
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In the Serial Reaction Time Task, participants respond to several stimuli usually being unaware that the stimuli follow a predefined sequence while still learning the sequence. In the present study, we aimed to clearly separate explicit intentional learning from implicit incidental learning by either informing participants about all details of the sequence or not informing participants about the existence of the sequence. Further, we explored the influence of anticipatory cues during practice while anticipatory cues were either presented (extrinsically triggered anticipation) or not presented (self-reliant intrinsic anticipation). Participants were tested before and after practice in the Practice Sequence and a Control Sequence. To test automatization, tests were performed in Single-Task and Dual-Task Blocks. Results showed that after learning with explicit instructions, participants memorized the sequence more deeply and executed the sequence faster than after learning without explicit instructions. Further, by learning with anticipatory cues, participants memorized the sequence less deeply and executed the sequence slower than by learning without anticipatory cues. Unexpectedly, automatization was sequence-unspecific and independent of the practice conditions. In conclusion, detailed explicit prior information about the sequence facilitates sequence learning while anticipatory online cues during practice hamper sequence learning.
INTRODUCTION
Motor sequence learning provides valuable insights into the process of skill acquisition to plan, execute, and coordinate movements. Motor sequence learning is closely linked to acquisition and memory processes (Reber & Squire, Citation1998). Investigating how we acquire and retain motor sequences sheds light on the broader mechanisms of learning and memory in the brain and is of significance for various applied contexts. For instance, knowledge about human motor control can be applied to clinical settings by designing assistive technologies and prosthetics that enhance motor skills and movement control (Davoodi & Loeb, Citation2012). In educational settings, it may aid in understanding how to optimize motor sequence learning, to enhance teaching methods and to improve learning outcomes (Jongbloed-Pereboom et al., Citation2019; van Abswoude et al., Citation2021).
Acquisition and Retrieval in the Serial Reaction Time Task
A widely used experimental paradigm to investigate motor sequence learning is the Serial Reaction Time (SRT) task (Schwarb & Schumacher, Citation2012). The SRT task is designed to study implicit learning, particularly the acquisition of motor sequences or patterns without conscious awareness while it can be also implemented in explicit learning settings, where the information of an existing regularity of sequence elements might be given to the learners. In the SRT task, participants are typically seated in front of a computer screen and instructed to respond as quickly as possible to a series of stimuli presented on the screen, such as colored shapes or symbols. The stimuli are arranged in a sequence that follows a specific pattern (i.e. a predictable sequential order). In the incidental (implicit) learning paradigm, participants are not explicitly informed about the sequence or pattern of the stimuli. Typically, they respond by pressing keys on a keyboard that are visual-spatially corresponding to the stimuli on the screen. The critical aspect of the SRT task is that the sequence of stimuli repeats over multiple trials. This repetition allows participants to incidentally learn the underlying sequence structure through the gradual acquisition of cognitive and motor associations (Dahm & Rieger, Citation2023; Verwey et al., Citation2015). Even though participants might not be explicitly aware of the sequence, their response times tend to decrease as they become more proficient in anticipating and responding to the upcoming stimuli (Dahm, Hyna, et al., Citation2023; Nissen & Bullemer, Citation1987). To dissociate the learning of stimulus-response coupling and sequence-learning, the performance of the practiced sequence is usually compared with a control sequence (e.g. a random sequence or an unpracticed sequence) (i.e. Keele et al., Citation2003).
Experimental findings indicate a dissociation of SRT task performance (reaction time difference between learned and pseudorandom sequences) and direct measures of sequence knowledge (free generation tests and recognition tests, e.g. Jiménez et al., Citation1996; Willingham et al., Citation1989). These findings have led to the assumption that motor sequences are acquired through distinct processes, which can be delineated into unconscious and conscious learning mechanisms (Destrebecqz & Cleeremans, Citation2001; Hikosaka et al., Citation1999; Jones & McLaren, Citation2009; Willingham et al., Citation1993). These can be further described as being based on associative learning leading to unconscious sequence acquisition and representation, that operates in addition to more rule-based and strategy-based learning (McLaren, Citation1994). These dissociations are supported by findings showing a dissociation of different measures dependent on practice being either intentional with explicit information provided about the existence of a sequence or incidental without sequence information provided (Jiménez et al., Citation2006; Jones & McLaren, Citation2009). However, explicit knowledge can also arise from implicit learning (Cleeremans & Jiménez, Citation2002) for instance in experimental groups who received no instruction about the existence of sequential characteristics prior to practice (Pascual-Leone et al., Citation1994; Perruchet & Amorim, Citation1992).
