
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Transporting ore from mines to ports is of significant interest in mining supply chains. These operations are commonly associated with growing costs and a lack of resources. Large mining companies are interested in optimally allocating resources to reduce operational costs. This problem has been previously investigated as resource constrained job scheduling (RCJS). While a number of optimisation methods have been proposed to tackle the deterministic problem, the uncertainty associated with resource availability, an inevitable challenge in mining operations, has received less attention. RCJS with uncertainty is a hard combinatorial optimisation problem that is challenging for existing optimisation methods. We propose an adaptive population-based simulated annealing algorithm that can overcome existing limitations of methods for RCJS with uncertainty, including pre-mature convergence, excessive number of hyper-parameters, and the inefficiency in coping with different uncertainty levels. This new algorithm effectively balances exploration and exploitation, by using a population, modifying the cooling schedule in the Metropolis-Hastings algorithm, and using an adaptive mechanism to select perturbation operators. The results show that the proposed algorithm outperforms existing methods on a benchmark RCJS dataset considering different uncertainty levels. Moreover, new best known solutions are discovered for all but one problem instance across all uncertainty levels.
1. Introduction
The mining supply chain in Australia is one of the largest in the world, where a significant proportion of the minerals mined are exported overseas. Mining is major contributor to the Australian economy, with the exporting minerals contributing around AUD 200 billion per annum to the economy, employing 240,000 individuals directly, and around 850,000 individuals indirectly.Footnote1 Due to its role in the export of raw materials, Australia has developed a reputation in building mining technologies and is one of the largest suppliers of these technologies and software, worldwide.Footnote2
There are numerous problems within the mining supply chain. Of significant interest, is the transportation of ore from mines to ports. In particular, transporting ore from multiple mining sites to a port where resources (trains and trucks) must be shared, is a key problem. If this problem is solved effectively, it can lead to large increases in throughput, thereby leading to substantial gains in revenue for the mining companies. In an abstract form, this problem can be formulated as a resource constrained job scheduling (RCJS) problem. The transportation of ore in batches can be viewed as jobs, while different transport modes (trains or trucks), can be viewed as resources. In the real setting, certain batches are required to be loaded on ships before others, and this aspect can be modelled by precedences between jobs. The timely arrival of ore at the ports is very important, as batches of ore that unnecessarily wait will lead to demurrage costs. This aspect is incorporated as a weighted tardiness for each job (different batches of ore being delayed lead to different costs), and the aim is to ensure the total weighted tardiness across all jobs is kept at minimum.
In the literature, this problem is known as RCJS with a shared central resource (Singh and Ernst Citation2011; Singh and Weiskircher. Citation2008; Singh and Weiskircher Citation2011). The complexity of RCJS makes it challenging for optimisation algorithms, and hence, several approaches have been proposed to tackle it. These include metaheuristics and matheuristics (Cohen et al. Citation2017; Ernst and Singh Citation2012; Nguyen et al. Citation2019; Nguyen and Thiruvady Citation2020; Nguyen, Zhang, and Chen Tan Citation2018; Singh and Ernst Citation2011; Thiruvady, Blum, and Ernst Citation2020; Thiruvady, Ernst, and Singh Citation2016; Thiruvady et al. Citation2012; Thiruvady, Singh, and Ernst Citation2014). The problem was introduced by Singh and Ernst (Citation2011), who proposed a Lagrangian relaxation based heuristic, which was able to find good solutions and lower bounds. Singh and Weiskircher. (Citation2008) and Singh and Weiskircher (Citation2011) consider a similar problem to RCJS that is modelled as machine scheduling with fractional shared resources. They propose collaborative approaches via agent-based modelling, which prove to be effective in tackling these problems. Ernst and Singh (Citation2012) propose a Lagrangian relaxation based matheuristic that employs particle swarm optimisation, which showed improvements in solution quality across the RCJS benchmark dataset. Thiruvady et al. (Citation2012) consider a variant of RCJS with hard due dates, and they show that an ant colony optimisation (ACO) and constraint programming hybrid can efficiently find feasible and high quality solutions. The study by Thiruvady, Singh, and Ernst (Citation2014) proposes a column generation approach for RCJS, which finds excellent solutions and lower bounds. An inherent issue is the time requirements in solving this problem, and hence, parallel implementations of metaheuristics and matheuristics have been attempted (Cohen et al. Citation2017; Thiruvady, Ernst, and Singh Citation2016). The best known solutions for RCJS have been obtained by Nguyen et al. (Citation2019) and Blum et al. (Citation2019). Nguyen et al. (Citation2019) develop a hybrid of differential evolution and column generation, and they show excellent results on small and medium sized problems. Blum et al. (Citation2019) devise a biased random key genetic algorithm, which produces excellent results, especially for large problem instances. In the interest of finding good solutions quickly, studies have shown that genetic programming can be effective for RCJS (Nguyen et al. Citation2021; Nguyen and Thiruvady Citation2020; Nguyen, Zhang, and Chen Tan Citation2018). Finally, Thiruvady, Blum, and Ernst (Citation2020) propose Merge search and CMSA for RCJS.
RCJS under uncertainty (RCJSU) is a variant of RCJS that takes into consideration different practical random sources such as job release times, job processing times or the availability of resources. Of vital importance in RCJS, and crucial in real-world settings, is the uncertain resource availabilities. That is, if trains and trucks breakdown or tracks and roads need maintenance leading to delays in the ore reaching ports, there can be substantial losses incurred. Therefore, planners need a solution method that can address disruptions due to random events to ensure that the solutions obtained can ensure smooth operations either by incorporating uncertainty into optimisation problems, reoptimisation, or reactive dispatching rules. Thiruvady et al. (Citation2022) develop the first RCJSU formulation and propose a surrogate-assisted ant colony system (SACS) to find robust solutions. The results show that SACS outperforms solution methods based on mixed integer programming (MIP), meta-heuristics and surrogate-assisted evolutionary algorithms. Further analyses show that SACS finds good solutions more quickly compared to standard ACO algorithms.
Although SACS has shown promising results, there are some key limitations. Firstly, surrogate models help SACS address the challenge of expensive solution evaluations, but the proposed algorithm tends to converge prematurely, especially for large instances. Therefore, SACS (as well as other existing algorithms in the study of Thiruvady et al. (Citation2022)) can waste a lot of time exploring the search space without making significant progress. Secondly, the proposed method has many pre-defined hyper-parameters such as the learning rate of ant colony systems (ACS) and pre-selection rate for the surrogate models. Because of this issue, the algorithm can have trouble in solving a wide range of instances without major modifications (e.g. reoptimise hyper-parameters). Finally, the performance of SACS is not consistent across different uncertainty levels and different problem sizes (i.e. number of machines). For medium problem sizes and large uncertainty levels, SACS does not show significantly superior performance compared to standard ACS.
This paper addresses the three key limitations discussed above by developing a new adaptive population-based simulated annealing (APSA) algorithm for RCJSU. The two main contributions of this paper are summarised as follows: (1) a new population-based simulated annealing algorithm with a balance between exploration and exploitation and (3) a new adaptive mechanism to update the probabilities for selecting perturbation operators to avoid premature convergence. Additionally, the new efficient simulated annealing algorithm adapts the Metropolis-Hastings method of Singh and Ernst (Citation2011) to converge substantially more quickly by using a faster cooling schedule. APSA is similar to memetic algorithms, and population-based stochastic local search (Hoos and Sttzle Citation2015; Ong, Hiot Lim, and Chen Citation2010) that combines evolutionary algorithms and local search heuristics; however, APSA adopts a much smaller population in which the population is improved mainly via local search and adaptive perturbations rather than crossover operators. The balance between exploration and exploitation within APSA allows the algorithms to perform efficiently against noisy and complex problems like RCJSU. Extensive experiments are conducted to validate the superior performance of the proposed algorithms for RCJSU and RCJS.
The paper is organised as follows. Section 2 provides a review of related work. In Section 3, a formulation of the RCJSU problem is provided, including an integer programming model. Section 4 discusses the adaptive population-based simulated annealing algorithm proposed in this study. The experimental evaluation and associated results are presented in Section 5. Section 6 concludes the paper and presents possibilities for future work.
2. Related work
A review of the literature related to RCJS is provided here, including methods and techniques that are effective at tackling problems similar to RCJS and RCJSU.
2.1. Optimisation techniques for tackling RCJS
Owing to the complexity of RCJS, mathematical programming methods on their own do not suffice in finding optimal or even feasible solutions to relatively small problems. Hence, metahuristics and matheuristics have been popular approaches for tackling the problem. Metaheuristics, including partical swarm optimisation (Ernst and Singh Citation2012), ACO (Thiruvady, Ernst, and Singh Citation2016), differential evolution (Nguyen et al. Citation2019), and genetic algorithms (Blum et al. Citation2019) have been known to find good solutions, albeit with large time overheads. RCJS can be modelled with graphs, and hence, ACO lends itself well to the problem. Nonetheless, past studies on RCJS have shown that ACO tends to converge slowly and gets trapped in local optima. Moreover, diversification strategies including local search (e.g. parallel implementations or niching techniques) help ACO, but the challenges still remain. Hybrid methods, especially those that can guarantee optimality, have also been explored (Nguyen et al. Citation2019; Singh and Ernst Citation2011; Thiruvady, Singh, and Ernst Citation2014), but the results show that only relatively small RCJS problem instances (up to 30 jobs) can be solved with these methods.
