
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This paper studies the multi-item stochastic capacitated lot-sizing problem with stationary demand to minimise set-up, holding, and backorder costs. This is a common problem in the industry, concerning both inventory management and production planning. We study the applicability of the Proximal Policy Optimisation (PPO) algorithm in this problem, which is a type of Deep Reinforcement Learning (DRL). The problem is modelled as a Markov Decision Process (MDP), which can be solved to optimality in small problem instances by using Dynamic Programming. In these settings, we show that the performance of PPO approaches the optimal solution. For larger problem instances with an increasing number of products, solving to optimality is intractable, and we demonstrate that the PPO solution outperforms the benchmark solution. Several adjustments to the standard PPO algorithm are implemented to make it more scalable to larger problem instances. We show the linear growth in computation time for the algorithm, and present a method for explaining the outcomes of the algorithm. We suggest future research directions that could improve the scalability and explainability of the PPO algorithm.
1. Introduction
Over the past decades, many digital technologies have been developed, enabling the storage and sharing of data and information. In companies, digital transformations allow adjusting business processes. The traditionally linear supply chain is becoming an integrated supply network. The integration of business processes that used to be siloed raises new questions for companies. Two typical business processes in supply chain management are production planning and inventory management, being two essential processes in delivering high-quality service to customers. In production planning, utilising the economies of scale to reduce costs might be beneficial; in inventory management, avoiding excess inventory and its costs is an important goal. Combining these seemingly conflicting objectives of production planning and inventory management is studied in the lot sizing domain. The primary purpose is to find policies that minimise the costs of production set-ups and holding inventory. Once typical real-life situations are included in the problem, such as stochastic demand, backorder or penalty costs, and service level or lead time targets, the problem becomes more complicated. While in single item inventory systems with stationary demand policies are typically used, these systems often do not consider a limited production capacity. When considering multiple products that need to be manufactured on a shared capacitated resource, this problem becomes more complex and is NP-hard (Karimi, Ghomi, and Wilson Citation2003). However, these complicating factors are often encountered in practice, for example, in the consumer goods, manufacturing, and process industry. Furthermore, previous studies on this topic focus on optimising the problem for a certain number of periods, while in practice we see a motivation for steady-state replenishment policies. Jans and Degraeve (Citation2008) argue that integrating these industrial concerns in lot sizing models warrants more research as it introduces new modelling challenges, and they conclude that more complex algorithms are needed to solve these models.
Utilising the increased availability of data, machine learning and data analytics techniques advanced enormously. Reinforcement learning offers many opportunities for solving complex sequential decision-making problems (Sutton and Barto Citation2018). In settings with uncertainty and changing environments, traditional solution methods that require a pre-determined model are often inadequate, but reinforcement learning methods overcome this obstacle through simulation and approximation. The value of reinforcement learning in several supply chain management problems was studied on several occasions (Giannoccaro and Pontrandolfo Citation2002; Chaharsooghi, Heydari, and Hessameddin Zegordi Citation2008; Kwon et al. Citation2008; Jiang and Sheng Citation2009; Kara and Dogan Citation2018). With the recent advances in deep learning (Goodfellow, Bengio, and Courville Citation2016), a combination of deep learning and reinforcement learning, called deep reinforcement learning (DRL) (Mnih et al. Citation2013), showed tremendous potential in solving complex combinatorial optimisation problems with large state spaces. A variety of issues in supply chain management, such as the joint replenishment problem (Vanvuchelen, Gijsbrechts, and Boute Citation2020), dual sourcing (Gijsbrechts et al. Citation2021), and scheduling (Rummukainen and Nurminen Citation2019) are solved by using deep reinforcement learning. This demonstrates that there are opportunities for this novel approach to lot sizing problems.
In addition to having the techniques available to find smart solutions to lot sizing problems, an important aspect for implementing such techniques in practice is by including these solutions in Decision Support Systems. In many companies, some type of automated replenishment software is utilised which gives recommendations on the preferred replenishment quantities, given the optimisation of some objective. Donselaar et al. (Citation2010) argue that planners in companies would generally follow these recommendations if they have trust in the quality of the system and if they are aligned with the objectives. Heuillet, Couthouis, and Díaz-Rodríguez (Citation2021) state that DRL algorithms suffer from a lack of explainability which can hinder the acceptance by users. Thus, to enable effective use in practice, an investigation is needed into the explainability of DRL results.
This paper applies DRL to the stochastic capacitated lot-sizing problem (S-CLSP) with stationary demand to specify near-optimal replenishment and production policies. We consider a problem with multiple products, limited capacity, set-up times, and stochastic demand that is fully backordered in case of shortage. The costs that are relevant in this case are set-up costs, holding costs, and backorder costs. We model the problem as a Markov Decision Process (MDP) and solve it using the Proximal Policy Optimisation (PPO) method, a DRL type. Solving the S-CLSP and applying this general-purpose method to practical problems comes with three main challenges. Addressing these challenges is the main contribution of this paper.
First, solving the S-CLSP using exact methods introduces several constraints and assumptions to the problem. As a result, it is challenging to solve the problem for heterogeneous products or when there are non-linear production constraints. By modelling the S-CLSP as an MDP and applying an approximate technique, we can extend the problem domain to include practical problem settings. In these settings, we focus on finding steady-state policies and demonstrate that better solutions are found using this DRL methodology than those seen with other available methods.
Second, when applying the DRL method, ensuring that the algorithm can accommodate the problem-specific requirements is essential. In this study, the algorithm should be able to deal with the capacity constraints and larger problem sizes. To ensure that this is the case, we adapt this general-purpose method to the S-CLSP by using feasibility masks to cope with capacity constraints. Additionally, Boute et al. (Citation2021) stress that implementing the PPO algorithm for large action spaces is quite challenging. This typically occurs in problems where simultaneous decisions are made. In our problem, simultaneous replenishment decisions for all products are needed. We adopt information about the characteristics of the optimal solution in small problem instances in the modelling of the state and action space, allowing the use of this DRL method in larger problem instances.
Finally, DRL methods are often criticised as ‘black box’ methods because of the use of Deep Neural Networks, leading to a lack of insights into the resulting solution (Heuillet, Couthouis, and Díaz-Rodríguez Citation2021). This lack of understanding may limit the applicability in practice. To overcome this hurdle, we illustrate how this solution's outcomes can be interpreted such that the resulting policy can be explained.
This paper is structured as follows. In Section 2, literature research is provided on solution methods in lot sizing and DRL applications. Section 3 introduces the studied S-CLSP. In Section 4, the methodology and PPO algorithm are described. The set-up of the experiments and their results are described in Section 5. The discussion and conclusion are presented in Section 6.
2. Literature review
2.1. A review of stochastic capacitated lot sizing
The literature on lot sizing considers the integration of production planning and inventory management. This topic has been studied for over a century, starting with the economic order quantity (EOQ) model proposed by Ford Whitman Harris in 1913 (Erlenkotter Citation1989). Where in inventory management the aim is to achieve a certain service level while holding as little inventory as possible, production planning aims at producing as efficiently as possible. This could result in conflicting outcomes, such as large batch sizes and thus large inventories, or small batch sizes and low inventories, a trade-off that (Graves Citation1988) already highlighted.
In problem settings with stochastic demand, inventory management approaches typically concern managing safety stocks (Graves and Willems Citation2000). The common sequential practice of determining the safety stocks, and then basing replenishment orders on this quantity received some discussion in the literature. Safety stocks are often placed to buffer against uncertainty in demand over replenishment cycles, meaning the time between two production periods, showing that production planning impacts inventory management. Simultaneously, the safety stock levels affect production quantities, indicating how inventory management impacts production planning (Tavaghof-Gigloo and Minner Citation2020). Tempelmeier (Citation2013) states that it is not possible to separate the inventory that is a result of the demand variability from the inventory that is a result of the capacity restrictions, and concludes that ‘using the safety stock as a decision variable does not make much sense’ (p. 32) in a dynamic planning situation. Since the production and inventory areas are highly interrelated, approaching this problem in an integrated manner should provide benefits, underscoring the relevance of lot sizing.
In lot sizing literature, the objective is to determine the timing and quantity of production that minimises the set-up, production, and holding costs, in essence combining the production planning and inventory management objectives. This problem typically occurs in make-to-stock (MTS) settings, as opposed to make-to-order (MTO) settings, where production only starts after the order has been placed. When a problem has set-up times that are dependent on the production sequence, this is referred to as a lot scheduling problem. We are interested in studying the lot sizing problem in a situation with multiple items, sequence-independent set-up times, stationary stochastic demand, and a shared capacitated production resource (S-CLSP).
Karimi, Ghomi, and Wilson (Citation2003) see the integration of stochasticity, backlogging, set-up times and set-up carryovers as an important future research direction for the CLSP, underscoring the relevance of our interest in the S-CLSP. At the same time, they see potential in the use of new solution methods to solve these NP-hard problems. When stochasticity is included in the problem setting, it is important to consider what strategy to use for handling uncertainty. Bookbinder and Tan (Citation1988) identify three strategies. First, there is the static strategy, where a production plan (timing and order sizes) must be determined at the beginning of the time horizon, without revision when more information becomes available. Second, there is the dynamic strategy, where every period a new production decision is made for that period, using the most recent information (e.g. demand observations). This is consistent with inventory literature, where the replenishment decision is made either continuously or periodically based on the most recent information (Axsäter Citation1993). Both the timing and size of the replenishment orders are thus determined in a dynamic fashion, namely at the beginning of every period, rather than in advance for some fixed time horizon. Third, there is the static-dynamic strategy which determines the production moments at the beginning of the time horizon, but the respective lot sizes are determined dynamically in each period. One could also use a rolling horizon approach, where a finite multi-period model is optimised, but implemented only for the first x periods, after which the optimisation is revisited (Baker Citation1977).
