Abstract
Aircraft maintenance is a highly regulated, safety critical, complex and competitive industry. There is a need to develop innovative solutions to address process efficiency without compromising safety and quality. This paper presents the case that in order to improve a highly complex system such as aircraft maintenance, it is necessary to develop a comprehensive and ecologically valid model of the operational system, which represents not just what is meant to happen, but what normally happens. This model then provides the backdrop against which to change or improve the system. A performance report, the Blocker Report, specific to aircraft maintenance and related to the model was developed gathering data on anything that ‘blocks’ task or check performance. A Blocker Resolution Process was designed to resolve blockers and improve the current check system. Significant results were obtained for the company in the first trial and implications for safety management systems and hazard identification are discussed.
Statement of Relevance: Aircraft maintenance is a safety critical, complex, competitive industry with a need to develop innovative solutions to address process and safety efficiency. This research addresses this through the development of a comprehensive and ecologically valid model of the system linked with a performance reporting and resolution system.
1. Introduction
1.1 Background to the research
Aircraft maintenance is a highly regulated, safety critical, complex industry currently facing unprecedented challenges. Pressure is on aircraft manufacturers, from their customers, to design aircraft with pushed out maintenance schedules. Customers are disappearing from the industry and grounded aircraft around the world are translating into substantial declines in business. As part of the European-funded ergonomics/human factors project ‘Human Integration in the Lifecycle of Aviation Systems’ (HILAS Citation2005–2009) one of the industrial partners, a large European aircraft maintenance organisation, set forward the following agenda to be covered as part of the project's remit: to improve the aircraft base maintenance check with the aim of improving efficiency (process and cost) and customer satisfaction while at the same time ensuring quality and safety. At the first meeting on the topic between the company and the HILAS ergonomics/human factor experts it was noted:
Twenty aircraft would arrive into Base Maintenance Nose-to-Tail. Each aircraft would be the same type (Boeing 737 NG) but the check will vary into potentially five different types (B1–B5). A crew will be chosen that have experience on this aircraft type. The company would like to change their processes across these twenty checks so that a perfect model of how to do the check emerges; it is hoped that when someone comes into work on a particular day there will be transparency over the work activities and the status of those activities so the person can resume tasks immediately, it is hoped this will be the same in terms of visibility for the customer, senior management and staff, it is hoped that processes will become more efficient and whatever is created can be replicated across other lines.(Minutes of the meeting, 30 August 2007)
1.2 The aircraft maintenance system
Aircraft maintenance is a highly dynamic and regulated industry characterised, for example, by complex and interdependent systems and technologies, detailed and legally binding task procedures and documentation, highly publicised accident rates and highly regulated management systems to ensure reliability, efficiency and safety at all times (Corrigan Citation2002). Task analysis has revealed aircraft maintenance activity to be a complex socio-technical system requiring sustained coordination, communication and cooperation between different work groups and teams including aircraft maintenance engineers (AMEs), crew managers, inspectors and hangar managers, various other subsystems, such as planning and commercial, stores, quality and engineering and external bodies, such as the regulators, the manufacturer, the customer and the airline, in order to ensure efficient and effective operations (Drury et al. Citation1990, Gramopadhye and Kelkar Citation1999, McDonald et al. Citation1999). Four of the key aspects of aircraft maintenance are as follows:
The regulations – aircraft maintenance is a highly regulated industry where maintenance organisations are continually subjected to audits and approvals by aviation authorities covering both quality and operational requirements. | |||||
Other external bodies – the manufacturer, customers, vendors and the airline also play a key role in influencing operational matters. | |||||
Internal functions – a number of key functions continually support pre-check aspects of aircraft maintenance (e.g. contract negotiation, personnel selection, personnel training, etc). | |||||
Maintenance production system – this is where the work is actually carried out, either aircraft or shop overhaul (base or heavy maintenance) or line (light) maintenance, all of which is continually supported by engineering, planning and commercial and quality departments. | |||||
The maintenance philosophy currently used in the design of present aircraft maintenance programmes is called Maintenance Steering Group 3 (Air Transport Association). The MSG committee decide which system and components will require maintenance. They use a decision tree to aid in answering a series of logical questions on the consequences of a failure. From this, a list of maintenance significant items (MSIs) and structural significant items (SSIs) are identified and the required maintenance is specified, such as lubrication and servicing, inspections, functional checks, etc. A document is then issued called the Maintenance Review Board (MRB) report, which outlines the initial maintenance requirements for the new aircraft type. The MRB is made up of the manufacturers and the aviation authorities, in consultation with the airlines and maintenance organisations, to ensure the continuous maintenance needs of the aircraft are met. Maintenance planning data (MPD) is produced by the manufacturer and provides only a general guidance to operators of current production aircraft for developing an individual scheduled maintenance programme. The final responsibility lies with the individual operator. The MRB items are included in the MPD. The MPD is split into three programmes:
-
Zonal programme: The aircraft is split into eight major zones and each zone into sub-zones. Most zonal visuals checks are included in the ‘daily’ ‘A’ ‘C’ checks (this categorisation will be explained below) and these are carried out by a general visual inspection (e.g. top skin of the flap at a ‘2C’ inspection).
-
Power plant and systems programme: This details all the basic scheduled maintenance tasks and frequencies required for MSIs. It also includes work to be carried out on the auxiliary power unit (APU) and power plant but does not include shop work for components. The required intervals are detailed in each case (e.g. 4A, 30 months, 6000 flight hours or even at engine change).
-
Structural inspection programme: Describes the detailed inspections required on the SSIs and this programme is split into three sections:
Fatigue damage: This relate to the cycles, which is the unit used to monitor this area (cycles are determined by a take-off and a landing but some operators may use an averaging technique). Normally, a programme has to be set up to monitor fatigue, Airbus uses the fleet leader programme and Boeing the supplemental structural inspection document, where 20% of the fleet is involved in a sampling of the SSIs once the threshold number of cycles is reached.
Environmental damage: Random nature (stress corrosion or leakages) has 100% inspection basis in specified areas with no threshold. Age dependent (corrosion with time) is treated much the same as fatigue calendar based but when the threshold is passed an age exploration programme is established or structural inspection programme for Boeing.
Accidental damage: This is treated in the same way as environmental damage with 100% compliance at the check interval, major accidental damage is normally discovered on pre-departure or walk-around checks. The manufacturers usually monitor the structural programmes and will then modify the MPD as a result of experience and tests.
Every newly acquired aircraft will then have a National Aviation Authority approved aircraft maintenance programme, otherwise referred to as the approved maintenance schedule (AMS). This document lays down the mandatory minimum maintenance programme. The AMS is modified by the maintenance organisation in order to suit individual organisational requirements as well as meeting all the legal requirements. Usually the AMS is broken down into checks at various intervals, designated as either line checks, overnight checks and A, B, C, D (the heaviest checks). The objective of these is to conduct both routine and non-routine maintenance of the aircraft. This maintenance includes scheduling the repair of known problems, replacing items after a certain flight time, number of cycles or calendar time, repairing defects discovered previously from reports logged by pilots and crews or items deferred from previous maintenance and performing scheduled repairs or inspections (Gramopadhye and Drury Citation2000).
Once maintenance and inspection are scheduled for an aircraft as per the MPD, they are translated into, first, a check ‘work pack’ and then into a set of ‘task cards’ giving the instructions for the aircraft maintenance personnel to carry out the different tasks on the aircraft. A major check (e.g. ‘C’) may have as many as 5000–10,000 task cards. Each task card will include a description of the task and contain information pertaining to the type of aircraft. Accomplishment of the intent of the task card initially comes from within the aircraft manufacturer's maintenance manuals; all tasks will also have a reference to the relevant section of this manual. This manual must be used at all times while performing maintenance on any part of an aircraft. The task card is also a legal document that when properly executed provides ‘proof’ of work accomplishment and it exacts accountability from the AME/inspector signing off the card.
A critical aspect of the workload is dependent on recognising and identifying defects during maintenance and inspection activities. In particular, there is pressure to identify critical defects that necessitate lengthy follow-up maintenance and additional logistical support early in the inspection process. Therefore, there is usually a heavy inspection workload at the commencement of each check. During inspection, each defect is written up as a non-routine work card and re-assigned to maintenance personnel for completion and sign-off.
1.3 Ergonomics/human factors in aircraft maintenance
From this picture of aircraft maintenance, it can be seen that it is an extremely complex activity. Reason and Hobbs (Citation2003, p. 1) note that it may also be an activity that is prone to error:
If some evil genius were given the job of creating an activity guaranteed to produce an abundance of errors, he or she would probably have come up with something that involved the frequent removal and replacement of large numbers of varied components, often carried out in cramped and poorly lit spaces with less-than-adequate tools, usually under severe time pressure. There could also be some additional refinements. Thus, it could be arranged that the people who wrote the manuals and procedures rarely if ever carried out the activity under real-life conditions. It could also be decreed that those who started a job need not necessarily be the ones required to finish it. A further twist might be that a number of different groups work on the same item of equipment either simultaneously or sequentially, or both together.
