
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Nonlinear dynamics is frequently encountered in practical applications. Adaptive dynamic programming (ADP), which is implemented via actor/critic neural networks with excellent approximation capabilities, is appropriate to be used in finding the solution for the control problem in the presence of known/unknown nonlinear dynamics. The objective of this paper is to introduce state-of-the-art ADP-based algorithms and survey the recent advances in the ADP-based control strategies for nonlinear systems with various engineering-oriented complexities. Firstly, the main motivation of the ADP-based algorithms is thoroughly discussed, and the way of implementing the ADP-based algorithms is highlighted. Then, the latest research results concerning ADP-based control policy design for nonlinear systems are reviewed in detail, Finally, we conclude the survey by outlining the challenges and possible research topics in the future.
1. Introduction
In the past decades, optimal control has drawn particular research attention owing to its wide applications in various engineering fields (e,g., power systems, finance, ecology, and aerospace) (Ding et al., Citation2019, Citation2020; Wang et al., Citation2022). Optimal control aims at minimising (or maximising) a performance index function for the addressed system subject to some physical constraints such as some limitations on the states and the control inputs (Prokhorov et al., Citation1995). From the mathematical point of view, optimal control theory solves a class of functional extreme value problems with constraints (Lewis & Vrabie, Citation2009). It is well recognised that the optimal control policy is often parameterised by solving a Hamilton–Jacobi–Bellman (HJB) equation. For a linear system, the HJB equation can be simplified to one Riccati equation which can be easily solved. Unfortunately, when it comes to the optimal control problem for a nonlinear system, it is a challenging problem to develop effective strategies to solve the corresponding HJB equation subject to the effects of nonlinearities.
As is well known, reinforcement learning has been a promising research front in recent years (Deb et al., Citation2007). In reinforcement learning, an agent interacts with the external environment and improves the actions or control policies based on the reward/punishment stimulus from the external environment. One representative reinforcement learning approach is developed based on the actor/critic neural networks (Enns & Si, Citation2003; Xue et al. (Citation2022)), and the implementation process can be divided into two steps: (1) policy evaluation: an actor neural network (ANN) exerts a control policy on the external environment, and then a critic neural network (CNN) evaluates the cost of this control policy (i.e. the response from the external environment); and (2) policy improvement: based on the policy evaluation, the control policy is improved with hope to achieve a better control performance compared with the previous control policy (Mohahegi et al., Citation2006). Such a two-step process is repeated until the cost of the control policy can satisfy specific standards (Beard & Saridis, Citation1998; Wang et al., Citation2009).
Inspired by reinforcement learning, the so-called adaptive dynamic programming (ADP), which was developed based on the reward/punishment mechanisms (Beard & Saridis, Citation1998), is regarded as an effective method to find solutions to optimal control problems for nonlinear systems. The ADP-based control scheme is implemented based on the actor/critic neural networks, and the core idea of the scheme is utilising two neural networks (i.e. CNN and ANN) to approximate the cost function and the optimal control policy, respectively (Liu et al., Citation2021; Vamvodakis & Lewis, Citation2010; Wang et al., Citation2009). To date, the ADP-related topics have received an increasing amount of research interest and the researchers have mainly focused on the following aspects: (1) the improvements of the ADP algorithms; (2) the design of the updating laws of neural network weights; (3) the convergence analysis of the ADP algorithms; and (4) the applications of the ADP algorithms to various practical control problems.
In engineering applications, complex external environments and physical constraints are often unavoidable, which makes the systems subject to various engineering-oriented complexities (Chen et al., Citation2022; Gao et al., Citation2021; Ma et al., Citation2022; Pang et al., Citation2021; Tian et al., Citation2010; Wei et al. Citation2022; Xu et al. Citation2020; Zhang et al., Citation2022; Zhang & Song, Citation2022; Zhang & Zhou, Citation2022). The engineering-oriented complexities can be generally categorised into network-oriented complexities and physics-oriented complexities (Ma et al., Citation2021; Shi et al., Citation2022). The network-oriented complexities, which are induced by the network-based transmission schemes, mainly contain communication protocols, event-triggered mechanisms, cyber-attacks, and so on Liu et al. (Citation2022), Pinto et al. (Citation2022), Zhang et al. (Citation2022), and Zhu et al. (Citation2022). The physics-oriented complexities are caused by the constraints of transmission networks and system components, and frequently-occurring physics-oriented complexities mainly include time delays, nonlinearities, sensor/actuator saturation constraints, faults, and so on L. Chen et al. (Citation2021), Liu et al. (Citation2022), Tan et al. (Citation2022), Zhao et al. (Citation2015), and Zhang et al. (Citation2021). The engineering-oriented complexities may decrease the reliability of signal transmissions and complicate the system dynamics, and further lead to degradation or deterioration of the corresponding system performance (Liu et al., Citation2022; Qian et al., Citation2020; Wang et al., Citation2022b). Therefore, the effects of the underlying complexities should be fully taken into consideration in the controller design and performance analysis. So far, the control problem for systems with different engineering-oriented complexities have attracted considerable attention from both academic researchers and engineering practitioners (Ming et al., Citation2022; Xu et al., Citation2015).
Based on the above discussion, this paper aims to give a review of the existing results on the ADP-based control methods for nonlinear systems with various engineering-oriented complexities. The organisation of this paper is shown in Figure . In Section 2, the basic idea and the implementation process of the ADP-based algorithms are introduced in detail. In-depth overviews of the recent research advances related to the applications of the ADP-based algorithms under network-oriented complexities and physics-oriented complexities are given in Sections 3 and 4, respectively. Section 5 lists some challenging issues in the research field of ADP. Section 6 concludes the survey and points out some meaningful topics for future research.
Figure 1. The organisation structure of this survey.

2. ADP-Based algorithm
The ADP-based algorithm is a suboptimal control scheme proposed with actor/critic neural networks. In this section, to facilitate the understanding of the ADP-based algorithms, we will firstly elaborate the difficulties in dynamic programming for nonlinear systems, and then introduce the implementation process of the ADP-based algorithms.
2.1. The difficulties of dynamic programming for nonlinear systems
The key idea of dynamic programming is Bellman's optimality principle, i.e. the global optimum must be the local optimum (Lewis & Vrabie, Citation2009). By resorting to the principle, a multi-step optimisation problem can be transformed into many one-step optimisation problems, and in this way, the decision making (or control) process can be executed continuously. The details of dynamic programming are given as follows.
Consider a class of discrete-time systems with the following form:
(1)
(1) where
,
, and
, respectively, represent the state vector, the control input, and the measurement output,
is a bounded nonlinear function, and
is the disturbance satisfying
and
is a known constant. A, B, C, D and E are known matrices with compatible dimensions. The cost function is defined as
(2)
(2) where
denotes the utility function with
, and
is positive for any nonzero
and
. According to the Bellman's optimality principle, the cost function (Equation2
(2)
(2) ) can be rewritten as
(3)
(3) The target of optimal control is to minimise or maximise (Equation3
(3)
(3) ) by designing a control policy. According to the HJB equation
we obtain the optimal cost function
and the optimal control policy
(4)
(4) Based on the above discussion, it is obvious that finding the solution to the optimal control problem through dynamic programming follows a backward manner. Based on (Equation4
(4)
(4) ),
is a pre-condition to derive the optimal control policy
, and the full knowledge of the system (Equation1
(1)
(1) ) (e.g. A, B, and
) is required. For a continuous-time system, the full knowledge of the system dynamics is necessary as well. Unfortunately, in engineering practice, it is difficult to obtain all the system information due to the complicated application environments, the limited economic budget, and the uncertainty of the system itself (Dong et al., Citation2008). It is often the case that the nonlinear function
is unknown. On the other hand, even if the nonlinear function
is known, the optimisation problem (Equation4
(4)
(4) ) needs to be solved in a backward manner, but the system state is calculated in a forward-in-time way, which leads to the well-known ‘curse of dimensionality’ and therefore poses huge challenges to the applications of dynamic programming in engineering practice (Yadav et al., Citation2007; Zhang et al., Citation2008). Considering the difficulties in implementing dynamic programming, the ADP, which is carried out in a forward-in-time manner, has been proposed as a proper approach to solve the optimal control problems for systems with nonlinear dynamics (Beard & Saridis, Citation1998; Mohahegi et al., Citation2006).
2.2. The implementation of the ADP-based algorithm
As shown in Figure , in light of the evaluation-improvement structure, two neural networks (i.e. the CNN and the ANN) are employed to approximate the cost function (Equation2(2)
(2) ) and the optimal control policy (Equation4
(4)
(4) ) in an online manner (Abu-Khalaf et al., Citation2006; Al-Tamimi et al., Citation2007, Citation2008; Balakrishnan & Biega, Citation1996; Cheng et al., Citation2007; Song et al., Citation2021). The weights of the two neural networks are updated adaptively, and in this way, the approximation errors of the two neural networks can be minimised (Havira & Lewis, Citation1972; Liu et al., Citation2005; Shervais et al., Citation2003; Tesauro, Citation1992).
Figure 2. The implementation of the ADP-based algorithm.
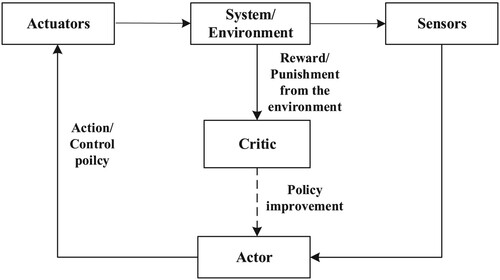
It is worth noting that there have been many researchers focusing on the improvement of ADP-based algorithms, and accordingly, many remarkable results have been reported (Ferrari et al., Citation2008; Kim & Lim, Citation2008; Padhi et al., Citation2006). The ADP-based algorithm to be introduced is proposed for the nonlinear discrete-time systems and belongs to the output feedback policy. The details of the algorithm are given as follows.
