
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The Heston model is a well-known two-dimensional financial model. Because the Heston model contains implicit parameters that cannot be determined directly from real market data, calibrating the parameters to real market data is challenging. In addition, some of the parameters in the model are non-linear, which makes it difficult to find the global minimum of the optimization problem within the calibration. In this paper, we present a first step towards a novel space mapping approach for parameter calibration of the Heston model. Since the space mapping approach requires an optimization algorithm, we focus on deriving a gradient descent algorithm. To this end, we determine the formal adjoint of the Heston PDE, which is then used to update the Heston parameters. Since the methods are similar, we consider a variation of constant and time-dependent parameter sets. Numerical results show that our calibration of the Heston PDE works well for the various challenges in the calibration process and meets the requirements for later incorporation into the space mapping approach. Since the model and the algorithm are well known, this work is formulated as a proof of concept.
1. Introduction
In finance, calibrating model parameters to fit real market data is challenging because most model parameters are implicit in the real market data [Citation4,Citation8,Citation12,Citation14,Citation15,Citation17]. We consider the well-known two-dimensional Heston model, which contains at least four parameters implicit in the market data. The Heston proposed a two-dimensional stochastic differential equations (SDE) model to simulate the behaviour of the stock price [Citation6] and presented a closed-form valuation formula for his model. Some calibration techniques are based on this formula [Citation4,Citation15]. The closed-form equation has some restrictions w.r.t. improving the model by considering non-constant parameters [Citation15]. Another strategy to improve the model is to introduce additional processes, which leads to an increase in the difficulty of the calibration process [Citation17]. Since the stock price and variance are stochastic processes in the Heston model, Monte Carlo optimization methods can be applied [Citation17]. New approaches also consider deep learning strategies and neural networks to calibrate the Heston model [Citation8,Citation11–13]. Another recent approach is to improve the calibration by using faster methods, such as a parallel GPU implementation [Citation5]. We consider the well-known two-dimensional Heston model, which contains at least four parameters implicit in the market data. The parameter calibration is formulated as a constrained optimization problem to minimize a cost functional. The cost functional describes the difference between the reference data, the subsequent market data, and the data obtained by numerically solving our model. In the space mapping approach [Citation1], a coarse and a fine optimization solver are used. This paper presents the first step ”a gradient descent algorithm” for the Heston model towards a space mapping approach in finance. Later, within space mapping, the gradient descent algorithm will compute a coarse and cheap approximation for the calibration problem of the Heston model.
Our goal is to introduce the space mapping approach to financial applications, and therefore we use the log-transformed normalized Heston model formulated as a partial differential equation (PDE) and the gradient descent algorithm as a pre-step, since both are well known and thus we can focus on the novel aspects. During our research, we didn't find any other PDE-based calibration approach for the Heston model. Of course, we are aware that there are already algorithms to compute the exact solution of the Heston calibration problem [Citation4]. However, these methods are limited to the assumption that the parameters are constant, whereas our approach considers time-dependent parameters and constant parameter calibration. Furthermore, if the parameters are assumed to be time dependent, an analytical solution can't be derived and thus an exact solution is not available. Therefore, as mentioned before, the paper is considered as a proof of concept to introduce a new calibration method based on financial research.
We focus on deriving a gradient descent algorithm for the Heston model that satisfies the requirements for its use in the space mapping approach. In addition to our financial model, the gradient descent algorithm requires the adjoint of the model. Therefore, we formally derive the adjoint of the Heston model and construct the gradient using well-known techniques from optimization of partial differential equations (PDEs) [Citation7,Citation18]. The gradient descent algorithm has previously been applied to the Heston model using neural networks, so it has not been explicitly computed [Citation13]. In this work, we focus on the calibration rather than the numerical solution of the model, i.e. our obtained results can be further improved by using more accurate numerical methods. Nevertheless, the calibration results obtained are remarkable. Our attempt can be easily extended to include time-dependent parameters for the variance, thus providing an improvement over current calibration strategies based on the semi-analytical solution of the Heston model.
The rest of the article is organized as follows. In Section 2, we introduce the Heston model and our approach to solving the resulting log-transformed Heston PDE. We then focus on parameter calibration. In Section 3, we derive the adjoint of the log-transformed Heston model and the corresponding gradient. We then discretize the method in Section 4 Finally, in Section 5 we focus on numerical results for the application of the gradient descent algorithm. We analyse the behaviour of the algorithm in various problems for constant and time-dependent parameter calibration. The paper ends with a conclusion and an outlook in Section 6.
