
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Inspired by the idea of Ma et al. (Journal of the Franklin Institute, 2018), we adopt relaxation technique and introduce relaxation factors into the gradient based iterative (GI) algorithm, and the relaxed based iterative (RGI) algorithm is established to solve the generalized coupled complex conjugate and transpose Sylvester matrix equations. By applying the real representation and straighten operation, we contain the sufficient and necessary condition for convergence of the RGI method. In order to effectively utilize this algorithm, we further derive the optimal convergence parameter and some related conclusions. Moreover, to overcome the high dimension calculation problem, a sufficient condition for convergence with less computational complexity is determined. Finally, numerical examples are reported to demonstrate the availability and superiority of the constructed iterative algorithm.
1. Introduction
Solving matrix equations is one of the research focuses of computational mathematics [Citation1–4]. The Sylvester matrix equation is an important type of matrix equations, which has a wide range of applications in control and system theory, pole assignment, model reduction and so further [Citation5–7]. Therefore, finding feasible and effective algorithms for the Sylvester matrix equation has important theoretical significance and practical application value.
In this paper, we aim to find the solution of the generalized coupled complex conjugate and transpose Sylvester matrix equations
(1)
(1) where
,
,
,
,
,
,
are the known matrices and
are unknown matrices to be solved. Equation (Equation1
(1)
(1) ) is involved in both science and engineering. Besides, its form includes many other special matrix equations, such as complex conjugate Sylvester matrix equations, complex transpose Sylvester matrix equations and complex conjugate and transpose Sylvester matrix equations [Citation8–10]. Therefore, it is meaningful to research efficient methods for solving Equation (Equation1
(1)
(1) ).
At present, the methods for solving the Sylvester matrix equation mainly include direct methods and iterative methods. However, when solving high-dimensional matrix equations, the direct methods may lead to lengthy computation time. In order to efficiently solve these matrix equations, we prefer to apply iterative methods. In the past few decades, many scholars are devoted to establishing iterative methods to solve various types of Sylvester matrix equations [Citation7,Citation11–14].
From the previous works [Citation15,Citation16], we know that it is difficult to calculate the exact solution of matrix equations, which consumes large computing costs. In the field of systems and control, calculating approximate solutions is sufficient. So iterative solutions have been widely concerned by researchers, and many researchers paid attention to iterative methods and got excellent results. Ding and Chen developed various iterative algorithms to solve Ax = b, AXB = F and other Sylvester matrix equations [Citation17–19]. Subsequently, many effective iterative methods were proposed. In [Citation10], the least squares based iterative method has been applied to find the solutions of the Sylvester transpose matrix equation . Xie and Ding constructed the gradient based iterative (GI) methods for the matrix equations AXB + CXD = F [Citation9]. Wu et al. also investigated the GI method for solving the Sylvester conjugate matrix equation
[Citation20]. Owing to the availability of the GI algorithm, the GI algorithm has been extended to solve general Sylvester matrix equations by researchers. For instance, Wu et al. proposed the GI algorithm to find the solution of coupled Sylvester-conjugate matrix equations [Citation21]
(2)
(2) where
,
,
(
,
are the known matrices. Song et al. applied the GI method to the coupled Sylvester-transpose matrix equations [Citation22]
(3)
(3) where
,
,
,
, (
,
) are the known matrices. The above two matrix equations are important types of matrix equations, which are frequently involved in the fields of systems and control. Not only that, they are also the generalized forms of matrix equations in [Citation10,Citation20], respectively. The convergence properties and the optimal convergence parameters of the GI algorithm for Equations (Equation2
(2)
(2) ) and (Equation3
(3)
(3) ) have been investigated.
Subsequently, Beik et al. proposed the GI algorithm for solving the generalized coupled Sylvester-transpose and conjugate matrix equations [Citation23]
(4)
(4) where
are known matrices with proper dimensions. The form of the above matrix equations is quite general. When p and
, are taken to be some special values, Equation (Equation4
(4)
(4) ) can be transformed into other matrix equations.
Except for the above classical Sylvester matrix equations, the GI algorithm has also been applied to solve periodic matrix equations [Citation24,Citation25]. Li et al. established the GI method for the forward periodic Sylvester matrix equations and backward forward periodic Sylvester matrix equations [Citation25]
(5)
(5) and
(6)
(6) where
are the known matrices. In theory, Li et al. proposed the sufficient and necessary conditions for the convergence of the GI algorithm. Numerical experiments have also showed the effectiveness of the GI algorithm.
