
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Fault diagnosis is an indispensable basis for the collaborative maintenance in prognostic and health management. Most of existing data-driven fault diagnosis approaches are designed in the framework of supervised learning, which requires a large number of labelled samples. In this paper, a novel self-training semi-supervised deep learning (SSDL) approach is proposed to train a fault diagnosis model together with few labelled and abundant unlabelled samples. The addressed SSDL approach is realised by initialising a stacked sparse auto-encoder classifier using the labelled samples, and subsequently updating the classifier via sampling a few candidates with most reliable pseudo labels from the unlabelled samples step by step. Unlike the commonly used static sampling strategy in existing self-training semi-supervised frameworks, a gradually exploiting mechanism is proposed in SSDL to increase the number of selected pseudo-labelled candidates gradually. In addition, instead of using the prediction accuracy as the confidence estimation for pseudo-labels, a distance-based sampling criterion is designed to assign the label for each unlabelled sample by its nearest labelled sample based on their Euclidean distances in the deep feature space. The experimental results show that the proposed SSDL approach can achieve good prediction accuracy compared to other self-training semi-supervised learning algorithms.
1. Introduction
As mechanical systems become more and more automatic and integrated, intelligent fault diagnosis of mechanical systems becomes increasingly important to guarantee safe operations (Wang et al. Citation2021; Lei et al. Citation2020; Shao et al. Citation2021). Moreover, in the context of industry 4.0, there is a new trend that maintenance planning is conducted in a collaborative way with production scheduling for more informative decision-making (Majdouline et al. Citation2021; Yang, Chen, and Dauzere-Peres Citation2021). Effective fault diagnosis is also an indispensable basis for designing advanced collaborative maintenance strategies (Hanachi et al. Citation2019; Artigao, Honrubia-Escribano, and Gomez-Lazaro Citation2020; Jeong, Leon, and Villalobos Citation2007; Shao et al. Citation2021).
Model-based, knowledge-based and data-driven techniques are three typical methods that widely studied in the field of fault diagnosis (Gao, Cecati, and Ding Citation2015a; Gao, Cecati, and Ding Citation2015b). Nowadays, the development of data-driven fault diagnosis techniques is accelerating and booming due to the following two reasons: (1) accurate mathematical models or complete experience knowledge bases are generally difficult to be established for complicated mechanical systems; and (2) abundant health condition data related to mechanical systems can be collected with the development of online measurements (Zhang, Yu, and Wang Citation2021, Zhao et al. Citation2020a, Citation2020b).
In general, data-driven fault diagnosis techniques utilise machine learning algorithms, especially deep learning ones, to train predictive models based on the condition data collected under normal and different faulty states. Most of these data-driven techniques depend on the fully annotated data, namely, the label of each collected sample should be determined to make it clear what operational state (normal or fault) it belongs to (Shao et al. Citation2018; Long, Zhang, and Li Citation2020b; Lee, Park, and Lee Citation2020; Zhao et al. Citation2021). This is called as the supervised learning strategy. However, labeling large number of samples to different operational states is usually time-consuming and costly, sometimes even impossible, for machinery fault diagnosis. In the case of limited labelled data, supervised learning is difficult to achieve good results. By contrast, the unlabelled data is always rich and can be inexpensively or easily collected. Therefore, how to improve fault diagnosis performance using additional unlabelled data has attracted our attention.
Study on constructing learning models that can make use of labelled data together with unlabelled data was termed semi-supervised learning. The idea of semi-supervised learning first came to the fore in the 1970s (Agrawala Citation1970). Thenceforth, lots of classical semi-supervised learning methods have been proposed, such as semi-supervised support vector machines (Bennett and Demiriz Citation1999), co-training (Blum and Mitchell Citation1998), self-training (Rosenberg, Hebert, and Schneiderman Citation2005), generative models (Nigam et al. Citation2000), and graph-based methods (Belkin, Niyogi, and Sindhwani Citation2006). Since the successful application of deep neural network in image classification in 2015, deep learning plays an important role in many fields. The success of deep learning techniques has resulted in the rapid development of deep semi-supervised learning, which integrates the classical semi-supervised learning frameworks and deep neural networks. We refer interested readers to Yang et al. (Citation2021), which provides a comprehensive survey on deep semi-supervised learning methods.
Compared with a large number of supervised fault diagnosis studies, less attention has been paid to semi-supervised fault diagnosis approaches. Zheng et al. (Citation2019) proposed an ensemble form of the semi-supervised fisher discriminant analysis model for fault classification. Hu et al. (Citation2017) developed a systematic semi-supervised self-adaptable fault diagnostics approach in response to the evolving environment. Roozbeh et al. (Citation2019) designed a semi-supervised deep-learning approach for diagnosing multiple defects in a gearbox directly connected to an induction machine shaft. Potocnik and Govekar (Citation2017) proposed a semi-supervised vibration-based classification and condition monitoring method for the reciprocating compressors installed in refrigeration appliances. Zhao, Jia, and Liu (Citation2021) proposed a semisupervised graph convolution deep belief network algorithm for fault diagnosis of electormechanical system.
As introduced in Yang et al. (Citation2021), semi-supervised learning can be classified into several categories, i.e. generative methods, consistency regularisation methods, graph-based methods, pseudo-labeling methods, and hybrid methods. Self-training is a kind of widely-used and promising pseudo-labeling method. The main procedure of self-training strategies is as follows: (1) train a classifier using the labelled dataset at first; (2) predict the pseudo labels for the unlabelled samples using the trained classifier; (3) generate an enlarged training dataset by selecting some pseudo-labelled samples; (4) retrain the classifier using the enlarged training dataset; and (5) repeat the above processes until the predetermined stop criterion is satisfied.
