
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The purpose of the article is to assess the in-sample fit and the out-of-sample forecasting performances of four stochastic volatility (SV) models in the Finnish housing market. The competing models are the vanilla SV, the SV model where the latent volatility follows a stationary AR(2) process, the heavy-tailed SV and the SV with leverage effects. The models are estimated using Bayesian technique, and the results reveal that the SV with leverage effects is the best model for modelling the Finnish house price volatility. The heavy-tailed SV model provides accurate out-of-sample volatility forecasts in most of the studied regions. Additionally, the models’ performances are noted to vary across almost all cities and sub-areas, and by apartment types. Moreover, the AR(2) component substantially improves the in-sample fit of the standard SV, but it is unimportant for the out-of-sample forecasting performance. The study outcomes have crucial implications, such as portfolio management and investment decision-making. To establish suitable time-series volatility forecasting models of this housing market, these study outcomes will be compared to the performances of their GARCH models counterparts.
I. Introduction
Volatility modelling and forecasting are a vital task in financial markets. As the asset volatility holds critical information; it has been recognized as the most risk measure broadly used in many areas of finance (Bollerslev, Chou, and Kroner Citation1992). In the housing market, as housing assets have a dual role of consumption and investment; understanding price volatility plays an essential role in the housing investment decision-making and the asset allocation (Milles Citation2008a). Moreover, housing is a crucial factor for the country’s economy; in particular, in Finland, Statistics Finland (Citation2016) reported that housing made up to 50.3% of the Finnish households’ total wealth. Thus, housing affects the country’s economy through wealth effects (Case, Quigley, and Shiller Citation2013) as well as through influences on many parties exposed to housing and mortgage activity. Therefore, better housing modelling and forecasting would be beneficial for consumers, mortgage market, mortgage insurance and mortgage-backed securities (Segnon et al. Citation2020). Furthermore, as pointed out by Zhou and Haurin (Citation2010), insights into house price volatility are the key input in designing housing policies. In the light of the abovementioned points, understanding the dynamics of the house price volatility is crucial for portfolio management, risk assessment and investment decision-making.
An increasing amount of studies have attempted to model and/or forecast the house price volatility of individual markets. However, the literature has mainly focussed on the use of different Generalized Autoregressive Conditional Heteroscedasticity (GARCH)-type models. Under this approach, the volatility evolution is modelled deterministically; a framework which has its roots from the Engle’s (Citation1982) and Bollerslev’s (Citation1986) groundbreaking works. Taylor (Citation1982), on the other hand, provided an alternative way; to model volatility probabilistically, meaning that volatility is treated as an unobserved component that follows a stochastic process. The specification is known as the Stochastic Volatility (SV) models. Even though SV models are theoretically attractive and there is some empirical evidence in their favour over GARCH models (Jaquier, Polson, and Rossi Citation1994; Gysels, Harvey, and Renault Citation1996; Kim et al., Citation1998; Nakajima and Omori Citation2012); they have drawn little attention among practitioners. The challenges pointed out by Bos (Citation2012) are highly non-linear estimations and lack of standard software packages implementing these methods. In response to these challenges, Chan and Grant (Citation2016b) provided the means for the Bayesian estimation of not only the vanilla SV model but also the heavy-tailed SV model and the SV model with leverage effects. Specifically, this study uses Chan and Grant (Citation2016b) approach to model and forecast the studied housing market. To the best of the author’ knowledge, in the housing markets, there has yet to be empirical modelling and forecasting using the SV framework. Hence, this is the first study that models and forecasts the Finnish housing market volatility using the SV framework in general, and incorporating both non-Gaussianity and asymmetry effects in particular.
Moreover, the emphasis of the housing market volatility modelling and/or forecasting has been on a limited number of countries such as the United States, United Kingdom, Australia and Canada. Regarding housing market volatility modelling without the forecasting aspect, the authors (to cite few) who have employed GARCH-type models to study US house prices include Dolde and Tirtiroglu (Citation1997, Citation2002), Miller and Peng (Citation2006), Milles (Citation2008b), and more recently, Apergis and Payne (Citation2020). The UK house price volatility investigation consists of the work of Willcocks (Citation2010), Tsai, Chen, and Ma (Citation2010), Milles (Citation2011b), and more recently, Begiazi and Katsiampa (Citation2019). The Australian house price volatility has been examined by Lee (Citation2009) and Lee and Reed (Citation2014b); while Hossain and Latif (Citation2009) and Lin and Fuerst (Citation2014) studied the Canadian house price volatility. For Finland, Dufitinema (Citation2020) has recently explored different aspects of the Finnish housing market volatility. Regarding the housing market volatility forecasting, the US housing market is the widely studied housing market. Beginning with the work of Crawford and Fratantoni (Citation2003), followed by Milles (Citation2008a), Li (Citation2012), more recently, Segnon et al. (Citation2020). For Finland, there has yet to be an empirical forecasting of the Finnish housing market, even though Statistics Finland (Citation2016) reported that housing made up to 50.3% of the Finnish households’ total wealth. Therefore, this article aims to fill that gap by being the first study that forecasts the Finnish housing market volatility and further extends the ongoing literature on the countries’ house price volatility forecasting.
Furthermore, in contrast to previous studies which employed the data sets of the family–home property type; the studied type of dwellings in the article at hand is apartments (block of flats) categorize by the number of rooms. That is one-room, two-room and more than three rooms apartment types. One reason is that, according to Statistics Finland Overview, at the end of Citation2018, among all occupied dwellings, 46% were in apartments; which reflects how living in flats is growing in popularity in Finland, compared to other house types. Detached and semi-detached houses occupied 39%, terraced 14%, while 1% were in other buildings. The other reason is that apartments property type has not only increased its attractiveness in consumers but also in the Finnish residential property investors. Currently, foreign investors own some 15,000 rental flats, and between 2015 and 2018, in the Finnish housing development which has been very active in apartment buildings (Statistics Finland Citation2019); the share of foreign investors was up to 38%, and domestic and individual investors together hold some 40% (KTI, Autumn, Citation2019). Additionally, in the same standpoint of housing investment, this study uses data on both metropolitan and geographical level, to analysis and cross-compare housing investment in different cities and sub-areas, and portfolio allocation across Finland.