While many studies (Destrebecqz & Cleeremans, Citation2001; Jiménez et al., Citation1996; Keele et al., Citation2003; Reber & Squire, Citation1998; Rüsseler & Rösler, Citation2000; Schuck et al., Citation2012; Song et al., Citation2007; Verwey et al., Citation2010) focused on the explicitness of sequence information after practice (distinction of explicit and implicit retrieval), a clear separation of explicit and implicit binding (or learning) has seldom been implemented experimentally so far (see for the explicitness of providing information before practice) (Tanaka & Watanabe, Citation2017). To acquire sequence representations, explicit information on the existence and structure of the to be learned sequence seems to be beneficial (Curran & Keele, Citation1993). Moreover, providing explicit information about the entire sequence prior to motor-practice increased recall performance of the sequence structure, but did not facilitate performance in the SRT directly after practice (Sanchez & Reber, Citation2013). However, none of these studies involved a follow-up measure of learning, that evaluates long-term learning effects.
FIGURE 1. Framework of acquisition and retrieval processes in motor learning. Depending on the information provided in the instructions, the acquisition of the action representation is intentional or incidental. Tests for retrieval constitute whether implicit or explicit representations are retrieved.
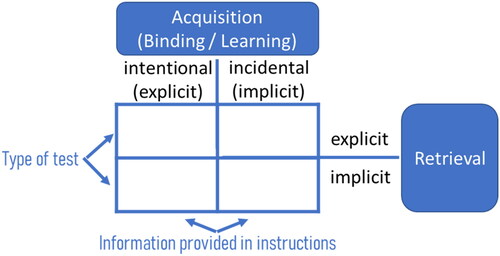
The binding and retrieval model in action control (Frings et al., Citation2020) suggests that action control is a dynamic process that involves the interaction between the binding and retrieval stages. These processing stages work together to enable the selection, initiation, and monitoring of actions in a flexible and goal-directed manner (Hommel, Citation2009; Hommel et al., Citation2001). In the binding stage, the brain binds together different features and aspects of a given action, such as the goal, the motor plan, and the context in which the action occurs. This process creates a coherent representation of the action and enables the integration of various information sources related to the action. For example, when picking up a cup of coffee, the binding stage would involve combining the goal of quenching thirst, the motor plan to reach out and grasp the cup, and the contextual information about the location of the cup. Once the action is bound, it enters the retrieval stage. At this stage, the brain is able to retrieve a relevant action representation from memory and to activate the associated motor plans and control processes necessary to execute the action. The retrieval process involves accessing and integrating information from long-term memory, such as learned action sequences and motor skills.
Automatization of Motor Sequences
In the context of skill acquisition, most models propose distinct learning stages and suggest a reduction in the need for attentional control as learning progresses (Chein & Schneider, Citation2012; Fitts & Posner, Citation1967). When it comes to motor sequence learning guided by external stimuli, it is expected that initially, sequence execution is controlled by reacting to each stimulus individually (referred to as the reaction mode; Verwey et al., Citation2015). As learning progresses, extrinsic visual-spatial representations of the sequence begin to guide its execution. This is known as the associative mode which still heavily demands for cognitive resources, but upcoming stimuli might be anticipated (Verwey et al., Citation2015). The learner relies on working-memory-dependent processes, utilizing spatially coded sequence information that is independent of the body parts involved (environment-based representations) for sequence execution (Hikosaka et al., Citation2002; Verwey et al., Citation2015). During these early learning stages, spatial representations are translated into a motor code in a step-by-step manner to generate motor commands, with a cognitive processor (in the prefrontal cortex) responsible for spatial representation and an executive controller (in the premotor cortex) handling translation of the spatial code into the motor code. With continued practice, attention-dependent visual-spatial representations become less necessary as the motor system, with its effector-dependent motor representations (Dahm, Weigelt, et al., Citation2023), takes over sequence production. This reduction in attentional demands during sequence production is believed to be a result of chunking processes that bind together sequence elements, leading to an increase in motor automaticity (referred to as the chunking mode; Immink et al., Citation2020; Verwey, Citation1996; Verwey et al., Citation2015). Such automaticity effects are accompanied by a shift in neural activations from frontal to parietal areas during sequence production (Lohse et al., Citation2014; Sakai et al., Citation1998). In later stages of learning, motor representations can be accessed with minimal reliance on working-memory resources, further contributing to motor automaticity, as indicated by decreased dual-task costs when an attention demanding cognitive task is executed while the primary motor task is performed (Abernethy et al., Citation2012; Fitts & Posner, Citation1967).
