
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This paper presents an online adaptive approximate solution for the optimal tracking control problem of model-free nonlinear systems. Firstly, a dynamic neural network identifier with properly designed weights updating laws is developed to identify the unknown dynamics. Then an adaptive optimal tracking control policy consisting of two terms is proposed, i.e. a steady-state control term is established to ensure the desired tracking performance at the steady state, and an optimal control term is proposed to ensure the optimal tracking error dynamics optimally. The composite Lyapunov method is used to analyse the stability of the closed-loop system. Two simulation examples are presented to demonstrate the effectiveness of the proposed method.
1. Introduction
The basic idea of the classical adaptive control is to update the model parameter and control law directly or indirectly, such that the control error can be minimized. However, it is generally not optimal. On the other side, the main drawback of the classical optimal control approach lies in that the system dynamics must be precisely known for solving the Hamilton-Jacobi-Bellman (HJB) equation in an off-line manner [Citation1]. Hence, by merging the knowledge from adaptive control and optimal control, the adaptive optimal control approach has been developed during the past decade and a survey of this research can be found in [Citation2–4].
To develop an online adaptive optimal control, Werbos [Citation5] introduced the general actor-critic (AC) framework for adaptive optimal control. The critic neural network (NN) approximates the evaluation function, mapping states to an estimated measure of the value function, whereas the NN approximates an optimal control law and generates the actions or control signals. Since then, various modifications to adaptive optimal control algorithms have been proposed as model-based methods (heuristic dynamic programming – HDP [Citation6] and dual heuristic programming-DHP [Citation7]) and model-free methods (action-dependent heuristic dynamic programming – ADHDP [Citation8] and Q learning [Citation9]). However, most of the previous works on adaptive optimal control have focused on discrete-time systems. The extensions of these adaptive optimal control research to continuous-time systems pose challenges in proving stability, convergence and ensuring the online updating law with model free [Citation10].
Discretizinging the continuous time system is generally not accurate, especially for the high-dimensional systems that prohibit the learning process. Hence, the online policy iteration-based algorithms are proposed to solve the linear [Citation11] and nonlinear [Citation12] continuous-time infinite horizon optimal control problems, which involve synchronous adaptive of both actor and critic NN. Furthermore, ref. [Citation10] extended the idea in refs. [Citation11,Citation12] by designing a novel AC-identifier architecture to approximate the HJB equation without the knowledge of system drift dynamics, but the knowledge of the input dynamics is required. The recent research in [Citation13] cancels this requirement by using the experience iteration technique. Based on ref. [Citation10], a simply identifier-critic structure-based optimal control method is proposed in [Citation14,Citation15], where just a critic NN is used to approximate the solution of the HJB equation and to calculate the optimal control action. In [Citation16], an optimal control method for nonzero-sum differential games of continuous-time nonlinear systems is designed directly from the critic NN instead of the action-critic dual network, which greatly simplifies the algorithm architecture.
Most of the existing adaptive optimal research studies mainly focus on dealing with regulation problems rather than trajectory tracking problems. The combined consideration of two aspects can ensure not only the realization of trajectory tracking and stabilization but also satisfying the prescribed performance index (such as minimization of the trajectory error, fuel consumption, etc.). In [Citation17] a new data-based iterative optimal learning control scheme is developed to solve a coal gasification optimal tracking control problem in the discrete-time domain. For continuous-time systems, linear quadratic tracking control of partially-unknown systems using reinforcement learning is present in [Citation18] and a nonlinear approximately optimal trajectory tracking method with exact model information is developed in [Citation19]. To relax the requirement of an explicit model, a steady-state control conjunction with an optimal control for nonlinear continuous-time systems is developed in [Citation20], which stabilizes the error dynamics in an optimal way.
Most of the above-mentioned adaptive optimal control method is based on the affine nonlinear system, to the best of our knowledge, only [Citation21] addressed the adaptive optimal control of unknown non-affine nonlinear systems in the discrete-time domain and [Citation22] introduces an adaptive recursive control for the model-based non-affine nonlinear continuous system. The optimal control of an unknown non-affine nonlinear continuous-time system is still a challenging task, which is the motivation of this paper.