The purpose of the study is to assess the in-sample fit and the out-of-sample forecasting performance of four stochastic volatility models in the Finnish housing market. The competing models are the vanilla SV, the SV model where the latent volatility follows a stationary AR(2) process, the heavy-tailed SV and the SV with leverage effects. In other words, the goal of this model comparison exercise is to examine, in the SV framework, which volatility model tends to fit better the dynamics of the Finnish house prices and which one provides superior out-of-sample forecasts. Additionally, these models are used to answer the following questions: Are leverage effects and heavy-tailed distributions crucial in modelling and forecasting the Finnish house price volatility? Is the AR(2) component a useful addition to the vanilla SV model? The study assesses the Finnish housing market by apartment types categorize by the number of rooms. That is, single-room, two-room and apartments with more than three rooms. These apartment type prices are for 15 main regions divided geographically, according to their postcode numbers, into 45 cities and sub-areas. Each model is estimated for each city and sub-area with significant clustering effects. For the assessment of the out-of-sample forecasting performance of the four models, the data is split into two parts: the training set used for the estimation and prediction, and the test set used for the evaluation of the forecast built by the fitted model. Results reveal that, for the in-sample fit analysis, in all three apartment types, the stochastic volatility model with leverage effect ranks as the best model for modelling the Finnish house price volatility. For the out-of-sample forecasting assessment, in most of the regions, the heavy-tailed stochastic volatility model excels in forecasting the house price volatility of the studied types of apartments. Additionally, the models’ performances are noted to vary across almost all cities and sub-areas, and by apartment types – no geographical pattern is observed. Moreover, for the in-sample fit analysis, the AR(2) component is found to be a valuable addition to the vanilla SV, whereas, for the out-of-sample forecasting assessment, the vanilla SV model outperforms the SV-2 in most of the regions.
The remainder of the article is as follows. Section 2 describes the data and outlines the methodology to be employed. Section 3 presents and discusses the results. Section 4 concludes the article.
II. Data and methodology
Data
The study uses quarterly house price indices of 15 main regions in Finland estimated by Statistics Finland using the so-called hedonic method. The studied period is from 1988:Q1 to 2018:Q4, and the type of dwellings is apartments categorize by the number of rooms, that is, one-room, two-room and more than three rooms apartment types. The studied regions are Helsinki, Tampere, Turku, Oulu, Lahti, Jyväskylä, Kuopio, Pori, Seinäjoki, Joensuu, Vaasa, Lappeenranta, Kouvola, Hämeenlina and Kotka. Additionally, these regions are divided geographically, according to their postcode numbers, into 45 cities and sub-areas. The data regions’ ranking according to their number of inhabitants and regional division by postcode numbers is described in detailed in Dufitinema (Citation2020).
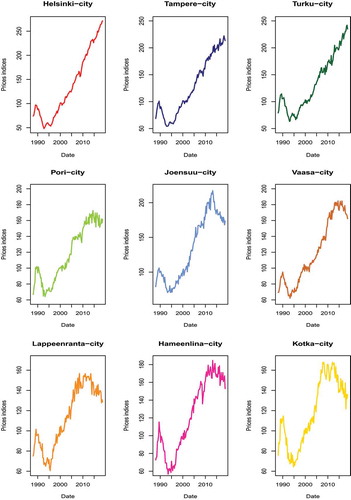
For a sample of three cities in each of the apartments categories, a house price movement is graphed in . Those are Helsinki, Tampere, Turku in the one-room flats group; Pori, Joensuu, Vaasa in the two-room flats group; Lappeenranta, Hämeenlina, Kotka in the more than three rooms flats group. A similar pattern is observed in all sample graphs from the end of 1980s to mid-1993. During this period, house prices in Finland experienced a structural break due to the financial market deregulation (Oikarinen Citation2009a, Citation2009b). Moreover, as it can be noted since the bursting of the bubble, one-room apartment prices have been increasing. Two-room apartments experienced downturns in the 2010s, same as large apartments; however, large apartments prices continue to decrease especially in less densely populated regions such as Kotka-city.
Figure 1. The house price movement – Sample cities
Methodology
The methodology used in this study is as follows: For each city and sub-area in each apartment type, we transform house price indices into continuous compound returns. Next, by employing the Akaike and Bayesian information criteria, we determine the ARMA model of appropriate order that filters out the first autocorrelations from the returns. Then, we test the clustering effects or Autoregressive Conditional Heteroscedasticity (ARCH) effects from the ARMA filtered returns. Lastly, for cities and sub-areas exhibiting ARCH effects, the four SV models’ in-sample estimations are performed, and the out-of-sample volatility forecasting performances are evaluated using the stochastic volatility framework.
Testing for ARCH effects
Two tests are employed to test clustering effects; those are Ljung-Box (LB) and Lagrange Multiplier (LM). An extensive discussion is given in Dufitinema (Citation2020) and results are outlined in . In summary, both tests found significant clustering effects in over half of the cities/sub-areas in all three studied types of apartments. Plus precisely, in the one–room flats category, ARCH effects were found in 28 out of 38 cities/sub-areas. In two-room flats category, they were significant in 27 out of 42;, and in the more than three rooms flats category, they were found in 31 out of 39.