If the aviation maintenance system is to be improved, then that system must be understood. Part of this understanding, as evidenced from the above, is that factors deep in the organisation could make a significant contribution to accident causation. Indeed one of the main accomplishments of the Reason model (e.g. Reason Citation1997) has been to open up this territory of immediate factors, workplace factors and organisational factors as systematic precursors of safety failures and not to lay the ‘blame’ with the individual. For example, his work with Managing Engineering Safety Health and Maintenance Error Investigation demonstrated that inputs to the task were important to how it was performed and there were systemic causes to incidents and accidents. The model provides a systematic analytic framework for working back from a particular event to identify the proximal and remote factors, which could have influenced this particular outcome. The weakness of this approach is that it provides no basis for understanding the systemic role of these organisational factors – how they normally operate and what was distinctive about their operation in the particular instance when things did not work well. Thus, it could be said that the strength of the Reason model is also its weakness. For example, Reason highlights the difference between foresight and hindsight: with hindsight one can often identify the presence of warning signs, which, if acted upon, could have prevented the disaster (Reason Citation1997, p. 38), quoting Wagenaar and Groeneweg: ‘Accidents appear to be the result of highly complex coincidences which could rarely be foreseen by the people involved’.
How ‘errors’ in aircraft maintenance have been dealt with has also been problematic. Because little was known about how the system actually operated, dealing with human error became centred on information campaigns highlighting the accident and telling people not to commit the error again. The people involved in the incident were usually sent for ‘training’ and thus at an operational level the organisation's ‘no blame’ policy became colloquially known as the ‘blame and train’ policy (Ward Citation2005). The categorisation of errors (mistakes) and violations (deliberate) also brought difficulty. The ADAMS (Citation1994–1999) project carried out in four different aircraft maintenance organisations across Europe began work intensively studying organisational systems. This was done through documentation analysis tracking task performance, naturalistic observations of tasks, interviewing and surveying people. In ADAMS, it was discovered that in over one-third of tasks surveyed the AME involved had not carried out their work in accordance with the procedure or manuals supplied by either the company or the manufacturer. It was found that in the normal state of events the system was not supporting performance but rather people were optimising system performance, turning error theory on its head. Out of the EU-funded projects ADAMS (Citation1994–1999), AMPOS (Citation1999–2001) and ADAMS2 (2001–2004) developed the idea of ‘well-intentioned people in dysfunctional organisations’ (WIPIDO). The question was raised as to why these things should be called ‘violations’ when people are doing them to make the system work. Error theories do not provide a criterion to distinguish between a good procedure or a good system and a bad one. It takes the value of the existing system for granted and because of this, and despite itself, it leaves the blame at the doorstep of the individual. If in accident investigations there is a finding that violations take place 30–40% of the time that says one thing but if it is known that in normal practice violations occur 30–40% of the time then it cannot be concluded that violations cause accidents.
Patrick Hudson's work in the oil and gas industry and Reason's (Citation1987) work on generic error modelling system developed this idea of ‘normal practice’ and the need to understand this more. In the USA work was on a similar trajectory with the High Reliability Organisation in the University of Berkeley, California reacting to and building on Perrow's (Citation1984) ‘Normal accidents’ work. Weick (Citation2001) in his ‘Making sense of the organisation’ introduced a shift from talking about ‘errors’ (which do carry a certain ‘moral’ weight) to ‘bricolage’ (which was more positive and in line with the idea of WIPIDO). At the same time, work was ongoing at the University of Texas developing line operations safety audit (LOSA) (Helmerich et al. Citation2001), which reinforced the notion that errors and violations are part of normal practice but introduced the idea of threat and error management (TEM). LOSA has demonstrated its power in flight operations; attempts to replicate this in the more complex environment of aircraft maintenance have been more problematic (Liston Citation2005). Also, however, what is assumed in LOSA and TEM is the inherent ‘goodness’ of the procedure to begin with. In maintenance, Patankar and Taylor's (Citation2003, Citation2004) work highlights the sometimes impractical nature of maintenance procedures that can lead to safety failures.
If one is to understand the relationship between a procedure and practice, one needs to fully understand the system behind the procedure. Dekker (Citation2008), in his phenomenological reconstructions of accidents, has demonstrated from the perspective of the person involved just how complex these system influences can be. Hollnagel's (Citation1998) work on cognitive reliability and error analysis method and Hollnagel and Woods (Citation2005) work on joint cognitive systems moved forward the analysis of systems to explore in particular three modes of processing: strategic; tactical; scrambled. However, with this type of analysis the organisational system is seen as a background factor, which, when not working optimally, interferes with the person, rather than seeing the system as being an active part of what enables the person to work. The work on resilience (Hollnagel et al. Citation2006, Citation2008) also brought this question to the fore and asked, in particular: What is the relationship between an organisation and its environment? How do organisations adapt to changes in their environment? How do they recover when things go wrong? They also introduced the notion of ‘emergence’ to explain how it is not possible to explain the whole from the sum of its parts. They also argue that both emergence and ‘resonance’ (causal relations are non-linear) make it difficult to map out organisational relationships. The actions of people in the system, for example, the performance of maintenance engineers, are central to mediating the relationship of that system to its environment (successfully executing a maintenance check). The system in all its complexity is what needs to be changed to support better human performance in order to improve the system outcomes.
The requirement, however, to change an organisational and operational system should not be taken for granted. There are very few longitudinal studies of change processes and such evidence as exists tends to suggest that achieving organisational and operational change is highly problematic (Pettigrew Citation1985, Pettigrew and Whipp Citation1991). There are very complex factors that combine to maintain stability in organisations. For this reason, one needs to understand the factors that can overcome these inertial forces in a properly planned and resourced programme of change. A series of in-depth investigations of ergonomics/human factors in the aircraft maintenance industry over the last 10 years has demonstrated some of the complex relationships between human and organisational factors that need to be taken into account if one is to be able to plan and implement change and improvement programmes with any likelihood of success (as carried out in the ADAMS (Citation1994–Citation1999, 2001–2004), AMPOS (Citation1999–2001) and HILAS (Citation2005–2009) projects). The interplay of these factors (e.g. need for extensive planning vs. need for flexibility; double standard in relation to task documentation; quality management systems' inability to cope with normal operations; professional culture overriding inadequacies in the environment; organisational culture of meeting customer over staff needs and the mistrust that ensues) can be seen to exemplify complex homeostatic mechanisms, which maintain the relative stability of the operational system in a dynamic environment (as opposed to allowing change to happen).
Understanding the prerequisites for change poses two theoretical and practical challenges: understanding in what respect the system needs to be improved; and understanding how to go about changing the system. The first challenge requires an independent criterion of system adequacy. Here, classic ergonomic/human factors error theories have fallen short. Theories of human error are driven by ambiguity over whether the error is systemic or cognitive. What Reason and Rasmussen describe as procedural violation, Weick describes as bricolage. It is not clear when either of these two conflicting interpretations may be appropriate or correct. The LOSA system defines error in terms of deviation from a procedure. This has the consequence of precluding a critical analysis of the procedural system. Instead of the procedure being the ultimate criterion of system adequacy, one needs to have a comprehensive and ecologically valid model of the operational system, which represents not just what is meant to happen, but what normally happens. Such a model gives the possibility of understanding how the system needs to change in order to improve the way it functions. Also, an adequate methodology is needed for the analysis and redesign of the operational processes through which operations achieve their outcomes. The work carried out here as part of the HILAS project has tried to address these issues by exploring a model of ergonomics/human factors that moves beyond analysing human fallibility and related performance deficits. It is increasingly addressing how people behave in normal operational contexts and how performance in such contexts can be improved. It is this work in relation to the aircraft maintenance check improvement programme that is reported here.
2 Methodology
2.1. Introduction to the methodology
The overall methodology of this work was participatory action research. Most would cite the origins of action research in organisational development work, for example, Lewin's seminal work (e.g. Schein Citation1989) and in the critical pedagogy put forward by Freire as a response to the traditional formal models of education, where the ‘teacher’ stands at the front and ‘imparts’ information to the ‘students’, who are passive recipients. Lewin combined the methodology of experimentation with solid theory and a concern for action around important social concerns (Coghlan Citation2002). Coghlan (Citation2002) argues that for Lewin it was not enough to try to explain things, one also had to try to change them. For Lewin there was a realisation that human systems could only be understood and changed if the members of the system were involved in the inquiry process. Coghlan (Citation2002 p. 63) notes: ‘action research is fundamentally about telling a story as it happens’. The elements of this action research story are an articulation of the context and purpose of the action research project and the cycles of diagnosing, planning action, taking action, evaluating action, which, in turn, lead to further diagnosing, planning action and so on (Coghlan and Brannick Citation2001).
Participatory action research then focuses on the effects of the researcher's direct actions of practice within a participatory community, with the goal of improving the performance quality of the community or an area of concern (Hult and Lennung Citation1980, Reason and Bradbury Citation2001). The actions have a set goal of addressing an identified problem in the workplace. May et al. (2002) (cited in Hughes Citation2003) define participatory action research as:
A continual reflective dialectic between theory and application of knowledge gained as a continuous research cycle. This reflective dialectic, involving ‘outsider’ professional university-based researchers, working collaboratively with ‘insider’ community-based researchers, opens traditional scientific knowledge to substantive incongruencies, inconsistencies and inaccuracies.(p. 6)
Essentially, Wadsworth (Citation1998) argues that participatory action research is research that involves all relevant parties in actively examining together current action (which they experience as problematic) in order to change and improve it. Participatory action research is not just research that it is hoped will be followed by action. It is action that is researched, changed and re-researched, within the research process by participants. Nor is it simply an exotic variant of consultation. Instead, it aims to be active co-research, by and for those to be helped.