2.2. Scheduling on problems with uncertainty
Uncertainty is inherent in many real-world applications, and dealing with uncertainty is often challenging when devising scheduling algorithms. If uncertainty is not considered, the ensuing scheduling algorithms in the deterministic setting are often not effective at even finding feasible solutions (e.g. if a machine breaks down, a job will not be able to start at its pre-determined start time). Hence, a good understanding of the setting in which the schedules are applied is important to ensure success of the scheduling algorithms. Often, reactive scheduling strategies can be more effective in dealing with frequently occurring situations with uncertainties, since the latest information can be incorporated into the decisions. Nonetheless, if predicting the schedules is needed and knowledge of uncertainty is available, the preference is to develop robust schedules. The focus of this paper is on finding robust schedules for RCJSU, since predictable schedules are necessary for mining operations to coordinate supporting activities and to ensure that ore arrives at ports in a timely manner. Of particular interest is the timely arrival of ore at the ports, which relies greatly on the availability of resources. This is indeed the focus in the RCJSU problem and presented in the formulation in Equations (Equation1(1)
(1) )–(Equation7
(7)
(7) ) (see Section 3).
When tackling scheduling problems with uncertainty, the aim is typically to devise methods that are capable of identifying good solutions under any uncertain scenario. These solutions are called robust solutions and the research area, robust proactive scheduling under uncertainty. There are numerous studies focussing on this area, which we summarise here. Beck and Wilson (Citation2007) investigate job shop scheduling, focussing on a variant which consists of stochastic processing times. They show that hybrids of tabu search and constraint programming with Monte Carlo simulation are effective in handling large-sized problems with uncertainty. Davari and Demeulemeester (Citation2019) develop a branch & bound method and a MIP to tackle the chance-constrained resource-constrained project scheduling problem. The study by Song et al. (Citation2019), proposes branch-and-bound algorithms that generate robust schedules on a variant of resource-constrained project scheduling with processing times that are uncertain depending on time. Ghasemi et al. (Citation2023) propose a mathematical model for a multi-mode resource-constrained project scheduling problem subject to interval uncertainty. Vonder et al. (Citation2006) consider resource-constrained project scheduling with uncertainty by ensuring robustness in start times of the tasks. They develop a heuristic approach to ensure stability in the schedules. Liang et al. (Citation2020) consider bi-objective resource-constrained project scheduling where the aim is to develop schedules with robust resource allocation and time buffering. To tackle the two objectives, they propose a two-stage heuristic method, where simulated annealing is used in the second stage to deal with the time buffers. Identifying robust solutions in uncertain problems introduces additional complexity, and for this purpose metaheuristcs such as swarm intelligence algorithms and evolutionary approaches are known to be effective. Bierwirth and Mattfeld (Citation1999) study genetic algorithms for dynamic job arrivals in classic job shop scheduling. Their results show that their approaches are superior to priority dispatching rules, which are popular in dynamic production scheduling. Wang et al. (Citation2015) devise a surrogate-assisted multi-objective evolutionary method to tackle proactive scheduling where machines are considered to have stochastic breakdowns. To cope with the uncertainty, they propose a job compression and rescheduling strategy (Gao et al. Citation2019). Support vector regression in conjunction with surrogate models have been proposed to enhance the speed of time-intensive simulations. The study by Wang, Yin, and Jin (Citation2020) provides an in-depth analysis and discussion of scheduling with machine breakdowns. Systematic reviews of scheduling in problems with uncertainty have also been conducted (Chaari et al. Citation2014; Ouelhadj and Petrovic Citation2008).
The least two decades have seen numerous studies that consider uncertainty in scheduling problems similar to that of RCJS. There are several similarities to project scheduling, and many studies have considered uncertainty within this setting (Chakrabortty, Sarker, and Essam Citation2017; Demeulemeester and Herroelen Citation2011; Herroelen and Leus Citation2005; Khodakarami, Fenton, and Neil Citation2007; Lambrechts, Demeulemeester, and Herroelen Citation2011; Masmoudi and Hait Citation2013; Moradi and Shadrokh Citation2019). In these studies, uncertainty is typically considered in respect to the resources, though, a few consider processing time related uncertainty. Lambrechts, Demeulemeester, and Herroelen (Citation2011) study uncertainty with resources, and specifically modes of execution related to the activities. They develop the notion of ‘time buffering’, that efficiently generates robust schedules. Masmoudi and Hait (Citation2013) consider resource levelling and resource constrained project scheduling, and they propose fuzzy modelling to tackle uncertainty. Their solution approaches are a genetic algorithm and a greedy method to identify robust schedules. Khodakarami, Fenton, and Neil (Citation2007) investigate Bayesian networks to identify causal structures considering uncertainty in sources and parameters of a project. They find that Bayesian networks are indeed very effective at dealing with uncertainty, including aspects such as representation, elicitation and management. Uncertainty associated with processing times has also been investigated (Chakrabortty, Sarker, and Essam Citation2017; Moradi and Shadrokh Citation2019). Moradi and Shadrokh (Citation2019) develop a problem-specific heuristic to deal with uncertainty and Chakrabortty, Sarker, and Essam (Citation2017) propose several Branch & Cut heuristics for project scheduling.Footnote3
2.3. Hybrid optimisation methods
Local search and population-based methods (Luke Citation2013) have been extensively investigated in the literature to tackle challenging scheduling problems. While local search heuristics are best known for their ability to find local optima efficiently, population-based optimisation methods such as genetic algorithms are better known for their exploration ability. Empirical studies have demonstrated the need to maintain a balance between exploration and exploitation when dealing with difficult combinatorial optimisation problems such as job shop scheduling (Cheng, Gen, and Tsujimura Citation1999). Such hybrid methods are commonly referred to as memetic algorithms (Ong, Hiot Lim, and Chen Citation2010) or population-based stochastic local search algorithms (Hoos and Sttzle Citation2015) in the literature. While hybrid algorithms are effective in combinatorial optimisation, there are still a few shortcomings. Firstly, design choices to develop competitive hybrid algorithms are difficult to make and can be sensitive to different problem subsets. Secondly, the performance of hybrid algorithms depend strongly on an ‘ideal’ setting of the algorithm parameters.
Hybrid algorithms have also been developed for RCJS. The study that introduced the problem (Singh and Ernst Citation2011) develops a Lagrangian relaxation heuristic, which combines MIP and simulated annealing. Following this, Thiruvady, Singh, and Ernst (Citation2014) show that a column generation and ACO hybrid is very effective on this problem by finding good lower bounds. Parallel implementations of ACO (Thiruvady, Ernst, and Singh Citation2016) have also been effective, by finding high-quality solutions quickly. Nguyen et al. (Citation2019) propose a hybrid algorithm combining differential evolution and local search, leading to excellent results. The study by Thiruvady, Blum, and Ernst (Citation2020) shows that parallel matheuristics based on MIP and ACO can effectively tackle this problem.
Thiruvady et al. (Citation2022) have developed SACS, a sophisticated algorithm combining ACO, surrogate modelling, and local search to deal with RCJSU. The experiments show that SACS can find excellent solutions for small problems thereby outperforming other meta-heuristics. However, further analyses show that SACS tends to converge prematurely and is inconsistent when working with different problem subsets. Moreover, SACS has many hyper-parameters (for ACO, local search, surrogate models), for which the ideal settings are difficult to find.
3. Problem formulation
Singh and Ernst (Citation2011) propose the original RCJS problem, which is taken directly from the mining industry in Australia. They consider a simplified version of the original problem, which they are able to restate as a job scheduling problem. A major component not considered in RCJS is uncertainty, which is unavoidable in real-world settings. Hence, this study considers this extension to solve what can be considered as closer to the original problem.
The formal definition of RCJSU as an integer program (IP) is provided by Thiruvady et al. (Citation2022). Past studies have considered uncertainty in different ways, including resource limits (Lambrechts, Demeulemeester, and Herroelen Citation2011) or uncertainty in job/task processing times (Chakrabortty, Sarker, and Essam Citation2017). However, in this study the focus is on uncertainty derived from the variability in resources, which in turn affects the processing times of jobs/tasks.Footnote4 The RCJSU problem is NP-hard as it is at least as hard as its deterministic counterpart, which has been shown to be NP-hard by Singh and Ernst (Citation2011). The IP formulation for RCJSU provided by Thiruvady et al. (Citation2022) extends the one for RCJS developed by Singh and Ernst (Citation2011). Uncertainty is introduced by considering several uncertain resource levels, that is, some proportion of the original resource limit is used for each uncertainty sample (details in Section 5.3).