The main contributions of this paper are listed as follows.
(1) The optimal tracking control of unknown non-affine nonlinear systems based on the critic identifier architecture is first proposed in this paper. Model-free property is achieved by a neuro identifier in conjunction with the novel updating laws for both the weights and the linear part matrix which is usually assumed to be a known Hurwitz matrix for the conventional black-box nonlinear system identification.
(2) Adaptive optimal tracking control policy consisting of two terms is proposed, i.e. a steady-state control term is established to ensure the desired tracking performance at the steady state, and an optimal control term is proposed to ensure the optimal tracking error dynamics. Online solution of the optimal control term is obtained directly by a single critic NN to approximate the optimal cost function of the HJB equation instead of the conventional action-critic dual network, which greatly reduces complexity and saves calculation time. A novel learning law driven by filtered parameter error is proposed for critic NN. The stability of the entire closed-loop system is proved by the properly designed composite Lyapunov method.
The main organization of the paper is as follows. The problem formulation is given in Section 2. The DNN identifier is designed in Section 3. Then, the optimal control strategy, based on the critic-identifier architecture, is present in Section 4. Two simulation examples are presented to verify the proposed scheme in Section 5 and the conclusion is drawn in Section 6.
2. Problem formulation
Consider the following non-affine nonlinear continuous-time systems
(1)
(1) where
is the state vector,
is the control input vector and
is an unknown continuous nonlinear smooth function for
and
.
The objective of the optimal tracking control problem is to design an optimal controller (1) to ensure that the state vector tracks the specified trajectory
and minimize the infinite horizon performance cost function as follows:
(2)
(2) where the tracking error is defined as
, the utility function with symmetric positive definite matrices
and
is defined as
.
From the basic optimal control theory, we define the Hamiltonian of (1) as
(3)
(3) where
denotes the partial derivative of the cost function
with respect to
.
The optimal cost function is given as
(4)
(4) and it satisfies the HJB equation
(5)
(5) where the control
is defined to be admissible for (2) on a compact set
, denoted by
.
Theoretically, the optimal control for nonlinear system (1) can be obtained from Equations (4) and (5). However, optimal control cannot be obtained in practical systems due to two reasons: 1). The optimal cost function should be obtained by solving the HJB equation (5). However, it is usually difficult to solve the high-order nonlinear partial differential equation (PDE) for general nonlinear systems via analytical methods. Moreover, the unknown nonlinear dynamic
makes the solution unavailable for HJB Equation (2). The idea of optimal control
cannot be derived by solving
due to the unavailability of
.
In this paper, we develop a critic-identifier to solve the optimal control of an unknown non-affine nonlinear continuous-time system, all the learning processes can be updated online.
3. Adaptive model-free identifier
We employ the following dynamic neural network (DNN) model to approximate the nonlinear dynamic system (1)
(6)
(6) where
is the state of the DNN,
are the weights in the output layers,
are the weights in the hidden layer,
is the matrix for the linear part of NNs,
is the control input, the active function
(as well as
) is the sigmoidal vector function which is defined as
, where a, b and c are constants.
Remark
If we define
, then (6) can be written as
. It has been proved in [Citation23] that DNN with the form
can approximate the nonlinear system (1) to any degree of accuracy if the hidden layer
is large enough. Here, to simplify the analysis process, we consider the simplest structure (i.e.
).
Then the nonlinear system (1) can be modelled by the DNN as follows:
(7)
(7) where
,
are the nominal unknown matrices and
are bounded as
(
are any positive definite symmetric matrices), and
is regarded as the modelling error or disturbance and is assumed to be bounded.
Assumption
The identification error is defined by . The difference in the activation function
satisfies the generalized Lipshitz condition
, and
is the known normalizing matrices.
