
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This paper proposes a method to compute solutions of optimal controls for dynamic systems in terms of radial basis function neural networks (RBFNN) with Gaussian neurons. The RBFNN is used to compute the value function from Hamilton–Jacobi–Bellman equation with the policy iteration. The concept of dominant system is introduced to create initial coefficients of the neural networks to stabilise unstable systems and guarantee the convergence of policy iteration. Model reduction and transfer learning techniques are introduced to improve robustness of RBFNN optimal control, and reduce computational time. Numerical and experimental results show that the resulting optimal control has excellent control performance in stabilisation and trajectory tracking, and much-improved robustness to disturbances and model uncertainties even when the system responses move to a domain of the state space that is larger than the domain where the neural networks are trained.
1. Introduction
Optimal controls are commonly determined with the help of the Hamilton–Jacobi–Bellman (HJB) equation. The HJB equation is a nonlinear partial differential equation for the value function of the optimal control problem. There have been many studies on the solution of the HJB equation in the mathematics and controls community. However, it remains a technical challenge to obtain analytical solutions of the HJB equation for nonlinear control problems. This paper presents a method to obtain approximate solutions of the HJB equation for nonlinear control systems. The method consists of radial basis function neural networks, reduced order modelling and transfer learning.
Crandall and Lions proposed the viscosity solution of the HJB equation in Crandall and Lions (Citation1983), and found that the HJB equation exists non-smoothnesss solution. A sequential alternating least squares method to solve the high dimensional linear HJB equation was presented in Stefansson and Leong (Citation2016). In addition to the numerical methods such as viscosity solution, finite difference and finite element, neural networks are other promising approaches that have garnered recent interest (Greif, Citation2017).
Neural networks have been extensively studied for solving partial differential equations (PDEs) (Han et al., Citation2018; Lagaris et al., Citation2000; Sirignano & Spiliopoulos, Citation2018). Neural networks with different activation functions have also been applied to the HJB equation (Munos et al., Citation1999; T. Nakamura-Zimmerer et al., Citation2021). The HJB equation with action constraints (Abu-Khalaf & Lewis, Citation2005; Yang et al., Citation2014) and fixed final time has been studied with the help of neural networks with polynomial neurons (Cheng et al., Citation2007a, Citation2007b). The least squares algorithm with a time-domain discounting factor and neuron was studied in Tassa and Erez (Citation2007) to improve the smoothness and convergence of neural networks solutions. The activation function
was also used to solve high dimensional HJB equations in T. Nakamura-Zimmerer et al. (Citation2020). The rectified linear neurons were used to approximate the value function using a grid-free approach in Jiang et al. (Citation2016). Effects of different types of neural networks for the solution of the Hamilton–Jacobi–Bellman equation are studied in Yang et al. (Citation2014).
The radial basis neural networks (RBFNN) were used to compute the HJB solution along the response trajectory (D. Zhang et al., Citation2016). The normalised Gaussian networks were adopted to develop a reinforcement learning framework to obtain the global value function for continuous time systems while training the networks along different trajectories (Doya, Citation2000). The actor-critic reinforcement learning together with the RBFNN was also applied to obtain the optimal control for a discrete-time system (D. Zhang et al., Citation2016).
Recently, the interest in solving the HJB solution in high dimensional state space is growing (Darbon & Osher, Citation2016; Yegorov & Dower, Citation2021). A neural network with sigmoid activation function was proposed to compute the viability sets of nonlinear continuous systems in Djeridane and Lygeros (Citation2006). The tanh activation function was considered to develop a causality-free neural network to solve high dimensional HJB equations including the co-state vector as part of the solution (T. Nakamura-Zimmerer et al., Citation2020; T. E. Nakamura-Zimmerer, Citation2022). Two neural networks architectures are introduced using minimum plus algebra to solve high dimensional optimal control problems with specified terminal cost using the min-pooling activation function in Darbon et al. (Citation2021). Indeed, neural networks can obtain excellent approximations of the value function from the solution of the HJB equation leading to the optimal policy. Among all the neural networks structures and activation functions, the polynomial activation functions are adopted in most cases to solve the optimal control problems in reinforcement learning (Abu-Khalaf & Lewis, Citation2005; Cheng et al., Citation2007a, Citation2007b; Liu et al., Citation2014; Luo et al., Citation2014; Modares & Lewis, Citation2014; Modares et al., Citation2014; Yang et al., Citation2014).
While the solutions of the HJB equation have been extensively studied, fewer investigations have focussed on the performance of optimal controls obtained in terms of the RBFNN. This paper presents an approach based on radial basis function neural networks with Gaussian activation functions to solve the HJB equation for various optimal control problems and to demonstrate the robustness of the optimal controls with the model reduction and transfer learning technique in machine learning. This study addresses the robustness improvement of the optimal controls obtained with the RBFNN, model reduction and transfer learning.
There are many studies on the radial basis function neural networks. An adaptive extended Kalman filter (AEKF) was developed for estimating the weights, centres, and width of RBFNN (Medagam & Pourboghrat, Citation2009). It has been shown that the RBFNN with one hidden layer and the same smoothing factor in each kernel are broad enough for universal approximation (Park & Sandberg, Citation1991). The RBFNN have been extensively applied to regression and classification problems. An excellent review of this method can be found in Wu et al. (Citation2012). The RBFNN have been shown to have advantage in terms of design, generality and tolerance to noises compared to other neural network structures (Yu et al., Citation2011). It has been found that RBFNN have an advantage over the conventional sigmoid neural networks (NN) owing to that the nth-dimensional gaussian function is well-established from probability theory, Kalman filtering, etc. (Lewis et al., Citation1998). An application of the RBFNN in control design can be found in W. Zhang et al. (Citation2022) to approximate the error model in vibration suppression. The advantages of RBFNN motivate us to further explore the potential of the RBFNN method to solve the HJB equation for nonlinear control systems.
Many mechanical systems with multi-degrees of freedom are underactuated by design. The dynamics of these systems live in a relatively high dimensional state space. It turns out to be highly advantageous to discover a reduced order model of the system, in which the limited control efforts can be focussed to stabilise the system and achieve improved tracking performance. The reduced order model also decreases numerical complexities in solving the HJB equation for nonlinear control systems. For this reason, it is important to find a reduced order model of the system before applying the RBFNN method to solve the HJB equation.
The balanced truncation model reduction (BTMR) method is a popular algorithm in the controls community to reduce the dimension of the dynamic system with the help of principal component analysis and singular value decomposition of the Hankel matrix constructed with the controllability and observability gramians. It has received much attention from the research community in the past decades (Gugercin & Antoulas, Citation2004; Pernebo & Silverman, Citation1982). The balanced model reduction has been applied to control design for high dimensional systems with thousands of degrees of freedom (Huang & Kramer, Citation2020; Wu et al., Citation2020). The controllability and observability gramians for nonlinear control systems can be computed from input-output data, leading to the so-called empirical gramians (Himpe, Citation2018). In this paper, the BTMR algorithms with both model-based and empirical gramians are considered for improving the robustness of the RBFNN optimal control, so as to reduce the computation complexity.
Since the mathematical model of nonlinear control systems can never perfectly capture the dynamics of the real system, the RBFNN control based on the mathematical model may need fine tuning when it is applied to the physical system in an experimental setting. This is where the transfer learning technique of machine learning comes in. After certain experimental data is obtained, the neural networks can be partially retrained in order to further improve the performance of the control.
The objective of this paper is to propose an efficient, practical and useful RBFNN algorithm to solve the HJB equation in optimal control. We demonstrate the RBFNN optimal control design with a linear rotary pendulum system and several nonlinear systems. In particular, the robustness of the RBFNN optimal control is explored and reported in terms of stabilisation and tracking of the pendulum and other nonlinear systems. The traditional LQR control and the optimal control obtained with the polynomial neural networks are used as benchmarks to compare with the proposed RBFNN optimal control design.
