets of actions for both the Parole Board and the offender.
The set of initial defensive actions by the Parole Board is as follows:
This decision is typically based on a wide range of information made available to the Parole Board. Not granting Parole is a defensive action as it prevents the convict from breaching their Parole conditions or posing risks to the community. On the other hand, granting Parole can also be considered a defensive action if the available information suggests that the convict has shown signs of reforming, as it encourages rehabilitation and helps prevent further re-offending.
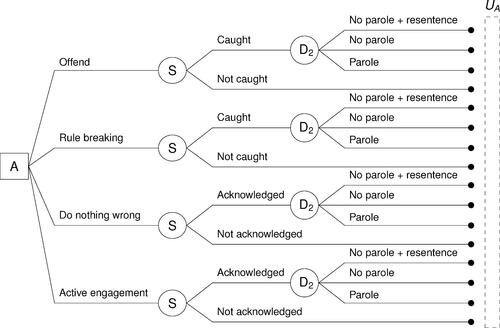
Once the initial decision has been implemented, the convict may choose to respond in several ways. The sets of possible actions will depend on the initial decision and may include both positive and negative actions from the point of view of the Parole Board. Therefore, here we define the action sets conditional on the initial decision as follows:
Since the convict’s responses are dependent upon the initial decision, the resulting outcomes will also be affected. Here, we solely focus on the outcomes for the convict in relation to their sentence/parole. Subsequent to any action that the convict takes after parole is granted, the only relevant outcomes are whether that action was detected by the authorities or not. For instance, the convict may choose to commit a crime while on parole, but that action will only have an effect on their future sentence/parole conditions if the authorities eventually detect it. Similarly, any action that the convict commits in prison upon parole being not granted will only have an effect on their future sentence/parole if it was noted by the prison authorities. We distinguish between
(when
Finally, the follow-up action sets will depend upon the outcome of the attack and the initial decision. We assume that the conditional follow-up action sets are as follows:
While the game between the Parole Board and the convict under consideration can still be succinctly represented using the influence diagram in (a), the sequence of actions and outcomes possible under different possible scenarios can be more effectively expressed using a decision tree instead. In this case, the Parole Board can express their game using two decision trees, as shown in and , one when they decide to grant parole () and the other when they do not (
).
Figure 2: Decision tree for the Parole Board if .
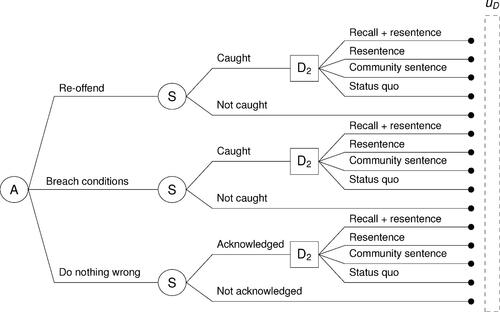
Figure 3: Decision tree for the Parole Board if .
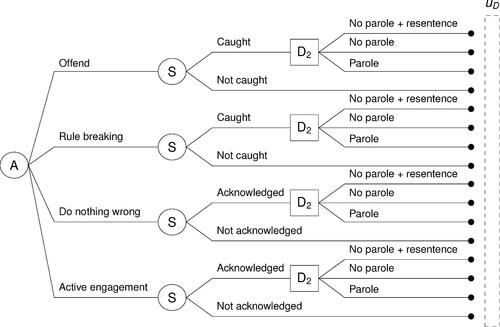
We have simplified the possible actions and outcomes for the purpose of effectively illustrating how ARA can be applied. However, in practice, these sets can be made realistic to include all possible actions and outcomes, as deemed appropriate. Nevertheless, while simplified, these sets were defined based on input from the members of the New Zealand Parole Board and thus represent an approximation of reality.
3.2 Eliciting Probabilities
As described in Section 2.2.2, the Parole Board will need to elicit the following two probabilities to find their optimal solution: and
. They could elicit
subjectively, taking into account the information available about the convict under consideration for parole, or they could elicit it using historical data that may be available. They may also want to consider the use of technology or monitoring tools that could aid in eliciting the probability. However, in general, eliciting this probability may be relatively easier since the possible outcome, at least in part, depends upon the monitoring that is put in place, and the Parole Board would know how effective the prescribed monitoring is likely to be.
