
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The paper deals with active fault diagnosis of stochastic large-scale systems consisting of several subsystems with separate inputs and observations, which are coupled through the system state. The subsystems are described by multiple models expressing their fault-free and faulty behaviour. The transition between the models is governed by a Markov chain. The paper proposes a distributed design of an active fault diagnosis algorithm, which takes into account the coupling among the subsystems in all stages of the algorithm. This results in a higher quality of the excitation signal and consequently in better decisions. The numerical example shows the improved performance of the proposed algorithm in comparison with the algorithms based on the decentralised design.
1. Introduction
Complexity and degree of integration of large-scale systems (LSSs) increase their liability to faults with possible catastrophic consequences. Therefore, they have to be detected reliably and as quickly as possible by a fault diagnosis (FD) system. The literature recognises two fundamental approaches that differ in the interaction with the monitored system. In the passive approach (Blanke et al., Citation2016; Gustafsson, Citation2009; Isermann, Citation2011; Katipamula & Brambley, Citation2011; Yao et al., Citation2019), the decisions generated by an FD system are based on passive observations of the monitored system measurable quantities. When the active approach is chosen, besides the decisions, the FD system generates an input signal to excite the monitored system (Ashari et al., Citation2012; Niemann & Poulsen, Citation2014; Punčochář et al., Citation2015; Raimondo et al., Citation2016). Its purpose is to obtain more information, which helps to detect faults that may pose a challenge for the passive FD. The active FD (AFD) approach has gained in popularity in the last decade (Campbell & Nikoukhah, Citation2004; Heirung & Mesbah, Citation2019; Niemann, Citation2006; Paulson et al., Citation2017; Scott et al., Citation2014; Stoustrup & Niemann, Citation2010). Within the AFD for stochastic systems, the multiple-model framework is used almost exclusively to describe fault-free and faulty models of the system (Blackmore et al., Citation2008; Škach et al., Citation2016).
Limited communication bandwidth and available computational power are two main reasons for developing special FD algorithms for the LSSs (Ferrari et al., Citation2012; Raimondo et al., Citation2016). In Punčochář and Straka (Citation2019) and Straka and Punčochář (Citation2019), a new AFD framework for stochastic LSSs was introduced involving three architectures – centralised, decentralised, and distributed. In the centralised architecture, all calculations are performed by a single central node, while in the decentralised architecture, the calculations are performed by multiple isolated nodes each tied to a single LSS subsystem. The distributed architecture is similar to the decentralised one and in addition, the nodes communicate with each other. The AFD algorithms consist of (i) the off-line stage, dealing with the design of the excitation input and decision generators, and (ii) the on-line stage, dealing with the state estimation and utilisation of the designed generators. The LSS consists of several subsystems which are subject to certain dynamic interactions called coupling. The input generator design cannot respect the coupling among the LSS subsystems fully for computational tractability reasons even for small-scale systemsFootnote1. To achieve reasonable computational costs of the AFD algorithm, the input generator design introduced in Punčochář and Straka (Citation2019) and Straka and Punčochář (Citation2019) rested on the decentralised architecture, which completely ignores the coupling. This, however, leads to lower quality of the excitation and consequently to lower quality of the FD.
This paper makes the following contribution: A novel distributed AFD algorithm is designed to take into account the coupling among the LSS subsystems in both stages. Compared to the AFD algorithm proposed by Straka and Punčochář (Citation2019), where the AFD node related to a subsystem uses the information received from other nodes in the on-line stage only, the novelty of the AFD algorithm proposed here lies in the off-line stage where the input signal generator is designed. In the proposed distributed AFD algorithm, the input signal generator related to a subsystem employs conveniently the information about the state of other subsystems to take into account the subsystem coupling. The contribution of the paper lies in a convenient aggregation of the effects of other subsystems (i.e. compressing the information) to achieve feasible computational costs. Note that using the information in the uncompressed form would lead to extreme computational costs of the centralised architecture. The additional information available to the generator improves the quality of the excitation input and consequently the quality of the FD.
The paper is structured as follows: Section 2 provides the LSS specification, decomposition, and the AFD problem formulation. A general solution to the AFD problem is briefly summarised in Section 3. The distributed design for the AFD is proposed in Section 4. The performance of the proposed algorithm is illustrated using two numerical examples in Section 5 and Section 6 draws concluding remarks.
