
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The standard Adstock regression is problematic for at least two reasons. Statistical inference is cumbersome and there is a chance of a spurious relation between sales and advertising. This paper shows that reformulating the equation solves both problems, and the result is that a proper model for Adstock is an unrestricted Koyck model. Maximum Likelihood estimation gives the parameter estimates. An illustration to the illustrious monthly Lydia Pinkham data shows the merits of the method.
I. Introduction and motivation
Broadbent (Citation1979, Citation1984) introduced the concept of Adstock for understanding sales and advertising relationships, when the two variables are observed over time. It basically translates advertising into a cumulative advertising process, and next it proposes to regress sales on accumulated advertising. The concept has been and still is very popular in practice, see Ephron and McDonald (Citation2002) and Dubé et al. (Citation2005), as well as in the academic literature, see Cleeren et al (Citation2008), Danaher et al, (Citation2008), Donagoglu and Klapper (Citation2006), Gijsenberg et al. (Citation2012), and Steenkamp and Gielens (Citation2003), Beltran-Royo et al (Citation2016), Naimi et al. (Citation2016), Havlena and Graham (Citation2004), Aurier and Broz-Giroux (Citation2014) and Yeh and Chang (Citation2023), to mention just a few. Hence, even though the concept was proposed a long time ago, it is still use in applied economics studies.
The idea of the Adstock concept is the following. Consider advertising and sales
for
, where the data can concern days or weeks or months. Assume for the moment that advertising is a stationary [I(0)] time series. Adstock is commonly defined as
where , which is a crucial assumption. Alternative versions of (1) can be found in Joy (Citation2006), which typically involve replacing
by
, where
is a monotone function. For (1), the half-life
is equal to
, where log denotes the natural logarithm. Also, the notion of Adstock can easily include other marketing mix variables, making the forthcoming regression models more involved.
Next, in practice one usually resorts to the regression model
where is often assumed to be a mean zero and uncorrelated error process with variance
. Given a selected value of
in (1), one can create
, and the parameters in (2) can be estimated using Ordinary Least Squares (OLS).
For at least two reasons, this methodology to examine the effects of advertising (or other marketing mix variables) is problematic. First, and as is often done in practice, one tends to maximize the fit of (2) by searching over values of . This favourably biases the statistical relevance of
. At the same time, it is an inconvenient method to estimate
, as no standard errors around the estimator
are obtained.
The second potential problem occurs in the case when there really is no effect of advertising on sales, and the true sales process is for example
with . The regression in (2) then gives spurious results, at a degree depending on the values of
and
. For example, if
and
, . A1 in Franses (Citation2018) shows that in 50.5% of the simulated cases, one would find a 5% significant parameter
in (2), in the actual case that sales and advertising are fully independent processes. Note that this parameter can be positive and can be negative. Theoretical results are presented in Granger, Hyung and Jeon (Citation2001), see also Yule (Citation1926).
Table 1. Searching for the optimal value of using (1) with (2).
The present paper presents a simple method to meet these two problems. This method will be given in the next section. After that, an illustration shows its empirical relevance. The last section concludes.
II. The solution
To solve the two problems at once, it is recommended to add an error term to (1), that is,
where is a temporally uncorrelated error term with mean 0 and variance
. This added error term can capture measurement errors in
and
in part due to uncertainty about the exact value of
. This added error term opens the way to rewrite the model in (2) in a convenient way.
With , and using the familiar lag operator L, defined by
, with
we can write (3) as
Plugging (4) into (2) gives
Multiplying both sides of (5) with , and re-arranging terms, gives
As is a process with only non-zero autocorrelation at the first lag, due to
and
, we can write (6) as
where , and where
is an uncorrelated error term with mean 0 and variance
. It is easy to see that
. The parameters in this model (7) can be estimated using Maximum Likelihood or Iterative Least Squares. Given estimates of
, it is also possible to estimate
and
.Footnote1
The model in (7) is an unrestricted equivalent of the Koyck (Citation1954) model, which in original format reads as
as it is based on the infinite distributed lag model
Franses and van Oest (Citation2007) show for (8) that statistical inference is complicated because appears in front of
and in front of
. This problem however disappears for (7). At the same time, (7) includes
, and the inclusion of this term prevents obtaining a potential spurious relationship between sales and advertising. Moreover, the estimation method gives a standard error for the estimated value of
. In sum, simply adding an error term to the Adstock equation makes all problems to disappear.
