Abstract
This paper reports on the genetic and environmental bases of differences in reading and spelling in a large unselected adolescent twin sample. The dual route cascaded (DRC) model of reading is introduced and used to provide endophenotypes for the basic psychological functions underlying reading. The model is then extended to a complementary dual-route model for spelling with tests tapping lexical and sublexical routes to spelling. Univariate analyses of the DRC-based phenotypes are reported. Model fitting supported high levels of additive genetic control over learning to read (heritabilities of 0.73, 0.71, and 0.61 for irregular, nonword, and regular word reading respectively), with remaining variance being best modelled as unique environment (including measurement error) rather than differences between families. Again, within the power of the present design, models specifying sex-limited genetic mechanisms were not supported, suggesting that the genes for both routes to reading are the same for both sexes and control similar proportions of variance. For spelling, the heritabilities were similar for the tasks corresponding to lexical and nonlexical reading (h2 = 0.76, 0.52 respectively). The value of future multivariate analyses for testing predictions from competing psychological models of reading are discussed, as is the need for linkage and association studies and for the development of more basic endophenotypes to fully resolve the genetic architecture of this important human behaviour.
The ability to read is both a critical factor underlying access to many positive life outcomes and of great scientific interest in understanding human cognition and evolution. It has been estimated that problems with reading have been proposed to be the single most significant class of psychological disorder in adolescents (Spreen, Citation1988). While little is known about the biology of reading, heritability data from U.S. behaviour genetic studies indicate that at least half of the group deficit (based on studying readers selected from the lower 10th percentile or the normal distribution) in reading ability is genetic (DeFries, Fulker, & LaBuda, Citation1987; Olson, Wise, Conners, & Rack, Citation1989). These data strongly suggest that an understanding of the genetics of reading will be invaluable in understanding and treating this disorder. This paper reports behaviour genetic analyses conducted on data from carefully targeted tests of reading and spelling in normal adolescent Australian twins. These behavioural data form the first part of a project examining the molecular genetics of reading using linkage and association methods, and this report gives an overview of the sample, the rationale for choosing biologically-relevant “endophenotypes” (traits that may require experimental means to assess, but which are thought to be highly penetrant markers of the underlying genetic basis of a phenotype) derived from the dual route cascaded (DRC) computational model of reading (Coltheart, Rastle, Perry, Langdon, & Ziegler, Citation2001), and univariate genetic modelling of the heritability and environmental determinants of variance in DRC-based component skills for reading.
The types of questions that genetically informative samples can answer are wide-ranging (Neale & Cardon, Citation1992). Most obviously, twin studies can address the basic question of the relative importance of genetic factors in behaviours such as learning to read and spelling. The nature of environmental factors can be addressed, distinguishing between common environmental effects (effects that are shared by siblings in a family, such as home environment variables, and perhaps schooling) and unique effects (usually including error in measurement). One can thus distinguish between environmental transmission and genetic transmission of familial traits and gather valuable clues as to the locus of environmental effects. In certain samples, it is possible to distinguish gene effects that depend on dominance or epistasis. Gene × Environment interactions can be studied, and gender effects can be explored, including tests for whether genetic or environmental effects are present in a sex-limited form; that is controlling different proportions of the variance in one sex versus the other, or even being entirely absent in one of the two sexes, as might be the case for genes that are activated only in one sex. In longitudinal studies, questions can be asked as to the change in genetic and environmental effects over time, in particular whether the same genes operate at across the life cycle, and whether heritabilities increase or decline with increasing exposure to the environment. Clearly these are valuable resources, addressing questions of great interest in psychology.
Psychological theory also has a lot to offer, as well as a lot to benefit from, genetically informative data. A well-specified psychological theory can be used to generate testable expected patterns of genetic and environmental variance among groups of behavioural tests, and the relative fit of relationships predicted by competing theories can be contrasted. In the present case, we outline a theory of reading, the DRC model (Coltheart et al., Citation2001), which accounts for differences in reading skill in terms of normal variance in the modules underlying two dissociable routes for computing phonology from letter input. Data are presented on the univariate heritability of DRC-based reading measures and derivative measures of spelling. Different models of inheritance are then contrasted. We end by discussing the value of extending these analyses into a multivariate framework, and of seeking genetic linkages and associations, and we consider the kinds of measures that might best aid future study.