2. The Heston model
The Heston model was proposed by Heston in 1993 [Citation6] and describes the dynamics of the underlying asset and the variance
by a two-dimensional SDE. This model is an extension of the well-known Black-Scholes model, which considers only a stochastic process for the asset and leads to
(1)
(1) where
is the risk-free rate,
is the volatility, and
is the Brownian motion. Heston introduced a second stochastic process for volatility by introducing
. He assumed that volatility follows an Ornstein–Uhlenbeck process, which can be rewritten as a Cox–Ingersoll process for the variance ν. This leads to the SDE system of Heston's model under the risk-neutral measure given by
(2)
(2) where
is the mean reversion rate,
is the long term mean, and
is the volatility of variance. The Brownian motions
and
are correlated by the constant
[Citation6]. For the variance process to be positive, the Feller condition
must be satisfied. If the Feller condition is violated, the (Equation2
(2)
(2) ) becomes complex which leads to computational problems. Using Kolmogorov's backward equation, we derive the Heston PDE under the risk-neutral measure
(3)
(3) where
denotes the fair price of the option. If we look at the European plain vanilla put option, the terminal condition (‘pay-off’) is as follows
(4)
(4) where
denotes the predefined strike price. Heston proposed the following boundary conditions
(5)
(5)
(6)
(6)
(7)
(7)
(8)
(8) The boundary conditions for the underlying follow directly from the assumptions on the financial market. We reverse the time direction by introducing
and thus the payoff condition (Equation4
(4)
(4) ) becomes an initial condition. Next, it is advantageous to use the variable transformation
for the asset, as it simplifies the numerical implementation, i.e. we obtain a log-transformed variable with normalization to the strike price K. We rewrite the option price equation as
and obtain the so-called log-transformed normalized Heston PDE
(9)
(9) defined on the semi-unbounded domain
,
,
and supplied with the initial condition
(10)
(10) and the following boundary conditions
(11)
(11)
(12)
(12)
(13)
(13) The boundary conditions for the underlying asset are the normalized log-transformation of Heston's proposed boundary conditions (Equation5
(5)
(5) ), (Equation6
(6)
(6) ) and (Equation8
(8)
(8) ). At
the parabolic PDE degenerates to a first-order hyperbolic PDE, and therefore we need to consider the Fichera theory [Citation2,Citation10] to assess whether it is necessary to provide these analytic boundary conditions or not.
From the Fichera condition at given by
(14)
(14)
it follows
if
(outflow) we must not supply any boundary conditions at
if
In the sequel, we assume that the Feller condition is satisfied. Therefore we obtain an outflow boundary at
and must not impose any analytic boundary conditions on this boundary. But we obviously need a numerical boundary condition to complete the scheme, which will be later discussed in Section 4.
In addition to the Heston PDE with constant parameters for the variance process, we also consider the time-dependent parameters ,
,
, as well as
. Then the corresponding PDE formulation is given by
(15)
(15) In the numerical simulations 5, we will also discuss variations of the constant and time-dependent parameter.
3. Derivation of a gradient-based optimization strategy
For a given data set and reference parameters
, we formulate the calibration as optimization task with the cost functional given by
As our aim is to fit the parameter to real market data and therefore no
exists, we set
and the cost functional reduces to
(16)
(16) In the following, we derive a gradient-based algorithm that allows us to calibrate the parameters numerically. To this end we use a Lagrangian approach.
3.1. First-order optimality conditions for the Heston model
Let us denote the Lagrange multipliers by , set
and split the boundary
into
First, we focus on the log-transformed normalized Heston equation with constant parameters (Equation9
(9)
(9) ) and define
Then it can be written as
Next, we define the operator e which will represent the constraint in the Lagrangian. Since at no boundary condition has to be given, we introduce
and the operator e is implicitly defined by
(17)
(17) The Lagrangian for the constrained parameter calibration problem is then given by
We formally compute the first-order optimality conditions by setting dL = 0. For details on the method we refer to [Citation7,Citation18]. Before computing the Gâteaux derivatives of L in arbitrary directions [Citation7], we note that by Green's first identity, it holds
(18)
(18) Therefore, we can rewrite
As e is linear in V, the Gâteaux derivative in some arbitrary direction h reads
For the cost functional we have
To identify the adjoint equation, we consider
for arbitrary h. Note that we are not allowed to vary
at
as the initial condition is fixed. Therefore we have
.