Eliciting is relatively less straightforward. This is because it involves trying to guess how the convict under consideration may think and act and what their preferences may be. The Parole Board could elicit this probability in multiple different ways too. They could either use historical information on similar offenders (e.g., by looking at the proportion of similar offenders who have been caught after choosing to re-offend while out on parole), or they could choose to elicit it subjectively by taking into account the information available about the convict under consideration. Alternatively, they could also elicit this probability assuming that the convict is strategic and would choose an action they consider best for them (maximizing their expected utility) after taking into account their preferences and uncertainties. Therefore,
can be elicited this way by following the steps detailed in Section 2.2.3. To do this, the Parole Board may choose to express the convict’s game using decision trees, just like they did for themselves. Again, in this case, the convict’s decision-making process can be expressed using two decision trees, shown in and , one when the Parole Board decides to grant them parole (
) and the other when it does not (
).
Figure 4: Decision tree for the convict if .
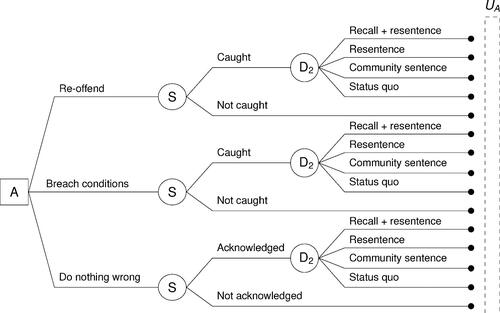
Figure 5: Decision tree for the convict if .
4 Case Study Analysis using ARA
To illustrate how ARA can be applied to a given case under consideration by the Parole Board, we presented a hypothetical case study to two members of the New Zealand Parole Board.
Case
study:
Arno, a 33-year-old man, has already served four out of his five-year prison sentence for a serious assault. His background includes an extensive history of antisocial behavior, and he has been involved with both the youth justice and child protection systems. Incidents of family violence have been recorded in his family home, where he suffered abuse and neglect. Arno’s criminal record started in the youth court with convictions for burglary, property offenses, driving offenses, breaches of the sentence, and two convictions for assaulting females. At the age of 22, he was involved in an aggravated pharmacy robbery as the getaway car driver. Over time, he has accumulated 35 convictions, including the current one. He has faced challenges with substance abuse and has undergone treatment in the past, but he had two positive drug tests for marijuana while in custody within the last year.
Arno is associated with the XXX gang,Footnote1 although he is not a patched member, unlike some of his relatives. He has committed offenses in the past in association with known XXX members. His RoC*RoI (Risk of Conviction leading to a Return to Imprisonment) is estimated at 0.68, indicating a 68% probability of re-conviction resulting in imprisonment over the next 5 years.
Of particular concern are his two convictions for assaulting his ex-partner. They have two children together, who are currently under the custody of Arno’s parents. Arno wishes to maintain contact with his children upon his release. Presently, he is in a relationship with another woman who is on a community supervision sentence and has a history of drug use.
During Arno’s initial two years of imprisonment, there were reports of several fights and associations with gang members. As a result, he was relocated from Waikeria prison to Mangaroa in Hawkes Bay, which is closer to his home. For the past eighteen months, he has been held in a low-medium security facility. Before his first appearance before the Parole Board, he successfully completed the Medium Intensity Rehabilitation Program (MIRP), and it was recommended that he participate in the shorter program at a Dependency Treatment Unit (DTU). He has since completed the DTU program with satisfactory progress reports. Recently, Arno’s classification has been changed to that of a minimum-security convict.
Arno’s proposed release plan includes the following points:
Arno will live with his parents, with his father known to consume large quantities of alcohol. However, his mother is described as supportive of Arno.
The family home is in close proximity to one of his siblings, who is a patched XXX gang member.
Arno has been provided with some work in forestry.
While he prefers not to undertake any further programs, he is willing to do so if required.
He plans to move in with his current partner in the near future.