Phenotypes for reading
Researchers into the biological bases of reading are presented with two related challenges. First, although reading impairments are heritable, as yet their biochemical characteristics and biological origins are poorly understood (Habib, Citation2000). This places great importance on the cognitive phenotype and suggests that a molecular genetic approach may be valuable in determining the underlying causes of the disorder. Second, studies of the cognitive phenotype indicate that skilled reading depends upon the use of a network of several distinct computational modules, probably at least seven (Coltheart et al., Citation2001; Zorzi, Houghton, & Butterworth, Citation1998). A deficiency in any one of these modules may result in some or other form of reading impairment, which means that reading is a complex phenotype.
Because reading is a complex phenotype, it is widely acknowledged that genetic progress depends on moving away from high-level phenotypes, which confound the basic building blocks of reading, and towards a comprehensive and direct evaluation of the basic component processes of reading (Castles, Datta, Gayan, & Olson, Citation1999) as best represented by endophenotypes. In this paper, we assessed reading using six tests of reading and spelling developed in line with the DRC computational model of reading (Coltheart et al., Citation2001). Because extensive cognitive experimentation suggests that these phenotypes closely mirror the architecture of the reading system itself, it is hoped that their use will increase the power of linkage analyses over that possible from measures that confound the function of multiple modules, decrease the likelihood of replication failures and, importantly, provide basic endophenotypes that are more likely to relate to a manageable set of gene functions.
Dual route model
Skilled reading (both reading aloud and reading comprehension) appears to be accomplished by a mental information-processing system that is both functionally and anatomically modular, as shown by neurological case-studies in which single modules have been selectively lesioned by stroke or other forms of brain damage (Habib, Citation2000). In a recent article (Coltheart et al., Citation2001), we argued that the leading framework for understanding normal reading and dyslexia is the DRC model, which is depicted schematically in .
Figure 1. Dual route cascading (DRC) model of reading. The direct series of processes constituting the lexical route are connected with dashed lines, while the nonlexical route components are connected with dotted lines. Shared input and out components are in solid lines.
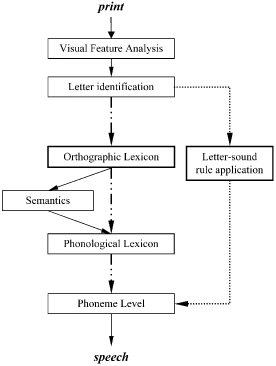
The DRC model proposes that normal reading requires the operation of multiple dissociable modules, or encapsulated processing systems, represented by the boxes in , which are connected in a network that directs processing downwards in a cascaded fashion. On presentation of a written word, initial modules detect visual features and identify letters. Then, and this is a key feature of the model, output from these common mechanisms is directed to two separate processing routes that independently compute the pronunciation of the word and then converge at the spoken word production level. The two routes are designated lexical (dashed line) and nonlexical (dotted line) to reflect their dependence on whole-of-word recognition (through access to an orthographic store or lexicon of known words) and generative or rule-based construction of phonology respectively. The two routes are distinguished by their performance on irregular words such as yacht (which the lexical route can read aloud correctly, but which the nonlexical route “regularises” due to its application of letter – sound rules, which this word violates), and nonwords such as yot, which the lexical route cannot read aloud (because there is no entry in the orthographic lexicon that matches this particular string of letters) but which the rule-based system can routinely process. Importantly, although each route depends on multiple modules, several of these are shared by both routes: It is the orthographic lexicon and letter – sound application modules that are unique to the lexical and nonlexical routes respectively and which therefore need to be isolated if pure endophenotypes are to be obtained.
Differences in reading can be seen as reflecting different levels of acquisition of elements of this system. On this view, the precise form of each child's reading skill depends upon the pattern of acquisition of elements of the system. For a considerable proportion of children identified with difficulties in reading the cause is a difficulty in acquiring letter – sound rule application. This is reflected in an inability to decode unfamiliar words into phonology or speech sounds, so the child will be unable to use sounding out as an aid to learning to read. Variance in this form of reading constitutes the differences used in defining developmental phonological dyslexia (Campbell & Butterworth, Citation1985; Castles & Coltheart, Citation1993). Other children have a specific difficulty at the level of the orthographic lexicon, that is, a difficulty in building up an extensive sight vocabulary. Reduced function in this form of reading is known clinically as developmental surface dyslexia (Castles & Coltheart, Citation1996; Hanley, Hastie, & Kay, Citation1992).