Table 1. ARCH effects tests results
In-sample fit analysis
For cities and sub-areas exhibiting clustering effects, the in-sample fit is performed using the stochastic volatility approach. That is, in contrast to the GARCH-type framework where the conditional variance is assumed to follow a deterministic process; a stochastic volatility (SV) model treats the time-varying volatility as an unobserved component that mimics a stochastic process. The most popular SV model is the vanilla SV model with normal distribution errors proposed and developed by Taylor (Citation1982, Citation1986). However, several authors have pointed out that a normal distribution assumption is not plausible when analysing asset returns with SV framework as well as GARCH-type models (Tsay Citation2013; Harvey and Shephard Citation1996; Omari et al. Citation2007; Nakajima and Omori Citation2012). A suitable distribution requires to accommodate the characteristics of asset returns such as skewness and fat tails. Therefore, for each city and sub-area in each apartment type, the in-sample estimations of the vanilla SV model and the SV model with additional AR(2) component are compared to the SV model with Student’s t errors (heavy-tailed SV) and SV model with leverage effects. The models are estimated on the whole sample data from 1988:Q1 to 2018:Q4.
Vanilla SV model
Let denotes the demeaned return process
A basic stochastic volatility model is of the following form:
where the follows an AR(1) process. To adopt the convention often used in literature, we write for
where is the latent stochastic process (more precisely, the log-variance process),
is a constant or the level of the log-variance process,
is a parameter representing persistence in the log-variance process,
is the volatility or the standard deviation of the log-variance process (also called volvol), and
is the random shocks in the log-variance process; a white noise uncorrelated with
.
is referred to as the SV parameter vector.
EquationEquation (1)(1)
(1) can be expressed in hierarchical form. In its centred parameterization form, it is written as:
where denotes the normal distribution with mean
and variance
.
The SV model with additional AR(2) component, which is referred to as the SV-2, is the model where the observation is the same as in EquationEquation (1)(1)
(1) ; however, the log-variance
mimics a stationary AR(2) process.
SV with student’s t errors (SVt)
As discussed above, the non-normal conditional residual distributions are recommended when analysing asset returns. The proposed distributions include, for instance, the Student’s t distribution by Harvey, Ruiz, and Shephard (Citation1994); the (semi-)parametric residuals by Jensen and Maheu (Citation2010) and Delatola and Griffin (Citation2011); the extended generalized Inverse Gaussian by (Silva, Lopes, and Migon Citation2006); and the generalized hyperbolic skew Student’s t errors by Nakajima and Omori (Citation2012).
The SV model with Student’s t errors is described as:
The observations now follow a conditionally Student’s t distribution with
degrees of freedom, mean
and scale
. The parameter vector of the SVt model is
.
SV with leverage effects (SVl)
It has been argued that the returns of financial variables have three major distribution characteristics. Those are heavy-tailedness, skewness and volatility clustering with leverage effects. The leverage effect emerged from Black’s (Citation1976) and Christie’s (Citation1982) studies outcome that a drop in return (a negative chock) has more impact on asset price volatility increase than a rise in return (a positive chock). Various extensions of the vanilla SV model with normal errors have been proposed to model this effect. The proposed asymmetric innovations include, for instance, the distributions featuring correlation and variance by Harvey and Shephard (Citation1996), and Jaquier, Polson, and Rossi (Citation2004); the skewed distributions by Nakajima and Omori (Citation2012) and the non-parametric distributions by Jensen and Maheu (Citation2014).
The SV model with leverage effects is described as:
The vector collects the SVl parameters. The parameter
measures the correlation between the residuals of the observations (
) and the innovations of the log-variance process (
). Leverage effects exist when
.
Model comparison
As the latent volatility process () enters the models in a non-linear fashion, the maximum likelihood estimation framework is not a straightforward task as in the GARCH-type models’ case. The reason being that for the SV models, the likelihood function does not have a closed form (Gysels, Harvey, and Renault Citation1996). Hence, the estimation of the SV models is done through Bayesian parameter estimation technique via Markov Chain Monte Carlo (MCMC) methods (Kim et al., 1998). The estimation of the four SV models was performed by following Chan and Grant’s approach, which is outlined in Chan and Grant (Citation2016b, Appendix A). In estimating the SV models, the vital step is the joint sampling of the log volatilities. The novelty of Chan and Grant’s approach is that instead of using the conventional Kalman Filter to achieve this key step; the algorithm employs the fast band matrix routines (Chan and Jeliazkov Citation2009; Chan Citation2013).
The four models performances are compared using two popular Bayesian model comparison criteria, namely, deviance information criterion (DIC) and Bayes factor. The deviance information criterion (DIC) proposed by Spiegelhalter et al. (Citation2002) is a trade-off between the model’s goodness of fit and its corresponding complexity. The fit is measured by the deviance, defined as
where is the likelihood function. The complexity is measured by an estimate of the effective number of parameters
, defined as
That is, the difference between the posterior mean deviance and the deviance evaluated at the posterior mean of parameters. Thus, the DIC is the sum between the Monte Carlo estimated posterior mean deviance and the effective number of parameters:
The smaller the DIC, the better the model supports the data. The widely used version of DIC is the one obtained by conditioning on the latent variables, that is, the DIC based on conditional likelihood. However, studies such as Li, Zeng, and Yu (Citation2012) have warned against using this DIC version on the grounds of being non-regular and thus invalidates the needed justification of DIC – the standard asymptotic arguments. Moreover, Millar (Citation2009) and Chan and Grant (Citation2016a) provided Monte Carlo evidence that this DIC version always favours the most complex and overfitted model. To overcome this issue, Chan and Grant (Citation2016a) proposed importance sampling algorithms to compute DIC by integrating out the latent variables; that is, the DIC based on the observed data likelihood. The authors showed in a Monte Carlo study that indeed the observed data DIC was able to select the correct model. Following Chan and Grant (Citation2016a) approach, this article carries out the four models comparison exercise using the observed data DICs.
Another popular metric for Bayesian model comparison is the Bayes factor; it is defined as a ratio of marginal likelihoods. That is, given the likelihood function of a model
and its prior density
, the Bayes factor in favour of Model
against
is
is the marginal likelihood under model ,
.
