
Abstract
This paper presents a smooth control strategy for the regulation problem of an uncertain system, which assures uniform ultimate boundedness of the closed-loop system inside of the zero-state neighbourhood. This neighbourhood can be made arbitrarily small. To this end, a class of nonlinear proportional integral controllers or PI controllers was designed. The behaviour of this controller emulates very close a sliding mode controller. To accomplish this behaviour saturation functions were combined with traditional PI controller. The controller did not need a high-gain controller or a sliding mode controller to accomplish robustness against unmodelled persistent perturbations. The obtained closed-solution has a finite time of convergence in a small vicinity. The corresponding stability convergence analysis was done applying the traditional Lyapunov method. Numerical simulations were carried out to assess the effectiveness of the obtained controller.
1. Introduction
Many of the nonlinear systems used in actual applications are uncertain or partially known (Abdallah, Dawson, Dorato, & Jamshidi, Citation1991; Bernhard, Citation2002; Grimble, Citation2006; Lee & Cheng, Citation1996; Siqueira, Terra, & Bergerman, Citation2011; Sira-Ramirez & Spong, Citation1988). Usually, these systems are subject, both to external unknown or unmodelled sustained perturbations and to the uncertainties produced by the mismatches and discrepancies between the system mathematical model and the actual plants (Fulwani, Bandyopadhyay, & Fridman, Citation2012). The control approaches known as adaptive and as robust are frequently used to overcome these obstacles. Essentially, the adaptive control approach consists of design a controller able to figure out the actual values of the uncertain terms (Krstic, Kokotovic, & Kanellakopoulos, Citation1995). On the other hand, a robust controller has a fixed structure, which provides a decent performance for a family of uncertain systems (Qu & Dawson, Citation1995; Spong & Sira-Ramirez, Citation1986). These control approaches have their own advantages; for instance, an adaptive controller can be applied to a wider range of uncertainties than a robust controller can (Pérez-Cruz, Ruiz-Velázquez, Rubio, & de Alba-Padilla, Citation2012; Rubio, Citation2012; Wen & Moreno-Armendariz, Citation2005), though its implementation is much more difficult. In addition, a robust controller does not need to be tuned while an adaptive one does. A third strategy combines both approaches to attempt a higher degree of robustness (Abdallah et al., Citation1991; Bartolini, Ferrara, & Usai, Citation1997). In Abdallah et al. Citation(1991), an excellent motivation using the robust control approach can be found. In that study, the robust control approach is divided into five categories: linear multi-variable control, passivity, variable structure, saturation, and robust and adaptive. Among these categories, the variable structure or sliding modes approach may well be one of the most used nowadays. This approach ensures robustness against disturbances and parameter variations, though having the inconvenience of produce high-frequency violent control signals, known as chattering. In fact, the presence of chattering may excite unmodelled high-frequency dynamics, resulting in unforeseen instability and damage to the actuators (Bondarev, Bondarev, Kostylyeva, & Utking, Citation1985; Levant & Fridman, Citation2002; Rafimanzelat & Yadanpanah, Citation2004). In recent years, emphasis has been placed on developing a technique to avoid this undesirable effect. Basically, there are three well-established types of approaches to eliminate the chattering effects. Continuous approximations, as the saturation function, of the sign function appearing in the sliding mode controllers are used in the first approach (Burton & Zinober, Citation1986; Eker, Citation2006; Slotine & Li, Citation1991). Approaches based on observers design are another way of overcoming the chattering; here, the idea consists of by passing the plant dynamics by a chattering loop, reducing the robust control problem to an exact robust estimation problem (Rubio & Soriano, Citation2010; Wen & Li, Citation2006). Unfortunately, the robustness with respect to the plant uncertainties and disturbances is reduced (Bondarev et al., Citation1985; Resendiz, Yu, & Fridman, Citation2008; Sira-Ramirez, Citation1993). The third type of approach, based on the high-order sliding-mode method, guaranties convergence to the origin of the sliding variable and its corresponding derivatives. Here, the high-order sliding-mode algorithms translate the discontinuity produced by the sign function to the higher order derivatives, producing continuous control signals; however, these algorithms require an onerous computing effort (Davila, Fridman, & Poznyak, Citation2006; Levant, Citation1993, Citation2001; Polyakov & Poznyak, Citation2009; Santiesteban, Fridman, & Moreno, Citation2010). In addition to these three approach types, the neural network-based techniques are efficient to identify and control uncertain models. A full review of these topic is beyond the scope of this introduction, but we refer the interested reader to the following references (Wen & Poznyak, Citation1999; Wen, Poznyak, & Li, Citation2001).
