
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Large negative stock and equity portfolio rates of return occur more frequently than they should under the Gaussian normal distribution. They tend to be kurtotic, roughly as if they were drawn from Student T-distributions with 2 to 5 degrees of freedom. A very easy adjustment to help assess the probability of losses is to work with a transformed Z score, For example, one should expect a stock return that is 17 standard deviations below the mean under the empirical distribution as often as one would expect to see a draw that is
standard deviations below the mean under the idealized normal distribution.
PL Credits:
Mandelbrot and Mandelbrot (Citation1997) and Fama (Citation1965) first described the remarkably fat-tailed nature of stock returns. Their observations have taken on more importance in recent decades. After the 1987 stock market crash and with the popularization of the related subject of “never-seen-before events” in Taleb (Citation2007) (with applications to option pricing and the equity premium, e.g., Welch Citation2016), both academics and investors are now increasingly worried about the far left tail of the distribution. Some papers have offered sophisticated analyses of univariate fat-tailed distributions—for example, as in Kon (Citation1984) or Koning, Cassidy, and Ouyed (Citation2018)—and papers pointing out that mixed distributions can dynamically generate fat tails—for example, in Bollerslev (Citation1986).
It is not the purpose of this paper to provide sophisticated modeling of statistical processes, much less to distinguish among them. Instead, it is to provide a quick and easy rule of thumb to assess probabilities for the fat-tailed equity return distributions that practitioners and academics usually have to work with. It is hoped that many analysts will then no longer merely pay short lip service to the fat tails before ignoring them. With this paper’s quick heuristic rule, better assessments become much easier.
There are good reasons to work with my simpler heuristically adjusted Z score (the Z′ score), rather than with the full statistical machinery of fat-tailed distributions. The former (Z′-score approach) is easy to use but only “roughly appropriate.” The latter could be more precise but requires estimating the appropriate kurtosis and distribution values. This opens up a few new cans of worms. The data may not be available, especially when one analyst is asked only to assess the work of another.Footnote1 When analysts publicly describe data, they often report just mean and standard deviation, rather than a deep analysis of skewness, kurtosis, and so on. There is also a disincentive to report tail estimates if one’s peers are not reporting likewise. Finally, “blissful ignorance” avoids arguments about the number of degrees of freedom and the flexibility that analysts often prefer to avoid.
illustrates both the problem and my proposed approach in the context of daily value-weighted market rates of returns from CRSP. The data begin on 3 July 1962 and end on 31 December 2023. The lowest rate of return of −17.1% occurred on 19 October 1987. With 15,480 days, the empirical probability of such a large negative return was about 0.00646%, or once every 61 years or so.
Table 1. Daily Value-Weighted Market Rates of Return, Post 1962/07/03, 15,479 Days
A daily rate of return mean close to zero and a standard deviation of about 1% per day translates into a Z score of −17. Using the normal Gaussian inference machinery would incorrectly assess the probability of observing a Z score this low to be This is many orders of magnitude rarer than what one would expect to observe, not only given 60 years of data but even given the age of the universe.Footnote2 Instead, if the empirical distribution were representative of the true distribution, an empiricist should have worked with an adjusted Z score that would have suggested an empirical probability of 0.00646%, once in every 15,480 draws. The normal distribution table shows that this adjusted Z score would have been −3.83.
The heuristic adjustment formula proposed here (with reasoning explained in the Appendix) offers an approximation of this best-to-use empirical Z estimate. It suggests using a corrected Z statistic of
instead of the original
This is not as good as a perfect empirical approximation, but it is a good and reasonable one. Researchers who are familiar with Z scores would immediately assess this −4.09 to be a very rare but not an outright impossible scenario. Translated into probability space and compared to the best-to-use empirical Z estimate, the heuristic
mistake amounts to an additional probability mass of 0.000042 (assessing 0.000022 instead of 0.000065). This mistake is even less than the probability mass of 1 in 15,480 days (0.0000646)—well within empirical estimation error for events so far in the tail. The mistakes for other Z scores, shown in , from about −4 to about −9, are similarly small. The heuristic
score fit well.Footnote3
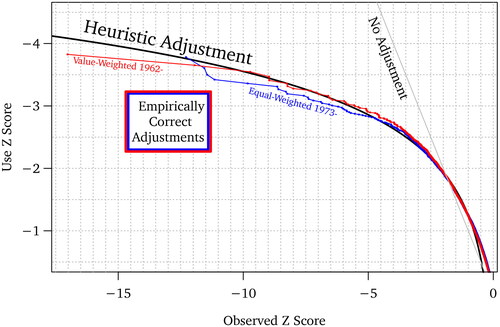
plots a visual illustration using two interesting example series. These are the value-weighted market rate of return from 1963 to 2023 and the equal-weighted market rate of return from 1973 to 2023. The plot shows the no-adjustment “naïve use” Z score input, which is useful if the data had come from a true normal distribution; the heuristic formula proposed Z score transform, and the empirically best Z-score. The plot reveals the following:
For untransformed Z inputs between −0.2 and −1.9, the
score after the heuristic-formula transform is less conservative (i.e., above the unadjusted Z score).Footnote4 However, (a) the differences between the untransformed Z and the transformed
For untransformed Z scores more negative than −1.9, the adjusted
Figure 1. Z Scores for Daily Market Rates of Return
extends the analysis to other starting periods. The heuristic adjustment formula works just as well as it did from 1962 to 2023 in . The scores are again very close to what they should be given the empirical distribution. They are both empirically and visually difficult to differentiate.