We are given several jobs , which are associated with the following information. Each job i has a release time
, processing time
, due time
, weight
and resource usage
, and must execute on machine
, (
). Jobs on the same machine cannot execute concurrently, or in other words, only one job may execute at one time. A time horizon is given, consisting of discrete points
, and D is chosen to be sufficiently large to ensure a feasible solution will always be found. Precendences may exist between any two jobs
and
that execute on the same machine. This is represented as
, where job i completes before job j starts.
A central resource constraint exists across all machines, where the cumulative resource usage of jobs executing at any time point must be at most . When considering uncertainty,
is allowed to vary. This leads to defining a sample, which has available a proportion of the resource
, and is an instance of the problem. As an input, the total number of samples
is provided, and the resource limit
applies to the
sample.
The IP can be defined as follows. Let be a binary variable, which indicates in sample s, job j completes or has completed by time t, if
. By this definition, a job stays complete once completed. Compared to RCJS, the IP formulation for RCJSU requires additional space complexity, which consists of
variables, and each set of constraints with an additional dimension owing to the samples. The IP formulation is:
(1)
(1)
(2)
(2)
(3)
(3)
(4)
(4)
(5)
(5)
(6)
(6)
(7)
(7) Equation (Equation1
(1)
(1) ), the objective function, states that the average total weighted tardiness (TWT) across all samples must be minimised. Constraints (Equation2
(2)
(2) ) ensure that all jobs complete. Once a job completes it stays complete, which is enforced by Constraints (Equation3
(3)
(3) ). Constraints (Equation4
(4)
(4) ) ensure that all jobs satisfy release times and the precedences are imposed by Constraints (Equation5
(5)
(5) ). In this constraint,
. Constraints (Equation6
(6)
(6) ) require that only one job can execute on one machine at every time point. Constraints (Equation7
(7)
(7) ) ensure that the resource limits, considering each sample, are satisfied.
For the RCJS, there are efficient scheduling heuristics that are known (see Section 4.4). These heuristics typically depend on an alternative formulation, where a sequence or permutation jobs are efficiently mapped to schedules. Previous studies have used this approach for RCJS, e.g. Thiruvady, Singh, and Ernst (Citation2014), and it has also proved beneficial for the RCJSU (Thiruvady et al. Citation2022). In this study, π represents a sequence of jobs while represents an efficient mapping from π to a feasible schedule. Therefore, π is effectively a solution to the problem, where given a sequence, a deterministic schedule can be efficiently constructed.
An example RCJS problem instance is shown in Table . This example shows how a solution is constructed and what the optimal solution is. The problem consists of three jobs, with the associated information in the tables. Moreover, the resource capacity is 10 units. Considering π, there are six potential sequences. Among the jobs, the resulting schedules from π will be efficient if Job 3 is scheduled early owing to an early due date and high weight. Additionally, Job 2 should be sequenced before Job 1 due to its higher weight. Given this information, the optimal solution is .
Table 1. An example with 3 jobs and 10 units of resource.
4. Population-based simulated annealing
Several metaheuristics have been able to find excellent solutions to RCJS in a time efficient manner. One of these approaches is simulated annealing (Singh and Ernst Citation2011). However, to tackle RCJSU, the traditional simulated annealing method has a few shortcomings, and hence, we propose an adaptive population-based simulated annealing (APSA). In particular, this method has three main differences from the traditional approach: (1) a population of solutions to track and exploit best known solutions, (2) a faster cooling schedule within the Metropolis-Hastings algorithm, and (3) adaptive probabilistic selection of the neighbourhood moves to perturb solutions in the population.
The proposed APSA approach is based on the well-known Metropolis-Hastings method, which for an optimisation problem, is known to converge to an optimal solution given infinite time (Granville, Krivanek, and Rasson Citation1994). As such, the approach proposed here, i.e. APSA, can be expected to exhibit the same characteristics and converge to the optimal solution given infinite time.
4.1. The APSA algorithm
Algorithm 1 shows the high-level APSA procedure for RCJSU. As input, the algorithm takes the following: (a) : an initial temperature, (b)
: time limit for the execution of the algorithm, (c) Iter: number of Metropolis-Hastings iterations, (d) v: population size, (e) γ: a parameter to control the cooling schedule and (f) ρ: a parameter that specifies how to adapt the probabilities (
0.9 for this study). In Line 2, the population Π is initialised, where each solution consists of a random list of all the tasks. The best known solution,
, is initialised to be empty. In Line 3, the probability distributions associated with three neighbourhood moves (discussed in the following) are initialised. The main procedure takes place between Lines 4–21, and the algorithm completes execution when the time limit is reached.

Within the main loop, the following is applied to each solution in the population. First, in Line 6, the Metropolis-Hastings algorithm is applied (Algorithm 2) using π as the best solution and for Iter iterations. The resulting solution is stored in .
is updated to π, if π is an improvement, i.e.
. Following this, between Lines 9–19, π is perturbed using a neighbourhood move (details follow in Section 4.3). As part of these steps, the probabilities associated with choosing one of the perturbation moves are adapted or updated. That is, if a move is selected, its corresponding probability reduced by an adaptation factor
.
Every solution obtained (by applying any neighbourhood move, etc.) requires the computation of its objective value. As mentioned earlier, a solution is represented by a sequence of the tasks. For each sequence of tasks π, a feasible schedule () is obtained by constructing
schedules corresponding to each uncertainty sample. Note, each schedule is resource feasible, ensuring that at most
resources are used at each time point for sample s. The result is that each sample has its own TWT. The objective value of π is computed as the average of the TWTs across all samples.
4.2. The metropolis-hastings algorithm

The Metropolis-Hastings method relies on the cooling schedule to ensure a gradual convergence to high-quality regions of the search space. However, due to the overheads introduced by uncertainty, the traditional gradual reduction in temperature will not suffice, and hence we propose a modified version of the method for RCJSU.
Algorithm 2 shows the Metropolis-Hastings procedure. It takes as input: (a) π: current best solution, (b) : initial temperature, (c) Iter: number of iterations that the algorithm will execute for and (d) γ: a parameter to determine the cooling schedule. C represents the best known objective value, and is set to a large number. The temperature
is set to the initial temperature
, and the best solution
is initialised to π. The algorithm executes for Iter iterations (see Lines 3–16 in Algorithm 2). Using
, the neighbourhood move of swapping a pair of jobs is applied. That is, two jobs within the sequence are selected at random and swapped (see Figure ). If the new solution found
is an improvement, C is updated to the objective value of
. Moreover,
is updated to
and the iteration count is reset. Otherwise, a move to the non-improving solution
is still chosen with probability
. The cooling schedule takes place in Line 14.
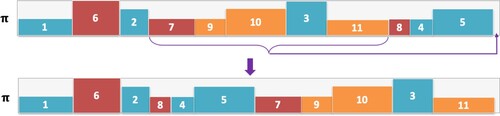
Figure 1. An example that demonstrates job swapping. Two indices are selected randomly, and the corresponding jobs are swapped. In this example, indices 3 and 9 are selected, and the jobs within those indices, 2 and 9, are swapped.
4.3. Adaptive perturbation
Key to the success of APSA is perturbing the best known solution, via three neighbourhood moves. In particular, when applied carefully at different stages of the search, the overall APSA algorithm is able to achieve excellent trade-offs between intensification and diversification.
The first neighbourhood move is β-sampling, which is first studied in the context of project scheduling (Valls, Quintanilla, and Ballestin Citation2003). The basic idea underlying the method is that consecutive jobs or tasks with a sequence are inter-dependent, and moving whole sub-sequences (maintaining certain dependencies) can lead to significant improvements in solutions. For the purposes of the current study, starting at a randomly selected position in the sequence, a sub-sequence of fixed length (5 jobs) is moved to the back of the permutation.
Figure provides an illustration of this method. π consists of 11 jobs. A position is chosen randomly, and this sub-sequence (p to p + 5) moves to the end (bottom part of the figure). Here, p = 4, which starts at Job 7, and Jobs 7, 9, 10, 3 and 11 are chosen to move to the end of the sequence. Subsequent jobs (Jobs 8,4, and 5) move up in the sequence to position 4. β-sampling is applied in the above manner in Line 10 of Algorithm 1.
Figure 2. An example that demonstrates β-sampling. From the sequence π, a subset of jobs is selected (7, 9, 10, 3, 11) and moved to the end of the sequence.
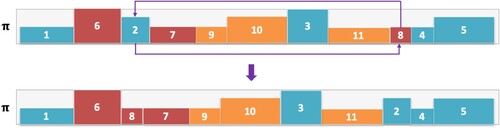
The second neighbourhood move is job swapping. This consists of swapping pairs of jobs in π. Figure shows an example of swapping one pair of jobs. Two positions or indices are chosen at random in the sequence π, and the jobs in these positions are swapped. In the example, Jobs 2 and 8 are swapped.