Consider a class of discrete-time systems in the form of (Equation1(1)
(1) ) and
denotes the bounded known/unknown nonlinear function.
With the help of the universal approximationstrategy, (Equation1(1)
(1) ) can be written as
where
,
, and
denote the bounded optimal weight matrix, the activation function, and the approximation error of the nonlinear neural network, respectively.
For the purpose of generating desired state estimates, the following neural network-based observer is constructed:
(5)
(5) where
is the estimate of
,
represents the estimate of
at the instant k, and L is the observer gain matrix to be designed.
In view of the gradient decent method, the updating rule of is chosen as
(6)
(6) where
is the tuning scalar of the nonlinear neural network.
The cost function (Equation2(2)
(2) ) and the control policy (Equation4
(4)
(4) ), which need to be approximated by the CNN and the ANN, respectively, are written as
and
where
,
and
represent the desired weight matrix, the activation function, and the approximate error of the CNN, respectively.
,
and
denote the desired weight matrix, the activation function, and the approximate error of the ANN, respectively. The above-mentioned variables are all assumed to be bounded.
In light of the universal approximation property, we utilise neural networks to approximate and
, i.e.
and
(7)
(7) where i is the iteration index, and
(
, respectively) is the estimate of
(
, respectively) at iteration i of time instant k. By resorting to the distinctive learning ability of neural networks, the cost function and the solution of the HJB equation are approximated in an iterative way, and the iteration will continue until
.
Defining as the residual error which is used to evaluate the approximation accuracy of the CNN, we have
By minimising
via the gradient decent approach, we can obtain the following updating law for the weight of the CNN
(8)
(8) where
is the CNN tuning scalar.
Next, according to the HJB equation, we have
Define
and assume
is an invertible function. Then, the suboptimal optimal policy can be expressed as
where
. Similarly, define
as the control input error. By minimising
, we can obtain the updating law for the weight of the ANN
(9)
(9) where
is the ANN tuning scalar.
The convergence of the introduced ADP-based algorithm has been proved in Al-Tamimi et al. (Citation2008). Furthermore, in Ding et al. (Citation2019), the stability of the nonlinear system (Equation1(1)
(1) ) has been analysed, and the boundedness has been proved with respect to the estimation error of the system state, the nonlinear neural network weights, and the CNN/ANN weights.
3. ADP-based algorithms under network-oriented complexities
In recent years, the network-based transmission technique has found successful applications in a large number of modern industrial systems due to its distinctive advantages in saving economic costs, reducing implementation difficulty, and decreasing hardwiring (Li et al., Citation2022). Nevertheless, compared with traditional point-to-point transmission strategies, the network-based transmission schemes give rise to some network-oriented complexities (e.g. communication protocols, event-triggered mechanisms, signal quantisation, packet losses, and cyber-attacks) owing to the unavoidable vulnerability and restricted bandwidth of transmission networks (Jiang et al., Citation2022; Wang et al., Citation2022a). The network-oriented complexities would inevitably degrade or even destroy the control/estimation performance if not handled properly. In this section, we focus on the summary of recent advances in ADP-based control policy design under various network-oriented complexities, and the considered network-oriented complexities mainly include communication protocols, event-triggered mechanisms, and cyber-attacks. To facilitate understanding, in each subsection, we will firstly give a brief introduction of the corresponding network-oriented complexities, and then present the relevant literature review.
3.1. ADP-Based algorithms under the scheduling of communication protocols
Network congestion, which is an inevitable phenomenon in many industrial applications, mainly results from the frequent signal transmissions between system components (i.e. sensors, estimators, and controllers) over a shared communication network with limited bandwidth (Dong et al., Citation2022; Li et al., Citation2022; Shen et al., Citation2022; Yao et al., Citation2022). Correspondingly, various communication protocols are often adopted to govern the signal transmission process to prevent collisions in the signal transmission process (Liu et al., Citation2022; Xu et al., Citation2022). Under the scheduling of communication protocols, only one sensor node is permitted to transmit the current signal at each time instant (Xu et al., Citation2021). In engineering practice, the widely adopted communication protocols include, but are not limited to, the Round-Robin communication protocol, the stochastic communication protocol, and the try-once-discard communication protocol (Xu et al., Citation2022).
Before proceeding further, let us utilise a simple example to illustrate the effects of the protocol scheduling. Define as the node accessing to the communication network selected by the protocol,
as the measurement signal of the jth sensor node, and
as the signal collected at the receiving end. The scheduling behaviours of the communication protocols can be characterised by the following transmission model:
(10)
(10) where
and
denotes the Kronecker delta function with the following form
is a time-varying variable representing the scheduling behaviour of the considered communication protocols. The system under communication protocol scheduling can be regarded as a switched system, and the switching behaviour is dependent on
. Hence, to design the control strategy and analyse the performance for the nonlinear systems under communication protocols scheduling, we need to modify the traditional ADP-based methods introduced in Subsection 2.2. Obviously, the time-varying nature of
complicates the system dynamics and poses significant challenges to the design of state estimation scheme (Equation5
(5)
(5) ), control strategy (Equation7
(7)
(7) ), and the updating laws of neural network weights (i.e. (Equation6
(6)
(6) ), (Equation8
(8)
(8) ), and (Equation9
(9)
(9) )).
So far, the ADP-based control issues for nonlinear systems under communication protocol scheduling are still in their infancy despite their clear practical significance. Under the scheduling of the stochastic communication protocol, N sensor nodes are stochastically scheduled to transmit the measurement signals to the estimator. For example, the discrete-time Markov chain has been utilised to describe in Ding et al. (Citation2019) and the system has been written as a stochastic parameter-switching system. Then, a novel control strategy has been proposed in Ding et al. (Citation2019) for the nonlinear discrete-time systems under the stochastic communication protocol scheduling. The results in Ding et al. (Citation2019) have been extended in Wang et al. (Citation2021), where the ADP-based approach has been employed to address the optimal control issue for the nonlinear discrete-time systems with stochastic communication protocols and input constraints. Different from that of the stochastic communication protocol, the scheduling behaviour of the Round-Robin communication protocol can be modelled by a periodic function, and therefore the system can be seen as a periodic parameter-switching system (
if
, where
is the function calculating the non-negative reminder). In Ding et al. (Citation2019), the ADP-based optimal output feedback controller has been designed for the nonlinear discrete-time systems with Round-Robin protocol.
3.2. ADP-Based algorithms under event-triggered mechanisms
In engineering practice, the sensors are usually equipped with energy-limited batteries, and signal transmissions between system components are usually the main cause of energy consumption (Cui et al., Citation2021; Gu et al., Citation2018; Shen et al., Citation2021; Wang & Wang, Citation2022; Xue et al. Citation2022; Zhu et al., Citation2022). For the purpose of energy saving, event-triggered mechanisms have been broadly adopted in engineering (Liu et al., Citation2022; Ma et al., Citation2021; Wang et al., Citation2022; Xie et al., Citation2017). Under event-triggered mechanisms, the signal transmissions between system components are activated only when the pre-specified triggering condition is satisfied. The triggering condition is dependent on the triggering threshold and the system state (Li et al., Citation2021). The triggering threshold determines when and how the triggering occurs. The triggering threshold should be determined to achieve the balance between the transmission-induced resource assumption and the control/estimation performance. Based on the characteristics of the triggering thresholds, the existing event-triggered mechanisms can be divided into two categories, i.e. the static event-triggered mechanisms (SETMs) with fixed triggering thresholds and the dynamic event-triggered mechanisms (DETMs) with dynamically adjusted thresholds.
Now, let us take a brief look on the SETMs. Define as the tth triggering instant and
as the static event generator as follows:
where
and
is a known constant. For
, the scheduling behaviour is governed by the following model
(11)
(11) where
In the static event-triggered case, owing to the introduction of
, the system dynamics becomes more complex than (Equation1
(1)
(1) ), which presents significant challenges to the design of the estimators (Equation5
(5)
(5) ), the controllers (Equation7
(7)
(7) ) as well as the updating law of the neural network weights (i.e. (Equation6
(6)
(6) ), (Equation8
(8)
(8) ), and (Equation9
(9)
(9) )).
Compared with the SETMs, the DETMs are more preferred in practical engineering since they can dynamically adjust the triggering thresholds and make an adequate trade-off between the energy consumption and the system performance. Define as the dynamic event generator described by
where
and
are two known constants, and
denotes the internal dynamical variable in the following form
where
and
. The scheduling of DETMs can be represented as follows
(12)
(12) where
Different from
,
is dependent on
, which is an internal dynamic variable reflecting the adjustment of the triggering thresholds. In the dynamic event-triggered case, in addition to π and
, the parameter τ and the internal dynamic variable
should also be taken into consideration in the controller design and performance analysis.