Most of existing self-training strategies, however, adopt a static method to determine the number of selected pseudo-labelled samples in the abovementioned third step. For example, the prediction confidences of pseudo-labelled samples are always compared with a pre-defined threshold, and then those samples whose confidences larger than the fixed threshold will be selected (Fan et al. Citation2018; Ye et al. Citation2017). Accordingly, a large number of pseudo-labelled samples may be selected at each iteration in the incremental learning process of these self-training strategies. However, for fault diagnosis problems with a small number of labelled samples, these self-training strategies may not be suitable because lots of pseudo-label predictions are unreliable and inaccurate in the initial stage. Using the enlarged training dataset containing many not-yet-reliable samples to retrain the classifier would block the subsequent improvement of classification accuracy. In this study, to overcome the above difficulties, a gradually exploiting mechanism (GEM) is proposed for self-training. The philosophy of GEM is that a small-size subset of reliable pseudo-labelled samples is selected in the initial stage, and a growing number of pseudo-labelled samples are selected in the subsequent stages to incorporate more information-rich and diverse samples.
In addition to the abovementioned sampling strategy, the self-training performance is also affected by the sampling criterion. In most of existing studies, the prediction accuracy of classifiers are always directly used as the confidence estimation for pseudo-labels (Dong et al. Citation2017; Fan et al. Citation2017). However, the accuracies of samples predicted by the classifier trained on the dataset with few reliable labels in the early stages are generally low. Therefore, using the prediction accuracy as the sampling criterion is difficult to select reliable pseudo-labels for the subsequent learning process. Since deep neural networks have powerful feature extraction ability and similar samples may have similar feature representations in a learned embedding space, a distance-based sampling criterion (DBSC) that takes the Euclidean distance in the deep feature space as the confidence estimation, is designed in this study.
In summary, the main contribution of our work develops a novel self-training semi-supervised deep learning (SSDL) approach based on the GEM and DBSC for dealing with the machinery fault diagnosis with few labelled data and abundant unlabelled data. The novelty of SSDL means that a new sampling strategy and a novel sampling criterion method are designed compared to existing self-training semi-supervised frameworks. The rest of the paper is organised as below. Section 2 describes the framework of SSDL, including the self-training strategy and the deep feature learning algorithm. The details of GEM and DBSC are introduced in Section 3. Section 4 details the procedure of the proposed SSDL for machinery fault diagnosis. Experimental results of case studies of fault diagnosis using the proposed SSDL are reported in Section 5. Finally, conclusions are given in Section 6.
2. Framework of the proposed SSDL
2.1 Self-training strategy
For a semi-supervised fault diagnosis problem, there are usually a labelled dataset of size
and an unlabelled dataset
of size
, where
and
represent the j-th collected sample and its operational state label, respectively. The framework of the self-training strategy used in SSDL is shown in Figure . Initially, the self-training strategy requires the training of a classifier on the labelled dataset
to minimise the following loss function:
(1)
(1) where the function
, parameterised by
, is employed to extract features from
. Considering that the input data of most fault diagnosis problems are one-dimensional signal data, a stacked sparse auto-encoder (SSAE) model is selected as the function
. The details of SSAE will be introduced in the next Subsection. The function
, parameterised by
, is used to classify the abstracted features
into a
-dimensional label vector, where
is the number of operational states. Here, the function
is realised by the Softmax, which is a famous classifer that widely used in the deep learning network (Long et al. Citation2020a; Zhang et al. Citation2020). Finally, the suffered loss between the label prediction
and its true label
is denoted as
. For ease of description, the classifier trained on the labelled dataset is denoted as SSAE-Softmax.
Figure 1. Overview of the framework of the proposed SSDL.
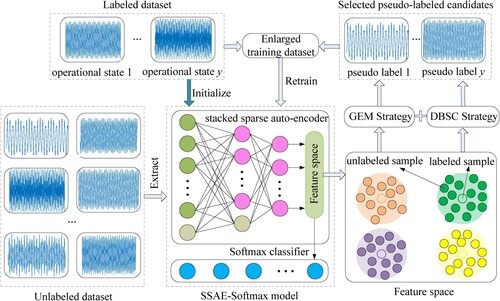
Through exploiting the unlabelled dataset , the SSAE-Softmax classifier is then iteratively updated by two steps, i.e. the pseudo label prediction and model retraining, to minimise the following objective function:
(2)
(2) where
represents the predicted pseudo label for the j-th unlabelled sample.
is a binary variable that is equal to one if and only if the suffered loss of the pseudo-labelled sample
is adopted in the optimization process.
In the pseudo label prediction step, the trained SSAE model, namely the function , is used to embed each labelled and unlabelled sample into a feature space. The proposed DBSC strategy is then employed to generate pseudo label for each unlabelled sample according to the Euclidean distance between the unlabelled sample and each labelled sample. In subsequence, a set of pseudo-labelled candidates is selected using the DBSC strategy as:
(3)
(3)
Note that the size of in each generation is controlled by the GEM strategy. In the model retraining step, an enlarged training dataset
is obtained by merging the initial labelled dataset
and the set
, i.e.
. The set
is subsequently used to retrain the SSAE-Softmax model so as to learn a more robust classifier.
2.2 SSAE-Softmax classifier
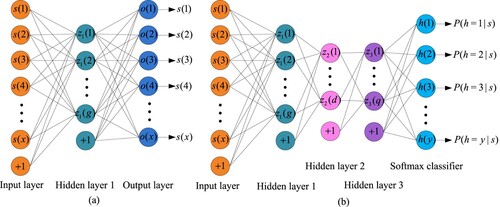
The training process of the SSAE-Softmax classifier on the initial labelled dataset or the enlarged training dataset is comprised of unsupervised pre-training followed by supervised fine-tuning. The SSAE model is established by stacking multiple trained sparse auto-encoders (SAEs). For any two consecutive SAEs in SSAE, the extracted features from the former one are used as the input data of the later one. SAE, shown in Figure (a), is a symmetrical structure neural network that trained to perfectly reconstruct the input data at the output layer through encoder and decoder processes, and the hidden layer in a trained SAE is then viewed as the extracted features of the input data. The detailed unsupervised training process of SAE can be referred to (Long et al. Citation2021). After unsupervised pre-training of SSAE, a Softmax classifier, i.e. a fully-connected layer, is stacked behind the last hidden layer of SSAE. The supervised fine-tuning of SSAE-Softmax classifier is finally performed using the back-propagation algorithm (Rumelhart, Hinton, and Williams Citation1986) to identify different kinds of operational states. The structure of the SSAE-Softmax classifier is shown in Figure (b).