The third neighbourhood move is to re-initialise the current solution to a randomly chosen sequence. Not surprisingly, the resulting solution can belong to vastly different areas of the search space with a very different objective function value. Hence, this neighbourhood move is expected to produce the largest amount of diversification.
4.3.1. Convergence of probabilities
At each time step, the three neighbourhood moves are selected in a probabilistic manner to perturb the best known solution, with a probability for using β-sampling,
for job swapping, and
for random re-initialisation, as shown in Algorithm 1. After a neighbourhood move is selected, the probability of selecting the same neighbourhood move in the subsequent step is reduced by a factor of ρ (set to 0.9 in this paper). The probability values
,
, and
, are then normalised such that their sum equals 1. Let
,
and
denote the probability values of
,
and
at time step t. The following theorem describes the convergence property of the probabilities.
Theorem 4.1
For any initial conditions ,
, and
within the range of
, subject to the constraint
, the probabilities
,
, and
will eventually converge to the uniform value of 1/3 when time t approaches infinity:
(8)
(8)
Proof.
Given that the probability values of ,
and
at time step t are
,
and
, the expected probabilities at time step t + 1 can be calculated as
(9)
(9)
(10)
(10)
(11)
(11) Hence the governing differential equations for evolving the probabilities
,
and
can be derived:
(12)
(12)
(13)
(13)
(14)
(14) At equilibrium of the differential Equations (Equation12
(12)
(12) )–(Equation14
(14)
(14) ),
. Solving this system of equations with
, we can obtain the following seven equilibria from the differential equations:
(
),
(
(
(
(
(
(
However, the first six equilibria are unstable, in the sense that a small disturbance will perturb the system away from those equilibria. The last equilibrium () is the only stable equilibrium. Hence, after a sufficient number of time steps, the probability values will converge to this stable equilibrium.
It is worth noting that the decay factor ρ has an impact on the rate at which the probabilities converge, however it does not change the equilibrium state upon convergence. In other words, regardless of the specific value of , the probabilities
,
, and
will eventually converge to the uniform value of 1/3 given a sufficiently long time. This can be demonstrated by extending the previous proof, wherein we consider a general parameter ρ in the differential equations.
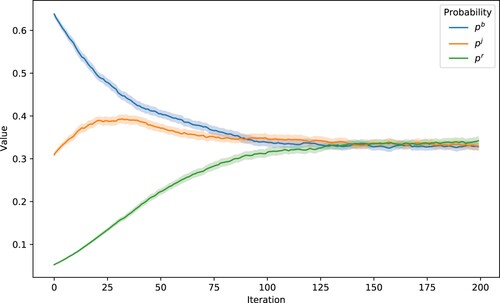
Figure shows a simulation of how the probabilities associated with each neighbourhood move (Algorithm 1) evolve across 200 simulations. We see that three probabilities converge to almost equal levels by 125 simulations.
Figure 3. Adaptive probabilities over 200 simulations.
4.4. Scheduling heuristic
The aim of the scheduling heuristic is to generate a resource feasible schedule from the sequence π. For this purpose, the serial scheduling scheme is employed (Kolisch Citation1996), which is adapted from previous studies on RCJS (Singh and Ernst Citation2011; Thiruvady, Ernst, and Singh Citation2016; Thiruvady et al. Citation2012; Thiruvady, Singh, and Ernst Citation2014). Note, Thiruvady et al. (Citation2022) show that this scheduling scheme can indeed be effective for RCJSU.
The scheduling heuristic works as follows. Jobs in π are selected in the order in which they appear. Each job (j) is tested to see if any of its preceding jobs have not yet been scheduled, and if so, j is placed on the waiting list. Otherwise, j is scheduled as early as possible to ensure that the resource limits are not violated. Once j is scheduled, any job that depends on j (and only j) on the waiting list is scheduled immediately. All such jobs on the waiting list are scheduled in order. Note, for RCJSU, schedules using the procedure above are created for each sample.
Figure shows how the scheduling heuristic works. The problem consists of 15 jobs to be scheduled on three machines. The height of a machine represents the amount of resources available, while a job's height represents its resource requirement. A colour implies a job's machine, i.e. jobs of one colour must go on one machine (e.g. ‘orange’ jobs should be scheduled on machine ).
Figure 4. An example of a problem with three machines and 15 jobs. From π, jobs are selected in order (left to right) and scheduled on machines that they belong to (e.g. orange jobs on ). Those jobs that have predecessors that are not yet scheduled will be put on the waiting list
; (a) Job 8 requires Job 2 to be scheduled before it can be scheduled. (b) Job 8 is scheduled once Job 2 has been scheduled, and this will be done as early as possible considering resources.
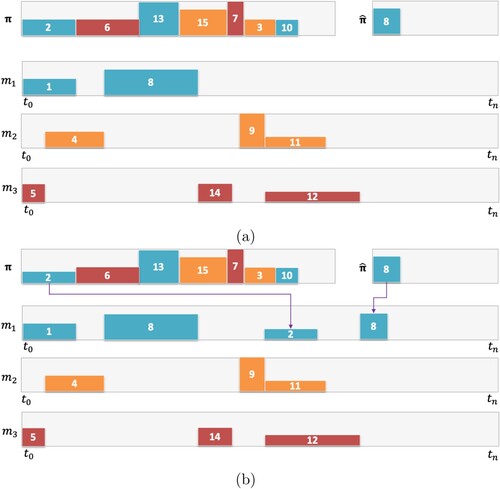
Figure (a) shows a permutation π, and a solution that is partially completed with a few jobs allocated to each machine. The waiting list also consists of some waiting jobs , where for example, Job 8 waits for Job 2 to be scheduled, considering Job 2 precedes Job 8. Figure (b) shows one step in the method, where the next job in π, Job 2, is chosen and scheduled in the first available resource feasible time slot on
. Once Job 2 is scheduled, the waiting list can be examined, and it is found that Job 8 can be released. Job 8 is scheduled as early as possible considering the resource availability.
5. Experiments
A set of experiments and different datasets are applied to fully evaluate the effectiveness and generalisation of the proposed algorithm. We first investigate APSA on RCJSU, and compare its performance to current state-of-the-art approaches, including ACS and SACS.Footnote5 We further investigate the effect of adaptive population-based approach in APSA by comparing its performance with standard simulated annealing (SA) with the same settings, and the specialised SA proposed in Singh and Ernst (Citation2011). Finally, we examine APSA's performance on the deterministic problem (RCJS), and we compare APSA to ACS, SACS and a column generation and ACO hybrid by Thiruvady, Singh, and Ernst (Citation2014).
5.1. Benchmark datasets
To summarise the RCJS problem, jobs correspond to the transportation of batches of ore, the transport modes (trains or trucks) correspond to resources, and the precedences represent batches of ore that need to arrive at the ports before others. The experiments are conducted on problem instances from the literature.Footnote6 The problem instances consist 36 randomly generated instances with 3–12, 15 and 20 machines. There are 3 instances per machine size and 10.5 jobs per machine.Footnote7 The resource usages are defined such that at least two machines may execute at the same time. While this data was originally created for the RCJS, each problem instance is modified to generate the data for RCJSU. Specifically, there are 10 samples generated for each problem instance, where each one has resource limits in the range .
is chosen to be the largest resource required by any job, i.e.
, which ensures a resource feasible schedule can always be found. Additionally, the multiplier
is used to select a proportion of the resources. Typically, a smaller value (e.g. 0.5 or 0.6) means that the problem instance is tightly constrained, where the schedules will need larger completion times, leading to higher overall TWTs.
To gain further insights concerning the strengths of APSA, we investigate a wider range of RCJS problem instances by using the problem generator of Nguyen et al. (Citation2019). The problem instances consider different levels of resource utilisation = [0.25, 0.5, 0.75], number of machines = [3, 4, 5, 6, 7, 8, 9, 10, 12, 15, 18, 20, 25], and the probability of precedences = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7 0.8, 0.9]. The resource utilisation indicates how many jobs may execute at the same time, for example, 0.5 indicates that only two jobs may execute at one time. The precedence probability indicates the denseness of the network, where a low probability implies that many jobs can overlap, while a high probability indicates that the jobs will have to be spread out. A total of 1755 problem instances are generated considering seeds, resource utilisation, network complexity and machine size.
5.2. Parameter settings
The parameter settings for APSA are selected through preliminary experimentation, tuning by hand and by using past studies as a guide. We refer to Algorithms 1 and 2. The time limit is set to 600 seconds. The initial temperature
is set to 1500 using Singh and Ernst (Citation2011) as a guide. The parametric experiments in Appendix 1 show that due to uncertainty and the overheads required to construct schedules with a number of samples, the parameters within the Metropolis-Hastings algorithm have to follow a much quicker cooling schedule. This is achieved by allowing only 1000 iterations (Iter = 1000) and
. Moreover, experiments regarding population size in Appendix 1 show that v = 10 is a reasonable choice. The sub-sequence size used within β-sampling of length 5 jobs, which is obtained from Singh and Ernst (Citation2011). Moreover, in Line 14 of Algorithm 1, there are
applications of job swapping, where
is a random number between 0 and 1. The parameter settings for ACS and SACS are obtained from Thiruvady et al. (Citation2022), to which we refer the reader for complete details.