The present work presents a smooth control strategy for the regulation problem of an uncertain system where the origin is not an equilibrium point. Hence, asymptotic stability of the closed-loop system cannot be expected in a single point (Benabdallah, Citation2009). Instead, in the present study, attention is focused on assuring uniform ultimate boundedness within an arbitrarily small neighbourhood of the zero state, which can be made as small as needed (there exist other alternative known as uniform stability, see Rubio & Pérez-Cruz, Citation2013; Rubio, Plamen, & Pacheco, Citation2011; Rubio & Wen, Citation2007). The idea behind this consists of shaping a class of nonlinear PI-controllers, which approximately emulate a sliding mode controller. This approach was accomplished using a combination of saturation functions and a traditional PI controller. The stability convergence analysis was carried out using the traditional Lyapunov method. The obtained continuous controller is quite robust against the unmodelled and persistent perturbation without needing to dominate it by a high-gain controller or by a sliding mode controller. In addition, the obtained closed-solution has a finite time of convergence in a small vicinity. As pointed out in Fulwani et al. Citation(2012), Santiesteban et al. Citation(2010), this property is very important. Examples of it can be found in many electro-mechanical, robotics, and power converter systems, which require a quick response without any overshoot. In this context, it is important to mention that the obtained results were based on the works of Santibanez, Kelly, Zavala-Rio, and Parada Citation(2008), Parra-Vega Citation(2001) and Ortega, Astolfi, and Barabanov Citation(2002) and were designed to control generalised uncertain systems of first or second orders.
The remainder of this work is organised as follows. In Section 2, the robust PI controller motivation is introduced. Some generalisations of this controller are developed in Section 3, while Section 4 is devoted to the conclusions. Convincing numerical simulations to assess the effectiveness of the obtained results can be found throughout the, where appropriated.
Notation: Let, x ∈ R, k ∈ (0, ∞), and sign() be the standard sign function. The linear saturation function will be refereed, as
In a similar way, the symbol α(x) ∈ R indicates a sigmoidal function; that is, α(x) is any smooth function with the property of α(0) = 0, xα(x) ≥ 0 and,
for all x ∈ R, and
sign(x), as long as L → ∞. On the other hand, α−1(s) indicates the inverse function of the corresponding sigmoidal function.
2. Robust PI controller motivation
Consider the following control system:
(1) where y ∈ R and u ∈ R are the system single state and the system single input, respectively; ρ(*) ∈ R is an unknown continuous function, which satisfies
for all t ≥ 0. It is well know that if we select u as
(2) then the state y globally converges on the origin in a finite time. However, discontinuities presented in the proposed controller lead to chattering. To overcome this drawback, the following controller is introduced, which can be seen as a generalisation of a PI
-controller with variable gains or a smooth approximated version of the twisting algorithm.
Let us introduce the following smooth bounded controller:
(3) where L, kp, kd, M1 and M2 are the positive gains to be designed; γ(y) is defined as
(4) Hence, the closed-loop system, defined in (Equation3
(3) ) and (Equation1
(1) ), is given by
(5) In the following subsection, it is demonstrated that the above system is globally ultimately stable.
2.1 Boundedness of the closed-loop system
Proposing Vy = y2/2 and differentiating Vy around the trajectories of (Equation5(5) ), we obtain
where kp, M1, and M2 must satisfy
with δ > 0. Obviously, if α(L|y|)β(y) > M1, then
. Hence, there exists a finite time, T0 > 0, after which,
(6) implying that
(7) Note that in the case when
,
holds. That is, after some finite T0 > 0, |y| ≤ yM where yM can be as small as desired. Having shown that y is ultimately bounded, we proceed to show that z is also ultimately bounded. To this end, the following auxiliary variable, w = y − kpz/kd, with its time derivative is given by
(8) with k = kd/kp > 0 is used. Therefore, to compute the confined region of w the following function Vw = w2/2 is used where its time derivative, around the trajectories of (Equation8
(8) ), produces the following relation:
(9) Remembering that |y(t)| ≤ yM for all t ≥ T0 (see the previous discussion), it is enough to select
with δ > 0 for assuring that
, if
. This implies that, after some finite time, T1 ≥ T0, the following inequality holds
Hence, substituting the inequality, |z/k| − |y| ≤ |w|, into the above expression, we have
Then, it can be concluded that both states, y and z, are ultimately bounded.