Tempelmeier (Citation2013) analyses three types of heuristics (ABC heuristic, column generation, and fix-and-optimise) that are used for solving the static uncertainty strategy version of the S-CLSP, all for a fixed time horizon of the problem. Helber, Sahling, and Schimmelpfeng (Citation2013) apply the fix-and-optimise heuristic to the S-CLSP with the static-dynamic uncertainty strategy. The authors focus on creating a specific schedule for a fixed time horizon rather than a general production policy for the case of stochastic demand and limited capacity. Several studies have been conducted to find production schedules for fixed time horizons with various types of service level constraints, and a variety of approaches (Tempelmeier Citation2011; Tempelmeier and Hilger Citation2015; De Smet et al. Citation2020; Tavaghof-Gigloo and Minner Citation2020). A gap in the literature can be found here, as Winands, Adan, and van Houtum (Citation2011) stress the importance of having a general policy (rather than a specific fixed period schedule) that informs the decision-maker about how to dynamically distribute capacity among products. This gap is addressed in this paper by investigating general policies for infinite time horizons. The interested reader is referred to Karimi, Ghomi, and Wilson (Citation2003) and Winands, Adan, and van Houtum (Citation2011) for a thorough review on capacitated and stochastic lot sizing.
This research paper focuses on the use of the dynamic uncertainty strategy in the S-CLSP. To the best of our knowledge, the dynamic uncertainty strategy is not studied in relation to stochastic capacitated lot sizing. Bookbinder and Tan (Citation1988) state that this strategy would lead to increased nervousness in the production system and thus do not recommend using this in practice. However, it seems very similar to periodic review policies that are typically followed in inventory management. The emphasis of companies on their supply chain flexibility and agility (Lee Citation2004) is an additional motivation for our investigation of the dynamic uncertainty strategy, regardless of the increased nervousness. The policy is known to be optimal when assumptions of stationary demand, full backlogging, and long-run average cost criterion hold (Federgruen and Zipkin Citation1984). In this policy, a replenishment order is generated to bring the inventory position to level S when the inventory position falls below s. This policy is generated for each product individually and does not consider resource constraints or set-up costs. Especially in multi-item settings, the interaction of ordering multiple products that are supplied by a constrained production resources presents additional questions, such as how to prioritise the orders. DeCroix and Arreola-Risa (Citation1998) address the issue of having multiple products. For the case of having homogeneous products, they characterise the optimal policy. For the case of heterogeneous products, they propose a heuristic. Nevertheless, set-up costs are ignored in this heuristic, which could result in very high production costs. We analyse how we can address the issue of prioritising in a multi-product setting while considering set-up costs and a dynamic uncertainty strategy.
Mula et al. (Citation2006) say that it is appropriate to model this sequential decision-making problem as a Markov Decision Process (MDP) and solve it using a stochastic dynamic program. However, solving large-scale MDPs suffers from the curse of dimensionality (Powell Citation2007). Increasing computation times as the problem size grows are also encountered by Helber, Sahling, and Schimmelpfeng (Citation2013), Tempelmeier and Hilger (Citation2015), and Tavaghof-Gigloo and Minner (Citation2020). Especially industrial lot sizing problems are large and have various practical production constraints that make them difficult to solve in an exact manner (Jans and Degraeve Citation2008). Therefore, we look into an approximate technique, namely DRL.
Where previous papers have focused on solving the S-CLSP with static and static-dynamic strategies, our paper addresses the gap in the literature around the S-CLSP with a dynamic uncertainty strategy by applying a DRL method to find a well-performing steady-state inventory and production policy. Furthermore, rather than focusing on a service-level constraint that has to be satisfied, we consider a cost of not being able to satisfy demand directly from stock.
2.2. Reinforcement learning in supply chain management
Reinforcement learning (RL) is about learning what to do to maximise a reward, but the agent is not explicitly told which action to perform in each state (Sutton and Barto Citation2018). Instead, the agent observes the state at time t and chooses an action
to take. The agent balances exploring new actions and exploiting the knowledge of the environment. Using the information about the reward of the action and the new state, the agent updates the knowledge of the environment. For more background on RL, the reader is referred to Sutton and Barto (Citation2018).
Giannoccaro and Pontrandolfo (Citation2002) already address the potential of RL to solve ‘a wider range of cases than conventional methods’ (p. 160). They show that policies found for an integrated inventory problem using the SMART algorithm perform better than benchmarks. The authors attribute the success of the resulting policy to the fact that it is more sophisticated than a simplistic policy, as it changes the decision based on additional variables (such as global inventory position). The explicit consideration of the stochastic nature of the environment with RL is another success factor, as it goes beyond ‘coping with uncertainty through a safety stock’ (p. 160). This SMART algorithm is similar to Q-learning, where the update of the action values is based on the estimate of the optimal future value (Sutton and Barto Citation2018). Pontrandolfo et al. (Citation2002) find similar successes of RL when applying it to a networked production system, and emphasise that using simulation makes it easy to solve a wide range of problems. The applicability of RL (specifically Q-learning) in uncertain settings is supported by Chaharsooghi, Heydari, and Hessameddin Zegordi (Citation2008) who apply the method to the beer distribution game, showing a better performance than existing heuristics. Kim et al. (Citation2005), Kwon et al. (Citation2008) and Jiang and Sheng (Citation2009) additionally found that RL is applicable in non-stationary uncertain environments, where it outperforms other methods. Wang, Li, and Zhu (Citation2012) find that while RL outperforms current heuristics, there is a limitation on the interpretability of the solutions for practitioners. Paternina-Arboleda and Das (Citation2005) counter the ‘black box’ critique that RL solutions are not interpretable. By using a decision tree to interpret the resulting RL policy, the authors illustrate the suitability of this method for practitioners. Additionally, the fact that an explicit model is not required for learning makes it especially useful in practice, as many real-life constraints can be included and no impractical assumptions have to be made (Gosavi, Ozkaya, and Kahraman Citation2007; Kara and Dogan Citation2018).
All the noted studies conclude that more research is needed to investigate how RL can be applied to more complicated problems with larger state spaces. In these studies, the state space is discrete, meaning that when the problem becomes more complex, the number of states in the state space increases exponentially. One area of investigation is called ‘case-based’ RL, where the state space is discretised, and each case represents a region that was visited previously (Kwon et al. Citation2008). Cases are dynamically appended to the state space if it is not in the region of a previously visited case. However, with this approach, the state space remains discrete. Besides the disadvantage of an increasing state space, this also results in limited generalisation capabilities in the learning algorithm, because the similarity between states is not shown by the discrete states (Sutton and Barto Citation2018). When looking at a problem with a large state space, an approach is needed where we can generalise the learnings of experience on a subset of the state space to similar states that were not visited in the learning process. The research avenue that addresses this problem looks into using approximations for the policies or value functions. Function approximations are a type of supervised learning. This can range from rather simple methods such as linear regression to more advanced methods like artificial neural networks. Early adopters of function approximation in RL are Paternina-Arboleda and Das (Citation2005), who add the least mean-square approximation to the SMART algorithm to approximate the reinforcement value function. This enables an increase in the state space by using multiple state dimensions as features. They apply this method in a stochastic lot scheduling problem. The reader is referred to Sutton and Barto (Citation2018) for a description of the various types of approximation functions that can be used in RL. We focus our literature review on the use of deep neural networks for approximation and its applications and challenges in supply chain management problems.
Sutton and Barto (Citation2018) describe that applying neural networks in RL settings creates issues that were not present in ‘regular’ supervised learning. Due to using RL, the targets used for training are nonstationary, and the sequence of observations used for training are highly correlated. Both issues can result in unstable or diverging Q-values in the training process. Mnih et al. (Citation2015) introduce the value-based method of Deep Q-Networks (DQN), which use target networks and experience replay memory to decorrelate the observations and improve the sample efficiency. Oroojlooyjadid et al. (Citation2017) apply this method to the beer game, which is essentially a decentralised partially observable MDP. They state that DQN allowed them to keep all the relevant state information in the problem, and their study is a proof of concept that DQN can be useful in real-life applications. Nevertheless, they see the need for more research focusing on the computational efforts of the algorithm, as in their case, the hyper-parameter tuning process was very time-consuming (∼28.5 million seconds). They managed to reduce the computation time for hyper-parameter tuning with transfer learning (to ∼1.5 million seconds), but further improvements are needed.
Kool, van Hoof, and Welling (Citation2019) find that using policy-gradient DRL methods works more effectively than using value-based methods. An additional benefit of policy-gradient methods is that they are more suitable in continuous action spaces, allowing for better scalability. With policy-gradient methods, the policy is directly parameterised. The weights of the neural network are updated by a form of gradient descent, where the objective is to minimise the loss function. The loss function indicates how well the policy is performing. Kool, van Hoof, and Welling (Citation2019) use the REINFORCE method with a baseline in routing problems to reduce the variance of the estimates. With reduced hyper-parameter tuning, the method shows good performance compared to benchmarks. However, even if REINFORCE has good theoretical convergence properties, it has a weak sample complexity (Vanvuchelen, Gijsbrechts, and Boute Citation2020). The REINFORCE method is essentially a Monte Carlo policy gradient method that uses the total trajectory reward to compute the gradient. Gijsbrechts et al. (Citation2021) employ the A3C algorithm (Mnih et al. Citation2016), a combination of policy- and value-based DRL, where the value estimate is used as a baseline for the policy gradient method. The A3C method showed excellent performance, enabling actions to prevent overfitting. Yet, the hyper-parameter tuning process resulted in very high computational expenses (∼260 million CPU seconds).