When it is assumed that advertising is a process integrated of order 0, that is, it is a stationary process, and when
, then
is also a stationary process. To make the regression model in (2), that is,
a balanced model, such that indeed
is white noise, then sales
is also a stationary process.
When advertising is a process integrated of order 1, that is, it is a non-stationary process, then with
, it then follows that
is then also a non-stationary process. This implies that EquationEquation (7)
(7)
(7) is a cointegration relationship, and this cointegration relation is a stationary moving average process of order 1, see also Baghestani (Citation1991).
The assumption that is crucial. When
is I(0), and
, then
is I(1), and for model (2) to hold, the cointegration relation is
and hence is I(1). A consequence is that when
is I(0) and
is I(1), EquationEquation (7)
(7)
(7) does not hold. Additionally, when
is I(1), and
, then
is I(2), and for model (2) to hold, then
is I(2). When
is I(1) and
is I(2), EquationEquation (7)
(7)
(7) again does not hold.
Finally, when advertising and sales simultaneously determine each other, EquationEquation (7)(7)
(7) needs to be extended to a simultaneous equation system, where instruments can be lagged sales and advertising variables.
III. Illustration
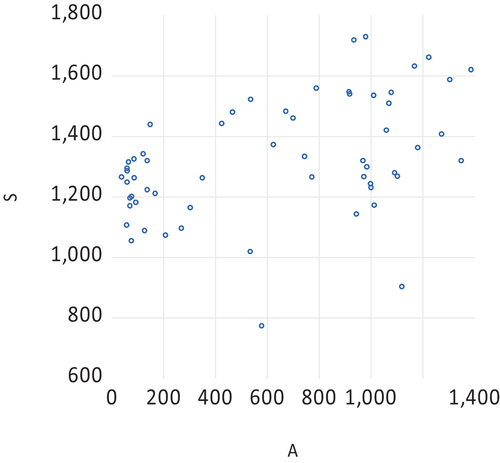
To illustrate the various aspects of the above discussion, consider the illustrious monthly Lydia Pinkham data in , with a scatter in . shows the results of a rather rough grid search for finding the proper value of . Looking at the patterns in the standard errors for
and the
values, one would be inclined to believe that
is anywhere around 0.6. A more refined grid search could now follow.
Figure 1. Monthly Lydia Pinkham sales and advertising data, 1954.01–1958.12.
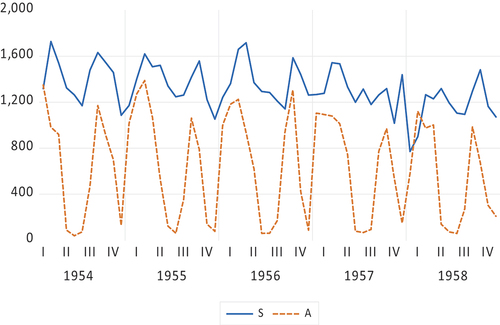
Figure 2. Monthly Lydia Pinkham sales against advertising data, 1954.01–1958.12.
However, if we resort to Maximum Likelihood estimation of (7) for 59 effective observations we obtain the parameter estimates (with standard errors in parentheses):
The and the Durbin Watson statistic is 1.954. We see that
is indeed close to 0.6, but now we have an estimated standard error. The standard error for the associated
is now 0.046, which is larger than those reported in , as expected.
Finally, using the calculation in footnote 1, we arrive at and
. The variance of the Adstock variable in (3) is 362,701 for
, and hence the error term
in (3) can indeed not be ignored.
IV. Conclusion
This paper has argued that the standard Adstock regression is problematic for at least two reasons. These problems can be alleviated by reformulating the equation (after adding an error term), which results in the fact that a proper model for Adstock is an unrestricted Koyck model. Maximum Likelihood estimates gives the parameter estimates. An illustration showed the merits of the method.
Acknowledgements
The author is grateful to the comments made by three anonymous referees.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Notes
1 The variance of the process is
, where the latter equals the variance of
, which is
. The first order autocovariances for the two processes are
and
, respectively. This gives two equations to solve for
and
.
References
- Aurier, P., and A. Broz-Giroux. 2014. “Modeling Advertising Impact at Campaign Level: Empirical Generalizations Relative to Long-Term Advertising Profit Contribution and Its Antecedents.” Marketing Letters 25 (2): 193–206. https://doi.org/10.1007/s11002-013-9252-3.