For choosing on
and
, we find with the Variational Lemma
Now, choosing
, we then obtain the terminal condition
.
We consider the four boundary conditions separately. At , also the parabolic adjoint PDE degenerates to a first-order hyperbolic PDE, and thus we have to consider the Fichera theory [Citation2,Citation10] for the variance again.
The Fichera condition w.r.t. the variance at of the adjoint is the same as before. Therefore no analytic boundary condition is supplied for this boundary, as we assume that the Feller condition holds. On
we have
(19)
(19) Choosing
yields
hence
. On the other hand, choosing
(Equation19
(19)
(19) ) must still hold. This yields
on
and
As
is given and independent of x, we obtain
there and thus
at this boundary. Similarly, we find on
that
(20)
(20) With the same arguments, we obtain
and
on
as well. Following the same arguments for
we obtain
with
and thus it reduces to
As
is given and independent of ν, we obtain
there and thus
at this boundary.
Altogether, the adjoint equation reads
(21)
(21)
which is equivalent to (22)
(22) with terminal condition
and
on the boundaries
,
and
and the outflow boundary at
.
3.2. Derivation of the gradient
Let be the parameters to be identified, as r and q are given by the data. We compute the optimality condition by setting
. Since the boundaries
,
and
are zero, we focus on
. In the following, we state the derivatives w.r.t. the different parameters separately. For
we get
Similarly, we obtain for the other derivatives
Note that
needs to hold for arbitrary directions
. Therefore, we can read off the gradient from the above expressions.
We extend this gradient formulation for time-dependent parameter . The gradient is then time-dependent as well and given by
3.3. Gradient descent algorithm for the parameter calibration
Solving the first-order optimality condition all at once is difficult due to the forward-backward structure. Therefore, we propose a gradient descent algorithm in the following.
For a given initial parameter set , we can solve the state equation for the Heston model with constant control variable ξ (Equation9
(9)
(9) ) or time-dependent parameter (Equation15
(15)
(15) ). With the state solution at hand, we can compute the corresponding adjoint equation (Equation21
(21)
(21) ) or (Equation22
(22)
(22) ) backwards in time. Then we have all the information available to compute the gradient and update the parameter set using a gradient step. The procedure is sketched in algorithm 1.

Since the parameter domain for ,
,
and ρ is restricted, as well as the constraint that the Feller condition has to be fulfilled, we use the projected Armijo rule [Citation18]. In the projected Armijo rule, we choose the maximum
for which
Here
is a numerical constant, which is problem-dependent and typically chosen as
. We will use this value for the numerical results later on.
4. Discretization
In this section, we introduce a closure boundary condition at for the Heston and its adjoint and perform a domain truncation to discretize the problem. Following the Fichera theory and assuming that the Feller condition holds, no analytical boundary condition needs to be imposed at
, neither for the Heston model nor for its adjoint, since the PDEs have a pure outflow boundary at this point. Nevertheless, we need a closure condition for this boundary for the discretization. We suggest to follow Heston's approach, as discussed in Refs [Citation3,Citation10] and use the reduced hyperbolic formulation of the Heston PDE and its adjoint. At
, we obtain
(23)
(23) for the log-transformed normalized PDE and similar for the adjoint
(24)
(24) Now, we perform a domain truncation to obtain a rectangular grid, instead of a semi-unbounded domain and introduce the grid points. We consider uniform meshes in each direction and obtain for the spatial directions
for
with
and
for
with
, as well as
for
with
for the temporal direction.
Since this is a proof-of-concept, simple and well-known spatial and temporal discretization methods are used to illustrate our approach. For the time discretization, we use the well-known alternating direction implicit (ADI) method, in more detail the Hundsdorfer-Verwer scheme [Citation9]. This scheme is of second order for any choice of θ, where θ is a measure of classification similar to the θ-method and is able to handle mixed derivative terms. To present the ADI method, we use a general second-order PDE formulation
(25)
(25) Since the log-transformed normalized Heston PDE and its adjoint are second-order PDEs and we further use the same discretization.