Effects of Anticipatory Information
When providing sequence information before movement initiation (as in intentional acquisition), the movement parameters can be preplanned ahead (Haith et al., Citation2016; Kaufman et al., Citation2014; Rosenbaum et al., Citation1987; Wong et al., Citation2015). However, planning long sequences entirely is unlikely (Ariani et al., Citation2021; Haggard, Citation1998). This is where online planning (Ariani & Diedrichsen, Citation2019) comes into play. Such online planning can be supported by anticipatory cues that are presented during movement execution. A recent study integrated anticipatory cues informing about the upcoming stimuli into sequence production, where anticipatory information (i.e. the upcoming path in a tracking task) reduced dual-task costs (Broeker et al., Citation2017) during the short-term acquisition in a single session experiment. In another study (Ariani et al., Citation2021), anticipatory cues enhanced the production of random sequences as long as the anticipatory cues were provided, but not when they were withdrawn. At this point, respective effects of anticipatory information on long-term sequence learning and automatization (measured as the reduction of dual-task costs) remain questionable. External cues on upcoming stimuli that are presented during practice might speed up the acquisition of a spatial code as sequence information is provided simultaneously for two successive elements. It has been shown that extrinsically triggered anticipation leads to more accurate and faster performance than self-reliant intrinsic anticipation in a single-session experiment (Jongbloed-Pereboom et al., Citation2019). An alternative idea is that external cues that trigger the appearance of the next stimulus already in advance, hamper the acquisition of the sequence. Instead of learning the sequence, participants may rely on the availability of these cues without the involvement of memory retrieval and may therefore even become dependent on this augmented extrinsic information. So, performance will deteriorate when the anticipatory information is not provided anymore. For instance, in music the representation of a motor sequence may be acquired stronger if practiced without seeing the notes because it involves the active use of memory processes (Craik & Lockhart, Citation1972). In addition, the availability of such visual cues might particularly hamper automatization, as the learner might be guided to use a reactive mode to solve the task. Here, the reactive mode is based on spatial sequence representations associated to attention demanding processes (Hikosaka et al., Citation1999).
Aims of the Study
In the present study, we designed explicit learning instructions by informing participants about the existence of a sequence and providing detailed visual information about the twelve element-structure of the motor sequence (Intentional Learning Group). The Incidental Learning Group received no information about the existence of a sequence. Due to the explicit knowledge of the sequence, we expected participants in the Intentional Learning Group to become faster in the Practice Sequence than those in the Incidental Learning Group (Yonelinas, Citation2002). However, automatization was expected to be stronger in the Incidental Learning Group than in the Intentional Learning Group because focusing on explicit information is expected to provoke a high dominance of the attention demanding spatial system. This would be in line with data on neural correlates of error processing, which is more pronounced after intentional sequence learning (Ferdinand et al., Citation2008). In addition to the explicitness in the instructions, we manipulated online anticipatory cue information during practice. For this, half of the participants were shown two target positions in one and the same stimulus. One of the targets was the actual target and the other one (the cue) provided information about the upcoming target. Regarding the anticipatory cue manipulation, we expected that extrinsically triggered anticipation cues during practice will hamper learning of the sequence (Ariani et al., Citation2021), particularly in the Incidental Learning Group.
In order to assess explicit and implicit retrieval processes, several test types have been used (Destrebecqz & Cleeremans, Citation2001; Keele et al., Citation2003; Reber & Squire, Citation1998; Rüsseler & Rösler, Citation2000; Schuck et al., Citation2012; Song et al., Citation2007). To start with, it is noteworthy to mention that most test types do not purely assess either explicit retrieval or implicit retrieval but rather a combination of both (Cleeremans, Citation2014; Destrebecqz & Cleeremans, Citation2001; Yonelinas, Citation2002). In the present study, we used four types of retrieval tests after practice that assessed free generation (rather explicit retrieval) and recognition (implicit and explicit retrieval) of either motor or visuospatial representations. We expected better retrieval performance after learning with explicit instructions than after learning with implicit instructions. Further, we expected better retrieval performance after learning without anticipatory cues than after learning with anticipatory cues.
METHODS
Participants
All participants were between 18 and 35 years old. Due to technical issues, the data sets of 15 participants were incomplete and therefore not analyzed. Of 87 complete data sets, seven were excluded from analysis due to the following reasons: Four participants were excluded because they made more than three errors in the cognitive secondary task (i.e. Tone Counting Task) during Dual-Task conditions (Dahm, Hyna, et al., Citation2023). Two participants performed extremely slowly, as indicated by RTs in the first test before practice that were more than 3 standard deviations above the mean of all participants. Removing such outliers is a common procedure (Ilyas & Chu, Citation2019), as outliers may lead to differences between groups in Pretest performance and in consequence bias practice effects. One participant had missing values in RTs because Target Tones in the Tone Counting Task were always followed by incorrect responses in the SRT.
The distribution of sex and the means and standard deviations of age, and of the Laterality Index (assessed with the Edinburgh Handedness Inventory, Oldfield, Citation1971) of the remaining 80 participants are shown in , separately for each practice group. All participants gave informed consent, and the study was approved by the local ethics committee.