We carry out experiments on all problem instances considering all uncertainty levels. There are 25 repetitions of for each algorithm, with each one given 10 min of wall clock time. The memory limit was 2 GB, which proved to be sufficient for all algorithms. The algorithms were implemented in C++ with GCC-5.4.0. All experiments were carried out on Monash University's Campus Cluster – MonARCH.Footnote8
The IP was implemented in Gurobi 9.0.1 (Optimization Citation2010). It was run for 10 min per problem instance and allowed a larger amount of memory of 10GB. Across all the runs, only one solution was found for one problem instance at the uncertainly of 0.8. This is not surprising given the size of the model, which is unsuitable in practical settings. Note, consider for example the IP model for an instance with 20 machines. The integer program for this problem instance consists of over 6.9 million decision variables, over 11.4 million constraints and over 49.3 million non-zeros. The size of this IP is clearly far too large to be able to provide meaningful solutions to RCJSU.
5.3. Comparison between APSA and the state-of-the-art
The results that follow are reported as a percentage difference from the best solution quality found by each algorithm averaged over 25 runs to the best solution found by any algorithm. Consider a problem instance and let be the best solution obtained by any algorithm for that problem instance. Let
be the best solution found by APSA for instance k averaged across 25 runs. Then the percentage difference for APSA is
.
Tables and show the results of ACS, SACS and APSA for low and high uncertainty levels (UL), respectively. The tables show the best result obtained by any algorithm (which is highlighted in bold if it is found by APSA) for each uncertainty level, followed by the percentage differences of each algorithm to the corresponding best solution. The best result found by any algorithm for a problem instance is highlighted in bold. Moreover, statistical tests were performed using a Wilcoxon ranked-sum test, and the statistically significant results are marked with a ‘*’. To summarise the performance of the algorithms across the problem instances, the last row of the tables reports the number of times (# best) an algorithm finds the best solution.
Table 2. Results of ACS, SACS and APSA shown as the percentage difference to the best solution for uncertainty levels 0.5, 0.6 and 0.7; Results in column ‘Best’ are highlighted in bold if APSA finds the best solution; Results for each algorithm are highlighted in bold when they achieve best average results, while statistically significant results (pair-wise Wilcoxon ranked-sum test) at a 95 confidence interval are marked with a *.
Table 3. Results of ACS, SACS and APSA shown as the percentage difference to the best solution for uncertainty levels 0.8, 0.9 and 1.0; Results in column ‘Best’ are highlighted in bold if APSA finds the best solution; Results for each algorithm are highlighted in bold when they achieve best average results, while statistically significant results (pair-wise Wilcoxon ranked-sum test) at a 95 confidence interval are marked with a *.
The results in both tables demonstrate the efficacy of our proposed APSA algorithm when compared against two state-of-the-art algorithms, ACS and SACS. The APSA consistently generates the best-known solutions across all problem instances with various levels of uncertainty, with only one exception on instance 15-2 under an uncertainty level of 0.9. Remarkably, the best solutions found by APSA averaged across 25 independent runs are statistically significantly better than those generated by ACS and SACS.
Upon a closer look, we observe that the superiority of APSA over the other two algorithms is less significant when dealing with the smallest (3-machine) and largest (20-machine) problem instances. Regarding the cases with 3 machines, this outcome is not surprising, given the simplicity of these small problem instances which all algorithms are expected to solve optimally or near-optimally. For the large problem instances with 20 machines, the performance of APSA is hindered by the relatively limited number of iterations (less than 10) that APSA can perform within the cutoff time. As a result, APSA has not well converged in these cases, resulting in less notable improvements when compared to the enhancements seen in other instances.
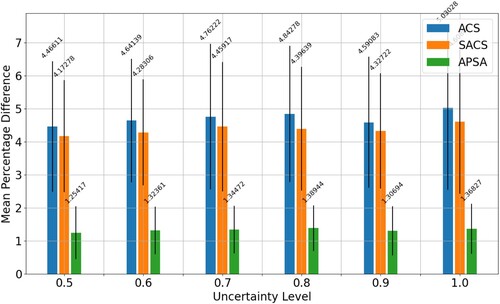
The results in Tables and are summarised in Figure . This figure shows how each algorithm (ACS, SACS, and APSA) performs across different uncertainty levels. The bars in the figure indicate the percentage difference from the best result averaged across all instances within a given uncertainty level. This figure clearly demonstrates that our proposed APSA algorithm significantly outperforms the two state-of-the-art methods across all uncertainty levels.
Figure 5. The figure shows a bar chart of the performance of ACS, SACS and APSA. It shows the average percentage difference to best (y-axis) for each uncertainty level (x-axis). We see that APSA has a distinct advantage across all uncertainty levels.
We now consider the additional problem instances using the problem generator of Nguyen et al. (Citation2019). Figure shows the results for uncertainty level 0.6 and resource utilisations of 0.25 (top), 0.5
(middle) and 0.75
(bottom), averaged across five seeds. The z-axis shows Gap as a percentage, which is the gap from either SACS (left) or APSA (right) (B) to the best solution obtained by APSA or SACS (
) (Gap
=
). A gap of 0 implies that the algorithm finds the best solution. We see that irrespective of the amount of resource utilisation, APSA significantly outperforms SACS. The gaps usually increase with lower proportion of precedences. Interestingly, with increasing machine size, APSA on rare occasions is outperformed by SACS, but these are for relatively few problem instances. On close examination of the results, we find for the large problem instances, that very few iterations of SA are performed, thereby rendering the adaptive component ineffective.
Figure 6. A comparison of SACS (left) and APSA (right) for RCJSU at uncertainty level 0.6 considering varying levels of resource utilisation (top = 0.25, middle = 0.5
, bottom = 0.75
), machine sizes and precedence proportion. Gap
=
, where B is APSA or SACS and b* is the best solution.
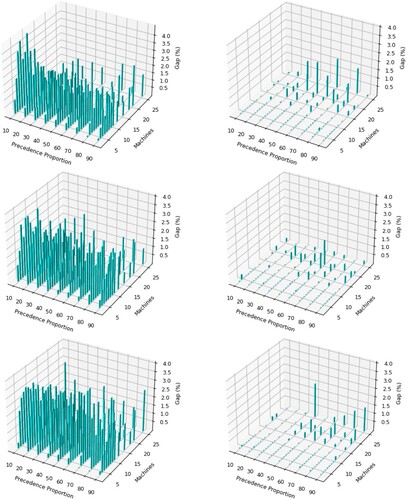
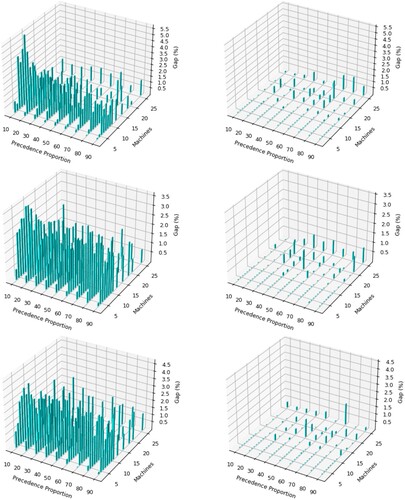
Figure shows the results for uncertainty level 0.9, and is similar to Figure . The results show a similar pattern to Figure , where overall, APSA significantly outperforms SACS. In similar fashion, the gaps increase with lower proportion of precedences, and SACS's performance improves on a very few problem instances when machine sizes get bigger. We note that the time allowance of 10 min for a single run can be limiting, especially for instances with 20 or more machines, and providing larger time allowances (e.g. 1 hour is reasonable in practical settings) can lead to substantial gains. Interestingly, some of the gaps are higher for uncertainty level 0.9 compared to 0.6, especially for low resource utilisation, implying that for less constrained problems and more room to utilise resources, APSA is the best solution.
Figure 7. A comparison of SACS (left) and APSA (right) for RCJSU at uncertainty level 0.9 considering varying levels of resource utilisation (top = 0.25, middle = 0.5
, bottom = 0.75
), machine sizes and precedence proportion. Gap
=
, where B is APSA or SACS and
is the best solution.
The strength of our proposed APSA approach lies in its ability to strike a strong balance between diversification and convergence. The simulated annealing component, on one hand, concentrates on the local improvement of solutions, which helps with convergence. On the other hand, keeping a population of solutions prevents the search from getting trapped in a local optimum, effectively enhancing the diversity of the search.