The remainder of the paper is outlined as follows. Section 2 reviews the optimal control formulation in terms of the HJB equation. Section 3 presents the RBFNN method to solve the nonlinear HJB equation. Section 4 discusses the balanced truncation algorithm and the RBFNN optimal control with the reduced order model. Section 6 presents numerical simulations and experimental results of the RBFNN optimal control for linear systems. Section 7 presents numerical simulations of the RBFNN optimal control for the nonlinear systems. Section 8 concludes the paper.
2. The Hamilton–Jacobi–Bellman equation
Consider a nonlinear time-invariant dynamic system governed by the state equation
(1)
(1) where
is the initial time,
is the initial state,
,
.
and
are nonlinear functions of their arguments. Define a target set at a terminal time t = T as
(2)
(2) where
. ϕ defines a set where the terminal state
must settle at time T.
The optimal control problem amounts to finding a control in an admissible set
that drives the system from the initial state
to the target set
such that the following performance index J is minimised while the state equation is satisfied.
(3)
(3) where
is called the Lagrange function.
Define a value function along the optimal trajectory based on the performance index as (4)
(4) By definition,the value function has the following properties
(5)
(5) Take the derivative of the value function with respect to time t based on the definition in Equation (Equation4
(4)
(4) )
(6)
(6)
Remark 2.1
A remark on the role of the value function is in order. By definition, we have
(7)
(7) Hence,
is a Lyapunov function. The existence of the Lyapunov function implies that the system under the optimal control
is stable.
By treating as a multi-variable function of the state and time, we can also apply the chain rule of differentiation along the optimal path to obtain the Hamilton–Jacobi–Bellman equation (HJB) as
(8)
(8) where H is the Hamiltonian function defined as
(9)
(9) and
is a vector of Lagrange multipliers.
Equation (Equation8(8)
(8) ) is a partial differential equation defined in the state space governing the value function. According to the definition of the value function, we have a terminal condition for the HJB equation as
. When there are constraints imposed on the states, boundary conditions can also be imposed to the HJB equation.
Consider a special case
(10)
(10) where
is a semi-positive definite symmetrical matrix, and
is a positive definite symmetrical matrix. The optimal control for this case is expressed in terms of the value function.
(11)
(11) When the system is nonlinear, it is difficult to obtain the function of
analytically. This study focuses on the RBFNN with Gaussian activation functions for obtaining the value function.
3. Neural networks solution of value function
In the following, we shall focus on the special time-invariant case when the terminal time , the terminal cost
, and the value function is only a function of the state, i.e.
.
The value function can be expressed in terms of radial basis function neural networks with Gaussian activation functions, (12)
(12) where
is the number of Gaussian functions
and C is an arbitrary integration constant to guarantee the value function to be non-negative.
(13)
(13)
(14)
(14) The vectors and matrices in the above equations are defined as
(15)
(15)
(16)
(16)
(17)
(17)
(18)
(18) where k is the iteration index of the policy iteration algorithm introduced next. In general, the elements of the mean matrix
and covariance matrix
can be trainable coefficients of the neural networks.
3.1. Implementation of RBFNN
In this study, the Gaussian functions are adopted as kernels to approximate an unknown function as is commonly done in statistics and mesh-free finite elements (J.-S. Chen et al., Citation2017; Silverman, Citation2018; Sun & Hsu, Citation1988) That is to say, a finite domain of interest in the state space can be divided into grids and take the grid coordinates as the mean
. Furthermore, the covariance matrix
is taken to be diagonal and the same constant for all Gaussian functions. It is noteworthy that with these choices of the mean and covariance matrix, the RBFNN can indeed deliver sufficiently accurate solutions of nonlinear partial differential equations (Wang et al., Citation2022a, Citation2022b, Citation2023). It is shown in this paper that the optimal control for nonlinear dynamic systems can also be obtained in this manner, which allows us to focus on the issues in the control design.
Future efforts will treat both and
as trainable coefficients. The effect of varying means and standard deviations on the optimal control solution will be studied in a separate paper.
In the following discussions, we drop the symbol for optimal solutions for brevity.
3.2. Policy iteration (PI) algorithm
Recall the optimal control and consider the RBFNN solution of the value function in Equation (Equation12(12)
(12) ). At the kth step of iterations, the control is given as
(19)
(19) where
and
denote the control and value function at the
step of iterations.
is chosen to be a stabilising initial control. The value function is updated with the following equation,
(20)
(20) According to Theorem 4 of reference Saridis and Lee (Citation1979), the pair
determined by Equations (Equation19
(19)
(19) ) and (Equation20
(20)
(20) ) leads to a convergent sequence such that
(21)
(21) where
denotes the true optimal value function and
is the true optimal control. Given a random value function and iteratively updating the new value function with the greedy policy is called value iteration or successive approximation (Saridis & Lee, Citation1979). Instead of updating the value function, the policy iteration is defined as iteratively updating the greedy policy to the optimal solution. Since the control
and the value function are both iteratively updated during the calculation of the RBFNN, it is hard to distinguish the current approach as value iteration or policy iteration. In this case, it is treated as policy iteration. The proof of convergence of the similar algorithm for saturated controls was presented by Abu-Khalaf and Lewis (Citation2005) and Meyn (Citation2022). Many examples reported in the literature also confirm the convergence of the successive approximation algorithm (Tassa & Erez, Citation2007). We have found that the choice of an initial stabilising control policy
is important to put the PI algorithm on the right track to converge.
Next, the updating equation is presented in matrix form. Consider the expressions of Gaussian function in Equations (Equation14(14)
(14) )–(Equation18
(18)
(18) ), the partial derivative is expressed as,
(22)
(22) where
(23)
(23) Hence, the gradient of the value function is
(24)
(24) where
in Equation (Equation23
(23)
(23) ). The control can now be written in the matrix form as
(25)
(25) Equation (Equation20
(20)
(20) ) in terms of these matrices reads
(26)
(26) where
and
(27)
(27) Define the error of the HJB equation due to the neural networks approximation as
(28)
(28) An integrated squared error in the state space
is defined as
(29)
(29)
3.3. Sampling method for integration
Computation of involves integration in high dimensional space and can be intensive. Therefore, instead of integration in Equation (Equation29
(29)
(29) ), we can uniformly sample a large number of points
to compute an approximate value of
. A sampled value
of
is obtained as
(30)
(30) where
is the number of sampled points
in the domain
. Define the following matrix and vectors as
(31)
(31)
(32)
(32)
(33)
(33) Later in the examples, the domain
is referred to as the sampling region or training region.
The sampled performance index reads
(34)
(34) The optimal coefficient vector at each iteration step can be obtained as
(35)
(35) assuming that the inverse of the matrix
exists. It has been found that when
, the inverse usually exists (Wang et al., Citation2022a, Citation2022b, Citation2023). The mean values and standard deviations of the Gaussian function are fixed in this paper. The state space is uniformly sampled along each dimension with a fixed grid size, and the standard deviation is set to be between four and five times the size of the fixed grid.
3.4. Dominant system
If the policy iteration algorithm starts with an initial estimate of the value function in terms of the RBFNN with randomly generated coefficients, the resulting control can push the system on to a track leading to instability for unstable systems. Hence, it is recommended to begin the policy iterations of an unstable system with a stabilising initial control, which will ensure system stability through the iteration process. We introduce the concept of dominant system to create the stabilising initial control. The dominant system is defined as an unstable linear system that has poles with larger positive real parts than that of the original system. A LQR control can be found to stabilise the dominant system and is used as the initial control to start the policy iteration. There are different ways to design the initial control, such as the supervised learning based control (Borovykh et al., Citation2022) and the unconstrained LQR control (Abu-Khalaf & Lewis, Citation2005). It should be noted that for stable systems, randomly generated initial coefficients for the RBFNN always make the policy iteration convergent.