TABLE 1. Sociodemographic data of the Incidental Learning group without anticipatory cues, the Incidental Learning group with anticipatory cues, the Intentional Learning group without anticipatory cues, and the Intentional Learning group with anticipatory cues.
Primary Task: Serial Reaction Time Task
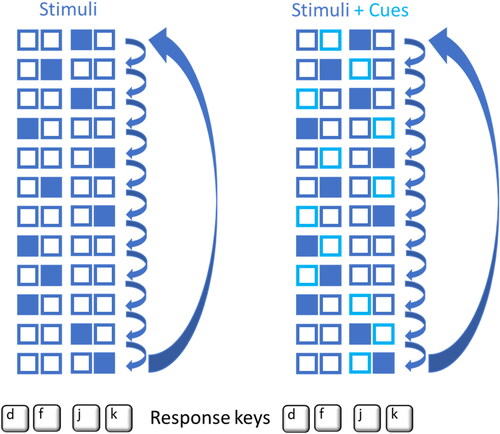
In the Serial Reaction Time Task, participants react as fast as possible to a series of stimuli (Reber & Squire, Citation1998). The experimental sequence (from Dahm & Rieger, Citation2023) had two possible orders which were counterbalanced across participants: a Practice Sequence (j-f-j-d-k-f-k-d-f-d-j-k) and a Control Sequence (d-f-j-d-j-f-k-j-k-d-k-f). In both sequences, each element appeared equally often, the same element was not repeated on successive trials, and each transition between elements occurred equally often. Thus, first order learning was not possible (Reber & Squire, Citation1998). The highest overlap of successive stimuli between the experimental sequences was a triplet (e.g. d-k-f). shows one of the sequences. Each Block involved 120 responses involving ten repetitions of the sequence. The starting point within the sequence was randomly chosen for each Block. A Block started with four empty boxes (2.5 × 2.5 cm). After 500 ms, one of the boxes was filled with blue color indicating the spatially corresponding response. Responses were given on the “d,” “f’,” “j,” and “k” keys of the keyboard. The index and middle finger of both hands were put on those keys accordingly. In case of an incorrect response, the target remained on screen until correct response. The subsequent stimulus appeared immediately after the correct response (response-stimulus interval = 0).
FIGURE 2. Figural explanations of the experimental sequences shown to participants in the explicit sequence learning instructions Without Anticipatory Cues (on the left) and With Anticipatory Cues (on the right). Filled boxes indicate the current response and light blue rectangles indicate the upcoming response. Note that during the Serial Reaction Time Task only one set of four boxes (2.5 × 2.5 cm) was shown at once.
Secondary Task: Tone Counting
In sessions involving the Tone Counting Task (TCT; Verwey et al., Citation2014), a short Tone Discrimination Task was performed to check and adjust participants individual sound setting. The Tone Discrimination Task involved a target tone (440 Hz; scientific pitch notation A4, 100 ms) and a distractor tone (698 Hz; scientific pitch notation: F5; 100 ms) which was first presented together with the instructions. Then, one of the tones was presented again (random order). Participants were able to adjust the loudness of the tones to their needs and setting. For this, participants indicated whether the tone was inappropriately quiet or inappropriately loud. In case the volume was appropriate, they indicated whether it is a high tone or a low tone. The discrimination task ended if both the low and high tone were four times consecutively identified correctly.
In the TCT (Verwey et al., Citation2014), participants counted the Target Tones. Each Block consisted of twenty tone-incidents. On each tone-incident a target tone, a distracter tone, or no-tone were randomly presented with the restriction that each incident appeared at least four times and maximal twelve times in a Block. In single TCT Blocks, 20 TCT incidents (Target Tones, Distractor Tones, no tone) were randomly presented with a random interval between tone-incidents of 2000 to 4000 ms.
To provoke dual-task costs in RTs of the SRTT, participants were asked to prioritize the TCT in Dual-Task Blocks. In Dual-Task Blocks each twelve-element sequence involved a random presentation of two tone-incidents. Between tone-incidents were at least two responses without tone-incidents. The tones appeared simultaneously with the onset of one of the visual stimuli (Verwey et al., Citation2014). At the end of each Block, participants reported the number of Target Tones via mouse click on response boxes from 1 to 12 on the screen.
Task and Procedure
The experiment was run on participants’ personal notebooks using OpenSesame 3.3.10 (Mathôt et al., Citation2012) using an out-of-the lab approach (Dahm, Ort, et al., Citation2023). The experiment file is available at https://osf.io/86tgm. Participation lasted approximately 15 min in each of the eleven sessions. Starting each session, participants were reminded to sit at a table in a quiet room. The time between consecutive sessions was approximately 24 h, but at least one night.