Figure 2. Structure of SAE and SSAE-Softmax neural network: (a) symmetrical structure neural network of SAE, where is the dimension of each sample,
is the number of neurons in the hidden layer 1; and (b) structure of SSAE-Softmax classifier, where
and
are the number of neurons in the hidden layer 2 and hidden layer 3, respectively,
denotes the probability that
is classified as operational state
(
).
3. The proposed GEM and DBSC
As shown in Figure , how to select pseudo-labelled samples into set in each generation has a great impact on the performance of SSDL. Therefore, two significant problems related to this procedure need to be appropriately dealt with. One is how to determine the size of
, and the other is which sampling criterion is effective for selecting candidates.
For fault diagnosis problems with a small number of labelled samples, it is difficult to train a good pseudo-label prediction model at the early iterations. Therefore, at this stage, incorporating excessive pseudo-labelled samples into set is irrational. Moreover, sample imbalance, i.e. the number of samples of different categories varies greatly, should be avoided in the sampling process because it will generally cause significant interference to the learning process of a classifier. With respect to the self-training for a semi-supervised classification problem, the classification loss is a simple and versatile sampling criterion. However, it is far away to train an effective pseudo-label classifier for fault diagnosis problems, where each class has a small number of labelled samples. Thus, in the case that each sample may have a high classification loss, i.e. low prediction accuracy, it is not a high identification method to select samples by comparing the classification loss difference between samples.
In this paper, the GEM strategy and DBSC strategy are proposed to address the abovementioned problems. The proposed GEM is a dynamic sampling strategy, which increases the number of pseudo-labelled samples in set steadily during iterations. The GEM strategy begins with a small-size subset of pseudo-labelled samples in the initial iteration. Since the SSAE-Softmax classifier becomes more discriminative and robust with the iteration of training process, more information-rich and diverse samples can be incorporated into
in the following iterations. In addition, to avoid sample imbalance in the training dataset, at each iteration, an equal number of samples is selected by the GEM strategy for each class in set
.
Instead of classification loss, the proposed DBSC strategy adopts the Euclidean distance in the deep feature space as the confidence estimation for pseudo-label prediction. Considering that similar samples always have similar feature representations, the Nearest Neighbors classifier is employed to assign the label for each unlabelled sample by its nearest labelled sample based on their Euclidean distances in the deep feature space. The confidence estimation of pseudo-label is also defined as the Euclidean distance between the unlabelled sample and its nearest labelled one. Therefore, in the candidate selection process, equal number of top reliable pseudo-labelled samples is selected for each class according to their pseudo-label estimation confidence.
More formally, since the trained SSAE model, i.e. the function , is used as the feature extractor, the estimation confidence for each unlabelled sample
is defined as the minimum Euclidean distance between
and an arbitrary labelled sample
in the feature space. Therefore, the estimation confidence and pseudo-label parameterised by
of
can be described by the following formulas (4) and (5), respectively.
(4)
(4)
(5)
(5) where the function
denotes the label extraction function for samples, namely
.
As shown in Equation (3), selecting set means determining the value of the binary variable
for each pseudo-labelled sample. For ease of description, we use
to represent all the binary variable values of the pseudo-labelled samples in set
. The selection indicator
determined for the operational state
(
) at the iteration step
can be calculated as:
(6)
(6) where
represents the size of set
at the iteration step
. The Equation (6) is used to ensure that equal number of top reliable pseudo-labelled samples is selected for each class. Based on the selection indicators of all the classes, the selection indicator
used for set
is generated as:
(7)
(7) where
is the logic OR operator between sets. For example,
. As iteration step
increases, a enlarging factor
is determined to enlarge the size of
as:
(8)
(8) where
is a predetermined parameter used to control the speed of enlarging the size of set
during iterations. The influence of parameter
on the performance of SSDL will be analysed in detail in the experimental section. Obviously, the Equation (8) guarantees the dynamic sampling required by the GEM strategy.
4. Procedure of the proposed SSDL for machinery fault diagnosis
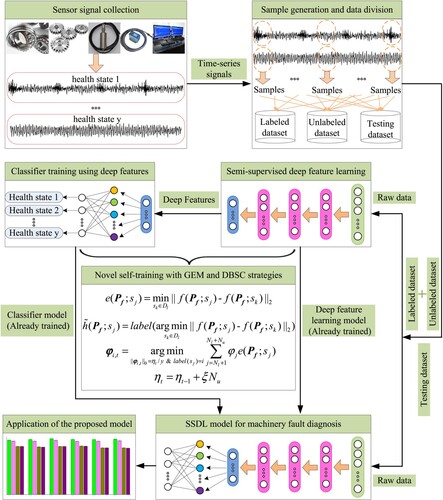
Based on all the components introduced above, the flowchart of constructing SSDL model for machinery fault diagnosis is shown in Figure and its general procedure is described as bellow.