4. Reduced order model
It has been numerically found that the reduced order model shows better robustness to disturbances and parameter uncertainties compared to the original system (Zhao & Sun, Citation2022). We take advantage of the reduced order model to better focus the control effort to stabilise the system and to reduce the dimension of the state space where the HJB equation applies. This approach will subsequently improve the numerical performance of the RBFNN when applied to find the value function from the HJB equation in high dimensional space.
There are different model order reduction methods. In this study, the balanced truncation model reduction technique is considered, which can be readily extended to become data-driven. This is one of the reasons for us to adopt this technique.
4.1. Balanced truncation
This section presents the procedure of the balanced truncation method, as it was described by Laub et al. (Citation1987). Before exploring the details about the balanced truncation algorithm, it is beneficial to provide a brief introduction about the concept of controllability and observability in control theory. Controllability measures the ability of the control to drive the system from an initial state to any desired state in a finite time. Observability refers to the ability to estimate the full state of the system from output measurements. Controllability and observability play important roles in the balanced truncation algorithm, as elaborated in the subsequent discussion.
Consider a linear time invariant (LTI) dynamical system in the state space,
(36)
(36) The balanced truncation reduced order model is realised by introducing a transformation
to the state
such that
which leads to a so-called balanced form of the system. In the following, the process of finding the transformation
to obtain the desired balanced order system is presented.
Let and
be the controllability and observability gramians of the stable subsystem. Consider two continuous time Lyapunov equations,
(37)
(37) Since
is stable, the Lyapunov equations have unique symmetric positive definite solutions
and
, which are the controllability and observability Gramians of the system (Gawronski & Juang, Citation1990; Phillips et al., Citation2022). The controllability and observability gramians can be defined as,
(38)
(38)
(39)
(39) After obtaining
and
, the transformation
is computed through the following steps.
Evaluate the Cholesky decomposition of gramians
and
Evaluate the singular value decomposition of the Hankel matrix defined as
The transformation
Define the transformed gramians as and
. The singular values
can be rewritten as
(43)
(43) where
,
.
will be truncated to obtain the reduced order system. Hence, in the transformed state
, we neglect the components
for
.
denotes the number of states to be included in the reduced order model of the stable subsystem.
Let denote the truncated state vector,
be the corresponding state matrix,
the reduced order control influence matrix and
the reduced order output matrix. The reduced order system output
has the same dimension as that of the original output of the system. It is proved that
is approximately equal to the original output
. The reduced order system is given as,
(44)
(44) where
,
and
,
.
is part of the transformation
after the columns corresponding to the truncated states are removed. The
-balanced truncation method which was presented in Heinkenschloss et al. (Citation2011) is adopted to include the effects of non-zero initial conditions for the LTI system. Details of application of balanced truncation algorithm with non-zero initial conditions for a high-dimensional LTI system can be found in Zhao and Sun (Citation2022).
4.2. Empirical balanced truncation
The controllability and observability gramians used in the balanced truncation method are defined for linear systems and are usually model-based. For nonlinear systems without a detailed mathematical model, the controllability and observability gramians can be estimated from input-output data. These are called empirical gramians. The empirical gramians yield the exactly same balanced truncation transformations for stable linear system. However, it has been found that the reduced order model from the empirical gramians contains more accurate information than the traditional model-based balanced truncation (Grundel et al., Citation2019; Singh & Hahn, Citation2005). The empirical controllability and observability gramians are defined as,
(45)
(45)
(46)
(46) where
(47)
(47) and
is the state response to an impulsive input
,
is the average of the state response,
is the output of the system starting from the initial condition
and
are unit vectors. The same calculation procedures as described by Equations (Equation40
(40)
(40) )–(Equation42
(42)
(42) ) can be applied to obtain the transformation matrix
for the reduced order model in Equation (Equation44
(44)
(44) ).
4.3. Control based on reduced order model
Applying the RBFNN solution to the control design of the reduced order model, the optimal policy for stabilisation is obtained as
(48)
(48) where the subscript r indicates the reduced order model.
For linear systems, we can also explicitly write a control to track a reference trajectory as as,
(49)
(49)
5. Transfer learning
When the RBFNN control presented in the previous section is well trained using the data simulated with a sufficiently accurate model of the dynamic system, it exhibits good control performance. When there are model uncertainties, unknown hardware gains and external disturbances, the real time performance of the model-based RBFNN control may deteriorate. To improve the robustness of the RBFNN control in real time, we make use of the transfer learning concept to retrain the neural networks with the experimental data.
Transfer learning is a machine learning technique for fine tuning network weights (Guo et al., Citation2019) for performance improvement when new data become available. It is common to freeze the weights in the hidden layers of the neural networks, and retrain the weights in the output layer with the new data. In this study, we have only one hidden layer whose weights are retrained with the experimental data. This retraining is done by feeding the new data to Equation (Equation30(30)
(30) ) and updating the network coefficients according to Equation (Equation35
(35)
(35) ) during the policy iteration. The system response
is used to update the system dynamics and the performance index. The system response
is collected from experiments and used to retrain the RBFNN. Note that parts of the system dynamics parameters remain model-based during the RBFNN training. The idea here is to make use of the model of the system and introducing the experimental data to update the performance of the optimal controls. The concept of transfer learning is compatible with this approach, allowing knowledge to be transferred from one domain (model-based) to another (experimental).
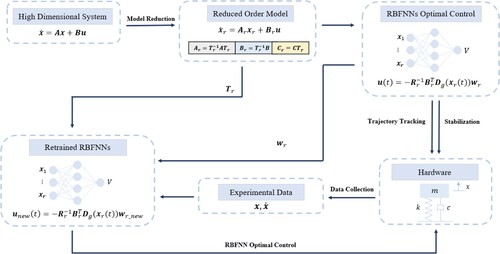
The retrained RBFNN control is experimentally evaluated and compared with the original model-based RBFNN control. A flowchart in Figure summarises the RBFNN control design procedure discussed in the previous sections.
Figure 1. Flowchart of the RBFNN optimal control algorithm with model reduction and transfer learning for linear systems.
6. RBFNN control for linear systems
The rotary pendulum is a benchmark dynamic system to study control performance. It is taken as a linear example for the RBFNN control validation due to its compatibility with numerical and experimental evaluation. The Quanser-Servo2 inverted pendulum system in Figure is the hardware to validate the performance of the algorithm. The system has two degrees of freedom. The corresponding state space is four dimensional, which makes the computation of the RBFNN control from the HJB equation more complicated. Note that the RBFNN control is first applied on a simple 2D system to validate its performance on the linear system as shown in Appendix.
Figure 2. Quanser-Servo2 Inverted Pendulum system hardware setup (Quanser, Citation2022).

6.1. Numerical simulations
The linearised model of the rotary pendulum at the equilibrium point is given by, (50)
(50)
(51)
(51) where θ is the angle of the rotary arm, α is the angle of the pendulum, τ is the applied torque at the base of the rotary arm.
is the moment of inertia of the rotary arm with respect to the axis of rotation of the arm,
is the moment of inertial of the pendulum link relative to the axis of rotation of the pendulum,
and
are the viscous damping coefficients of the rotary arm and the pendulum, respectively.
is the mass of the rotary arm and
is the mass of the pendulum,
is the length of the pendulum and
. The nominal values of the rotary pendulum parameters provided by Quanser are listed in Table .
Table 1. Parameters of the rotary pendulum system.