Schulman et al. (Citation2017) proposed the PPO algorithm, designed to be more scalable, data-efficient, and robust (in terms of parameter tuning) than other algorithms. The PPO algorithm alternates between sampling from the policy and performing several updates to the neural network. PPO can be used in an actor-critic way. To avoid destructively large policy updates, the loss function that is used for the gradients is clipped, so that the updates do not move out of the ‘trust-region’ of the policy. This is similar to the Trust Region Policy Optimisation (TRPO) method (Schulman et al. Citation2015), but PPO is less complicated as it only changes the loss function. Furthermore, PPO appears to have a set of hyper-parameters for which it performs well in a variety of settings, indicating good robustness. Vanvuchelen, Gijsbrechts, and Boute (Citation2020) applied the PPO problem in the Joint Replenishment Problem, showing very good performance and outperforming heuristics. Rummukainen and Nurminen (Citation2019) apply PPO to the lot scheduling problem and also conclude that PPO is a promising method for solving sequential decision-making problems. Park et al. (Citation2021) apply PPO to the job-shop scheduling problems and find promising results as well. Based on the motivation and findings of these studies, we conclude that the PPO method seems to be applicable in the case of the S-CLSP.
3. Problem statement
In the S-CLSP problem, a manufacturing facility produces K products on one production system (machine). The machine has a limited production capacity. Each product has a batch size, and the capacity of the machine is specified in the number of batches that can be produced in a period. Set-ups are carried over from one period to the next, meaning that if the last product is produced again in the next period, no additional set-up is required. The production quantity must be feasible given the limited capacity (Equation1(1)
(1) ). Demand follows a discrete stationary stochastic distribution. The overall objective is to minimise the expected costs due to set-ups, inventory, and backorders (Equation3
(3)
(3) ).
The index set is defined by
and
. Since we are looking for a steady-state policy, we are interested in the long-term costs, and consider
.
The decision variables are
| = | Production quantity (in number of batches) for product i in period t | |
| = | Inventory position of product i at the beginning of period t | |
| = | On hand inventory of product i at the beginning of period t | |
| = | Backorders that occurred for product i as a result of the demand in period t−1 | |
| = | Set-up carryover state variable; | |
| = | Set-up state variable; | |
| = | Ratio of inventory position after production to average demand of product i in period t |
The parameters are
| CAP>0 | = | Production capacity in the number of batches that can be produced |
| = | Set-up time for product i in the number of batches | |
| = | Batch size of product i | |
| = | Set-up cost for product i | |
| = | Holding cost per period for product i | |
| = | Backorder cost for product i | |
| = | Demand for product i in period t |
3.1. Sequence of events
At the beginning of each period t, the production quantities are determined. The production quantity is immediately produced that period and must satisfy capacity constraints (Equation1
(1)
(1) ):
(1)
(1) Demand
is observed at the end of the period and satisfied if possible. We assume unmet demand is backordered (Equation2
(2)
(2) ).
(2)
(2) Costs are incurred at the end of each period (Equation3
(3)
(3) ). For every unit of inventory (
) that is carried over to the next period, a holding cost
is incurred. For every backorder that occurred (
), there is a backorder cost
. The negative inventory position is considered as backorders, meaning that if a backorder cannot be fulfilled in the next period, it is considered again as a backorder. If a product is produced, set-up costs
are incurred if a set-up was needed (Equation4
(4)
(4) ):
(3)
(3)
(4)
(4) The product that is set up in the beginning of the period is always produced first, and we assume that the product with the lowest inventory position (after production) to demand ratio (Equation5
(5)
(5) ) is produced last, such that any following period may take advantage of the set-up carryover. This logic is presented in (Equation6
(6)
(6) ). We choose to implement
in this way to reduce the action space (Equation8
(8)
(8) ), rather than considering the production sequence as a decision variable:
(5)
(5)
(6)
(6)
3.2. Markov decision process
We model the S-CLSP as a Markov Decision Process (MDP). At each time step, the process is in some state , and the decision-maker chooses any action
that is feasible (given capacity constraints) in that state. At the next time step, the process moves randomly (because of demand stochasticity) into new state
, giving a cost
. The probability of moving into the new state is given by the state transition function
. The transition is independent of all previous states and actions, meaning that it satisfies the Markov property.
The state of the system is used to determine the action
to take. Multi-dimensional state space (Equation7
(7)
(7) ) contains the observations of the inventory positions
of the products and set-up carryover indicators
.
(7)
(7) Action (Equation8
(8)
(8) ) consists of the production quantities
for all products. The action space is discrete and it consists of the possible combinations of
given the capacity constraints. In Section 4.2, we describe how we ensure the feasibility of the actions in case of set-up times, as this is related to the
variable in the state space:
(8)
(8) The objective of the MDP is to find a policy
which minimises the costs (similar to maximising the long-term rewards). A policy constitutes a mapping from states to actions. The value function
indicates the value of beginning in state
and following policy
. The value function is the expected value of the cumulative costs of period t onwards following policy
(Equation9
(9)
(9) ), with
being the discount factor that is used to determine the present value of the costs:
(9)
(9) For MDPs, the optimal policy
can be found by solving the recursive Bellman Optimality Equations (Equation10
(10)
(10) ) (Bellman Citation1954):
(10)
(10) The Bellman Optimality Equation is a system of equations, one for each state. In principle, this system of equations could be solved exactly if the dynamics of the system are known. However, for larger problems, this becomes computationally very expensive and we have to resort to methods of approximately solving the Bellman optimality equations. DRL is one of such methods, and in the next section, we elaborate on how we used the PPO algorithm to solve this problem.
4. Proximal policy optimisation approach
A high-level description of the PPO algorithm is shown in Algorithm 1. We use the actor-critic structure as described by Schulman et al. (Citation2017). The policy is represented by a neural network with parameters θ, also known as the actor network . Another neural network with parameters ϕ is used to estimate the value function when following the policy of the actor, called the critic network
. The values of the parameters in the neural networks are updated by the algorithm while training. The updates from the old to the new policy are clipped, as this avoids large differences in the policy, and results in relatively stable training behaviour (Schulman et al. Citation2017). To provide samples to train the neural network, a buffer is filled with training data of states, actions, and rewards that are gotten when rolling out the current policy of the actor network. These training data are used to compute the loss functions required for updating the network weights. In applying this PPO algorithm, multiple updates are performed with the same training data.

In this paper, the ‘standard’ PPO algorithm as described by Schulman et al. (Citation2017) was implemented, with several modifications to make it suitable for S-CLSP. The main modifications are using a feasibility mask, scaling the states and rewards, and using knowledge of the optimal solution for small problem instances to reduce the action space (Section 4.2).
4.1. Neural network architecture
Fully connected feed-forward neural networks are used (similar to the work by Schulman et al. Citation2017) consisting of two hidden layers with a width of 256 nodes, using a hyperbolic tangent (tanh) activation function. For problem instances with , 2 hidden layers with a width of 512 nodes were used. The dimension of the first layer (i.e. input layer) is the same as the dimension of the state space (
), and the dimension of the last layer in the actor network (i.e. output layer) is the same as the dimension of the action space (
). The critic network is set up in the same way as the actor network, except for the last layer, which just has one dimension and outputs an estimate of the value function. This architecture is illustrated in Figure .
Figure 1. Illustration of neural network architecture.
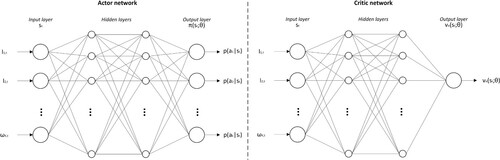
For initialising the neural network, the method described by Glorot and Bengio (Citation2010) is used to initialise the parameters. Glorot-Uniform initialisation is used for the weights, and the bias is initialised at 0. This method is suggested by them to ensure that gradients can propagate well through the network and results in faster convergence.
4.2. Adjusting state and action spaces
To ensure that the neural network and its hyperbolic tangent activation function respond well to the state input, the values of our state space are scaled such that they are in the interval . We set
at 15 times the average demand rate
(Equation11
(11)
(11) ). When the optimal policy is found for small problem instances, it is unlikely to result in inventory levels that exceed this limit. Therefore, setting this limit is also a good way of narrowing down the potential state space, to ensure that the algorithm encounters primarily states that are reasonable in the exploration phase:
(11)
(11) This inventory and backorder limit was also implemented in inventory transition function (Equation12
(12)
(12) ). Note that we expect less backorders than inventory, so the backorder limit is half of the inventory limit:
(12)
(12) We apply the PPO algorithm with a discrete action space. This means that the actor can choose any action in the feasible set. The feasible set consists of all the feasible combinations of
, given the production capacity. This means that as the number of products or the capacity limit increases, the number of feasible combinations and thus the size of the action space increases dramatically, which comes with a decrease in algorithm performance and an increase in computational costs. For this reason, the problem was modelled with a batch size
, which reduces the dimensions of the action space.
4.2.1. Action reduction
Even with the use of batch sizes in the model, the list of all feasible actions is still very large, while it is very unlikely that all of the actions will be desirable. Using knowledge about the characteristics of the optimal solution for small problem instances allows us to reduce the action space for larger instances. By solving the problem to optimality for three products, it was observed that typically not all products were produced in one period, even if the inventory levels were low. Additionally, the produced quantities were never larger than the EOQ values. Therefore, we only considered actions that had a maximum number of products () produced in one period, and the production quantity was not allowed to be greater than the number of batches required to produce the EOQ plus one batch of slack. The determination of
and EOQ is described in the appendix.