The victim of his current offense lives 3 hr away, and although she was threatened by him earlier in his sentence, she has not heard from him recently.
4.1 Eliciting Utilities and Probabilities
After presenting the case study to the members of the New Zealand Parole Board, we elicited their subjective utilities for all possible combinations of actions and outcomes by following the decision trees in and . To standardize the values, they were asked to score their utilities on a scale of to
, representing the least and most desirable outcomes, respectively. These utilities are listed in and .
Table 1: Parole Board’s subjective utilities when .
Table 2: Parole Board’s subjective utilities when .
We then asked the Parole Board members to elicit what they believe Arno’s utilities will be, also on a scale of to
Note that these utilities are random since the Parole Board members cannot be certain of Arno’s preferences. To introduce randomness, we assumed truncated normal distributions between
and
, with mean values being the Arno’s utilities elicited by the Parole Board members, and a standard deviation of 0.5. This standard deviation was chosen because the board members felt that Arno’s true utilities will be mostly (interpreted as
of the times) within
of the elicited values. These elicited mean utilities for Arno are listed in and .
Table 3: Parole Board’s subjective utilities for Arno when .
Table 4: Parole Board’s subjective utilities for Arno when .
The board members were also able to elicit their subjective probabilities for all possible combinations of actions, which are listed in and .
Table 5: Parole Board’s subjective probabilities ).
Table 6: Parole Board’s subjective probabilities .)
Additionally, they provided their beliefs about the random probabilities and
for Arno, which are listed in . Once elicited, Arno’s random probabilities
were modeled using Beta distributions. Similarly, his random probabilities
were modeled using Dirichlet distributions.
Table 7: Parole Board’s subjective probabilities for Arno .
Table 8: Parole Board’s subjective probabilities for Arno .
Table 9: Parole Board’s subjective probabilities for Arno .
Table 10: Parole Board’s subjective probabilities for Arno .
4.2 ARA Solution for the Parole Board
The Parole Board is interested in determining their optimal decision given all the utilities and probabilities elicited for this particular case. In other words, with all the available information, should they grant Arno parole or not? To find
, we need to solve (1)–(4) step-by-step. However, to solve (3), we must first find
by modeling Arno’s strategic thinking using (5)–(8). The latter set of equations is solved using a Monte-Carlo approach. We simulate the random probabilities from the corresponding Beta and Dirichlet distributions and the random utilities from the corresponding Normal distributions a large number of times (in our case, 1000 times) to approximate
.
An underlying assumption in finding this solution is that Arno is a boundedly rational person and will choose an action that maximizes his expected utility. As such, McCarthy and Chaudhary (Citation2014) consider that his preferences are influenced by the expected benefit from an outcome, relative to the cost of that action. These preferences, in turn, are affected by his attitude toward risk, as well as the uncertainty related to the outcome. All the information on Arno that the Parole Board will have access to will enable them to build a picture of the kind of person Arno might be and, therefore, infer his attitudes toward risk and uncertainty, as well as the utility he will derive from a certain outcome.
We first approximate and find the optimal decision
, that is, the utilities and probabilities elicited above for Case 1 (our base case) in Section 4.3.1. Then, to illustrate how the optimal ARA solution will change if the Parole Board’s belief about Arno’s risk perception were different, we consider Case 2 and Case 3 in Sections 4.3.2 and 4.3.3, respectively. To illustrate how the optimal ARA solution will change if the Parole Board’s own preferences were to change, we consider Case 4 in Section 4.3.4.
4.3 ARA Solutions
4.3.1 Case 1 (Base Case)
This is our base case, where the Parole Board’s preferences and beliefs, and their beliefs about Arno’s preferences and beliefs, are as given in . To solve the problem for the Parole Board, we first find —the Parole Board’s best guess of what Arno is likely to do when given parole or otherwise—by modeling Arno’s strategic thinking using (5)–(8). Then, we find their expected utilities
using (1) and (2). Both of these quantities are listed in . Finally, the Parole Board’s expected utility
found using (3), comes to be
if parole was granted and
, otherwise. Thus, the decision that will maximize the Parole Board’s expected utility, in this case, is to not grant parole. However, it is a difficult choice since the expected utilities for both choices are not too different.