The state equations of the linear model in Equations (Equation50(50)
(50) ) and (Equation51
(51)
(51) ) with the nominal values of the parameters are given by,
(52)
(52)
(53)
(53) where
is the state vector of the rotary pendulum. The outputs are the angles of rotary arm θ and pendulum α. In simulations, it is assumed that all the system states are available for the full state feedback control. In experiments, the derivatives of the angle measurements can be obtained through a low pass filter (Quanser, Citation2022),
(54)
(54) Model-based balanced truncation and empirical balanced truncation are both applied to the Quanser inverted pendulum system to obtain a reduced order model. The empirical balanced truncation is designed for the stable system with steady state impulse response. However, the empirical balanced truncation has been shown to be a suitable method for systems with unstable modes and non-homogeneous initial conditions due to its data-driven nature (Himpe, Citation2018). In support of this finding, numerical simulations have demonstrated the applicability of empirical balanced truncation to the Quanser inverted pendulum within a short simulation time
in this study. In this case, due to the instability of the system, the reduced order model obtained from empirical balanced truncation is different from balanced truncation. Details of the reduced order model matrices from model-based and empirical gramians can be found in Table .
Table 2. Summary of reduced order model matrices from model-based gramians and empirical gramians.
The Hankel singular values of the rotary pendulum from model-based gramians are shown in Table . The first two rows represent the unstable modes of the system with infinite singular values out of the range of the plot. The last two rows represent the stable modes of the system with finite singular values. Table suggests that the first three eigen-modes dominate the system. Hence, the order of the reduced order model is chosen to be r = 3 to approximate the original model for both balanced truncation and empirical balanced truncation.
Table 3. Hankel singular values of the rotary pendulum.
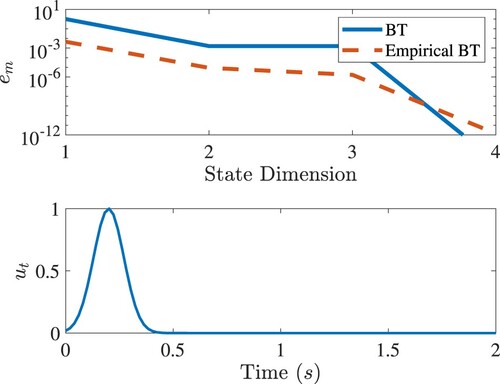
Figure shows the relative output error of the two reduced order models compared to the output of the original system in Equations (Equation47
(47)
(47) ) and (Equation48
(48)
(48) ) when the same input
is applied.
is defined as
(55)
(55) where
is the number of integration steps and i is the discrete time index, corresponding to the physical time
.
is the integration time step or sample time in experiments. The relative output error of the empirical balanced truncation is less than the model-based balanced truncation as seen in Figure . This indicates that the empirical gramians contain more accurate information than the model-based balanced gramians.
Figure 3. Top: Relative output errors of the reduced order model by the balanced truncation and empirical balanced truncation. Below: The input signal.
The LQR control of the original system is taken as a benchmark to compare with the performance of the RBFNN controls designed with the reduced order models. The and
matrices for the LQR control of the original system and the reduced order models are given by,
(56)
(56) The sampling region for the RBFNN method with the reduced order model is chosen as
. The means of Gaussian neurons are uniformly distributed in the region
. The standard deviations of Gaussian neurons are
. The number of neurons
and the sampling points
.
denotes the trainable weights of the RBFNN for the reduced order model.
We first consider tracking control. The reference signal is chosen as,
(57)
(57) After that, the reference in the reduced order model space reads,
(58)
(58) The optimal control is given Equation (Equation49
(49)
(49) ). A root mean square (RMS) error is defined to quantify the performance of the tracking control,
(59)
(59) We have chosen the time duration of 50 s and integration step
. Hence, the number of integration steps
.
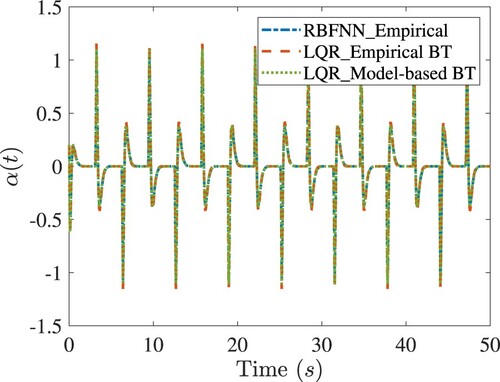
Consider a square wave reference. Figure shows the performance of the controls under consideration. From this figure, it is clear that the RBFNN optimal control has the ability to track the desired trajectory with different reduced order models and shows similar results compared to the LQR control of the original system. The RMS tracking errors of the RBFNN controls based on the model-based BT and empirical BT reduced order model and the LQR are 3.13, 3.16 and 3.71, respectively. Figures and show the comparisons of empirical RBFNN with the LQR control designed with the empirical BT and model-based BT.
Figure 4. Tracking the square wave of the rotary army in simulations. In the legend, ‘LQR’ denotes the LQR control designed with the original model; ‘RBFNN’ denotes the RBFNN control designed with the model-based BT; ‘Empirical RBFNN’ denotes the RBFNN control designed with the empirical BT.
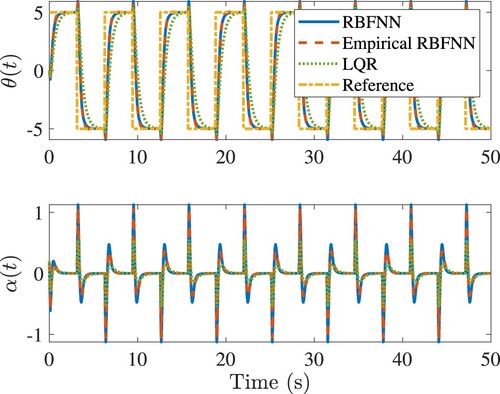
Figure 5. Comparisons of tracking response of the rotary army in simulations. In the legend, ‘RBFNN_Empirical’ denotes the RBFNN control designed with the empirical BT; ‘LQR_Empirical BT’ denotes the LQR control designed with the empirical BT; ‘LQR_Model-based BT’ denotes the LQR control designed with the model-based BT.
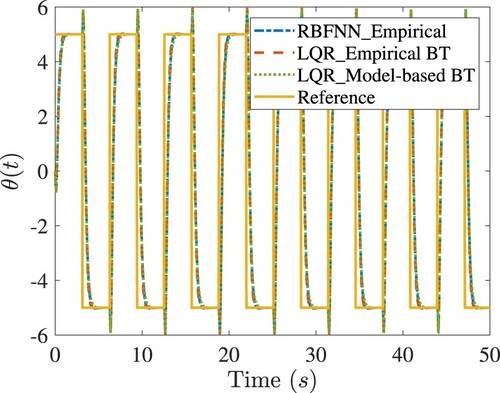
Figure 6. Comparisons of tracking response of the rotary army in simulations. Legends are the same as in Figure .
6.2. A summary
The rotary pendulum model is inherently unstable. Finding an initial stabilising random control to enable policy iteration convergence in RBFNN control design using the original model is a challenging mask. We have discovered that it is much easier to find an initial stabiliser for the reduced order system to make the policy iteration converge. This is an interesting phenomenon that deserves further investigation.
The RBFNN controls are pre-trained and can be implemented in the hardware. In the following, experimental data of the RBFNN controls were collected from the Quanser-Servo2 inverted pendulum and further improve the performance of these controls with the transfer leaning technique.
6.3. Experimental validation
Two control experiments of pendulum balancing and rotary arm trajectory tracking are carried out on the Quanser-Servo2 Inverted Pendulum system with the RBFNN optimal controllers. All the experiments are done with Quanser HIL and MATLAB Simulink. The sample time is set to . The tests run for
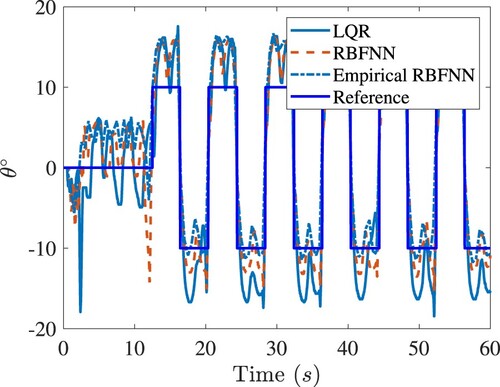
. The closed-loop responses tracking the square wave as the reference signal for rotary arm are shown in Figure . Both the RBFNN optimal controls deliver better tracking performance than the LQR control.
