
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Distance covariance (Székely et al. 2007) is a fascinating recent notion, which is popular as a test for dependence of any type between random variables X and Y. This approach deserves to be touched upon in modern courses on mathematical statistics. It makes use of distances of the type and
, where
is an independent copy of
. This raises natural questions about independence of variables like
and
, about the connection between
and the covariance between doubly centered distances, and about necessary and sufficient conditions for independence. We show some basic results and present a new and nontechnical counterexample to a common fallacy, which provides more insight. We also show some motivating examples involving bivariate distributions and contingency tables, which can be used as didactic material for introducing distance correlation.
Disclaimer
As a service to authors and researchers we are providing this version of an accepted manuscript (AM). Copyediting, typesetting, and review of the resulting proofs will be undertaken on this manuscript before final publication of the Version of Record (VoR). During production and pre-press, errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal relate to these versions also.1 Introduction
Independence of random variables is an important and nontrivial topic in probability and statistics. There are many subtleties concerning independence and correlation, see e.g. Mukhopadhyay (2022), Rodgers and Nicewander (1988), and Rousseeuw and Molenberghs (1994). It is often emphasized in class that two real random variables X and Y having zero covariance does not imply their independence. The recent work of Székely et al. (2007) provided a surprising contrast, since the distance covariance they introduced does characterize independence. In our opinion this topic would be a valuable addition to a graduate course on mathematical statistics, because distance covariance is a general method with interesting properties and wide ranging applications, for instance in variable selection (Chen et al. 2018), sparse contingency tables (Zhang 2019), independent component analysis (Matteson and Tsay 2017), and time series (Davis et al. 2018). It can be computed fast (Huo and Székely 2016; Chaudhuri and Hu 2019), and there are interesting connections with other dependence measures (Edelmann and Goeman 2022). Its robustness to outliers was studied recently (Leyder et al. 2024).
The formulation of the distance covariance, described in Section 3, is very simple but contains some subtleties that often give rise to misunderstandings. It is based on pairwise differences and
, where
is an independent copy of
. In order to provide a context for the role of these pairwise differences, we establish some connections between independence of X and Y and independence relations involving
and
. We have not found these results in the literature, and we believe they could provide a pedagogic background.
We also construct an elementary counterexample to a common misunderstanding, with the aim of clarifying why the distance covariance approach requires “double centering” of the interpoint distances and
.
Most of the material in this paper is accessible to students who took an introductory course in probability and statistics. Only the statements of Proposition 1(b) and Proposition 2(c) and the proofs in the Appendix require knowledge of characteristic functions, but this is not needed to follow the examples.
2 Some results on pairwise differences
Let us denote independence of a pair of real random variables as . We start by looking at pairwise differences of only one of the variables, say X. We consider an independent copy
of X, that is,
and
. Then the following implications hold.
Proposition 1 .
For a pair of random variables it holds that
(a) implies
.
(b) If the characteristic function of X has no roots or only isolated roots, or the
characteristic function of is analytic, then
implies
.
The proof can be found in the Appendix. Part (a) is general, as it does not require any conditions on X or Y, such as the existence of certain moments. Part (b) is a bit more involved. We have been unable to find this proposition in the literature, but since part (a) is straightforward we expect that it is known.
The conditions on the characteristic functions in part (b) of Proposition 1 look quite stringent, but there are many relevant cases. The characteristic functions of the Gaussian, Student, exponential, Poisson, chi-square, Gamma, Laplace, logistic, Cauchy, and stable distributions have no roots. Distributions whose characteristic functions have non-isolated zeroes are unusual, but some examples do exist, see e.g. Ushakov (1999), page 265. The alternative condition that is analytic is satisfied whenever X and Y are bounded, see e.g. Berezin (2016), page 147.
Next we consider pairwise differences of both X and Y. For this we take an independent copy of
, that is,
and
.
Proposition 2 .
For a pair of random variables it holds that
(a) implies
.
(b) and
together imply
.
(c) If is symmetric and its characteristic function has no roots or is analytic,
implies
.
We could not find these results in the literature either, and in our opinion they could provide a useful background when the notion of distance covariance is taught. Also, parts (a) of Propositions 1 and 2 could be used as exercises in a chapter on characteristic functions. Together with the partial converses in these propositions they would make a viable homework assignment, as long as the exact statements of the propositions are provided, and perhaps also those of the lemmas in the Appendix.
It is worth noting that the converse of part (a) of Proposition 2 does not hold without further conditions, because there exists a nontrivial counterexample (Gabor Székely 2024, personal communication). Therefore also the converse of Proposition 1(a) cannot hold without further conditions, or else we could prove the converse of Proposition 2(a) by applying the converse of Proposition 1(a) twice.