To date, considerable research effort has been devoted to the ADP-based control policy design for the networked nonlinear systems with SETMs. By the ADP-based method, the optimal control problem has been handled in Zhu et al. (Citation2017) for a class of nonlinear continuous-time systems, and a new static event-triggered condition has been proposed to reduce computational complexity. The event-triggered strategy in Zhu et al. (Citation2017) has been extended to the nonlinear continuous-time system with input constraints in Song and Liu (Citation2020). For the multi-player continuous-time systems with SETM, the optimal tracking control issue has been converted to the optimal regulation problem, which has been investigated by means of the ADP-based approach in Zhang et al. (Citation2022). In Wu and Wang (Citation2021), the ADP-based suboptimal tracking control approach has been proposed for a class of nonlinear continuous-time systems with partial known measurement signals and SETMs. For the path planning issue for unmanned vehicles, a SETM-based model predictive ADP has been implemented in Hu et al. (Citation2021). For the nonlinear non-affine systems with constrained inputs, a SETM-based control method has been designed in Zhang et al. (Citation2021). In the temperature field, for a special class of discrete-time systems with distributed parameters, the SETMs-based optimal control problem has been addressed by resorting to the ADP-based method in N. Chen et al. (Citation2021). In Deng et al. (Citation2022), an ADP-based control strategy has been proposed for the quarter-car electromagnetic active suspension systems under SETMs in both sensors-to-observer and controller-to-actuator channels.
When it comes to systems under DETMs, the optimal control problem in the ADP framework has also been well investigated. In Han et al. (Citation2021), the DETM-based controller design issue has been considered for the switched affine discrete-time systems with constrained control inputs. Under the DETM, a novel adaptive learning structure has been proposed and the optimal control issue has been studied in Mu et al. (Citation2022) for a class of nonlinear discrete-time systems with two controllers. Via the value-iterative ADP-based algorithm, the DETM-based tracking control strategy has been proposed in Wang et al. (Citation2021) with application to the waste water treatment. The ADP-based optimal control problem has been studied in Wang et al. (Citation2022) for a class of nonlinear discrete-time systems under cyber-attacks and DETMs. In Zhao et al. (Citation2022), the near-optimal consensus tracking control issue has been discussed for the discrete-time multi-agent systems, and the dynamic event-triggered condition has been designed for each agent. By means of the ADP-based approach, the DETM-based stochastic optimal regulation issue has been solved in Ming et al. (Citation2022) for the nonlinear networked continuous-time systems with delayed control inputs.
3.3. ADP-Based algorithms under cyber-attacks
As the communication technologies advances, the digital-network-based communication has been playing a more and more crucial role in the past several decades. Considering the inherent and longstanding openness of networks, the systems adopting network-based transmission schemes are especially vulnerable to cyber-attacks, which may lead to performance degradation or even instability (Chen et al., Citation2022; Niu et al., Citation2020; Wang et al., Citation2022). Generally speaking, the cyber-attacks for networked systems can be classified into three types, i.e. denial-of-service (DoS) attacks, deception attacks, and replay attacks (Gao et al., Citation2022; Tao et al., Citation2022; Xiao et al., Citation2021). DoS attacks block the signal transmissions between system components by congesting the transmission channels (Zhao et al., Citation2022). In the case of deception attacks, the measurements/control inputs are maliciously modified (Cui et al., Citation2021; He et al., Citation2020). Replay attacks aim to repeat or delay the transmitted signals (Zhu & Martinez, Citation2014).
Due to its opening-up characteristic, an NCS could be susceptible to cyber-attacks leading to performance degradation or even system instability. Accordingly, the cyber-security research has been gaining growing popularity as to how to guarantee satisfactory performance under the effects of possible cyber-attacks (Cheng et al., Citation2022; Yuan et al., Citation2020; Zhu et al., Citation2021).
Now let us take DoS attacks as an example to briefly introduce the effects of the cyber-attacks. Denoting as the sth attack instant for the networked nonlinear systems subject to DoS attacks, we have the following model
(13)
(13) where
reflects the DoS attacks featured by
In the existing literature, Bernoulli distributedsequence and Markov chain have usually been adopted to characterise the occurrence of the DoS attacks (Yuan et al., Citation2020). Obviously, the attack-induced switch parameter
complicates the system dynamics and thereby brings in difficulties to the design of the estimator (Equation5
(5)
(5) ), the control strategy (Equation7
(7)
(7) ), and the selection of updating laws of the neural network weights (i.e. (Equation6
(6)
(6) ), (Equation8
(8)
(8) ), and (Equation9
(9)
(9) )).
So far, in the ADP framework, systems subject to cyber-attacks have just received some initial research attention. In Yang et al. (Citation2018), a security control strategy has been developed for the nonlinear discrete-time systems in the presence of actuator saturation and DoS attacks. With ADP-based methods, the structure optimisation problem has been solved for the multi-machine power system under DoS attacks (Zhu et al., Citation2021). In Cheng et al. (Citation2022), a distributed secondary control strategy has been proposed for the battery energy storage system subject to DoS attacks. Inspired by the basic idea of the two-player zero-sum game, the optimal control issue has been addressed for the nonlinear continuous-time systems in Lian et al. (Citation2021), where three neural networks have been utilised to approximate the critic, the actor, and the deception attack, respectively. The ADP-based resilient control issue has been investigated in Huang and Dong (Citation2021) for the nonlinear continuous-time systems, where the control signals have been transmitted via a communication link under deception attacks.
4. ADP-based algorithms under physics-oriented complexities
In engineering practice, physics-oriented complexities are frequently encountered due mainly to the complex external environments and the physical limitations of system components (Han et al., Citation2021). Representative physics-oriented complexities include faults, time delays, saturation constraints, and nonlinearities (Qu et al., Citation2021; Sun et al., Citation2022). If not fully considered in the design of the control strategies, the influences of the physics-oriented complexities may deteriorate the system performance or even result in instability (Sun & van Kampen, Citation2021; Zhang et al., Citation2021). In this section, recent research advances are reviewed with regard to the ADP-based control policy design under various physics-oriented complexities. The considered physics-oriented complexities include time delays and saturation constraints. In each subsection, the engineering backgrounds will be briefly introduced at first for the corresponding physics-oriented complexities, and then the relevant literature reviews will be given.
4.1. ADP-Based algorithms under time delays
Time delay, which results from the finite signal transmission speed and the vulnerability of the networks, is a ubiquitous network-induced phenomenon (Jiang et al., Citation2021; Ning et al., Citation2021; Qian et al., Citation2021). Time delays can be categorised into invariant time delays, time-varying delays, and so on Qian et al. (Citation2019) and Zhang et al. (Citation2021). The existence of time delays may degrade the control/estimation performance of the addressed system (Qian et al., Citation2021).
Now, let us briefly introduce the effects of the time delays, where the invariant time delay is taken as an example. The time-delayed systems are represented by the following model:
(14)
(14) where d represents the known invariant time delay. Obviously, the delayed state
makes the system model more complex compared with traditional model (Equation1
(1)
(1) ) of the nonlinear system. As a result, when the control/estimation problems need to be solved for (Equation14
(14)
(14) ),
should be fully taken into consideration. In this case, the ADP-based algorithm has been developed for the time-delayed systems in Ni et al. (Citation2015).
So far, the ADP-based control methodologies have been thoroughly investigated for time-delayed systems. In Zhang et al. (Citation2011), the initial research has been reported on the neural network-based optimal control problem for a class of nonlinear discrete-time systems with delayed inputs and delayed states. In Song et al. (Citation2013), the multi-objective optimal control issue has been investigated for the discrete-time systems with invariant time delays. A dual iterative ADP-based algorithm has been proposed in Wei et al. (Citation2013) for a special class of nonlinear discrete-time systems in consideration of distributed but multiple state/input delays. In Xu et al. (Citation2014), for the nonlinear discrete-time systems with packet losses (in both sensor-to-controller and controller-to-actuator channels) and state delays, the neural network-based stochastic optimal control has been investigated in the framework of zero-sum games. In view of the ADP-based method, the distributed optimal consensus control problem has been studied in Zhang et al. (Citation2018) for a class of multi-agent systems, where the considered time-varying input delays have been dependent on the sampling period. By employing the value-iterative ADP-based algorithm, the optimal control problem has been discussed for nonlinear continuous-time systems with invariant state and input delays in Shi et al. (Citation2020). In Zhu et al. (Citation2021), by adopting the ADP-based approach, the optimal regulation strategy has been established for a class of nonlinear continuous-time systems, where both state and input delays have been considered.
4.2. ADP-Based algorithms under saturation constraints
Because of the harsh external environment and limited economic budgets, system components (e.g. sensors and actuators) in engineering practice are usually subject to physical limitations and influences of protective equipment, which may lead to various saturation constraints (Bao et al., Citation2022; Chen et al., Citation2020; Hou et al., Citation2022; Yuan et al., Citation2019). The saturation constraints include input saturation, state saturation, etc (Chen & Wang, Citation2021).
Let us discuss the impacts of the saturation constraints with input saturation phenomenon as the example. Define as the mth element of
and r as the saturation bound. The control input
belongs to
where
. It is easy to see that the saturation phenomenon introduces an extra nonlinearity to the system dynamics, thereby making the analysis and synthesis of the addressed systems more difficult (He & Jagannathan, Citation2005; Liang et al., Citation2020; Rizvi & Lin, Citation2022).
The ADP-based control problems for the nonlinear systems with saturation constraints have been extensively studied, and much progress has been made on this topic. For the nonlinear continuous-time systems with uncertain interconnections and constrained control inputs, the distributed optimal control policy design problem has been addressed in Tan (Citation2018) via the ADP-based method. Considering the influences of unknown input constraints, the stabilising control issue has been investigated in Zhao et al. (Citation2018). For the mobile manipulation systems with input constraints, an ADP-based hierarchical motion/force control framework has been established in Zhao et al. (Citation2019). By resorting to integral reinforcement learning techniques, the optimal control problem has been solved for the nonlinear continuous-time systems with multiple controllers under input constraints in Ren et al. (Citation2020). In Khankalantary et al. (Citation2020), the robust tracking control problem has been investigated for a class of nonlinear multi-agent systems with input constraints. For the wireless sensor networks with constrained inputs, the event-triggered adaptive control problem has been investigated in the framework of nonzero-sum games in Su et al. (Citation2020). In Ding et al. (Citation2020), the ADP-based consensus control problem has been investigated for the multi-agent systems with input saturation.