Table 2. Daily Value-Weighted Market Rate of Return, Later Starts
The appropriateness of the heuristic adjustment formula depends on the fat-tailedness of the distribution, which can be measured. provides statistics for the kurtosis and maximum-likelihood degrees of freedom of the empirically observed distribution of rates of return for various market and two size (marketcap) portfolios. The two are not monotonically related, because the latter considers not just the kurtosis but also other moments in its fit. All empirical kurtoses are far above the 3.0 expected for the normal distribution. If Black Friday is excluded, the estimated degrees of freedom for Student T distributions lie between about 2.7 and 6; the exception is the small and equal-weighted market daily stock returns from 1973 on and the value-weighted market monthly stock returns from 1998 on, all of which reach above 7. The degree-of-freedom estimates for the data of and were 3.05, 2.78, and 3.27, respectively. The heuristic formula fits well for all these cases.Footnote5
Table 3. Empirically Estimated Kurtosis and Student T Degrees of Freedom
To assess the robustness of the adjustment formula, we can look briefly at one more extreme case in which the estimate for the degrees of freedom is higher (less kurtotic, more Gaussian normal) and in which there are far fewer observations. examines value-weighted monthly market rates of return after 1978, with its estimate for the Student T degrees of freedom of 7.03. There are only 312 months to work with. shows that its worst month had a rate of return equivalent to a Z score of −4.08. With 312 months, the empirical frequency suggests a monthly occurrence of about 0.3%, that is, about once every 26 years. The appropriate Z score to match the empirical distribution in a normal table would have been −2.73. The heuristic formula adjusts the more misleading score to a better
score.
Table 4. Monthly Value-Weighted Market Rate of Return, 1998, 312 Months
In general, the formula seems to fit remarkably well for Student T distributions from about 2 to about 10 degrees of freedom. Beyond 10 degrees of freedom, the Student T distribution becomes more like the normal distribution and the use of the unadjusted Z rather than the adjusted becomes more attractive again. However, stock returns are rarely this normal.
expands the perspective to non-market portfolios. In particular, it explores the two extreme decile marketcap portfolios on CRSP. There is not much to be said. The formula does a good job adjusting poor Z scores to better scores for both portfolios. Recall that showed the degrees of freedom estimates for these portfolios in this sample to be about 5 and 7.
Table 5. Extreme CRSP Size Decile Rates of Return, Post 1973, 12,861 Days
expands the perspective even further, now to the zero-investment factors developed by Fama and French (Citation2015) (and some others posted on Ken French’s website). Again, the heuristic estimates fit just as well as they did for the overall market, not only in the United States but also in Europe and Japan.
Table 6. Fama–French Daily Factors, Post 1973
expands the perspective further again, this time to (thousands of) individual US stocks. And, again, the Z′ performance seem as good as before. The adjustment formula would work quite well for at least about 95% of individual stocks.
An earlier draft explored whether kurtosis also distorts regression coefficients and consequent inference, for example, in Fama–Macbeth regressions that explore whether value metrics can predict future stock returns. The answer is that such coefficient inference is barely distorted at all. Ordinary least squares coefficients and coefficient standard errors are very robust to non-normal conditional error distributions. (This extends to even more extremely different distributions, like the binomial distribution.) Note, however, that if such regressions are then used to predict stock return performance and losses, not only the coefficient estimates but also the error estimates become relevant again. In this case, the above empirical heuristic adjustment would become important again.
Table 7. Individual Stocks
Conclusion
There is only one important aspect of this paper worth remembering:
For negative Z scores, better probability assessments for stock and portfolio returns can be obtained by using the heuristic adjustment formula:
The improvement is modest for Z scores between 0 and −2, but it becomes progressively larger and more important for Z scores more negative than −2, that is, further in the left tail.
Secondarily, this paper also offered some empirical evidence about the fat-tailedness of a variety of recent stock and portfolio return distributions. If one wants to think of daily or monthly stock returns in the context of Student T distributions, empirical stock returns have resembled Student T distributions with between 2 and 7 degrees of freedom when including Black Tuesday (October 1929) and between 3 and 7 degrees of freedom when sample periods start thereafter.
usethis.pdf
Download PDF (199.6 KB)Disclosure:
This research was conducted independently, without external support or conflicts of interest.
Additional information
Notes on contributors
Ivo Welch
Ivo Welch is the J. Fred Weston Distinguished Professor at the Anderson Graduate School of Management at UCLA, Los Angeles, CA.