3 Connection with distance covariance
If we obtain from Proposition 2(a) that
. But then it follows that also
, since the absolute value is a continuous function. If X and Y have second moments, that is,
and
are finite, also
and
are finite. Therefore the covariance of
and
exists as well, and since
we have
(1)
(1)
Therefore, when the second moments of X and Y exist, is a necessary condition for
. However, it is not a sufficient condition. In order to illustrate this, we set out to construct a simple counterexample.
Example 1. The smallest example we were able to produce is a probability distribution on 4 points in the plane. Table 1 lists the coordinates of , and the 4 points are plotted in the top panel of Figure 1. Note that X and Y are uncorrelated but not independent, since the distribution of
depends on x. The
regression line is horizontal. The resulting distribution of
contains 5 points, given in the middle panel of Table 1 with their probabilities, and plotted in the bottom left panel of Figure 1. It is easily verified that
is exactly zero. So this is an example with non-independent X and Y for which
Székely et al. (2007) proposed to use another function. Instead of the interpoint distances above, they compute their doubly centered version given by
(2)
(2)
where and
are also independent copies of X. For
to exist it is necessary that
is finite. Note that
is not a distance itself, since it also takes on negative values. Moreover,
is zero, and the same holds for
and
. This explains the name ‘doubly centered’. It turns out that the second moments of
exist as well.
If also is finite, Székely et al. (2007) compute what they call the distance covariance of X and Y, given by
(3)
(3)
(In fact they took the square root of the right hand side, but we prefer not to because the units of (3) are those of X times Y.) They proved the amazing result that when the first moments of X and Y exist, it holds that(4)
(4)
This yields a necessary and sufficient condition for independence. The implication is not obvious at all, and was proved by complex analysis. Their work also made it clear that always
because they can write
as an integral of a nonnegative function.
The bottom panel of Table 1 lists the coordinates of the and their probabilities, and these points are plotted in the bottom right panel of Figure 1. Note that we now have 7 points instead of 5. Indeed, the atom
of
has split into three atoms of
. Even though all four pairs have the same
, they can obtain different
because different means were subtracted from their
and
. This implies that the doubly centered distance
cannot be written as a function of
.
In spite of the name ‘distance covariance’, dCov is thus fundamentally different from the covariance of distances in (1). As we just saw, dCov is not a function of the pairwise differences and
alone: to compute
we need to know the actual values of x and
. So the arrow
in (4) is not an immediate consequence of
or even of the fact that
, instead it is truly derived from
. (If
were a function of
it would follow from
that
and hence
, which we know is not true in general.)
In the example we obtain exactly , which confirms the dependence of X and Y. The example thus illustrates that the double centering in
is necessary to characterize independence, since without it we obtained
which provided no clue about the dependence of X and Y.
The regression line in the bottom right panel of Figure 1 is not horizontal but goes up. Its slope must be positive or zero because it is a positive multiple of , which we know is always nonnegative. The regression line also has to pass through the origin
, because the doubly centered distances of X as well as Y have zero mean, so the average of the points in this plot is the origin. In this tiny example the regression line also happens to pass through one of the points in the plot, but that is a coincidence. The line does not have to pass through any point, as can be verified by e.g. changing the first x-coordinate of the original data from -1.0 to -1.5 .
Székely et al. (2007) also derived a different expression for dCov. Working out the covariance in (3) yields terms, that exist when X and Y also have second moments. With elementary manipulations and a lot of patience these terms can be reduced to three:
Combining the first term on the right with minus the second, and the third with twice the second, Székely and Rizzo (2023) obtain
which connects dCov with the covariance of distances in (1). Since we have seen that implies that
, the only way that X and Y can be independent is when both terms on the right hand side are zero. In the example
but X and Y are dependent, so the second term has to be nonzero, and indeed
.
4 Distance correlation and finite samples
Since the units of are those of X times Y, and
, one often uses the unitless distance correlation defined as
(5)
(5)
which always lies between 0 and 1. Note that the conventional definition is the square root of (5).
So far we have worked with population distributions, but dCov and dCor can also be used for finite samples. One can simply apply them to the empirical distribution of the sample. In particular, for a univariate sample we denote
for
as well as
(6)
(6)
Double centering yields the values
so that for all i and
for all j. The dCov of a bivariate sample is then defined as
(7)
(7)
The dCor of a bivariate sample is analogous to (5). When based on an i.i.d. sample of size n from a pair of random variables with first moments, the finite-sample
converges almost surely to
when
(Székely et al. 2007).