4.2.2. Eligibility and feasibility masks
From the optimal solution, we know that in certain states, some actions will never be chosen (we call them ineligible), and some actions are infeasible due to set-up times. The PPO algorithm could benefit from avoiding to explore these actions, as they are not beneficial in achieving low costs. We hid those actions with an eligibility mask. To ensure that the policy consists of eligible actions (i.e. a probability distribution with zero probability for ineligible actions), the eligibility mask uses a soft-max activation function over the eligible actions. In the case that a product was not set up at the beginning of period t, and its inventory position was above a threshold
, that product would not be eligible for production in period t.
Moreover, given the set-up carryover variable , some actions in
could be infeasible due to the required set-up times. The determination of feasibility is made based on
and
, such that all actions satisfy capacity constraint (Equation1
(1)
(1) ). The feasibility masks work in the same way as the eligibility mask. This feasibility and eligibility mask is computed every time the MDP is in a new state, so this augmentation to the standard PPO algorithm comes at an additional computation cost (see Section 5.4).
4.3. Collecting training samples
In each training iteration, training data is collected by gathering a sample from the current policy of actor , starting in a state with no inventory and a random product set up. By following the current policy and drawing random demand, we generate this sample. This policy is simulated for a trajectory of
periods to approximate the infinite horizon MDP (Tang and Abbeel Citation2010) and the state, action and scaled reward are stored for each period in the (training) buffer. The rewards are normalised before use in further calculations to ensure that scale of the rewards is similar to that of the state input features, which secures that the difference in scale does not inhibit learning. Additionally, the probability distribution over all actions, made by
, is stored for each state that is visited, as well as the value predictions of each visited state, made by
. For training the networks, a truncated buffer (m) of 256 periods of the trajectory is used.
4.4. Computing advantages
Before the weights can be updated, the advantage of taking a certain action rather than another needs to be calculated, such that the policy is updated in a direction that increases the chances of taking better actions. To do so, we use the generalised advantage estimation method (Schulman et al. Citation2016). This method is proposed as a way of estimating the gradient that significantly reduces variance and has a tolerable level of bias, increasing the effectiveness of learning with policy gradient techniques. Advantage function (Equation13(13)
(13) ) measures whether or not an action
performs better than the policy's default behaviour
:
(13)
(13) Generalised advantage estimator (Equation14
(14)
(14) ) is the exponentially weighted average of the k-step estimators (Equation15
(15)
(15) ) that estimate the advantage of the actions (Equation16
(16)
(16) ) for k-steps ahead, with decay parameter λ. The calculated advantages are normalised before being used for the updates:
(14)
(14)
(15)
(15)
(16)
(16) We set γ and λ to the values that are found to work well in the PPO algorithm (Schulman et al. Citation2017):
and
.
4.5. Updating the network weights
To update the weights of θ and ϕ, mini-batch gradient descent is applied, using the Adam optimiser (Kingma and Ba Citation2014) with learning rates , which was found to work well (Schulman et al. Citation2017). With mini-batch gradient descent, the sample is split into batches, and an average gradient is calculated for each batch. A batch size of 64 is used, meaning that, with our truncated buffer size of 256, there are 4 batches. In addition, the training data is used 10 times (called epochs), meaning that in total the networks are updated 40 times in each training iteration. The data is shuffled in each batch to decorrelate the updates and avoid overfitting (Mnih et al. Citation2013).
For each update two loss functions are computed, for
and
for
. For actor loss (Equation17
(17)
(17) ), the mean loss of all the sample points in the batch is used, based on the calculated advantages, as well as the ratio of the updated policy to the old policy. Buşoniu et al. (Citation2018) mention that because of the non-linear nature of neural networks, a change to the policy ‘can quickly change the distribution of the state visited by the updated policy away from the on-policy distribution for which the update was valid’ (p. 20). Therefore, the changes in the policy distribution should be kept small, which in PPO is done by clipping the objective function (Schulman et al. Citation2017). The ratio of the updated policy to the old policy (Equation18
(18)
(18) ) is clipped to the range of
to ensure that the update to the policy network is not too large, which results in a more stable training behaviour:
(17)
(17)
(18)
(18) Typically as the training procedure progresses, the entropy of the policy decreases (i.e. the actions become less random). To encourage the exploration of actions, which is desirable in the case of having large action spaces, we add an entropy bonus to the policy loss function (Mnih et al. Citation2016). This entropy bonus is composed of an entropy coefficient
multiplied with the average Shannon entropy S (Citation1948) of an episode buffer.
The value loss is defined as the mean-squared error (Equation19(19)
(19) ), where the predictions of the critic network are compared with the real observations of the cost
for the sample point that occurred at time t:
(19)
(19)
is defined as the sum of the discounted costs until the end of the buffer trajectory and the discounted infinite horizon cost after the end of trajectory (Equation20
(20)
(20) ). Since the infinite horizon cost after the end of the trajectory is not known, this is approximated by the value function in the last period of the trajectory:
(20)
(20) Considering that the actor and critic networks do not share weights, combining the policy and value loss is not necessary.
4.6. Training procedure
Every 100 iterations, we evaluate the performance of the current policy by simulating it n = 5 times for 1000 time periods, removing a warm-up period of length 10. Based on this, the 95% confidence interval of the mean costs per period is calculated (Equation21(21)
(21) ), using the mean (
) and the standard deviation (
) of the costs of the n replications:
(21)
(21) To stop the training procedure, two criteria that indicate convergence have to be met. The first criterion is that the average performance in the evaluation periods has not improved (i.e. average performance does not exceed highest upper bound) for 10 consecutive evaluation periods. If the performance of the current policy is very unstable, the confidence interval (and thus upper bound) may become very wide. To avoid early stopping as a result of this wide interval, we clip the upper bound:
. The second criterion is that the entropy of the actor is low enough, meaning that the policy is not that random anymore. Even though the output of the actor is a stochastic policy, we know that the policy will converge to a somewhat deterministic policy. To ensure that the algorithm has arrived at a fairly deterministic policy, we consider that if the entropy is below 20% of the maximum entropy, the entropy is low enough. If these two criteria have not been met after 10,000 training iterations, the training procedure is stopped.
An overview of the PPO algorithm hyper-parameters used in the implementation can be found in Table . Experimentation on the hyper-parameters confirmed the suitability of the parameters found by Schulman et al. (Citation2017).
Table 1. PPO hyperparameters.
5. Results
Experiments are carried out to examine the applicability of the PPO algorithm to the S-CLSP. The applicability consists of three elements: (1) performance, (2) scalability, and (3) explainability. Simulation studies are conducted with various problem settings to show the performance and scalability of the PPO algorithm. The performance of the learned inventory policy by the PPO algorithm is compared to the optimal policy (whenever possible) and a heuristic policy (Section 5.1). Throughout this section, we use the term ‘solution’ to represent the results of a policy in the simulation study.
To test the quality of the PPO algorithm, experiments are conducted with three different set of experiments. In each of these sets, we generate problem instances with different problem parameters (details of the set-up in Section 5.2, results in Section 5.3). The scalability of the PPO algorithm is studied by examining the relationship between the computation time and the problem size (Section 5.4). Finally, a multiple linear regression analysis is done to explore the PPO algorithm's explainability (Section 5.5).
5.1. Benchmark heuristic policy
To evaluate the performance of the PPO algorithm in larger problem settings, it must be compared to a benchmark. Unfortunately, no generic policy exists in the literature that incorporates both stochastic demand and a limited production capacity in an infinite horizon. In cases with unlimited capacity, the products are looked at in isolation. However, when there is limited production capacity available, the individual product replenishment decisions may conflict with each other, resulting in infeasible production schedules and excessive backorders. Therefore, some mechanism is needed to prioritise the different production decisions. When stochasticity is ignored in a capacitated system, a fixed replenishment cycle is used. In such a setting, inventory may deplete faster than expected due to demand uncertainty, also resulting in backorders. A more flexible mechanism is needed to react to demand realisations.
We present the aggregate modified base-stock heuristic (AMBS) as a way of dealing with stochastic demand and limited production capacity in an infinite horizon. It is a simulation-based heuristic, where we optimise the parameters for the backorder threshold (), holding cost threshold (
) and set-up threshold (
) using grid-search. In every period, the products are ranked in descending order of the expected backorder costs (given the current inventory levels). If this expected backorder cost is above some threshold
, a batch of this product is produced. This logic is continued until capacity runs out in a period, or if all products are below this threshold. In problem instances where we have a set-up time, there is an additional requirement that only
new set-ups are allowed in a period, which ensures that capacity is mainly used for production, rather than set-ups. If there is capacity left, and all products are below the backorder threshold, additional production batches are decided for the products that are set up in that period. The product that is produced last is determined based on the lowest inventory to EOQ ratio (as we make sure that we can continue producing this product in the next period). For the other products that are set up, we rank them in ascending order of their inventory level to the EOQ quantity ratio. If we can produce a batch of a product without exceeding the holding cost threshold
, we will produce this batch. This holding cost threshold ensures that the capacities are not exhausted as much as possible, as this could result in too much inventory build-up. Detailed notation can be found in the appendix.
Experimentation shows that our AMBS heuristic outperforms the lot size-reorder point policy as presented by Nahmias and Olsen (Citation2015b) by
. This
-policy is presented as optimal for a situation with stochastic demand and unlimited capacity under continuous review .Footnote1 However, in case of limited capacity, deciding the production quantities on an aggregate level, taking into consideration the inventories of all the products, provides benefits. Furthermore, the AMBS heuristic performs only 10% worse than the optimal solution to a deterministic demand problem with limited production capacity (based on assumptions of having sequence-independent set-up times and a rotational cycle policy) as presented by Nahmias and Olsen (Citation2015a). The average optimality gap between the AMBS heuristic and the optimal policy is 8.77% (more on the optimal policy in Section 5.3).