In the last two years, the design of ADP-based control strategy has received particularly considerable research attention for the systems with saturation constraints. The decentralised stabilisation issue has been studied for the nonlinear interconnected systems with input constraints in Yang et al. (Citation2021). For the nonlinear systems with constrained inputs, an event-triggered adaptive critic learning scheme has been proposed with a discounted cost function in Yang and Wei (Citation2021). In Liu et al. (Citation2021), by adopting the basic idea of zero-sum games, an adaptive critic has been established. Via integral reinforcement learning techniques, the optimal tracking control problem has been tackled for the nonlinear continuous-time systems with input constraints (Mishra & Ghosh, Citation2022). The adaptive integrated guidance and control issues have been studied for the missile interception systems in Zhang and Yi (Citation2021), where both multiple states and input constraints have been considered. An optimal controller has been designed for the nonlinear systems with state saturation in Xu et al. (Citation2022), where the control barrier function has been considered in the selection of the utility function.
5. Some challenging problems
In the past few decades, significant progress has been made in the research related to the applications of ADP to various systems such as multi-agents, networked systems, nonlinear systems, and affine systems. Many remarkable research results have been published on the analysis, synthesis, and applications of ADP-based algorithms. In this section, some ADP-related challenging issues are listed as follows.
An underlying assumption in most ADPresearches is that the weights of the neural networks, the activation function of the neural networks, and the approximate error of the neural networks are bounded, which is of vital importance for the theoretical analysis of the ADP-based algorithms. Nevertheless, it is usually difficult to acquire the accurate bounds in practical applications, which greatly restricts the applications of the ADP-based approaches.
To guarantee the convergence of the ADP-based algorithm, the initial control input of the iterative ADP-based algorithm should be admissible. Unfortunately, it may be time-consuming to find a satisfying initial control input for a complex system, which brings significant difficulties to the applications of the ADP-based algorithms in engineering practice.
The online implementation of the ADP-based algorithm unavoidably introduces a heavy computing burden, especially when the dimension of the system state is high. It is important but challenging to develop an effective and efficient weight update algorithm in the ADP-based methods.
6. Conclusions and future works
An in-depth review has been presented with respect to the applications of the ADP-based algorithms to systems with various engineering-oriented complexities. Five typical engineering-oriented complexities have been reviewed in this paper, i.e. communication protocols, event-triggered mechanisms, cyber-attacks, time delays, and saturation constraints. Recent advances of the ADP-based control strategies have been reviewed for nonlinear systems with the above-mentioned complexities in great detail. According to the reviewed literature, some research topics which can be investigated in the future are provided as follows:
Nowadays, the ADP-related security control issue has stirred initial research attention, but the implementation of the ADP-based algorithm on large-scale networked control systems (such as complex networks and sensor networks) under deception attacks has not been investigated yet.
To guarantee the ultimate boundedness of the estimation error of neural network weight, linear matrix inequalities have been widely employed. Since the computational complexity and the conservatism are the major concerns of linear matrix inequalities, some other approaches should be developed with reduced computational complexity and conservatism.
In order to facilitate theoretical analysis of ADP-based methods, various assumptions have been made. To further broaden the application field of ADP, how to remove or slacken the strong assumptions is a very meaningful topic with considerable engineering significance.
Much research effort has been devoted to the improvement of the ADP-based algorithms. From the perspective of engineering practice, the comparisons between the performances of different algorithms have not yet attracted enough research attention.
Along with the development of the economy and the society, the application environment is more and more complicated. So far, the improvement of the ADP-based algorithm to systems in more complicated environments has not received enough research attention.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
Date sharing is not applicable to this article as no new data were created or analysed in this study.
Additional information
Funding
Notes on contributors
Yuhan Zhang
Yuhan Zhang received the B.Eng. degree in electronic information science and technology from the Shandong University of Science and Technology, Qingdao, China, in 2016, and the M.Sc. degree in marketing from the University of Nottingham, Nottingham, UK, in 2017. She is currently pursuing the Ph.D. degree in control science and engineering from Shandong University of Science and Technology, Qingdao, China. Yuhan Zhang is a very active reviewer for many international journals.
Lei Zou
Lei Zou received the Ph.D. degree in control science and engineering in 2016 from Harbin Institute of Technology, Harbin, China. He is currently a Professor with the College of Information Science and Technology, Donghua University, Shanghai, China. From October 2013 to October 2015, he was a visiting Ph.D. student with the Department of Computer Science, Brunel University London, Uxbridge, U.K. His research interests include control and filtering of networked systems, moving-horizon estimation, state estimation subject to outliers, and secure state estimation. Professor Zou serves (or has served) as an Associate Editor for IEEE/CAA Journal of Automatica Sinica, Neurocomputing, International Journal of Systems Science, and International Journal of Control, Automation and Systems, a Senior Member of IEEE, a Member of Chinese Association of Automation, a Regular Reviewer of Mathematical Reviews, and a very active reviewer for many international journals.
Yang Liu
Yang Liu received the B.Sc. degree and the Ph.D. degree in the Department of Automation at Tsinghua University, Beijing, China, in 2010 and 2016, respectively.Since 2021, he has been working as a Research Associate in the Department of Aeronautical and Automotive Engineering, Loughborough University, U.K. His research interests include system security, complex networks as well as stochastic systems. He is a Member of IEEE and a Member of Chinese Association of Automation; and a very active reviewer for many international journals.
Derui Ding
Derui Ding received both the B.Sc. degree in Industry Engineering in 2004 and the M.Sc. degree in Detection Technology and Automation Equipment in 2007 from Anhui Polytechnic University, Wuhu, China, and the Ph.D. degree in Control Theory and Control Engineering in 2014 from Donghua University, Shanghai, China. He is currently a Senior Research Fellow with the School of Science, Computing and Engineering Technologies, Swinburne University of Technology, Melbourne, VIC, Australia. His research interests include nonlinear stochastic control and filtering, as well as distributed control, filtering and optimization. He received the 2021 Nobert Wiener Review Award from IEEE/CAA Journal of Automatica Sinica, the 2020 and 2022 Andrew P. Sage Best Transactions Paper Awards from the IEEE Systems, Man, and Cybernetics (SMC) Society, and the IET Premium Awards 2018. He is a Senior Member of the Institute of Electrical and Electronic Engineers (IEEE). He is serving as an Associate Editor for IEEE Transactions on Industrial Informatics, IEEE/CAA Journal of Automatica Sinica, Neurocomputing and IET Control Theory & Applications.
Jun Hu
Jun Hu received the B.Sc. degree in information and computation science and M.Sc. degree in applied mathematics from Harbin University of Science and Technology, Harbin, China, in 2006 and 2009, respectively, and the Ph.D. degree in control science and engineering from Harbin Institute of Technology, Harbin, China, in 2013. From September 2010 to September 2012, he was a Visiting Ph.D. Student in the Department of Information Systems and Computing, Brunel University, U.K. From May 2014 to April 2016, he was an Alexander von Humboldt research fellow at the University of Kaiserslautern, Kaiserslautern, Germany. From January 2018 to January 2021, he was a research fellow at the University of South Wales, Pontypridd, U.K. He is currently Professor in the Department of Mathematics, Harbin University of Science and Technology, Harbin 150080, China. His research interests include nonlinear control, filtering and fault estimation, time-varying systems and complex networks. He has published more than 80 papers in refereed international journals. Dr. Hu serves as a reviewer for Mathematical Reviews, as an editor for Neurocomputing, Journal of Intelligent and Fuzzy Systems, Neural Processing Letters, Systems Science and Control Engineering, and as a guest editor for International Journal of General Systems and Information Fusion.