It is noted here that the obtained bounds for y and z are quite conservative, as the present paper is concerned with showing that the whole state is bounded. However, the following subsection is focused on finding a better bound for the state variable, y.
2.2 Improving the estimation of the confined region of the variable, y
In order to determine a good-estimation for the bound, , such that
for all t > T* ≥ T2, we propose the following Lyapunov function:
(10) It must be stressed that the proposed function, V, is a strictly positive and radially unbounded function, with a local minimum at the origin (see Ortega, Loria, & Kelly, Citation1995). Thus, its time derivative, around (Equation5
(5) ), satisfies the following inequality:
(11) where the set of control parameters M1 and M2 must be selected according to the previous discussion. Therefore, from the last inequality,
as long as α(L|y|)β(y) > M1. Once again, inequality (Equation6
(6) ) is satisfied, implying that there exists a finite time, T1 ≥ T0 such that
works in the lineal region. Consequently, inequality (Equation11
(11) ) converts to
and, evidently,
, while
(12) Thus, there exists a time, t > T* ≥ T1 such that g(y(t)) ≤ 0∀t > T*. In other words, y is confined to moving inside of the compact set,
, where
It should be stressed that the confined region can be shrunk by selecting the values of the control parameters, kp, kd, L, β0 and β1, as conveniently large.
Remark 1:
Evidently, can be numerically computed by plotting, y > 0, versus, g(y), and detecting the sign change of g(y).
Henceforth, is used to denote the set of positive control gains parameters.
Proposition 1:
Consider the scalar uncertain system (Equation1(1) ), with the uncertain
, in closed-loop with
(13) where the set control parameters, Q, satisfies the restrictions
(14) with
(15) Then, the closed-loop system is uniformly ultimately bounded. Besides, for some finite time, T > 0,
for all, t > T > 0, where
is the single root of
(16)
The following properties help to stress some facts about the proposed controller:
| (P1) | If ρ(y, t) = r, where r is a constant and, under the same consideration in Proposition 1, we have that y → 0 and z → −r, as long as t → ∞. | ||||
| (P2) | Suppose that | ||||
Based on the previous facts, Lemma 1 is established as follows.
Lemma 1:
Consider the closed-loop system (Equation1(1) ) and (Equation13
(13) ), and suppose that the uncertain term can be written as
where r0 is any fixed constant and ρb(y) satisfies P2. Tacking
=
and restricting the set of control parameters Q, according to (Equation14
(14) ), then we have y → 0 and z → −r0, as long as t → ∞.
The above Lemma is a straightforward consequence of properties P1 and P2.
Comment 1:
The inequality (Equation17(17) ) is quite easy to fulfil by adequately fixing the set of parameters, Q. For instance, suppose that
Hence, ρb(y) = |sin (y)|i with i ∈ N. Then, using the following setup
inequality (Equation17
(17) ) converts to
which always holds. In addition, note that the parameter L does not needs to be too large.
Numerical example: In order to test the effectiveness of the proposed control law strategy (Equation13(13) ), for the uncertain system (Equation1
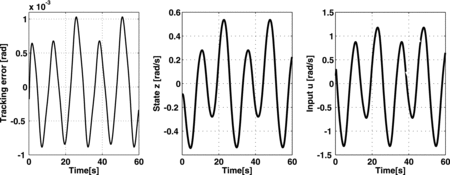
(1) ), we run a numerical simulation for the unknown term, ρ(y, t) = 0.5sin (t/4) + sin (y). The control objective was to follow the reference signal, sin (t/2). The system was initialised at 0.2 rads; the control function was
, with L = 50, kp = 3, kd = 1, M1 = 3 and M2 = 2. The corresponding results can be seen in . From this figure it can be seen that the proposed control law effectively makes the uncertain system to follow the selected reference in a very short period of time.
Figure 1. Close-loop response of the uncertain first-order system.