2. AFD problem formulation
2.1. LSS specification
Consider an LSS Σ described at time instant by the following state-space model
(1a)
(1a)
(1b)
(1b) where
and
are the continuous and discrete parts of the LSS state
,
is the input,
is the state noise described by the known probability density function (PDF)
,
is the output, and
is the measurement noise described by the known PDF
. The functions
,
,
, and
are knownFootnote2. Each element
of the discrete set
represents a multi-index into a set of M possible models describing behaviour of the LSS Σ in the fault-free and faulty conditions during a sampling period. The random process
is assumed to be Markov with known transition probability
(2)
(2) The state and measurement noises are white, mutually independent and independent of the initial condition
described by
so thatFootnote3
(3)
(3) for any
. Both the continuous part
of the state
and the discrete part
are unknown and can be inferred indirectly through available
and
.
2.2. LSS decomposition
Since the AFD for the LSS Σ with a centralised architecture is not computationally tractableFootnote4, the decentralised or distributed architectures based on a decomposition of Σ were considered in Punčochář Straka (Citation2019); Straka Punčochář (Citation2019). The LSS Σ (see Figure ) consists of N subsystemsFootnote5 that are coupled through the stateFootnote6
. Each subsystem
has its own inputs
, outputs
, and a set of possible fault-free and faulty models
. It can be described by the following representation
(4a)
(4a)
(4b)
(4b)
(4c)
(4c) where
and
are continuous and discrete parts, respectively, of the local stateFootnote7
of the subsystem
,
is the local input,
is the local state noise described by
,
is the local output,
is the local measurement noise described by
. The functions
,
,
, and
are known. The discrete part
represents an index into the set
, which includes one model representing the behaviour of subsystem
in fault-free condition,
, and
models that represent the behaviour of subsystem in faulty conditions,
.The LSS Σ given by (Equation1a
(1a)
(1a) ) and (Equation2
(2)
(2) ) is assumed to satisfy the following independence conditions:
| (IC-1) | The initial states | ||||
| (IC-2) | The model indices | ||||
Figure 1. The decomposition of an LSS into interconnected subsystems.
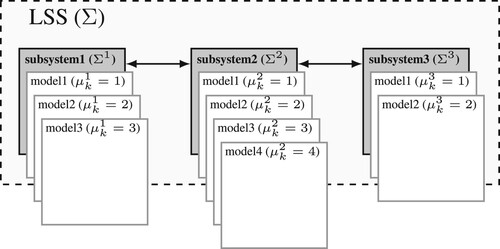
The independence conditions IC-1 and IC-2 mean that the occurrence of a fault in a subsystem does not influence the occurrence of faults in other subsystems. The condition IC-2 is considered for convenience purposes only to make the exposition clear. Note that the AFD problem with coupled faults was treated in Straka and Punčochář (Citation2020b) for conditionally dependent faults and in Straka and Punčochář (Citation2020c) for dependent faults. Relaxation of IC-2 would lead to an introduction of a central node in the on-line stage, whereas the off-line stage would not be affected.
In this paper, the subsystems are coupled only through the continuous state that appears in the dynamics (Equation4a
(4a)
(4a) ) of all subsystems, i.e. besides
, the local continuous state
is affected by the local continuous states of other subsystems
. The AFD algorithm proposed in Punčochář and Straka (Citation2019) approximated the dynamics (Equation4a
(4a)
(4a) ) by neglecting the coupling through
in both stages and the AFD algorithm proposed in Straka and Punčochář (Citation2019) neglected the coupling through
in the off-line stage, where the input signal generator is designed. Such approximation is acceptable if the coupling is weak, in which case the approximation has little effect on the FD quality. However, when the coupling is strongerFootnote9, it should be taken into account by both stages of the AFD design at least to a certain extent. Hence, the paper focuses on the distributed design that considers the coupling.
2.3. AFD problem
For convenience, the AFD problem and its general solution are described for the centralised architecture only. The AFD strives to design a function that transforms the complete available information observed up to the time step k to a decision about the faults (subsystem models) and to an input signal
, which role is to excite the system to improve the detection quality. The AFD system can be described at any time instant as
(5)
(5) where
. The vector
consists of the decisions
about the model indices
,
represents the AFD node decision generator at the time step k,
is the excitation input and
is a function describing the input signal generator. Note that by providing the decision
, the AFD performs the fault detection and the fault identification simultaneously.
The optimal AFD system should minimise the following additive discounted criterionFootnote10
(6)
(6) where
is a chosen discount factor and
is a detection cost function that allows different costs to be assigned for selecting the vector of decisions
while the LSS behaviour is currently governed by the vector of model indices
. The cost function is versatile and may stress the cost of missed detections or false alerts or even the cost of incorrect fault identification. This paper assumes that the costs are not related across the subsystems, and thus the following additive detection cost functionFootnote11 is used
(7)
(7) where
penalises discrepancy between the model index
and the decision
generated by the AFD system.