Then from (6) and (7), we can obtain the error dynamic equation
(8)
(8) where
Lemma
[Citation24]
is a Hurwitz matrix,
,
if
is controllable,
is observable and
is satisfied, the algebraic Riccati equation
has a unique positive definite solution
.
Theorem
Consider the identification scheme (6) for (1), the following updating law
(9)
(9) where k1, k2 and k3 are positive constants, can guarantee the following stability properties:
For a precise identifier case i.e.
For bounded modelling error and disturbances i.e.
Proof:
Consider the Lyapunov function candidate
(10)
(10)
Hence (15) becomes
(16)
(16) Case 1: For precise identifier case i.e.
, (16) becomes
(17)
(17) From (17) we get
. Furthermore, from the error dynamics (8) we have
. By integrating (17) on both sides from 0 to ∞, we have
, which implies that
. Since
and
, using Barbalat's Lemma we have
.
Case 2: For bounded modelling error and disturbances i.e. . Equation (16) can be represented as
(18)
(18) where
.
Since ,
,
,
are
functions,
is the ISS-Lyapunov function. Using Theorem 3.1 in [Citation24], the dynamics of the identification error (8) is input to state stable, which implies
. This completes the proof of Theorem 3.1.
4. Optimal control design
In this section, adaptive optimal control is designed based on the DNN identifier. From Section 3, we know that a nonlinear system (1) can be represented by DNN with the updating law (9) as follows:
(19)
(19) where the model error
is still assumed to be bounded
.
and
are bound as Theorem 3.1.
Then (19) can be further rewritten as
(20)
(20) where
. For bounded
and
,
is bounded as well i.e.
.
To achieve optimal tracking control, the control action u is designed as where
is the steady-state control which ensures that the tracking error is at the steady state, and
is the adaptive optimal control which is used to minimize the infinite horizon performance index function optimally.
should be designed to compensate for the nonlinear dynamic in (20). Hence, let
be
(21)
(21) where
denotes the state tracking error,
is the feedback gain and
denotes the generalized inverse of
.
From (20) and (21), the error dynamic equation becomes
(22)
(22) In this case, the tracking problem with (20) is transferred to the regulator problem of (22). The adaptive optimal control
is designed to stabilize (22) optimally. Hence rewrite the infinite horizon performance cost function (2) as
(23)
(23) where
is the utility function with the optimal control
.
According to the optimal regulator problem design in [Citation25], an admissible control policy should be designed to ensure that the infinite horizon cost function (23) related to (22) is minimized. So, design the Hamiltonian of (22) as
(24)
(24) where
is the partial derivative of the value function with respect to e.
Then we define the optimal cost function as
(25)
(25) and it satisfies the following HJB equation
(26)
(26) The last optimal control value
for (22) can be obtained by solving
from (24)
(27)
(27) where
is the solution of the HJB equation (26).
From (27), we can learn that the optimal control value is based on the optimal value function
. However, it is difficult to solve the nonlinear partial differential HJB equation (26) to obtain
. The usual method is to get the approximate solution via a critic NN as [Citation4,Citation5,Citation25]. A single-layer NN will be used to approximate the optimal value function
(28)
(28) and its derivative is
(29)
(29) where
is the nominal weight vector,
is the active function and
is the approximation error, I represents the number of neurons.
and
are the partial derivatives of
and
with respect to e, respectively.
Assumption
The nominal weight vector , the active function
and its derivative
are all bound, i.e
.
Then substituting (28) with (27), one obtains
(30)
(30) The critic NN is approximated as
(31)
(31) where
is the estimation of the nominal
.
Then the approximate optimal control can be obtained from (30) and (31)
(32)
(32)
Remark
The available adaptive optimal control method is usually based on the dual NN architecture, where the critic NN and action NN are employed to approximate the optimal cost function and optimal control policy, respectively. The complicated structure and computational burden make it difficult for practical implantation. In the following, we will calculate the optimal control action directly from the critic NN instead of the action-critic dual network.