In the first step, we split the operator of the PDE into three operators
(26)
(26) with
where
describes the discretization matrix of the first derivative w.r.t. x and accordingly
of the second derivative w.r.t. x,
and
of the first and second derivative w.r.t. ν, I denotes the identity matrix. The discretization matrices are derived using central finite differences. Let
and simplify
. In each time step, we have to solve the following system of equations
(27)
(27) We choose
and improve the implementation as we used the approach in [Citation16] by using a matrix based instead of a vector-based implementation of
.
At this point, we have to discuss the boundary conditions for the Heston model again. We start with the x dimension. We set and similar
, as we suggest a sufficiently small
and a sufficiently large
. For the variance boundaries, we follow the approach of Kùtik and Mikula [Citation10]. Due to the Fichera theory, at
we gain an outflow boundary and no information can enter the domain from the region
. Since the same holds for the adjoint, we propose the same approach there. In these, we extend the numerical domain for this case and introduce ghost cells
,
where
and determine the ghost cell values
,
by zero order extrapolation. We obtain a constant function
(28)
(28) Now we consider the boundary, where
and the truncation shrinks the domain from
. Dirichlet boundary condition from Heston would cause an unnatural jump in the solution. Therefore different strategies have been developed to overcome this issue, e.g. [Citation10]. Again, we follow Kùtik and Mikula and impose artificial homogeneous Neumann boundary conditions. The choice is motivated by the variance independence of the original boundary condition from Heston, for sufficiently large
. Again, we use zero-order extrapolation to implement this condition. We add ghost cells
,
where
and determine their values
,
by a constant function
(29)
(29) For a discussion about different numerical boundary conditions for the variance of the Heston model, we refer to [Citation3]. The integrals appearing in the gradient are computed by the trapezoidal rule.
5. Numerical results
Following [Citation3], we use
(30)
(30) for generating an artificial
for each time step
. For the discretization, we use
As bounds for the projected Armijo rule for
, we set
Note that the projected Armijo-rule ensures that the Feller condition holds within each optimization step. Hence we are in the case of an outflow boundary. We set the maximal iteration value for the calibration to 20. For the initial guesses
we used generated random numbers within a maximal percentage difference from
. We use four different percentages 10, 25, 50 and 75 and for each we generate five sets. The initial parameters as well as the calibrated parameters in the constant case are given in Table for
, Table for
, Table for
and Table for ρ.
Table 1. Five initial values sets for for the different percentages and the corresponding calibrated values for C0.
Table 2. Five initial values sets for for the different percentages and the corresponding calibrated values for C0.
Table 3. Five initial values sets for for the different percentages and the corresponding calibrated values for C0.
Table 4. Five initial values sets for for the different percentages and the corresponding calibrated values for C0.
We observe that the calibration leaves nearly untouched, whereas the other parameter values are significantly changed. This could be reasoned by the structure of the drift term
, since
and
are multiplied. As a optimization measure, we compute the relative reduction of the cost functional using
(31)
(31) Table shows the relative reduction of the cost functional for the different test cases for
.
Table 5. Relative reduction of the cost functional computed with Equation31(31)
(31) using the different test cases for
and
in the constant calibration setting.
As the calibrated values differ over the test cases, it is reasonable to assume, that we only find local minima. However the results are remarkable.
Since in the real market the parameter are not considered as constant, we improve the approach by considering different parameters, and some parameter sets as time-dependent. From the relative change in the constant calibration setting, we choose the following (additional) test cases listed in Table . Further the table includes the links to the cost functional reduction tables and figures of the cost function evolution with respect to the different cases.
Table 6. Different cases for calibration setting.
For each case of the time-dependent test cases is generated as before and
is assumed to be constant and thus also the same as before.