3. Some generalisations of the proposed control scheme
The proposed scheme can be also extended for the case where the uncertain term is unbounded. Suppose that the uncertain term can be upper-bounded by some nonlinear strictly positive function, as
(18) where
and ρu(y) is any strictly positive non-bounded function (for instance,
). Then, the following proposition is fulfilled:
Proposition 2:
Consider the scalar uncertain system (Equation1(1) ), where the uncertainty fulfils the inequity (Equation18
(18) ), in closed-loop with
(19) where control parameters are selected according to (Equation14
(14) ) and (Equation15
(15) ). Then, the closed-loop system is uniformly ultimately bounded. That is,
, for t > T > 0, where
is the single root of (Equation16
(16) ).
Proof:
First of all, we must recall that the closed-loop system, defined by (Equation1(1) ) and (Equation19
(19) ), is
(20) where
. Following the same steps as in Proposition 1 is easy to see that this closed-loop system is stable. Now, to estimate a convenient bound for
, we use the proposed function, V, given in (Equation10
(10) ). Hence, the time derivative of, V, around the trajectories of (Equation20
(20) ) can be upperbounded by
Now from the restriction that
for some finite time,
Once again,
as long as
, implying that
for a finite time.
3.1 Controlling a second-order uncertain system
Suppose that we have the following uncertain second-order nonlinear system:
(21) where x = (x1, x2) ∈ R2 is the vector state, u ∈ R is the control action, and ρ(*) is a scalar uncertain nonlinear function, provided that
(22) with
. The control objective is to render the states x1 and x2 to the origin by using a continuous controller. To accomplish this, the auxiliary variable, σ(x) = λx1 + x2, with λ > 0, is forced to move very close to the origin in a finite time. Roughly speaking, it is attempted to make variables σ(.) and
almost zero in a finite time. Now, this control problem is solved, taking advantage of the previously proposed robust control scheme, leading to the following controller:
(23) where ρl(x) = (kb + λ|x2| + ka‖x‖), and for simplicity,
(24) From the above relation, after some simple algebra,
, may be written as
(25) where p(x, t) lumped all the uncertain terms, defined by
Then, the parameter
is redefined as
(26) and selecting the control parameters M1and M2 according to (Equation14
(14) ) and (Equation15
(15) ), respectively. It is easy to check whether σ and z are bounded (see the previous section). In fact, from the first equation of (Equation25
(25) ), there is T0 > 0, such that
(27) Now in order to determine a good-estimation for the bound,
, such that,
, from the above restriction, we have that
works in the linear region, after t ≥ T0. Therefore, the following Lyapunov function can be proposed:
(28) where the time derivative around of the trajectories of (Equation25
(25) ) leads to
(29) After some simple algebra, it is easy to show that
can be upperbounded by
In addition, evidently,
, as long as
Consequently, there exists a finite time T1 ≥ T0 > 0, after which
, where
is the single root of g(y). This section is ended by introducing the following proposition, which summarises the above developments.
Proposition 3:
The second-order nonlinear system (Equation21(21) ) in closed-loop with (Equation23
(23) ), where the saturation function level parameters were selected according to (Equation14
(14) ) and (Equation15
(15) ), is uniformly ultimately bounded. That is,
for all t > T > 0, where
is the single root of (Equation16
(16) ).
3.2 Stabilisation of a class of nonlinear systems
It is well known that many mechanical systems admit the following cascade form:
(30) where x = [x1, x2, x3, x4] is the state, u ∈ R is the controller, f: R4 → R and b: R4 → R are nonlinear smooth functions, d1 and d2 are bounded perturbations, and, f and di satisfy the following:
The control objective is to render the state x to one small vicinity at the origin by using a continuous controller. Similarly to before, the variable σ is selected as
where the set of constants λi > 0 will be selected below. Therefore, its corresponding time derivative is
where d0 = d1 + λ2d1 and Kx = λ1x2 + λ2x3 + λ3x4. Now, using simple algebra, the last equation can be rewritten as
(31) where ρl(x) and p(x, t) are defined by
with k > 1. Again, using simple algebra,
.