Substituting (28) with (24), one obtains
(33)
(33) where
is the residual HJB equation error due to the DNN identifier error
and NN approximation error
.
Then (33) can be written as the general identification form as
(34)
(34) where
,
.
According to the least square method learning rules, one can get the estimation of nominal as
in the case of residual HJB equation error equals zero. However,
is not always zero and it is also difficult to finish the subsequent closed-loop stability analysis based on the least square method. Inspired by [Citation14,Citation26], we develop a novel robust estimation method of
. The following equation is used to identify (34)
(35)
(35) where
can be assumed to be the model error and unknown disturbance.
For (35), the filtered version of is defined as
(36)
(36) where
is a positive constant,and z is an auxiliary variable.
We further define the auxiliary variables and
as
(37)
(37) where
is a filter parameter. It should be noted that the fictitious filtered variable
is just used for analysis.
Then we get
(38)
(38)
(39)
(39) From the first equation in (36), one obtains
(40)
(40) According to (38), (39) and (40), we have
(41)
(41) Furthermore, we define the auxiliary regression matrix
and vector
as
(42)
(42) where
is a positive constant as defined in (37).
The solution of (42) is derived as
(43)
(43) Finally, we denote a vector M as
(44)
(44) The adaptive law for updating
is provided by
(45)
(45) where
is the learning gain.
Theorem
For system (34) with the updating law (44) then the value function weight error converges to a compact set around zero.
Proof:
The Lyapunov function is selected as
(46)
(46)
It can be seen from [Citation26] that the persistently excited (PE) for can make the matrix defined in (43) is positive define, i.e.
Then according
, the derivative of (46) is calculated as
(48)
(48) Then
converges into the compact set
Theorem
For system (1) with an adaptive optimal control signal (21) and (32) and adaptive laws (9) and (45), the tracking error e is uniformly ultimately bound, and the optimal control
in (32) converges to a small bound around its ideal optimal solution
in (30).
Proof:
Design the Lyapunov function as
where
can be expressed as (10) and the time derivative of (18) satisfies the following inequality
(49)
(49)
Substituting (32) with (22), one obtains
(53)
(53) Then time derivation of (52) can be deduced from (28) and (53) as
(54)
(54) Then from (49), (50) and (54), the time derivative of L is
and satisfied the following inequality
(55)
(55) If we can choose the appropriate parameters to satisfy the following condition
(56)
(56) Then (55) can be further represented as
(57)
(57) where
are all positive constants from condition (56).
Then if
(58)
(58) which means the identification error
, the tracking error e and NN weights error
are all bound.
Moreover, we have
(59)
(59) When
, the upper bound of (59) is
(60)
(60) where
depends on the DNN identification approximation error and the critic NN weight error
.
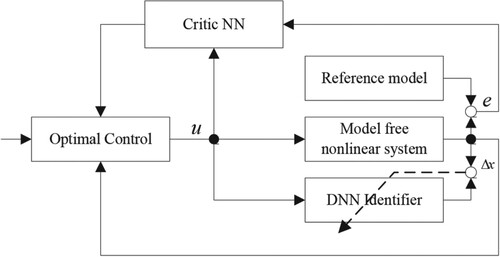
The structure diagram of the control scheme is illustrated in Figure .
Figure 1. Structural diagram of the control scheme.
A summary of the ADP-based optimal tracking control algorithm is as follows
(1) Select the proper initial values of active functions σ(·) and ϕ(·) in Equation (6) and updating gains k1, k2, k3 in Equation (9) for the identifier. σ(·) is usually selected as the sigmoidal function
where a, b and c are the designed constants. ψ (·) is selected as ψ (·) = I. α,β and γ are tuned online according to equations (9). Hence, there is no need to select the initial weight values of α,β and γ. Meanwhile, select the proper function ϕ(·) in Equation (31) and the updating gain μ in Equation (45) for the critic NN ϕ (·) is usually selected as a smooth function consisting of a different combination between state tracking errors.