The Pretest and Posttest were eleven days apart (see ). In between, participants practiced six Blocks of 120 responses each day (600 sequence repetitions in total). In Incidental Instruction Groups, participants were not informed about a possible sequential structure of the stimulus material. In the Intentional Instruction Groups, participants were informed about the twelve-element sequence in advance to each practice session. All twelve elements were shown graphically (see ), and participants were asked to memorize the sequence for at least three minutes. In the Without Anticipatory Cues Groups, the subsequent response-relevant stimulus (s + 1) was not foreseeable in the stimulus material (s) but could be anticipated during acquisition of the sequence representation. In the With Anticipatory Cue Groups, the subsequent response-relevant stimulus (s + 1) was already forecasted in the stimulus material (s) by a brighter bounding box (see ). The same color (blue) with light saturation was chosen to maintain primary salience of the actual target (dark color with filled boxes). After each Block, participants received feedback about the mean reaction time of correct responses in that Block. The feedback was intended to increase participants’ motivation to perform as fast and correct as possible (Wilson et al., Citation2017).
FIGURE 3. Depiction of the experimental design. For a detailed description of the Pretest and the Posttest see . Note that Instruction and Practice differed between participants according to their group assignment.
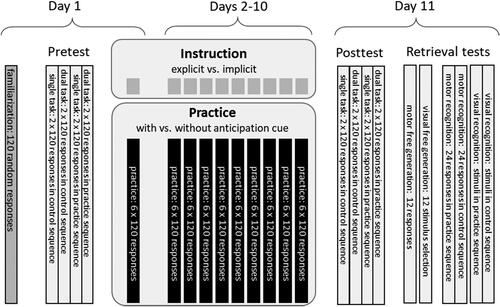
Session 1 started with a Familiarization Block of 120 random responses. This was followed by the Pretest. In the Pretest, Single-Task Blocks and Dual-Task Blocks were performed with the Practice Sequence and the Control Sequence. Each Block was performed twice in a counterbalanced order (see ).
TABLE 2. Pretest and Posttest were performed from top to bottom.
In Session 11, participants performed the Posttest, which was equal to the Pretest, but included further tests in the following order. First, to test for motor representations, participants performed a Free Generation Test where they responded twelve times on the keyboard while seeing empty boxes. Second, to test for visuospatial representations, participants performed a Free Recall Test of the visuospatial stimuli where they selected the stimulus order by twelve mouse-clicks on the four possible stimuli. Third, to test for motor recognition, participants indicated on a rating scale from 1 (very unlikely) to 9 (very likely) whether a previously performed Block of 24 responses corresponded to the Practice Sequence. This was done for the Practice Sequence and the Control Sequence. Fourth, to test for visuospatial recognition, participants indicated on a rating-scale from 1 (very unlikely) to 9 (very likely) whether a visually depictured sequence (as in ) corresponded to the Practice Sequence. This was done for the Practice Sequence and the Control Sequence as well as for their Mirror Sequences. The order of the four sequences in the recognition tests was randomized without restrictions.
Data Analysis
Reaction time (RT) was defined as the time between stimulus onset and the correct response. The total error rate above all participants was M±SD = 6.5 ± 6% (see supplemental material for each condition separately). RTs of the first twelve responses were excluded from each test block. To analyze sequence-specific Learning in Single-Task Blocks, we calculated the median of the remaining 108 correct responses. Afterwards, the mean of the two equal Blocks (see ) was calculated. To analyze recall performance in the Free Generation Tests, we calculated the number of triplets that matched with the Practice Sequence and, as a control, with the Mirror Sequence (Bird & Heyes, Citation2005). Here, a score of 12 indicates a full match and a score of 0 indicates no match of the sequences. We further analyzed visuospatial and motor sequence recognition ratings.
Dependent variables were analyzed using mixed model ANOVAs (Kassambara, Citation2021). Further comparisons were conducted using t-tests with Holm adjusted pairwise comparisons. Where appropriate, we report minimum (pmin) or maximum (pmax) statistical values. Statistical significance was set at p < .05. Raw data as well as the code for data preparation and data analyses are available at https://osf.io/86tgm.
RESULTS
Reaction Times in Test Blocks
To assess general Sequence-unspecific and Sequence-specific Learning effects, we analyzed RTs in Single-Task and Dual-Task Blocks. The distribution of RTs (in ms) of Instructions (Intentional, Incidental) and Anticipatory Cues (With, Without) is shown separately for Session (Pretest, Posttest), Sequence (Practice, Control), and Task (Single-Task, Dual-Task) in .
FIGURE 4. Violin plots and means of reaction time (RT in ms) depending on Instruction (Intentional, Incidental), Anticipatory Cues (With, Without), task (Single-Task, Dual-Task), Sequence (Practice, Control), and Session (Pretest, Posttest).
