
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Historical time series sometimes have missing observations. It is common practice either to ignore these missing values or otherwise to interpolate between the adjacent observations and continue with the interpolated data as true data. This paper shows that interpolation changes the autocorrelation structure of the time series. Ignoring such autocorrelation in subsequent correlation or regression analysis can lead to spurious results. A simple method is presented to prevent spurious results. A detailed illustration highlights the main issues.
I. Introduction
Historical time series sometimes have missing observations, for various reasons. Consider for example the two time series in , which are the contribution to Gross Domestic Product in Holland (in 1000 guilders) for Domestic production, trade and shipping (for convenience with acronym DPTS) and Army Navy (AN). The data are observed for 1738–1779, and as is typical for historical data, there are many missing observations. Given the time span, there could be 42 annual observations, but the number of effective observations is 24.
Figure 1. The contribution to Gross Domestic Product in Holland (in 1000 guilders) for Domestic production, trade and shipping.
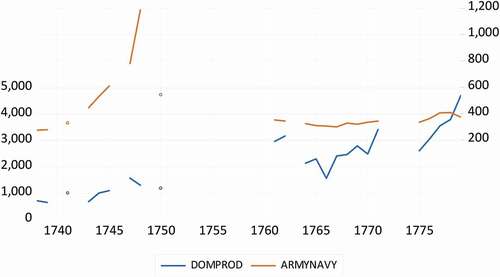
Suppose one is interested in any correlation or regression relation between these two variables. One approach could now be to simply ignore the missing data and compute the correlation or run a regression. This simple solution could work well, but in case the data show autocorrelation, that is, the data in year T-1 are informative for the data year T; then, the number of missing observations may be an obstacle for analysis. Indeed, when there are just three observations, and suppose
is missing then this means that one simply cannot compute a first-order autocorrelation.
An often consider alternative is to interpolate the missing observations using the adjacent observed observations. For the missing above, this would entail that it is replaced by
, which is a function of
and
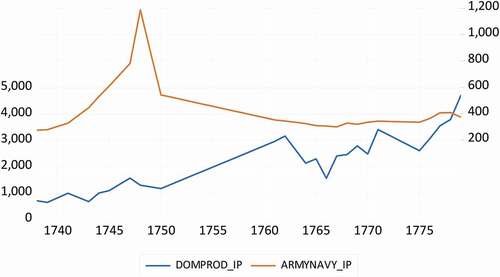
. With this replaced value, one does have information to compute the first-order autocorrelation. Frequently, researchers choose a linear interpolation scheme, and this results in data like those in , which displays some straight lines between various points. For another example, consider Figure 8A in O’Rourke and Jeffrey (Citation2002).
Figure 2. The contribution to Gross Domestic Product in Holland (in 1000 guilders) for the Army and Navy.
In this paper, I will show that there is downside to interpolation and that is that it changes the autocorrelation structure of the time series. Next, ignoring such autocorrelation in subsequent correlation or regression analysis can lead to spurious results. A simple method is presented to prevent spurious results. A detailed illustration to the abovementioned two time series highlights the main issues.
II. Correlation and interpolation
Consider again the two time series in , and suppose we are interested in measuring the relationship between these two variables. The data are observed for 1738–1779, and as is clear from , there are many missing observations. Given the time span, there could have been 42 annual observations, but the number of effective observations is 24.
The estimated correlation between these two variables is −0.269. When we consider a simple regression model and apply Ordinary Least Squares (OLS) to
We obtain the estimation results
where the numbers in parentheses are the HAC standard errors (Heteroscedasticity and Autocorrelation Consistent). The estimated t-statistic on b is −2.097, and hence, there seems to be a significant relationship, with a p value of 0.048. There does seem to be some autocorrelation in the estimated residuals as the Eviews package gives a Durbin Watson test statistic value of 0.216, which is closer to 0 than to 2 (the value if there is no autocorrelation).
We may now want to increase the effective sample size from 24 to 42 by interpolating the missing observations. An often-applied technique is to draw a straight line between the begin and end points of a period with missing data, and the use the points on that line as the new observations. For example, suppose there are three observations , and suppose the observation on
is missing. One can then decide to insert for
:
In general, if there are missing observations in between any
and
, then the interpolation scheme is
to
If this scheme is applied to the two variables with 42–24 = 18 missing observations, we obtain the data as depicted in .
The correlation between these two interpolated series is −0.333, a slight increase relative to the −0.269 before, at least in an absolute sense. When we consider a simple regression model to these interpolated series, and apply OLS to
We obtain the estimation results
where the numbers in parentheses are again the HAC standard errors. The estimated t-statistic on b is now −2.351, and hence, there seems to be a significant relationship, now even with a p value of 0.024. The Durbin Watson test statistic value for the 42 estimated residuals is 0.186, which is even closer to 0 and further away from 2.
The question now is whether this correlation and this relation is a statistical artefact. We seem to miss out on first-order autocorrelation, given the small Durbin Watson values, and also after interpolation, the first-order autocorrelation seems to increase.
To see if there is autocorrelation in each of the variables, we compute the first-order autocorrelation like
and also the second- to fifth-order autocorrelations. These estimates are displayed in . Comparing the columns with raw data and interpolated data, it is evident that the interpolated data have much more autocorrelation. In fact, the first-order autocorrelation seems to approach 1, which is the case of the so-called unit root, in which case one needs to resort to cointegration analysis, as is done in for example O’Rourke and Jeffrey (Citation2002).