For an example of two models, if missed detection (,
) and false alert (
,
) are perceived as equally bad by a designer, it is common to choose
, where
is the Kronecker delta. On the other hand, if a missed detection has more serious consequences compared to a false alarm, the choice
specifies the cost of the missed detection by several orders of magnitude higher than the cost of the false alert (Nelles, Citation2014).
3. General solution to AFD problem
The AFD problem formulation presented in the previous section belongs to the class of imperfect state information problems as only the history is available for control or decision making instead of the state
(Bertsekas, Citation2000). These problems are difficult to address directly for the infinite time horizon as the dimension of
increases without limit. A solution is to assume that the optimal AFD node can be split into an optimal state estimator that uses the Bayesian recursive relations (Bar-Shalom et al., Citation2001) to compute a conditional PDF
and a decision-making law that maps this conditional PDF into the input
and decision
(Bertsekas, Citation2000; Bertsekas & Shreve, Citation1996). Given the optimal state estimator, the original problem can be recast as a perfect state information problem where only the decision-making law is to be designed based on a new model consisting of the original model coupled with the optimal state estimator.
The conditional PDF calculated by the state estimator can be represented exactly or approximately using a finite number of statistics. The statistics collected into an information state
evolve in time as
(8)
(8) where
represents the state estimator associated with the LSS Σ model. Here, the future output
is regarded as a random disturbance described by the conditional PDF
and the initial condition
contains statistics describing the conditional PDF
.
Given the information state , it suffices to consider a time invariant AFD node that is described at a time step
as
(9)
(9) where
and
are unknown functions to be sought. The detection cost function for the perfect state information model equivalent to L in (Equation6
(6)
(6) ) can be shown (Bertsekas, Citation2000) to satisfy
(10)
(10) Having the reformulated problem specification, the optimal AFD node is determined by the Bellman function, which can be computed off-line (Straka & Punčochář, Citation2019) because it depends only on the a priori known PDF
, transition probabilities
, measurement PDF
, cost function
, and the discount factor η. Then, the optimal decisions and optimal inputs can be determined on-line by solving much simpler optimisation problems. More precisely, the Bellman function is required for the optimal input signal generator
while the optimal decision generator
works independently of the Bellman function (Straka & Punčochář, Citation2019). Thus, the AFD algorithm consists of two stages: the off-line stage involved with the design of the input signal generator, which uses the Bellman function, and the on-line stage connected with the state estimation, which generates the decisions and selects the optimal excitation according to the Bellman function.
The computation costs of the Bellman function calculation are extreme for LSSs as the dimension of the information state can be very high even for low-dimensional state
due to the number of subsystems and their models. Consider, for example, an LSS with N subsystems each described by
models (one model for fault-free behaviour and one model for faulty behaviour). It leads to N-dimensional index
and the information state
consists of
statistics of
and
probabilities
.
For this reason, the input signal generator design proposed in Punčochář and Straka (Citation2019) and Straka and Punčochář (Citation2019) uses solely the decentralised architectureFootnote12, which ignores the coupling among the subsystems and calculates the Bellman function for each subsystem separately using approximate models that are mutually isolated. Thus, each subsystem has its own information state of a significantly smaller dimension than the LSS information state and the computation of the Bellman function related to the subsystem is tractable.
The aim of the distributed design proposed in this paper is to take into account the coupling of the subsystems during the design of the input generator. Thus, the quality of the excitation signal and subsequently of the detection should be improved by using more information from other subsystems that are available in the distributed architecture. Such design comes with lower computational costs than the centralised design.
4. AFD with distributed design
The main idea of the AFD with distributed design is that the information about the LSS state communicated among the AFD nodes will be used not only to generate the decision (Straka & Punčochář, Citation2019) but also to generate the excitation input.
Distributed state estimation: First, the perfect state information model is constructed for the distributed architecture. The estimation algorithm in each AFD node consists of four steps (Straka & Punčochář,Citation2019):
Prediction – calculation of
;
Filtering – calculation of
Merging – calculation of the approximation
Fusion – calculation of
The symbol denotes a composition of the past globalFootnote14 data
related to the whole system Σ and the present data
, and
related to the subsystem
only, i.e.
(11)
(11) The estimation algorithm is illustrated in Figure for two nodes
and
.The dashed arrow loop represents the estimation algorithm, which can be expressed using the perfect state information model as
(12)
(12) where
differs from
in (Equation8
(8)
(8) ) because the filtering, merging, and prediction steps are performed locally at the AFD node level.