Based on Proposition 3, u is introduced as
(32) Note that the proposed controller (Equation32
(32) ) in closed-loop with (Equation31
(31) ) corresponds to the previously obtained system (Equation25
(25) ). Therefore, following similar steps as before, after some finite time, t ≥ T0,
Even more, there exists some time, T1 ≥ T0, such that
for all t ≥ T1, where
is the single root of g(y) (e.g. (Equation16
(16) )). Hence,
, where
can be forced to be very close to zero. This means that
(33) where
for all t ≥ T1. Observe that the first three differential equation of system ( Equation30
(30) ) are globally Lipschitz. That is, the states {x1, x2, x3} cannot have a finite time of scape (Khalil, Citation2002). Therefore, after some finite period of time, T1 > t, these last three equations of (Equation30
(30) ) can be rewritten as
(34) where
where
with
. Now, to ensure the ultimate boundedness of system (Equation34
(34) ), matrix Aλ has to be Hurwitz, and the system has to be asymptotically and exponentially stable if
and
. It can be easily solved invoking Khalil’s vanishing perturbation theorem (see Khalil, Citation2002). To achieve this, it is enough to satisfy the following inequity:
(35) where Q and P satisfy the following Lyapunov equation:
(36) where Q > 0 and P > 0. That is to say, if Aλ is selected such that the expressions (Equation35
(35) ) and (Equation36
(36) ) are fulfilled, the state q exponentially decayed to zero. However, considering the perturbations d1 ≠ 0 and δ1 ≠ 0, it is easy to see that the state q is ultimately bounded. This means that
, where the constant
can be as small as needed.Footnote1 According to the above discussion, the following proposition gives sufficient conditions to ensure the ultimately boundedness of system (Equation30
(30) ) in closed-loop with (Equation32
(32) ).
Proposition 4:
Let us consider the nonlinear system (Equation30(30) ) in closed-loop with (Equation32
(32) ), under the assumptions that Aλ is selected according to (Equation35
(35) ) and (Equation36
(36) ), and the saturation function level parameters were selected according to (Equation14
(14) ) and (Equation15
(15) ). Then, there exists a finite time T > 0 where the state x is ultimately bounded, with
, where
can be as small as needed, selecting adequately
and L.
3.3 Numerical example
To show the effectiveness of the proposed controller (Equation23(23) ), it was applied it to the well-known inverted pendulum attached to a DC-motor, whose state model is given by
where x1 and x2 are the pendular angle position and the pendular angle velocity, respectively; the control signal u corresponds to the motor torque. The parameters M, L, g and J are the pendulum mass, the pendulum arm length, the gravity constant and the arm inertia, respectively, while ρ is a bounded perturbation. Assuming that physical parameters are partially known and ρ given by
The objective is to drive the tracking errors e1 = x1 − xr and
close enough to the origin. That is, e1 ≅ 0 and e2 ≅ 0. Thus, defining σ = e1 + e2 and repeating similar steps as before, the following controller
assures that both errors can be as small as desired if the set of control parameters satisfies the conditions (Equation14
(14) ) and (Equation15
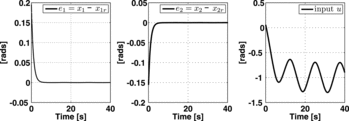
(15) ). In order to achieve a good performance, the control parameters were fixed as
where
and σM = 68 × 10−4 (see (Equation26
(26) ) and (Equation27
(27) ), respectively). By numerical computation, it is easy to see that the steady-state error of ‘σ’ is given by
, implying that
.
shows the closed-loop response of both tracking errors and the corresponding controller. From this figure, it is clear that the proposed controller effectively renders the errors close enough to the origin in about 2.25 s.
Figure 2. Close-loop response of the uncertain inverted pendulum attached to a DC-motor.
4. Conclusions
A smooth control strategy for the regulation problem of an uncertain system was obtained. This strategy assures uniform ultimate boundedness of the closed-loop system inside of the zero-state neighbourhood, which can be made arbitrarily small. To accomplish this, a class of nonlinear PI controllers was designed. This controller behaves as if it were a sliding mode controller. This behaviour approximation was in turn achieved using a combination of saturation functions and a traditional PI controller. The controller robustness against unmodelled and persistent perturbations did not need a high-gain controller or a sliding mode controller to dominate it. In addition, the obtained closed-solution has a finite time of convergence in a small vicinity. To perform the corresponding stability converge analysis the traditional Lyapunov method was used. Finally, the effectiveness of the obtained controller was validated by numerical simulations, which demonstrated clearly the controller is able to render the system to a small vicinity of the origin. It is worth mentioning that the obtained controller was designed for a generalisation of uncertain systems of first or second order. However, a generalisation for systems of higher order can be obtained.
Acknowledgements
This research was supported by the Centro de Investigación en Computación of the Instituto Politecnico Nacional (CIC-IPN), and by the Secretaría de Investigación y Posgrado of the Instituto Politecnico Nacional (SIP-IPN), under Research Grants 20131342 and 20131304. Julio A. Mendoza is a doctoral student at the Centro en Investigación en Computación and a scholarship holder of the CONACYT and he wants to thanks both institutions.