5.2. Experimental set-up
In the first set of experiments, problem instances were generated for each combination of the number of products (K), demand variability (COV) and capacity factor (cf), as shown in Table . Demand follows a discrete uniform distribution, similar to Vanvuchelen, Gijsbrechts, and Boute (Citation2020). Following Tempelmeier (Citation2011), we also investigate different levels of the coefficient of variation (COV). In settings with a high COV = 0.58, the demand follows the distribution , where a low COV = 0.14 has the distribution
. We vary the capacity available for production based on parameters that Tempelmeier (Citation2011) used for creating low (cf = 1.1) and medium (cf = 1.5) capacity scenarios. Based on the average demand
, batch sizes
and capacity factor cf, CAP for a problem instance is computed (Equation22
(22)
(22) ). All products in this set are identical in terms of demand distribution and cost settings. In this set, the backorder costs, set-up costs, batch sizes and set-up times are fixed as shown in Table .
(22)
(22) In the second set of experiments, problem instances are generated for a combination of different numbers of products K, backorder costs
, set-up costs
, as well as for a heterogeneous set of products in terms of demand and cost settings. Details on the experiments with heterogeneous products are shown in Table . We base the settings for the backorder costs on the experiments by Tempelmeier (Citation2011), who considers different fill rate (
) constraints. Rather than a service level constraint, we determine costs for backorders such that the PPO algorithm takes this into consideration when learning to minimise the costs. In our problem statement, we consider a gamma service level (which also considers waiting time for backorders) rather than a fill rate (Tempelmeier Citation2006). We consider service level targets of 90% and 98%. To transform this target service level to backorder costs (Equation23
(23)
(23) ), we use the idea of the critical ratio of the newsvendor model (Arrow, Harris, and Marschak Citation1951) to determine the ratio of holding cost to backorder costs, where we have holding costs
in all experiments. This results in
for a low service target and
for a high service target. Even though (Equation23
(23)
(23) ) is based on fill rate as a service measure, we also consider it appropriate for the gamma service level as our experiments show that the gamma service level (average 91.3% for set 1) and fill rate (average 92.8% for set 1) are very similar as ‘repeated’ backorders are unlikely. To determine the set-up costs, we use different values of
of 5 and 10 periods (Equation24
(24)
(24) ) as used by Tempelmeier (Citation2011). When varying the demand of the products, we have half of the products with a low mean demand
and the other half of the products have a high mean demand
. In this set, the coefficient of variation, capacity, batch sizes and set-up times are fixed.
(23)
(23)
(24)
(24)
Table 2. Experimental settings.
In the last set of experiments, problem instances are generated for a combination of different numbers of products K, set-up costs , set-up times
and batch sizes
. The set-up costs are determined using the
(Equation24
(24)
(24) ). The set-up times are based on experiments run by Brandimarte (Citation2006), who use a set-up time factor sf that indicates the fraction of capacity that would be lost if all products would be set up in one period. They use the factors 0.3 and 0.5, and we allocate this time required for set-ups evenly over all products (Equation25
(25)
(25) ). We varied the batch sizes from small (
, i.e. no batch size) to large batch sizes (
, 2.5 times the period demand). In this set, the coefficient of variation, capacity, the mean demand, and the backorder costs are fixed.
(25)
(25)
Considering there is some randomness involved when training the neural networks using the PPO algorithm (e.g. initialising, filling the buffer, sampling from the buffer), we replicate the training in each experiment three times to analyse the robustness of the algorithm, setting a different random seed for each replication. This means we have three trained actor neural networks per experiment setting. The final performance of the PPO algorithm is determined by 10 simulation runs for 10,000 periods, where the first 1000 periods are discarded (warm-up periods). For each experiment setting, all three neural networks and the AMBS heuristic encounter the same demand realisations in the simulation runs. We report the best and average PPO solution for each experimental setting.
5.3. Experiment results
In this section, we discuss the results of the various set of experiments. We report the improvement compared to the AMBS heuristic in terms of costs. In the appendix, extended tables are presented that also show the difference to the AMBS heuristic for the average inventory levels, backorders, set-ups and lot sizes .Footnote2
Only the problem instances with K = 2 products were computationally tractable to solve to optimality .Footnote3 Value iteration, a type of Dynamic Programming was used to find the optimal solution. On average, a small optimality gap of 5.24% was found, and the gap is even smaller for the best-performing PPO replications. The gap was lower for low variability and medium capacity settings (see Table ).
Table 3. Optimality gaps of best PPO performance (a) and average PPO performance (b) for K = 2 products in %.
5.3.1. Set of Experiments 1
In Table , the differences between the AMBS heuristic and best PPO solution are shown for the first set of experiments. We observe that the PPO solution outperforms the benchmark on average with 7% lower costs, and even 8% when we look at the best performing replication. In situations with medium capacity and lower variability of demand, this improvement is larger. The main explanation for this improvement is a lower average inventory level and a lower number of set-ups required for the PPO solution, against an increase in the number of backorders, visualised in Figure . Because less set-ups are required, the lot sizes are larger as production occurs less frequently. The PPO algorithm specifically looks to find a balance between all different cost components, and it appears to work better at doing so than the AMBS heuristic. Interestingly, we find that the PPO algorithm results in an average gamma service level of 91.3%, which is close to the target of 90%, whereas the AMBS heuristic reaches 95.1%, exceeding the target considerably.
Figure 2. Illustration of (a) average product inventory costs, (b) average product backorder costs and (c) average product set-up costs for the PPO (best replication) and AMBS solutions.
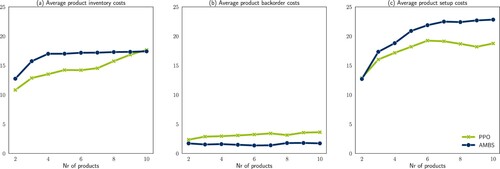
Table 4. Results for experiment set 1 showing the difference in average period costs between the best PPO performance (a), average PPO performance (b) and the AMBS heuristic in %. The size of the action space for the different problem instances is also shown (c).
Table 5. Experimental settings set 2 and results showing the difference in average period costs between the best PPO replication (a) and average of the PPO replications (b) and the AMBS heuristic in %.
From Table , we also see that there is a relationship between the size of the action space and the improvement found by the PPO solution. For larger action spaces, the gap with the benchmark starts to decrease. The PPO algorithm is based on exploring the different states and action spaces. When the action space is too large, sufficient exploration becomes more challenging, resulting in lower performance.
5.3.1.1 Impact of state and action space modifications
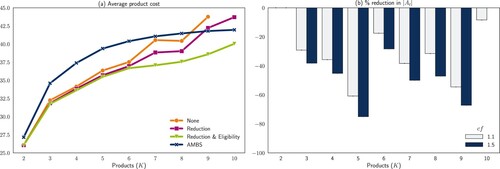
In our application of the PPO algorithm, we dealt with the large action space by applying knowledge about the characteristics of the optimal solution of small problem instances to model a ‘smart’ action space (as explained in Section 4.2), as well as adapting the size of the neural networks. Figure shows the impact of the action reduction (Section 4.2.1) and eligibility masks (Section 4.2.2). Note that in the instance with K = 10 and cf = 1.5, the PPO algorithm without modifications was not able to run as the necessary neural network exceeded the computer memory size. As a result, these observations are missing from Figure . Observe that both the action reduction and eligibility mask modifications of the PPO algorithm were necessary to enable it to outperform the AMBS heuristic in larger problem instances. Figure also indicates that using some knowledge about the characteristics of the optimal solution of small problem instances substantially reduces the action space. However, this modification alone is not enough to improve the performance of the PPO algorithm. This combination of action reduction and eligibility masks is needed to avoid the algorithm getting stuck in parts of the action space that will not provide good solutions. Nevertheless, the eligibility mask modifications come at an additional computation cost (Section 5.4).
Figure 3. The impact of state and action space modifications on (a) the average product costs in the best PPO replications and (b) the size of the action space.
We suggest future research to investigate more methods to cope with large action spaces, such as initialising the PPO algorithm with a smart policy, changing some PPO algorithm parameters based on the size of the problem, encouraging more exploration in training the network, modelling the actions in a continuous space rather than discrete, or using an action elimination framework (Zahavy et al. Citation2018).
5.3.2. Set of Experiments 2
In Table , the differences between the AMBS heuristic and best and average PPO solution are shown for the second set of experiments. We observe that on average the PPO solutions outperform the benchmark with 3.65% for situations with four products. Similar to experiment set 1, we see the performance of the PPO algorithm decreasing as the number of products (and thus action space) increases. Especially in settings with a high , the PPO solution performs better. The AMBS heuristic is mainly focused on producing a product when it exceeds some backorder cost threshold, while the PPO solution considers the total costs. Also for problem instances with heterogeneous products (in terms of costs and demand levels), PPO outperforms the AMBS. The AMBS does consider the item-specific backorder costs, but then does not consider the item-specific set-up costs in the decision to start production. Furthermore, we find that in experiments with heterogeneous products in terms of costs, related to having product-specific service level targets, the PPO algorithm is better at reaching differentiated service level targets and prioritising the high-service products than the AMBS heuristic. In situations with low
and high
, the AMBS heuristic performs slightly better than PPO. Generally, PPO results in lower inventory and higher backorders than AMBS, meaning that higher
leads to worse results. We suspect that this is a result of the fact that backorders are occurring much less frequently than the set-ups. The PPO algorithm learns a lot from all the events that are encountered, and if backorders are underrepresented in the events, this could inhibit the impact the PPO algorithm attributes to having backorders. Future research could focus on how to improve the ability to learn from rare events, for instance, by increasing their occurrence during the training iterations.