Figure 2. Scheme of distributed AFD algorithm.
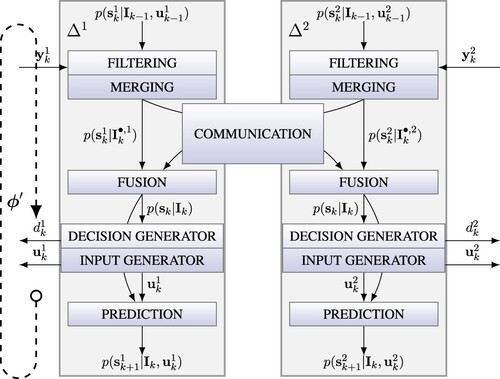
Distributed AFD node : Two problems are associated with the model (Equation12(12)
(12) ). First, the dimension of the information state
is too large for the Bellman function calculation. Second, the Bellman function calculation for the nth node
requires running the estimation algorithms for all subsystems. The first problem will be addressed by aggregating the effects of other subsystems to reduce the order of the statistic. The second problem will be dealt with by a suitable global model approximation.
4.1. Reducing model order by aggregation
The dimension of the statistic can be reduced if the dynamics function of each subsystem
can be decomposed as
(13)
(13) where
is a function that aggregates the effects of other subsystems
on the subsystem
, and
is a function that combines this aggregated effect with the local effects of
. A reduced order form of the model (Equation4a
(4a)
(4a) ) for the subsystem
can be written as
(14a)
(14a)
(14b)
(14b)
(14c)
(14c) where
is a new
-dimensional random variable defined as
(15)
(15) Note that the dimension of all arguments of the function
is
and a reduction of the dimension is actually achieved only if
is less than
for all subsystems.
Typical examples of subsystem dynamics that are particularly suitable in this regard are additive models. A nonlinear additive model has the following structure
(16)
(16)
(17)
(17) where
represents the local effect and
with
aggregates effect of other subsystems. The additive linear model has an even simpler structure
(18)
(18) where
,
,
and
are matrices related to the subsystem
. The linear additive model is attractive especially from a computational point of view because having the Gaussian conditional PDF of
, the aggregated effect
(19)
(19) can be represented exactly by the mean and covariance matrix for each
.
To complete the model (Equation14a(14a)
(14a) ), the dynamics for the new random variable
could be defined using (Equation15
(15)
(15) ) and the dynamics of other subsystems. Nevertheless, it is more convenient to consider the conditional PDF
, which can be obtained from
using (Equation15
(15)
(15) ). The evolution of the conditional PDF
can be described by the following model
(20)
(20) where
is a mapping that encapsulates the distributed estimation algorithm and the model of the LSS Σ. The dimension of the statistic needed to describe this conditional PDF is less than the dimension of statistic that would be needed without aggregating the effect of other subsystems. Nevertheless, the mapping
is not suitable for the distributed design of the AFD because the inputs
and observations
of the whole LSS are involved. This issue is treated in the following section.
4.2. Local approximation of the reduced order model
Since the dependence on inputs and observations of other subsystems in the model (Equation20(20)
(20) ) comes from the distributed estimation algorithm through
, the proposed approximation aims to neglect this influence by assuming that
is independent of
and its stochastic properties are time-invariant. The particular consequences of this approximation for the distributed estimation algorithm are as follows. The conditional PDF
can be factorised using the conditional independence of
and
as
(21)
(21) where
is a known PDF of
conditioned by
. This conditional PDF approximates
at all time steps, i.e.
(22)
(22) Note that the time index is left out intentionally to emphasise that this conditional PDF is time-invariant. The prediction step of the distributed estimation algorithm uses this approximation to compute
(23)
(23) where
is given by (Equation14c
(14c)
(14c) ) and the state noise PDF
. The filtering and merging steps of the distributed estimation algorithm are performed without any change and result in the conditional PDF
. The fusion step does not need to be performed due to the independence induced by the approximation (Equation22
(22)
(22) ).
The final local approximate model of a reduced order can be written using the statistic computed by the estimation algorithm. If the conditional PDF is described by the statistic
and the conditional PDF
is described by the statistic
, the local approximate model can be written as
(24)
(24) where
represents a modified distributed estimation algorithm with the reduced order model (Equation14
(14a)
(14a) ).