Thus, in terms of this research it was the management of the company that had set the research agenda but most of the work was carried out with non-managerial staff in a collaborative manner, designing and re-designing component parts of the improvement initiative. Staff were involved in shaping aspects such as organisational architecture, the use and sharing of knowledge, process measurement and re-design and IT support, which, as per Sinclair's (Citation2007) framework for designing new systems, were all felt to be important aspects of designing the improvement system. Thus, in relation to culture there were many sub-cultures involved in the work. Following Hendrick and Kleiner (2002, cited in Schutz et al. Citation2007), there were a number of distinct intervention areas within the project. It was agreed that intervention would be needed at each level:
The personnel subsystem: a total crew of around 60 people were involved in the checks from the hangar manager, the crew managers, eight zonal teams of around seven to eight people working on the different aircraft zones (landing gears, wings, engine, cabin, etc). These staff were supported on a daily basis by the support planner, the materials coordinator and the commercial officer. | |||||
The technical subsystem: the actual check process itself. In this instance it was B1, B2, B3, B4 and B5 checks of 1 week or 2 weeks in duration. | |||||
The internal environment: the hangar where the check took place and all the departments involved in the upkeep of the hangar, for example, facilities supplying cleaners, equipment repair, etc, the environmental officer ensuring waste recycling. | |||||
The external environment: this hangar, like the others in the company, is located in base maintenance. This area oversees the running of the checks, including any work carried out in related workshops and the resourcing of the checks from a personnel point of view. The base maintenance department operates within a broader aircraft services structure of planning and commercial, engineering, quality, supply chain, human resources, IT. | |||||
Due to the scale of the project it was decided that one researcher from Trinity College Dublin (TCD) would be based full time on site, with another researcher supporting the work, attending meetings on site but returning to TCD after. The company also provided a dedicated staff member to assist with the environmental management aspect in particular. This staff member had a background in continuous improvement and in particular was trained in Six Sigma (Harry and Schroeder Citation1999, Welch and Byrne Citation2001) to the level of Black Belt. This group along with the Organisational Learning Manager of the company and the Base Maintenance Manager became known as the ‘Improvement Team’. This team would manage the overall development and implementation of the initiative. The steps in the improvement initiative were developed over time and were based on a review of the literature in relation to change, ergonomics/human factors, ongoing work on the HILAS project, time spent understanding and working with other continuous improvement initiatives in the company (Lean (Womack et al. Citation1991, Womack and Jones Citation2003) and Six Sigma in particular). The initiative was developed iteratively with all of the check staff involved in the hangar. This is outlined in brief here as the main focus of this paper is on two aspects of the initiative (firstly, operational process modelling to understand the current aviation maintenance system and the check processes better and, second, development of a new performance reporting and management procedure to allow staff to identify and resolve anything that affected check performance). All of these strands of activity run in parallel.
-
Culture and team engagement (the personnel subsystem)
Assess organisational readiness to change and identify key areas to be addressed with staff.
Have initial communication session with all staff explaining rationale for and objectives of change.
Establish a hangar improvement team (HIT) to run with the change process.
Train the HIT, crew managers and all hangar staff in all tools/methods of change
Engagement with an iteratively developed meeting schedule to facilitate improvement and resolve blockers.
Engagement with an iteratively developed company wide process for blocker resolution.
-
Process improvement (the technical subsystem)
Mapping the current ‘as is’ process using the HILAS operational process model (OPM).
Gathering and evaluating the blockers to the current process.
Resolving blockers and making improvements to the process.
Communicating the status of blocker reports to staff through the use of high visibility notice boards in the hangar.
Designing the new ‘to be’ process.
Implementing the new process.
-
Improving the workplace environment (internal environment)
Assess the needs of the hangar from a staff perspective and from a Lean 5 S's perspective.
Create improvement plan based on assessment.
Implement the improvement plan and the Lean 5 S's in the hangar.
Work with company Environment Manager in relation to waste disposal and recycling.
-
Relationships and interactions with other areas of the system (external environment)
Establish relationships with people from other departments involved in the check process (e.g. planning and commercial, engineering).
Explore relationships between the new blocker report and existing company IT systems to gather data on different aspects of check performance (e.g. company Enterprise Resource Planning (ERP) system for check data management).
Establish a systematic approach to the oversight of key performance indicators (KPIs) in relation to the overall base maintenance process and the check process within that.
Strengthen relationship with the customer, including having daily meetings, post check ‘wash up’ meetings, post check customer surveys and analysis.
2.2 Modelling the aircraft maintenance check system
One of the first tasks was to map the ‘normal’ operational system of an aircraft maintenance check. As argued earlier, to change a system one must first understand that system. Due to the nature of aircraft maintenance (e.g. double standard in relation to task documentation, professional culture overriding inadequacies in the environment) that understanding has not been easy. This paper attempts to address the need for a comprehensive and ecologically valid model of the check system, linking a performance reporting system and a way of resolving reports with the model. The OPM developed in the TATEM (Citation2004–2008) and HILAS projects was used for this purpose.
The OPM is a comprehensive model, which (in a generic way) describes process activities and models their underlying causal logic (Bunderath et al. Citation2008). It:
stores and manages data, information and knowledge about the current system; | |||||
represents the system graphically in different ways (system level, process activity/technical steps, stakeholder/social relations, dependencies/information flow and critical path – see ), based on that data; | |||||
supports transformation of the operational process into future or alternative versions. | |||||
Figure 1. Components of the operational process model.
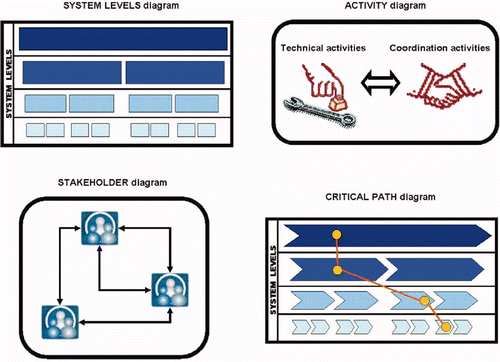
The OPM approach differs from standard process modelling in: (a) the scope of what is considered as critical elements, for example, social relations among key stakeholders; (b) consequently, how the relations between these elements and their underlying mechanisms are expressed. In summary, the system activity is systematised in the process model around the following elements:
-
System level: Any operational process is embedded in a wider system context. Outcomes of activities at each level in the hierarchy of an organisations' system feed into subsequent levels.
-
Process activity: The process activity diagrams not only map out the process as it is defined by, for example, manuals and procedures or company policies, but integrate the additional human activities that enable the formally identified process to work. The diagrams distinguish between technical activities as required to manipulate the technology object and coordination activities that are critical to understand how outcomes are produced in processes.
-
Dependencies: States are gates in the process progression at which the status of the process is consolidated to provide a stable platform for its progress. In order to achieve a state, certain resources are required. These demands can be expressed as a set of dependencies. These dependencies can be located within a process, span across process levels or arise outside of the operation.
-
Stakeholder: It is not sufficient to review individuals' activities. One has to include the pattern of their relationships. The notion of stakeholder includes every role that has a direct or indirect contribution to defining the system constraints.
As noted above, a lot of work had been done becoming familiar with the base maintenance check processes (ADAMS (Citation1994–Citation1999, 2001–2004) and AMPOS (Citation1999–2001) projects). This grounded the work carried out here but, as each organisation is different, time was first spent becoming familiar with the organisation, attending the daily 09.00 hours check technical meeting with the hangar manager, crew managers from each zone of the aircraft, support planner, materials coordinator and commercial officer. This was to allow the researchers to become familiar with the organisation's check process, the terminology used and the working culture but also, importantly, to build up trust between check personnel and the researchers. The researchers also worked closely with the Base Maintenance Management Team and the Improvement Team. In particular, a lot of time was spent learning about Lean and Six Sigma and how they were being implemented and working in the company. Aspects of these initiatives were felt to be important to link this work with. The Lean environmental management programme of Lean 5 S's, for example, was felt to be appropriate to support the workplace environment improvements. Six Sigma had it strength in the in-depth ‘inch wide and mile deep’ analysis into problems of Green and Black Belt projects. However, it was felt that ergonomics/human factors could also add significantly to these methods. For example, in relation to understanding processes it was felt that the OPM provided a much richer and safer means of modelling the system than the Lean ‘value stream mapping’, which focuses on what adds value to the process and what does not (waste). In HILAS, the OPM takes a sociological, technological and information flow perspective of the process. Within this type of mapping it is less likely that some part of the process, which might initially appear as ‘waste’ and would in fact be safety critical, for example, checking or verifying information in different formats, would be ‘mapped out’ of the process as can happen in value stream mapping. Thus, the HILAS OPM helps to ensure safety as a priority.