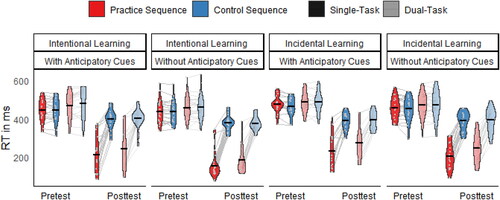
Sequence-unspecific Learning was indicated by the significant main effect of Session, F (1, 76) = 642, p < .001, = .89. RTs became significantly shorter from Pretest (M±SD = 462 ± 62 ms) to Posttest (M±SD = 304 ± 111 ms). This was significant in all groups in both the Practice Sequence (p < .001, d ⩾ 2.5) as well as in the Control Sequence (p ⩽ .003, d ⩾ 1.4).
Sequence-specific Learning – shorter RTs in the Practice Sequence than in the Control Sequence – was indicated by the significant main effect of Sequence, F (1, 76) = 429.6, p < .001, = .85. However, this was modified by the significant interaction between Sequence and Session as well as two three-way interactions (see below). The significant interaction between Sequence and Session, F (1, 76) = 649.9, p < .001,
= .9, indicated that RTs were significantly shorter in the Practice Sequence than in the Control Sequence in the Posttest (p < .001, d = 2.6), but not in the Pretest (p = .985, d < 0.1).
The significant interaction between Sequence, Instruction, and Session, F (1, 76) = 5.2, p = .025, = .06, indicated that in the Posttest RTs in the Practice Sequence were significantly shorter in the Intentional Instruction Group than in the Incidental Instruction Group (p = .019, d = 0.5). This was not the case in the Control Sequence (p = .673, d = 0.1). In the Pretest, both sequences did not significantly differ between the Instruction Groups (p ⩾ .119, d ⩽ 0.4). Hence, detailed explicit information about the sequence facilitates the learning of the sequence.
Like the Instruction conditions, the significant interaction between Sequence, Anticipatory Cues, and Session, F (1, 76) = 5.5, p = .021, = .07, indicated that in the Posttest RTs in the Practice Sequence were significantly shorter in the Without Anticipatory Cues Group than in the With Anticipatory Cues Group (p = .019, d = 0.5). This was not the case in the Control Sequence (p = .279, d = 0.2). In the Pretest, both sequences did not significantly differ between the Anticipatory Cues Groups (p ⩾ .28, d ⩽ 0.2). Hence, anticipatory cues during learning hamper the learning of the sequence.
Automatization—measured by dual-task costs that are evident be the comparison of performance in Dual-Task Blocks and Single-Task Blocks - was indicated by the significant main effect of Task, F (1, 76) = 76.7, p < .001, = .5, which was modified by the significant interaction between Task, Session, and Sequence. The interaction indicated that RTs in the Pretest were significantly longer in Dual-Task Blocks than in Single-Task Blocks in both sequences (p < .001, d ⩾ 0.6), while RTs in the Posttest were significantly longer in Dual-Task Blocks than in Single-Task Blocks in the Practice Sequence (p < .001, d = 0.7), but not in the Control Sequence (p = .428, d = 0.1). Surprisingly, after practice dual-task costs were not significant in the Control Sequence, but still in the Practice Sequence. This may indicate automated stimulus-response coupling in the Control Sequence, while performance in the Practice Sequence might still demand for attentional cognitive processing. All remaining effects were not significant,
< .04.
Reaction Times during Practice
To assess performance during practice, we analyzed RTs in Single-Task and Dual-Task Blocks. The distribution of RTs (in ms) of Instructions (Intentional, Incidental) and Anticipatory Cues (With, Without) is shown separately for Session (Pretest, Posttest) in .
FIGURE 5. Violin plots and means of dual-task costs (ΔRT in ms) depending on Instruction (Intentional, Incidental), Anticipatory Cues (With, Without), and Session (from 1 to 10).
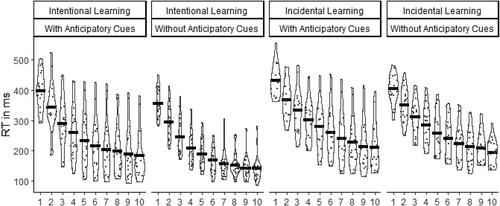
Learning effects were shown by the significant main effect of Session, F (9, 684) = 459.9, p < .001, = .86, indicating that RTs were reduced over time (M1±SD = 395 ± 58 ms, M2±SD = 336 ± 69 ms, M3±SD = 292 ± 75 ms, M4±SD = 260 ± 77 ms, M5±SD = 237 ± 79 ms, M6±SD = 218 ± 77 ms, M7±SD = 203 ± 77 ms, M8±SD = 195 ± 71 ms, M9±SD = 186 ± 70 ms, M10 = 180 ± 66 ms).