Although the theory of the GI algorithm has been systematically proposed by researchers, this algorithm still has some drawbacks. In [Citation26], Fan et al. pointed out that the GI algorithm costs large computation time and storage space when encountering ill-posed problems. In order to further optimize the convergence performance of the GI algorithm, the relaxed gradient based iterative (RGI) algorithm has been proposed by introducing the relaxed factor to adjust the weight of the iteration sequences. Niu et al. developed the RGI algorithm to solve the Sylvester matrix equations [Citation27]. Numerical experiments have shown that relaxation techniques can effectively reduce computation time and storage space, and improve the convergence rate of the GI algorithm.
Due to the superiority of the RGI algorithm, many scholars have extended this algorithm to solve more general matrix equations. Recently, in [Citation28,Citation29], Huang et al. applied the RGI algorithm to solve coupled Sylvester-conjugate matrix equation (Equation2(2)
(2) ) and coupled Sylvester-transpose matrix equation (Equation3
(3)
(3) ). And the experiments results illustrate that the convergence rate of the RGI algorithm is faster than the GI one. Then Wang et al. consider the solution of the complex conjugate and transpose matrix equations
(7)
(7) where
,
,
(
) are the known matrices. By introducing relaxation factors and applying the hierarchical identification principle [Citation30], Wang et al. presented the RGI method to solve Equation (Equation7
(7)
(7) ). However, Wang et al. didn't discuss the generalized form of Equation (Equation7
(7)
(7) ). Based on the ideas of [Citation30], we extend the RGI algorithm to the generalized coupled complex conjugate and transpose Sylvester matrix equations.
Inspired by the idea of [Citation28], we construct the RGI algorithm for solving Equation (Equation1(1)
(1) ). Its form can be specific written as
(8)
(8) The form of the above matrix equations is quite general, which contains several classic Sylverster matrix equations. Especially, Equations (Equation2
(2)
(2) )–(Equation3
(3)
(3) ) are special cases of Equation (Equation1
(1)
(1) ). If i = j = p = q = 1, Equation (Equation1
(1)
(1) ) will reduce to Equation (Equation7
(7)
(7) ). Therefore, finding faster algorithms to solve Equation (Equation1
(1)
(1) ) is of great significance.
To accelerate convergence rate of the GI algorithm for Equation (Equation1(1)
(1) ), we combine relaxation technology with hierarchical identification principle, and we derive the relaxed gradient based iterative (RGI) algorithm to solve Equation (Equation1
(1)
(1) ). This principle regards the unknown matrix as the system parameter matrix to be solved, then it builds a recursive formula to approach the unknown solution [Citation27,Citation28,Citation30,Citation31]. Furthermore, we can effectively control the weight of the iteration sequence by introducing relaxation factors. In theory, we exploit the real representation and the straightening operator to prove the convergence properties of the constructed algorithm. Meanwhile, the sufficient and necessary condition for convergence is presented. Finally, numerical experiments further demonstrate the effectiveness and superiority of the RGI algorithm. The main motivation and contribution of this paper are summarized as follows:
In order to accelerate the convergence rate of the GI algorithm [Citation23], we combine the GI algorithm with relaxation technique. By introducing l relaxation factors, we construct the RGI algorithm for Equation (Equation1
(1)
To optimize convergence theory, we utilize real representation and straighten operation as tool, and present the sufficient and necessary condition for convergence of the RGI method. To overcome high-dimensional computing problems, the sufficient condition for convergence and some related results are proposed. Besides, we use numerical experiments to fully demonstrate the effectiveness and superiority of the RGI algorithm.
The remainder of this paper is structured as follows. In Section 2, we list several useful notations and definitions. Moreover, we construct the relaxed gradient based iterative (RGI) algorithm to find the iterative solution of Equation (Equation1(1)
(1) ) in Section 3. In Section 4, we deduce the convergence properties of the proposed method, including the sufficient and necessary condition for convergence, the optimal convergence factor and the related corollary. In Section 5, two numerical experiments are reported to validate the superior of convergence for the new algorithm. In the end, Section 6 proposes the some conclusions.
2. Preliminaries
For the sake of convenience, we provide several main notations and lemmas which are used throughout this paper. The set of complex matrix is denoted by
. For
, there are some related notations as follows:
Then, some significant definitions and lemmas are listed below.