The interpretation of the marginal likelihood is that of the density forecast of the data under model evaluated at the actual observed data
. Therefore, the more likely the observed data are to be under the model, the ‘larger’ the corresponding marginal likelihood would be. Furthermore, the Bayes factor is a consistent model selection creation (Kass and Raftery Citation1995). However, one potential drawback of the marginal likelihoods is that they are relatively sensitive to the prior distribution. In addition, their computation is non-trivial; the integral in EquationEquation (4)
(4)
(4) does not have an analytical solution as it is often high-dimensional. Chan and Grant (Citation2016b) provided an improved approach to compute the marginal likelihoods using an adaptive importance sampling method called the cross-entropy method. It is an importance sampling estimator based on independent draws from convenient distributions. This article employs Chan and Grant (Citation2016b) approach; the model selection criterion results are available from the author upon request.
Out-of-sample volatility forecasting
For the out-of-sample forecasting performance comparison of the four used models, the data is split into two parts: the training set which includes 25-year sample data (estimation sample: 1988:Q1–2013:Q4) and 5-year sample data for the test set or validation test (5-year forecast: 2014:Q1–2018:Q4). The prediction procedure starts with the estimation of each model using the training data set. Next, the estimated models are used to build the one-step-ahead (quarter) volatility forecasts. Finally, the predicted volatility () is compared to the proxy of the true volatility (
).
By nature, true volatility is unobserved, and its appropriate proxy to use in the evaluation of the forecasting performance of different models remains the centre of active ongoing debate. Although most studies such as Brailsford and Faff (Citation1996), Brooks and Persands (Citation2002), and Sadorsky (Citation2006) have employed the squared return as a proxy of , the realized volatility (RV) has been recognized as the natural benchmark against which to quantify volatility forecasts since it provides a consistent non-parametric estimate of the variability of the asset price over a given discrete period. The point which was first pointed out by Andersen and Bollerslev, in their (Citation1998a)’s work which was further developed by Andersen, Bollerslev, and Lange (Citation1999); (Citation2003); Citation2004) and Patton (Citation2007). Recently, in the stock market, the use of available intraday data and realized daily volatility had been praised for providing better forecast accuracy (Xingyi and Zakamulin Citation2018). In the housing market,
is also proxied by realized volatility calculated from the asset returns, as employed by Zhou and Kang (Citation2011). Following this study, a proxy of the true volatility used in this article is the released volatility constructed as a rolling sample. Moreover, following other studies on conditional volatility forecasting, the forecasting accuracy of the studied models is measured using two popular measures; the Root Mean Squared Error (RMSE) and the Mean Absolute Error (MAE). The two criteria are defined as follows:
where is the number of forecasts,
is the forecast volatility, and
is the true volatility.
III. Results and discussions
In-sample fit analysis
For cities and sub-areas with significant clustering effects in each apartment category, all four stochastic models are estimated using the Bayesian approach. The estimated observed data DICs and their standard errors are reported in . Various conclusions can be drawn from this model comparison exercise.
Table 2. Estimated DICs – One room flats
Table 3. Estimated DICs – Two-room flats
Table 4. Estimated DICs – More than three rooms flats
Overall, in all three apartment types, the SVl model ranks as the best model for modelling the Finnish house price volatility. In the one–room flats category, out of 28 cities/sub-areas exhibiting ARCH effects, SVl model comes on top in 19. In two–room flats category, SVl model leads in 24 cities/sub–areas out of 27;, and in the more than three rooms flats category, SVl comes on top in 20 cities/sub–areas out of 31. These results are in line with the general finding that asymmetric volatility (leverage effect and volatility feedback effect) is a crucial component in modelling assets returns. The results are also consistent with the findings of Dufitinema (Citation2020) who documented, using the GARCH-type framework, the evidence of leverage effects in the price volatility of the studied types of apartment.
Next, the SV-2 model interchanges with the SVl and takes the first place. This pattern is observed in eight cities/sub-areas in the one-room flats category, in three cities/sub-areas in the two-room flats category, and in nine cities/sub-areas in the more than three rooms flats category. The exceptions of this general pattern are Oulu-area1 in the one-room apartments, Helsinki-city and Vassa-area1 in the more than three rooms apartments. In both sub–areas (Oulu and Vassa), the heavy-tailed model (SVt) performs better, followed by the Vanilla SV; whereas in the Helsinki–city the model performance rank is the other way around.
Finally, to further investigate the features that are vital in modelling the Finnish house price volatility dynamics; the vanilla SV and SV-2 model are compared. In doing so, the question of whether the AR(2) component is a useful addition to the vanilla SV model is also answered. As it can be observed in the one–room flats category where the SV-2 model outperforms the vanilla SV in 20 out 28 cities/sub–areas; the richer AR(2) volatility process provides significant benefits. In the two–room flats category, the SV-2 performs better than SV in 17 cities/sub-areas out of 27, and in 22 out of 31 in the more than three rooms flats category. Although the SV-2 general excel in comparison to the vanilla SV, cautions should be taken when modelling house prices volatility of individual regions. As it can be noted, the performance of the two models differs across cities and sub-areas, and by apartment types – no geographical pattern is observed. Therefore, retaining the standard specification of an AR(1) volatility process or adding a component depends on the house price dataset under study.
In summary, the stochastic volatility model with leverage effect is the best model for modelling the house prices volatility of most of the Finnish cities and sub-areas. In the rest of the regions, the SVl swaps places with the SV model where the latent volatility follows a stationary AR(2) process. In a few cases, the second place is less clear-cut; the vanilla and the heavy-tailed SV models share the ranking. However, again as above, the model performance differs from region to region. Therefore, when modelling house price, even by employing the SV framework, one has to enable different house price dynamics across cities and sub-areas; rather than imposing one SV model on the whole dataset. As it has been stressed in various studies, such as Milles (Citation2011b) and Begiazi and Katsiampa (Citation2019) that house prices present a heterogeneous dynamics across different areas and property types.