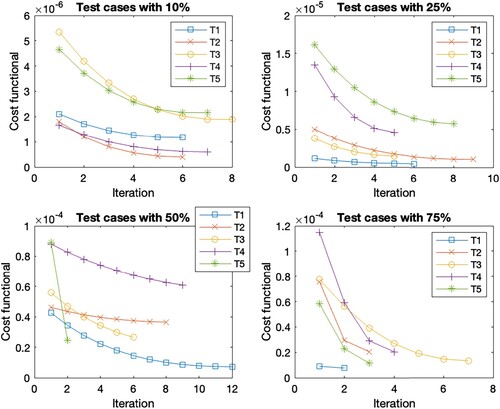
In general, the Figures show the same cost functional evolution. The first test cases with the initial guess closest to the reference set have the smallest initial cost functional value. As the distance to the reference set increases, so does the initial cost function value. Accordingly, the final cost function value is higher for the sets with a more distant initial guess. But the deviation within the initial guess shows the largest cost function reduction within the first steps. This is due to the existence of different minima, as these sets find the closest minima instead of the optimal minima. Overall, the reduction of the cost function per iteration decreases as the number of iterations increases. The number of iterations within the different test cases with a 10 % deviation is the same for all scenarios, except for T2 where it varies between 7 and 8. The scenarios with 75 % deviation give the same number of iterations in cases T1, T2 and T5, for cases T3 and T4 we observe iteration numbers with a total difference of one from each other. For the deviation of 25 %, we observe the same number of iterations for T1, a difference of one iteration for T2, T3 and T4 across all scenarios, and a difference of two for the last case T5. The largest difference within the number of iterations is found in the 50 % deviation. While T5 has the same number of iterations and T2 has a total difference of 2 for all cases. For the other test cases, Table shows the number of iterations. These are the only cases where we see an increase in the number of iterations due to considering time-dependent parameters since the number of iterations increases when
is considered time-dependent. These are highlighted in bold in the table. If we look at the corresponding Figures , , as well as , we observe that the reduction of the cost function in the end is very small, s.t. the gain from iterations 10 forward is almost negligible. Thus, 10 iterations are sufficient for a sufficient cost function reduction in all cases.
Figure 1. Cost functional evolution per iteration for the test cases within the constant parameter calibration.
We have highlighted the largest relative cost functional reduction with bold numbers and the smallest relative cost functional value with italics over the Tables . Comparing the relative cost functional values for each case gives an absolute difference between the reductions, see Table . We observe that in 9 cases the difference is less than three, while in eight cases it is between three and five, and only in three cases it is greater than five. These are T1 with a deviation of 10 % with a difference of 5.91, a difference of 8.37 for T5 with a deviation of 25 %, and T4 with a deviation of 50 % with the highest difference of 12.93. Overall, we observe that the reductions between C0-C4 as well as C5-C7 are comparable, while a larger difference can be seen between these two case sets.
Table 7. Relative cost function reduction for the C1 calibration.
Table 8. Relative cost function reduction for the C2 calibration.
Table 9. Relative cost function reduction for the C3 calibration.
Table 10. Relative cost function reduction for the C4 calibration.
Table 11. Relative cost function reduction for the C5 calibration.
Table 12. Relative cost function reduction for the C6 calibration.
Table 13. Relative cost function reduction for the C7 calibration.
Table 14. Number of iterations for the different case scenarios for Tests 1, 3, and 5 within the percentage difference in the initial parameter set.
Table 15. Absolute difference between the largest and smallest relative cost functional reduction.
To quantify the general behaviour for the different calibrations, we compute the average relative cost functional reduction by
(32)
(32)
and summarize the results in Table . Note, that all cost function reduction averages are huge. We observe that a time-dependent calibration for one parameter alone (C1-C4) doesn't improve the cost functional reduction significantly. The first slightly improvement can be found by using at least two time-dependent parameters (C5-C7). Surprisingly C7 gives the best calibration results, where is the only variable which is calibrated as a constant, even though in total it has only two times the smallest cost functional reduction and never the largest, as well as C5, where all parameters are calibrated as time-dependent gives the least improvement, when considering combinations of time-dependent parameter calibration. The fact that
is generated with constant parameters and the best case considers time-dependent parameters indicates that the time-dependency is a good way to overcome the local minima. Those results are inline with literature [Citation15,Citation17].
Table 16. Average cost functional reduction in percentage for the different cases over the 20 test cases, as well as a list for the corresponding relative cost functional reduction as well as the figures of the cost functional evolution.
6. Conclusion and outlook
Our paper began with an introduction to the Heston model. The introduction was followed by the derivation of a gradient-based optimization, including the derivation of a gradient descent algorithm. In the next section, the discretization of the schemes and algorithms is presented and numerical results are illustrated. These show that the gradient descent algorithm is a feasible calibration technique. The relative cost function reduction is remarkable, even though we can expect to find only local minima. Thus, our approach follows recent research. Furthermore, the assumption of at least time-dependent parameters is better suited to the real market situation, since in the real market almost no parameter is constant. In future work, we plan to incorporate the gradient descent algorithm into the space mapping approach and to test the space mapping approach on real market data.