Notes
1. To avoid unnecessarily extending this report, the computing of is ommited.
References
- Abdallah, C., Dawson, D.M., Dorato, P., & Jamshidi, M. (1991). Survey of robust control for rigid robots. IEEE Control Systems Magazine, 11, 24–30.
- Bartolini, G., Ferrara, A., & Usai, E. (1997). Applications of a sub-optimal discontinuos control algorithm for uncertain second order systems. International Journal of Robust and Nonlinear Control, 7, 299–319.
- Benabdallah, A. (2009). On the practical output feedback stabilization for nonlinear uncertain systems. Nonlinear Analysis, 14, 145–153.
- Bernhard, P. (2002). Survey of linear quadratic robust control. Macroeconomic Dynamics, 6, 19–39.
- Bondarev, A.G., Bondarev, S.A., Kostylyeva, N.Y., & Utking, V.I. (1985). Sliding modes in systems with asymptotic state observers. Automatica i telemechanica (Autom. Remote Control), 46, 679–684.
- Burton, J.A., & Zinober, S.I. (1986). Continuous approximation of VSC. International Journal of Systems Sciences, 17, 875–885.
- Davila, J., Fridman, L., & Poznyak, A. (2006). Observation and identification of mechanical system via second order sliding modes. International Journal of Control, 79, 1251–1262.
- Eker, I. (2006). Sliding mode control with PID sliding surface and experimental application to an electromechanical plant. ISA Transactions, 45, 109–118.
- Fulwani, D., Bandyopadhyay, B., & Fridman, L. (2012). Non-linear sliding surface: Towards high performance robust control. IET Control Theory & Applications, 6, 235–242.
- Grimble, M.J. (2006). Robust industrial control systems. Chichester: Wiley.
- Khalil, H.K. (2002). Nonlinear systems (3rd ed.). Upper Saddle River, NJ: Prentice Hall.
- Krstic, M., Kokotovic, P.V., & Kanellakopoulos, I. (1995). Nonlinear and adaptive control design (1st ed.). New York, NY: John Wiley & Sons.
- Lee, G.W., & Cheng, F.T. (1996). Robust control of manipulators using the computed torque plus H∞ compensation method. IEE Proceedings on Control Theory and Applications, 143, 64–72.
- Levant, A. (1993). Sliding order and sliding accuracy in sliding mode control. International Journal of Control, 58, 1247–1263.
- Levant, A. (2001). Universal SISO sliding-mode controllers with finite-time convergence. International Journal of Control, 46, 1447–1451.
- Levant, A., & Fridman, L. (2002). Higher order sliding modes. In J. Barbot & W. Perruguetti (Eds.), Sliding mode control in engineering (pp. 53–101). New York, NY: Marcel Dekker Inc.
- Ortega, R., Astolfi, A., & Barabanov, N.E. (2002). Nonlinear PI control of uncertain systems: An alternative to parameter adaptation. System & Control Letters, 47, 259–278.
- Ortega, R., Loria, A., & Kelly, R. (1995). A semiglobally stable output feedback PID regulator for robot manipulators. IEEE Transactions on Automatic Control, 40, 1432–1436.
- Parra-Vega, V. (2001). Second order sliding mode control for robot arms with time base generators for finite-time tracking. Dynamics and Control, 11, 175–186.
- Pérez-Cruz, J.H., Ruiz-Velázquez, E., Rubio, J.J., & de Alba-Padilla, C.A. (2012). Robust adaptive neurocontrol of SISO nonlinear systems preceded by unknown deadzone. Mathematical Problems in Engineering, 2012, 1–23.
- Polyakov, A., & Poznyak, A. (2009). Lyapunov function design for finite-time convergence analysis: “Twisting” controller for second-order sliding mode realization. Automatica, 45, 444–448.
- Qu, Z., & Dawson, D.M. (1995). Robust tracking control of robot manipulators. New York, NY: IEEE press.
- Rafimanzelat, M.R., & Yadanpanah, M.J. (2004). A novel low chattering sliding mode controller. In 5th Asian Control Conference, Melbourne, Australia (Vol. 3, pp. 1958–1963).
- Resendiz, J., Yu, W., & Fridman, L. (2008). Two-stage neural observed mechanical systems. IEEE Transactions on Circuits and Systems II, 55, 1076–1081.