Out-of-sample volatility forecasting
Since the model that performs better in-sample does not necessarily imply that it will provide accurate forecasts, the out-of-sample forecast performance of the four competing models is investigated. The procedure starts by estimating the models using the training dataset, build 5-year volatility forecasts in terms of one step ahead, and validate the constructed predictions using the test dataset. For each city and sub-area in each apartment category, report the Root Mean Squared Error (RMSE) and the Mean Absolute Error (MAE); the measures used in assessing the forecasting accuracy for each model. The lower the value of the two criteria, the better the model’s forecasting performance.
Table 5. The results of RMSE and MAE – One room flats
Table 6. The results of RMSE and MAE – Two-room flats
Table 7. The results of RMSE and MAE – More than three rooms flats
Overall, in all three apartment types, both evaluation criteria rank the heavy-tailed stochastic volatility model (SVt) as the best model. Especially in the two rooms and more than three rooms flats categories, where the SVt model provides the best forecasts in, respectively, 17 out on 27 and 18 out of 31 cities/sub-areas. In the one-room flats category, the SVt and SVl models are neck and neck; they forecast best in, respectively, 9 and 10 out of 28 cities/sub-areas. These results confirm again, the importance of the heavy-tailed distributions not only in modelling but also in forecasting assets volatility. Moreover, as it has been found in other assets such as stocks (Nakajima and Omori Citation2009; Chan and Grant Citation2016a), even in the SV framework, when the heavy-tailed distribution is employed, it provides the model with extra flexibility against misspecification and outlier. The same conclusion can also be drawn in the case of house prices, where the SVt outperforms the SV model with standard errors.
A geographical pattern is observed in some regions where, in all three apartment types, the same model performs well in producing accurate forecasts. In Helsinki-city, Helsinki-area1 and Kuopio-city, the SVt is the first–ranked model across all apartment types, whereas the SVl comes on top in Pori-area1. These results imply that, in addition to the volatility clustering, the returns distributions of the former regions in all three apartments types are characterized by skewness and heavy-tailedness. While in the latter area, the returns’ major characteristic is leverage effect; a drop in apartment price causes an increase in house price volatility.
Regarding, the forecasting performance of the vanilla SV in comparison to the SV-2 model, unlike in the in-sample fit analysis where the SV-2 general excel; for the out-of-sample forecasting assessment, the vanilla SV model outperforms the SV-2 in most of the regions. Plus precisely, the vanilla SV does better in approximately 64% (18 out of 28) in the one-room apartments category; in 59% (16 out of 27) in the two-room apartments category; and in 52% (16 out of 31) in the more than three rooms apartments category. Thus, for forecasting the house prices at least, one can feel comfortable retaining the standard specification of an AR(1) volatility process. However, as there is no geographical pattern observed, the same as discussed above, cautions should be taken when forecasting house prices volatility of individual regions.
In summary, indeed, a model that performs well in the in-sample analysis may not provide accurate out-of-sample forecasts. The heavy-tailed stochastic volatility model is the best model for forecasting the house prices volatility of most of the Finnish cities and sub-areas. On the second place comes the stochastic volatility model with leverage effect, while the vanilla SV and SV-2 models share the last two rankings. Moreover, apart from a few areas (two cities and two sub–areas), no geographical pattern is observed in all three apartment types; the models’ forecasting performances vary across cities and sub-areas, and by apartment types.
IV. Conclusions, implications and further research
Volatility forecasting is one of the most fundamental methodologies in financial economics as it is a vital tool for asset allocation in general, and specifically for investors who implement volatility targeting. This article assesses the in-sample fit and the out-of-sample forecasting performance of four stochastic volatility models in the Finnish housing market. The competing models are the vanilla SV, the SV model where the latent volatility follows a stationary AR(2) process, the heavy-tailed SV and the SV with leverage effects. The study uses quarterly house price indices from 1988:Q1 to 2018:Q4, for 15 main regions in Finland.
The study has various findings. First, in all three apartment types, the stochastic volatility model with leverage effect ranks as the best model for modelling the Finnish house price volatility; indicating that leverage effect is a crucial component in modelling house price returns. Second, in most of the regions, the heavy-tailed stochastic volatility model excels in forecasting the house price volatility of the studied types of apartments, indicating that the skewness and the heavy-tailedness characteristics are vital components in forecasting house price volatility. Moreover, results suggest that the t innovations component is a useful addition to the vanilla SV model. Third, for the in-sample fit analysis, the AR(2) component is found to be a valuable addition to the vanilla SV, whereas, for the out-of-sample forecasting assessment, the vanilla SV model outperforms the SV-2 in most of the regions. Last, except for two cities and two sub-areas, no geographical pattern is observed for the models’ out-of-sample forecasting performances in all three apartment types. Their performances vary across cities and sub-areas, and by apartment types.
The findings have some housing investment implications. As housing investors, policy-makers and consumers are recommended to monitor the asset volatility; accurate forecasts help to improve portfolio diversifications across Finland and by apartment type. In addition, in the viewpoint of volatility as a measure of risk, precise predictions are the key to assessing investment risks; an essential decision-making factor for foreign as well as domestic investors who dominate the Finnish housing market.
In the standpoint of establishing suitable time-series volatility forecasting models of this housing market; these study findings – the performance of the four stochastic models – will be weighed up to their GARCH models counterparts. One reason is that Dufitinema and Pynnönen (Citation2020) have found, in all three apartment types, evidence of long-range dependence in the returns and volatility for the majority of cities and sub-areas. The long memory present in the housing market returns suggests that the asset is forecastable on a long horizon, whereas the evidence of long-range dependence in the housing market volatility is the key to establish suitable time-series volatility forecasting models for the market. The other reason is that Dufitinema (Citation2020) employed the Exponential GARCH (EGARCH) model to investigate whether the asymmetric effects of shocks are noted in the Finnish house price volatility. The author found that, indeed, these asymmetric impacts of shocks are observed in all three studied apartment types. Therefore, to assess whether the deterministic conditional variance under GARCH or the unobserved time-varying volatility under SV is more favoured by the house price data; these study outcomes will be compared to the performance of the short memory and long memory GARCH-type models. Namely, the EGARCH model, the Component GARCH (CGARCH) model and the Fractionally Integrated GARCH (FIGARCH) model. The aim is to provide to the investors, risk managers and consumers enlightenments with regards to which forecasting approach delivers accurate and superior volatility forecasts of the apartment types under study.