References
- Abu-Khalaf, M., Lewis, F. L., & Huang, J. (2006, December). Policy iterations on the Hamilton-Jacobi-Isaacs equation for H∞ state feedback control with input saturation. IEEE Transaction Automatic Control, 51(12), 1989–1995. https://doi.org/10.1109/TAC.2006.884959
- Al-Tamimi, A., Abu-Khalaf, M., & Lewis, F. L. (2007, February). Adaptive critic designs for discrete-time zero-sum games with application to H∞ control. IEEE Transactions on System, Man, and Cybernetics: Cybernetics, 37(1), 240–247. https://doi.org/10.1109/TSMCB.2006.880135
- Al-Tamimi, A., Lewis, F. L., & Abu-Khalaf, M. (2008, August). Discrete-time nonlinear HJB solution using approximate dynamic programming: convergence proof. IEEE Transactions on System, Man, and Cybernetics: Cybernetics, 38(4), 943–949. https://doi.org/10.1109/TSMCB.2008.926614
- Balakrishnan, S. N., & Biega, V. (1996, July). Adaptive-critic-based neural networks for aircraft optimal control. Journal of Guidance Control and Dynamics, 19(4), 893–898. https://doi.org/10.2514/3.21715
- Bao, G., Ma, L., & Yi, X. (2022, December). Recent advances on cooperative control of heterogeneous multi-agent systems subject to constraints: A survey. Systems Science & Control Engineering, 10(1), 539–551. https://doi.org/10.1080/21642583.2022.2074169
- Beard, R. W., & Saridis, G. N. (1998, March). Approximate solutions to the time-invariant Hamilton-Jacobi-Bellman equation. Journal of Optimization Theory and Applications, 96(3), 589–626. https://doi.org/10.1023/A:1022664528457
- Chen, H., Tian, E., & Wang, L. (2022, May). State-of-charge estimation of lithium-ion batteries subject to random sensor data unavailability: a recursive filtering approach. IEEE Transactions on Industrial Electronics, 69(5), 5175–5184. https://doi.org/10.1109/TIE.2021.3078376
- Chen, L., Chen, Y., & Zhang, N. (2021, October). Synchronization control for chaotic neural networks with mixed delays under input saturations. Neural Process Letters, 53(5), 3735–3755. https://doi.org/10.1007/s11063-021-10577-9
- Chen, N., Li, B., Luo, B., Gui, W., & Yang, C. (2021). Event-triggered optimal control for temperature field of roller kiln based on adaptive dynamic programming. IEEE Transactions on Cybernetics, 53(5), 2805–2817. https://doi.org/10.1109/TCYB.2021.3121409
- Chen, Y., Fu, Z., Fei, S., & Song, S. (2020, May). Delayed anti-windup strategy for input-delay systems with actuator saturations. Journal of the Franklin Institute, 357(8), 4680–4696. https://doi.org/10.1016/j.jfranklin.2020.02.008
- Chen, Y., & Wang, Z. (2021, March). Local stabilization for discrete-time systems with distributed state delay and fast-varying input delay under actuator saturations. IEEE Transactions on Automatic Control, 66(3), 1337–1344. https://doi.org/10.1109/TAC.9
- Cheng, P., Liu, S., Chen, B., & Yu, L. (2022, May). Multi-agent reinforcement learning for decentralized resilient secondary control of energy storage systems against doS attacks. IEEE Transactions on Smart Grid, 13(3), 1739–1750. https://doi.org/10.1109/TSG.2022.3142087
- Cheng, T., Lewis, F. L., & Abu-Khalaf, M. (2007, March). A neural network solution for fixed final time optimal control of nonlinear systems. Automatica, 43(3), 482–490. https://doi.org/10.1016/j.automatica.2006.09.021
- Cui, Y., Liu, Y., Zhang, W., & Alsaadi, F. E. (2021, January). Sampled-based consensus for nonlinear multiagent systems with deception attacks: the decoupled method. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 51(1), 561–573. https://doi.org/10.1109/TSMC.6221021
- Cui, Y., Yu, L., Liu, Y., Zhang, W., & Alsaadi, F. E. (2021, December). Dynamic event-based non-fragile state estimation for complex networks via partial nodes information. Journal of the Franklin Institute, 358(18), 10193–10212. https://doi.org/10.1016/j.jfranklin.2021.10.038
- Deb, A. K., Jayadeva, K., Gopal, M., & Chandra, S. (2007, July). SVM-based tree-type neural networks as a critic in adaptive critic designs for control. IEEE Transactions on Neural Networks, 18(4), 1016–1030. https://doi.org/10.1109/TNN.2007.899255
- Deng, Y., Gong, M., & Ni, T. (2022). Double-channel event-triggered adaptive optimal control of active suspension systems. Nonlinear Dynamics, 108, 3435–3448. https://doi.org/10.1007/s11071-022-07360-3
- Ding, D., Wang, Z., & Han, Q. (2019, August). Neural-network-based output-feedback control with stochastic communication protocols. Automatica, 106, 221–229. https://doi.org/10.1016/j.automatica.2019.04.025
- Ding, D., Wang, Z., & Han, Q.-L. (2020, August). Neural-network-based consensus control for multiagent systems with input constraints: the event-triggered case. IEEE Transactions on Cybernetics, 50(8), 3719–3730. https://doi.org/10.1109/TCYB.6221036
- Ding, D., Wang, Z., Han, Q.-L., & Wei, G. (2019, June). Neural-network-based output-feedback control under Round-Robin scheduling protocols. IEEE Transactions on Cybernetics, 59(6), 2372–2384. https://doi.org/10.1109/TCYB.2018.2827037
- Dong, D., Chen, C., Tarn, T. J., Pechen, A., & Rabitz, H. (2008, August). Incoherent control of quantum systems with wavefunction-controllable subspaces via quantum reinforcement learning. IEEE Transactions on System, Man, and Cybernetics: Cybernetics, 38(4), 957–962. https://doi.org/10.1109/TSMCB.2008.926603
- Dong, Y., Song, Y., & Wei, G. (2022, January). Efficient model-predictive control for nonlinear systems in interval type-2 T-S fuzzy form under round-robin protocol. IEEE Transactions on Fuzzy Systems, 30(1), 63–74. https://doi.org/10.1109/TFUZZ.2020.3031394
- Enns, R., & Si, J. (2003, July). Helicopter trimming and tracking control using direct neural dynamic programming. IEEE Transactions on Neural Networks, 14(4), 929–939. https://doi.org/10.1109/TNN.2003.813839
- Ferrari, S., Steck, J. E., & Chandramohan, R. (2008, August). Adaptive feedback control by constrained approximate dynamic programming. IEEE Transactions on System, Man, and Cybernetics: Cybernetics, 38(4), 982–987. https://doi.org/10.1109/TSMCB.2008.924140
- Gao, C., Wang, Z., He, X., & Yue, D. (2021, November). Sampled-data-based fault-tolerant consensus control for multi-agent systems: A data privacy preserving scheme. Automatica, 133, 109847. https://doi.org/10.1016/j.auto-matica.2021.109847
- Gao, H., Dong, H., Wang, Z., & Han, F. (2022). Recursive minimum-variance filter design for state-saturated complex networks with uncertain coupling strengths subject to deception attacks. IEEE Transactions on Cybernetics, 52(10), 11121–11132. https://doi.org/10.1109/TCYB.2021.3067822
- Gu, Z., Shi, P., Yue, D., & Ding, Z. (2018). Decentralized adaptive event-triggered H∞ filtering for a class of networked nonlinear interconnected systems. IEEE Transactions on Cybernetics, 49(5), 1570–1579. https://doi.org/10.1109/TCYB.6221036
- Han, F., Wang, Z., Dong, H., & Liu, H. (2021). Partial-nodes-based scalable H∞-consensus filtering with censored measurements over sensor networks. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 51(3), 1892–1903. http://doi.org/10.1109/TSMC.2019.2907649.
- Han, X., Qi, H., Wang, Z., Xu, N., Zhao, X., & Zhao, J. (2021, July). An event-triggered integer-mixed adaptive dynamic programming for switched nonlinear systems with bounded inputs. International Journal of Robust and Nonlinear Control, 31(15), 7280–7297. https://doi.org/10.1002/rnc.v31.15
- Havira, R., & Lewis, J. (1972). Computation of quantized controls using differential dynamic programming. IEEE Transactions Automatatic Control, 17(2), 191–196. https://doi.org/10.1109/TAC.1972.1099943
- He, P., & Jagannathan, S. (2005, February). Reinforcement learning-based output feedback control of nonlinear systems with input constraints. IEEE Transactions on System, Man, and Cybernetics: Cybernetics, 35(1), 150–154. https://doi.org/10.1109/TSMCB.2004.840124
- He, W., Mo, Z., Han, Q.-L., & Qian, F. (2020, September). Secure impulsive synchronization in lipschitz-type multi-agent systems subject to deception attacks. IEEE/CAA Journal of Automatica Sinica, 7(5), 1326–1334. https://doi.org/10.1109/JAS.2020.1003297.
- Hou, N., Li, J., Liu, H., Ge, Y., & Dong, H. (2022). Finite-horizon resilient state estimation for complex networks with integral measurements from partial nodes. Science China-Information Sciences, 65, 132205. https://doi.org/10.1007/s11432-020-3243-7
- Hu, C., Zhao, L., & Qu, G. (2021). Event-triggered model predictive adaptive dynamic programming for road intersection path planning of unmanned ground vehicle. IEEE Transactions on Vehicular Technology, 70(11), 11228–11243. https://doi.org/10.1109/TVT.2021.3111692
- Huang, X., & Dong, G. (2021, December). ADP-based robust resilient control of partially unknown nonlinear systems via cooperative interaction design. IEEE Transactions on Systems Man Cybernetics: Systems, 51(12), 7466–7474. https://doi.org/10.1109/TSMC.2020.2970040
- Jiang, B., Dong, H., Shen, Y., & Mu, S. (2022, June). Encoding-decoding-based recursive filtering for fractional-order systems. IEEE/CAA Journal of Automatica Sinica, 9(6), 1103–1106. https://doi.org/10.1109/JAS.2022.105644
- Jiang, B., Gao, H., Han, F., & Dong, H. (2021). Recursive filtering for nonlinear systems subject to measurement outliers. Science China-Information Sciences, 64, 172206. https://doi.org/10.1007/s11432-020-3135-y
- Khankalantary, S., Izadi, I., & Sheikholeslam, F. (2020, December). Robust ADP-based solution of a class of nonlinear multi-agent systems with input saturation and collision avoidance constraints. ISA Transactions, 107, 52–62. https://doi.org/10.1016/j.isatra.2020.07.029
- Kim, Y. J., & Lim, M. T. (2008, July). Parallel optimal control for weakly coupled nonlinear systems using successive Galerkin approximation. IEEE Transactions on Automatic Control, 53(6), 1542–1547. https://doi.org/10.1109/TAC.2008.921047
- Lewis, F. L., & Vrabie, D. (2009). Reinforcement learning and adaptive dynamic programming for feedback control. IEEE Circuits and Systems Magazine, 9(3), 40–58. https://doi.org/10.1109/MCAS.7384
- Li, J., Dong, H., Shen, Y., & Hou, N. (2022, August). Encoding-decoding strategy based resilient state estimation for bias-corrupted stochastic nonlinear systems. ISA Transactions, 127, 80–87. https://doi.org/10.1016/j.isatra.2022.04.048
- Li, J., Tian, X., & Wei, G. (2022, November). Protocol-based control for nonlinear systems with environment-dependent energy harvesting sensors: an average dwell-time method. Nonlinear Analysis: Hybrid Systems, 46, 101241. https://doi.org/10.1016/j.nahs.2022.101241.