Definition 2.1
[Citation28]
Let , then A can be uniquely expressed as
with
.
denotes the real representation of a complex matrix A
(9)
(9)
Definition 2.2
[Citation32]
For two matrices ,
, the Kronecker product is defined as
(10)
(10)
Definition 2.3
[Citation28]
Let denote an n-dimensional column vector which has 1 in the ith position and 0's elsewhere. The vec-permutation matrix
can be defined as
(11)
(11) If
and
, we have
(12)
(12) and
(13)
(13)
Next, we review several lemmas which are used to prove the convergence property.
Lemma 2.1
[Citation33]
If ,
,
, then
(14)
(14)
(15)
(15)
Lemma 2.2
[Citation29]
For two matrices A and B, it has
(16)
(16)
Lemma 2.3
[Citation28]
For ,
,
, if the matrix equation AXB = F has unique solution, then the iterative sequences
converges to the exact solution
for any initial matrix
by the following algorithm
(17)
(17) and the algorithm is convergent if and only if
(18)
(18) Meanwhile, the optimal convergence factor is
(19)
(19)
Proof.
Define error matrix
According to the expression (Equation17
(17)
(17) ), it has
Let
, utilizing the properties of matrix Frobenius norm, Lemmas 2.1 and 2.2, it follows that
Repeatedly applying the relationship of the above expression leads to
If the convergence parameter μ is selected to satisfy
the following inequality holds
This means that
. Due to that the matrix equation AXB = F has unique solution, then it has
. The proof of Equation (Equation18
(18)
(18) ) is completed.
Taking the vec-operator of both sides of the expression (Equation17(17)
(17) ) and applying Lemma 2.2, it can get
The above equation implies that
is the iterative matrix of the algorithm. Thus, the optimal convergence parameter satisfies the following equation
which means that
has a non-trivial solution. By simple deductions, Expression (Equation19
(19)
(19) ) can be obtained.
Lemma 2.4
[Citation28]
The properties of real representation are as follows:
For two complex matrices ,
, then
(20)
(20) Here, unitary matrices
is defined as
(21)
(21) Furthermore, based on the definition of matrix Frobenius norm and real representation, then
(22)
(22)
(23)
(23)
Lemma 2.5
[Citation29]
If are any given positive number, denote the maximum and minimum values of
as
and
, respectively. It has
(24)
(24) then, the optimal convergence parameter μ is selected as
Proof.
Build function , and then Equation (Equation24
(24)
(24) ) has been obtained by drawing graph in [Citation29]. Besides,
if and only if
. The optimal convergence factor μ satisfies
The above equation indicates that
, that is,
. By simple calculations, it has
Thus, the proof is completed.
3. The relaxed gradient-based iterative algorithm
In this section, we mainly propose the relaxed gradient based iterative (RGI) algorithm to solve the generalized coupled complex conjugate and transpose matrix equation. The main idea of this algorithm is to use the hierarchical identification principle to divide Equation (Equation1(1)
(1) ) into several subsystems. The unknown matrixes
are regarded as the identified parameters matrices. Meanwhile, we construct intermediate matrices and adopt an average strategy. Then, the relaxation factors
,
are introduced, which are utilized to adjust the weights of matrix schemes. The construction process of the RGI algorithm is as follows.
Firstly, define the following intermediate matrices, ,
,
(25)
(25)
(26)
(26)
(27)
(27)
(28)
(28) From the expression of Equation (Equation1
(1)
(1) ), some subsystems are given below,
,
,
(29)
(29)
(30)
(30)
(31)
(31)
(32)
(32) According to the above fictitious subsystems and Lemma 2.3, we can put forward the iterative schemes as follows,
,
,
(33)
(33)
(34)
(34)
(35)
(35)
(36)
(36) For the sake of convenience, we provide the following notations,
,
(37)
(37) Combining Equations (Equation25
(25)
(25) )–(Equation28
(28)
(28) ) with Equations(Equation33
(33)
(33) )–(Equation36
(36)
(36) ) and utilizing the hierarchical identification principle, the recursive systems are established. Due to that the unknown matrices
are included in the expressions, we replace
in (Equation25
(25)
(25) )–(Equation28
(28)
(28) ) with
, respectively. Therefore, the following expressions are given,
,
,
(38)
(38)
(39)
(39)
(40)
(40)
(41)
(41) Then, by taking the average value of
and
, for
we have
Inspire by the idea of the RGI method in [Citation28], we introduce the relaxation factors
(
) into the above recursive systems. Based on the previous analysis process, the relaxed gradient-based iterative (RGI) algorithm for Equation (Equation1
(1)
(1) ) is presented as follows.