Since the overall detection cost function (Equation7(7)
(7) ) is additive over individual subsystems, the detection cost function for the AFD node
is given as
(25)
(25) The distributed AFD node for the subsystem
is a time invariant system that is described at a time step k as
(26)
(26) where
and
are unknown functions. They can be designed in a way similar to Straka and Punčochář (Citation2019), which considered the AFD description (Equation9
(9)
(9) ).
The proposed approximation can be interpreted as follows: In addition to the time-varying statistic , which represents an estimate of the local state, the Bellman function is also parametrised by time-invariant statistic
that represents the influence of other subsystems. As a result, the Bellman function takes into account the coupling among the LSS subsystems.
4.3. Algorithm of AFD with distributed design
Now, each step of the algorithm is specified for a node , with a special focus on the steps important for the distributed design. Details of other steps can be found in Straka and Punčochář (Citation2020a).
Assume: The prediction PDF is available.
Filtering: Infer the filtering PDF using the Bayesian rule.
Merging: The generalised pseudo-Bayesian method of the second-order (GPB2) (Watanabe & Tzafestas, Citation1993) is used to compute the approximation .
Fusion: The AFD nodes communicate their filtering estimates. The estimates received by the AFD node are fused to obtain
.
Statistic construction: The statistic corresponding to
and the statistic
are computed from the statistic
for the fused PDF
using relation (Equation15
(15)
(15) ).
Decision generation: The decision is given by (Equation26
(26)
(26) ).
Input generation: The input is given by (Equation26
(26)
(26) ).
Prediction: The prediction PDF is calculated using the Chapman–Kolmogorov equation.
5. Numerical illustration
The performance of the proposed distributed AFD is illustrated by means of two simple numerical examples.
Example 5.1
Consider the system Σ that consists of two coupled multiple-model linear subsystems
where n = 1, 2,
, both subsystems have two models (
) with
The models
and
represent the fault-free behaviour and the models
and
represent the faulty behaviour. The transition probabilities of the models for each subsystem are given in Table .
Table 1. Transition probabilities of the models.
The state noises and measurement noises
have all standard Gaussian PDF
. The initial condition
has Gaussian PDF
and initial
has probability
, which means that each subsystem is fault-free at the beginning. The admissible inputs of subsystems are
. The detection cost function
penalises missed detections and false alerts equally using the zero-one function
(28)
(28) The discount factor is
.
Performance of the following algorithms is analysed:
passive FD (PFD) with random input generator with
PFD with switching input generator
AFD with decentralised design and decentralised estimation proposed in Straka and Punčochář (Citation2019), which neglects the coupling in both stages.
AFD with decentralised design and distributed estimation proposed in Straka and Punčochář (Citation2019), which neglects the coupling in the off-line stage only.
The proposed distributed AFD (see Section 4) that respects the coupling among the subsystems during both on-line and off-line stages.
The state estimation was carried out by a bank of Kalman filters. The dimension of the information state was
(29)
(29) where
is the dimension of the sufficient statistics for
consisting of
-dimensional mean and
elements of the covariance matrix and
is the number of probabilities
in the information state. For the decentralised design, the information state of each AFD node has dimension
while for the distributed design the information states were
dimensional with the increase caused by the statistic
aggregating the coupling effect. It should be noted, that the centralised design of the AFD would require a single
dimensional information state, which means immense memory requirements even for such a simple system.
The Bellman function was calculated by the value iteration algorithm over a grid of discrete information states. The distributed design used the grid , where
Thus, the grids and
are related to the aggregated effect of other subsystems
. The decentralised design used the grid
. The number of discrete states was 900375 for the grid of
and 25725 for the grid
.
The performance of the algorithms was evaluated using Monte Carlo (MC) simulations where each MC simulation was run over the finite time horizon F = 400. The estimate
of the criterion (Equation6
(6)
(6) ) obtained by the MC simulations, the probabilities of missed detection (
) and false alerts (
), and time requirementsFootnote15
of a single MC run are given in Table .
Table 2. Performance of decentralised and distributed PFD and AFD architectures for Example 5.1.
By comparing the results, it is clear that AFD achieves performance superior to PFD. Within the PFD algorithms, the switching input generator excites the system better than the random input generator. Also, when using the distributed estimation, the detection quality is better than when using the decentralised estimation. Within the AFD algorithms, the best detection quality (in terms of the criterion, missed detections and false alerts) is achieved by the proposed distributed AFD algorithm. The values achieved by the decentralised and distributed estimation confirm that it is worth respecting the coupling during the on-line stage of the algorithm even if the Bellman function calculation ignores the coupling.
The computational times of the on-line stage of the algorithms indicate that using the decentralised estimation is computationally cheaper than using the distributed estimation because it does not execute the fusion step. When analysing the computational times of the proposed algorithm, it can be seen that the usage of the extended information state is computationally very cheap with respect to other steps of the on-line stage.