5.4. Convergence characteristics of APSA
We examine the convergence of APSA, and compare it to ACS and SACS. We choose four problem instances, which are sufficiently diverse in size to allow making somewhat general inferences about APSA. The results are shown in Figure , where each sub-figure corresponds to one problem instance. The plots show time in seconds on the x-axis and TWT (logarithmic scale) on the y-axis.
Figure 8. Convergence profiles of ACS, SACS and APSA on four RCJSU problem instances of different sizes. The instances chosen are 3–53, 6–28, 9–47 and 12–14. The TWTs on the y-axes are presented on a logarithmic scale.
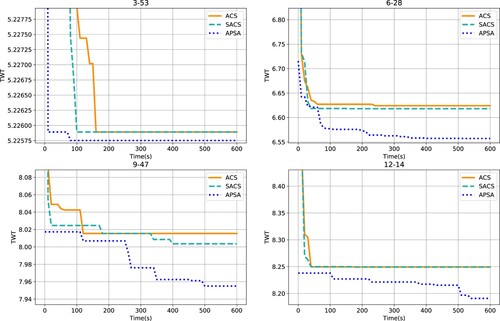
Again, APSA is clearly the best performing method across all four problem instances. There are two main advantages of the algorithm, especially related to the population and diversification. Firstly, the starting solution, irrespective of the problem instance, is better than ACS or SACS. This can be attributed to the use of population, where at the beginning of the search process, there is a substantial amount of diversity in the starting solutions. Secondly, and more importantly, there is continuous improvement in APSA over-time. This can be clearly seen for medium to large problem instances (6–28, 9–47 and 12–14). The increased diversity allowed by the re-initialisation of the solutions in the population ensures that the population does not get stuck in local optima.
5.5. Comparison of APSA to the original SA
The original SA (OSA) algorithm (Singh and Ernst Citation2011) can be adapted to tackle the RCJSU problem.Footnote9 The main difference is that every time a new solution is created, a new objective needs to be computed, which involves creating multiple schedules corresponding to the samples. Otherwise, all the settings for the algorithm remain the same as the original algorithm.
Table presents the results for APSA and OSA at the uncertainty levels 0.6 and 0.9. Except for the smallest problem instances with 3 machines, APSA significantly outperforms the OSA algorithm by achieving better solutions with more than 85% improvement for both uncertainty levels. This result suggests that the novel components integrated into APSA, including solution population, adaptive probabilistic selection, and a quicker cooling schedule, lead to substantial advancements beyond the traditional OSA approach.
Table 4. A comparison of APSA and the original SA (Singh and Ernst Citation2011) (OSA) for the uncertainty levels of 0.6 and 0.9; Results for each algorithm are highlighted in bold when they achieve best average results, while statistically significant results (pair-wise Wilcoxon ranked-sum test) at a 95 confidence interval are marked with a *.
5.6. Effects of population on APSA
We investigate how the population size influences the performance of our proposed APSA approach. To do this, we compare APSA with a population size of 10 against a version of APSA without a population, effectively having a population size of 1.
The results are presented in Table , with comparisons conducted on instances with uncertainty levels of 0.6 and 0.9. Notably, APSA with a population size of 10 clearly outperforms the one without a population, and this advantage increases with higher uncertainty levels. This result underscores the significance of incorporating a solution population into our algorithm.
Table 5. A comparison of APSA with different population sizes, v = 10 and v = 1, on the problem instances with uncertainty levels of 0.6 and 0.9; Results for each algorithm are highlighted in bold when they achieve best average results, while statistically significant results (pair-wise Wilcoxon ranked-sum test) at a 95 confidence interval are marked with a *.
5.7. Comparisons on the deterministic problem
APSA's advantages obtained from the population, a quicker cooling schedule and adaptive probabilistic selection for the perturbation of solutions, make for an effective algorithm in the uncertain setting. Its performance on the deterministic problem or RCJS is worth investigating, to see if any of the novelties proposed in the algorithm can be beneficial for the deterministic problem. The results are shown in Table , where APSA to ACS, SACS, and a column generation and ACO hybrid (CGACO) are compared.
Table 6. A comparison of CGACO (Thiruvady, Singh, and Ernst Citation2014), ACS, SACS and APSA on RCJS.
CGACO is also run 25 times on each problem instance. A single sample was used for ACS, SACS and APSA, leading to the original resource limit (effectively RCJS). We see in Table that beyond small problem instances (> 4 machines), APSA has a clear advantage. It generally performs best, but without the same large gains seen on RCJSU.
5.8. Insights gained from APSA
APSA is proven to be effective on the RCJSU problem, and especially across problem instances with wide-ranging resource utilisations, network complexities and machine sizes. In particular, the experimental analysis of APSA shows that the complex RCJSU problem can be tackled efficiently. Being time efficient means that this approach can be used to gain insights into mining operations thereby assisting with management decisions. In particular, the timely arrival of ore at ports means that there are little or no losses in transporting the ore to its final destination, and moreover, insights can be gained into how larger quantities of ore can be mined and transported efficiently. Additionally, further problem components related to this problem could be introduced and tackled efficiently. This aspect will be considered in future work.
6. Conclusion
This study investigates an optimisation problem that originates in the mining industry, specifically transporting ore from mines to ports. Past studies have considered the problem as deterministic, however, in real settings, the resources needed to transport the ore are subject to uncertainty. The problem is also called resource constrained job scheduling with uncertainty, where for this study, we consider multiple uncertain scenarios. To tackle this problem, we propose an adaptive population-based simulated approach, which has significant advantages over previously proposed ACO based approaches. We find that using a population, increasing the rate of the cooling schedule within the Metropolis-Hastings algorithm and adaptively selecting intensification and diversification via the neighbourhood moves, proves advantageous. These modifications, compared to traditional simulated annealing, lead to finding robust solutions, and hence, best results on a benchmark dataset for RCJSU.
Despite the success of APSA on RCJSU, investigating how the approach performs on other optimisation problems with uncertainty will be of interest in future work. In particular, it is expected an adaptation of APSA is likely to be effective for problems that consist of highly constrained disjoint feasible regions, such as RCJSU. These include other scheduling problems, such as project scheduling, job shop scheduling, and flow shop scheduling, where minor changes will be required to APSA in the representation and evaluation approach. Additionally, the application of APSA to other combinatorial optimisation problems will mainly require an effort to identify suitable neighbourhood structures. Otherwise, it can be adapted in a relatively straightforward manner to tackle other combinatorial optimisation problems.
The MIP model in Section 3 is clearly too complex and large for existing solvers, but decomposition approaches such as column generation or Benders' decomposition may prove effective. The advantage of such methods is that they can provide guarantees of solution quality (via lower bounds to RCJSU), which can help to measure the quality of the solutions found by APSA.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
The authors confirm that the data supporting the findings of this study are available within the article.
Additional information
Notes on contributors

Dhananjay Thiruvady
Dhananjay Thiruvady is Associate Head of School (Industry Research) and Senior Lecturer (Mathematics and Optimisation) at the School of IT, Deakin University. He received his PhD in Optimisation from Monash University, Australia, in 2012. His expertise is in developing methods derived from artificial intelligence (constraint programming, nature-based meta-heuristics, Bayesian networks) and mathematical programming. He works at the interface of academia and industry and has applied the techniques he has developed to mining, scheduling, health and biosecurity. He has published over 60 journal and conference papers in high-ranked venues such as IEEE Transactions on Evolutionary Computation, International Journal of Production Research, Computers and Operations Research and International Journal of Production Economics. He serves on the program committees of conferences such as Genetic and Evolutionary Computation Conference and the Australasian Data Mining Conference.

Su Nguyen
Su Nguyen is a Senior Lecturer (AI and Analytics) at RMIT University, Australia. He received his Ph.D. degree in Artificial Intelligence and Operations Research from Victoria University of Wellington (VUW), Wellington, New Zealand, in 2013. His expertise includes simulation-optimisation, evolutionary computation, automated algorithm design, interfaces of artificial intelligence and operations research, and their applications in logistics, energy, and transportation. Nguyen has a strong track record in developing simulation models, simulation-based decision support tools, and simulation-optimisation algorithms for industry applications. He has 70+ publications in top peer-reviewed journals and conferences in computational intelligence and operations research. His current research focuses on hybrid intelligence systems that combine the power of modern artificial intelligence technologies and operations research methodologies. He was the chair (2014-2018) of IEEE task force on Evolutionary Scheduling and Combinatorial Optimisation and is a member of IEEE CIS Data Mining and Big Data technical committee. He delivered tutorials about evolutionary simulation-optimisation and AI-based visualisation at Parallel Problem Solving from Nature Conference (2018), IEEE World Congress on Computational Intelligence (2020), and Genetic and Evolutionary Computation Conference (2022).

Yuan Sun
Yuan Sun is a Lecturer in Business Analytics and Artificial Intelligence at La Trobe University, Australia. He received his BSc in Applied Mathematics from Peking University, China, and his PhD in Computer Science from The University of Melbourne, Australia. His research interest is on artificial intelligence, machine learning, operations research, and evolutionary computation. He has contributed significantly to the emerging research area of leveraging machine learning for combinatorial optimisation. His research has been published in top-tier journals and conferences such as IEEE TPAMI, IEEE TEVC, EJOR, NeurIPS, ICLR, VLDB, ICDE, and AAAI.