![]()
In the RGI algorithm μ indicates the convergence parameter. The relaxation factors (
) are used to control the weight of iterative sequences, and it can effectively improve the convergence rate of the GI method. In particular, if the relaxed factors are selected as
for all l, Algorithm 1 will reduce to the GI algorithm [Citation23]. Besides, Algorithm 1 with
and p = q = i = j = 1 will change into the iterative method in [Citation30]. Compared with the RGI algorithm in [Citation28], the new algorithm is more general which includes many kind of iterative formulas.
In what follows, the convergence properties of the RGI method are analysed below. At the same time, we also provide the detailed proof of convergence theory.
4. Convergence analysis of the RGI algorithm
The section presents the sufficient and necessary condition for convergence of the RGI algorithm. Furthermore, to overcome the high-dimensional calculation problem of the iterative matrix, we further discuss the sufficient condition for convergence.
Theorem 4.1
Assume that the generalized coupled complex conjugate and transpose matrix Equation (Equation1(1)
(1) ) has a unique solution, then the iterative sequences
converge to the exact solution
by the RGI algorithm for any initial matrices
for all
if and only if the convergence factor μ is selected to satisfy
(42)
(42) where
(43)
(43)
(44)
(44)
(45)
(45)
Proof.
Denote
(46)
(46) To facilitate our statement, the expressions of
are defined as follows
(47)
(47) From the definition of error matrices and the expression of
in the RGI algorithm, we derive that for
(48)
(48) It follows from the expression of
in the RGI method that
(49)
(49) By the expression of
in Algorithm 1, for
one has
(50)
(50) It follows from the expression of
in Algorithm 1 that for
(51)
(51) Combing (Equation48
(48)
(48) )–(Equation51
(51)
(51) ) with Line 5 of the RGI algorithm leads to
(52)
(52) According to Lemma 2.4, taking the real representation on both sides of (Equation52
(52)
(52) ) results in
(53)
(53) Using straightening operator in (Equation53
(53)
(53) ) and applying Definition 2.3, for
we have
(54)
(54) Furthermore, by applying the real representation on two sides of (Equation47
(47)
(47) ), we get
(55)
(55) Then, utilizing the vec-operator in (Equation55
(55)
(55) ) can deduce
(56)
(56) Finally, substituting (Equation56
(56)
(56) ) into (Equation54
(54)
(54) ) results in
(57)
(57) Denote
(58)
(58) Thus, Equation (Equation57
(57)
(57) ) can be written as the following expression
(59)
(59) The matrices M and Q are given in (Equation43
(43)
(43) ) and (Equation44
(44)
(44) ). It follows from Equation (Equation59
(59)
(59) ) that the matrix
is the iterative matrix of Algorithm 1. So the sufficient and necessary condition for convergence of the RGI algorithm is
(60)
(60) Due to the fact that the iterative matrix
is similar to
, and
is symmetric matrix, so one obtains
(61)
(61) Since
, it follows that
(62)
(62) Finally, the range of convergence parameter μ making the RGI algorithm convergent is
(63)
(63) Here, we complete the proof of Theorem 4.1.
In order to further effectively utilize the RGI algorithm, we should get the optimal convergence parameter μ of this method. When reaches minimum value, the convergence behaviour of the RGI method achieves the optimum. According to Lemma 2.5, the necessary and sufficient condition for
is
(64)
(64) By simple calculations, the optimal convergence parameter is obtained as
(65)
(65) Then, we will further discuss the convergence properties of the RGI method with the relaxation parameters
for
. Some relevant conclusions are proposed below.
Theorem 4.2
Assume that and
represent the initial value and unique solution of the RGI algorithm, respectively. Based on the conditions of Theorem 4.1, if the relaxation factor are selected as
for
, it holds that
(66)
(66)
And the optimal convergence parameter is
(67)
(67) Under this situation, the following inequality holds
(68)
(68)
Proof.