(2) The inputs/outputs data of an unknown non-affine nonlinear system (1) is used to train the identifier.
(3) Adaptive optimal tracking control law consisting of the steady-state control law in an equation and the optimal control law in Equation (32) is obtained based on the first two steps.
5. Simulations
We consider the following two examples to illustrate the theoretical results in this section.
Example
Considering the following non-affine nonlinear system
(61)
(61)
The identification error is shown in Figure . We can see that the proposed identifier can model the non-affine nonlinear system accurately. Then, with the identified model, the adaptive optimal tracking controller is implemented for the unknown non-affine nonlinear continuous system (61). Define the trajectory error as . The activation function of critic NN is selected as
. The adaptive gain of the critic NN is selected as
, and the steady control gain is selected as K = 1200. Figures and represent the trajectory tracking, and the convergence property for the weight of the critic NN is shown in Figure , which demonstrates that the proposed adaptive optimal tracking controller can ensure satisfactory tracking performance for an unknown non-affine nonlinear continue system.
Figure 2. State identification error.
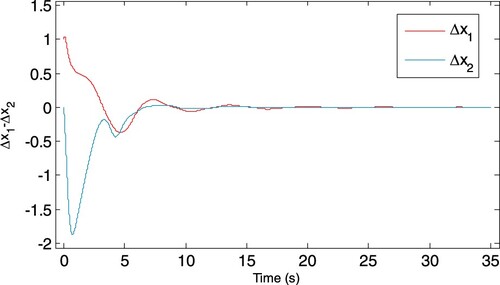
Figure 3. State tracking for x1.
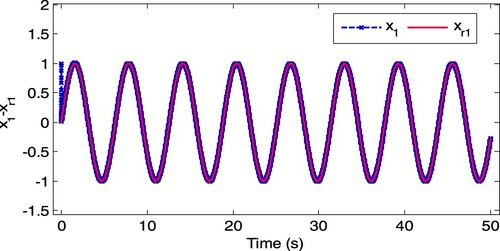
Figure 4. State tracking for x2.
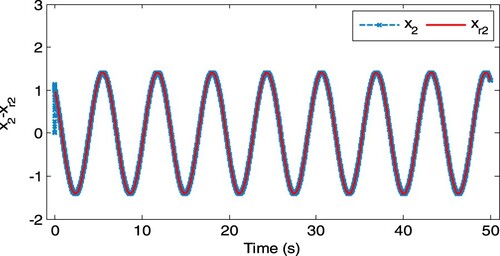
Figure 5. Convergence property for the critic NN weight .
![Figure 5. Convergence property for the critic NN weight x=[βγ],.](/cms/asset/5fe6b4cb-0c25-4453-9990-ec1f12ab2f70/taut_a_2170058_f0005_oc.jpg)
Example
The classical 2-DOF single-track vehicle model, as shown in Figure , is commonly used in AFS/DYC control design [Citation27]. The parameter notations are shown in Table .
Figure 6. Single-track vehicle model.
Table 1. Description of vehicle model parameters.
The mathematical model of Figure considering the uncertainty parameters is expressed as follows:
(62)
(62) where
is the side slip angel,
is the yaw rate;
,
is the active steer angle,
is the corrective yaw moment and
is the driver steer input
The main object of vehicle stability control is to design the proper controller to make the actual vehicle yaw rate and sideslip to follow the desired responses. The reference model is usually selected as
(63)
(63) where
are the designed time constants of raw rate and sideslip angle, respectively.
With the assumption that the variation and uncertainty of tire cornering stiffness can be described as
(64)
(64) where
and
are the nominal and actual cornering stiffness of the front and rear tires respectively,
are the deviation magnitude,
are perturbations.