Moreover, it would also be of interest to incorporate, in a multivariate analysis, macroeconomic factors such as interest rates and unemployment rates; as the interaction between these variables and house prices is often of interest. Additionally, several studies have referred to the importance of spatial dependence in regional housing markets known as ‘the ripple effect’. The phenomenon refers to the house prices’ tendency to rise first in the part of the country during an upswing and to gradually spread out or ‘ripple out’ across the country. Meen, Citation1999 was the fisrt to provide convincing economic explanations for the ripple effect, and by utilizing different approaches, many studies have contributed to the discussions of the spatial interaction of regional house prices. Among the methods used to detect the ripple effect includes tests of cointegration (Alexander and Barrow Citation1994), the concept of absolute and conditional convergence (Chow, Fung, and Cheng Citation2016), a measure of the regional–national return spillover indices through Vector Autoregressive (VAR) model (Tsai Citation2015), and use of time-series volatility models (Morley and Thomas Citation2011; Lin and Fuerst Citation2014). Therefore, following Morley and Thomas and Lin and Fuerst, and using the current study outcomes, the analysis of the spatial spillover in the Finnish housing market is also subjected to future research. That is, as the stochastic volatility model with leverage effect (SVl) has been ranked as the best model for modelling the Finnish house price volatility of most of the regions. The ripple effects will be allowed in the model by incorporating house prices of the most populated area – the Helsinki region – as highlighted by the above-cited studies that the most populated area in a country may be a leading factor to influence the rest of the housing markets.
Furthermore, it would be worth investigating the structural breaks in the studied housing market. For instance, as discussed earlier, during the period of the end of 1980s to mid-1993, house prices in Finland experienced a structural break due to the financial market deregulation. By examining the occurrence of structural breakpoints, the full sample data can be divided into subsamples based on the estimated break dates, and hence improve forecast accuracy.
Disclosure statement
No potential conflict of interest was reported by the author.
Additional information
Funding
References
- Alexander, C., and M. Barrow. 1994. “Seasonality and Cointegration of Regional House Prices in the UK”. Urban Studies. 31: 1667–1689. doi:10.1080/00420989420081571.
- Andersen, T. G., and T. Bollerslev. 1998a. “Answering the Skeptics: Yes, Standard Volatility Models Do Provide Accurate Forecasts”. International Economic Review. 39(4):885–905. doi:10.2307/2527343.
- Andersen, T. G., T. Bollerslev, F. X. Diebold, and P. Labys. 2003. “Modeling and Forecasting Realized Volatility”. Econometrica. 71:579–625. doi:10.1111/1468-0262.00418.
- Andersen, T. G., T. Bollerslev, and N. Meddahi. 2004. “Analytic Evaluation of Volatility Forecasts”. International Economic Review. 45:1079–1110. doi:10.1111/j.0020-6598.2004.00298.x.
- Andersen, T. G., T. Bollerslev, and S. Lange. 1999. “Forecasting Financial Market Volatility: Sample Frequency Vis–á–vis Forecast Horizon”. Journal of Empirical Finance. 6:457–477. doi:10.1016/S0927-5398(99)00013-4.
- Apergis, N., and J. E. Payne. 2020. “Modeling the Time Varying Volatility of Housing Returns: Further Evidence from the U.S Metropolitan Condominium Markets”. Review of Financial Economics. 38(1):24–33. doi:10.1002/rfe.1063.
- Begiazi, K., and P. Katsiampa. 2019. “Modelling U.K House Prices with Structual Breaks and Conditional Variance Analysis”. Journal of Real Estate Finance and Economics. 58:290–309. doi:10.1007/s11146-018-9652-5.
- Black, F. 1976. “Studies of Stock Market Volatility Changes”, Proceedings of the 1976 Meetings of the American Statistical Association, Business and Economics Statistics Section, Boston, MA; pp. 177–181.
- Bollerslev, T. 1986. “Generalized Autoregressive Conditional Heteroscedasticity”. Journal of Econometrics. 31(3):307–327. doi:10.1016/0304-4076(86)90063-1.
- Bollerslev, T., R. Y. Chou, and K. F. Kroner. 1992. “ARCH Modeling in Finance: A Review of the Theory and Empirical Evidence”. Journal of Econometrics. 52:1–2, 5–59. doi:10.1016/0304-4076(92)90064-X.
- Bos, C. S. 2012. “Relating Stochastic Volatility Estimation Methods”, In L Bauwens, C Hafner, S Laurent ( Ed.s), Handbook of Volatility Models and Their Applications, 147– 174. John Wiley & Sons. doi:10.1002/9781118272039.ch6.
- Brailsford, T. J., and R. W. Faff. 1996. “An Evaluation of Volatility Forecasting Techniques”. Journal of Banking and Finance. 20:307–327. doi:10.1016/0378-4266(95)00015-1.
- Brooks, C., and G. Persands. 2002. “Model Choice and Value–at–risk Performance”. Financial Analysts Journal. 58:87–97. doi:10.2469/faj.v58.n5.2471.
- Case, K. E., J. M. Quigley, and R. J. Shiller. 2013. “Wealth Effects Revisited 1975–2012”. Critical Finance Review. 2:101–128. doi:10.1561/104.00000009.
- Chan, J. C. 2013. “Moving Average Stochastic Volatility Models with Application to Inflation Forecast”. Journal of Econometrics. 176(2):162–172. doi:10.1016/j.jeconom.2013.05.003.
- Chan, J. C., and A. L. Grant. 2016b. “Modeling Energy Price Dynamics: GARCH versus Stochastic Volatility”. Energy Economics. 54:182–189. doi:10.1016/j.eneco.2015.12.003.