In terms of modelling the check four workshops took place with a selection of staff from hangar manager to crew managers to AMEs and aircraft maintenance assistants (AMAs), representing different work categories (e.g. sheet metal, avionics) and different zones of the aircraft (e.g. wings, landing gear, cabin). The first step was to identify the major states in the process (i.e. initial picture established, set-up, inspection and commence critical path, routine and rectification, final test and close up). Within these states the technical process steps were outlined and then, finally, two workshops were held to explore and map the social relations among these steps. The major technical steps can be seen in . The maps were then presented back to all staff who had been involved in the process mapping and then subsequently to all hangar staff for further validation.
Table 1. Overview of technical process steps involved in a base maintenance check process.
As noted in the introduction to aircraft maintenance, thousands of tasks are performed on checks and how exactly all of this is done is housed in the heads of AMEs around the world. This work here helped to bring some of that to paper and allow the organisation to begin to build organisational memory in the form of the OPM of both how that work is done and how the problems in performing that work can be addressed through the blocker reporting and the blocker resolution process.
2.3 Development of a performance report for aircraft maintenance
One aspect of understanding the check was modelling the system as described above. Another aspect was developing a new performance reporting and management procedure to allow staff to identify and resolve anything that affected check performance. An evaluation took place of the existing reporting structures that were in place in the organisation. Staff had a number of self-reports that they could submit. Each of these reports focused on a unique aspect of performance and safety (airworthiness and personal):
Task card amendment form for reporting on any suggested amendment to the task card. This report went to the Planning and Commercial Department. | |||||
Quality discrepancy report for reporting on any issue that was seen to compromise the quality of the aircraft or the work being carried out. This report went to the Quality Assurance Department. | |||||
Accident/dangerous occurrence report for reporting on any personal incident, accident or near miss. This report went to the Safety and Security Department. | |||||
Forward driver report for making any suggestions for change or improvement that would yield a financial return on investment for the company. This report went to different allocated ‘drivers’ in each department. | |||||
There was also a company confidential and voluntary error-reporting process. There was no report that addressed performance on the check. Staff felt that the reports that existed were very ‘formal’ and quite ‘serious’. They also felt that the actual process for reporting needed to be simplified and the actual report forms themselves needed to be more readily available (all of the reports were paper based and sometimes it was difficult to know where to locate the actual paper).
Following on from the process-mapping activity, a report was thus developed with a selection of check staff from hangar manager to crew managers to AMEs and AMAs, representing different work categories (e.g. sheet metal, avionics) and different zones of the aircraft (e.g. wings, landing gear, cabin). The report was based on the OPM of the check and designed to simply report on anything that ‘blocked’ task or check performance. This report became known as the ‘blocker report’. The blocker report is not an error or incident-reporting form but a ‘problem’-reporting form. It is an informal report, completely voluntary and anonymous if staff wish (staff can choose to give their staff identification number). Its structure is based on the OPM of the check. The report is designed to be simple to use. It is on one page, back and front, and takes no more than 10 min to complete. The time spent on the report is as minimal as possible to reduce interference with the operational work. At the same time, the way the report is structured enables systematic data entry for further evaluation, data transformation and generation by a central ergonomic/human factor analyst.
In the blocker report, the data fields are organised in 10 different sections:
-
Blocker identification (e.g. staff identification, aircraft registration, task card number, date and time).
-
Blocker classification/type of blocker (see below).
-
Location in process (as indicated on the replica of the OPM of the check process on the blocker report itself).
-
Direct outcome (e.g. interruption, on hold, work around, extra steps, incomplete work, clutter workspace).
-
Consequences (to immediate workflow, people, process, e.g. re-plan shift, workload increase, delay to next process).
-
Staff involved (e.g. AMA, AME, crew manager, hangar manager, support planner, materials coordinator, tools stores).
-
Impact (e.g. high, medium, low and area of impact, for example, local, across areas, in process, across processes).
-
Suggestion to resolve the blocker (following discussion with the persons colleagues, team and crew manager).
-
Action taken to resolve the blocker (following investigation with the HIT).
-
Closing blocker (Has action been taken? Is initiator satisfied? Is HIT satisfied? Is area manager satisfied?).
The blocker report captures data from the individual, at the point of origin. People who perform the process are in the best position to report on it. It is a self-report and, as such, subjective. However, the conceptual design of the report facilitates it being a building block in a more objective picture of the status of the operational system:
A structure that adopts standardisation by being linked to model based reference points (OPM). | |||||
An overall data integration strategy that links subjective elements with other data sources (e.g. if a query note was raised to the Engineering Department on the same topic) and other stakeholders' perspectives (in particular, work colleagues, crew manager and the HIT) to achieve the best integrated picture of what is known about the system. | |||||
There are two main objectives that the data should support. First, managing individual blockers and, second, identifying system vulnerabilities through trending and analysis of individual blockers. Blockers classification is important in terms of trending the data and blockers are categorised into the following categories:
Input to process: tools/equipment/parts/materials/manpower/information/workpack/taskcard/ planning. | |||||
Task: preparation/task set-up/access/new task/repetitive task/support. | |||||
Process: clarity/interface with other processes/adequacy of procedures/milestones. | |||||
People/team: team set-up/lack of coordination/lack of common understanding/ peer pressure/lack of communication. | |||||
Human factors: time pressure/stress/knowledge/skills/motivation/fatigue/task interruption/training/safety. | |||||
Organisational factors: estimation/contract/workshop/planning/engineering/ quality/human resources/continuous improvement (CI)/organisational learning. | |||||
Organisational culture: leadership/regulations/quality assurance/support/ commercial pressure/external factors. | |||||
Workplace environment: temperature/access/air/noise/lighting/housekeeping/ hangar layout/storage/IT facilities/Lean 5 S's. | |||||
Technology: aircraft/engine/system/sub-system/component/design/new technology/ familiarity. | |||||
Other: Please specify. | |||||
The blocker report has undergone a process of iterative development with all hangar staff and is now on revision 17. This report provides for the collection of data on an ongoing basis. In HILAS the OPM is a living tool and the blockers are gathered on an ongoing basis and resolved at any time, thereby allowing for more organic continuous improvement of the process. In comparison in Lean value stream mapping usually takes place as part of a Kaizen event (a rapid improvement event lasting 1 week), waste is identified and the improvements are made within the week or in a 30 d follow-up improvement plan. It does not allow for the continual gathering of information on problems to processes the way the blocker report does. A simple example of a blocker gathered during normal maintenance activity was ‘faulty jack for main landing gear’.
2.4 Development of the blocker resolution process
A process for resolving blockers to task performance was developed around a meeting schedule. This was developed with a selection of staff from hangar manager to crew managers to AMEs and AMAs, representing different work categories (e.g. sheet metal, avionics) and different zones of the aircraft (e.g. wings, landing gear, cabin). This became known as the blocker resolution process. As noted above from the description of aircraft maintenance the system is extremely complex. A lot of coordination work is facilitated by face-to-face contact with other AMEs, crew managers, etc, particularly at the morning technical progress meeting, which takes place between all crew managers, hangar manager, support planner, materials coordinator and the commercial officer. At this meeting, things such as times where power would be on/off the aircraft or hydraulics would be on/off would be negotiated. Staff felt that it was important that the process to resolve blockers was as simple as the process to report them. They wanted to build on what people already did within the system. Some continuous improvement initiatives in the company in the past had not worked. It was felt by staff that part of the reason for this was that they were not well integrated with what people already did in the organisation. People did not see continuous improvement as ‘part of the day job’. Thus, the blocker resolution process was built into the current meeting schedule that happened in the company, with some extra meetings added to focus specifically on the resolution process.
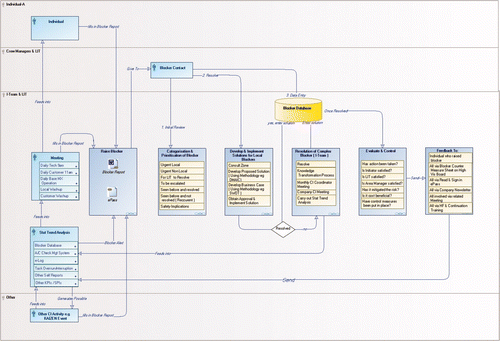
The blocker resolution process was designed to ensure that staff at as local a level as possible to the blocker were able to resolve the blocker. Thus, blockers were initially informally discussed with one's zonal team, if not resolved there it went to the HIT for resolution. This team was made up of the hangar manager, three crew managers (representing avionic, sheet metal and mechanical trades), six AMEs and an AMA (consisting of one avionic, two sheet metal, two mechanical, one operative). The HIT met once per week for 1 h. The blockers were discussed here and possible solutions sought. If the blocker was not resolved at the level of the HIT, it went to the weekly meeting of the Improvement Team, then to the fortnightly meeting of the cross-departmental working group and, if not resolved there, finally to the monthly meeting between the Improvement Team and the Chief Operating Officer of the company. All blockers were recorded in a specially developed database for trending and statistical analysis purposes. Meetings (short and with very focused agendas) became central to the initiative. The HIT were given training in change management, continuous improvement, in the specific HILAS, Lean and Six Sigma tools and technologies, for example, the Six Sigma problem-solving methodology: define, measure, analyse, improve, control (DMAIC). The HIT were also given training in how to hold meetings, how to ensure that everyone at the meeting was enabled to make the best contribution they could, how to take minutes and action items. Standardised forms and templates were developed for this. A more detailed overview of the blocker resolution process can be seen in .