- Rubio, J.J. (2012). Modified optimal control with a back propagation network for robotic arms. IET Control Theory & Applications, 6, 2216–2225.
- Rubio, J.J., & Pérez-Cruz, J.H. (2013). Evolving intelligent system for the modelling of nonlinear systems with dead-zone input. Applied Soft Computing. Advance online publication. doi:http://dx.doi.org/10.1016/j.asoc.2013.03.018
- Rubio, J.J., Plamen, A., & Pacheco, J. (2011). Uniformly stable backpropagation algorithm to train a feedforward neural network. IEEE Transactions on Neural Networks, 22, 356–366.
- Rubio, J.J., & Soriano, L.A. (2010). An asymptotic stable proportional derivative control with sliding mode gravity compensation and with a high gain observer for robotic arms. International Journal of Innovative Computing, Information and Control, 6, 4513–4526.
- Rubio, J.J., & Wen, Y. (2007). Stability analysis of nonlinear system identification via delayed neural networks. IEEE Transactions on Circuits and Systems II: Express Briefs, 54, 161–165.
- Santibanez, V., Kelly, R., Zavala-Rio, A., & Parada, P. (2008). A new saturated nonlinear PID global regulator for robot manipulators. In Proceedings of the 17th IFAC Word Congress, South Korea (pp. 11690–11695).
- Santiesteban, R., Fridman, L., & Moreno, J.A. (2010). Finite-time convergence analysis for “Twisting” controller via a strict Lyapunov function. In International Workshop on Variable Structure Systems (pp. 26–28).
- Siqueira, A.A.G., Terra, M.H., & Bergerman, M. (2011). Robust control of robots: Fault tolerant approaches. Berlin: Springer Verlag.
- Sira-Ramirez, H. (1993). A dynamical variable structure control strategy in asymptotic output tracking problem. IEEE Transactions on Automatic Control, 38, 615–620.
- Sira-Ramirez, H., & Spong, M.W. (1988). Variable structure control of flexible joint manipulators. IEEE International Journal of Robotics and Automation, 3, 57–64.
- Slotine, J.J., & Li, W. (1991). Applied nonlinear control. Englewood Cliffs, NJ: Prentice Hall.
- Spong, M.W., & Sira-Ramirez, H. (1986). Robust control design techniques for a class of nonlinear systems. In IEEE American Control Conference, Seattle, WA (pp. 1515–1522).
- Wen, Y., & Li, X. (2006). PD control of robot with velocity estimation and uncertainties compensation. International Journal of Robotics and Automation, 21, 1–9.
- Wen, Y., & Moreno-Armendariz, M.A. (2005). Robust visual servoing of robot manipulators with neuro compensation. Journal of the Franklin Institute, 342, 824–838.
- Wen, Y., & Poznyak, A. (1999). Indirect adaptive control via parallel dynamic neural networks. IEE Proceedings on Control Theory and Applications, 146, 25–30.
- Wen, Y., Poznyak, A., & Li, X. (2001). Multilayer dynamic neural networks for non-linear system on-line identification. International Journal of Control, 74, 1858–1864.
Appendix A
Proof of property in P1
If ρ(y, t) = r with r being constant, then the single equilibrium point given by is asymptotically and globally stable for the system (Equation5
(5) ). Under the assumption in Proposition 1, y and z are globally stable in a Lyapunovian sense. However, to assure convergence at
, we must use the following function:
(1) where V(x) > 0 was previously defined in (Equation10
(10) ). Evidently, its time derivative of around (Equation5
(5) ) leads to
(2) Since, V1(x), is bounded from below and,
, is semi-definite negative, then global stability of x = (y, z) is once again assured. However, remarking that
, if and only if y = 0, straightforwardly proves global asymptotic stability of the equilibrium point, (y = 0, z = −r), via LaSalle’s theorem (see Khalil, Citation2002).□
Proof of property in P2
From the previously-defined Lyapunov function, V(x) > 0, defined in (Equation10(10) ), its corresponding time derivative is around the trajectories of (Equation5
(5) ) (for more detail, review the first expression of (Equation11
(11) )), and after substituting, |ρ(y, t)| ≤ ρb(y), the following expression holds:
Now, from the assumption (Equation17
(17) ), it can be assured that
, for all y ∈ R − {0}. After using LaSalle’s theorem, it is easy to show that both variables, y and z, asymptotically converge on the origin.□