5 Examples
The material in this section and the next one can be used as exercises for students, in a lab session or a homework assignment.
Example 2. The distance covariance can be applied to contingency tables. For instance, contingency tables can be modeled by Bernoulli variables X and Y, that can only take on the values 0 and 1. We denote their joint probability as
and the marginal probabilities as
and
. It can be verified that
(8)
(8)
Therefore iff
for all
, which is equivalent to
. Note that (8) is similar to Pearson’s chi-square statistic, but not identical. If we divide the chi-square statistic by the sample size, and let the sample size grow, it converges to the population version
which is not equivalent to (8). It is not too difficult to derive that(9)
(9)
Now it is easy to see that implies that (9) becomes zero. But it is not true the other way around. A counterexample is given by
. This zeroes
, but X and Y are not independent and
is strictly positive. (Unlike Example 1 in Table 1, here the plain
is not zero.)
Example 3. The main advantage of dCor over the usual product-moment correlation Cor is that from it follows that
. Most introductory statistics books stress that this does not hold for Cor. A typical illustrative example is to take a univariate variable X with a distribution that has a second moment and is symmetric about zero, and to put
. (If a bivariate density is desired, one can add a Gaussian error term to Y.) Let us take the simple case where X follows the uniform distribution on
. Clearly X and Y are dependent, but by symmetry
. However, we will see that
is strictly positive.
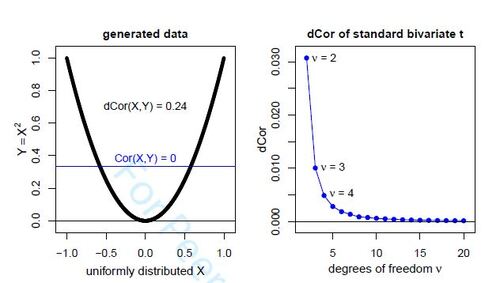
The computation of offers an opportunity for carrying out a simple numerical experiment. First we have to generate a sample of size n from this bivariate distribution. This is easy, for instance in R we can run X = runif(n,min=-1,max = 1) followed by Y = X^2 . This yields the left panel of Figure 2, in which the horizontal regression line illustrates that the classical correlation
is zero. To compute the sample distance correlation we can use the R package energy (Rizzo and Székely 2022) or the package dccpp (Berrisch 2023). In the first case we run energy::dcor2d(X,Y) which uses the algorithm of Huo and Székely (2016), and in the second case the command is dccpp::dcor(X,Y)^2 which carries out the algorithm of Chaudhuri and Hu (2019). Both algorithms for dCor are very fast as their computation time is only
, and they do not store the
matrices of all
and
. When we let n grow, the answer quickly converges to approximately
. The result stabilizes even faster if we use an equispaced set X = seq(from=-1,to = 1,by = 2/(n-1)), so the computation becomes a crude numerical integration.
Example 4. In the previous example the left panel of Figure 2 immediately reveals the dependence, because the conditional expectation depends on x. But there are more subtle situations, where for instance the conditional expectation is constant but some other moment is not. A nice example is the bivariate t-distribution. When its center is
and its scatter matrix is the identity matrix, it is called the standard bivariate t-distribution with density
(10)
(10)
where is the degrees of freedom parameter. The marginal distribution of Y is the usual univariate t-distribution with center 0 given by
(11)
(11)
where is the constant needed to make the density integrate to 1, and the scale parameter s equals 1 here. In general
when
. A plot of the bivariate density (10) looks a lot like that of the standard bivariate Gaussian distribution, with circular symmetry. When
the correlation
exists and is zero. But whereas X and Y are independent in the standard Gaussian setting, they are no longer here, since the bivariate density (10) does not equal the product of the marginal densities of X and Y. The conditional density of Y given
is now
(12)
(12)
(Ding 2016), so it is again a univariate t with center 0, but now with degrees of freedom and a scale parameter that depends on x. Due to the increased degrees of freedom, the conditional expectation already exists for
and equals zero, so it is constant. The conditional variance exists for any
and equals
. It is thus lowest for
and increases with
.
We now study the distance correlation of these dependent but uncorrelated variables X and Y. An analytic derivation of may not be possible, but in R we can easily generate data from the standard bivariate t-distribution by rmvt(n,df = df) where df is the degrees of freedom
. The function rmvt is in the R package mvtnorm (Genz et al. 2023). We can then compute the distance correlation in exactly the same way as in Example 3 above. Figure 2 shows the resulting estimates of
obtained for
100 000 and
ranging from 2 to 20, a computation that took under one minute. The distance correlation goes down to zero for increasing
, which is understandable because for
the standard bivariate t-distribution converges to the standard Gaussian distribution, where X and Y are indeed independent.