Figure 2. Operational process model of the blocker resolution process. LIT = local improvement team; DMAIC = define, measure, analyse, improve, control; SWOT = strenghs, weaknesses, opportunities, threat; CI = continuous improvement; A/C = aircraft; KPI = key performance indicator; SPI = safety performance indicator.
3 Results
3.1 Overall results
The results of the initiative in terms of meeting the objectives as laid out by management in relation to the first hangar to be involved were significant for the organisation and included the following:
20 aircraft were delivered ‘early’ or ‘on-time’ (no ‘lates’) to the customer, giving 22 d back to the customer. | |||||
This translated into improved aircraft availability for utilisation by the operator by 136 h (8.5 d) over the course of the line of 20 aircraft. | |||||
The contract with the customer included bonus/penalty payment – the maintenance provider ended up receiving a substantial bonus payment. | |||||
There was great involvement of all hangar staff and increased morale. | |||||
The customer was very satisfied and complimented the programme. | |||||
Also, through the iterative development with staff across the 20 checks a model was developed that was subsequently rolled out to other hangars and demonstrated significant results there also.
3.2 Results of the operational process modelling
The major benefit of the operational process modelling of the check system came in allowing all stakeholders to have a shared understanding of the check system and in particular their role in the process and the nature of the dependencies to and from them. As the focus groups happened and the model emerged, people began to understand the ‘bigger’ picture of the check. Zonal teams can often work independently of each other and even on the HIT some people from different trades had not met each other before. This shared understanding in itself led to some suggestions to coordinate and manage the check better. The modelling was important also for understanding and resolving individual blockers to understand their context in the larger check system. Finally, the model and this shared understanding was also helpful in ensuring that suggestions for resolving blockers did not have any negative impact on another area.
Most of the modelling work took place on the check itself (see ). Sufficient time was not spent mapping the other systems that operate around the check. In some instances blockers originated or had cross-departmental implications. In these instances they were more difficult to resolve as the shared understanding of the current situation had not been built up through the modelling. In one blocker, for example, which will be discussed later, planning input led to knock-on delays and frustration for operational personnel. Also, in this first trial, blockers were only raised from the check personnel themselves, not from other departments (the report is being extended to line maintenance and support areas). If blockers were raised from other areas then interesting situations would have arisen. For example, in the company, operational personnel complained of poor estimates for task performance duration but estimation personnel expressed their frustration at lack of data from operational personnel in relation to how long tasks actually took. Thus, both aspects of this situation would need to be understood better and modelled. It is only in engaging all stakeholders in performance improvement that these issues can be addressed effectively. The OPM has been extended therefore to map the overall aircraft maintenance system, including processes such as planning, estimation, etc, in order to link with the process mapping at the check level and have a better understanding of the nature of the dependencies that this relationship creates. A future step is also to link up the OPM of the check to the OPM of flight operations being developed in the flight operations strand of the HILAS project.
3.3 Results of the trial of blocker report
In the initial piloting of the initiative in the first hangar 141 blockers were raised across the 20 checks. Examples of blockers raised include:
Storage of parts on strip out of the cabin is a problem. | |||||
No 110V power at forward cabin door. | |||||
IT scanners missing from upstairs and keyboards locked out. | |||||
Inventory of repetitive parts needed. | |||||
Paperwork – access cards have no panel description. | |||||
Overtime should be monitored to avoid fatigue issues. | |||||
All blockers were categorised using the classification system outlined above. The largest source of blockers was in relation to:
Parts and materials: 34 blockers. | |||||
Equipment: 28 blockers. | |||||
People resources/manpower: 25 blockers. | |||||
Environment: 19 blockers. | |||||
Information resources: 10 blockers. | |||||
Process dynamic/process clarity: nine blockers. | |||||
Actual contract with the customer: three blockers. | |||||
Team: two blockers. | |||||
Communication: two blockers. | |||||
Aircraft technology: two blockers. | |||||
Tools: one blocker. | |||||
Not categorised: six blockers. | |||||
Each blocker was resolved, taking varying lengths of time. A blocker countermeasure sheet was designed to be placed on a high visibility notice board in the hangar, giving all staff a weekly update on the status of each blocker. The impact that these blockers had on task performance was also measured. The total number (n = 231) of reported outcomes of blockers was higher than the number of blockers reported (n = 141). This is due to the fact that in some cases it was felt appropriate to report more than one outcome. In most cases, the occurrence of a blocker resulted in an interruption of the task. The impact of this was usually mitigated by local rescheduling (one of the frequently reported consequences). Other outcomes included work-arounds (alternative way of progressing work) and leaving work in an incomplete state until it could be resumed.
When completing the blocker report, people were also asked to identify, by marking the replicated OPM of the check process on the back of the report, where in the process the problem arose first and where it had the greatest knock-on impact. The greatest impact was in routine and rectification work. The high occurrence of blockers in the routine work phase can be linked to the issues in regard to parts and materials provision into the operation. In general, the rectification phases (routine and non-routine – see ) as well as the ‘close up’ seem to suffer the most from knock-on consequences of blockers occurring during the course of the check. This demonstrates that intervention at earlier parts of the check and upstream from the check could lead to a reduction in a significant amount of downtime at a later time in the check (a finding that would appear to be supported by Baranzini Citation2009). The panel chart blocker, as outlined below, is an example of how the upstream planning process had a significant impact on the actual check process. On the access panel cards there was no description of what the panel was. There was only a number given. The AME had to go into the maintenance manual to find the descriptor text for and location of the panel to be fitted. This required the AMEs to access the data on the computer and identify each panel location before doing the task. This happened on every zone on every aircraft input, taking a lot of time. Similarly, at a more local level, better planning for and provision of equipment for jacking and docking of the aircraft could lead to a reduction in and disruption to the downtime at the routine work stage. Thus, with the blocker report the company could analyse individual problems that arise and could also aggregate data on blockers and use these data to gain insight on and the leverage needed to encourage management to address issues that are arising in different departments and upstream of the check process. What was significant for management was that they were not just getting ‘one-off’ complaints from staff but getting aggregated ‘hard data’ on the amount and impact of problems arising.
3.4 Results of resolving blockers
As noted above, all of the blockers were resolved throughout the course of the 20 checks. This significantly helped to encourage reporting of blockers in the first instance. When the initiative was moved to other hangars, reporting was also high there (104 blocker reports in the first 3 months in the second hangar to introduce the system). If blockers were confined to the hangar then there was a much higher chance that the problem could be resolved quickly by the HIT. It was agreed that the team would meet once per week in a dedicated hour-long meeting on process-improvement activity and resolving blockers. The DMAIC methodology of Six Sigma was used by the team to resolve blockers if necessary. Also each HIT would have an elected representative who would attend a weekly meeting with the Improvement Team and the elected representative from the other hangar HITs. This was to ensure learning across the organisation in relation to improvement, raising and resolving problems, etc. This worked well; for example, discussions took place on proposed solutions to problems that may have been tried out and worked/not worked in an area before. This also helped to support the movement of the initiative from one hangar to the next.
However, if blockers crossed departments then they became more difficult to resolve. As noted above, the modelling of the check had given all of the check staff a greater understanding of the overall system. This understanding, however, was not shared across departments in the organisation, particularly at the level of the cross-department improvement meetings. Representatives from each area would attend the meeting usually in pairs from their department. The team membership shifted a lot depending on who was available that day to attend the meetings. While most engaged well with the process, some department representatives felt it was a waste of their time to be sitting in a meeting discussing blockers, only some of which related to their areas. Thus, meetings started off on a fortnightly basis but ended up becoming monthly and finally on a very disjointed ad hoc basis depending on the nature of the blocker to be resolved.
Part of this problem lay at the door of the Improvement Team, who did not communicate the rationale behind the whole initiative well enough that each person understood the importance for the company as a whole. But this also had to do with the way the company was structured into individual business units, each with their own budget, targets and objectives to meet. The improvement initiative was centred around base maintenance and not enough time was spent working with other departments, bringing their objectives and needs into the process, supporting them, through process modelling of the overall aircraft maintenance system, in understanding more the interrelatedness and interdependencies of their work and maybe even creating improvement teams in each of the areas in a similar way to the HITs. The membership of the Improvement Team could also have been opened up to include a representative from each area. It was hoped the fortnightly meeting would achieve this but it did not. It took a long time even in the Improvement Team to build up relationships among the team and similarly with the HITs, although it was quicker there as there was a stronger sense of being from one area.
An example of a blocker that was particularly difficult to resolve was the panel chart blocker mentioned above. This blocker had a number of different aspects to it. These aspects are outlined here as per the blocker report raised by the crew manager and the subsequent analysis by the HIT.