5.3.3. Set of Experiments 3
In Table , the differences between the AMBS heuristic and best PPO solution are shown for the third set of experiments. Here we see again the impact of the large action spaces on the performance of the PPO algorithm. Specifically, we see that for situations with 6 and 8 products, a minimum batch size is needed to start training, as otherwise the action space would be infeasible in terms of memory size. Nevertheless, the PPO algorithm generally manages to outperform the AMBS heuristic, with bigger improvements in the case of a high . With a low
, the PPO algorithm requires less set-ups, resulting in lower costs. With a high
, the PPO solution has a sharp decrease in inventory and set-ups, resulting in higher backorders. Nevertheless, overall the PPO solution still finds lower costs than AMBS.Footnote4
Table 6. Results for experiment set 3 showing the difference in average period costs between the best (a) and average (b) PPO performance and the AMBS heuristic in %. The size of the action space (c) for the different problem instances is also shown.
The batch size was mainly implemented to effectively reduce the size of the action space. We observe that this measure was an effective way of finding improvements on the AMBS heuristic. Additionally, we see no increase in average cost for the PPO algorithm due to the reduced granularity in the action space with these current settings. One would expect that this batch size implementation would only decrease the performance of the AMBS heuristic, because for the heuristic a batch size is not necessary. Nevertheless, we found that even for the AMBS heuristic, a batch size of size 2 (costs: 115.00) or 4 (costs: 114.88) performs slightly better than no batch size (costs: 115.45). Even though the inventory increases somewhat, this is offset by a reduced number of backorders. However, for the AMBS heuristic, the large batch size showed to be ineffective in finding the right policy. With an increase in the batch size, the number of batches that can be produced in a period decreases dramatically (given the utilisation rate constraint). With a large batch size, the problem essentially changes from determining the best production quantity to a choice of allocating the scarce batch production slots to the different products. Therefore, we consider the implementation of the batch size effective, but note that the reduction in granularity should be reasonable.
5.4. Computation times
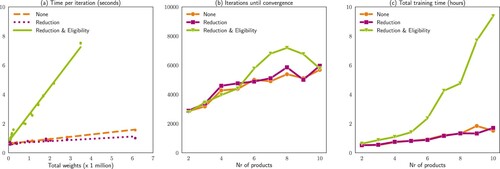
The total training time of the PPO algorithm is composed of the number of iterations required to converge during training, as well as the time needed to compute one iteration. Figure shows the results of these components, as well as the impact of the state and action space modifications that were implemented in the PPO algorithm. The experiments are run on an Intel Xeon Gold 6130 Processor with 16 cores.
Figure 4. Illustration of (a) time per iteration in seconds, based on the weights of the actor and critic network, (b) the average number of iterations needed to converge in the PPO algorithm, based on the number of products in the experiment and demand variability and (c) the total training time until convergence in hours.
Our analysis showed that the time required for one iteration is mainly based on the number of weights in the actor and critic networks for a problem instance. In one training iteration, the training buffer is filled, the advantage and gradient are computed and the network weights are updated. The number of weights in the actor network is dependent on the input vector (state space ), number and size of hidden layers (
) and the output vector (action space
) (Equation26
(26)
(26) ). The number of weights in the critic network is computed in a similar way, but has only one output node (Equation27
(27)
(27) ):
(26)
(26)
(27)
(27) There appears to be linear growth in computation time as the number of weights grows. Note that we increased the size of the hidden layers for larger problems to accommodate the larger action space. This has a major impact on the number of weights and therefore computation time. Furthermore, the additional computations required for computing the eligibility mask in each new state impact the time per iteration significantly.
When investigating the average number of iterations required for convergence, the results of Set 1 give the most insights, as this number of iterations is mostly related to the variability of demand and the number of products. PPO is able to learn a good policy that improves on the benchmark quite quickly, but then slowly finds further improvements, until it converges (seen in Figure ). In settings with higher variability, PPO requires on average 16% fewer iterations to converge to a solution. The reason for this might be that with high variability, the PPO algorithm will encounter a wider selection of the state-action space more quickly during training, and hence learn faster. Additionally, with an increasing number of products, PPO needs more iterations to converge, as was to be expected due to the increasing action space requiring more exploration.
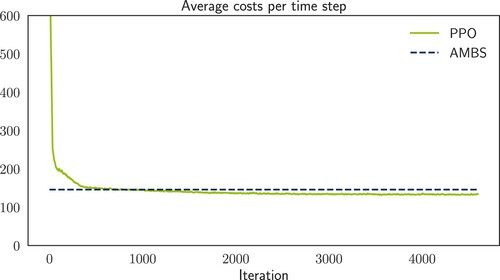
Figure 5. Performance of the PPO algorithm in experiment set 1 with K = 4, low and cf = 1.1. The AMBS performance is equalled after ∼1000 iterations, and PPO stops improving after ∼3500 iterations.
Upon combining the time per iteration and the number of iterations, we see that more time is required to train larger problem instances. Additionally, we have performed three replications for each experiment setting to assess the robustness in learning, which requires three times the computation time. There is a slight gap in performance between the best and average replication, so a trade-off must be made for how much additional replications are desired to achieve small improvements in algorithm performance. However, it is good to note that this training can be done offline, and after the training, a steady-state policy results that can make decisions instantly based on the state variable. This is unlike MILP problems which have to be solved in their entirety at the moment of requiring a decision.
The time required for the AMBS heuristic to find the right ,
and
parameters depends on the granularity of the grid search and the number of products (as this impacts the number of available batches). One parameter simulation requires
seconds. In our grid search, we searched
combinations of parameters, meaning that for problems with 10 products, it took around 2.5 hours to find the optimal settings. Many actions could be taken to improve this computation time for AMBS, for instance, parallel search or a smarter grid search. The same holds for the PPO algorithm, as it is well known that neural network computations can be speed up significantly when run on GPU cores (as opposed to the CPU cores we used). While improvements are possible in the computation times, we demonstrate that the PPO algorithm performs well and also appears to scale linearly with regards to the size of the problem with our action space modifications to improve scalability. This shows that PPO is an interesting method for solving sequential decision-making problems with complicated real-life constraints.
5.5. Explainability
The use of neural networks often receives criticism that it is a ‘black box’ because it is hard to understand why a certain output is generated by the network (Heuillet, Couthouis, and Díaz-Rodríguez Citation2021). In this section, we make the output of the PPO networks interpretable. More specifically, we find a relationship between the action and the states in each of the experimental settings. For this explainability analysis, multiple regression analysis is employed to determine the relationship between the dependent variable (action) and multiple independent variables (states).
We define multiple linear regression equation (Equation28(28)
(28) ), where for each product we predict the production quantity
based on the product's inventory position
, the sum of all inventory positions in the system
and the set-up carryover variable
:
(28)
(28) For every problem instance in our experiment sets, Ordinary Least Squares estimation is used to estimate the intercept c and β coefficients for all products. The state variables explain a large part of the variance in the production quantity (average
-value = 0.621), and 97.4% of the β-coefficients were found to be statistically significant (p<.001 ).
In Figure , the average value of the coefficients in each of the experiment sets is shown. We see that is typically negative, which means that when
is higher,
will be lower. This is as expected, because with high levels of inventory, less additional production is needed to prevent backorders. For
, which determines the relationship between the total system inventory position and
, we do not observe the same consistency in the direction of the coefficient. For
large positive coefficients are observed, so
seems to have the strongest relationships with
, indicating that when the machine is set up for product i,
will be higher. When the demand uncertainty increases, the relationship between
and
becomes weaker. This can be explained by the fact that with more uncertain demand, switching production to another product to avoid backorders may be more beneficial than when the upcoming demand is fairly certain. For settings where the set-up costs are higher,
has more impact on
, and
becomes less important as a predictor. This indicates that when the set-up costs are high, it is better to take more advantage of the set-up by producing more of that product. This is consistent with expectations because when set-up costs are higher, it is sensible to try to prevent changing over to a new product due to the high costs.
Figure 6. Values of the coefficients in the regression models of the different experiment sets. and
have the strongest relationship with
.

Performing the multiple regression analysis shows that finding explanations for decisions made by the PPO solution can be done in a rather straightforward way. This is essential in enabling the understanding and trustworthiness of the algorithm, making it more suitable to use in practice. For future research, we suggest to look at more intricate explanation mechanisms as summarised by Heuillet, Couthouis, and Díaz-Rodríguez (Citation2021) that may be better suited to the non-linear nature of neural networks, and that even have the capability to predict single policy actions (rather than general policy characteristics). Another avenue for future research is to utilise the findings of DRL algorithms to create new well-performing heuristics for complex problems that can be more easily understood and implemented in practice.
6. Conclusion
We investigated the applicability of a DRL methodology for finding near-optimal policies in the S-CLSP that minimise the costs of set-ups, backorders, and holding inventory. This shows how uncertainty in problems can be handled in optimisation, and how trade-offs can be found for conflicting objectives. Our study proposes to use the PPO algorithm, a method that performs well without extensive hyper-parameter tuning. We report that the PPO algorithm comes close to the optimal solution. In the experiments, we looked at various problem instances with different numbers of products, demand variability, capacity restrictions, cost settings, heterogeneous products (in terms of demand and costs) and set-up times. To demonstrate the potential of PPO in industrial use, we show that for larger problem instances where the optimal solution is unknown, the algorithm finds solutions that outperform the benchmark (an aggregate modified base-stock heuristic) by ∼7%.
In addition to the good performance of the algorithm, the computation time is promising as well. The computation time appears to have linear growth, making it an attractive method for solving industrial-size problems. An interesting avenue for future research is how to deal with larger action spaces, as we observe that the size of the action space may become restrictive in finding well-performing solutions. Moreover, we illustrate a way of explaining the resulting policies, which is an essential step in providing trust in the algorithm and enabling its implementation in the industry.