Step 1: Collect sensor signals (e.g. acceleration, attitude) of mechanical equipment in different health states;
Step 2: Employ window slicing technique on the time-series signals to generate samples;
Step 3: For the samples of each health state, randomly select few samples into the labelled dataset
, randomly select abundant samples with removed state labels into the unlabelled dataset
Step 4: Initialise a set
Step 5: If
Step 6: Select the set of pseudo-labelled candidates
Step 7: Generate the enlarged training dataset
Step 8: Train the SSAE-Softmax model
Step 9: Obtain the diagnostic performance
Step 10: If
Step 11: Save the best diagnostic performance
Step 12: Obtain the pseudo-labels of all samples in
Step 13:
Step 14: Update the selection indicator
Step 15: Enlarge the sampling number
Step 16: Output
Figure 3. Flowchart of constructing SSDL model for machinery fault diagnosis.
5. Experiments and discussion
5.1 Experimental data preparation
To evaluate the performance and robustness of the proposed SSDL, two experimental cases related to the fault diagnosis of a benchmark bearing and a delta 3-D printer were prepared. The experimental data of bearing faults was downloaded from the Case Western Reserve University Bearing Data Center (Citationn.d.), which is a benchmark dataset that widely used in this field. The experimental data of the delta 3-D printer faults was acquired from a test-rig constructed by our research group.
5.1.1 Benchmark bearing data
The main components of the test-rig used for collecting bearing data include a 2-hp motor, a torque transducer, a dynamometer, and control electronics. Single-point faults with diameters of 7, 14, and 21 mils were separately seeded on the test bearings at different locations including the inner raceway (IR), ball (BA), 3 o’clock of outer raceway (OR-3), 6 o’clock of outer raceway (OR-6), and 12 o’clock of outer raceway (OR-12), respectively. Vibration data was collected using an accelerometer with the sampling frequency of 12 kHz for motor speed set to 1797 RPM. In this study, four datasets shown in Table are set up, including different fault locations (L) and different fault diameters (D). In a dataset, each operational state (O) contains 300 samples, and each sample is a collected vibration signal segment including 400 sampling data points. Note that the notation ‘N’ in the column L denotes the normal state. For each state O, 10 samples are randomly selected as the labelled dataset for training, 150 samples with removed operational state labels are randomly selected as the unlabelled dataset for training, and the remaining 140 are used for testing.
Table 1. Description of the four datasets for bearing fault diagnosis.
5.1.2 Delta 3-D printer data
As shown in Figure (a), the test-rig constructed by our group for the fault diagnosis of 3-D printers consists of a delta 3-D printer, an attitude sensor, and a laptop. Considering that the faults of mechanical transmission can be reflected by the attitude of the moving platform, as shown in Figure (b), one attitude sensor was installed on the moving platform of 3-D printer to collect attitude data under different operational states. The attitude sensor is a three-dimensional motion attitude measurement system, which can obtain 12-channel signals including 3-channel angular velocity signals, 3-channel vibratory acceleration ones, 3-channel magnetic field intensity ones and 3-channel attitude angle ones. Note that a low-cost attitude sensor (BWT901) was used in the experiments, which is beneficial to verify the performance of the algorithm because the noise of data will be increased. There are three synchronous belts (denoted from SB-1 to SB-3) and 12 joint bearings (denoted from JB-1 to JB-12) in the delta 3-D printer. Different fault states were simulated by relaxing the length of teeth of each synchronous belt by three teeth (4.5 mm). In addition, the screw (0.700 mm pitch) of each joint bearing was loosened a 0.25-turn to simulate 0.175 mm clearance. Figure (c)-(d) shows the normal state and fault state of a synchronous belt and a joint bearing, respectively. As shown in Table , four datasets are formed by combining different states. In a dataset, each state O contains 720 samples, and each sample is a collected 12-channel signal segment including 45 sampling data points. For each state O, 10 samples are randomly selected as the labelled dataset for training, 300 samples with removed operational state labels are randomly selected as the unlabelled dataset for training, and the remaining 410 are used for testing.
Figure 4. Experimental data preparation for delta 3-D printer: (a) test-rig; (b) installed attitude sensor; (c) normal and fault state of a synchronous belt; and (d) normal and fault state of a joint bearing screw.

Table 2. Description of the four datasets for 3-D printer fault diagnosis.
5.2 Hyper-parameter analysis
Two hyper-parameters (i.e. the network architecture of SSAE-Softmax model, which is denoted as na, and the enlarging factor ) were analysed because they have a great impact on the performance of the proposed SSDL. Taking the dataset BD-1 as an example, the diagnosis accuracies of SSDL under different hyper-parameter combinations are described in Table . Note that the network architecture of SSAE-Softmax is denoted as the number of hidden layers and the number of neurons in each hidden layer. For example, the na = [50-50-50] in Table implies that the model has three hidden layers and each hidden layer has 50 neurons. The other hyper-parameters including the batch size, iterations, and learning rate for the training algorithm of SSAE-Softmax model were set as 10, 100, and 0.5, respectively, in the following experiments. All the SSDLs under different hyper-parameter combinations were run independently five times on dataset BD-1 to reduce the effect of randomness. Therefore, the average diagnosis accuracies (avg) and the standard deviations (std) are also reported in Table .
Table 3. Diagnosis accuracies of SSDL under different combinations of network architecture and enlarging factor.
Table 4. Hyper-parameter settings for all the approaches on bearing datasets.
Table 5. Hyper-parameter settings for all the approaches on 3-D printer datasets.
The following conclusions can be inferred from the results. On the one hand, under the same architecture, the performance of the SSDL is generally not good enough when the value of is large (e.g.
= 1/3 or
= 1/5). This is because that a large
will urge
to increase rapidly and unreliable pseudo-labelled data may be sampled to train the classifier at each step. On the other hand, at the same level of
, it can be seen that the performance of the SSDL was not improved monotonously with the increase of the number of hidden layers and the number of neurons in each hidden layer. Therefore, to make the SSDL have better performance, the fitting ability of the SSAE-Softmax model cannot be too strong or too weak.