- Li, Z., Hu, J., & Li, J. (2021, January). Distributed filtering for delayed nonlinear system with random sensor saturation: A dynamic event-triggered approach. Systems Science & Control Engineering, 9(1), 440–454. https://doi.org/10.1080/21642583.2021.1919935
- Lian, B., Xue, W., Lewis, F. L., & Chai, T. (2021, September). Online inverse reinforcement learning for nonlinear systems with adversarial attacks. International Journal of Robust and Nonlinear Control, 31(14), 6646–6667. https://doi.org/10.1002/rnc.v31.14
- Liang, M., Wang, D., & Liu, D. (2020, November). Neuro-optimal control for discrete stochastic processes via a novel policy iteration algorithm. IEEE Transactions on System, Man, and Cybernetics: Systems, 50(11), 3972–3985. https://doi.org/10.1109/TSMC.6221021
- Liu, D., Zhang, Y., & Zhang, H. (2005, September). A self-learning call admission control scheme for CDMA cellular networks. IEEE Transactions on Neural Networks, 16(5), 1219–1228. https://doi.org/10.1109/TNN.2005.853408
- Liu, F., Jiang, C., & Xiao, W. (2021, April). Multistep prediction-based adaptive dynamic programming sensor scheduling approach for collaborative target tracking in energy harvesting wireless sensor networks. IEEE Transactions on Automation Science and Engineering, 18(2), 693–704. https://doi.org/10.1109/TASE.2020.3019567
- Liu, H., Wang, Z., Fei, W., & Li, J. (2022, May). Resilient H∞ state estimation for discrete-time stochastic delayed memristive neural networks: a dynamic event-triggered mechanism. IEEE Transactions on Cybernetics, 52(5), 3333–3341. https://doi.org/10.1109/TCYB.2020.3021556
- Liu, P., Zhang, H., Ren, H., & Liu, C. (2021, October). Online event-triggered adaptive critic design for multi-player zero-sum games of partially unknown nonlinear systems with input constraints. Neurocomputing, 462, 309–319. https://doi.org/10.1016/j.neucom.2021.07.058
- Liu, S., Wang, Z., Wang, L., & Wei, G. (2022, August). H∞ pinning control of complex dynamical networks under dynamic quantization effects: a coupled backward Riccati equation approach. IEEE Transactions on Cybernetics, 52(8), 7377–7387. https://doi.org/10.1109/TCYB.2020.3021982
- Liu, S., Zhao, X., Tian, E., & Wei, G. (2022, August). Distributed recursive filtering under random access protocols: a multirate strategy. International Journal of Robust and Nonlinear Control, 32(12), 7132–7148. https://doi.org/10.1002/rnc.v32.12
- Liu, Y., Shen, B., & Sun, J. (2022, November). Stubborn state estimation for complex-valued neural networks with mixed time delays: the discrete time case. Neural Computing and Applications, 34(7), 5449–5464. https://doi.org/10.1007/s00521-021-06707-y
- Liu, Y., Shen, B., & Zhang, P. (2022, June). Synchronization and state estimation for discrete-time coupled delayed complex-valued neural networks with random system parameters. Neural Networks, 150, 181–193. https://doi.org/10.1016/j.neunet.2022.02.028
- Ma, L., Wang, Z., Cai, C., & Alsaadi, F. E. (2021, November). A dynamic event-triggered approach to H∞ control for discrete-time singularly perturbed systems with time-delays and sensor saturations. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 51(11), 6614–6625. https://doi.org/10.1109/TSMC.2019.2958529
- Ma, L., Wang, Z., Hu, J., & Han, Q.-L. (2021, July). Probability-guaranteed envelope-constrained filtering for nonlinear systems subject to measurement outliers. IEEE Transactions on Automatic Control, 66(7), 3274–3281. https://doi.org/10.1109/TAC.2020.3016767
- Ma, L., Wang, Z., Liu, H., & Alsaadi, F. E. (2022, June). Neural-network-based filtering for a general class of nonlinear systems under dynamically bounded innovations over sensor networks. IEEE Transactions on Network Science and Engineering, 9(3), 1395–1408. https://doi.org/10.1109/TNSE.2022.3144484
- Ming, Z., Zhang, H., Luo, Y., & Wang, W. (2022). Dynamic event-based control for stochastic optimal regulation of nonlinear networked control systems. IEEE Transactions on Neural Networks and Learning Systems. https://doi.org/10.1109/TNNLS.2022.3140478
- Mishra, A., & Ghosh, S. (2022). Simultaneous identification and optimal tracking control of unknown continuous-time systems with actuator constraints. International Journal of Control, 95(8), 2005–2023. https://doi.org/10.1080/00207179.2021.1890824
- Mohahegi, S., Venayagamoorth, G. K., & Harley, R. H. (2006, November). Adaptive critic design based neuro-fuzzy controller for a static compensator in a multimachine power system. IEEE Transactions on Power Systems, 21(4), 1744–1754. https://doi.org/10.1109/TPWRS.2006.882467
- Mu, C., Wang, K., & Ni, Z.. Adaptive learning and sampled-control for nonlinear game systems using dynamic event-triggering strategy. IEEE Transactions on Neural Networks and Learning Systems, 33(9), 4437–4450. https://doi.org/10.1109/TNNLS.2021.3057438
- Ni, Z., He, H., Zhong, X., & Prokhorov, D. V. (2015, August). Model-free dual heuristic dynamic programming. IEEE Transactions on Neural Networks and Learning Systems, 26(8), 1834–1839. https://doi.org/10.1109/TNNLS.2015.2424971
- Ning, B., Han, Q.-L., & Ding, L. (2021, August). Distributed finite-time secondary frequency and voltage control for islanded microgrids with communication delays and switching topologies. IEEE Transactions on Cybernetics, 51(8), 3988–3999. https://doi.org/10.1109/TCYB.2020.3003690
- Niu, H., Bhowmick, C., & Jagannathan, S. (2020, January). Attack detection and approximation in nonlinear networked control systems using neural networks. IEEE Transactions on Neural Networks and Learning Systems, 31(1), 235–245. https://doi.org/10.1109/TNNLS.5962385
- Padhi, R., Unnikrishnan, N., Wang, X., & Balakrishnan, S. N. (2006, December). A single network adaptive critic (SNAC) architecture for optimal control synthesis for a class of nonlinear systems. Neural Networks, 19(10), 1648–1660. https://doi.org/10.1016/j.neunet.2006.08.010
- Pang, K., Ma, L., Bai, H., & Xue, S. (2021). Finite-time containment control for nonlinear second-order multiagent system under directed topology. IEEE Systems Journal, 16(4), 6175–6184. https://doi.org/10.1109/JSYST.2021.3130611
- Pinto, E. R., Nepomuceno, E. G., & Campanharo, A. S. L. O. (2022, December). Individual-based modelling of animal brucellosis spread with the use of complex networks. International Journal of Network Dynamics and Intelligence, 1(1), 120–129. https://doi.org/10.53941/ijndi0101011
- Prokhorov, D. V., Santiago, R., & Wunsch, D. C. (1995). Adaptive critic designs: a case study for neurocontrol. Neural Networks, 8(9), 1367–1372. https://doi.org/10.1016/0893-6080(95)00042-9
- Qian, W., Gao, Y., & Yang, Y. (2019, October). Global consensus of multiagent systems with internal delays and communication delays. IEEE Transactions on Systems,Man,and Cybernetics: Systems, 49(10), 1961–1970. https://doi.org/10.1109/TSMC.6221021
- Qian, W., Li, Y., Zhao, Y., & Chen, Y. (2020, November). New optimal method for L2- L∞ state estimation of delayed neural networks. IEEE Transactions on Neural Networks and Learning Systems, 415, 258–265. https://doi.org/10.1016/j.neucom.2020.06.118.