Previous phenotypic studies
Most previous studies have focussed on the heritability of group deficits among twins selected for at least one member of the twin pair being significantly (1.5 SD or more) below the mean on one or more measures of reading. Initial small studies of reading in these selected groups suggested low heritabilities, especially for lexical reading (Olson et al., Citation1989; Stevenson, Citation1991), but subsequent research has indicated substantial heritabilities for a range of reading measures in a range of samples. Castles et al. (Citation1999) reported a modest heritability of .31 for reading impairment among twins selected for one member having surface dyslexia (shared environment accounted for 63% of variance), but a much larger heritability (.67) for the same trait among twins where at least one member of each twin pair had phonological dyslexia. Subgroup selections in Castles et al.'s study were based on irregular-word and nonword reading. Similar heritabilities have been reported when alternative measures of component processes in reading have been used, such as the orthographic and phonological choice tasks of Olson and colleagues (Castles et al., Citation1999; Gayan & Olson, Citation2001), although, interestingly, orthographic choice (recognising the word in pairs such as rane and rain) was not itself highly correlated with relative nonword versus exception-word reading skill (Olson, Forsberg, & Wise, Citation1994). Very recently, data from normal, unselected samples have begun to be reported (Gayan & Olson, Citation2003). These data suggest heritabilities as high as .80 and .87 for nonlexical reading and lexical reading respectively. Spelling has been less often examined than reading, and nonword spelling analogs have not previously been submitted to genetic analysis. An early analysis of spelling in 112 monozygotic (MZ) and 86 same-sex dizygotic (DZ) twins suggested an h2 of .6 (DeFries, Stevenson, Gillis, & Wadsworth, Citation1991), without distinguishing the type of word spelled.
The present research examines reading in a normal unselected sample, using DRC-derived reading measures, and analogous measures of spelling. It forms one of very few studies to examine the heritability of reading in an unselected sample, and provides preliminary data for further multivariate and linkage studies on the genetic and environmental relationships between lexical and nonlexical routes to reading and to spelling.
Method
Subjects
The results reported here are based on data collected from late July 2002 through April 2003 as part of an ongoing study of melanocytic naevi (moles). These participants were enlisted between 1992 and 1999 by contacting the principals of primary schools in the greater Brisbane area, media appeals and by word of mouth. Informed consent was obtained from all participants and parents prior to testing. Blood was obtained from twins, siblings and most parents for blood grouping and DNA extraction. Parents were also asked the ancestry of all eight great-grandparents of the twins. More than 95% of great-grandparents were identified as being of northern European ancestry, mainly from Britain and Ireland. Further details are reported by McGregor et al. (Citation1999) and the clinical protocols have been described in detail elsewhere (Wright et al., Citation2001; Wright & Martin, 2004). Reading and spelling data were collected from 541 families. Although nontwin siblings were also sampled, only data from twins are reported in the current analyses. The mean age of the twins in this sample was 18.5 years (SD = 2.7). Participants received a thank you letter and two complimentary movie tickets for their participation.
Measures
Each twin received an approach pack in the mail. The approach pack contained a letter describing the study and the reading and spelling assessment instruments in a sealed envelope marked “Reading List: Please DO NOT open until an interviewer calls you. Reading the list prior to the phone call will disqualify the reading test” along with separate materials for other studies being conducted in this group (measures of laterality, personality, olfactory and gustatory perception, and attitudes towards parenting).
Reading test
Regular-word, irregular-word and nonword reading were assessed using a 120-word extended version of the Castles and Coltheart tests (Castles & Coltheart, Citation1993) with additional items added to increase the difficulty of this test for an older sample (see Appendix A). Irregular words are proposed to provide a pure test of lexical reading, because the nonlexical route will sound them out incorrectly. Conversely, nonwords allow for a pure test of nonlexical reading because entries for nonwords will not be contained in the lexicon. Regular words can be read correctly by either the lexical or the nonlexical route. Words were presented in a mixed order to avoid blocking effects.
Spelling tests
Regular- and irregular-word spelling was tested by verbally presenting 18 regular words and 18 irregular words in random order and recording the subjects' oral spelling of the words. The items were one-to-one matched on frequency, number of phonemes and grammatical class (see Appendix B). Regular words, of course, cannot be used as a pure test of nonlexical spelling because these can also be spelled using the lexical system. It is difficult to assess nonword spelling because subjects often are not able to unambiguously identify the desired phonetic target from the verbal stimulus and, because of this, spelling errors cannot be categorised as being due to incorrect spelling of an accurately perceived target (as opposed to incorrect initial identification of the target nonword).
In order to examine nonlexical spelling skills, a new test was developed that was designed to be an analog of nonword spelling. The test involved subjects spelling the words given in the irregular spelling test under a different set of instructions requiring them to regularise the spellings. Subjects were told:
“Next I am going to read 18 of those words back to you again. This time, I would like you to give me a spelling for each word so that someone who had never seen the word could still pronounce it properly. For example, if I gave you the word “yacht” you could say “Y O T”. Do you understand?”