5.3 Algorithm performance analysis
Compared with existing self-training semi-supervised learning approaches, GEM and DBSC strategies are two main improvements in the proposed SSDL. Therefore, in this subsection, the performance of these two strategies are analysed first. As stated before, most existing self-training semi-supervised learning approaches adopt a static sampling strategy that selecting pseudo-labelled samples into the enlarged training dataset when their prediction confidences larger than a fixed threshold (Fan et al. Citation2018; Ye et al. Citation2017). Therefore, the first contrastive approach was selected as the SSDL where the sampling strategy GEM was replaced by this static sampling strategy (denoted as SSDL-SS). As shown in Section 4, the termination condition of the iterative learning of SSDL is when the sampling size is greater than
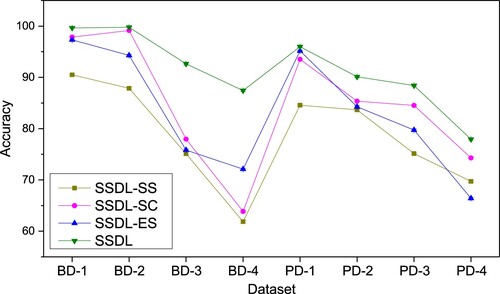
. However, due to the static sampling strategy employed in SSDL-SS, a predetermined number of iterations (denoted as iter) is adopted as the termination criterion for the iterative learning of SSDL-SS. The second contrastive approach was defined as the SSDL where the sampling criterion DBSC was replaced by the widely used one (Dong et al. Citation2017; Fan et al. Citation2017) that the prediction accuracy of classifier was employed directly as the confidence estimation for pseudo-labels (denoted as SSDL-SC). It means that the pseudo-labels of samples were assigned as the predicted labels of the classifier directly in SSDL-SC. Recall that an equilibrium strategy is used in GEM to guarantee that an equal number of pseudo-labelled samples is selected for each class at each iteration. Therefore, to analyse its effectiveness, the third contrastive approach was defined as the SSDL where the equilibrium strategy was not adopted in GEM (denoted as SSDL-ES). Note that the static sampling strategy used in SSDL-SS also implies that the pseudo-labels of unlabelled samples are predicted by the classifier directly, and the equilibrium strategy is not employed in SSDL-SS either.
Considering the influence of hyper-parameter settings on the prediction accuracy, for fair comparison, different hyper-parameter combinations were tested first to achieve the optimal hyper-parameter setting, as shown in and , for all the above contrastive approaches on each dataset. The comparative results of five trials on the bearing testing datasets and 3-D printer testing datasets are described in Figure . From these results, one can find that the performance of the proposed SSDL are much better than that of SSDL-SS, SSDL-SC, and SSDL-ES, which demonstrates the effectiveness of the strategies designed in SSDL for semi-supervised learning.
Figure 5. The prediction accuracies obtained by all the algorithms on each testing dataset.
Although the labels of samples in the unlabelled dataset are removed and cannot be used in the training process, they can be used to calculate the following two metrics, namely the prediction accuracy of the model on the unlabelled dataset Du (denoted as Accu) and the accuracy of the selected pseudo-labelled candidates in set (denoted as Accs), at each iteration to observe the performance improvement of the model during the iterative learning process:
(9)
(9)
(10)
(10) where the right_predicted_labels denotes the number of samples in set Du whose labels are predicted right by the SSAE-Softmax classifier, the right_pseudo-labels denotes the number of samples in set
whose pseudo labels are consistent with their true labels,
and
denote the size of Du and
, respectively.
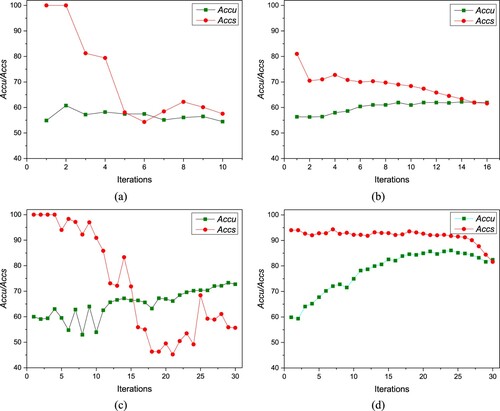
Owing to space constraints, as shown in Figures and , we only show the iterative Accu and Accs values of the SSDL-SS, SSDL-SC, SSDL-ES and SSDL on the BD-1 and BD-4 datasets. We can find that the Accs value drops a lot in the iterative learning process of SSDL-SS, which means that the pseudo labels of most of the candidates in set at the later iterations are incorrect. This is the reason why the Accu value of SSDL-SS stagnates in the iterative learning process and the poor performance of SSDL-SS achieved on the testing datasets. There are two possible reasons for the degradation of Accs value of SSDL-SS. The first one is that the pseudo-labels predicted by the classifier are not reliable sometimes. This phenomenon can also be found by observing the Accs value of SSDL-SC on the dataset BD-4. The second one is that the equilibrium strategy is not adopted. Without using the equilibrium strategy, sample imbalance (i.e. the number of samples of different categories varies greatly) may occur in the enlarged training dataset
. This is not good for training a high performance classifier. This phenomenon can also be found by observing Accs and Accu values of SSDL-ES both on the datasets BD-1 and BD-4.
Figure 6. The iterative Accu and Accs values of the contrastive approaches on the BD-1: (a) SSDL-SS; (b) SSDL-SC; (c) SSDL-ES; and (d) SSDL.
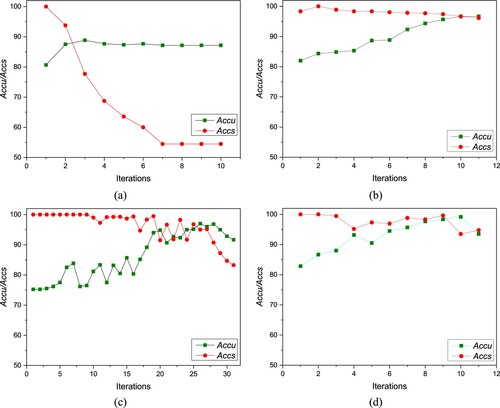
Figure 7. The iterative Accu and Accs values of the contrastive approaches on the BD-4: (a) SSDL-SS; (b) SSDL-SC; (c) SSDL-ES; and (d) SSDL.