Table 11: Parole Board’s probabilities and utilities
for Case 1.
4.3.2 Case 2: Timid (risk-averse) Arno
We now consider a case where the Parole Board believes that Arno would think that he is more likely to get caught when he breaches his bail conditions. Here, we change to be 0.6 and
to be 0.4. All other elements of Case 1 remain unchanged. In this case, the Parole Board’s best guess of what Arno is likely to do
and their expected utilities
are summarized in . Here, the Parole Board’s expected utility
comes to be
if parole was granted and
, otherwise. Thus, the decision that will maximize the Parole Board’s expected utility in this case is to grant parole.
Table 12: Parole Board’s probabilities and utilities
for Case 2.
It can be seen that here only the probabilities related to when parole was granted changed and, as a result, the expected utility for when parole was granted also changed. There was no change in other values compared to Case 1 (barring minor variations due to Monte Carlo simulations).
4.3.3 Case 3: Confident (Risk-Seeking) Arno
We now consider a case where the Parole Board believes that Arno would be very confident that he could re-offend or breach his parole conditions and not get caught. To reflect this belief, we change to be 0.05 and
to be 0.95. Additionally, we change
to be 0.05 and
to be 0.95. All other elements of Case 1 remain unchanged. In this case, the Parole Board’s best guess of what Arno is likely to do when given parole or otherwise and their expected utilities are summarized in . Here, the Parole Board’s expected utility
comes to be
if parole was granted and
, otherwise. Thus, the decision that will maximize the Parole Board’s expected utility, in this case, is to not grant parole.
Table 13: Parole Board’s probabilities and utilities
for Case 3.
Again, note that only the probabilities related to when parole was granted changed and, as a result, the expected utility for when parole was granted also changed. shows that the Parole Board will reach a conclusion that, in this case, Arno is very likely to either re-offend or breach his conditions if given parole (as expected, given Arno’s believed risk preference).
4.3.4 Case 4: Different Preferences for the Parole Board Members
It is interesting to note that most of the utility values elicited from the two members of the New Zealand Parole Board in and are negative. This is not entirely unreasonable since, even an offender who is not granted parole and chooses to spend their time without offending or rule-breaking within the prison, is still a cost both to the society as well as the public coffers. However, it is known that members of the same Parole Board may not be consistent and may view outcomes differently based on their professional or personal background, as well as biases (Ruhland Citation2020). To examine whether the ARA solution will be sensitive to the utilities of the Parole Board members, we change the utility values as shown in and . The main differences in the utilities reflect that the board members associate a more positive utility for good compliance and also a more negative utility where the system fails to acknowledge such positive behavior from the offender. The other changes in the utility values are minor and reflect the natural variation one would expect to see when the values are elicited by different people who still share similar values/beliefs.
Table 14: Parole Board’s subjective utilities when - Modified
Table 15: Parole Board’s subjective utilities when - Modified
In this case, since we have not changed beliefs about Arno’s probabilities, does not change from Case 1, as it can be seen in —except for minor variation due to Monte-Carlo sampling. However, the Parole Board’s expected utilities
, change with significantly positive expected utilities for the offender’s positive behavior, such as Do nothing wrong or Active engagement.
Table 16: Parole Board’s probabilities and utilities
for Case 4
As a result, the Parole Board’s expected utility comes to be
if parole was granted and 2.52, otherwise. Thus, the decision that will maximize the Parole Board’s expected utility, in this case, is to not grant parole.
5 Summary and Further Work
In this article, we have modeled the Parole Board decision-making problem using ARA as a defend-attack-defend game. The main novelty is that we elicited the required utilities and probabilities by interviewing real decision-makers: two sitting members of the New Zealand Parole Board. For a realistic case study, we found the optimal ARA decision (whether to grant parole or not) by conducting interviews with these members and using Monte Carlo simulations. Additionally, we explored how this decision would change if some of the inputs/assumptions made by the Parole Board members were to change, particularly regarding the perceived risk behavior of the offender and how they value each of the possible outcomes.