Each word was then presented verbally, and the letter string used for spelling was recorded. Words were repeated on request. The acceptable strings for a correct response are given in Appendix C.
Procedure
Within 2 weeks of the approach pack being mailed a trained researcher interviewed each participant over the telephone. The rationale for the study was explained and if consent was obtained subjects either completed the reading test during this contact, or at a later pre-arranged time. As a validity check, each subject was asked if they had opened the envelope prior to testing (none reported opening the envelope before testing) and whether they agreed to re-test if required. Four sibpairs (three male DZs and one male MZ pair) required re-testing (data from these pairs were anomalous in that one twin was discordant from the sample mean or from their co-twin by 4-5 z-score units on a single test, against a background of otherwise normal performance). These eight subjects are being followed up for retest to exclude the possibility that their initial results were due to a tester error, data transcription errors, or to noncompliance or misunderstanding of test instructions. Their data are not included in the present analyses. The reading tests, mixed regular- and irregular-word spelling test, and regularisation-spelling tests were then given, in that order. Each test was given in accordance with the instructions outlined above, and responses were recorded for subsequent scanning into a database. Testing took less than 15 min. If a blood sample had not yet been obtained, this was also arranged at this time, if the subject consented.
Test scores on each of the three reading subtests and three spelling tests were calculated as a simple sum of correct items. Prior to analysis, all raw data were log-odds transformed and normalised. The age-adjusted polychoric correlations between the different tests are shown in , separately for male and female subjects.
Table I. Age-adjusted polychoric correlations
Analyses
Zygosity.
Zygosity in the same-sex twin pairs was diagnosed by typing eight highly polymorphic DNA microsatellite markers and three blood groups (ABO, MNS, Rh). The probability of dizygosity, given concordance for all markers in our panel, was < 10 – 3. In 50 pairs of twins for whom DNA was not available, zygosity was judged by similarity of appearance based on photographs supplied by the respondents. Such procedures have previously demonstrated at least 95% agreement with diagnoses based on extensive blood sampling (Martin, Citation1975; Ooki, Yamada, Asaka, & Hayakawa, Citation1990). The number of complete and incomplete twin pairs, tabulated separately by zygosity and test, are shown in .
Table II. No. complete and incomplete twin pairs by zygosity
Analysis of raw continuous data.
The application of raw data methods to continuous data, based on multivariate normal theory, enables the preliminary testing of basic assumptions concerning the equality of means and variances within twin pairs, across sex and zygosity, as well as tests of hypotheses about the covariance structure. Because this approach uses both complete and incomplete twin pair data, it has the added advantage of increasing the accuracy of the estimation of the means and variances, thereby improving the covariance estimates. The scripts used are available for download at: www.maccs.mq.edu.au/∼tim/research/reading/mxscripts/
Genetic analyses.
General, common and scalar sex-limitation univariate genetic models were fitted to the data by the method of maximum likelihood in Mx (Neale, Boker, Xie, & Maes, Citation2002) to decompose the total variance in the observed measures into variance attributable to A (additive genetic effects), D (genetic dominance effects), C (common environment) and E (unique environment, including measurement error). Because MZ twins are genetically identical, the correlations for additive and nonadditive genetic effects between MZ twins are both 1. For DZ twins, the correlations for additive and nonadditive genetic effects are 0.5 and 0.25 respectively. These relationships are summarised in the path diagram shown in .
Figure 2. Univariate genetic sex limitation model. A, C, and E are latent variables representing additive genetic, shared environmental and unique variance. A′ is a sex-specific latent variable, able to account for genetic effects present in one sex but not the other. Pf and Pm are the observed phenotypes of the two twins, distinguished by sex (f = female, m = male) for dizygotic twins (DZs) differing in sex. Alpha (α) is the genetic correlation between the two twins, set at 1 for monozygotic (MZ) and .5 for DZ twins. β is the shared environmental coefficient, set at .5 for all twins (all twins in this sample shared the same home environment). Parameters af, cf, ef, and am, cm, em, and a′ are the path coefficients that we estimate under a maximum likelihood model, and which, in standardised form, represent our estimates of the genetic, common, and unique sources of variance for the reading and spelling phenotypes. In the analyses presented here, a model in which the a, c, and e path coefficients were allowed to differ between the sexes was estimated as the saturated model against which less complex models were tested.