Figure 7. The closed-loop tracking responses of the rotary arm of Quanser-Servo2. Legends are the same as in Figure .
Experimental data have been obtained to improve the control performance through retraining the neural networks. The transient responses of the system have been eliminated and the remaining data have been restricted to the time interval for the model-based BT design and
for the empirical BT design. The effect of retraining on balancing control is shown in Figure . It is clear that the retraining of the neural networks with experimental data benefits the control designed with the empirical BT most.
Figure 8. The closed-loop responses of the rotary arm under various controls for balancing the inverted pendulum of Quanser-Servo2. Top: Responses before retraining. Bottom: Responses after retraining. Legends are the same as in Figure .
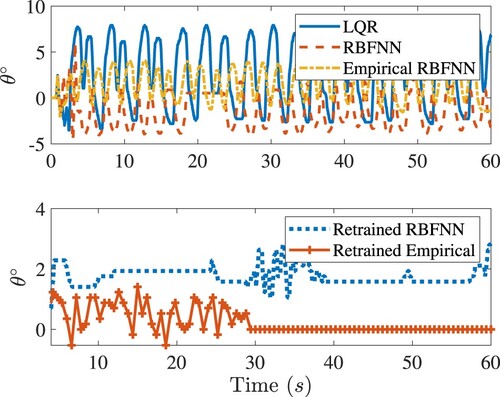
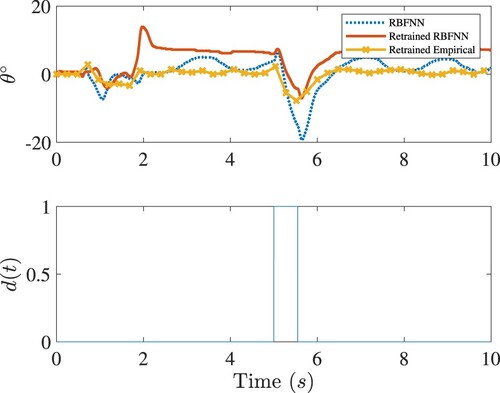
Figure shows the effect of retraining on tracking control. Compared to Figure , the performance improvement of tracking the angle is obvious. Moreover, suppression of many spiky responses of
angle in Figure is a strong evidence of the benefits of retraining.
Figure 9. The closed-loop tracking response of the rotary arm of Quanser-Servo2. Legends are the same as in Figure .
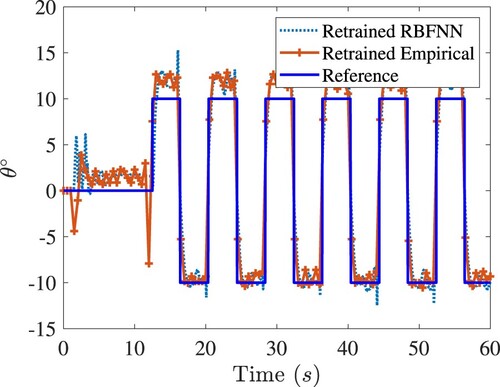
Figure 10. The closed-loop response of the pendulum in the rotary arm tracking control of Quanser-Servo2. Legends are the same as in Figure .
A measure of control effort is defined in terms of the integrated absolute control voltage , which is given by,
(60)
(60) Table lists the RMS tracking errors and the control effort with a consideration of the effects of retraining. It is worth noting that the RBFNN control designed with the empirical BT has the smallest RMS error.
Table 4. Summary of control performance for LQR, RBFNN, empirical RBFNN, retrained RBFNN and retrained empirical RBFNN.
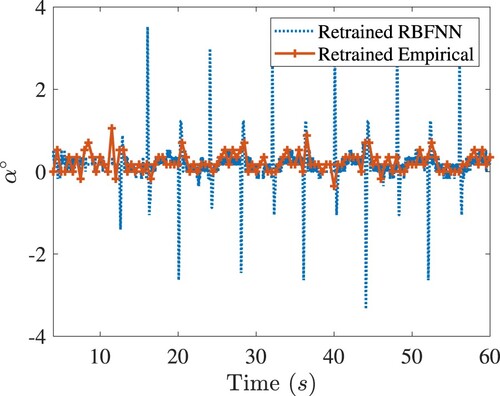
The robustness of the balancing control to disturbance is also investigated through experimental evaluation. A torque disturbance is injected at
by introducing a voltage pulse to the motor. Figure shows that the retrained empirical RBFNN has superb robustness to disturbance compared to the other two controls.
Figure 11. Robustness comparisons of all the controls under consideration. Top: The closed-loop angle response of the rotary arm in balancing control of Quanser-Servo2. Bottom: Disturbance
. Legends are the same as in Figure .
7. Nonlinear controls
The RBFNN method is now applied to obtain optimal controls for nonlinear systems and study the robustness of RBFNN control with respect to the model uncertainty.
7.1. A second order system
Neural networks with polynomial activation functions (Poly-NN) have been applied to find the solutions of the HJB equation. This has been a popular example in the literature (L. Chen et al., Citation2023; Du et al., Citation2024; Lin et al., Citation2024; Luo et al., Citation2014; Modares & Lewis, Citation2014; Qin et al., Citation2023; Yang et al., Citation2014). In the following, the performance of the optimal control expressed in terms of the RBFNN with Gaussian neurons is compared with that of the polynomial neural networks (Poly-NN). Consider a second order nonlinear system,
(61)
(61) We take the Poly-NN reported in Abu-Khalaf and Lewis (Citation2005) to compare with the proposed RBFNN control. No control constraints are imposed in the comparison. Both the neural networks are trained in the sampling region
and applied to two regions
and
to check their ability to provide good control performance beyond the training region. This is a way to study the generalisation of the neural networks.
The Poly-NN has 24 neurons where the RBFNN has neurons. The sampling points are
for both neural networks. The standard deviations of Gaussian neurons are
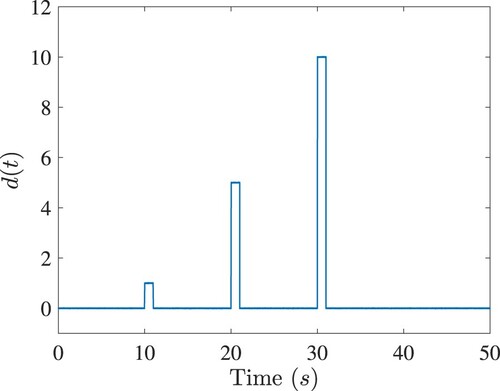
. To investigate robustness of the controls, a disturbance
is considered to each state of the system as shown in Figure .
(62)
(62) where
is the Gaussian white noise. Its signal-to-noise (SNR) ratio is 50 dB.
Figure 12. Disturbances to the second order nonlinear system.
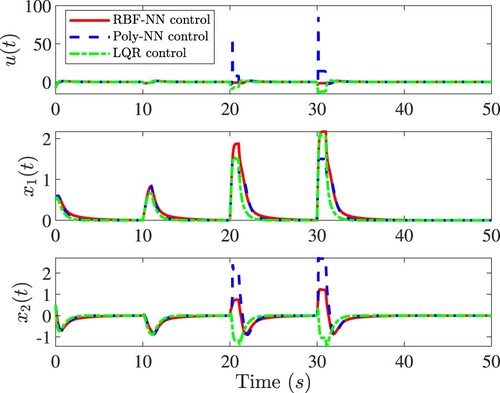
The closed-loop responses are shown in Figure . Within the training region , the RBFNN, Poly-NN and LQR controls have about the same performance when the system starts from the same initial condition
and is subject to the disturbance
. Note that the LQR control is designed based on the linearised system. When the disturbance becomes stronger, the RBFNN control can still stabilise the system with reasonable effort. However, the Poly-NN control performs poorly.