For future research, it is interesting to investigate how the algorithm could benefit from incorporating more information (e.g. demand forecasts) in the state space. Especially in the data-rich heavily interconnected supply network, this could be very advantageous. Other extensions could be to include additional objectives in the problem, such as reducing nervousness in production planning and investigating alternative explanation mechanisms for the outcomes of the algorithm. Implementation of this algorithm can support companies to reap the benefits of the digital supply chain, which include reducing costs and improving service to customers.
Acknowledgements
We thank SURFsara (www.surf.nl) for the support in using the Lisa Compute Cluster. We thank presenters in the Eindhoven seminar on RL for presentations and inspiration, and Wouter Kool for his feedback and insights on implementing RL.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Additional information
Notes on contributors

Lotte van Hezewijk
Lotte van Hezewijk is a Ph.D. candidate in the Department of Industrial Engineering & Innovation Sciences (IE&IS) at Eindhoven University of Technology (TU/e). Simultaneously, she works as Analytics Consultant at ORTEC. Her research is focused on exploring the benefits of Machine Learning in supply chain applications.

Nico Dellaert
Nico Dellaert is Associate Professor and Chair of Quantitative Analysis of Stochastic Models for Logistic Design in the Department of IE&IS at the TU/e. His prime research interests are on the integration of capacity and production decisions, on city logistics and multimodal transportation and on healthcare planning. In his work, he uses a large variety of mathematical modelling techniques. In most cases, companies or hospitals have been involved in the research.

Tom Van Woensel
Tom Van Woensel is Full Professor of Freight Transport and Logistics in the OPAC group (Operations, Planning, Accounting and Control) of the Department of IE&IS at the TU/e. Current interests include Last Mile Logistics, vehicle routing problems, crowd shipping, (service) network design, machine learning, Big Data, and IoT-driven issues and opportunities. He is also a director of the European Supply Chain Forum, in which some 75 multinational companies are involved.

Noud Gademann
Noud Gademann is Principal Consultant in Supply Chain Optimization at ORTEC. He also filled positions as assistant professor and researcher at the University of Twente and Eindhoven University of Technology in the field of Production and Operations Management and Warehouse Management, with a strong focus on the development and application of optimisation models and algorithms. He has a broad interest and experience in a large variety of industries, including discrete manufacturing, process industry, consumer goods and retail, warehousing and logistics, service industry, and rail services.
Notes
1 Since in our problem setting, demand events only occur once a day, this periodic review setting is similar to the continuous review problem.
2 For the lot size, we take the sum of production batches produced in subsequent periods that a product is continually set up
3 In Section 4.2, a problem with three products was solved to optimality. Nevertheless, to make this computationally tractable, the state space had to be made very small by adjusting the inventory limits. This is an arbitrary change that impacts the final solution, which we wanted to avoid in remaining experiments.
4 There are two outlier cases in the analysis, for which we notice extensive backorder build-up in the AMBS heuristic. In these situations with a very limited capacity of only 3 batches, the AMBS heuristic easily gets into a long 100% utilisation loop in which we produce 2 batches of different products in every period, without having the minimum required batch size for stability and recovering from backorder build-up. In these settings, the PPO algorithm learns to avoid such extensive backorder situations.
References
- Arrow, Kenneth J., Theodore Harris, and Jacob Marschak. 1951. “Optimal Inventory Policy.” Econometrica: Journal of the Econometric Society 19 (3): 250–272.
- Axsäter, Sven. 1993. “ Continuous Review Policies for Multi-level Inventory Systems with Stochastic Demand.” In Logistics of Production and Inventory. Handbooks of Operations Research and Management Science, Vol. 4, edited by Stephen C. Graves, Alexander H. G. Rinnooy Kan, and Paul H. Zipkin, 175–197. North-Holland.
- Baker, Kenneth R. 1977. “An Experimental Study of the Effectiveness of Rolling Schedules in Production Planning.” Decision Sciences 8 (1): 19–27.
- Bellman, Richard. 1954. “The Theory of Dynamic Programming.” Bulletin of the American Mathematical Society 60 (6): 503–515.
- Bookbinder, James, and Jin-Yan Tan. 1988. “Strategies for the Probabilistic Lot-Sizing Problem with Service-Level Constraints.” Management Science 34 (9): 1096–1108.
- Boute, Robert N., Joren Gijsbrechts, Willem van Jaarsveld, and Nathalie Vanvuchelen. 2021. “Deep Reinforcement Learning for Inventory Control: A Roadmap.” European Journal of Operational Research 298 (2): 401–412.
- Brandimarte, Paolo. 2006. “Multi-item Capacitated Lot-Sizing with Demand Uncertainty.” International Journal of Production Research 44 (15): 2997–3022.
- Buşoniu, Lucian, Tim de Bruin, Domagoj Tolić, Jens Kober, and Ivana Palunko. 2018. “Reinforcement Learning for Control: Performance, Stability, and Deep Approximators.” Annual Reviews in Control 46: 8–28.
- Chaharsooghi, S. Kamal, Jafar Heydari, and S. Hessameddin Zegordi. 2008. “A Reinforcement Learning Model for Supply Chain Ordering Management: An Application to the Beer Game.” Decision Support Systems 45 (4): 949–959.
- DeCroix, Gregory A., and Antonio Arreola-Risa. 1998. “Optimal Production and Inventory Policy for Multiple Products under Resource Constraints.” Management Science 44 (7): 950–961.
- De Smet, Niels, Stefan Minner, El Houssaine Aghezzaf, and Bram Desmet. 2020. “A Linearisation Approach to the Stochastic Dynamic Capacitated Lotsizing Problem with Sequence-Dependent Changeovers.” International Journal of Production Research 58 (16): 4980–5005.
- Donselaar, Karel H. Van, Vishal Gaur, Tom Van Woensel, Rob A. C. M. Broekmeulen, and Jan C. Fransoo. 2010. “Ordering Behavior in Retail Stores and Implications for Automated Replenishment.” Management Science 56 (5): 766–784.
- Erlenkotter, Donald. 1989. “Note – An Early Classic Misplaced: Ford W. Harris's Economic Order Quantity Model of 1915.” Management Science 35 (7): 898–900.
- Federgruen, A., and P. Zipkin. 1984. “An Efficient Algorithm for Computing Optimal (s, S) Policies.” Operations Research 32 (6): 1268–1285.
- Giannoccaro, Ilaria, and Pierpaolo Pontrandolfo. 2002. “Inventory Management in Supply Chains: A Reinforcement Learning Approach.” International Journal of Production Economics 78 (2): 153–161.
- Gijsbrechts, Joren, Robert N. Boute, Jan Albert Van Mieghem, and Dennis Zhang. 2021. “Can Deep Reinforcement Learning Improve Inventory Management? Performance on Dual Sourcing, Lost Sales and Multi-echelon Problems.” Manufacturing & Service Operations Management.
- Glorot, Xavier, and Yoshua Bengio. 2010. “Understanding the Difficulty of Training Deep Feedforward Neural Networks.” Journal of Machine Learning Research 9: 249–256.
- Goodfellow, Ian, Yoshua Bengio, and Aaron Courville. 2016. Deep Learning. Cambridge, MA: MIT Press.
- Gosavi, Abhijit, Emrah Ozkaya, and Aykut F. Kahraman. 2007. “Simulation Optimization for Revenue Management of Airlines with Cancellations and Overbooking.” OR Spectrum 29 (1): 21–38.
- Graves, Stephen C. 1988. “Safety Stocks in Manufacturing Systems.” Journal of Manufacturing and Operations Management 1: 67–101.
- Graves, Stephen C., and Sean P. Willems. 2000. “Optimizing Strategic Safety Stock Placement in Supply Chains.” Manufacturing and Service Operations Management 2 (1): 68–83.
- Helber, Stefan, Florian Sahling, and Katja Schimmelpfeng. 2013. “Dynamic Capacitated Lot Sizing with Random Demand and Dynamic Safety Stocks.” OR Spectrum 35 (1): 75–105.
- Heuillet, Alexandre, Fabien Couthouis, and Natalia Díaz-Rodríguez. 2021. “Explainability in Deep Reinforcement Learning.” Knowledge-Based Systems 214: 106685.
- Jans, Raf, and Zeger Degraeve. 2008. “Modeling Industrial Lot Sizing Problems: A Review.” International Journal of Production Research 46 (6): 1619–1643.
- Jiang, Chengzhi, and Zhaohan Sheng. 2009. “Case-Based Reinforcement Learning for Dynamic Inventory Control in a Multi-agent Supply-Chain System.” Expert Systems with Applications 36 (3): 6520–6526.
- Kara, Ahmet, and Ibrahim Dogan. 2018. “Reinforcement Learning Approaches for Specifying Ordering Policies of Perishable Inventory Systems.” Expert Systems with Applications 91: 150–158.
- Karimi, Behrooz, S. M. T. Fatemi Ghomi, and J. M. Wilson. 2003. “The Capacitated Lot Sizing Problem: A Review of Models and Algorithms.” Omega 31 (5): 365–378.
- Kim, C. O., J. Jun, J. K. Baek, R. L. Smith, and Y. D. Kim. 2005. “Adaptive Inventory Control Models for Supply Chain Management.” International Journal of Advanced Manufacturing Technology 26 (9–10): 1184–1192.
- Kingma, Diederik P., and Jimmy Ba. 2014. “Adam: A Method for Stochastic Optimization.” Preprint arXiv:1412.6980.
- Kool, Wouter, Herke van Hoof, and Max Welling. 2019. “Attention, Learn to Solve Routing Problems!,” 1–25. Preprint arXiv:1803.08475v3.