Figure 2. Cost functional evolution per iteration for the different test set in the case scenario C1.
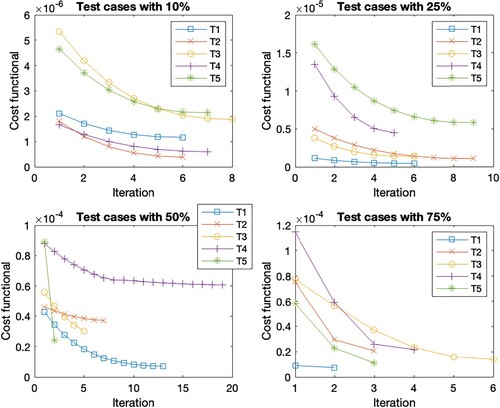
Figure 3. Cost functional evolution per iteration for the different test set in the case scenario C2.
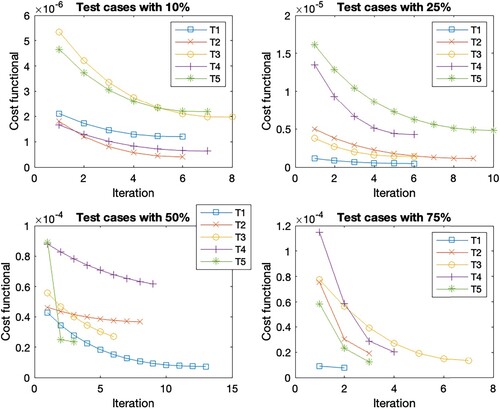
Figure 4. Cost functional evolution per iteration for the different test set in the case scenario C3.
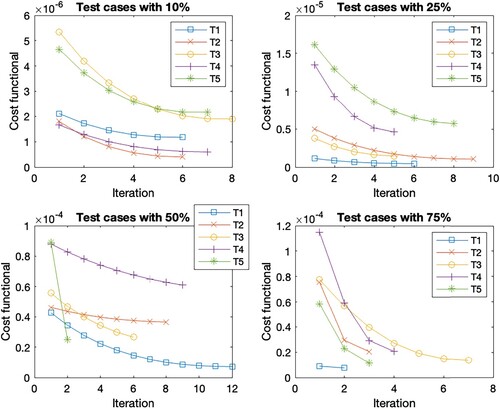
Figure 5. Cost functional evolution per iteration for the different test set in the case scenario C4.
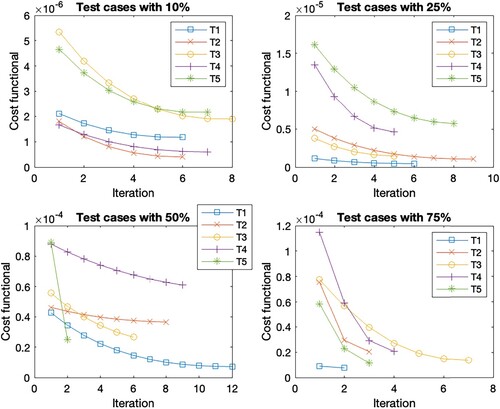
Figure 6. Cost functional evolution per iteration for the different test set in the case scenario C5.
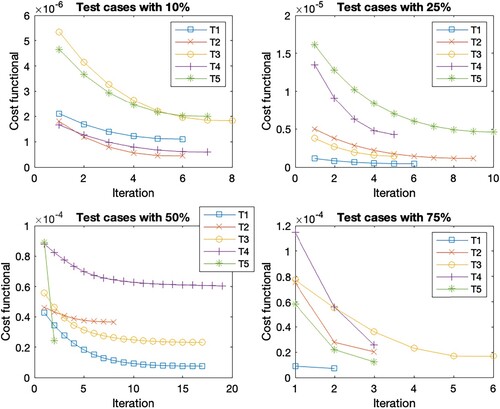
Figure 7. Cost functional evolution per iteration for the different test set in the case scenario C6.