Figure 13. Performance comparison of RBFNN, Poly-NN control and LQR controls for the nonlinear system in Equation (Equation61(61)
(61) ). Top: The control
. Middle: The response
. Bottom: The response
.
This is due to the well-known fact that polynomials generate large extrapolation errors in regression applications. We compare both the controls in the training region and in a larger region
in Figure . As seen from the figure, the Poly-NN control grows unbounded quickly outside the training region and can no longer stabilise the system, while the RBFNN control remains bounded and can still stabilise the system in this larger region. As a matter of fact, the RBFNN control will remain bounded and approach zero at locations far away from the training region, because all the Gaussian neurons with means in the training region decrease exponentially.
Figure 14. Comparison of spatial distribution of RBFNN and Poly-NN optimal controls u as a function of the state . Left: The control
plotted in the training region
. Right: The control
plotted beyond the training region into the larger region
.
![Figure 14. Comparison of spatial distribution of RBFNN and Poly-NN optimal controls u as a function of the state x. Left: The control u(x) plotted in the training region Xs1∈[−1,1]×[−1,1]. Right: The control u(x) plotted beyond the training region into the larger region Xs2∈[−2,2]×[−2,2].](/cms/asset/db99f4a6-3c95-4203-9bde-f43012e35e31/tcon_a_2328687_f0014_oc.jpg)
7.2. Duffing system
Consider the Duffing system as another example to test the robustness of RBFNN controller with changing parameters,
(63)
(63) The sampling region is
. Corresponding to the sampling region, the means of Gaussian neurons are uniformly distributed in the region
.
We take as the nominal value and allow β to vary in a known range
. Both the RBFNN and LQR controls are designed with the nominal value of β. Note that the LQR control is designed for the linearised system at
. The performance index J of the LQR design is defined as,
(64)
(64) where k is the discrete time index, and
is number of integration steps of the simulation. The matrices are given by
(65)
(65) We have chosen
. The integration time step is
. We simulate the closed-loop system starting from the same initial condition
.
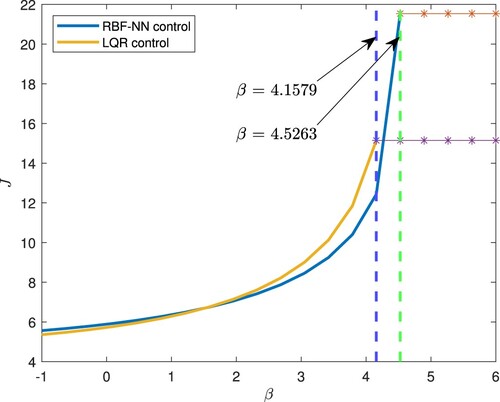
The index J is used to evaluate the performance of both the RBFNN and LQR controls. Figure shows the performance index J as a function of β for both the RBFNN and LQR controls. When the actual value of β is less than the nominal value 2, the linearised model of the system remains valid. As a result, the LQR control is slightly better than the RBFNN control. However, when , the linearised model at
becomes less accurate, resulting in poor performance of the LQR control compared with the RBFNN control. When β reaches a critical value
, marked by the vertical lines in the figure, the closed-loop system becomes unstable and the performance index J grows unbounded. For the LQR control,
, while for the RBFNN control,
. This is a quantitative measurement of robustness to model uncertainty.
Figure 15. Robustness of the RBFNN and LQR controls with respect to the model uncertainty β. The vertical dash lines mark the critical value of β, beyond which the closed-loop system becomes unstable.
Finally, we should point out that the RBFNN with one hidden layer can find optimal controls with good performance and robustness for nonlinear dynamic systems. The design of RBFNN itself is not optimised in this study. However, there are studies on how to design RBFNN in the literature, such as ErrCor algorithm (Yu et al., Citation2011), hierarchical growing strategy (GGAP algorithm) (Sundararajan et al., Citation1999), MRAN algorithm (Kadirkamanathan & Niranjan, Citation1993), resource allocation algorithm (Platt, Citation1991), and adaptive RBF algorithms (Alwardi et al., Citation2013, Citation2012; González-Casanova et al., Citation2009). These algorithms can be considered for optimal design of RBFNN architecture in the future study.
Remark 7.1
This paper proposes a method to compute the solutions of nonlinear optimal control expressed in terms of the RBFNN with Gaussian activation functions for multi-degree-of-freedom dynamic systems. Combined with model reduction and transfer learning algorithm, the computational efficiency and the control performance have been significantly improved. Extensive numerical simulations and experimental studies show that the RBFNN offer excellent control performance and much-improved robustness to disturbances and model uncertainties. It is worth mentioning that the RBFNN control delivers the same performance as the LQR control for the LTI system. Our previous work (Zhao & Sun, Citation2022) indicates that the BT reduction for the LTI system leads to significant performance improvements compared to the LQR control. For nonlinear systems, such as the Duffing system shown in Section 7.2, the nonlinear optimal control solution from RBFNN shows improved robustness compared to the LQR control for the linearised system.
Remark 7.2
Our early work (Gholami et al., Citation2023) indicates that other neural networks, such as multi-layer perceptron, are not suitable for solving the HJB equation. In the paper (Gholami et al., Citation2023), we adopted a two-layer perceptron neural networks with hyperbolic tangent functions to approximate the derivative of the value function in the HJB equation. However, it is very time-consuming to solve the optimal control. Additionally, the structure of multi-layer perceptron is not beneficial to obtain the explicit expression of the optimal coefficient in Equation (Equation35(35)
(35) ), which is one of the reasons why the proposed RBFNN method is efficient and accurate.
8. Conclusion
This paper has presented a RBFNN optimal control approach with Gaussian neurons. Instead of analytically solving the HJB equation, the RBFNN computes the optimal control solution with high efficiency. The RBFNN optimal controls are obtained off-line in the state space for both linear and nonlinear dynamic systems. Extensive simulations and experimental studies have been presented and suggest that the RBFNN optimal control can deliver excellent performance and robustness. We have also implemented model reduction techniques to reduce computational burden of the RBFNN design when solving HJB equations in high dimensional state space, and explored transfer learning concept to update the coefficients of the neural networks with new experimental data leading to a better control performance in experiments. The extensive numerical simulations and experimental validations prove that the neural networks with one-hidden layer have significant potential for different electro-mechanical systems, particularly high-dimensional nonlinear dynamical systems. The work demonstrates that with a limited number of neurons, the RBFNN can be successfully implemented on the micro-controller hardware. Moreover, a comparative analysis between RBFNN and other similar machine learning algorithms, such as LANN-SVD algorithm can be an interesting research topic for the future.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Abu-Khalaf, M., & Lewis, F. L. (2005). Nearly optimal control laws for nonlinear systems with saturating actuators using a neural network HJB approach. Automatica, 41(5), 779–791. https://doi.org/10.1016/j.automatica.2004.11.034
- Alwardi, H., Wang, S., & Jennings, L. S. (2013). An adaptive domain decomposition method for the Hamilton–Jacobi–Bellman equation. Journal of Global Optimization, 56(4), 1361–1373. https://doi.org/10.1007/s10898-012-9850-2
- Alwardi, H., Wang, S., Jennings, L. S., & Richardson, S. (2012). An adaptive least-squares collocation radial basis function method for the HJB equation. Journal of Global Optimization, 52(2), 305–322. https://doi.org/10.1007/s10898-011-9667-4
- Borovykh, A., Kalise, D., Laignelet, A., & Parpas, P. (2022). Data-driven initialization of deep learning solvers for Hamilton–Jacobi–Bellman PDEs. IFAC-PapersOnLine, 55(30), 168–173. https://doi.org/10.1016/j.ifacol.2022.11.047
- Chen, J.-S., Hillman, M., & Chi, S.-W. (2017). Meshfree methods: Progress made after 20 years. Journal of Engineering Mechanics, 143(4), 04017001. https://doi.org/10.1061/(ASCE)EM.1943-7889.0001176
- Chen, L., Dong, C., & Dai, S.-L. (2023). Adaptive optimal consensus control of multiagent systems with unknown dynamics and disturbances via reinforcement learning. IEEE Transactions on Artificial Intelligence. https://doi.org/10.1109/TAI.2023.3324895
- Cheng, T., Lewis, F. L., & Abu-Khalaf, M. (2007a). A neural network solution for fixed-final time optimal control of nonlinear systems. Automatica, 43(3), 482–490. https://doi.org/10.1016/j.automatica.2006.09.021
- Cheng, T., Lewis, F. L., & Abu-Khalaf, M. (2007b). Fixed-final-time-constrained optimal control of nonlinear systems using neural network HJB approach. IEEE Transactions on Neural Networks, 18(6), 1725–1737. https://doi.org/10.1109/TNN.2007.905848
- Crandall, M. G., & Lions, P.-L. (1983). Viscosity solutions of Hamilton–Jacobi equations. Transactions of the American Mathematical Society, 277(1), 1–42. https://doi.org/10.1090/tran/1983-277-01
- Darbon, J., Dower, P. M., & Meng, T. (2021). Neural network architectures using min plus algebra for solving certain high dimensional optimal control problems and Hamilton–Jacobi PDEs. Preprint. arXiv:2105.03336.