Notes
1 Even when the data are available (which is not always the case), it is also easy to make a mistake working with the unadjusted standard deviation and the Student T distribution. Jonathan Lewellen graciously pointed out to me that my first draft had missed a necessary correction.
2 A common way to diagnose (but not adjust for) this problem statistically is through maximum likelihood estimate of the power coefficient in the Pareto distribution of extreme values (Hill Citation1975). (This is the slope of the extreme value distribution at the tail beyond a researcher-chosen cutoff.) Not surprisingly, the Hill statistics strongly indicate that returns are not drawn from a normal distribution.
3 The illustrative Z scores in the table were chosen as the 5th, 10th, 15th, and 20th lowest realization plus, where appropriate, the realizations closest to Z scores of −6, −5, and −4.
4 There are two roots to Due to the local curvature of the log function, the difference between the unadjusted Z and the adjusted
score remains small, between 0 and −2.
5 I am not using a formal metric to judge “fitting well.” There are issues related to whether a difference from 1.1 to 1.4 is more important than a difference from 4.1 to 4.4. The probabilities are 0.136, 0.080, 0.001, and 0.0003, respectively. The first two have higher absolute probability differences (0.055 vs. 0.0006), while the latter two have higher relative probability differences (1.7 vs. 2.9 times).
References
- Bollerslev, Tim. 1986. “Generalized Autoregressive Conditional Heteroskedasticity.” Journal of Econometrics 31 (3): 307–327. doi:10.1016/0304-4076(86)90063-1.
- Fama, Eugene F. 1965. “The Behavior of Stock-Market Prices.” The Journal of Business 38 (1): 34–105. doi:10.1086/294743.
- Fama, Eugene F., and Kenneth R. French. 2015. “A Five-Factor Asset Pricing Model.” Journal of Financial Economics 116 (1): 1–22. doi:10.1016/j.jfineco.2014.10.010.
- Hill, Bruce M. 1975. “A Simple General Approach to Inference about the Tail of a Distribution.” The Annals of Statistics 3 (5): 1163–1174. doi:10.1214/aos/1176343247.
- Kon, Stanley J. 1984. “Models of Stock Returns—A Comparison.” The Journal of Finance 39 (1): 147–165. doi:10.2307/2327673.
- Koning, Nico, Daniel T. Cassidy, and Rachid Ouyed. 2018. “Extended Model of Stock Price Behaviour.” Journal of Mathematical Finance 08 (01): 1–13. doi:10.4236/jmf.2018.81001.
- Mandelbrot, Benoit B., and Benoit B. Mandelbrot. 1997. The Variation of Certain Speculative Prices. The University of Chicago Press.
- Taleb, Nassim Nicholas. 2007. The Black Swan: The Impact of the Highly Improbable. (2nd ed) New York: Random House.
- Welch, Ivo. 2016. “The (Time-Varying) Importance of Disaster Risk.” Financial Analysts Journal 72 (5): 14–30. doi:10.2469/faj.v72.n5.3.
Appendix A.
Chosen Formula Approximation
A good adjustment formula translates the Z statistic of the empirical distribution into an equivalent “as-if” Z statistic of a normal distribution. Ideally, an adjustment-map function would satisfy, for all x (or at least for very negative x) that the resulting left-tail probabilities match:
where F is the to-be-matched cumulative distribution function and Q is the quantile function (the inverse of F). Although this is easy to approximate numerically, there are no closed-form solutions for g even when the to-be-matched distribution is not an empirical but a well-known analytical statistical distribution (such as a Student T). Moreover, we are also not interested in a perfect adjustment formula
but in an approximate and more easily remembered heuristic one. The log-linear form, that is,
with its strong curvature in x, is indicated by a visual inspection of the empirical distribution in . Similar log-related formulas appear commonly in extreme-value statistics.
For intuition, consider the case in which the true distribution, is the (more fat-tailed) Student T distribution. shows the best coefficients on an adjustment formula of the form
for Student T distributions with various degrees of freedom (fat-tailedness). The chosen heuristic approximation of
is near a best-fit 3.2 degrees of freedom, rounded to make the formula easier to remember. Although the (a,b) coefficients look different for different degrees of freedom, they move in opposite directions and thus their fitted values are not greatly different. For example, for an empirical Z score of −5, for 2 degrees of freedom (i.e., the −2.07,−0.57 coefficients) suggests a revised Z score of −2.99. For 3 degrees of freedom, the Z score is −2.95. For 4 degrees of freedom, it is −3.06. The rounded in-text heuristic of
suggests −2.86. Compared to the unadjusted Z of −5, the disagreements among approximation formulas ranging from −2.86 to −3.06 appear trivial.
Table A1. Well-Fitting Formula on Z Scores Below −3
Natural heterogeneity among different empirical return series and general robustness considerations suggest that this heuristic formula is often “good enough.” Researchers who need more accuracy are advised to work with estimates of kurtosis and/or their distributions directly rather than rely on the simple approximation used here. However, it is unclear whether such accuracy can even be meaningfully empirically obtained, given the limited number of centuries of stock return data available.