The impact of sequence information provided in advance to movement initiation was evident in the significant main effect of Instruction, F (1, 76) = 13.1, p < .001, = .15, indicating shorter RTs in the Intentional Learning Groups (M±SD = 226 ± 97 ms) than in the Incidental Learning Groups (M±SD = 277 ± 94 ms).
The impact of sequence information provided during movement execution was evident in the significant main effect of Anticipation Cue, F (1, 76) = 5.6, p = .021, = .07, indicating shorter RTs in the Without Anticipatory Cues Groups (M±SD = 236 ± 90 ms) than in the With Anticipatory Cues Groups (M±SD = 268 ± 105 ms). All interaction effects were not significant,
< .02.
Free Generation Performance
Participants performed two Free Generation Tests where they either visually selected the order of the 12 stimuli by clicking with the cursor or by pressing the 12 keys. From this, we calculated the number of matching triplets with the Practice Sequence and the Control Sequence. The latter indicates the number of matching triplets that would result by chance. Therefore, we calculated Free Generation Performance as the difference score between matching triplets in the Control Sequence and Practice Sequence which indicates the level of memorization of the Practice Sequence.Footnote1 The distribution of the Free Generation Performance depending on Instruction (Intentional, Incidental) and Anticipatory Cues (With, Without) are shown in .
FIGURE 6. Violin plots and means of the Free Generation Performance when selecting visual stimuli or responding on the keyboard depending on Instruction (Intentional, Incidental) and Anticipatory Cue (With, Without).
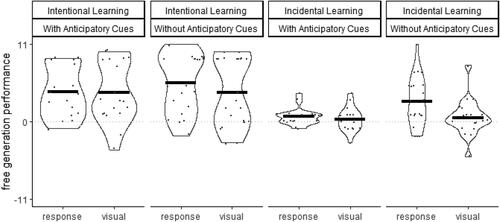
A mixed model ANOVA with the between-subject factors on Instruction (Intentional, Incidental) and Anticipatory Cues (With, Without) and the within-subject factor Modality (Response, Visual) was conducted on Free Generation Performance. The impact of sequence information provided in advance to movement initiation was evident in the significant main effect of Instruction, F (1, 75) = 21.2, p < .001, = .22, indicated significantly more memorized triplets of the Practice Sequence in the Intentional Instruction Groups (M±SD = 4.5 ± 4.2) than in the Incidental Instruction Groups (M±SD = 1.2 ± 2.7).
The impact of sequence information provided during movement execution was evident in the significant main effect of Modality, F (1, 75) = 9.7, p = .003, = .12, and the significant interaction between Anticipatory Cues and Modality, F (1, 75) = 6.4, p = .014,
= .08. Free Generation Performance was significantly higher in the Without Anticipatory Cues Group (M±SD = 4.3 ± 4) than in responses in the With Anticipatory Cues Group (M±SD = 2.6 ± 3.3, p = .046, d = 0.5) for responses, but not for visual selections (p = .89, d = 0.03). All remaining effects and interactions were not significant,
⩽ .02.
Recognition Ratings
As for Free Generation Tests, participants performed two recognition ratings after they either saw a visually presented order of 12 stimuli without pressing keys or after they pressed the 12 keys. Again, we calculated the difference score between ratings in the Control Sequence and ratings in the Practice Sequence which indicates the Recognition Performance of the Practice Sequence. The distribution of the Recognition Performance depending on Instruction (Intentional, Incidental) and Anticipatory Cues (With, Without) are shown in .
FIGURE 7. Violin plots and means of the Recognition Performance after seeing visual stimuli or responding on the keyboard depending on Instruction (Intentional, Incidental) and Anticipatory Cues (With, Without).
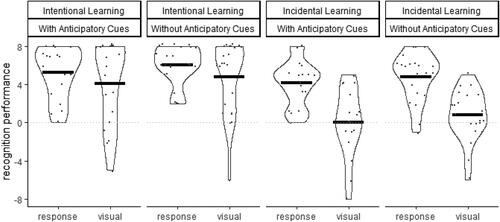
A mixed model ANOVA with the between-subject factors on Instruction (Intentional, Incidental) and Anticipatory Cues (With, Without) and the within-subject factor Modality (Response, Visual) was conducted on Recognition Performance. The impact of sequence information provided in advance to movement initiation was evident in the significant main effect of Instruction, F (1, 76) = 22.1, p < .001, = .23, indicated significantly higher Recognition Performance in the Intentional Instruction Group (M±SD = 5.1 ± 3.3) than in the Incidental Instruction Group (M±SD = 2.5 ± 3.5).
The impact of sequence information provided during movement execution was evident in the significant main effect of Modality, F (1, 76) = 39.6, p = .003, = .34, and the significant interaction between Instruction and Modality, F (1, 76) = 12.3, p = .001,
= .14. In the Incidental Instruction Group, Recognition Performance was significantly higher after responses (M±SD = 4.5 ± 2.4) than after visual presentation of the sequence (M±SD = 0.4 ± 3.1, p < .001, d = 1.2) whereas this did not significantly the Intentional Instruction Group (p = .061, d = 0.3). All remaining effects and interactions were not significant,
⩽ .02.