The Parole Board members we interviewed commented that ARA closely resembles how they aim to think. They reported that the ARA decisions for each of the cases considered were consistent with the decisions they would arrive at in each case. However, they also identified that the entire process of eliciting and deriving ARA solutions would not be feasible during their day-to-day operations due to the time and expertise it demanded.
Thus, this study provides validation that ARA can closely imitate a decision-maker’s thinking and produce solutions that are consistent with an experienced decision-maker’s own decisions. Indeed, ARA has the potential to significantly enhance existing Parole Board decision support tools, such as the SPDMF discussed in Section 2, by providing case-specific decision-making support. However, this work also highlights the key challenges in implementing ARA, namely, the time and expertise required for the elicitation of numerous utilities and probabilities and for deriving the ARA solutions.
Implementing ARA requires the decision-maker to provide two key inputs: their own probabilities and utilities, as well as those of the opponent. It is well-documented that eliciting expert probabilities can be very challenging (see, e.g., Falconer et al. Citation2022). Additionally, there is an issue concerning the decision maker’s biases and how they might influence the elicited probabilities (Montibeller and von Winterfeldt Citation2015, 2018).
Eliciting utility functions, especially multi-attribute utilities, is a complex and time-consuming process that demands a high level of expertise (see e.g., González-Ortega, Radovic, and Ríos Insua Citation2018; Morton Citation2018). However, recent research on easy-to-use online tools for eliciting personal utility shows promise (Schneider et al. Citation2022), and such approaches could potentially be employed for applications like Parole Board decision-making.
One way to reduce the burden of elicitation is to estimate using predictive models of recidivism. Several such models have been proposed; see Tollenaar and van der Heijden (Citation2023) for a recent comparison of these approaches. Another potential solution to elicit expert probabilities while avoiding some biases was recently proposed by Falconer et al. (2023). Instead of direct elicitation, this approach infers the expert priors from the expert’s past decision-making and is well-suited for repetitive decision-making tasks like those in the Parole Board context.
Even when the required probabilities and utilities can be obtained practically, there is still a need to develop an easy-to-use decision-making tool that can perform the ARA analysis for practitioners. The foundational elements of such a tool have already been discussed (González-Ortega, Insua, and Cano Citation2019). However, it is only with the availability of such a tool that the full potential of ARA can be truly harnessed.
Note
Acknowledgments
The authors would like to thank the New Zealand Parole Board for their participation in this study. This research was partially conducted when the first and the second authors were based at the University of Waikato, and completed while the third author was visiting the first author at the University of Auckland. We thank the University of Waikato for providing travel funding to conduct the case study.
Disclosure Statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
1 A well-known NZ gang—the actual gang name has been withheld for publication.
References
- Banks, D. L., Rios, J., and Ríos Insua, D. (2015), Adversarial Risk Analysis, Boca Raton, FL: CRC Press.
- Brown, G., Carlyle, M., Salmerón, J., and Wood, K. (2006), “Defending Critical Infrastructure,” Interfaces, 36, 530–544. DOI: 10.1287/inte.1060.0252.
- Buglar, S. (2016), “The ‘Focal Concerns’ of Parole Board Decision-Making: A Thematic Analysis,” Current Issues in Criminal Justice, 27, 285–302. DOI: 10.1080/10345329.2016.12036047.
- Canada, P. (2019), Decision-Making Policy Manual for Board Members (2nd ed.), Parole Board of Canada.
- Cano, J., Pollini, A., Falciani, L., and Turhan, U. (2016a), “Modeling Current and Emerging Threats in the Airport Domain through Adversarial Risk Analysis,” Journal of Risk Research, 19, 894–912. DOI: 10.1080/13669877.2015.1057201.
- Cano, J., Ríos Insua, D., Tedeschi, A., and Turhan, U. (2016b), “Security Economics: An Adversarial Risk Analysis Aproach to Airport Protection,” Annals of Operations Research, 245, 359–378. DOI: 10.1007/s10479-014-1690-7.
- Caplan, J. (2007), “What Factors Affect Parole: A Review of Empirical Research,” Federal Probation, 71, 16–19.