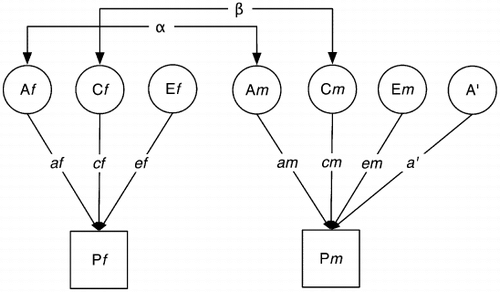
In the absence of data from separated twin pairs, half siblings, or similar pairs of relatives, nonadditive and shared environmental effects are confounded, so that only one can appear in a given model. Current methods use structural equation modelling (SEM) to decide which combination of the four parameters (A, C, D, and E) provides the most parsimonious explanation of the observed pattern of MZ and DZ twin correlations (Neale & Cardon, Citation1992) while at the same time estimating the size of the genetic and environmental parameters. An important assumption of the biometrical model is that shared environmental effects correlate to an equal extent in MZ and DZ twin pairs (Kendler, Neale, Kessler, & Heath, Citation1994; Xian et al., Citation2000). Detecting dominance is unlikely given the large sample sizes required, and, because it is inconceivable that complex behavioural traits can be measured without error, all models include an estimate of E.
Briefly, general sex-limitation models hypothesise that in addition to a common set of genetic and environmental factors influencing the trait in male and female subjects, there are additional, sex-specific genetic effects uncorrelated across sex. Common sex-limitation models are restricted to common genetic and environmental factors that are unconstrained across sex. Scalar sex-limitation models remove sex-specific effects and constrain the variance components for female subjects to be equal to a scalar multiple (k2) of the male variance components. Both the common and scalar sex-limitation models are nested within the general sex-limitation model and goodness of fit statistics can be used to compare models. Under maximum likelihood, twice the difference in log-likelihood between the full and the nested models is asymptotically distributed as a chi-square statistic, with the degrees of freedom for each test equalling the difference in degrees of freedom between the full and nested models.
Results
The means and standard deviations of the raw scores for each of the six tests are shown in . No differences in the means for the reading and spelling measures were observed between first and second twins or across zygosity for any of the variables. Significant sex differences were observed for lexical processing (spelling and reading of irregular words) and spelling regular words, whereas constraining the male and female means to be equal provided a good fit for the nonlexical tasks (nonwords reading and spelling by regularisation) as well as regular word reading. A model constraining the variance to be equal for first and second twins, across zygosity and across sex fitted the data well for all measures. There were several minor within-twin pair variance differences for irregular reading, as well as within-sex differences for nonword reading and spelling by regularisation, but no more than would be expected by chance given the number of comparisons for means and variances performed.
Table III. Six measures of reading and spelling
Twin pair correlations and covariance comparisons
Age-corrected maximum likelihood twin pair polychoric correlations and 95% confidence intervals for each variable are shown in . For every variable, MZ correlations were larger than their DZ counterparts, and for most of the measures of reading and spelling, the DZ correlations were clearly larger than half their MZ counterparts suggesting common environmental effects (rather than dominance). A model that fixed MZ and DZ correlations to zero gave a very poor fit in every case, indicating significant twin pair resemblance for each measure. Likewise, a model constraining the MZ and DZ twin pair correlations to be equal fitted worse than a model allowing for MZ and DZ twin pair correlations to vary freely. This suggests that additive gene action is a significant source of familial aggregation. We next fitted univariate models to the data in order to test more formally the sources of variation.
Table IV. Twin pair correlations (95%CI)
Genetic analyses
Based on observed covariance structure, phenotypic variance was modelled as a product of additive genetic variance (A), common environment (C: nongenetic effects shared by each twin), and unique variance (E: nongenetic effects not shared by co-twins, including measurement error). In this paper we report univariate models for each of the six tests of reading and of spelling, comparing the goodness-of-fit of successively restrictive models. For each test, a nonscalar (general) sex limitation model (Neale & Cardon, Citation1992) was constructed in which the A, C, and E parameters were allowed to differ for male and female subjects, and, in addition, sex-specific additive genetic effects were modelled (A′). The variables comprising the saturated nested alternative models are shown in .
The saturated model (I) was compared to three reduced models: A common-effects sex-limitation model (dropping the sex-specific A′ factor: Model II); a model with a scalar sex limitation factor (Model III); and a final univariate ACE model, equating A, C, and E parameters across gender: Model IV.
Reading.
Phenotypic modelling of the three single-word reading measures is presented in . For each reading measure, Model IV, which constrained the sources of variance to be qualitatively and quantitatively equal across sex, provided the most parsimonious fit to the data. For each measure, the preferred model could be further simplified by dropping the common environmental parameter without any significant change in the log-likelihood when compared to the saturated ACE model. Familial aggregation for the three reading measures could be entirely explained by additive genetic effects accounting for 73%, 61% and 71% of the variance in irregular word reading, nonword reading and regular word, respectively. The remaining sources of variance were attributable to unique environmental effects including measurement error.