Example 5.2
This example is adapted from Harirchi et al. (Citation2017). An apartment consisting of four rooms equipped with a radiant heating system is considered. The system can be described by a linear state-space continuous-time model
where the list of parameters and variables is given in Table and the parameter values are
,
,
,
,
,
,
,
.
Table 3. Building parameters and variables.
The continuous-time model was discretised with a sampling period of 5 min and an error-state model was set up with a separate input, an independent state noise, and direct measurement of the room air temperature for each room. The steady-state values were
,
,
,
,
. The fault-free model is then
with
,
, noise
being the deviation from a nominal ambient air temperature modelled as Gaussian random variable
,
The measurement noise has standard Gaussian PDF
, the initial condition has Gaussian PDF
. The faulty behaviour represented sensor faults
,
,
,
,
,
. The matrix of transition probabilities of the models was
and the LSS behaviour was initially fault-free. The admissible inputs of subsystems are
. The detection cost function
is the zero-one function (Equation28
(28)
(28) ). The discount factor is
.
The state estimation was again carried out by a bank of the Kalman filters. The Bellman function was calculated by the value iteration algorithm over grids of discrete information states with and
where
The number of discrete states was 3, 306, 744 for the grid and 61, 236 for the grid
. Here, it should be emphasised, that the centralised architecture would require a single
dimensional information state, whereas the decentralised and distributed architectures require four
dimensional and
dimensional information states, respectively.
The performance of the algorithms was evaluated using the Monte Carlo (MC) simulations where each MC simulation was run over the finite time horizon F = 400, i.e. 2000 min. The estimate
of the criterion (Equation6
(6)
(6) ) obtained by the MC simulations, the probabilities of missed detection (
) and false alerts (
), and time requirements
of a single MC run are given in Table .
Table 4. Performance of decentralised and distributed PFD and AFD architectures for Example 5.2.
The results confirm superior performance of the AFD algorithms. Among them, the best performance is achieved by the proposed distributed AFD. The reason lies again in the utilisation of the additional information from the other nodes. The results also indicate that using the distributed architecture at least in the on-line stage improves the detection quality. When analysing the computational costs, it follows that the costs are affected by (i) the architecture used by the on-line stage (decentralized architecture neglecting the coupling is cheaper than the distributed architecture, in which the nodes must fuse the estimates obtained from other nodes) and (ii) the dimension of the Bellman function representation as the proposed AFD with distributed design leads to its higher dimension and consequently to computational costs related to the manipulations with the Bellman function.
6. Conclusion
The paper dealt with active fault diagnosis for large-scale systems that can be decomposed into subsystems with separate measurements and inputs. The subsystem behaviour was described by stochastic multiple models representing the fault-free and faulty behaviour. The inputs were utilised by the AFD to excite the system to achieve better fault detection. An AFD algorithm was developed by means of the distributed design so that the coupling among the subsystems is taken into account in both the on-line and off-line stages. The excitation generated by the proposed distributed AFD algorithm leads to better detection of the faults appearing in the subsystems. The improved performance of the proposed AFD algorithm was confirmed by two numerical examples, which also showed that the computational costs of the on-line part of the algorithm are comparable with the AFD algorithms with decentralised design and the price for the improved performance is paid by the increased memory requirements of the Bellman function representation. Nevertheless, the memory requirements are still significantly lower than for the centralised design.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
Ondřej Straka
Ondřej Straka received the master's degree in cybernetics and control engineering and the Ph.D. degree in cybernetics from the University of West Bohemia, Pilsen, Czech Republic, in 1998 and 2004, respectively. Since 2015, he has been an Associate Professor with the Department of Cybernetics, University of West Bohemia. He is the Head of the Identification and Decision Making Research Group (IDM), NTIS–New Technologies for the Information Society. He has participated in a number of projects of fundamental research and in several project of applied research (e.g. GNSS- based safe train localisation and attitude and heading reference system). He was involved in the development of several software frameworks for nonlinear state estimation and system identification. He has published over 70 journal and conference papers in journals, such as Automatica, the IEEE Transactions on Automatic Control, the IEEE Transactions on Aerospace and Electronic Systems, the IEEE Transactions on Cybernetics, and Signal Processing and at international conferences such as American Control Conference, World Congresses and Symposia of the IFAC, and FUSION Conferences. His current research interests include local and global nonlinear state estimation methods, system identification, performance evaluation, and fault detection. Dr. Straka was a recipient of Werner von Siemens Excellence Award in 2014 for the most important result in the basic research.