According to the fact that is the symmetric matrix, it has
(69)
(69) Combining Expression (Equation59
(59)
(59) ) with the properties of matrix norms, we derive
(70)
(70) with
(71)
(71) Based on Lemma 2.4 and
, it holds
(72)
(72) By the definition of the error matrix and Inequality (Equation70
(70)
(70) ), we derive that
(73)
(73) Moreover, when
is minimized, the convergence performance of the RGI algorithm can achieve optimal. So we should choose the optimal parameter
to minimize
. The minimum value of
is
(74)
(74) which indicates that
has a non-trivial solution. By simple derivations, the best convergence parameter is
(75)
(75) If the convergence parameter μ is selected as the one in (Equation75
(75)
(75) ), it will lead to
(76)
(76) Then Equation (Equation68
(68)
(68) ) can be derived by substituting Equation (Equation76
(76)
(76) ) into (Equation73
(73)
(73) ).
Remark 4.1
In Theorem 4.1, the sufficient and necessary condition for convergence of the RGI method is obtained. However, involves the calculation of real representation and Kronecker product, which leads to high-dimensional problems. In order to overcome this drawback and develop computational efficiency, we further derive sufficient condition for the convergence with less computational complexity.
Corollary 4.1
Assume that the conditions of Theorem 4.1 are satisfied, then Algorithm 1 is convergent for any initial matrix if the parameters ω and μ are selected to satisfy the following inequality
(77)
(77)
Proof.
By the properties of Frobenius norm of matrix, one has (78)
(78)
Notice the fact that
, and we have the following inequality
(79)
(79) By combining (Equation79
(79)
(79) ) with (Equation42
(42)
(42) ), the conclusion of Corollary 4.1 is correct.
5. Numerical experimental results
In this section, we present two numerical examples to testify the effectiveness and feasibility of the RGI algorithm proposed in this paper. All experiments are performed on a personal computer with AMD Ryzen 5 5600U with Radeon Graphics 2.30 GHz, 16.0 GB. The programming language is computed in MATLAB R2021b. In our experiment, we compare the convergence behaviour of the RGI algorithm with the GI one in terms of the iterative number (IT), calculation time (CPU) in seconds and the relative error (ERR).
Example 5.1
[Citation34]
We consider the generalized coupled complex conjugate and transpose Sylvester matrix Equation (Equation1(1)
(1) ) in the case of p = q = 4, and its form is as follows
(80)
(80) with
This matrix equation has the following exact solution
In this example, the initial iterative matrices are taken as , and the relative iterative error is defined as
(81)
(81) where
stand for the kth iteration solution. The iteration is terminated if the relative iterative error is less than δ or the number of the prescribed iteration step
is exceeded. Here, δ is a positive number.
By some calculations, we find that Example 5.1 satisfies the condition of Theorem 4.1. Then the optimal parameter of the RGI algorithm is obtained as when relaxation factors are chosen as
. However, there are errors in the experiment, and the convergence rate of the RGI method is not the fastest if μ is chosen to be 5.2559e−06. Thus, we try to find the optimal experimental parameter near the value
. In Figure , we compare the convergence performance of the RGI algorithm under
,
,
and
, respectively. As shown in Figure , if the convergence parameter μ is selected as different values, the convergence curve also has corresponding change. In order to more intuitively observe the performance of the RGI algorithm under different convergence parameters, we list the IT of the RGI algorithm in Table . It is evident that the convergence performance is the best when parameter μ is chosen to be
.
Figure 1. Comparison of convergence performance of RGI with different parameters μ for Example 5.1.
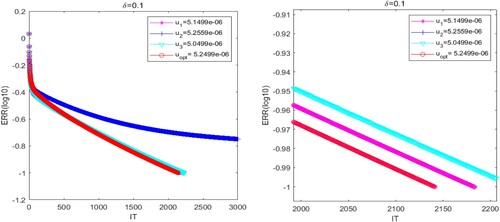
Table 1. Iterative number of the RGI algorithm with different μ for Example 5.1.
Moreover, the RGI algorithm with reduces to the GI algorithm. Similarly, we adopt the method of experiment debugging to find the optimal experimental parameter of the GI algorithm. Finally, the IT of the GI algorithm with
is the least.
In Figures –, we present that the convergence curves of the RGI and GI algorithms with different δ. In this experiment, we compare the convergence curves of two algorithms under the optimal experimental parameters. It follows from Figures – that the ERR decreases as the IT increases and gradually approaches 0, which indicates that the tested algorithms are effective and convergent. In addition, Figures – clearly show that the IT of the RGI and GI algorithms are decreasing as the increasing of δ. Besides, we can find that the convergence speed of the RGI algorithm is always faster than the GI one in the above four situations.