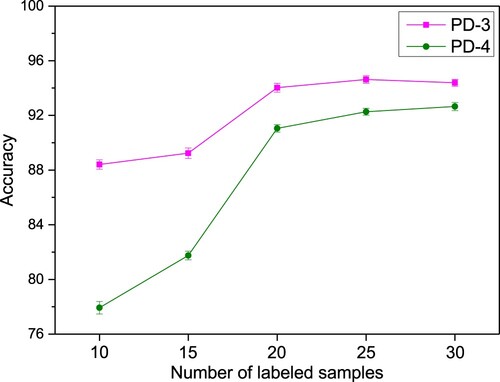
In addition to the above performance analysis of each improved strategy of SSDL, the effect of the size of the labelled dataset on the performance of the proposed SSDL is also analysed. Taking datasets PD-3 and PD-4 as examples, recall that only about 3.2% of the samples in these training datasets are labelled (10 labelled samples and 300 unlabelled samples). Figure shows the prediction accuracies of SSDL when the number of labelled samples is 10, 15, 20, 25 and 30, respectively. It can be clearly seen that the diagnostic accuracy of SSDL has been greatly improved with the increase of labelled samples, and satisfying performance can still be achieved at a relatively low ratio of labelled samples.
Figure 8. The prediction accuracies obtained by SSDL under different number of labelled samples on datasets PD-3 and PD-4.
5.4 Comparisons with the state-of-the-art
In order to further study the performance of the proposed SSDL, several state-of-the-art semi-supervised learning approaches including mixmatch (Berthelot et al. Citation2019), mean teachers (MT for short) (Tarvainen and Valpola Citation2017), and learning to impute (LTI for short) (Li, Foo, and Bilen Citation2020) were employed for comparison. SSAE-based deep deep neural networks are always adopted as the backbone architecture for competitive fault diagnosis models (Shao et al. Citation2018). Therefore, besides the above three semi-supervised learning approaches, two baseline models trained in supervised learning fashion, denoted as BFS and BSU, were also constructed and used for comparison. BFS denotes that we only take the labelled dataset to train a SSAE-Softmax classifier without exploiting the unlabelled dataset
, while BSU means that all the samples in
and
are labelled and used to train a SSAE-Softmax classifier.
The average diagnosis accuracy and standard deviations obtained by each approach in five independent repeated experiments are depicted in Table . From this table, we can observe that the proposed SSDL can obtain higher average diagnosis accuracy than the other three state-of-the-art semi-supervised learning approaches (i.e. mixmatch, MT and LTI) on each dataset. The overall average diagnosis accuracy obtained by SSDL is 91.49%. It is better than that of the LTI, mixmatch and MT, whose overall average diagnosis accuracy is 89.44%, 88.40% and 86.91%, respectively. The experimental results demonstrate the superiority of the proposed SSDL for machinery fault diagnosis.
Table 6. Comprehensive comparison of diagnosis accuracy.
Through comparing the results of SSDL with that of BFS, one can find that the prediction accuracy of the model can be greatly improved by exploiting the unlabelled dataset. Specifically, the proposed SSDL achieves about 8.9–28.0 points improvements over the BFS on all the testing datasets. With respect to the comparison between the results of SSDL and BSU, it can be seen that the performance of SSDL is close to that of the totally supervised learning on most datasets (e.g. BD-1, BD-2, BD-3, PD-1, and PD-2), proving the high effectiveness of the proposed SSDL for fault diagnosis with few labelled samples. However, for some complicated datasets (e.g. BD-4, PD-3 and PD-4), there is still a big gap between SSDL and BSU. Therefore, continuously improve the performance of SSDL in dealing with large and complex data is the direction of our future study.
6. Conclusions
A large number of labelled samples are always required by most of existing data-driven fault diagnosis approaches designed under supervised learning frameworks. However, labeling large number of samples to different operational states is always time-consuming and costly, sometimes even impossible, for machinery fault diagnosis. To solve this problem, a novel self-training semi-supervised deep learning (SSDL) approach is proposed in this paper. The SSDL approach adopts a gradually exploiting mechanism (GEM) to start with few reliable unlabelled samples and gradually increasing its quantity for model updating. Moreover, a distance-based sampling criterion (DBSC) is presented to remarkably improve the performance of label estimation. The influence of hyper-parameters on the performance of the proposed SSDL is analysed in the experiments. The superiority of the present SSDL in dealing with fault diagnosis problems with few labelled and abundant unlabelled samples is also demonstrated by comparing with other state-of-the-art semi-supervised learning approaches. There are in general three contributions for the addressed work: (1) we propose the GEM strategy for semi-supervised self-training to better exploit the unlabelled samples; (2) we design the DBSC for label estimation to remarkably improve the performance of pseudo-labelled sample selection in the iterative learning process; and (3) an integrated SSDL based on the GEM and DBSC is proposed for dealing with the machinery fault diagnosis with few labelled data. In the future studies, the proposed SSDL will be explored to extend its application for other fault diagnosis problems considering more realistic situations, such as variable working condition and unknown abnormality identification.
Acknowledgments
The valuable comments and suggestions from the editors and the anonymous reviewers are very much appreciated.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors

Jianyu Long
Jianyu Long received the B.E. degree and the Ph.D. degree in Metallurgical Engineering from Chongqing University, Chongqing, China, in 2012 and 2017, respectively. He is currently an associate professor with the School of Mechanical Engineering, Dongguan University of Technology, Dongguan, China. His research interests include machine learning, prognostics and system health management.