Ivo Punčochář
Ivo Punčochář received the master's degree in cybernetics and control engineering and the Ph.D. degree in cybernetics from the University of West Bohemia, Pilsen, Czech Republic, in 2003 and 2008, respectively. Since 2014 he is a senior researcher at the research centre New Technologies for the Information Society at the University of West Bohemia. He is also a member of the Identification and Decision Making Research Group established there. He has participated in several projects of fundamental and applied research that dealt with fault detection, state estimation, and GNSS-based safe positioning. He has published over 30 conference and journal papers. His primary research interests include active fault detection, optimal stochastic control and global navigation satellite systems. He was a member of team that received the Werner von Siemens Excellence Award in 2014 for the most important outcome of basic research.
Notes
1 As will be shown in the numerical example.
2 The functions are assumed to be Borel measurable.
3 The variable denoted with j>i stands for the whole sequence of variables from time i to time j stacked into a column vector.
4 The centralised architecture is connected with a high-dimensional information state (see Section 3), which prohibits design of the input generator.
5 A symbol with the superscript pertains to the corresponding subsystem (e.g. ), whereas a symbol without the superscript relates to the whole LSS (e.g. Σ).
6 The quantities of the LSS are compositions of the quantities of its subsystems as ,
,
,
,
, and
.
7 Note that is called local state for convenience, even though it is not technically a state of the subsystem due to the coupling.
8 With a slight abuse of terminology, the function will be called PDF although
is a discrete random variable. A more formal notation would require using the cumulative distribution function or the Dirac delta function instead of the PDF.
9 For example, neglecting the energy flow between the subsystems would dramatically worsen the model quality.
10 The operator denotes the expectation over all involved random variables.
11 The cost function is assumed to be lower semi-analytic.
12 The algorithms differ in the architecture used for the on-line stage.
13 If the information from other nodes is not available (e.g. due to communication problems), approximate models have to be used, which neglect the coupling. This corresponds to the (partially) decentralised architecture.
14 It should be reminded that this global information was obtained by the AFD nodes during the information communication and subsequent fusion at the previous time instant k−1.
15 All the numerical simulations in the paper were performed using the R2019a version of Matlab software running on the PC equipped with Intel
CoreTM i7–4790 CPU (3.60 [GHz]). Note that although the on-line stages should run in parallel at each AFD node, they were executed sequentially for all nodes in the simulations.
References
- Ashari, A. E., Nikoukhah, R., & Campbell, S. L. (2012). Active robust fault detection in closed-loop systems: Quadratic optimization approach. IEEE Transactions on Automatic Control, 57(10), 2532–2544. https://doi.org/10.1109/TAC.2012.2188430
- Bar-Shalom, Y., Li, X. R., & Kirubarajan, T. (2001). Estimation with applications to tracking and navigation. John Wiley & Sons.
- Bertsekas, D. P. (2000). Dynamic programming and optimal control (2nd ed., Vol. I). Athena Scientific.
- Bertsekas, D. P., & Shreve, S. E. (1996). Stochastic optimal control: The discrete-time case. Athena Scientific.
- Blackmore, L., Rajamanoharan, S., & Williams, B. C. (2008). Active estimation for jump Markov linear systems. IEEE Transactions on Automatic Control, 53(10), 2223–2236. https://doi.org/10.1109/TAC.2008.2006100
- Blanke, M., Kinnaert, M., Lunze, J., & Staroswiecki, M. (2016). Diagnosis and fault-tolerant control (3rd ed.). Springer-Verlag.
- Campbell, S. L., & Nikoukhah, R. (2004). Auxiliary signal design for failure detection. Princeton University Press.
- Ferrari, R. M. G., Parisini, T., & Polycarpou, M. M. (2012). Distributed fault detection and isolation of large-scale discrete-time nonlinear systems: An adaptive approximation approach. IEEE Transactions on Automatic Control, 57(2), 275–290. https://doi.org/10.1109/TAC.2011.2164734
- Gustafsson, F. (2009). Automotive safety systems. IEEE Signal Processing Magazine, 26(4), 32–47. https://doi.org/10.1109/MSP.2009.932618
- Harirchi, F., Yong, S. Z., Jacobsen, E., & Ozay, N. (2017). Active model discrimination with applications to fraud detection in smart buildings. IFAC Papers Online, 50(1), 9527–9534. https://doi.org/10.1016/j.ifacol.2017.08.1616. (20th IFAC World Congress)
- Heirung, T. A. N., & Mesbah, A. (2019). Input design for active fault diagnosis. Annual Reviews in Control, 47(9), 35–50. https://doi.org/10.1016/j.arcontrol.2019.03.002
- Isermann, R. (2011). Fault-diagnosis applications. Springer.