-
The panel charts were not organised by aircraft zone:
For example, cards can come under; fuselage exterior, cabin door, landing gear nose, strut wing LH slat, wing fuselage fairings – but it cannot be identified what zone it refers to. The Copy Card given to each Crew Manager does not pick out all of the panels relevant to the zone. When staff removed an access panel (192E, 192F on the landing gear) they have to search through the Access Panel Cards to find it – these examples are located under 0008 Centre Accessory.
Another example is under the category ‘ALL’ (0005) numbers 334HB which under the MPD is on the horizontal stabiliser, elevator hinge cover. Why is this in this ‘ALL’ area – why is it not in the ‘TAIL’ zone? All the 334 panels under ‘ALL’ should be in the ‘TAIL’.
Another example in the LANDING GEAR NOSE section (0003) there are 5 panels listed, however there are 6 panels in this area (as per MPD 06–41–00 page 210). The other panel (114AW) is listed under FUSELAGE EXTERIOR (0001). There are numerous other examples of this.(Blocker report, crew manager)
-
The panel charts had no text descriptors and thus there was a requirement by staff for multiple cross referencing:
On the Access Panel Cards there is no description of what the panel is. There is only a number given. You have to go into the MPD manual to find the descriptor text for what the panel is. Is it possible that the information in the MPD manual is cut and paste into the Access Panel Cards? We also need on the Access Panel Card the CARD Number that calls up that panel.(Blocker report, crew manager)
-
The HIT felt the issue raised an efficiency concern:
Extra time spent on documentation is non-value added/waste element to operational process.
Time taken away from other tasks.
-
And an ergonomic/human factors concern:
Increase in cognitive processing demand.
Causing ongoing frustration, motivational impact.
Perceived imbalance between effort to fix this blocker vs. additional workload over 20 checks.
-
And finally a potential for safety concern: ‘It is also a safety issue as if a panel is not in a zone then the refit of this panel could be missed when it comes to the refit of all the panels’ (Blocker report, crew manager).
This blocker crossed several departments and interviews and reviews took place with people from the check, from planning and commercial, from engineering and quality. It turned out that the work packs were produced at another site of the company and were configured by the SAP enterprise resource planning (ERP) system of again another site. Reconfigurations to SAP were not possible due to a backlog; thus, the Planning and Commercial Department produced an in-house interim solution of printing the panel cards out directly from a current copy of the MPD and attaching the relevant page(s) to the task card as referenced on the work pack. However, this interim solution was not aircraft specific and was thus not authorised by the Quality Department. It took 9 months of interventions by the Improvement Team and the Chief Operating Officer to obtain commitment and support from different departments and different site locations to resolve the blocker. This, while taking a long time, was significant in demonstrating the commitment of senior management to the improvement initiative.
3.5 Linking with other company data: existing and future developments
Managing operational performance in aviation requires an integrated approach to the coordinated roles of people in the operational system. This includes flight crew, planners, dispatchers, maintenance technicians, engineers, check managers, amongst many others. It is important to give adequate task support for planning, managing and carrying out the operation. This is evidenced above in relation to the need for modelling the overall aircraft maintenance system, how support functions relate to each other and to the check process, etc. The data gathered here demonstrate that performance of the system in relation to operational, safety and commercial goals critically depends upon other departments and often times what happens before the operation itself starts.
Most maintenance organisations and indeed aviation companies highlight the large amount of data that they gather yet do not often utilise to what they feel might be the best purposes to optimise overall system performance. Each department in the organisation appeared to operate on its own, providing inputs to other areas as per specifically designed ‘service level agreements’. There did not appear to be an overall structure for looking at KPIs pre-check, during check and post-check and on a company-wide scale. As a result of this initiative, a review commenced of data outputs from different departments and a process has started to link financial indicators with other KPIs, safety performance indicators (SPIs) and quality performance indicators (QPIs) across the organisation (e.g. turnaround time, cost, quality/ergonomics/human factors/safety incidents, workforce attendance, overtime hours, etc) into a coherent framework such as that presented by the ‘balanced scorecard’ approach (Kaplan and Norton Citation1996, Citation2006).
At the hangar level, a framework has been developed around four headings: people; process; workplace environment; health and safety. These aspects reflect the different strands of the improvement initiative. The HIT from the hangar not only chose the KPIs that they felt best reflected their work in relation to these aspects but also KPIs that they felt would challenge their behaviour and help improve the working of the hangar. Some KPIs chosen, for example, were attendance levels (under people), turn around time, number of blockers raised and resolved (under process), housekeeping and Lean 5 S audit findings (under workplace environment) and number of personal health and safety issues in hangar (under health and safety). These were updated weekly and presented to all staff, as noted earlier, on a high visibility notice board in the hangar.
At an organisational level, this has not yet been achieved. This is partly because, as noted earlier, the different departments in the company tend to operate as separate business units and it has been difficult to obtain agreement on what would a base maintenance or a company-wide KPI high visibility board look like. The HILAS framework is centred around intervention across the organisation at the operational, tactical and strategic levels. At these levels it is suggested the following data might be collected:
Operational level (‘day-to-day’ or ‘real time’ operations management): Analysis of self-reports from staff (blocker, task card, health and safety, quality discrepancy reporting, suggestion scheme, error reporting schemes). | |||||
Tactical level (‘turning strategy into reality’): Rework, task overrun, query notes, quality audits (process, environment, health and safety), Lean 5 S audits, post-check customer satisfaction surveys. | |||||
Strategic level: Quality data (incident reports, overdue conformances), human resource data (training, competency, attendance, overtime, rosters), planning and commercial data (task estimates, pre-check inputs, task card sign-off, documentation), materials data (part ordering, tracking, delivery), financial data (recoverability, cost). | |||||
A process has also started to look at linking company KPIs/SPIs/QPIs to individual level objectives through the company performance management and development system (ePASS). Future work also needs to happen, linking individual blocker reports with check and company level KPIs. Similarly, check-by-check analysis linked to company level KPIs also needs to happen. Also, from a quality and safety perspective, it is important to learn not just from major deviations, but also from minor variations in performance and outcome. These variations when trended can give a much richer picture of what happens in normal practice. For these reasons, while human performance reporting is central, it needs to be seen in the context of the integration of all other relevant data streams – planning, human resources, flight data records, process outcomes, etc. Thus, data can be gathered from ‘normal’ and ‘non-normal’ performance. It is these data that not only provide the basis for strategic business analysis but also, in terms of ergonomics/human factors, for safety and risk management.
4 Discussion
The main objectives, as set at the initial stage of the process, could be said to have been met from process efficiency and cost reduction perspectives. Overall, the improvement initiative was deemed to have been successful and base maintenance management were happy with the results. It contributed significantly to winning a contract with the same customer the next year. The mix of the different levels of intervention was felt to be an important aspect of designing the improvement system. The improvements taking place at the workplace environment level helped to show staff that management were committed and serious about the initiative and willing to invest in them and their working conditions. Once this commitment had been demonstrated to them, the AMEs responded very well. They demonstrated that when given the responsibility to take charge of designing the improvement initiative, of investigating and resolving blockers, of improving the check, of meeting customer representatives and their needs, they were willing and able to meet the challenge. They felt that they were shown respect when data they had not seen before were put on the high visibility notice boards in relation to overall check performance, combining some of the KPIs/SPIs/QPIs noted above. They were involved in not just identifying problems and possible areas for improvement but were actually empowered and given a budget to resolve them. Their work was recognised and supported in the organisation and they were given adequate time off from their duties to carry out the improvement work. In the beginning, some of the HIT members did not know how to use the company email system. At the end of the first trial they were ‘firing off’ emails to different departments requesting status updates on the resolution of certain blockers.
The work on mapping and modelling the current check process and identifying blockers to task performance based on taking a systems perspective on the location, effect and impact of those blockers led to new understandings of the nature of work performed on checks. As noted in the introduction to aircraft maintenance thousands of tasks are performed on checks and how exactly all of this is done is housed in the heads of AMEs around the world. This work helped to bring some of that to paper and allow organisations to begin to build organisational memory in the OPM of both how that work is done and how the problems in performing that work can be addressed. However, a lot of problems that were difficult to resolve came from outside or upstream of the check. This would appear to support the finding from Baranzini's (Citation2009) work on aircraft maintenance teams. The way teams are organised in aircraft maintenance highlights what he refers to as the team externality concept. This defines: ‘… the specific performance of a system that is not controllable by the work team, which turns out to be dependent on that external performance’ (p. iv). Thus: ‘… for highly dependent systems like operational teams in hangar maintenance it is the environment (externalities) that accounts for performance more than internal team capabilities’ (p. v).