- Qian, W., Xing, W., & Fei, S. (2021, September). H∞ state estimation for neural networks with general activation function and mixed time-varying delays. IEEE Transactions on Neural Networks and Learning Systems, 32(9), 3909–3918. https://doi.org/10.1109/TNNLS.2020.3016120
- Qu, B., Wang, Z., Shen, B., & Dong, H. (2021). Distributed state estimation for renewable energy microgrids with sensor saturations. Automatica, 131, 109730. https://doi.org/10.1016/j.automatica.2021.109730
- Ren, H., Zhang, H., Mu, Y., & Duan, J. (2020, February). Off-policy synchronous iteration IRL method for multi-player zero-sum games with input constraints. Neurocomputing, 378, 413–421. https://doi.org/10.1016/j.neucom.2019.10.075
- Rizvi, S. A. A., & Lin, Z. (2022, February). Adaptive dynamic programming for model-free global stabilization of control constrained continuous-time systems. IEEE Transactions on Cybernetics, 52(2), 1048–1060. https://doi.org/10.1109/TCYB.2020.2989419
- Shen, B., Wang, Z., Tan, H., & Chen, H. (2021). Robust fusion filtering over multisensor systems with energy harvesting constraints. Automatica, 131, 109782. https://doi.org/10.1016/j.automatica.2021.109782
- Shen, Y., Wang, Z., Shen, B., & Han, Q.-L. (2022). Recursive state estimation for networked multi-rate multi-sensor systems with distributed time-delays under the Round-Robin protocol. IEEE Transactions on Cybernetics, 52(6), 4136–4146. https://doi.org/10.1109/TCYB.2020.3021350
- Shervais, S., Shannon, T. T., & Lendaris, G. G. (2003, March). Intelligent supply chain management using adaptive critic learning. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 33(2), 235–244. https://doi.org/10.1109/TSMCA.2003.809214
- Shi, H., Wang, M., & Wang, C. (2022, September). Model-based event-triggered neural learning control for discrete-time strict-feedback systems. International Journal of Robust and Nonlinear Control, 32(13), 7611–7630. https://doi.org/10.1002/rnc.v32.13
- Shi, J., Yue, D., & Xie, X. (2020, July). Adaptive optimal tracking control for nonlinear continuous-time systems with time delay using value iteration algorithm. Neurocomputing, 396, 172–178. https://doi.org/10.1016/j.neucom.2018.07.098
- Song, B., Miao, H., & Xu, L. (2021, January). Path planning for coal mine robot via improved ant colony optimization algorithm. Systems Science & Control Engineering, 9(1), 283–289. https://doi.org/10.1080/21642583.2021.1901158
- Song, R., & Liu, L. (2020, September). Event-triggered constrained robust control for partly-unknown nonlinear systems via ADP. Neurocomputing, 404, 294–303. https://doi.org/10.1016/j.neucom.2020.05.012
- Song, R., Xiao, W., & Wei, Q. (2013, November). Multi-objective optimal control for a class of nonlinear time-delay systems via adaptive dynamic programming. Soft Computing, 17(11), 2109–2115. https://doi.org/10.1007/s00500-013-1111-x
- Su, H., Zhang, H., Jiang, H., & Wen, Y. (2020, October). Decentralized event-triggered adaptive control of discrete-time nonzero-sum games over wireless sensor-actuator networks with input constraints. IEEE Transactions on Neural Networks and Learning Systems, 31(10), 4254–4266. https://doi.org/10.1109/TNNLS.5962385
- Sun, B., & van Kampen, E.-J. (2021, May). Intelligent adaptive optimal control using incremental model-based global dual heuristic programming subject to partial observability. Applied Soft Computing, 103, 107153. https://doi.org/10.1016/j.asoc.2021.107153.
- Sun, J., Shen, B., & Liu, Y. (2022). A resilient outlier-resistant recursive filtering approach to time-delayed spatial–temporal systems with energy harvesting sensors. ISA Transactions, 127, 41–49. https://doi.org/10.1016/j.isatra.2021.12.040
- Tan, H., Shen, B., & Li, Q. (2022, March). Fusion estimation for stochastic uncertain systems with time-correlated Rician fading channels. Journal of the Franklin Institute, 359(5), 2340–2358. https://doi.org/10.1016/j.jfranklin.2022.01.033
- Tan, L. N. (2018, July). Distributed optimal control for nonholonomic systems with input constraints and uncertain interconnections. Nonlinear Dynamics, 93(2), 801–817. https://doi.org/10.1007/s11071-018-4228-8
- Tao, H., Tan, H., Chen, Q., Liu, H., & Hu, J. (2022, December). H∞ state estimation for memristive neural networks with randomly occurring doS attacks. Systems Science & Control Engineering, 10(1), 154–165. https://doi.org/10.1080/21642583.2022.2048322
- Tesauro, G. (1992, May). Practical issues in temporal difference learning. Machine Learning, 8(3-4), 257–277. https://doi.org/10.1007/BF00992697
- Tian, E., Yue, D., & Peng, C. (2010). Reliable control for networked control systems with probabilistic actuator fault and random delays. Journal of the Franklin Institute, 347(10), 1907–1926. https://doi.org/10.1016/j.jfranklin.2010.10.010
- Vamvodakis, K. G., & Lewis, F. L. (2010, May). Online actor-critic algorithm to solve the continuous-time infinite horizon optimal control problem. Automatica, 46(5), 878–888. https://doi.org/10.1016/j.automatica.2010.02.018
- Wang, D., Hu, L., Zhao, M., & Qiao, J. (2021). Adaptive critic for event-triggered unknown nonlinear optimal tracking design with wastewater treatment applications. IEEE Transactions on Neural Networks and Learning Systems. https://doi.org/10.1109/TNNLS.2021.3135405.
- Wang, F.-Y., Zhang, H., & Liu, D. (2009). Adaptive dynamic programming: an introduction. IEEE Computational Intelligence Magazine, 4(2), 39–47. https://doi.org/10.1109/MCI.2009.932261
- Wang, L., Tian, E., Wang, C., & Liu, S. (2022, July). Secure estimation against malicious attacks for lithium-ion batteries under cloud environments. IEEE Transactions on Circuits and Systems I: Regular Papers, 52(6), 4136–4146. https://doi.org/10.1109/TCSI.2022.3187725.
- Wang, M., & Wang, L. (2022, April). Finite-time performance guaranteed event-triggered adaptive control for nonlinear systems with unknown control direction. Journal of the Franklin Institute, 359(6), 2463–2486. https://doi.org/10.1016/j.jfranklin.2022.02.003
- Wang, M., Zou, Y., & Yang, C. (2022, March). System transformation-based neural control for full-state-constrained pure-feedback systems via disturbance observer. IEEE Transactions on Cybernetics, 52(3), 1479–1489. https://doi.org/10.1109/TCYB.2020.2988897
- Wang, X., Ding, D., Dong, H., & Yi, X. (2022a). PI-based security control against joint sensor and controller attacks and applications in load frequency control. IEEE Transactions on System, Man, and Cybernetics: Systems, 53(2), 970–980. https://doi.org/10.1109/TSMC.2022.3190005
- Wang, X., Ding, D., Dong, H., & Yi, X. (2022b). Supplementary control for quantized discrete-time nonlinear systems under goal representation heuristic dynamic programming. IEEE Transactions on Neural Networks and Learning Systems. https://doi.org/10.1109/TNNLS.2022.3201521.
- Wang, X., Ding, D., Dong, H., & Zhang, X.-M. (2021, April). Neural-network-based control for discrete-time nonlinear systems with input saturation under stochastic communication protocol. IEEE/CAA Journal of Automatica Sinica, 8(4), 766–778. https://doi.org/10.1109/JAS.6570654
- Wang, X., Ding, D., Ge, X., & Han, Q.-L. (2022, March). Neural-network-based control for discrete-time nonlinear systems with denial-of-service attack: the adaptive event-triggered case. International Journal of Robust and Nonlinear Control, 32(5), 2760–2779. https://doi.org/10.1002/rnc.v32.5
- Wang, X., Sun, Y., & Ding, D. (2022, December). Adaptive dynamic programming for networked control systems under communication constraints: a survey of trends and techniques. International Journal of Network Dynamics and Intelligence, 1(1), 85–98. https://doi.org/10.53941/ijndi0101008
- Wei, Q., Lu, J., Zhou, T., Cheng, X., & Wang, F.-Y. (2022, June). Event-triggered near-optimal control of discrete-time constrained nonlinear systems with application to a boiler-turbine system. IEEE Transactions on Industrial Informatics, 18(6), 3926–3935. https://doi.org/10.1109/TII.2021.3116084
- Wei, Q., Wang, D., & Zhang, D. (2013, December). Dual iterative adaptive dynamic programming for a class of discrete-time nonlinear systems with time-delays. Neural Computing and Applications, 23(7-8), 1851–1863. https://doi.org/10.1007/s00521-012-1188-7
- Wu, X., & Wang, C. (2021, May). Event-driven adaptive near-optimal tracking control of the robot in aircraft skin inspection. International Journal of Robust and Nonlinear Control, 31(7), 2593–2613. https://doi.org/10.1002/rnc.v31.7
- Xiao, S., Ge, X., Han, Q.-L., & Zhang, Y. (2021). Secure distributed adaptive platooning control of automated vehicles over vehicular Ad-Hoc networks under denial-of-service attacks. IEEE Transactions on Cybernetics, 52(11), 12003–12015. https://doi.org/10.1109/TCYB.2021.3074318
- Xie, X., Zhou, Q., Yue, D., & Li, H. (2017). Relaxed control design of discrete-time Takagi-Sugeno fuzzy systems: an event-triggered real-time scheduling approach. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 48(12), 2251–2262. https://doi.org/10.1109/TSMC.2017.2737542
- Xu, D., Wang, Q., & Li, Y. (2020, May). Optimal guaranteed cost tracking of uncertain nonlinear systems using adaptive dynamic programming with concurrent learning. International Journal of Control, Automation and Systems, 18(5), 1116–1127. https://doi.org/10.1007/s12555-019-0165-7
- Xu, H., Jagannathan, S., & Lewis, F. L. (2014, September). Stochastic optimal design for unknown linear discrete-time system zero-sum games in input-output form under communication constraints. Asian Journal of Control, 16(5), 1263–1276. https://doi.org/10.1002/asjc.v16.5