In order to more specifically verify the advantages of the RGI algorithm, we list detailed numerical results of the RGI and GI algorithms in Table , which includes IT, CPU and ERR. According to Table , the IT and CPU of the tested algorithms are gradually increase with the decreasing of the parameter δ. Moreover, it can be seen that the IT and CPU of the RGI method are always less than the GI one. Therefore, we can conclude that the convergence performance of the RGI algorithm proposed in this paper is better than the GI algorithm [Citation23].
Figure 2. The convergence curves of the tested methods with (left) and
(right) for Example 5.1.
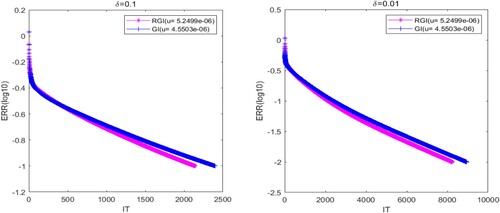
Figure 3. The convergence curves of the tested methods with (left) and
(right) for Example 5.1.
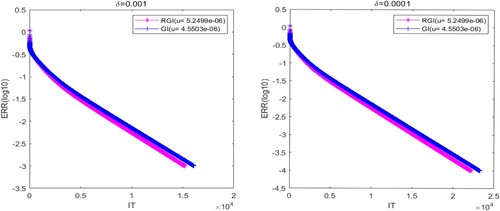
Table 2. Numerical results of the tested methods with different δ for Example 5.1.
Example 5.2
We consider the generalized coupled complex conjugate and transpose Sylvester matrix equation (Equation1(1)
(1) ) in the special case of p = q = 2, and it has
(82)
(82) with the following parametric matrices
It has the exact solution
The initial iterative matrices are taken to be . Then, we denote the relative iterative error by
(83)
(83) In this example, all runs are stopped once ERR is less than ξ or k reaches the maximal iterative steps
. Here, ξ is a positive number.
For Example 5.2, we also compare the convergence performance of the RGI and GI algorithms. The optimal convergence parameters involved in two algorithms are determined by the following method. If relaxation factors are selected as , the optimal convergence factor of the RGI algorithm is adopted as
by Theorem 4.1. Moreover, the RGI algorithm with
reduce to the GI algorithm. By some calculations, the best convergence parameter of the GI algorithm is
.
In Figures –, we plot the graphs of ERR(log10) versus the IT of the RGI and GI algorithms with different ξ. According to the convergence curves, we observe that the two algorithms are both convergent and efficient. It is obvious that the convergence rate of the RGI method () is always faster than GI one (
) for the four cases of ξ. In addition, it follows from Figures – that the IT and CPU of the tested algorithms are increasing with the decreasing of ξ. In particular, the convergence advantage of the RGI algorithm is more obvious when ξ is smaller. The results illustrate that the RGI algorithm is superior to the GI algorithm if the relaxation parameters are chosen appropriately.
Figure 4. The convergence curves of the tested methods with (left) and
(right) for Example 5.2.
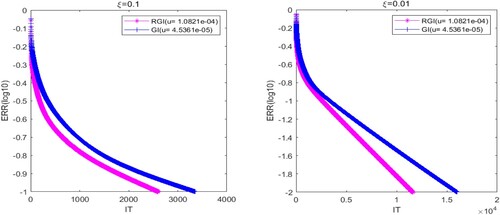
In order to further verify the advantages of the proposed algorithm, we clearly report the numerical results of the RGI and GI methods for Example 5.2 in Table . From Table , it is easy to discover that the IT of the algorithms is increasing with the decreasing of relative error. Furthermore, the IT and CPU of the RGI method are less than those of the GI one. As a whole, the proposed algorithm has better convergence behaviours than the GI method. This means that the relaxation technique can effectively improve the convergence rate of the GI algorithm.
Figure 5. The convergence curves of the tested methods with (left) and
(right) for of Example 5.2.
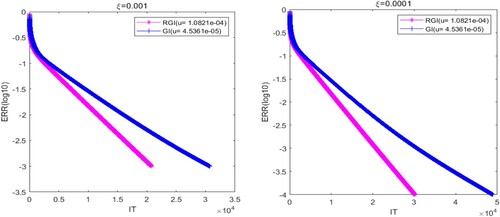
Table 3. Numerical results of the tested methods with different ξ for Example 5.2.