Yibin Chen
Yibin Chen received the B.E. degree in Traffic Engineering from Wuyi University, Jiangmen, China. He is currently working toward the Master degree with the College of Mechatronics and Control Engineering, Shenzhen University, Shenzhen, China. His research interests include fault diagnosis and few shot learning.

Zhe Yang
Zhe Yang received the B.E. degree in Measurement and Control and Instrument, the M.Sc. degree in Mechanical Engineering from Xi’an Jiaotong University, Xi’an, China, in 2012 and 2015, respectively, and the Ph.D. degree in Mechanical Engineering from Politecnico di Milano, Milan, Italy, in 2020. He is currently a Postdoctoral Fellow with the Dongguan University of Technology, Dongguan, China. His research interests include the development of methods for prognostics and system health management.

Yunwei Huang
Yunwei Huang received the B.E. degree and the Ph.D. degree in Metallurgical Engineering from Chongqing University, Chongqing, China, in 2013 and 2020, respectively. He is currently a Postdoctoral Fellow with the Dongguan University of Technology, Dongguan, China. His research interests include few shot learning and artificial intelligence.

Chuan Li
Chuan Li received his Ph.D. degree from the Chongqing University, China, in 2007. He has been successively a Postdoctoral Fellow with the University of Ottawa, Canada, a Research Professor with the Korea University, South Korea, and a Senior Research Associate with the City University of Hong Kong, China. He is currently a Professor with the School of Mechanical Engineering, Dongguan University of Technology, Dongguan, China. His research interests include prognostics & health management, and intelligent systems.
References
- Agrawala, A. K. 1970. “Learning with a Probabilistic Teacher.” IEEE Transactions on Information Theory 16: 373–379.
- Artigao, E., A. Honrubia-Escribano, and E. Gomez-Lazaro. 2020. “In-Service Wind Turbine DFIG Diagnosis Using Current Signature Analysis.” IEEE Transactions on Industrial Electronics 67: 2262–2271.
- Belkin, M., P. Niyogi, and V. Sindhwani. 2006. “Manifold Regularization: A Geometric Framework for Learning from Labeled and Unlabeled Examples.” Journal of Machine Learning Research 7: 2399–2434.
- Bennett, K. P., and A. Demiriz. 1999. “Semi-supervised Support Vector Machines.” Proceedings of the Neural Information Processing Systems, 368–374.
- Berthelot, D., N. Carlini, I. Goodfellow, N. Papernot, A. Oliver, and C. Raffel . 2019. MixMatch: A holistic approach to semi-supervised learning: arXiv:1905.02249.
- Blum, A., and T. M. Mitchell. 1998. “Combining Labeled and Unlabeled Data with co-Training.” Proceedings of the Eleventh Annual Conference on Computational Learning Theory, 92–100.
- Case Western Reserve University. n.d. Bearing Data Center. https://csegroups.case.edu/bearingdatacenter/home.
- Dong, X., D. Meng, F. Ma, and Y. Yang. 2017. “A Dual-Network Progressive Approach to Weakly Supervised Object Detection.” Proceedings of the ACM International Conference on Multimedia, 279–287.
- Fan, H., X. Chang, D. Cheng, Y. Yang, D. Xu, and A. G. Hauptmann. 2017. “Complex Event Detection by Identifying Reliable Shots from Untrimmed Videos.” Proceedings of the IEEE International Conference on Computer Vision, 736–744.
- Fan, H., L. Zheng, C. Yan, and Y. Yang . 2018. “Unsupervised Person re-Identification: Clustering and Fine-Tuning.” Acm Transactions on Multimedia Computing Communications and Applications 83: 1–18.
- Gao, Z., C. Cecati, and S. X. Ding. 2015a. “A Survey of Fault Diagnosis and Fault-Tolerant Techniques-Part i: Fault Diagnosis with Model-Based and Signal-Based Approaches.” IEEE Transactions on Industrial Electronics 62: 3757–3767.
- Gao, Z., C. Cecati, and S. X. Ding. 2015b. “A Survey of Fault Diagnosis and Fault-Tolerant Techniques-Part ii: Fault Diagnosis with Knowledge-Based and Hybrid/Active Approaches.” IEEE Transactions on Industrial Electronics 62: 3768–3774.
- Hanachi, H., J. Liu, I. Y. Kim, and C. K. Mechefske. 2019. “Hybrid Sequential Fault Estimation for Multi-Mode Diagnosis of gas Turbine Engines.” Mechanical Systems and Signal Processing 115: 255–268.
- Hu, Y., P. Baraldi, F. Di Maio, and E. Zio. 2017. “A Systematic Semi-Supervised Self-Adaptable Fault Diagnostics Approach in an Evolving Environment.” Mechanical Systems and Signal Processing 88: 413–427.
- Jeong, I. J., V. J. Leon, and J. R. Villalobos. 2007. “Integrated Decision-Support System for Diagnosis, Maintenance Planning, and Scheduling of Manufacturing Systems.” International Journal of Production Research 45: 267–285.
- Lee, J., B. Park, and C. Lee. 2020. “Fault Diagnosis Based on the Quantification of the Fault Features in a Rotary Machine.” Applied Soft Computing 97: 106726.
- Lei, Y., B. Yang, X. Jiang, F. Jia, N. Li, and A. K. Nandi. 2020. “Applications of Machine Learning to Machine Fault Diagnosis: A Review and Roadmap.” Mechanical Systems and Signal Processing 138: 106587.
- Li, W., C. Foo, and H. Bilen . 2020. Learning to impute: a general framework for semi-supervised learning: arXiv:1912.10364.
- Long, J., J. Mou, L. Zhang, S. Zhang, and C. Li. 2021. “Attitude Data-Based Deep Hybrid Learning Architecture for Intelligent Fault Diagnosis of Multi-Joint Industrial Robots.” Journal of Manufacturing Systems 61: 736–745.