- Xu, H., Zhao, Q., & Jagannathan, S. (2015, August). Finite-horizon near-optimal output feedback neural network control of quantized nonlinear discrete-time systems with input constraint. IEEE Transactions on Neural Networks and Learning Systems, 26(8), 1776–1788. https://doi.org/10.1109/TNNLS.2015.2409301
- Xu, J., Sheng, L., & Gao, M. (2021, May). Fault estimation for nonlinear systems with sensor gain degradation and stochastic protocol based on strong tracking filtering. Systems Science & Control Engineering, 9(S2), 60–70. https://doi.org/10.1080/21642583.2020.1833789
- Xu, J., Wang, J., Rao, J., Zhong, Y., & Wang, H. (2022, April). Adaptive dynamic programming for optimal control of discrete-time nonlinear system with state constraints based on control barrier function. International Journal of Robust and Nonlinear Control, 32(6), 3408–3424. https://doi.org/10.1002/rnc.v32.6
- Xu, Y., Lv, W., Lin, W., Lu, R., & Quevedo, D. E. (2022). On extended state estimation for nonlinear uncertain systems with round-robin protocol. Automatica, 138, 110154. https://doi.org/10.1016/j.automatica.2021.110154
- Xu, Y., Yao, Z., Lu, R., & Ghosh, B. K. (2022). A novel fixed-time protocol for first-order consensus tracking with disturbance rejection. IEEE Transactions on Automatic Control, 67(11), 6180–6186. https://doi.org/10.1109/TAC.2021.3131549
- Xue, S., Luo, B., Liu, D., & Yang, Y. (2022, January). Constrained event-triggered H∞ control based on adaptive dynamic programming with concurrent learning. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 52(1), 357–369. https://doi.org/10.1109/TSMC.2020.2997559
- Yadav, V., Padhi, R., & Balakrishnan, S. N. (2007, July). Robust/optimal temperature profile control of a high-speed aerospace vehicle using neural networks. IEEE Transactions on Neural Networks, 18(4), 1115–1128. https://doi.org/10.1109/TNN.2007.899229
- Yang, H., Li, Y., Yuan, H., & Liu, Z. (2018, September). Adaptive dynamic programming for security of networked control systems with actuator saturation. Information Sciences, 460, 51–64. https://doi.org/10.1016/j.ins.2018.05.039
- Yang, X., & Wei, Q. (2021, January). Adaptive critic learning for constrained optimal event-triggered control with discounted cost. IEEE Transactions on Neural Networks and Learning Systems, 32(1), 91–104. https://doi.org/10.1109/TNNLS.5962385
- Yang, X., Zhou, Y., Dong, N., & Wei, Q. (2021). Adaptive critics for decentralized stabilization of constrained-input nonlinear interconnected systems. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 52(7), 4187–4199. https://doi.org/10.1109/TSMC.2021.3089944
- Yao, M., Wei, G., Ding, D., & Li, W. (2022, September). Output-feedback control for stochastic impulsive systems under Round-Robin protocol. Automatica, 143, 110394. https://doi.org/10.1016/j.automatica.2022.110394
- Yuan, Y., Wang, Z., Yu, Y., Guo, L., & Yang, H. (2019). Active disturbance rejection control for a pneumatic motion platform subject to actuator saturation: an extended state observer approach. Automatica, 107, 353–361. https://doi.org/10.1016/j.automatica.2019.05.056
- Yuan, Y., Yuan, H., Ho, D. W. C., & Guo, L. (2020, January). Resilient control of wireless networked control system under denial-of-service attacks: A cross-layer design approach. IEEE Transactions on Cybernetics, 50(1), 48–60. https://doi.org/10.1109/TCYB.6221036
- Zhang, B., & Song, Y. (2022, September). Model-predictive control for Markovian jump systems under asynchronous scenario: an optimizing prediction dynamics approach. Transactions on Automatic Control, 67(9), 4900–4907. https://doi.org/10.1109/TAC.2022.3164832
- Zhang, B., Song, Y., & Cai, H. (2022, May). An efficient model predictive control for Markovian jump systems with all unstable modes. Nonlinear Analysis: Hybrid Systems, 44, 101117. https://doi.org/10.1016/j.nahs.2021.101117
- Zhang, H., Song, R., Wei, Q., & Zhang, T. (2011, December). Optimal tracking control for a class of nonlinear discrete-time systems with time delays based on heuristic dynamic programming. IEEE Transactions on Neural Networks, 22(12), 1851–1862. https://doi.org/10.1109/TNN.2011.2172628
- Zhang, H., Wei, Q., & Luo, Y. (2008, August). A novel infinite-time optimal tracking control scheme for a class of discrete-time nonlinear systems via the greedy HDP iteration algorithm. IEEE Transactions on Systems, Man, and Cybernetics: Cybernetics, 38(4), 937–942. https://doi.org/10.1109/TSMCB.2008.920269
- Zhang, H., Yue, D., Zhao, W., Hu, S., & Dou, C. (2018, July). Distributed optimal consensus control for multiagent systems with input delay. IEEE Transactions on Cybernetics, 48(6), 1747–1759. https://doi.org/10.1109/TCYB.2017.2714173
- Zhang, Q., & Zhou, Y. (2022, December). Recent advances in non-Gaussian stochastic systems control theory and its applications. International Journal of Network Dynamics and Intelligence, 1(1), 111–119. https://doi.org/10.53941/ijndi0101010
- Zhang, S., Ma, L., & Yi, X. (2022, June). Model-free adaptive control for nonlinear multi-agent systems with encoding-decoding mechanism. IEEE Transactions on Signal and Information Processing Over Networks, 8, 489–498. https://doi.org/10.1109/TSIPN.2022.3174966
- Zhang, S., Zhao, B., & Zhang, Y. (2021, July). Event-triggered control for input constrained non-affine nonlinear systems based on neuro-dynamic programming. Neurocomputing, 440, 175–184. https://doi.org/10.1016/j.neucom.2021.01.116
- Zhang, W., Sheng, L., & Gao, M. (2021, May). Finite-horizon H∞ state estimation for time-varying complex networks based on the outputs of partial nodes. Systems Science & Control Engineering, 9(S2), 48–59. https://doi.org/10.1080/21642583.2020.1837691
- Zhang, W., Tang, Y., Zheng, W., & Liu, Y. (2021, November). Stability of time-varying systems with delayed impulsive effects. International Journal of Robust and Nonlinear Control, 31(16), 7825–7843. https://doi.org/10.1002/rnc.v31.16
- Zhang, W., & Yi, W. (2021, November). Composite adaptive dynamic programming for missile interception systems with multiple constraints and less sensor requirement. ISA Transactions, 117, 40–53. https://doi.org/10.1016/j.isatra.2021.01.040
- Zhang, X., Zhao, B., Liu, D., & Zhang, S. (2022, January). Event-triggered optimal tracking control of multiplayer unknown nonlinear systems via adaptive critic designs. International Journal of Robust and Nonlinear Control, 32(1), 29–51. https://doi.org/10.1002/rnc.v32.1
- Zhang, X.-M., Han, Q.-L., & Ge, X. (2021). Sufficient conditions for a class of matrix-valued polynomial inequalities on closed intervals and application to H∞ filtering for linear systems with time-varying delays. Automatica, 125, 109390. https://doi.org/10.1016/j.automatica.2020.109390
- Zhao, B., Jia, L., Xia, H., & Li, Y. (2018, September). Adaptive dynamic programming-based stabilization of nonlinear systems with unknown actuator saturation. Nonlinear Dynamics, 93(4), 2089–2103. https://doi.org/10.1007/s11071-018-4309-8
- Zhao, D., Wang, Z., Han, Q.-L., & Wei, G. (2022, August). Proportional-integral observer design for uncertain time-delay systems subject to deception attacks: an outlier-resistant approach. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 52(8), 5152–5164. https://doi.org/10.1109/TSMC.2021.3117742
- Zhao, Q., Xu, H., & Jagannathan, S. (2015, March). Optimal control of uncertain quantized linear discrete-time systems. International Journal of Adaptive Control and Signal Processing, 29(3), 325–345. https://doi.org/10.1002/acs.v29.3
- Zhao, T., Liu, Y., Li, Z., Su, C.-Y., & Feng, Y. (2019, October). Adaptive control and optimization of mobile manipulation subject to input saturation and switching constraints. IEEE Transactions on Automation Science and Engineering, 16(4), 1543–1555. https://doi.org/10.1109/TASE.8856
- Zhao, Y., Dai, X., Gong, D., Lv, X., & Liu, Y. (2022). Event-triggered adaptive dynamic programming consensus tracking control for discrete-time multiagent systems. Complexity. 6028054, 1–14. https://doi.org/10.1155/2022/6028054
- Zhu, J., Zhang, P., & Hou, Y. (2021, October). Adaptive dynamic programming-based optimal regulation on input-constrained nonlinear time-delay systems. Neural Computing and Applications, 33(19), 13039–13047. https://doi.org/10.1007/s00521-021-06000-y
- Zhu, K., Wang, Z., Wei, G., & Liu, X. (2022). Adaptive set-membership state estimation for nonlinear systems under bit rate allocation mechanism: A neural-network-based approach. IEEE Transactions on Neural Networks and Learning Systems. https://doi.org/10.1109/TNNLS.2022.3149540.
- Zhu, M., & Martinez, S. (2014, March). On the performance analysis of resilient networked control systems under replay attacks. IEEE Transactions on Automatic Control, 59(3), 804–808. https://doi.org/10.1109/TAC.2013.2279896
- Zhu, S., Tian, E., Xu, D., & Liu, J. (2022, April). An adaptive torus-event-based controller design for networked T-S fuzzy systems under deception attacks. International Journal of Robust and Nonlinear Control, 32(6), 3425–3441. https://doi.org/10.1002/rnc.v32.6
- Zhu, Y., Zhao, D., He, H., & Ji, J. (2017, May). Event-triggered optimal control for partially unknown constrained-input systems via adaptive dynamic programming. IEEE Transactions on Industrial Electronics, 64(5), 4101–4109. https://doi.org/10.1109/TIE.2016.2597763
- Zhu, Z., Zeng, F., Qi, G., Li, Y., Hou, J., & Mazur, N. (2021). Power system structure optimization based on reinforcement learning and sparse constraints under doS attacks in cloud environments. Simulation Modelling Practice and Theory, 110, 102272. https://doi.org/10.1016/j.simpat.2021.102272