Table V. Univariate model reduction and standardised variance components for reading
Spelling.
Phenotypic modelling results for the three spelling measures are shown in . The preferred models for spelling mirrored those for reading with one exception. As in the case of the reading measures, the sex-limitation models were rejected. Instead, a model (IV) in which the sources of variance were qualitatively and quantitatively the same across sex provided the best fit for the spelling measure data. The common environmental parameters for irregular-word spelling and spelling by regularisation, but not regular-word spelling, could also be dropped from the saturate ACE model without any significant change in the log-likelihood. Common environmental effects accounted for 19% of the variance in regular word spelling while additive genetic effects explained 76%, 41% and 52% of the variance in irregular, regular and regularisation-based spelling respectively.
Table VI. Univariate model reduction and standardised variance components for spelling
Discussion
The present analyses indicate that all six measures of reading and spelling have substantial heritabilities, with additive genetic effects accounting for around three quarters of the variance in reduced models, and unique environment (including measurement error) accounting for the remaining variance. With the moderate power of the present sample, there was insufficient evidence to support effects of shared environment. In no case did any form of sex-limited models fit the data better than models without sex-specific effects. This is one of the only analyses to examine sex-differences, and suggests that the causes of variance in reading are common and have common patterns of expression across both male and female readers. Again, much larger samples may detect effects too small to be significant in our analyses. Regular-word reading, predicted to reflect the output of the lexical and nonlexical routes, also showed a similar pattern of familial aggregation to that of lexical and nonlexical reading and spelling. Because this is one of only a very few phenotypic analyses of spelling, and the only analysis to distinguish between routes to spelling as predicted by the dual route model, the data on spelling were of particular interest. The spelling models mirrored those for reading, with some suggestion of shared environment effects on regular spelling. Future multivariate analyses addressing the common basis of variance in spelling and reading will therefore be valuable and are discussed below.
Because many previous studies have used populations selected for one or more sibs having a reading disorder, the present data support the value of normal samples, free from the biases that potentially confound more selective samples, in demonstrating heritable variance in clinically important traits, suggesting that substantial genetic variance exists within this normal group. The magnitude of these heritabilities supports the finding that much of the variance in reading in Western countries is heritable (Gayan & Olson, Citation2003).
In line with our view of reading as the orchestrated functioning of several separate, normally distributed, processes, the data suggest that the same genetic and environmental variance that is involved in more extreme difficulties in reading may be implicated in normal, skilled reading and spelling. Future work on this sample will report genome-wide scan analyses for the two core components of reading identified by DRC, and fine-mapping analyses for each of these phenotypes at existing candidate linkage sites, but it is clear both that theoretically valid phenotypic measures are valuable in articulating traits for multivariate behaviour and genetic analysis, and that tests which target specific components within the dual-route model itself will be of particular value in advancing our understanding of the genetic bases of reading.
Future linkage studies
Although progress has been made in genetic research on reading, in particular linkage to chromosome 6 (Cardon et al., Citation1994; Gayan et al., Citation1999; Smith, Kimberling, Pennington, & Lubs, Citation1983), no genes have yet been found. Understanding the functional role of the genes at these sites would represent a fundamental breakthrough in our understanding of reading.
In part, characterising gene function relies on adequate specification of the phenotypes controlled by these genes. Although traits as broad as vocabulary and single-word reading and as (relatively) narrow as nonword reading are linked to sites such as chromosome 6, these phenotypes are known not, in fact, to be basic psychological processes. As discussed previously, impaired nonword reading can be the outcome of disruptions at a number of discrete sites within the DRC model: visual feature analysis, letter identification, letter – sound rule application, and the phoneme level (see ). Future research, then, should pursue these still-more basic phenotypes.
Further genome-wide scans are also required: the currently known linkages are insufficient to account for the known levels of heritability for reading disorder. Thus, it is clear that a genome-wide scan is likely to uncover additional linkage sites in the absence of additional phenotypic or endophenotypic information.