- Ejaz, M., Joe, S., and Joshi, C. (2021), “Adversarial Risk Analysis for Auctions Using Mirror Equilibrium and Bayes Nash Equilibrium,” Decision Analysis, 18, 185–202. DOI: 10.1287/deca.2021.0425.
- Ejaz, M., Joshi, C., and Joe, S. (2021), “Adversarial Risk Analysis for First-Price Sealed-Bid Auctions,” Australian and New Zealand Journal of Statistics, 63, 357–376. DOI: 10.1111/anzs.12315.
- ———(2022), “Adversarial Risk Analysis for Auctions Using Non-strategic Play and Level-k Thinking: A General Case of n Bidders with Regret,” Communications in Statistics - Theory and Methods, 52, 7146–7164. DOI: 10.1080/03610926.2022.2042023.
- Esteban, P. G., and Ríos Insua, D. (2014), “Supporting an Autonomous Social Agent Within a Competitive Environment,” Cybernetics and Systems, 45, 241–253. DOI: 10.1080/01969722.2014.894852.
- Factsheet. (2018), “Percentage of Sentences Served,” Ministry of Justice, New Zealand Government. Available at https://www.justice.govt.nz/assets/Factsheet-Percentage-of-sentence-served.pdf.
- Falconer, J. R., Frank, E., Polaschek, D. L. L., and Joshi, C. (2022), “Methods for Eliciting Informative Prior Distributions: A Critical Review,” Decision Analysis, 19, 189–204. DOI: 10.1287/deca.2022.0451.
- ———(2023), “On Eliciting Expert Prior Distributions by Modelling Past Decision-Making,” Decision Analysis. DOI: 10.1287/deca.2023.0046.
- Gil, C., Ríos Insua, D., and Rios, J. (2016), “Adversarial Risk Analysis for Urban Security Resource Allocation,” Risk Analysis, 36, 727–741. DOI: 10.1111/risa.12580.
- Gobeil, R., and Serin, R. C. (2009), “Preliminary Evidence of Adaptive Decision Making Techniques Used by Parole Board Members,” International Journal of Forensic Mental Health, 8, 97–104. DOI: 10.1080/14999010903199258.
- ———(2010), Parole Decision Making, Cambridge Handbooks in Psychology, pp. 251–258, Cambridge: Cambridge University Press. DOI: 10.1017/CBO9780511730290.032.
- González-Ortega, J., Radovic, V., and Ríos Insua, D. (2018), Utility Elicitation, Cham: Springer.
- González-Ortega, J., Insua, D. R., and Cano, J. (2019), “Adversarial Risk Analysis for Bi-agent Influence Diagrams: An Algorithmic Approach,” European Journal of Operational Research, 273. 1085–1096. DOI: 10.1016/j.ejor.2018.09.015.
- Joshi, C., Aliaga, J. R., and Insua, D. R. (2020), “Insider Threat Modeling: An Adversarial Risk Analysis Approach,” IEEE Transactions on Information Forensics and Security, 16, 1131–1142. DOI: 10.1109/TIFS.2020.3029898.
- McCarthy, B., and Chaudhary, A. (2014), Rational Choice Theory, pp. 4307–4315. New York: Springer.
- Montibeller, G., and von Winterfeldt, D. (2015), “Cognitive and Motivational Biases in Decision and Risk Analysis,” Risk Analysis, 35, 1230–1251. DOI: 10.1111/risa.12360.
- ———(2018), Individual and Group Biases in Value and Uncertainty Judgments, pp. 377–392, Cham: Springer.
- Morton, A. (2018), Multiattribute Value Elicitation, pp. 287–311, Cham: Springer.
- Naveiro, R., Redondo, A., Ríos Insua, D., and Ruggeri, F. (2019), “Adversarial Classification: An Adversarial Risk Analysis Approach,” International Journal of Approximate Reasoning, 113, 133–148. DOI: 10.1016/j.ijar.2019.07.003.
- Parnell, G. S., Smith, C. M., and Moxley, F. I. (2010), “Intelligent Adversary Risk Analysis: A Bioterrorism Risk Management Model,” Risk Analysis, 30, 32–48. DOI: 10.1111/j.1539-6924.2009.01319.x.