Fatemeh Shiri
Fatemeh Shiri is a research fellow in the Vision and Language discipline group at the Faculty of IT, Monash University. She completed her studies at the Australian National University and Data61-CSIRO, where she developed deep learning approaches for computer vision tasks and time-series data. She has a strong background in computer vision, natural language processing, and machine learning, and has published in high-ranking conferences and journals, including IEEE Transactions on Pattern Analysis and Machine Intelligence and International Journal of Computer Vision. She has collaborated extensively with industry partners, particularly in projects involving natural language processing with DSTG (Defence Science and Technology Group).

Nayyar Zaidi
Nayyar Zaidi is a member of Centre for Cyber Resilience and Trust (CREST) at Deakin University and leads AI activities of the group. He works as Sr. Lecturer at Deakin University, Burwood, Australia. Dr. Zaidi is a distinguished researcher in Machine Learning and Artificial Intelligence, and has a track record of publishing in top journals such as 'Journal of Machine Learning Research', 'Springer Machine Learning', 'Springer DMDK', etc. His pure research constitutes topics in ‘data generation’, ‘robust machine learning’, ‘large-scale machine learning’, and ‘effective feature engineering’. His applied research is focussed on ‘network security anomaly detection’, ‘human dialogue evaluation, ‘financial risk management’, etc. He has published over 40 peer-reviewed articles and serves as program committee member for major conferences such as IEEE ICDM, KDD, IJCAI, SDM, PAKDD and many others.

Xiaodong Li
Xiaodong Li received his Ph.D. degree in Artificial Intelligence from University of Otago, Dunedin, New Zealand. He is a professor in Artificial Intelligence currently with the School of Computing Technologies, RMIT University, Melbourne, Australia. His research interests include machine learning, evolutionary computation, data mining/analytics, multiobjective optimisation, multimodal optimisation, large-scale optimisation, deep learning, math-heuristic methods, and swarm intelligence. He served as an Associate Editor of journals including IEEE Transactions on Evolutionary Computation, Swarm Intelligence (Springer), and International Journal of Swarm Intelligence Research. He is a founding member of IEEE CIS Task Force on Swarm Intelligence, a former vice-chair of IEEE Task Force on Multi-modal Optimization, and a former chair of IEEE CIS Task Force on Large Scale Global Optimization. He is the recipient of 2013 ACM SIGEVO Impact Award and 2017 IEEE CIS ‘IEEE Transactions on Evolutionary Computation Outstanding Paper Award’. He is an IEEE Fellow, and an IEEE CIS Distinguished Lecturer (2024–2026).
Notes
3 Benchmark datasets obtained from the project scheduling problem library (PSPLIB) (Kolisch and Sprecher Citation1997).
4 We refer the reader to the study by Thiruvady et al. (Citation2022) for a detailed discussion of uncertainty in respect to this problem.
5 Note, evolutionary algorithms have been investigated for RCJSU (Thiruvady et al. Citation2022), but have not proved successful. Hence, we do not directly compare APSA to these approaches in this study.
6 https://github.com/andreas-ernst/Mathprog-ORlib/blob/master/data/RCJS_Instances.zip consists of problem instances for RCJS. The resource usage within the problem instances is modified to generate problem instances for RCJSU (Thiruvady et al. Citation2022).
7 These settings are obtained by considering resource utilisation and complexity observed from the real-world situations investigated in Singh and Ernst (Citation2011).
9 Full details of the algorithm can be found in Singh and Ernst (Citation2011), and due to space limitations, we do not provide the full algorithm or its description here.
References
- Beck, J. Christopher, and Nic Wilson. 2007. “Proactive Algorithms for Job Shop Scheduling with Probabilistic Durations.” Journal of Artificial Intelligence Research 28: 183–232. https://doi.org/10.1613/jair.2080
- Bierwirth, Christian, and Dirk C. Mattfeld. 1999. “Production Scheduling and Rescheduling with Genetic Algorithms.” Evolutionary Computation 7 (1): 1–17. https://doi.org/10.1162/evco.1999.7.1.1
- Blum, C., D. Thiruvady, A. T. Ernst, M. Horn, and G. Raidl. 2019. “A Biased Random Key Genetic Algorithm with Rollout Evaluations for the Resource Constraint Job Scheduling Problem.” In AI 2019: Advances in Artificial Intelligence, edited by J. Liu and J. Bailey, 549–560. Cham: Springer International Publishing.
- Chaari, T., S. Chaabane, N. Aissani, and D. Trentesaux. 2014. “Scheduling under Uncertainty: Survey and Research Directions.” In 2014 International Conference on Advanced Logistics and Transport (ICALT), 229–234. IEEE.
- Chakrabortty, Ripon K., Ruhul A. Sarker, and Daryl L. Essam. 2017. “Resource Constrained Project Scheduling with Uncertain Activity Durations.” Computers & Industrial Engineering 112:537–550. https://doi.org/10.1016/j.cie.2016.12.040
- Cheng, Runwei, Mitsuo Gen, and Yasuhiro Tsujimura. 1999. “A Tutorial Survey of Job-Shop Scheduling Problems Using Genetic Algorithms, Part II: Hybrid Genetic Search Strategies.” Computers & Industrial Engineering 36 (2): 343–364. https://doi.org/10.1016/S0360-8352(99)00136-9
- Cohen, D., A. Gómez-Iglesias, D. Thiruvady, and A. T. Ernst. 2017. “Resource Constrained Job Scheduling with Parallel Constraint-Based ACO.” In Artificial Life and Computational Intelligence, edited by M. Wagner, X. Li, and T. Hendtlass, 266–278. Cham: Springer International Publishing.
- Davari, Morteza, and Erik Demeulemeester. 2019. “A Novel Branch-and-Bound Algorithm for the Chance-Constrained Resource-Constrained Project Scheduling Problem.” International Journal of Production Research 57 (4): 1265–1282. https://doi.org/10.1080/00207543.2018.1504245
- Demeulemeester, Erik, and Willy Herroelen. 2011. “Robust Project Scheduling.” Foundations and Trends® in Technology, Information and Operations Management 3 (3–4): 201–376. http://dx.doi.org/10.1561/0200000021.
- Ernst, A. T., and G. Singh. 2012. “Lagrangian Particle Swarm Optimization for a Resource Constrained Machine Scheduling Problem.” In 2012 IEEE Congress on Evolutionary Computation, 1–8. IEEE.
- Gao, K., F. Yang, M. Zhou, Q. Pan, and P. N. Suganthan. 2019. “Flexible Job-Shop Rescheduling for New Job Insertion by Using Discrete Jaya Algorithm.” IEEE Transactions on Cybernetics 49 (5): 1944–1955. https://doi.org/10.1109/TCYB.6221036
- Ghasemi, M., S. M. Mousavi, S. Aramesh, R. Shahabi-Shahmiri, E. K. Zavadskas, and J. Antucheviciene. 2023. “A New Approach for Production Project Scheduling with Time-Cost-Quality Trade-Off Considering Multi-Mode Resource-Constraints under Interval Uncertainty.” International Journal of Production Research 61 (9): 2963–2985. https://doi.org/10.1080/00207543.2022.2074322.
- Granville, V., M. Krivanek, and J.-P. Rasson. 1994. “Simulated Annealing: A Proof of Convergence.” IEEE Transactions on Pattern Analysis and Machine Intelligence 16 (6): 652–656. https://doi.org/10.1109/34.295910
- Herroelen, W., and R. Leus. 2005. “Project Scheduling under Uncertainty: Survey and Research Potentials.” European Journal of Operational Research 165 (2): 289–306. https://doi.org/10.1016/j.ejor.2004.04.002
- Hoos, Holger H., and Thomas Stützle. 2015. Stochastic Local Search Algorithms: An Overview. Heidelberg, Berlin: Springer. 1085–1105.
- Khodakarami, Vahid, Norman Fenton, and Martin Neil. 2007. “Project Scheduling: Improved Approach to Incorporate Uncertainty Using Bayesian Networks.” Project Management Journal 38 (2): 39–49. https://doi.org/10.1177/875697280703800205
- Kolisch, Rainer. 1996. “Serial and Parallel Resource-Constrained Project Scheduling Methods Revisited: Theory and Computation.” European Journal of Operational Research 90 (2): 320–333. https://doi.org/10.1016/0377-2217(95)00357-6
- Kolisch, Rainer, and Arno Sprecher. 1997. “PSPLIB–A Project Scheduling Problem Library: OR Software–ORSEP Operations Research Software Exchange Program.” European Journal of Operational Research 96 (1): 205–216. https://doi.org/10.1016/S0377-2217(96)00170-1
- Lambrechts, Olivier, Erik Demeulemeester, and Willy Herroelen. 2011. “Time Slack-Based Techniques for Robust Project Scheduling Subject to Resource Uncertainty.” Annals of Operations Research 186 (1): 443–464. https://doi.org/10.1007/s10479-010-0777-z
- Liang, Yangyang, Nanfang Cui, Xuejun Hu, and Erik Demeulemeester. 2020. “The Integration of Resource Allocation and Time Buffering for Bi-Objective Robust Project Scheduling.” International Journal of Production Research 58 (13): 3839–3854. https://doi.org/10.1080/00207543.2019.1636319
- Luke, S. 2013. Essentials of Metaheuristics. 2nd ed. San Francisco, California: Lulu. https://cs.gmu.edu/∼sean/book/metaheuristics/.