- Chan, J. C., and I. Jeliazkov. 2009. “Efficient Simulation and Integrated Likelihood Estimation in State Space Models”. International Journal of Mathematical Modelling and Numerical Optimisation. 1(1):101–120. doi:10.1504/IJMMNO.2009.030090.
- Chan, J. C. C., and A. L. Grant. 2016a. “On the Observed–Data Deviance Information Criterion for Volatility Modeling”. Journal of Financial Econometrics. 14(4):772–802. doi:10.1093/jjfinec/nbw002.
- Chow, W. W., M. K. Fung, and A. C. S. Cheng. 2016. “Convergence and Spillover of House Prices in Chinese Cities”. Applied Economics. 48(51):4922–4941. doi:10.1080/00036846.2016.1167829.
- Christie, A. A. 1982. “The Stochastic Behavior of Common Stock Variances–Value, Leverage and Interest Rate Effects”. Journal of Financial Economics. 10:407–432. doi:10.1016/0304-405X(82)90018-6.
- Crawford, G. W., and M. C. Fratantoni. 2003. “Assessing the Forecasting Performance of Regime–Switching, ARIMA and GARCH Models of House Prices”. Real Estate Economics. 31(2):223–243. doi:10.1111/1540-6229.00064.
- Delatola, E. I., and J. E. Griffin. 2011. “Bayesian Nonparametric Modeling of the Return Distribution with Stochastic Volatility”. Bayesian Analysis. 6: 901–926. doi:10.1214/11-BA632.
- Dolde, W., and D. Tirtiroglu. 1997. “Temporal and Spatial Information Diffusion in Real Estate Price Changes and Variances”. Real Estate Economics. 25(4):539–565. doi:10.1111/1540-6229.00727.
- Dolde, W., and D. Tirtiroglu. 2002. “Housing Price Volatility Changes and Their Effects”. Real Estate Economics. 30:41–66. doi:10.1111/1540-6229.00029.
- Dufitinema, J. 2020. “Volatility Clustering, Risk–return Relationship and Asymmetric Adjustment in the Finnish Housing Market”. International Journal of Housing Markets and Analysis. 13(4):661–688. doi:10.1108/IJHMA-12-2019-0125.
- Dufitinema, J., and S. Pynnönen. 2020. “Long–range Dependence in the Returns and Volatility of the Finnish Housing Market”. Journal of European Real Estate Research. 13(1):29–50. doi:10.1108/JERER-07-2019-0019.
- Engle, R. F. 1982. “Autoregressive Conditional Heteroscedasticity with Estimates of Variance of United Kingdom Inflation”. Econometrica. 50(4):987–1007. doi:10.2307/1912773.
- Gysels, E., A. C. Harvey, and E. Renault. 1996. “Stochastic Volatiltiy”, In GS Maddala, CR Rao ( Eds.), Handbook of Statistics, 14, 119–191: Elsevier. doi:10.1016/s0169-7161(96)14007-4.
- Harvey, A. C., E. Ruiz, and N. Shephard. 1994. “Multivariate Stochastic Variance Models”. The Review of Economic Studies. 61(2):247–264. doi:10.2307/2297980.
- Harvey, A. C., and N. Shephard. 1996. “Estimation of an Asymmetric Stochastic Volatility Model for Asset Returns”. Journal of Business & Economic Statistics. 14(4):429–434. doi:10.1080/07350015.1996.10524672.
- Hossain, B., and E. Latif. 2009. “Determinants of Housing Price Volatility in Canada: A Dynamic Analysis”. Applied Economics. 41(27):3521–3531. doi:10.1080/00036840701522861.
- Jaquier, E., N. G. Polson, and P. E. Rossi. 1994. “Bayesian Analysis of Stochastic Volatility Models”. Journal of Business & Economic Statistics. 20(1):69–87. doi:10.1080/07350015.1994.10524553.
- Jaquier, E., N. G. Polson, and P. E. Rossi. 2004. “Bayesian Analysis of Stochastic Volatility Models with Fat–Tails and Correlated Errors”. Journal of Econometrics. 122(1):185–212.
- Jensen, M. J., and J. M. Maheu. 2010. “Bayesian Semiparametric Stochastic Volatility Modeling”. Journal of Econometrics. 157(2):306–316.
- Jensen, M. J., and J. M. Maheu. 2014. “Estimating a Semiparametric Asymmetric Stochastic Volatility Model with a Dirichlet Process Mixture”. Journal of Econometrics. 178(3):523–538.
- Kass, R. E., and A. E. Raftery. 1995. “Bayes Factors”. Journal of the American Statistical Association. 90(430):773–794.
- Kim, S., Shephard, N. And Chib, S. 1998. “Stochastic Volatility: Likelihood Inference and Comparison with ARCH models”. The Review of Economic Studies. 65(3):361–393 doi:10.1111/1467-937x.00050.
- KTI Autumn, 2019. “KTI Market Review”, Technical report, KTI Property Information .
- Lee, C. L. 2009. “Housing Price Volatility and Its Determinants”. International Journal of Housing Markets and Analysis. 2(3):293–308. doi:10.1108/17538270910977572.
- Lee, C. L., and R. Reed. 2014b. “Volatility Decomposition of Australian Housing Prices”. Journal of Housing Research. 23(1):21–43. doi:10.1080/10835547.2013.12092084.
- Li, K.-W. 2012. “A Study on the Volatility Forecast of the US Housing Market in the 2008 Crisis”. Applied Financial Economics. 22(22):1869–1880. doi:10.1080/09603107.2012.687096.
- Li, Y., T. Zeng, and Y. Yu 2012. “Robust Deviance Information Criterion for Latent Variable Models”, SMU Economics and Statistics Working Paper Series.
- Lin, P.-T., and F. Fuerst. 2014. “Volatility Clustering, Risk–return Relationship, and Asymmetric Adjustment in the Canadian Housing Market”. Journal of Real Estate Portfolio Management. 20(1):37–46.
- Meen, G. 1999. “Regional House Prices and the Ripple Effect: A New Interpretation”. Housing Studies. 14(6):733–753. doi:10.1080/02673039982524.