6. Concluding remarks
In this paper, by adopting the relaxation technique into the GI algorithm, we establish the relaxed gradient-based iterative (RGI) algorithm to solve the generalized coupled complex conjugate and transpose Sylvester matrix equations. The main idea of the algorithm is introducing relaxation parameter to control the weights of iterative sequences. Applying straighten operation and real representation of complex matrices, we derive the necessary and sufficient condition for convergence of the RGI algorithm. Besides, the optimal convergence parameter and some related conclusions are given. To overcome high-dimensional computational problems, we propose sufficient condition for convergence with smaller computational complexity. Finally, numerical experiments verify that the RGI algorithm has more excellent convergence performance than the GI one.
Note that in our experiment, the relaxation factors (
) are obtained through experimental debugging. The selection criteria for the optimal relaxation factors are not provided. The future research direction is to further develop the theory of selecting the optimal relaxation factor. Besides, the value of the convergence parameter μ in the RGI algorithm is fixed. To optimize the convergence performance of the RGI algorithm, we will consider to introduce different step size factors into the RGI algorithm.
example1.pdf
Download ()u111.eps
Download ()u1u2u3.pdf
Download ()example2.pdf
Download ()x3.eps
Download ()x2.eps
Download ()x1.eps
Download ()x2.pdf
Download ()q2.eps
Download ()x4.pdf
Download ()q2.pdf
Download ()q3.eps
Download ()q4.pdf
Download ()u111.pdf
Download ()x4.eps
Download ()q1.pdf
Download ()example01.pdf
Download ()q3.pdf
Download ()u222.pdf
Download ()x3.pdf
Download ()x1.pdf
Download ()q1.eps
Download ()q4.eps
Download ()u222.eps
Download EPS Image (318.8 KB)Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Hajarian M. Computing symmetric solutions of general Sylvester matrix equations via Lanczos version of biconjugate residual algorithm. Comput Math Appl. 2018;76:686–700. doi: 10.1016/j.camwa.2018.05.010
- Hajarian M. Developing CGNE algorithm for the periodic discrete-time generalized coupled Sylvester matrix equations. Comput Appl Math. 2015;34:755–771. doi: 10.1007/s40314-014-0138-7
- Zhou Y-H, Zhang X, Ding F. Partially-coupled nonlinear parameter optimization algorithm for a class of multivariate hybrid models. Appl Math Comput. 2022;414:Article ID 126663.
- Dehghan M, Hajarian M. The generalised Sylvester matrix equations over the generalized bisymmetric and skew-symmetric matrices. Int J Syst Sci. 2012;43:1580–1590. doi: 10.1080/00207721.2010.549584
- Zhou B, Wei X-Z, Duan G-R. Stability and stabilization of discrete-time periodic linear systems with actuator saturation. Automatica. 2011;47:1813–1820. doi: 10.1016/j.automatica.2011.04.015
- Zhou B, Duan G-R. Periodic Lyapunov equation based approaches to the stabilization of continuous-time periodic linear systems. IEEE Trans Automat Contr. 2011;57:2139–2146. doi: 10.1109/TAC.2011.2181796
- Ding F, Wang F. Decomposition based least squares iterative identification algorithm for multivariate pseudo-linear ARMA systems using the data filtering. J Franklin Inst. 2017;354:1321–1339. doi: 10.1016/j.jfranklin.2016.11.030
- Shen H-L, Peng C, Zhang T. Gradient based iterative solutions for Sylvester conjugate matrix equations. J Math Res Appl. 2017;03:103–118.
- Li X, Ding J, Ding F. Gradient based iterative solutions for general linear matrix equations. Comput Math Appl. 2009;58:1441–1448. doi: 10.1016/j.camwa.2009.06.047
- Li X, Liu Y-J, Yang H-Z. Gradient based and least squares based iterative algorithms for matrix equations AXB+CXTD=F. Appl Math Comput. 2010;217:2191–2199.
- Bai Z-Z, Guo X-X, Yin J-F. On two iteration methods for the quadratic matrix equations. Int J Numer Anal Model. 2005;2:114–122.
- Chen Z-B, Chen X-S. Modification on the convergence results of the Sylvester matrix equation AX + XB = C. J Franklin Inst. 2022;359:3126–3147. doi: 10.1016/j.jfranklin.2022.02.021
- Xu L, Ding F, Zhu Q-M. Separable synchronous multi-innovation gradient-based iterative signal modeling from on-line measurements. IEEE Trans Instrum Meas. 2022;71:1–13.