6 Testing for independence
Now suppose we have an i.i.d. sample from a bivariate random variable
, and we want to test the null hypothesis
that X and Y are independent. If we know that
is bivariate Gaussian,
is equivalent to the true parameter
being zero, where
is the unknown covariance matrix of
. In that particular situation
can be tested by computing the sample correlation coefficient of
and comparing it to its null distribution for that sample size.
However, in general we do not know whether data come from a Gaussian distribution, and the bivariate point cloud may have a different shape. We have illustrated in Examples 1, 3, and 4 that dependent variables can be uncorrelated, so a test of would not suffice anyway. What we need is a distribution-free independence test, meaning that it works for any distribution of
. Since we know that
is characterized by
, a natural idea is to compute the test statistic
from the sample. Larger values of
provide more evidence against
than smaller values, but how can we compute the p-value when we do not know the kind of distribution that
has?
Since all we have is the dataset , this is what we must use. Whatever the distribution of
, a random permutation of
will be independent of
. More formally, if we draw a permutation
from the uniform distribution on all
permutations on
, we have
. If n is very small we can use all possible permutations
, and otherwise we can draw many of them, say
permutations
. We can then estimate the p-value by counting how often
with the permuted
is larger than the observed
:
The stems from the fact that the original
corresponds to the identical permutation
and is independent of
under
, and has the advantage that
cannot become exactly zero, which would be unrealistic.
The permutation test is simple, and it is fast due to the fast algorithms for dCov. Note that it would make no difference if we would replace dCov by dCor, since the denominator of dCor is constant, so it is easiest to stick with dCov. Also, it does not matter whether we square dCov or not. More information about testing independence can be found in (Székely and Rizzo 2023). A potential exercise for students would be to generate samples from the bivariate distributions in Example 3 or 4 of Section 5 and compute
for different sample sizes. In that setting they can also estimate the power of the permutation test for a fixed level, for instance by rejecting
when
, using simulation.
Supplementary Material. This is an R script that reproduces the examples.
A. Appendix with proofs
In order to prove Proposition 1, it turns out that the following lemma is very helpful.
Lemma 1 .
If is a pair of random variables and we construct an independent copy
of X, that is,
and
, then
is equivalent to the condition
(13)
Proof of Lemma 1.
For the direction we compute the characteristic functions
On the subset both left hand sides equal
so
(14)
(14)
Since is Hermitian its set of roots is symmetric, so we have that
and in that case
cancels in (14), yielding (13).
For the direction we compute
In this equality we can replace by
whenever
, so then
(15)
(15)
But this also holds when because then
. Therefore (15) holds unconditionally, hence
. ▪
Proof of Proposition 1.
For (a) we use the fact that implies
for any t and v, which is stronger than condition (13) in Lemma 1, hence
.
For (b) we also start from condition (13) in Lemma 1. If the characteristic function of X has no roots we always have so
(16)
(16)
hence .
Suppose that does have roots but they are isolated, implying that the non-roots form a dense set. That is, any root t is the limit of a sequence of non-roots
for
. In each
we have
by condition (13). Since characteristic functions are absolutely continuous we can pass to the limit, again yielding (16).
If we assume nothing about roots but is analytic, so are
and
. All characteristic functions take the value 1 at the origin, and are absolutely continuous. Therefore there is a
such that for all
in the disk
it holds that
as well as
and
are nonzero. On that disk we can thus divide by
in (14), hence
holds on it. Since
and
are analytic, so is their product. By analytic continuation (16) holds, so again
. ▪
We now consider pairwise differences of both variables X and Y. This requires a second lemma.
Lemma 2 .
If is a pair of random variables and we construct an independent copy
of it, that is,
and
, then
is equivalent to the condition
(17)
(17)
Proof of Lemma 2.
For the direction we compute the characteristic functions
On the subset both left hand sides equal
. Therefore
For the direction we compute
hence . □
Proof of Proposition 2.
For (a) we use the fact that implies that
for any t and v, hence
which is condition (17) in Lemma 2, so
.
For (b), implies
for all t with
by Lemma 1. In the remaining points
it holds that
and then
by condition (17) of Lemma 2, so
as well. The combination yields (16), hence
.
Part (c). By symmetry of and hence of X and Y we know that
as well as
and
are real and even, hence condition (17) yields
(18)
(18)
If has no roots, it follows from
and continuity of
that always
. Therefore also
and
. Taking square roots on both sides of (18) yields (16), hence
.