Multivariate studies
It will be valuable to apply full multivariate analysis methods to the current data. This will happen shortly, when all available subjects have been contacted and assessed. A potential 100 additional subjects are available, which will increase the power of the study somewhat. Phenotypically, multivariate studies will allow us to determine whether the genetic causes of variance in reading and in spelling overlap, and, if so, if they overlap along lines predicted by the dual route model. Multivariate analyses of the phenotypes will also be able to indicate if reading and spelling of regular words are determined by the genetic and environmental influences affecting lexical and nonlexical reading (which we predict from the dual route model of reading) or whether they have their own unique genetic or environmental sources of variance. In combination with genetic data, it will also be possible to examine the association of existing (and new) genetic linkage markers to each of the cognitive modules within the dual route model, and to understand why the particular patterns of association occur in terms of the cognitive processes affected by these linkages. For example, markers on chromosome 6 have been linked with both irregular-word reading and nonword reading (Gayan et al., Citation1999; Marlow et al., Citation2003). Such joint-linkage may suggest a role for the gene in the C6p22 (a region on the short arm of chromosome 6) region in modules that are shared by both DRC routes for reading. One might predict, then, that the linkage here is for letter input or phonological output. Alternatively, the linkage may reflect a biochemical or structural factor affecting the neural processes of both lexical access and nonlexical grapheme – phoneme conversion. Only work with the power of large samples and specific phenotypes targeting these components can answer these questions, and it is hoped that such studies can be completed.
Finally, as the full nomological network of genes, causal pathways, psychological variables and outcomes becomes better understood, new possibilities for research become apparent. As genetics helps to explain the origin of the different types of reading skill that we observe, it may also allow genetic predictions to contrast theories of reading such as the dual route model, which we have adopted to models of reading such as the triangle models (Harm & Seidenberg, Citation1999), which do not utilise separate systems for grapheme – phoneme correspondence and whole-word lexical access, but rather rely on the learning of a single distributed network to generate both of these effects. Although both types of model agree that different types of dyslexia occur (Curtin, Manis, & Seidenberg, Citation2001) they differ in very basic ways in how they explain reading. Multivariate modelling of the present data may be used to test for evidence for separate genetic or environmental sources for the dual routes proposed by DRC, or to reject such models in favour of single shared genetic and environmental source, shared by all forms of word reading. It is also the case that both the psychological and biological causes of failure to read (either lexically or nonlexically) are currently an open question: there are several candidates, for instance rapid temporal sequencing as an on-line aid requisite to decoding graphemes into phonemes, and working memory constraints on learning new symbol – sound connections as a basis for accumulating the lexicon. Covariance (or lack thereof) of traits such as temporal sequence skill and phonological loop length with the genes for reading would provide powerful tests of these hypothesised causes of reading.
- Campbell, R, and Butterworth, B, 1985. Phonological dyslexia and dysgraphia in a highly literate subject: A developmental case with associated deficits of phonemic processing and awareness, Quarterly Journal of Experimental Psychology A 37 (1985), pp. 435–475.
- Cardon, LR, Smith, SD, Fulker, DW, Kimberling, WJ, Pennington, BF, and DeFries, JC, 1994. Quantitative trait locus for reading disability on chromosome 6, Science 266 (5183) (1994), pp. 276–279.
- Castles, A, and Coltheart, M, 1993. Varieties of developmental dyslexia, Cognition 47 (1993), pp. 149–180.
- Castles, A, and Coltheart, M, 1996. Cognitive correlates of developmental surface dyslexia: A single case study, Cognitive Neuropsychology 13 (1996), pp. 25–50.
- Castles, A, Datta, H, Gayan, J, and Olson, RK, 1999. Varieties of developmental reading disorder: Genetic and environmental influences, Journal of Experimental Child Psychology 72 (1999), pp. 73–94.
- Coltheart, M, Rastle, K, Perry, C, Langdon, R, and Ziegler, J, 2001. DRC: A dual route cascaded model of visual word recognition and reading aloud, Psychological Review 108 (2001), pp. 204–256.
- Curtin, S, Manis, FR, and Seidenberg, MS, 2001. Parallels between the reading and spelling deficits of two subgroups of developmental dyslexics, Reading & Writing 14 (5 – 6) (2001), pp. 515–547.
- DeFries, JC, Fulker, DW, and LaBuda, MC, 1987. Evidence for a genetic aetiology in reading disability of twins, Nature 329 (6139) (1987), pp. 537–539.
- DeFries, JC, Stevenson, J, Gillis, JJ, and Wadsworth, SJ, 1991. Genetic etiology of spelling deficits in the Colorado and London twin studies of reading disability, Reading & Writing 3 (3 – 4) (1991), pp. 271–283.
- Gayan, J, and Olson, RK, 2001. Genetic and environmental influences on orthographic and phonological skills in children with reading disabilities, Developmental Neuropsychology 20 (2001), pp. 483–507.