- Polaschek, D. L. L., and Yesberg, J. A. (2018), “High-Risk Violent Prisoners’ Patterns of Change on Parole on the Draor’s Dynamic Risk and Protective Factors,” Criminal Justice and Behavior, 45, 340–363. DOI: 10.1177/0093854817739928.
- Polaschek, D. L. L., Yesberg, J. A., and Chauhan, P. (2018), “A Year Without a Conviction: An Integrated Examination of Potential Mechanisms for Successful Reentry in High-Risk Violent Prisoners,” Criminal Justice and Behavior, 45, 425–446. DOI: 10.1177/0093854817752757.
- Rios, J., Ríos Insua, D. (2012), “Adversarial Risk Analysis for Counter-Terrorism Modeling,” Risk Analysis, 32, 894–915. DOI: 10.1111/j.1539-6924.2011.01713.x.
- Ríos Insua, D., Rios, J., and Banks, D. (2009), “Adversarial Risk Analysis,” Journal of the American Statistical Association, 104, 841–854. DOI: 10.1198/jasa.2009.0155.
- Rios Insua, D., Banks, D., and Rios, J. (2016), “Modeling Opponents in Adversarial Risk Analysis,” Risk Analysis, 36, 742–755. DOI: 10.1111/risa.12439.
- Rios Insua, D., Couce-Vieira, A., Rubio, J. A., Pieters, W., Labunets, K., and Rasines, D. G. (2021), “An Adversarial Risk Analysis Framework for Cybersecurity,” Risk Analysis, 41, 16–36. DOI: 10.1111/risa.13331.
- Roberts, J. (2009), “Listening to the Crime Victim: Evaluating Victim Input at Sentencing and Parole,” Crime and Justice, 38, 347–412. DOI: 10.1086/599203.
- Roponen, J., Ríos Insua, D., Salo, A. (2020), “Adversarial Risk Analysis Under Partial Information,” European Journal of Operational Research, 287, 306–316. DOI: 10.1016/j.ejor.2020.04.037.
- Ruhland, E. L. (2020), “Philosophies and Decision Making in Parole Board Members,” The Prison Journal, 100, 640–661. DOI: 10.1177/0032885520956566.
- Schneider, P., van Hout, B., Heisen, M., Brazier, J., Devlin, N. (2022), “The Online Elicitation of Personal Utility Functions (OPUF) Tool: A New Method for Valuing Health States,” Wellcome Open Research, 7, 14. DOI: 10.12688/wellcomeopenres.17518.1.
- Serin, R., Gobeil, R., Lloyd, C., Chadwick, N., Wardrop, K., and Hanby, L. (2016), “Using Dynamic Risk to Enhance Conditional Release Decisions in Prisoners to Improve their Outcomes,” Behavioral Sciences & the Law, 34, 321–336. DOI: 10.1002/bsl.2213.
- Serin, R. C., and Gobeil, R. (2014), “Analysis of the Use of the Structured Decision Making Framework in Three States,” US Department of Justice, National Institute of Corrections.
- Sevillano, J. C., Ríos Insua, D., and Rios, J. (2012), “Adversarial Risk Analysis: The Somali Pirates Case,” Decision Analysis, 9, 86–95. DOI: 10.1287/deca.1110.0225.
- Shachter, R. D. (1986), “Evaluating Influence Diagrams,” Operations Research, 34, 871–882. DOI: 10.1287/opre.34.6.871.
- Tollenaar, N., and van der Heijden, P. G. M. (2023), “Which Method Predicts Recidivism Best?: A Comparison of Statistical, Machine Learning and Data Mining Predictive Models,” Journal of the Royal Statistical Society, Series A, 176, 565–584. DOI: 10.1111/j.1467-985X.2012.01056.x.
- Vîlcicč, E. “Revisiting parole decision making: testing for the punitive hypothesis in a large U.S. jurisdiction,” International Journal of Offender Therapy and Comparative Criminology, 62, 1357–1383.
- Wang, S., and Banks, D. (2011), “Network Routing for Insurgency: An Adversarial Risk Analysis Framework,” Naval Research Logistics (NRL), 58, 595–607. DOI: 10.1002/nav.20469.