If, on the other hand, is analytic, so are
and
. All characteristic functions take the value 1 at the origin, and are absolutely continuous. Therefore there is a
such that for all
in the disk
it holds that
as well as
and
are strictly positive. On that disk we can thus take square roots of (18), yielding
on it. Since
and
are analytic, so is their product. By analytic continuation the equality must hold everywhere, yielding (16) so again
. □
Table 1: Example 1: but X and Y are dependent.
Figure 1: Example with a distribution on 4 points, from . Top: plot of Y versus X. Bottom left: plot of pairwise distances of Y versus those of X. Bottom right: doubly centered distances
of Y versus those of X.
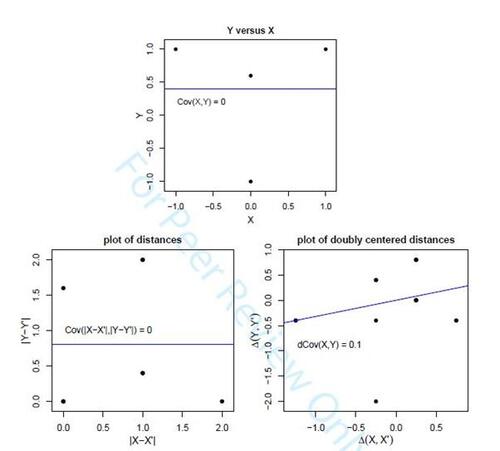
Figure 2: Left: dependent variables generated in Example 3, with horizontal regression line illustrating that X and Y are uncorrelated. Right: Plot of the distance correlation of the standard bivariate t-distribution in Example 4, for a range of .
dCov_example_script.zip
Download Zip (4.1 KB)References
- Berezin, S. V. (2016). On analytic characteristic functions and processes governed by SDEs. Physics and Mathematics 2, 144–149.
- Berrisch, J. (2023). dccpp: Fast Computation of Distance Correlations. R package version 0.1.0, CRAN.
- Chaudhuri, A. and W. Hu (2019). A fast algorithm for computing distance correlation. Computational Statistics and Data Analysis 135, 15–24.
- Chen, X., X. Chen, and H. Wang (2018). Robust feature screening for ultra-high dimensional right censored data via distance correlation. Computational Statistics & Data Analysis 119, 118–138.
- Davis, R. A., M. Matsui, T. Mikosch, and P. Wan (2018). Applications of distance correlation to time series. Bernoulli 24, 3087–3116.
- Ding, P. (2016). On the conditional distribution of the multivariate t distribution. The American Statistician 70, 293–295.
- Edelmann, D. and J. Goeman (2022). A Regression Perspective on Generalized Distance Covariance and the Hilbert-Schmidt Independence Criterion. Statistical Science 37, 562–579.
- Genz, A., F. Bretz, T. Miwa, X. Mi, F. Leish, F. Scheipl, B. Bornkamp, M. Maechler, and T. Hothorn (2023). mvtnorm: Multivariate Normal and t Distributions. R package version 1.2-4, CRAN.
- Huo, X. and G. J. Székely (2016). Fast Computing for Distance Covariance. Technometrics 58, 435–447.
- Leyder, S., J. Raymaekers, and P. J. Rousseeuw (2024). Is Distance Correlation Robust? ArXiv preprint arXiv:2403.03722.
- Matteson, D. S. and R. S. Tsay (2017). Independent component analysis via distance covariance. Journal of the American Statistical Association 112, 623–637.
- Mukhopadhyay, N. (2022). Pairwise Independence May Not Imply Independence: New Illustrations and a Generalization. The American Statistician 76, 184–187.
- Rizzo, M. and G. J. Székely (2022). energy: Multivariate Inference via the Energy of data. R package version 1.7-11, CRAN.
- Rodgers, J. L. and W. A. Nicewander (1988). Thirteen Ways to Look at the Correlation Coefficient. The American Statistician 42, 59–66.
- Rousseeuw, P. J. and G. Molenberghs (1994). The Shape of Correlation Matrices. The American Statistician 48, 276–279.
- Székely, G. J. and M. L. Rizzo (2023). The Energy of Data and Distance Correlation. Chapman & Hall.
- Székely, G. J., M. L. Rizzo, and N. K. Bakirov (2007). Measuring and testing dependence by correlation of distances. The Annals of Statistics 35, 2769–2794.
- Ushakov, N. (1999). Selected Topics in Characteristic Functions. VSP Publishers, Leiden, The Netherlands.
- Zhang, Q. (2019). Independence test for large sparse contingency tables based on distance correlation. Statistics & Probability Letters 148, 17–22.