- Gayan, J, and Olson, RK, 2003. Genetic and environmental influences on individual differences in printed word recognition, Journal of Experimental Child Psychology 84 (2003), pp. 97–123.
- Gayan, J, Smith, SD, Cherny, SS, Cardon, LR, Fulker, DW, Brower, AM, et al., 1999. Quantitative-trait locus for specific language and reading deficits on chromosome 6p, American Journal of Human Genetics 64 (1999), pp. 157–164.
- Habib, M, 2000. The neurological basis of developmental dyslexia: An overview and working hypothesis, Brain 123 (2000), pp. 2373–2399.
- Hanley, JR, Hastie, K, and Kay, J, 1992. Developmental surface dyslexia and dysgraphia: An orthographic processing impairment, Quarterly Journal of Experimental Psychology A 44 (1992), pp. 285–319.
- Harm, MW, and Seidenberg, MS, 1999. Phonology, reading acquisition, and dyslexia: Insights from connectionist models, Psychological Review 106 (1999), pp. 491–528.
- Kendler, KS, Neale, MC, Kessler, RC, and Heath, AC, 1994. Parental treatment and the equal environment assumption in twin studies of psychiatric illness, Psychological Medicine 24 (1994), pp. 579–590.
- Marlow, AJ, Fisher, SE, Francks, C, MacPhie, IL, Cherny, S, Richardson, A, et al., 2003. Use of multivariate linkage analysis for dissection of a complex cognitive trait, American Journal of Human Genetics 72 (2003), pp. 561–570.
- Martin, NG, 1975. The inheritance of scholastic abilities in a sample of twins. II. Genetical analysis of examinations results, Annals of Human Genetics 39 (1975), pp. 219–229.
- McGregor, B, Pfitzner, J, Zhu, G, Grace, M, Eldridge, A, Pearson, J, et al., 1999. Genetic and environmental contributions to size, color, shape, and other characteristics of melanocytic naevi in a sample of adolescent twins, Genetic Epidemiology 16 (1999), pp. 40–53.
- Neale, MC, Boker, SM, Xie, G, and Maes, HH, 2002. "Mx: Statistical Modelling". 2002, (6th ed.). VCU Box 900126, Richmond, VA 23298: Department of Psychiatry, University of Virginia.
- Neale, MC, and Cardon, LR, 1992. Methodology for genetic studies of twins and families, (1992), Kluwer Academic Publishers.
- Olson, RK, Forsberg, H, and Wise, B, 1994. Genes, environment, and the development of orthographic skills, (1994), p. pp. 27 – 71, In V. W. Berninger (Ed.), The varieties of orthographic knowledge, 1: Theoretical and developmental issues, New York: Kluwer Academic Publishers.
- Olson, RK, Wise, B, Conners, F, and Rack, J, 1989. Specific deficits in component reading and language skills: Genetic and environmental influences, Journal of Learning Disabilities 22 (1989), pp. 339–348.
- Ooki, S, Yamada, K, Asaka, A, and Hayakawa, K, 1990. Zygosity diagnosis of twins by questionnaire, Acta Genetica Medica et Gemellologica (Roma) 39 (1990), pp. 109–115.
- Smith, SD, Kimberling, WJ, Pennington, BF, and Lubs, HA, 1983. Specific reading disability: Identification of an inherited form through linkage analysis, Science 219 (4590) (1983), pp. 1345–1347.
- Spreen, O, 1988. Prognosis of learning disability, Journal of Consulting and Clinical Psychology 56 (1988), pp. 836–842.
- Stevenson, J, 1991. Which aspects of processing text mediate genetic effects?, Reading and Writing 3 (3 – 4) (1991), pp. 249–269.
- Wright, M, De Geus, E, Ando, J, Luciano, M, Posthuma, D, Ono, Y, et al., 2001. Genetics of cognition: outline of a collaborative twin study, Twin Research 4 (2001), pp. 48–56.
- Wright, M, and Martin, NG, 2004. The Brisbane Adolescent Twin Study: Outline of study methods and research projects, Australian Journal of Psychology 56 (2004), pp. 65–78.
- Xian, H, Scherrer, JF, Eisen, SA, True, WR, Heath, AC, Goldberg, J, et al., 2000. Self-reported zygosity and the equal-environments assumption for psychiatric disorders in the Vietnam Era Twin Registry, Behavior Genetics 30 (2000), pp. 303–310.
- Zorzi, M, Houghton, G, and Butterworth, B, 1998. Two routes or one in reading aloud?, 24 (1998), pp. 1131–1161, A connectionist dual-process model. Journal of Experimental Psychology: Human Perception & Performance.