- Darbon, J., & Osher, S. (2016). Algorithms for overcoming the curse of dimensionality for certain Hamilton–Jacobi equations arising in control theory and elsewhere. Research in the Mathematical Sciences, 3(1), 1–26. https://doi.org/10.1186/s40687-016-0068-7
- Djeridane, B., & Lygeros, J. (2006). Neural approximation of PDE solutions: An application to reachability computations. In Proceedings of the 45th IEEE Conference on Decision and Control (pp. 3034–3039). San Diego, CA, USA: IEEE.
- Doya, K. (2000). Reinforcement learning in continuous time and space. Neural Computation, 12(1), 219–245. https://doi.org/10.1162/089976600300015961
- Du, Y., Jiang, B., & Ma, Y. (2024). Adaptive optimal sliding-mode fault-tolerant control for nonlinear systems with disturbances and estimation errors. Complex & Intelligent Systems, 10, 1087–1101.
- Gawronski, W., & Juang, J.-N. (1990). Model reduction in limited time and frequency intervals. International Journal of Systems Science, 21(2), 349–376. https://doi.org/10.1080/00207729008910366
- Gholami, A., Sun, J.-Q., & Ehsani, R. (2023). Neural networks based optimal tracking control of a delta robot with unknown dynamics. International Journal of Control, Automation and Systems, 21(10), 3382–3390. https://doi.org/10.1007/s12555-022-0745-9
- González-Casanova, P., Muñoz-Gómez, J. A., & Rodríguez-Gómez, G. (2009). Node adaptive domain decomposition method by radial basis functions. Numerical Methods for Partial Differential Equations: An International Journal, 25(6), 1482–1501. https://doi.org/10.1002/num.v25:6
- Greif, C. (2017). Numerical methods for Hamilton–Jacobi–Bellman equations [PhD thesis]. University of Wisconsin, Milwaukee].
- Grundel, S., Himpe, C., & Saak, J. (2019). On empirical system gramians. PAMM, 19(1), e201900006. https://doi.org/10.1002/pamm.v19.1
- Gugercin, S., & Antoulas, A. C. (2004). A survey of model reduction by balanced truncation and some new results. International Journal of Control, 77(8), 748–766. https://doi.org/10.1080/00207170410001713448
- Guo, Y., Shi, H., Kumar, A., Grauman, K., Rosing, T., & Feris, R. (2019). Spottune: Transfer learning through adaptive fine-tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4805–4814). Long Beach, CA, USA.
- Han, J., Jentzen, A., & E, W. (2018). Solving high-dimensional partial differential equations using deep learning. Proceedings of the National Academy of Sciences, 115(34), 8505–8510. https://doi.org/10.1073/pnas.1718942115
- Heinkenschloss, M., Reis, T., & Antoulas, A. C. (2011). Balanced truncation model reduction for systems with inhomogeneous initial conditions. Automatica, 47(3), 559–564. https://doi.org/10.1016/j.automatica.2010.12.002
- Himpe, C. (2018). Emgr – the empirical gramian framework. Algorithms, 11(7), 91. https://doi.org/10.3390/a11070091
- Huang, Y., & Kramer, B. (2020). Balanced reduced-order models for iterative nonlinear control of large-scale systems. IEEE Control Systems Letters, 5(5), 1699–1704. https://doi.org/10.1109/LCSYS.7782633
- Jiang, F., Chou, G., Chen, M., & Tomlin, C. J. (2016). Using neural networks to compute approximate and guaranteed feasible Hamilton–Jacobi–Bellman PDE solutions. Preprint. arXiv:1611.03158.
- Kadirkamanathan, V., & Niranjan, M. (1993). A function estimation approach to sequential learning with neural networks. Neural Computation, 5(6), 954–975. https://doi.org/10.1162/neco.1993.5.6.954
- Lagaris, I. E., Likas, A. C., & Papageorgiou, D. G. (2000). Neural-network methods for boundary value problems with irregular boundaries. IEEE Transactions on Neural Networks, 11(5), 1041–1049. https://doi.org/10.1109/72.870037
- Laub, A., Heath, M., Paige, C., & Ward, R. (1987). Computation of system balancing transformations and other applications of simultaneous diagonalization algorithms. IEEE Transactions on Automatic Control, 32(2), 115–122. https://doi.org/10.1109/TAC.1987.1104549
- Lewis, F., Jagannathan, S., & Yesildirak, A. (1998). Neural network control of robot manipulators and non-linear systems. CRC Press.
- Lin, J., Zhao, B., Liu, D., & Wang, Y. (2024). Dynamic compensator-based near-optimal control for unknown nonaffine systems via integral reinforcement learning. Neurocomputing, 564, 126973. https://doi.org/10.1016/j.neucom.2023.126973
- Liu, D., Li, H., & Wang, D. (2014). Online synchronous approximate optimal learning algorithm for multi-player non-zero-sum games with unknown dynamics. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 44(8), 1015–1027. https://doi.org/10.1109/TSMC.2013.2295351
- Luo, B., Wu, H.-N., Huang, T., & Liu, D. (2014). Data-based approximate policy iteration for affine nonlinear continuous-time optimal control design. Automatica, 50(12), 3281–3290. https://doi.org/10.1016/j.automatica.2014.10.056
- Medagam, P. V., & Pourboghrat, F. (2009). Optimal control of nonlinear systems using RBF neural network and adaptive extended Kalman filter. In American Control Conference (pp. 355–360). St. Louis, MO, USA: IEEE.
- Meyn, S. (2022). Control systems and reinforcement learning. Cambridge University Press.
- Modares, H., & Lewis, F. L. (2014). Optimal tracking control of nonlinear partially-unknown constrained-input systems using integral reinforcement learning. Automatica, 50(7), 1780–1792. https://doi.org/10.1016/j.automatica.2014.05.011
- Modares, H., Lewis, F. L., & Naghibi-Sistani, M.-B. (2014). Integral reinforcement learning and experience replay for adaptive optimal control of partially-unknown constrained-input continuous-time systems. Automatica, 50(1), 193–202. https://doi.org/10.1016/j.automatica.2013.09.043
- Munos, R., Baird, L. C., & Moore, A. W. (1999). Gradient descent approaches to neural-net-based solutions of the Hamilton–Jacobi–Bellman equation. In Proceedings of International Joint Conference on Neural Networks (Vol. 3, pp. 2152–2157). Washington, DC, USA: IEEE.