- Long, J. Y., Z. Z. Sun, C. Li, Y. Hong, Y. Bai, and S. H. Zhang. 2020a. “A Novel Sparse Echo Autoencoder Network for Data-Driven Fault Diagnosis of Delta 3-D Printers.” IEEE Transactions on Instrumentation and Measurement 69: 683–692.
- Long, J. Y., S. H. Zhang, and C. Li. 2020b. “Evolving Deep Echo State Networks for Intelligent Fault Diagnosis.” IEEE Transactions on Industrial Informatics 16: 4928–4937.
- Majdouline, I., S. Dellagi, L. Mifdal, E. M. Kibbou, and A. Moufki. 2021. “Integrated Production-Maintenance Strategy Considering Quality Constraints in dry Machining.” International Journal of Production Research,. Early Access.
- Nigam, K., A. McCallum, S. Thrun, and T. M. Mitchell. 2000. “Text Classification from Labeled and Unlabeled Documents Using EM.” Machine Learning 39: 103–134.
- Potocnik, P., and E. Govekar. 2017. “Semi-supervised Vibration-Based Classification and Condition Monitoring of Compressors.” Mechanical Systems and Signal Processing 93: 51–65.
- Razavi-Far, R., E. Hallaji, M. Farajzadeh-Zanjani, M. Saif, S. H. Kia, H. Henao, and G.-A. Capolino. 2019. “Information Fusion and Semi-Supervised Deep Learning Scheme for Diagnosing Gear Faults in Induction Machine Systems.” IEEE Transactions on Industrial Electronics 66: 6331–6342.
- Rosenberg, C., M. Hebert, and H. Schneiderman. 2005. Semi-supervised self-training of object detection models, the 7th IEEE Workshop on Applications of Computer Vision: 29-36.
- Rumelhart, D. E., G. E. Hinton, and R. J. Williams. 1986. “Learning Representations by Back-Propagating Errors.” Nature 323: 533–536.
- Shao, H. D., H. K. Jiang, Y. Lin, and X. Q. Li. 2018. “A Novel Method for Intelligent Fault Diagnosis of Rolling Bearings Using Ensemble Deep Auto-Encoders.” Mechanical Systems and Signal Processing 102: 278–297.
- Shao, H. D., J. Lin, L. W. Zhang, D. Galar, and U. Kumar. 2021a. “A Novel Approach of Multisensory Fusion to Collaborative Fault Diagnosis in Maintenance.” Information Fusion 74: 65–76.
- Shao, H., M. Xia, G. Han, Y. Zhang, and J. Wan. 2021b. “Intelligent Fault Diagnosis of Rotor-Bearing System Under Varying Working Conditions with Modified Transfer Convolutional Neural Network and Thermal Images.” IEEE Transactions on Industrial Informatics 17: 3488–3496.
- Tarvainen, A., and H. Valpola. 2017. “Mean Teachers are Better Role Models: Weight-Averaged Consistency Targets Improve Semi-Supervised Deep Learning Results.” Proceedings of the Neural Information Processing Systems, 1195–1204.
- Wang, Z., Q. Liu, H. Chen, and X. Chu. 2021. “A Deformable CNN-DLSTM Based Transfer Learning Method for Fault Diagnosis of Rolling Bearing Under Multiple Working Conditions.” International Journal of Production Research 59: 4811–4825.
- Yang, W., L. Chen, and S. Dauzere-Peres. 2021a. “A Dynamic Optimisation Approach for a Single Machine Scheduling Problem with Machine Conditions and Maintenance Decisions.” International Journal of Production Research,. Early Access.
- Yang, X., Z. Song, I. King, and Z. Xu. 2021b. A survey on deep semi-supervised learning: arXiv:2103.00550.
- Ye, M., A. J. Ma, L. Zheng, J. Li, and P. C. Yuen. 2017. “Dynamic Label Graph Matching for Unsupervised Video re-Identification.” Proceedings of the IEEE International Conference on Computer Vision, 5152–5160.
- Zhang, Y. Y., X. Y. Li, L. Gao, W. Chen, and P. G. Li. 2020. “Ensemble Deep Contractive Auto-Encoders for Intelligent Fault Diagnosis of Machines Under Noisy Environment.” Knowledge-Based Systems 196: 105764.
- Zhang, C., J. Yu, and S. Wang. 2021. “Fault Detection and Recognition of Multivariate Process Based on Feature Learning of one-Dimensional Convolutional Neural Network and Stacked Denoised Autoencoder.” International Journal of Production Research 59: 2426–2449.
- Zhao, X., M. Jia, J. Bin, T. Wang, and Z. Liu. 2020a. “Multiple-Order Graphical Deep Extreme Learning Machine for Unsupervised Fault Diagnosis of Rolling Bearing.” IEEE Transactions on Instrumentation and Measurement 70: 3506012.
- Zhao, X., M. Jia, and Z. Liu. 2021a. “Semisupervised Graph Convolution Deep Belief Network for Fault Diagnosis of Electormechanical System with Limited Labeled Data.” IEEE Transactions on Industrial Informatics 17: 5450–5460.
- Zhao, B., X. Zhang, Z. Zhan, and Q. Wu. 2021b. “Deep Multi-Scale Adversarial Network with Attention: A Novel Domain Adaptation Method for Intelligent Fault Diagnosis.” Journal of Manufacturing Systems 59: 565–576.
- Zhao, M., S. Zhong, X. Fu, B. Tang, and M. Pecht. 2020b. “Deep Residual Shrinkage Networks for Fault Diagnosis.” IEEE Transactions on Industrial Informatics 16: 4681–4690.
- Zheng, J., H. Wang, Z. Song, and Z. Ge. 2019. “Ensemble Semi-Supervised Fisher Discriminant Analysis Model for Fault Classification in Industrial Processes.” ISA Transactions 92: 109–117.