Table 1. Autocorrelations in the various variables, computed using
Footnote1Before we turn to correlation and regression analysis, we first examine the potential consequences of interpolation for the time series.
III. What does interpolation do?
To understand what interpolation does to the time series properties of variables, consider the following very simple and stylized case. Consider the following four observations:
and assume that each of these four observations is a draw from a white noise process, that is they have mean zero, variance , and they are uncorrelated, that is, the correlation between any
and
for
is zero. It is now easy to derive that
Next, we consider three distinct cases when one or two observations can be missing. We use the linear interpolation technique, but for alternative methods, qualitatively similar results can be obtained, although the notation and mathematical expressions quickly become involved.
Case a: is missing and is interpolated using
and
In this case, the data series becomes
Call these observations
For this data series, it holds that
and that
Hence, the first-order autocorrelation becomes
So, the first-order autocorrelation quickly jumps from 0 to 0.4.
Case b: and
are missing and are interpolated using
and
When there are two observations missing, the linear interpolation method results in the new observations
We now have that
and that
which makes the first-order autocorrelation to become
The differences between cases a and b are that, as could be expected, the variance decreases (from to
), and that the first-order autocorrelation increases (from 0.4 to 0.84).
Case c: is missing and is interpolated using
and
, while there are five observations, that is, one more than case a.
In this case, we thus have
which gives
and
resulting in
So, when the number of non-interpolated data decreases, the first-order autocorrelation also decreases.
IV. What does neglected autocorrelation do?
Already in Udny (Citation1926), the issue of spurious correlation was raised, which basically occurs due to neglected autocorrelation. When the data have trends, Granger and Newbold (Citation1974) showed that high-valued nonsense correlations can occur. In Phillips (Citation1986), it was shown that for trended data such nonsense correlations can be obtained when people rely on inappropriate statistical methodology. Later, Granger, Hyung, and Jeon (Citation2001) derived the asymptotic distribution of the t test on the parameter in the simple regression
where in reality
that is, the two variables are independent first-order autoregressive time series with the same parameter . This asymptotic distribution is
instead of the commonly considered distribution. Clearly,
and hence, more often significant test values will be found. Indeed, Table 5A.1 in Franses (Citation2018) shows that when for example , one will obtain around 23% significant t test values. And, in this case, the average absolute correlation between
and
is 0.131 for 100 observations, and as large as 0.248 for 25 observations.
In sum, neglected autocorrelation leads to spurious relations.
V. How to prevent spurious results?
A simple remedy to prevent spurious results is to explicitly incorporate lags of the variables. In our illustrative example, this means that we move from
to
The OLS estimation results for this extended model are
Clearly, the parameter for Army Navy is now insignificant.
Given the high-valued autocorrelations in , and also given the estimate of 0.990 for , one can also correlate the differences of the two variables, thereby imposing that each of the two has a unit root. Then, the regression becomes
and the OLS estimation results (with HAC standard errors) are
Clearly, there is no significant link between the two differenced variables.
VI. Conclusion
When analysing historical time series with missing observations, it is a common practice either to ignore these missing values or otherwise to interpolate between the adjacent observations and continue with the interpolated data as true data. In this paper, we have shown that interpolation changes the autocorrelation structure of the time series. Ignoring such autocorrelation in subsequent correlation or regression analysis could lead to spurious results. A simple method was presented to prevent spurious results. A detailed illustration highlighted the main issues and showed that presumably none-zero correlation disappears when the data are analysed properly.
Further research should indicate how often spurious correlations appear in historical research.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Notes
1 The data source is Brandon, P. and U. Bosma (2019), Calculating the weight of slave-based activities in the GDP of Holland and the Dutch Republic – Underlying methods, data and assumptions, The Low Countries Journal of Social and Economic History, 16 (2), 5–45, doi: 10.18352/tseg.1082
References
- Franses, P. H. 2018. Enjoyable Econometrics. Cambridge UK: Cambridge University Press.
- Granger, C. W. J., N. Hyung, and Y. Jeon. 2001. “Spurious Regressions with Stationary Series.” Applied Economics 33 (7): 899–904. doi:https://doi.org/10.1080/00036840121734.
- Granger, C. W. J., and P. Newbold. 1974. “Spurious Regression in Economics.” Journal of Econometrics 2 (2): 111–120. doi:https://doi.org/10.1016/0304-4076(74)90034-7.
- O’Rourke, K. H., and G. W. Jeffrey. 2002. “When Did Globalization Begin?” European Review of Economic History 6 (1): 23–50. doi:https://doi.org/10.1017/S1361491602000023.
- Phillips, P. C. B. 1986. “Understanding Spurious Regressions in Econometrics.” Journal of Econometrics 33 (3): 311–340. doi:https://doi.org/10.1016/0304-4076(86)90001-1.
- Udny, Y. G. 1926. “Why Do We Sometimes Get Nonsense Correlations between Time Series? A Study in Sampling and the Nature of Time Series.” Journal of the Royal Statistical Society 89 (1): 1–64. doi:https://doi.org/10.2307/2341482.