If this is the case, and this work would appear to support that, then the working of the cross-department improvement teams is crucial. However, in this first pilot this did not work that well. Previous research suggests that when setting up initiatives like this time is needed away from the operational realities of the organisation for trust to develop among people (Teague Citation2004, Ward Citation2005). This time was given to the Improvement Team as there was a very obvious acknowledgement that people on that team came from very different backgrounds and it was okay to ask questions of each other and about each other's work. At a cross-departmental level this did not happen. There was an underlying assumption that each area knew what the other did and how they all fitted together in the organisation and worked together to fulfil the overall goals of the organisation. However, this was not the case. The researchers did not pick up on this early enough in the initiative and did not act on it. This can be a downside of participatory action research, where as a participant one is caught up in the ‘action’ to the detriment of the research and reflection. This made the overall effort more not less labour intensive as more time was spent buying over people individually to help resolve different blockers. The elements of an action research story should be an articulation of the context and purpose of the action research project and the cycles of diagnosing, planning action, taking action, evaluating action (Coghlan and Brannick Citation2001). This cycle took place within each component of the initiative; however, on a larger scale there was not enough ongoing forced reflection and evaluation of the initiative to lead to more insightful diagnosing, planning and taking action. In an initiative of this scale where so much time and energy is invested, along with the internal reviews and milestone evaluations that took place within the company, there should be ongoing external evaluation by qualified experts. This, while being part of the project plan, did not take place on a regular basis. Also, this evaluation would need to focus on the cost-effectiveness of implementing such initiatives (Stanton and Barber Citation2003, Gallwey Citation2004).
The work in HILAS is complex and still ongoing. This paper reflects only a small amount of the work that is taking place. Out of this part of the project, however, an embryonic model of an organisation's readiness to implement system change is emerging. This ‘ten-step model’ has yet to be piloted and tested but consists of asking 10 sets of questions and thus could function as a ‘readiness to change audit’. This builds on all of the work noted here and needs further development in the future (see Ward and Gaynor Citation2009).
4.1 Implications for safety management systems and hazard identification
The removal of blockers from the system could also have said to have affected quality and safety. One obvious way that this has an impact on quality and safety is that it increases reporting on problems that are occurring that normally would not be heard of. The Quality Department, for example, became involved in the panel chart blocker. Within aircraft maintenance, voluntary reporting on errors or mistakes made has always been problematic. At a recent meeting labelled Europe's First Annual Error Management Best Practice Symposium (2008) a number of organisations were of the opinion that a successful error management system will generate one or two internal reports per person per annum and this includes near misses and issues that overlap into the health and safety arena. Maintenance tends to suffer from a much lower voluntary error-reporting culture than flight operations (Nisula and Ward Citation2008). Patankar and Driscoll (Citation2004) note in relation to the Federal Aviation Administration Aviation Safety Action Programs (ASAPs) in terms of the events reported to the respective flight operations and maintenance event review committees, the ratio seems to be about 10:1 – flight ASAPs receive about 10 times as many reports as maintenance ASAPs. Patankar and Driscoll (Citation2004) highlight the importance of trust between AMEs and their crew managers as a factor in higher reporting. Other factors they note are that the AMEs must find that the process actually improves safety and the report and the reporting process must be standardised or well understood.
A reporting culture includes a ‘just culture’ and expresses itself mainly as creating good reporting of incidents and near incidents, including both quantity and quality of reports. It is also expressed as a willingness to report by all employees and as the ability of the organisation to bring about certain elements listed here (Akselsson et al. Citation2009). While the blocker report was not an error report, some lessons could be learned from it and the blocker resolution process in relation to error reporting. These findings would appear to support those of Patankar and Driscoll (Citation2004) and are outlined here:
A just culture – one where people feel they can report mistakes made without fear of punishment (deliberate acts of damage or violations are different). In a survey of 53 European aviation organisations, most organisations admitted to still having to work on the ‘no-blame’ aspects of a just culture in relation to mistakes made (Ward Citation2008). This is not specific to the aviation industry, with a survey commissioned by NASA showing that of the 9500 of their staff surveyed: ‘Many employees … believe that speaking up about a perceived safety issue could jeopardise their careers’ (Air Safety Week Citation2004). Through the collaborative development of this initiative, trust was built up among staff involved and people felt that they could report all of the difficulties they were having with task performance as they themselves were the ones investigating and resolving the blockers. It was also significant that they felt that something would happen to any report that they raised and this built confidence in the system over time. This leads onto the next item – motivation for reporting. | |||||
Motivation for reporting – In this initiative the blocker was not an error report. People felt it was ‘informal’ and that they could report anything on it and that something would happen to change the system and rectify the problem they raised. Not all blockers had direct safety or quality implications, however, they could point towards hazards in the system. International Civil Aviation Organisation (ICAO) is currently mandating every aviation organisation to have a safety management system that includes hazard identification as a core feature. ICAO define a hazard as: ‘a condition or an object with the potential of causing injuries to personnel, damage to equipment or structures, loss of material, or reduction of ability to perform a prescribed function’ (ICAO Citation2008). While this was not always the explicit motivation of staff for reporting, a number of reports would fall under this category (e.g. panel chart, fatigue). The main motivation for staff, however, was that through the initiative and the blocker resolution process something would change. | |||||
User-friendly forms for reporting – Investment needs to be made into customising reporting forms for organisations and the individuals using them. The blocker report was designed by the staff for use by themselves. It proved popular with staff and was taken up widely in the organisation. | |||||
Good training and instructions for reporting with usable content – Tailor-made training programmes need to be developed for not just using the reporting forms but for engaging staff in the reports becoming translated into change in the organisation. Training was developed with staff on using the blocker and the blocker resolution process. This training was given by staff to other staff. This gave the overall process credibility and made the training more efficient. | |||||
Feedback to those reporting, showing (a) that and how reports are used and (b) an appreciation to groups with good reporting – feedback was given on a weekly basis to all staff in the hangar via the use of the high visibility notice board. People were thanked regularly for submitting blocker reports. The high level ‘picture’ of the initiative was communicated to all staff via the management communications and the high visibility notice boards. | |||||
A regular follow-up that reporting is functioning – Staff themselves monitored the working of the blocker resolution process ensuring resolution in a timely manner or, if that was not the case, communication on the status of the report. | |||||
Thus, to increase reporting it is essential that something happens to the reports and that somehow the system changes as a result of reporting. It is equally as important that the staff who submit reports are those who are involved in making the changes happen as a result of the reports as this builds trust in not just the system but in the organisation. As noted above, not all blockers were hazards and hazard identification also needs to come from other sources; for example, company voluntary error-reporting schemes, safety surveys, normal operations monitoring schemes such as LOSA, trend analysis, feedback from training, investigation and follow-up of reported hazards and incidents. As also noted above, systems like LOSA have their difficulties and errors are not necessarily predictive of incidents and error management does not necessarily lead to system improvement. Safety surveys and safety culture surveys are an important aspect of measuring performance but they do have their problems. Culture can be defined as the attitudes and values shared by everybody in the organisation. But low scoring subgroups may not be detected from mean values from analysis of safety culture questionnaires. Not even standard deviations may reveal small subgroups and outliers may be dangerous (Akselsson et al. Citation2009). Thus, these methods could be supported by something like the blocker report. By gathering data designed to improve performance, data can also be gathered that not just ensures quality and safety but may even improve them (e.g. improving elements of the system leading to frustration and the possibility for mistakes). Flight operations and maintenance factors combined contribute to over 65% of aviation accidents and to 88% of all ergonomic/human factor-related accidents (Rankin Citation2008). Removing blockers from the system could have a significant impact on this.
A final impact for safety is that the OPM and the blocker report could also provide a way of investigating incidents, such that there is a more systemic account of what was happening in and around the incident. Dekker (Citation2008) argues that there needs to be a clear understanding of the ‘normal’ or ‘informal’ operation of systems so that any behaviour can be looked at or investigated in light of this. For this to happen, however, it is essential that all staff are involved in developing an understanding of the normal operational system. What is unique about the blocker report is that it is grounded in a common view of the operational system through the use of the OPM of the check process. Hazard identification is a crucial part of the move from reactive to proactive risk analysis as recommended by ICAO. However, much standardisation is also needed in the area of actually carrying out risk analysis on hazards. Currently, the formula used is risk = probability × severity of hazard. As many ways as there are to gather data on hazards, so too there are as many rankings that can be given to both the probability and the severity of a hazard depending on a number of factors, including who is doing the analysis. High levels of subjectivity can enter into this process, thus affecting what is considered acceptable levels of risk.
This is another area where HILAS could potentially play a role across the industry. The OPM could provide an ‘organisational memory’ of the ‘normal’ operating system, not just for organisations but for the aviation industry. Data could be linked from ‘normal’ and ‘non-normal’ sources and all these data in relation to the process and its outcomes could be aggregated in one database. This would enable a quantitative assessment of the relationship between all the process inputs/blockers etc and their impacts on process/check outcomes to be analysed. This would enable the building of a quantitative risk model of the operation, which could direct the organisation strategically to where the system as a whole needs to be improved, including planning, supply, etc, in order to achieve more consistent reliable, safer and more cost-effective outcomes.
Acknowledgements
We would like to acknowledge the EU Commission funding for the HILAS project under the 6th Framework Programme and all of the industrial and research partners who are currently iteratively developing and trialling the HILAS tools and methodologies. A special thanks also to all of the staff at the organisation where this part of the project took place.