- Masmoudi, Malek, and Alain Hait. 2013. “Project Scheduling under Uncertainty Using Fuzzy Modelling and Solving Techniques.” Engineering Applications of Artificial Intelligence 26 (1): 135–149. https://doi.org/10.1016/j.engappai.2012.07.012
- Moradi, Hadi, and Shahram Shadrokh. 2019. “A Robust Scheduling for the Multi-Mode Project Scheduling Problem with a Given Deadline under Uncertainty of Activity Duration.” International Journal of Production Research 57 (10): 3138–3167. https://doi.org/10.1080/00207543.2018.1552371
- Nguyen, S., and D. Thiruvady. 2020. “Evolving Large Reusable Multi-Pass Heuristics for Resource Constrained Job Scheduling.” In 2020 IEEE Congress on Evolutionary Computation (CEC), 1–8. IEEE.
- Nguyen, Su, Dhananjay Thiruvady, Andreas T. Ernst, and Damminda Alahakoon. 2019. “A Hybrid Differential Evolution Algorithm with Column Generation for Resource Constrained Job Scheduling.” Computers & Operations Research 109:273–287. https://doi.org/10.1016/j.cor.2019.05.009
- Nguyen, Su, Dhananjay Thiruvady, Mengjie Zhang, and Damminda Alahakoon. 2021. “Automated Design of Multipass Heuristics for Resource-Constrained Job Scheduling With Self-Competitive Genetic Programming.” IEEE Transactions on Cybernetics 52:1–14
- Nguyen, Su, Mengjie Zhang, and Kay Chen Tan. 2018. “Adaptive Charting Genetic Programming for Dynamic Flexible Job Shop Scheduling.” In Proceedings of the Genetic and Evolutionary Computation Conference, GECCO ’18, 1159–1166. New York, USA: ACM.
- Ong, Yew-Soon, Meng Hiot Lim, and Xianshun Chen. 2010. “Memetic Computation-Past, Present & Future.” IEEE Computational Intelligence Magazine 5 (2): 24–31. https://doi.org/10.1109/MCI.2010.936309
- Optimization, Gurobi. 2010. “Gurobi Optimizer Version 5.0.” https://www.gurobi.com/.
- Ouelhadj, Djamila, and Sanja Petrovic. 2008. “A Survey of Dynamic Scheduling in Manufacturing Systems.” Journal of Scheduling 12 (4): 417–431. https://doi.org/10.1007/s10951-008-0090-8
- Singh, G., and A. T. Ernst. 2011. “Resource Constraint Scheduling with a Fractional Shared Resource.” Operations Research Letters 39 (5): 363–368
- Singh, G., and R. Weiskircher. 2008. “Collaborative Resource Constraint Scheduling with a Fractional Shared Resource.” In IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology, Vol. 2, 359–365. IEEE.
- Singh, G., and R. Weiskircher. 2011. “A Multi-Agent System for Decentralised Fractional Shared Resource Constraint Scheduling.” Web Intelligence and Agent Systems 9 (2): 99–108. https://doi.org/10.3233/WIA-2011-0208
- Song, Wen, Donghun Kang, Jie Zhang, Zhiguang Cao, and Hui Xi. 2019. “A Sampling Approach for Proactive Project Scheduling under Generalized Time-Dependent Workability Uncertainty.” Journal of Artificial Intelligence Research 64 (1): 385–427. https://doi.org/10.1613/jair.1.11369
- Thiruvady, D., C. Blum, and A. T. Ernst. 2020. “Solution Merging in Matheuristics for Resource Constrained Job Scheduling.” Algorithms 13 (10): 256–287. https://doi.org/10.3390/a13100256
- Thiruvady, D., A. T. Ernst, and G. Singh. 2016. “Parallel Ant Colony Optimization for Resource Constrained Job Scheduling.” Annals of Operations Research 242 (2): 355–372. https://doi.org/10.1007/s10479-014-1577-7
- Thiruvady, Dhananjay, Su Nguyen, Fatemeh Shiri, Nayyar Zaidi, and Xiaodong Li. 2022. “Surrogate-Assisted Population Based ACO for Resource Constrained Job Scheduling with Uncertainty.” Swarm and Evolutionary Computation69:101029. https://doi.org/10.1016/j.swevo.2022.101029
- Thiruvady, D., G. Singh, and A. T. Ernst. 2014. “Hybrids of Integer Programming and ACO for Resource Constrained Job Scheduling.” In Hybrid Metaheuristics: 9th International Workshop, HM 2014, edited by M. J. Blesa, C. Blum, and S. Voß, Vol. 8457, 130–144. Hamburg: LNCS.
- Thiruvady, D., G. Singh, A. T. Ernst, and B. Meyer. 2012. “Constraint-Based ACO for a Shared Resource Constrained Scheduling Problem.” International Journal of Production Economics 141 (1): 230–242. https://doi.org/10.1016/j.ijpe.2012.06.012
- Valls, V., S. Quintanilla, and F. Ballestin. 2003. “Resource-Constrained Project Scheduling: A Critical Activity Reordering Heuristic.” European Journal of Operational Research 149 (2): 282–301. https://doi.org/10.1016/S0377-2217(02)00768-3
- Van De Vonder, S., E. Demeulemeester, W. Herroelen, and R. Leus. 2006. “The Trade-Off Between Stability and Makespan in Resource-Constrained Project Scheduling.” International Journal of Production Research 44 (2): 215–236. https://doi.org/10.1080/00207540500140914
- Wang, Du-Juan, Feng Liu, Yan-Zhang Wang, and Yaochu Jin. 2015. “A Knowledge-Based Evolutionary Proactive Scheduling Approach in the Presence of Machine Breakdown and Deterioration Effect.” Knowledge-Based Systems 90:70–80. https://doi.org/10.1016/j.knosys.2015.09.032
- Wang, Dujuan, Yunqiang Yin, and Yaochu Jin. 2020. Rescheduling under Disruptions in Manufacturing Systems: Models and Algorithms. Singapore: Springer.
Appendix 1. Parameter tuning
APSA shown in Algorithm 1 consists of parameters including the population size v, number of iterations of the Metropolis-Hastings method Iter, the cooling schedule parameter γ and the adaptation parameter ρ. γ is obtained from the study by Singh and Ernst (Citation2011), and ρ was determined through tuning by hand. To determine v and Iter, we carry out experiments on a subset of the problem instances by considering problem size and then selecting them randomly. The instances chosen are 4–61, 8–53, 12–14 and 20–6. Table shows the results for . We see that a small (v = 1) or very large population (v = 20) is inefficient. The best choice is between
or v = 10 with v = 5 being preferred for larger problem instances and v = 10 being preferred for smaller-medium problem instances. Since there is no clear advantage, we select v = 10 as the choice for further experiments.
Table A1. A comparison of APSA variants with different population sizes, , on selected problem instances (4–61, 8–53, 12–14 and 20–6) with uncertainty levels of 0.6 and 0.9.
Table A2 shows the results for the experiments on the same set of problem instances keeping v = 10 but varying the number of Metropolis-Hastings iterations. We see here that for the small to medium sized instances, APSA with 1000 iterations has an advantage. As the instances get bigger, 5000 iterations is best (12–14) and for the largest instance 10,000 iterations proves most effective. Overall, 1000 iterations has a slight advantage, and hence we use this value for the experiments in this study.
Table A2. A comparison of APSA variants with different levels of Metropolis-Hastings iterations, , on selected problem instances (4–61, 8–53, 12–14 and 20–6) with uncertainty levels of 0.6 and 0.9.
Table shows the results for the experiments on the same set of problem instances keeping and Iter = 1000, but varying γ. We see that for small problem instances, 0.2 or a very fast cooling schedule is most effective. For the medium sized problem instances, 0.5 has the advantage, and for the largest instance, the trade-off is between 0.8 and 0.2 depending on the uncertainty level. Interestingly, the original slow cooling schedule of 0.95 proposed by Singh and Ernst (Citation2011), proves ineffective with RCJSU.
Table A3. A comparison of APSA variants with different levels of γ, , on selected problem instances (4–61, 8–53, 12–14 and 20–6) with uncertainty levels of 0.6 and 0.9.