- Millar, R. B. 2009. “Comparison of Hierarchical Bayesian Models for Overdispersed Count Data Using DIC and Bayes Factors”. Biometrics. 65:962–969. doi:10.1111/j.1541-0420.2008.01162.x.
- Miller, N., and L. Peng. 2006. “Exploring Metropolitan Housing Price Volatility”. The Journal of Real Estate Finance and Economics. 33(1):5–18. doi:10.1007/s11146-006-8271-8.
- Milles, W. 2008a. “Boom–bust Cycles and the Forecasting Performance of Linear and Non-linear Models of House Prices”. Journal of Real Estate Finance and Economics. 36:249–264. doi:10.1007/s11146-007-9067-1.
- Milles, W. 2008b. “Volatility Clustering in US Home Prices”. Journal of Real Estate Research. 30(1):73–90.
- Milles, W. 2011b. “Clustering in UK Home Prices Volatility”. Journal of Housing Research. 20(1):87–101. doi:10.1080/10835547.2011.12092031.
- Morley, B., and D. Thomas. 2011. “Risk–return Relationships and Asymmetric Adjustment in the UK Housing Market”. Applied Financial Economics. 21(10):735–742. doi:10.1080/09603107.2010.535782.
- Nakajima, J., and Y. Omori. 2009. “Leverage, Heavy–tails and Correlated Jumps in Stochastic Volatility Models”. Computational Statistics and Data Analysis. 53:2535–2553. doi:10.1016/j.csda.2008.03.015.
- Nakajima, J., and Y. Omori. 2012. “Stochastic Volatility Model with Leverage and Asymmetrically Heavy–tailed Error Using GH Skew Student’s T –distribution”. Computational Statistics & Data Analysis. 56(11):3690–3704.
- Oikarinen, E. 2009a. “Household Borrowing and Metropolitan House Price Dynamics – Empirical Evidence from Helsinki”. Journal of Housing Economics. 18(2):126–139. doi:10.1016/j.jhe.2009.04.001.
- Oikarinen, E. 2009b. “Interaction between Housing Prices and Household Borrowing: The Finnish Case”. Journal of Banking & Finance. 33(4):747–756. doi:10.1016/j.jbankfin.2008.11.004.
- Omari, Y., S. Chib, N. Shephard, and J. Nakajima. 2007. “Stochastic Volatility with Leverage: Fast and Efficient Likelihood Inference”. Journal of Econometrics. 140(2):425–449.
- Patton, A. J. 2007. “Volatility Forecast Comparison Using Imperfect Volatility Proxies”. Working paper, Oxford University.
- Sadorsky, P. 2006. “Modeling and Forecasting Petroleum Futures Volatility”. Energy Economics. 28:467–488. doi:10.1016/j.eneco.2006.04.005.
- Segnon, M., R. Gupta, K. Lesame, and M. E. Wohar. 2020. “High–frequency Volatility Forecasting of US Housing Markets”. Journal of Real Estate Finance & Economics. doi: 10.1007/s11146-020-09745-w.
- Silva, R. S., H. F. Lopes, and H. S. Migon. 2006. “The Extended Generalized Inverse Gaussian Distribution for Log–Linear and Stochastic Volatility Models”. Brazilian Journal of Probability and Statistics. 20(1):67–91. https://www.jstor.org/stable/43601074
- Spiegelhalter, D., N. Best, B. Carlin, and A. V. der Linde. 2002. “Bayesian Measures of Model Complexity and Fit(with Discussion)”. Journal of the Royal Statistical Society Series B. 64:583–639. doi:10.1111/1467-9868.00353.
- Statistics Finland. 2016. “Households’ Assets”, Technical report. Last checked: 10/ 02/2020.http://www.stat.fi/til/vtutk/2016/vtutk-2016-2018-06-05-tie-001-en.html
- Statistics Finland (2019). “Building and Dwelling Production”, Technical report. Last checked: 10/ 02/2020 http://www.stat.fi/til/ras/index-en.html
- Statistics Finland Overview (2018). 2018 “Overview, Household–dwelling Units and Housing Conditions”, Technical report. Last checked: 10/ 02/2020. http://www.stat.fi/til/asas/2018/011/asas-2018-01-2019-10-10-kat-002- en.html
- Taylor, S. J. 1982. “Financial Returns Modelled by the Product of Two Stochastic Processes: A Study of Daily Sugar Prices 1961-75”. In O. D. Anderson, edited by. Time Series Analysis, Theory and Practice. Amsterdam: North–Holland; p. 203–226.
- Taylor, S. J. 1986. Modelling Financial Time Series. Chichester: Wiley.
- Tsai, I.-C. 2015. “Spillover Effect between the Regional and the National Housing Markets in the UK”. Regional Studies. 49(12):1957–1976.
- Tsai, I.-C., M.-C. Chen, and T. Ma. 2010. “Modelling House Price Volatility States in the UK by Switching ARCH Models”. Applied Economics. 42(9):1145–1153. doi:10.1080/00036840701721133.
- Tsay, R. S. 2013. An Introduction to Analysis of Financial Data with R. Hoboken, New Jersey: John Wiley & Sons.
- Willcocks, G. 2010. “Conditional Variances in UK Regional House Prices”. Spatial Economic Analysis. 5(3):339–354. doi:10.1080/17421772.2010.493951.
- Xingyi, L., and V. Zakamulin (2018). “Forecasting Stock Volatility: The Gains Form Using Intraday Data.” Available at SSRN: https//ssrn.com/abstract=2847059; http://dx.doi.10.2139/ssrn.2847059.
- Zhou, J., and Z. Kang. 2011. “A Comparison of Alternative Forecast Models of REIT Volatility”. The Journal of Real Estate Finance and Economics. 42:275–294 . doi: 10.1007/s11146-009-9198-7.
- Zhou, Y., and D. R. Haurin. 2010. “On the Determinants of House Value Volatility”. The Journal of Real Estate Research. 32:377–396.