Related Research Data
References
- ADAMS . 1994–1999 . Human factors in aircraft dispatch and maintenance , Brussels : European Commission . Under the EU BRITE-EURAM Programme. Contract No. BRPR-CT95–0038, Project No. BE95–1732
- ADAMS . . Human factors in aircraft dispatch and maintenance . Programme for Industrial Materials and Technology. Project No. GRD1–2000–25751 . Brussels. European Commission . Under the EU BRITE-EURAM III Programme for Industrial Materials and Technology. Project No. GRD1–2000–25751
- Air Safety Week . 2004 . Space agency seeks safety culture change , Rockville, MD : Access Intelligence, LLC . 3 May, 2004
- Air Transport Association . 2007 . MSG-3 process operator/manufacturer scheduled maintenance development , Washington, DC : ATA Publications .
- Akselsson , R. . Resilience safety culture . paper presented at the International Ergonomics Association Conference . August 2009 , Beijing.
- AMPOS . 1999–2001 . Aircraft maintenance procedure optimisation system , Brussels : European Commission . Under the EU ESPRIT Programme. Project No. 29053
- Baranzini , D. 2009 . Aircraft maintenance teams Thesis (Doctoral). Trinity College Dublin
- Bunderath , M. . The operational impact to the maintainer (ground crew support and human factors) . Aircraft health Management for New operational and Enterprise solutions proceedings . June 15–16 2008 , London, England. The Institution of Engineering and Technology (IET) .
- Coghlan , D. 2002 . Putting ‘research’ back into OD and action research: A call to OD practitioners . Organisational Development Journal , 20 ( 1 ) : 61 – 65 .
- Coghlan , D. and Brannick , T. 2001 . Doing action research in your own organisation , London : Sage .
- Corrigan , S. 2002 . Comparative analysis of safety management systems and safety culture in aircraft maintenance Thesis (Doctoral). Trinity College Dublin
- Dekker , S. 2008 . Just culture: Balancing safety and accountability , London : Ashgate .
- Drury , C. G. , Prabhu , P. and Gramopadhye , A. K. . Task analysis of aircraft inspection activities: methods and findings . Proceedings of the Human Factors Society 34th annual meeting . pp. 1181 – 1184 . Santa Monica, , CA, USA : The Human Factors Society .
- Gallwey , T. 2004 . “ The role of ergonomics today ” . In The Irish Ergonomics Review, 2004 , Edited by: O'Sullivan , L. and Chan , S. Dublin : The Irish Ergonomics Society .
- Gramopadhye , A. K. and Drury , C. 2000 . Editorial . International Journal of Industrial Ergonomics , Special issue, Aviation Maintenance
- Gramopadhye , A. K. and Kelkar , K. P. 1999 . Analysis of shift change in the aircraft maintenance environment: findings and recommendations , Washington, DC : Federal Aviation Administration . Technical Report. Office of Aviation Medicine, Federal Aviation Administration
- Harry , M. J. and Schroeder , R. 1999 . Six sigma: The breakthrough management strategy revolutionizing the world's top corporations , New York, NY : Doubleday .
- Helmerich , R. L. , Klinect , J. R. and Wilhelm , J. A. . System safety and threat and error management: The line operations safety audit (LOSA) . Proceedings of the eleventh international symposium on aviation psychology . pp. 1 – 6 . Columbus, OH : The Ohio State University .
- HILAS . 2005–2009 . Human integration into the lifecycle of aviation systems , Brussels : European Commission . Priority No. 1.4 – Aeronautics and Space Research Area 3. Priority Title: Improving Aircraft Safety and Security, IP8. Proposal/Contract No. 516181
- Hollnagel , E. 1998 . CREAM: Cognitive reliability and error analysis method , Oxford : Elsevier .
- Hollnagel E. Nemeth C. P. Dekker S. Remaining sensitive to the possibility of failure Ashgate Aldershot 2008
- Hollnagel , E. and Woods , D. 2005 . Joint cognitive systems: Foundations of cognitive systems engineering , Boca Raton, FL : Taylor & Francis .
- Hollnagel E. Woods D. D. Leveson N. Resilience engineering, concepts and precepts Ashgate Aldershot 2006
- Hughes , J. N. 2003 . Commentary: Participatory action research leads to sustainable school and community improvement . School Psychology Review , 32 ( 1 ) : 38 – 43 .
- Hult , M. and Lennung , S. 1980 . Towards a definition of action research: A note and bibliography . Journal of Management Studies , 172 ( 1 ) : 242 – 250 .
- International Civil Aviation Organisation (ICAO) . 2008 . Safety management manual (SMM) , second edition , Montreal, , Canada : ICAO . Doc 9859
- Kaplan , S. and Norton , D. P. 1996 . The balanced scorecard, translating strategy into action , Boston, MA : Harvard Business School Press .
- Kaplan , R. S. and Norton , D. P. 2006 . Alignment – Using the balanced scorecard to create corporate synergies , Boston, MA : Harvard Business School Press .
- Liston , P. 2005 . Human factor competence in aircraft maintenance Thesis (Doctoral). Trinity College Dublin
- McDonald , N. 1999 . Human-centred management guide for aircraft maintenance. Final public deliverable of the ADAMS European Commission Research Project , Dublin : Trinity College .
- Nisula , J. and Ward , M. . Challenges of maintenance SMS practical implementation . Presentations to the ICAO Asia and Pacific Ocean Approved Maintenance Organisation and Air Operator Maintenance Organisation SMS Implementation . June 3–4 2008 , Bangkok.
- Patankar , M. and Driscoll , D. 2004 . Factors affecting the success or failure of aviation safety action programs in aviation maintenance organizations [online] The Maintenance & Engineering ASAP Study, Year 2 Report. Available from: http://www.slu.edu/Documents/parks/M-ASAP_Year_2_Report.pdf [Accessed 11 July 2009]
- Patankar , M. and Taylor , J. 2003 . Applied human factors in aviation maintenance , Aldershot, , UK : Ashgate Publishing, Ltd .
- Patankar , M. and Taylor , J. 2004 . Risk management and error reduction in aviation maintenance , Aldershot, , UK : Ashgate Publishing, Ltd .
- Perrow , C. 1984 . Normal accidents, Living with high risk technologies , London : Basic Books .
- Pettigrew , A. 1985 . The awakening giant: Continuity and change at ICI , Oxford : Basil Blackwell .
- Pettigrew , A. and Whipp , R. 1991 . Managing change for competitive success , Oxford : Basil Blackwell .
- Rankin , B. . SMS Risk Management for Maintenance & Engineering . Presentation to the ICAO Asia and Pacific Ocean Approved Maintenance Organisation and Air Operator Maintenance Organisation SMS Implementation . June 3–4 2008 , Bangkok.
- Reason , J. 1987 . “ Generic Error-Modelling System (GEMS). A cognitive framework for locating common human error forms ” . In New technology and human error , Edited by: Rasmussen , J. , Duncan , K. and Leplat , J. Chichester : Wiley .
- Reason , J. 1997 . Managing the risks of organizational accidents , Aldershot : Ashgate .
- Reason , J. and Hobbs , A. 2003 . Managing maintenance error: A practical guide , Aldershot : Ashgate .
- Reason P. Bradbury H. Handbook of action research: Participative inquiry and practice Sage Thousand Oaks, CA 2001
- Schein , E. H. 1989 . Organisation development: Science, technology or philosophy , USA : Massachsetts Institute of Technology . MIT Sloan School of Management Working Paper, 3065–89-BPS
- Schutz , A. L. , Counte , M. A. and Meurer , S. 2007 . Assessment of patient safety research from an organisational ergonomics and structural perspective . Ergonomics , 50 ( 9 ) : 1451 – 1484 .
- Sinclair , M. A. 2007 . Ergonomics issues in future systems . Ergonomics , 50 ( 12 ) : 1957 – 1986 .
- Stanton , N. and Barber , C. 2003 . On the cost effectiveness of ergonomics. Editorial . Applied Ergonomics , 34 : 407 – 411 .
- TATEM . 2004–2008 . Technologies and techniques for new maintenance concepts , Brussels : European Commission . Under EU Aeronautics and Security Programme. Project No. AIP3-CT-2004–502909
- Teague , P. 2004 . Social partnership and the enterprise, some lessons from the Irish experience . Political Economy Review , 2 ( 1 ) : 6 – 35 .
- Wadsworth , Y. 1998 . What is participatory action research? . Action Research International , Paper 2. The Institute of Workplace Research, Learning and Development and Southern Cross University Press
- Ward , M. 2005 . Contributions to human factors from three case studies in aircraft maintenance Thesis (Doctoral). Trinity College Dublin
- Ward , M. . HILAS maintenance solutions . Keynote Presentation made at the Ariworthiness Standards Institute; 8th annual world aviation maintenance seminar and conference . March 11–13 2008 , Prague.
- Ward , M. and Gaynor , D. 2009 . “ The ergonomic design and implementation of an improvement initiative for an aircraft base maintenance check ” . In Irish Ergonomic Review , Dublin : The Irish Ergonomics Society .
- Weick , K. E. 2001 . Making sense of the organisation , Oxford : Blackwell Business .
- Welch , J. and Byrne , J. A. 2001 . Jack, straight from the gut , New York : Warner Books .
- Womack , J. P. , Jones , D. T. and Roos , D. 1991 . The machine that changed the world: The story of lean production , New York : Harper Perennial .
- Womack , J. P. and Jones , D. T. 2003 . Lean thinking, banish waste and create wealth in your organisation , 2nd edition , New York : Free Press .