- Baghestani, H. 1991. “Cointegration Analysis of the Advertising-Sales Relationship.” The Journal of Industrial Economics 39 (6): 671–682. https://doi.org/10.2307/2098669.
- Beltran-Royo, C., L. F. Escudero, and H. Zhang. 2016. “Multiperiod Multiproduct Advertising Budgeting: Stochastic Optimization Modeling.” Omega – International Journal of Management Science 59 (March 2016): 26–39. https://doi.org/10.1016/j.omega.2015.02.013.
- Broadbent, S. S. 1979. “One Way TV Advertisements Work.” Journal of the Market Research Society 21 (3): 139–166.
- Broadbent, S. S. 1984. “Modeling with Adstock.” Journal of the Market Research Society 26 (4): 295–312.
- Cleeren, K., M. G. Dekimpe, and K. Helsen. 2008. “Weathering Product-Harm Crises.” Journal of the Academy of Marketing Science 36 (2): 262–270. https://doi.org/10.1007/s11747-007-0022-8.
- Danaher, P. J., A. Bonfrer, and S. Dhar. 2008. “The Effect of Competitive Advertising Interference on Sales for Packaged Goods.” Journal of Marketing Research 45 (2): 211–225. https://doi.org/10.1509/jmkr.45.2.211.
- Donagoglu, T., and D. Klapper. 2006. “Goodwill and Dynamic Advertising Strategies.” Quantitative Marketing and Economics 4 (1): 5–29. https://doi.org/10.1007/s11129-006-6558-y.
- Dubé, J. P., G. J. Hitsch, and P. Machanda. 2005. “An Empirical Model of Advertising Dynamics.” Quantitative Marketing and Economics 3 (2): 107–144. https://doi.org/10.1007/s11129-005-0334-2.
- Ephron, E., and C. McDonald. 2002. “Media Scheduling and Carry-Over Effects: Is Adstock a Useful TV Planning Tool?” Journal of Advertising Research 42 (4): 66–71. https://doi.org/10.2501/JAR-42-4-66-70.
- Franses, P. H., and R. van Oest. 2007. “On the Econometrics of the Geometric Lag Model.” Economics Letters 95 (2): 291–296. https://doi.org/10.1016/j.econlet.2006.10.023.
- Franses, P. H. 2018. Enjoyable Econometrics. Cambridge UK: Cambridge University Press.
- Gijsenberg, M. J., H. J. van Heerde, M. G. Dekimpe, and V. R. Nijs. 2012. Understanding the role of adstock in advertising decisions. Unpublished manusscript.
- Granger, C. W. J., N. Hyung, and Y. Jeon. 2001. “Spurious Regressions with Stationary Series.” Applied Economics 33 (7): 899–904. https://doi.org/10.1080/00036840121734.
- Havlena, W., and J. Graham. 2004. “Decay Effects in Online Advertising: Quantifying the Impact of Time Since Last Exposure on Branding Effectiveness.” Journal of Advertising Research 44 (4): 327–332. https://doi.org/10.1017/S0021849904040401.
- Joy, J. 2006. “Understanding advertising adstock transformations, MPRA paper 7683.” SSRN Electronic Journal. https://doi.org/10.2139/ssrn.924128.
- Koyck, L. M. 1954. Distributed Lags and Investment Analysis. Amsterdam: North Holland.
- Naimi, T. S., C. S. Ross, M. B. Siegel, W. DeJong, and H. Jernigan. 2016. “Jernigan 92016), Amount of Televised Alcohol Advertising Exposure and the Quantity of Alcohol Consumed by Youth.” Journal of Studies on Alcohol and Drugs 77 (5): 723–729. https://doi.org/10.15288/jsad.2016.77.723.
- Steenkamp, J. B. E. M., and K. Gielens. 2003. “Consumer and Market Drivers of the Trial Probability of New Consumer Packaged Goods.” Journal of Consumer Research 30 (3): 368–384. https://doi.org/10.1086/378615.
- Yeh, L. T., and D.-S. Chang. 2023. “Measuring the Lagged Effects of Advertising Goodwill on Dynamic Promotional Efficiency in the Automobile Industry.” Journal of the Operational Research Society 74 (10): 2094–2108. in print. https://doi.org/10.1080/01605682.2022.2128910.
- Yule, G. 1926. “Why Do We Sometimes Get Nonsense-Correlations Between Time-Series?--A Study in Sampling and the Nature of Time-Series.” Journal of the Royal Statistical Society 89 (1): 1–64. https://doi.org/10.2307/2341482.