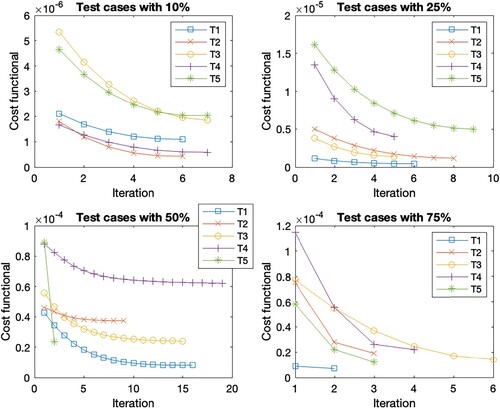
Figure 8. Cost functional evolution per iteration for the different test set in the case scenario C7.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- J.W. Bandler, Q.S. Cheng, S.A. Dakroury, A.S. Mohamed, M.H. Bakr, K. Madsen, and J. Sondergaard, Space mapping: the state of the art, IEEE Trans. Microw. Theory Techn. 52(1) (2004), pp. 337–361.
- Z. Bučková, M. Ehrhardt, and M. Günther, Fichera theory and its application in finance, in Progress in Industrial Mathematics at ECMI 2014, G. Russo, V. Capasso, G. Nicosia, and V. Romano, eds., Springer International Publishing, Cham, 2016, pp. 103–111.
- A. Clevenhaus, C. Totzeck, and M. Ehrhardt, A study of the effects of different boundary conditions on the variance of the Heston model, in Progress in Industrial Mathematics at ECMI 2023 , K. K. Burnecki and M. Teuerle, ed., Springer International Publishing, Heidelberg-Berlin, 2024.
- Y. Cui, S. del Baño Rollin, and G. Germano, Full and fast calibration of the Heston stochastic volatility model, Eur. J. Oper. Res. 263(2) (2017), pp. 625–638.
- A. Ferreiro-Ferreiro, J. García-Rodríguez, L. Souto, and C. Vázquez, A new calibration of the Heston stochastic local volatility model and its parallel implementation on gpus, Math. Comput. Simul. 177 (2020), pp. 467–486.
- S.L. Heston, A closed-form solution for options with stochastic volatility with applications to bond and currency options, Rev. Fin. Stud. 6(2) (1993), pp. 327–343.
- M. Hinze, R. Pinnau, M. Ulbrich, and S. Ulbrich, Optimization with PDE Constraints, Springer, Heidelberg-Berlin, 2009.
- B. Horvath, A. Muguruza, and M. Tomas, Deep learning volatility: a deep neural network perspective on pricing and calibration in (rough) volatility models, Quant. Fin. 21(1) (2021), pp. 11–27.
- W. Hundsdorfer, Accuracy and stability of splitting with stabilizing corrections, Appl. Numer. Math.42(1-3) (2002), pp. 213–233.
- P. Kútik and K. Mikula, Diamond–cell finite volume scheme for the Heston model, DCDS-S 8(5) (2015), pp. 913–931.
- I.M.S. Leite, J.D.M. Yamim, and L.G. da Fonseca, The deeponets for finance: An approach to calibrate the Heston model, in Progress in Artificial Intelligence G. Marreiros, F. S. Melo, N. Lau, H. Lopes Cardoso, and L. P. Reis, eds., Cham, EPIA 2021. Lecture Notes in Computer Science, Springer International Publishing, vol. 12981. https://doi.org/10.1007/978-3-030-86230-5_28
- S. Liu, A. Borovykh, L.A. Grzelak, and C.W. Oosterlee, A neural network-based framework for financial model calibration, J. Math. Ind. 9 (2019), pp. 1–28.
- S. Liu, C.W. Oosterlee, and S.M. Bohte, Pricing options and computing implied volatilities using neural networks, Risks 7(1) (2019), pp. 16.
- F. Mehrdoust, I. Noorani, and A. Hamdi, Two-factor Heston model equipped with regime-switching: American option pricing and model calibration by Levenberg-Marquardt optimization algorithm, Math. Comput. Simul. 204 (2023), pp. 660–678.
- S.S. Mikhailov and U. Nögel, Heston's Stochastic Volatility Model Implementation, Calibration and Some Extensions, John Wiley and Sons, New York, 2004.
- L. Teng and A. Clevenhaus, Accelerated implementation of the ADI schemes for the Heston model with stochastic correlation, J. Comput. Sci. 36 (2019), pp. 101022.
- L. Teng, M. Ehrhardt, and M. Günther, On the Heston model with stochastic correlation, Int. J. Theor. Appl. Fin. 6 (2016), pp. 1650033.
- F. Tröltzsch, Optimale Steuerung Partieller Differentialgleichungen, Springer, Heidelberg-Berlin, 2009.