- Kwon, Ick-Hyun, Chang Ouk Kim, Jin Jun, and Jung Hoon Lee. 2008. “Case-Based Myopic Reinforcement Learning for Satisfying Target Service Level in Supply Chain.” Expert Systems with Applications 35 (1–2): 389–397.
- Lee, Hau L. 2004. “The Triple – A Supply Chain.” Harvard Business Review 82 (10): 102–113.
- Mnih, Volodymyr, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. 2016. "Asynchronous Methods for Deep Reinforcement Learning.” Proceedings of the 33rd International Conference on Machine Learning. New York, NY, USA.
- Mnih, Volodymyr, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. 2013. “Playing Atari with Deep Reinforcement Learning,” 1–9. Preprint arXiv:1312.5602.
- Mnih, Volodymyr, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, et al. 2015. “Human-Level Control Through Deep Reinforcement Learning.” Nature 518 (7540): 529–533.
- Mula, Josefa, Raul Poler, Jose P. Garcia-Sabater, and Francisco Cruz Lario. 2006. “Models for Production Planning under Uncertainty: A Review.” International Journal of Production Economics 103 (1): 271–285.
- Nahmias, Steven, and Tara Lennon Olsen. 2015a. “Inventory Control Subject to Known Demand.” In Production and Operations Analysis. 7, 198–248. Long Grove, IL: Waveland Press.
- Nahmias, Steven, and Tara Lennon Olsen. 2015b. “Inventory Control Subject to Uncertain Demand.” In Production and Operations Analysis. 7, 249–314. Long Grove, IL: Waveland Press.
- Oroojlooyjadid, Afshin, Mohammad Reza Nazari, Lawrence V. Snyder, and Martin Takáč. 2017. “A Deep Q-Network for the Beer Game: Reinforcement Learning for Inventory Optimization.” Preprint arXiv:1708.05924v3.
- Park, Junyoung, Jaehyeong Chun, Sang Hun Kim, Youngkook Kim, and Jinkyoo Park. 2021. “Learning to Schedule Job-Shop Problems: Representation and Policy Learning Using Graph Neural Network and Reinforcement Learning.” International Journal of Production Research 59 (11): 3360–3377.
- Paternina-Arboleda, Carlos D., and Tapas K. Das. 2005. “A Multi-Agent Reinforcement Learning Approach to Obtaining Dynamic Control Policies for Stochastic Lot Scheduling Problem.” Simulation Modelling Practice and Theory 13 (5): 389–406.
- Pontrandolfo, P., A. Gosavi, O. G. Okogbaa, and T. K. Das. 2002. “Global Supply Chain Management: A Reinforcement Learning Approach.” International Journal of Production Research 40 (6): 1299–1317.
- Powell, Warren B. 2007. Approximate Dynamic Programming: Solving the Curses of Dimensionality. Vol. 703. Hoboken, NJ: John Wiley & Sons.
- Rummukainen, Hannu, and Jukka K. Nurminen. 2019. “Practical Reinforcement Learning Experiences in Scheduling Application.” IFAC PapersOnLine 52 (13): 1415–1420.
- Schulman, John, Sergey Levine, Philipp Moritz, Michael Jordan, and Pieter Abbeel. 2015. “Trust Region Policy Optimization.” Proceedings of the 32nd International Conference on Machine Learning. Lille, France.
- Schulman, John, Philipp Moritz, Sergey Levine, Michael I. Jordan, and Pieter Abbeel. 2016. “High-Dimensional Continuous Control Using Generalized Advantage Estimation.” Conference Track Proceedings of the 4th International Conference on Learning Representations.San Jose, Puerto Rico.
- Schulman, John, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. “Proximal Policy Optimization Algorithms.” Preprint arXiv:1707.06347, 1–12.
- Shannon, Claude Elwood. 1948. “A Mathematical Theory of Communication.” The Bell System Technical Journal 27 (3): 379–423.
- Sutton, Richard S., and Andrew G. Barto. 2018. Reinforcement Learning: An Introduction. Cambridge, MA: MIT Press.
- Tang, Jie, and Pieter Abbeel. 2010. “On a Connection Between Importance Sampling and the Likelihood Ratio Policy Gradient.” Advances in Neural Information Processing Systems 23: 1000–1008.
- Tavaghof-Gigloo, Dariush, and Stefan Minner. 2020. “Planning Approaches for Stochastic Capacitated Lot-Sizing with Service Level Constraints.” International Journal of Production Research 59 (17): 5087–5107.
- Tempelmeier, Horst. 2006. Inventory Management in Supply Networks: Problems, Models, Solutions. Köln, Germany: University of Cologne.
- Tempelmeier, Horst. 2011. “A Column Generation Heuristic for Dynamic Capacitated Lot Sizing with Random Demand Under a Fill Rate Constraint.” Omega 39 (6): 627–633.
- Tempelmeier, Horst. 2013. “Stochastic Lot Sizing Problems.” In Handbook of Stochastic Models and Analysis of Manufacturing System Operations. International Series in Operations Research & Management Science , 313–344. New York: Springer.
- Tempelmeier, Horst, and Timo Hilger. 2015. “Linear Programming Models for a Stochastic Dynamic Capacitated Lot Sizing Problem.” Computers and Operations Research 59: 119–125.
- Vanvuchelen, Nathalie, Joren Gijsbrechts, and Robert Boute. 2020. “Use of Proximal Policy Optimization for the Joint Replenishment Problem.” Computers in Industry 119: 103239.
- Wang, Jiao, Xueping Li, and Xiaoyan Zhu. 2012. “Intelligent Dynamic Control of Stochastic Economic Lot Scheduling by Agent-based Reinforcement Learning.” International Journal of Production Research 50 (16): 4381–4395.
- Winands, Erik M. M., Ivo JBF Adan, and Geert-Jan van Houtum. 2011. “The Stochastic Economic Lot Scheduling Problem: A Survey.” European Journal of Operational Research 210 (1): 1–9.
- Zahavy, Tom, Matan Haroush, Nadav Merlis, Daniel J. Mankowitz, and Shie Mannor. 2018. “Learn What Not to Learn: Action Elimination with Deep Reinforcement Learning.” Preprint arXiv:1809.02121, 1–12.
Appendices
Appendix 1. Action elimination
EOQ quantity (EquationA1(A1)
(A1) ) is used to determine the maximum number of batches that are allowed to be produced for one product in one period. Note that in our problem instances with a limited amount of products, the capacity available for production is rarely enough to produce the EOQ quantity in one period. When the number of products increases, it could be that there is enough capacity to produce the EOQ quantity in one period, however, in these cases it is very uncommon that only one product is produced. Therefore, we do not expect this reduction technique to negatively impact the performance of the policy:
(A1)
(A1) We determine a maximum number of products
that is allowed to be produced in one period. We base this value on the probability that k products are produced in the same period. The probability
that a product i is produced depends on the time between orders
(EquationA2
(A2)
(A2) ) and (EquationA3
(A3)
(A3) ):
(A2)
(A2)
(A3)
(A3) To determine the probability that k products are produced in a period, we first compute the potential number of combinations of k products in the total set K. We then multiply this with the probabilities of production for each product (EquationA4
(A4)
(A4) ).
is the maximum k for which
, in other words, the maximum number of products which has a higher than 1% chance of being produced:
(A4)
(A4)
Appendix 2. Aggregated modified base-stock heuristic
In this section, the detailed notation for the aggregate modified base-stock heuristic (Algorithm 2) is presented.

The heuristic bases its replenishment decisions partly on the expected backorder costs (EquationA5(A5)
(A5) ). This computation is based on the uniform demand distribution that is considered, denoted by
, with mean demand
:
(A5)
(A5) After the production batches have been decided to cover the expected backorders, additional production is determined for products that are set up. This determination is based on the order of the inventory to EOQ-value ratio (EquationA6
(A6)
(A6) ) and (EquationA1
(A1)
(A1) ):
(A6)
(A6) After each decision on a production batch, the remaining capacity is computed (EquationA7
(A7)
(A7) ), based on set-ups required and the number of batches produced:
(A7)
(A7) The relevant parameters in this problem are
,
and
. A grid-search is performed to find the best functioning values. The grid search is done by rolling out the heuristic 10 times for 1000 periods and discarding the first 100 as warm-up periods. The average costs are recorded, and the parameter combination of
,
and
resulting in the minimum costs is used. For
we look at several proportions of average EOQ-cost (EquationA8
(A8)
(A8) ). In this case,
(EquationA9
(A9)
(A9) ):
(A8)
(A8)
(A9)
(A9) For
, we look at several proportions of the total EOQ holding costs. In this case,
(EquationA10
(A10)
(A10) ):
(A10)
(A10) For
, we look at all possible quantities, given the number of products in the system. Since set-ups are carried over from one period to the next, there will be at most K−1 set-ups in a period. In this case,
.
Appendix 3. Extended experimental results
In this section, three tables are shown with the extended results for the experiment sets. They show the average costs of the PPO solution, as well as the differences in percentage in costs, inventory, backorders, set-ups and lot sizes, compared with the AMBS heuristic.
Table D1. Extended results for experiment set 1 showing the average PPO costs (), difference in average period costs (
), average inventory level (
), average backorders (
), average set-ups (
) and average lot size (
) between the best PPO performance and the AMBS heuristic in %.
Table D2. Extended results for experiment set 2 (K = 4) showing the average PPO costs (), difference in average period costs (
), average inventory level (
), average backorders (
), average set-ups (
) and average lot size (
) between the best PPO performance and the AMBS heuristic in %.
Table D3. Extended results for experiment set 3 (K = 4) showing the average PPO costs (), difference in average period costs (
), average inventory level (
), average backorders (
), average set-ups (
) and average lot size (
) between the best PPO performance and the AMBS heuristic in %.