- Katipamula, S., & M. R. Brambley (2011). Review article: Methods for fault detection, diagnostics, and prognostics for building systems – a review, part II. HVAC&R Research, 11(2), 169–187. https://doi.org/10.1080/10789669.2005.10391133
- Nelles, O. (2014). Nonlinear system identification: From classical approaches to neural networks and fuzzy models. Springer.
- Niemann, H., & Poulsen, N. K. (2014, June). Active fault detection in MIMO systems. In Proceedings of the 2014 American Control Conference (pp. 1975–1980). Institute of Electrical and Electronics Engineers Inc.
- Niemann, H. H. (2006). A setup for active fault diagnosis. IEEE Transactions on Automatic Control, 51(9), 1572–1578. https://doi.org/10.1109/TAC.2006.878724
- Paulson, J. A., Martin-Casas, M., & Mesbah, A. (2017). Input design for online fault diagnosis of nonlinear systems with stochastic uncertainty. Industrial & Engineering Chemistry Research, 56(34), 9593–9605. https://doi.org/10.1021/acs.iecr.7b00602
- Punčochář, I, & Straka, O. (2019). Non-centralized active fault diagnosis for stochastic systems. In 2019 American control conference. Institute of Electrical and Electronics Engineers Inc.
- Punčochář, I., Široký, J., & Šimandl, M. (2015). Constrained active fault detection and control. IEEE Transactions on Automatic Control, 60(1), 253–258. https://doi.org/10.1109/TAC.2014.2326274
- Raimondo, D. M., Boem, F., Gallo, A., & Parisini, T. (2016). A decentralized fault-tolerant control scheme based on active fault diagnosis. In Proceedings of the 55th IEEE conference on decision and control (pp. 2164–2169). Institute of Electrical and Electronics Engineers Inc.
- Raimondo, D. M., G. R. Marseglia, Braatz, R. D., & Scott, J. K. (2016). Closed-loop input design for guaranteed fault diagnosis using set-valued observers. Automatica, 74(2), 107–117. https://doi.org/10.1016/j.automatica.2016.07.033
- Scott, J. K., Findeisen, R., Braatz, R. D., & Raimondo, D. M. (2014). Input design for guaranteed fault diagnosis using zonotopes. Automatica, 50(6), 1580–1589. https://doi.org/10.1016/j.automatica.2014.03.016
- Škach, J., Punčochář, I., & Lewis, F. L. (2016). Optimal active fault diagnosis by temporal-difference learning. In Proceedings of the 55th IEEE conference on decision and control (pp. 2146–2151). Institute of Electrical and Electronics Engineers Inc.
- Stoustrup, J., & Niemann, H. H. (2010). Active fault diagnosis by controller modification. International Journal of Systems Science, 41(8), 925–936. https://doi.org/10.1080/00207720903470197
- Straka, O., & Punčochář, I. (2019). Decentralized and distributed active fault diagnosis for stochastic systems with indirect observations. In 22nd international conference on information fusion. Institute of Electrical and Electronics Engineers Inc.
- Straka, O., & Punčochář, I. (2020a). Decentralized and distributed active fault diagnosis based on interactive multiple models. International Journal of Applied Mathematics and Computer Science, 30(2), 239–249. https://doi.org/10.34768/amcs-2020-0019
- Straka, O., & Punčochář, I. (2020b). Distributed active faults diagnosis for systems with conditionally dependent faults. IFAC Papers Online, 53(2), 13613–13618. https://doi.org/10.1016/j.ifacol.2020.12.857
- Straka, O., & Punčochář, I. (2020c). Hierarchical active fault diagnosis for stochastic large scale systems with coupled faults. In 2020 IEEE 23rd international conference on information fusion (p. 1–8). Institute of Electrical and Electronics Engineers Inc.
- Watanabe, K., & Tzafestas, S. G. (1993). Generalized pseudo-Bayes estimation and detection for abruptly changing systems. Journal of Intelligent and Robotic Systems, 7(1), 95–112. https://doi.org/10.1007/BF01258214
- Yao, L., Li, L., Guan, Y., & Wang, H. (2019). Fault diagnosis and fault-tolerant control for non-Gaussian nonlinear stochastic systems via entropy optimisation. International Journal of Systems Science, 50(13), 2552–2564. https://doi.org/10.1080/00207721.2019.1671535