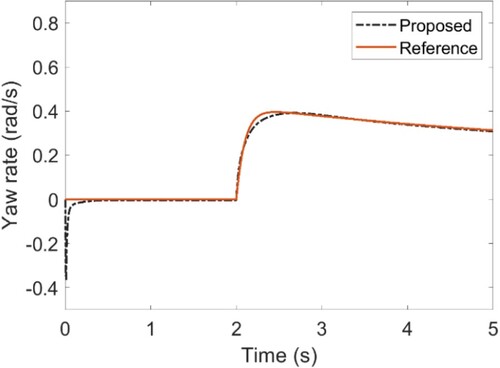
Simulation parameters of the vehicle system are selected as m = 1704kg, Cf= 63224N/rad, Cr= 84680 N/rad, Iz= 3048 kg m2, lf= 1.135 m and lr = 1.555 m. A 28-degree step steer manoeuvre with an initial speed (of 80 km/h) is simulated to verify the proposed method. The time-varying parameters of Cf and Cr are obtained from (64) by selecting Δf, Δr as constant 0.5 and ρf, ρr as band-limited white noise with the amplitude ±0.01. As shown in Figures and , the proposed method still demonstrates strong robustness and self-adaptive performance, i.e. less tracking error for yaw rate and sideslip angle, when encountering time-varying cornering stiffness in step steer manoeuvre.
Figure 7. Side-slip angle.
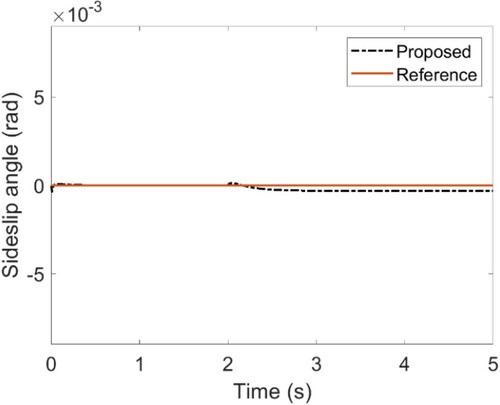
Figure 8. Yaw rate.
To show the identification performance of the proposed algorithm, the performance index-Root Mean Square (RMS) for the state’s error has been adopted for comparison.
(65)
(65) where n is the number of the simulation steps,
is the corresponding state response at the ith step.
The RMS values of the side slip angle and yaw rate are 0.915 × 10−4 and 3.173 × 10−4, respectively.
6. Conclusions
In this paper, we develop an adaptive optimal controller with a critic-identifier structure to solve the trajectory tracking problem for model uncertain non-affine nonlinear continuous-time system. First, a model-free DNN identifier is designed to reconstruct the unknown dynamic. Then, based on the identification model, an adaptive optimal controller is presented, which can realize the trajectory tracking and stabilize the error dynamic optimally. In addition, a critic NN is introduced to approximate the optimal value function, and a novel robust tuning law is established to update the critic NN weight. The stability of the closed-loop system is proved by the Lyapunov approach. Simulation results of two examples are presented to verify the validity of the proposed approach.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Powell B. Approximate dynamic programming: solving the curses of dimensionality. New Jersey: Wiley-Blackwell; 2007.
- Lebedev D, Margellos K, Goulart P. Convexity and feedback in approximate dynamic programming for delivery time slot pricing. IEEE Trans Control Syst Technol. 2022;30(2):893–900.
- Zhang H, Liu D, Luo Y, et al. Adaptive dynamic programming for control: algorithms and stability. London: Springer; 2013.
- Lewis FL, Liu D, Editors. Approximate dynamic programming and reinforcement learning for feedback control. Hoboken (NJ): Wiley; 2013.
- Werbos P. Approximate dynamic programming for real-time control and neural modeling. handbook of intelligent control, neural, fuzzy, and adaptive approaches. New York (NY): Van Nostrand Reinhold; 1992.
- Miller W, Sutton R, Werbos P. Neural networks for control. Cambridge (MA): MIT Press; 1990.
- Fairbank M, Alonso E, Prokhorov D. Simple and fast calculation of the second-order gradients for globalized dual heuristic dynamic programming in neural networks. IEEE Trans Neural Netw Learn Syst. 2012;23(10):1671–1676.