- Nakamura-Zimmerer, T., Gong, Q., & Kang, W. (2020). A causality-free neural network method for high-dimensional Hamilton–Jacobi–Bellman equations. In 2020 American Control Conference (pp. 787–793). Denver, CO, USA: IEEE.
- Nakamura-Zimmerer, T., Gong, Q., & Kang, W. (2021). Adaptive deep learning for high-dimensional Hamilton–Jacobi–Bellman equations. SIAM Journal on Scientific Computing, 43(2), A1221–A1247. https://doi.org/10.1137/19M1288802
- Nakamura-Zimmerer, T. E. (2022). A deep learning framework for optimal feedback control of high-dimensional nonlinear systems [Thesis]. UC Santa Cruz.
- Park, J., & Sandberg, I. W. (1991). Universal approximation using radial-basis-function networks. Neural Computation, 3(2), 246–257. https://doi.org/10.1162/neco.1991.3.2.246
- Pernebo, L., & Silverman, L. (1982). Model reduction via balanced state space representations. IEEE Transactions on Automatic Control, 27(2), 382–387. https://doi.org/10.1109/TAC.1982.1102945
- Phillips, J., Daniel, L., & Silveira, L. M. (2022). Guaranteed passive balancing transformations for model order reduction. In Proceedings of the 39th Annual Design Automation Conference (pp. 52–57). New Orleans, LA, USA.
- Platt, J. (1991). A resource-allocating network for function interpolation. Neural Computation, 3(2), 213–225. https://doi.org/10.1162/neco.1991.3.2.213
- Qin, C., Qiao, X., Wang, J., Zhang, D., Hou, Y., & Hu, S. (2023). Barrier-critic adaptive robust control of nonzero-sum differential games for uncertain nonlinear systems with state constraints. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 54, 50–63.
- Quanser (2022). QUBE-Servo2. https://www.quanser.com/products/qube-servo-2/
- Saridis, G. N., & Lee, C.-S. G. (1979). An approximation theory of optimal control for trainable manipulators. IEEE Transactions on Systems, Man, and Cybernetics, 9(3), 152–159. https://doi.org/10.1109/TSMC.1979.4310171
- Silverman, B. (2018). Density estimation for statistics and data analysis. CRC Press.
- Singh, A. K., & Hahn, J. (2005). On the use of empirical gramians for controllability and observability analysis. In Proceedings of the American Control Conference (pp. 140–141). Portland, OR, USA: IEEE.
- Sirignano, J., & Spiliopoulos, K. (2018). DGM: A deep learning algorithm for solving partial differential equations. Journal of Computational Physics, 375, 1339–1364. https://doi.org/10.1016/j.jcp.2018.08.029
- Stefansson, E., & Leong, Y. P. (2016). Sequential alternating least squares for solving high dimensional linear Hamilton–Jacobi–Bellman equation. In Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (pp. 3757–3764). Daejeon, Korea (South).
- Sun, J. Q., & Hsu, C. S. (1988). A statistical study of generalized cell mapping. Journal of Applied Mechanics, 55, 694–701. https://doi.org/10.1115/1.3125851
- Sundararajan, N., Saratchandran, P., & Lu, Y. W. (1999). Radial basis function neural networks with sequential learning: MRAN and its applications (Vol. 11). World Scientific.
- Tassa, Y., & Erez, T. (2007). Least squares solutions of the HJB equation with neural network value-function approximators. IEEE Transactions on Neural Networks, 18(4), 1031–1041. https://doi.org/10.1109/TNN.2007.899249
- Wang, X., Jiang, J., Hong, L., & Sun, J.-Q. (2022a). First-passage problem in random vibrations with radial basis function neural networks. Journal of Vibration and Acoustics, 144(5), 051014. https://doi.org/10.1115/1.4054437
- Wang, X., Jiang, J., Hong, L., & Sun, J.-Q. (2022b). Stochastic bifurcations and transient dynamics of probability responses with radial basis function neural networks. International Journal of Non-Linear Mechanics, 147, 104244. https://doi.org/10.1016/j.ijnonlinmec.2022.104244
- Wang, X., Jiang, J., Hong, L., Zhao, A., & Sun, J.-Q. (2023). Radial basis function neural networks solution for stationary probability density function of nonlinear stochastic systems. Probabilistic Engineering Mechanics, 71, 103408. https://doi.org/10.1016/j.probengmech.2022.103408
- Wu, Y., Hamroun, B., Le Gorrec, Y., & Maschke, B. (2020). Reduced order LQG control design for infinite dimensional port Hamiltonian systems. IEEE Transactions on Automatic Control, 66(2), 865–871. https://doi.org/10.1109/TAC.9
- Wu, Y., Wang, H., Zhang, B., & Du, K.-L. (2012). Using radial basis function networks for function approximation and classification. ISRN Applied Mathematics, 2012, 1–34. https://doi.org/10.5402/2012/324194
- Yang, X., Liu, D., & Wang, D. (2014). Reinforcement learning for adaptive optimal control of unknown continuous-time nonlinear systems with input constraints. International Journal of Control, 87(3), 553–566. https://doi.org/10.1080/00207179.2013.848292
- Yegorov, I., & Dower, P. M. (2021). Perspectives on characteristics based curse-of-dimensionality-free numerical approaches for solving Hamilton–Jacobi equations. Applied Mathematics & Optimization, 83(1), 1–49. https://doi.org/10.1007/s00245-018-9509-6
- Yu, H., Xie, T., Paszczyñski, S., & Wilamowski, B. M. (2011). Advantages of radial basis function networks for dynamic system design. IEEE Transactions on Industrial Electronics, 58(12), 5438–5450. https://doi.org/10.1109/TIE.2011.2164773
- Zhang, D., Liu, W., Qin, C., & Chen, H. (2016). Adaptive RBF neural-networks control for discrete nonlinear systems based on data. In Proceedings of the 12th World Congress on Intelligent Control and Automation (pp. 2580–2585). Guilin, China: IEEE.
- Zhang, W., Shen, J., Ye, X., & Zhou, S. (2022). Error model-oriented vibration suppression control of free-floating space robot with flexible joints based on adaptive neural network. Engineering Applications of Artificial Intelligence, 114, 105028. https://doi.org/10.1016/j.engappai.2022.105028
- Zhao, A., & Sun, J.-Q. (2022). Control for stability improvement of high-speed train bogie with a balanced truncation reduced order model. Vehicle System Dynamics, 60(12), 4343–4363. https://doi.org/10.1080/00423114.2021.2025408
Appendix. A linear 2D system
In this section, we adopt a linear 2D system as an example to validate the performance of the RBFNNs control presented in Sections 2 and 3. It is noted that the model reduction algorithm is not applied since the system has a low dimension and requires reasonably low computational cost. The linear 2D system is defined as,
(A1)
(A1) where m = 1, c = 2 and k = 1. The region to distribute Gaussian neurons is chosen as
. The region to sample points for integration is chosen as
. The number of neurons
are
and the sampling points are
.
and
are chosen as,
(A2)
(A2) The results are shown in Figure . From Figure , we can see that RBFNNs can find the exactly same optimal solution as LQR for the linear 2D system.
Figure A1. Comparison of RBFNNs and LQR control performances for the linear 2D system. Top: Control . Middle: Response
. Bottom: Response
. The initial condition of the system is
.
![Figure A1. Comparison of RBFNNs and LQR control performances for the linear 2D system. Top: Control u(t). Middle: Response x1(t). Bottom: Response x2(t). The initial condition of the system is x(0)=[1,1]T.](/cms/asset/2333d903-4fb1-4ce0-ac59-68b69e0a4db8/tcon_a_2328687_f0016_oc.jpg)