- Ding F. Least squares parameter estimation and multi-innovation least squares methods for linear fitting problems from noisy data. J Comput Appl Math. 2023;426:Article ID 115107. doi: 10.1016/j.cam.2023.115107
- Ding J, Liu Y-J, Ding F. Iterative solutions to matrix equations of the form AiXBi=Fi. Comput Math Appl. 2010;59:3500–3507. doi: 10.1016/j.camwa.2010.03.041
- Ding F, Ding J. Iterative solutions of the generalized Sylvester matrix equations by using the hierarchical identification principle. Appl Math Comput. 2008;197:41–50.
- Ding F, Chen T-W. Gradient based iterative algorithms for solving a class of matrix equations. IEEE Trans Automat Contr. 2005;50:1216–1221. doi: 10.1109/TAC.2005.852558
- Ding F, Chen T-W. On iterative solutions of general coupled matrix equations. SIAM J Control Optim. 2006;44:2269–2284. doi: 10.1137/S0363012904441350
- Ding F, Chen T-W. Iterative least-squares solutions of coupled Sylvester matrix equations. Syst Control Lett. 2005;54:95–107. doi: 10.1016/j.sysconle.2004.06.008
- Wu A-G, Zeng X-L, Duan G-R, et al. Iterative solutions to the extended Sylvester-conjugate matrix equations. Appl Math Comput. 2010;217:130–142.
- Wu A-G, Feng G, Duan G-R, et al. Iterative solutions to coupled Sylvester-conjugate matrix equations. Comput Math Appl. 2010;60:54–66. doi: 10.1016/j.camwa.2010.04.029
- Song C-Q, Chen G-L, Zhao L-L. Iterative solutions to coupled Sylvester-transpose matrix equations. Appl Math Model. 2011;35:4675–4683. doi: 10.1016/j.apm.2011.03.038
- Beik FPA, Mahmoud MM. Gradient-based iterative algorithm for solving the generalized coupled Sylvester-transpose and conjugate matrix equations over reflexive (anti-reflexive) matrices. Trans Inst Meas Control. 2014;36:99–110. doi: 10.1177/0142331213482485
- Lv L-L, Chen J-B, Zhang L, et al. Gradient-based neural networks for solving periodic Sylvester matrix equations. J Franklin Inst. 2022;359:10849–10866. doi: 10.1016/j.jfranklin.2022.05.023
- Li S-H, Ma C-F. Factor gradient iterative algorithm for solving a class of discrete periodic Sylvester matrix equations. J Franklin Inst. 2022;359:9952–9970. doi: 10.1016/j.jfranklin.2022.09.041
- Fan W, Gu C-Q, Tian Z-L. Jacobi-gradient iterative algorithms for Sylvester matrix equations. In: Linear algebra society topics. Shanghai, China: Shanghai University; 2007. p. 16–20.
- Niu Q, Wang X, Lu L-Z. A relaxed gradient based algorithm for solving Sylvester equations. Asian J Control. 2011;13:461–464. doi: 10.1002/asjc.v13.3
- Huang B-H, Ma C-F. The relaxed gradient-based iterative algorithms for a class of generalized coupled Sylvester-conjugate matrix equations. J Franklin Inst. 2018;355:3168–3195. doi: 10.1016/j.jfranklin.2018.02.014
- Huang B-H, Ma C-F. On the relaxed gradient-based iterative methods for the generalized coupled Sylvester-transpose matrix equations. J Franklin Inst. 2022;359:10688–10725. doi: 10.1016/j.jfranklin.2022.07.051
- Wang W-L, Song C-Q, Ji S-P. Iterative solution to a class of complex matrix equations and its application in time-varying linear system. J Appl Math Comput. 2021;67:317–341. doi: 10.1007/s12190-020-01486-6
- Ding F. Hierarchical multi-innovation stochastic gradient algorithm for Hammerstein nonlinear system modeling. Appl Math Model. 2013;37:1694–1704. doi: 10.1016/j.apm.2012.04.039
- Wu A-G, Zhang Y, Qian Y-Y. Complex conjugate matrix equations. Beijing: Science Press; 2017.
- Ding F, Chen T-W. Hierarchical gradient-based identification of multivariable discrete-time systems. Automatica. 2005;41:315–325. doi: 10.1016/j.automatica.2004.10.010
- Zhang H-M. A finite iterative algorithm for solving the complex generalized coupled Sylvester matrix equations by using the linear operators. J Franklin Inst. 2017;354:1856–1874. doi: 10.1016/j.jfranklin.2016.12.011