- Zhu L, Modares H, Peen G, et al. Adaptive suboptimal output-feedback control for linear systems using integral reinforcement learning. IEEE Trans Control Syst Technol. 2015;23(1):264–273.
- Wei Q, Liu D, Shi G. A novel dual iterative q-learning method for optimal battery management in smart residential environments. IEEE Trans Ind Electron. 2015;62(4):2509–2518.
- Bhasin S, Kamalapurkar R, Johnson M, et al. A novel actor-critic-identifier architecture for approximate optimal control of uncertain nonlinear systems. Automatica (Oxf). 2013;49(1):82–92.
- Vrabie D, Pastravanu O, Abu-Khalaf M, et al. Adaptive optimal control for continuous-time linear systems based on policy iteration. Automatica (Oxf). 2009;45:477–484.
- Vamvoudakis K, Lewis F. Online actor critic algorithm to solve the continuous-time infinite horizon optimal control problem. Proc Int Joint Conf Neural Netw. 2009;46:3180–3187.
- Modares H, Lewis F, Naghibi-Sistani M. Adaptive optimal control of unknown constrained-input dystems using policy iteration and neural networks. IEEE Trans Neural Netw Learn Syst. 2013;24(10):1513–1525.
- Na J, Lv Y, Wu X, et al. Approximate optimal tracking control for continuous-time unknown nonlinear systems). Nan Jing, China, Proceedings of the 33rd Chinese control conference; 2014; p. 8990–8995.
- Lv Y, Na J, Yang Q, et al. Online adaptive optimal control for continuous-time nonlinear systems with completely unknown dynamics. Int J Control. 2016;89(1):99–112.
- Zhang H, Cui L, Luo Y. Near-optimal control for nonzero-sum differential games of continuous-time nonlinear systems using single-network ADP. IEEE Trans Cybern. 2013;43(1):2168–2267.
- Wei Q, Liu D. Adaptive dynamic programming for optimal tracking control of unknown nonlinear systems with application to coal gasification. IEEE Trans Autom Sci Eng. 2014;11(4):1020–1036.
- Modares H, Lewis F. Linear quadratic tracking control of partially-unknown continuous-time systems using reinforcement learning. IEEE Trans Autom Control. 2014;59(11):3051–3056.
- Kamalapurkar R, Dinhb H, Bhasin S, et al. Approximate optimal trajectory tracking for continuous-time nonlinear systems. Automatica (Oxf). 2015;51:40–48.
- Lv Y, Ren X, Na J. Adaptive optimal tracking controls of unknown multi-input systems based on nonzero-sum game theory. J Franklin Inst. 2019;22(12):2226–2236.
- Zhang X, Zhang H, Sun Q, et al. Adaptive dynamic programming-based optimal control of unknown nonaffine nonlinear discrete-time systems with proof of convergence. Neurocomputing. 2012;91:48–55.
- Wang H, Tian Y. Non-affine nonlinear systems adaptive optimal trajectory tracking controller design and application. Stud Inf Control. 2015;24(1):5–11.
- Li X, Yu W. Dynamic system identification via recurrent multilayer perceptrons. Inf Sci (Ny). 2002;147:45–63.
- Poznyak A, Yu W, Sanchez E, et al. Nonlinear adaptive trajectory tracking using dynamic neural networks. IEEE Trans Neural Netw. 1999;10(6):1402–1411.
- Abu-Khalaf M, Lewis F. Nearly optimal control laws for nonlinear systems with saturating actuators using a neural network HJB approach. Automatica (Oxf). 2005;41(5):779–791.
- Na J, Yang J, Wu X, et al. Robust adaptive parameter estimation of sinusoidal signals. Automatica (Oxf). 2015;53:376–384.
- Yang X, Wang Z, Peng W. Coordinated control of AFS and DYC for vehicle handling and stability based on optimal guaranteed cost theory. Veh Syst Dyn. 2009;47(1):57–79.