DISCUSSION
The aim of the present study was to investigate automatization after implicit and explicit sequence learning for which participants either received detailed sequence information (Intentional Learning Groups) or not (Incidental Learning Groups). During learning, participants received either anticipation cues that informed about the next upcoming stimulus or anticipated intrinsically (without cues). Before and after practice, participants were tested in Single-Task as well as Dual-Task Blocks. In the Posttest, RTs of the Practice Sequence were shorter after intentional learning than after incidental learning, indicating the expected facilitation effects of explicit information that is given prior to practice (Yonelinas, Citation2002). Further, RTs of the Practice Sequence were shorter after practice Without Anticipatory Cues than after practice With Anticipatory Cues, while anticipatory information was not present in test conditions. Hence, external cues during practice hamper sequence-specific learning. Similarly, RTs during practice indicated that explicit information prior to practice enhances the acquisition while anticipatory cues hampered acquisition. Unexpectedly, dual-task costs did not significantly differ between groups, indicating similar automatization in all groups. Free Generation Performance showed that expectedly more parts of the sequence were retrieved in the Intentional Instruction Group than in the Incidental Instruction Group. Moreover, practice Without Anticipatory Cues also facilitated Free Generation Performance as compared to practice With Anticipatory Cues. Finally, as expected, recognition performance showed the recognition of the sequence to be facilitated in the Explicit Instructions Group compared to the Implicit Instructions Group, while the anticipatory cues during practice did not significantly influence recognition.
Sequence-Unspecific Learning
Independent from the sequence, RTs were reduced from Pretest to Posttest. Such sequence-unspecific learning effects (Dahm, Hyna, et al., Citation2023; Dahm & Rieger, Citation2023; Kraeutner et al., Citation2016) may result from enhanced Stimulus-Response Coupling (Ariani & Diedrichsen, Citation2019; Hardwick et al., Citation2019; Schneider & Shiffrin, Citation1977) or simply stem from Testing Effects (learning from repeated testing) (Rowland, Citation2014). More importantly, RTs differed between Dual-Task Blocks and Single-Task Blocks in the Pretest which shows the expected dual-task costs. These dual-task costs indicate attentional demands for the motor task and were reduced from Pretest to Posttest, particularly in the Control Sequence. This finding was somewhat unexpected. Instead of sequence-specific automatization, we observed sequence-unspecific automatization in all groups. Possibly, participants automatized the Stimulus-Response Coupling (Dahm, Hyna, et al., Citation2023), that is, by intensifying the associations between stimuli and their corresponding responses.
Sequence-specific automatization effects as a reduction in dual-task costs have been reported in studies on learning Discrete Sequences (Verwey, Citation2023; Verwey et al., Citation2010). Thus, sequence-specific automatization effects may evolve dependent on sequence characteristics. Automatization may evolve earlier in learning discrete sequences. Further, sequence-specific reductions in dual-task costs might be influenced by sequence complexity (e.g. number of elements). For instance, dual-task costs were lower in familiar sequences than in random sequences using a continuous six-element sequence (Curran & Keele, Citation1993), but not using a continuous twelve-element Sequence (Cohen & Poldrack, Citation2008).
Sequence-Specific Performance
Although we did not observe a sequence-specific reduction in dual-task costs, we observed sequence-specific learning in RTs. Shorter RTs in the Intentional Instruction Group than in the Incidental Instruction Group were observed in the Practice Sequence, but not in the Control Sequence. Hence, as in other studies where participants were informed in advance to practice about a regular sequence structure (Curran & Keele, Citation1993; Ferdinand et al., Citation2008), intentional learning facilitated sequence learning. The results of the RTs during practice further support this finding of enhanced acquisition in the Intentional Learning Group compared to the Incidental Learning Group.
Further, shorter RTs after practice Without Anticipatory Cues than after practice With Anticipatory Cues were observed only in the Practice Sequence, but not in the Control Sequence. Hence, anticipatory cues that provide temporally preceding information about the next upcoming stimulus deteriorate motor sequence learning. This stands in contrast to a previous study showing that anticipation triggered by extrinsic cues leads to more accurate and faster performance than self-reliant intrinsic anticipation (Jongbloed-Pereboom et al., Citation2019). One might argue that performance is boosted for the time the cues are present (Jongbloed-Pereboom et al., Citation2019), but hampered if the cues are withdrawn during tests as in the present study. In respect to the posttest performance, it can be claimed that a test without the cues is as a transfer setting in which the stimulus properties are switched. Thus, the negative effect of anticipatory information during practice on test performance in conditions without such augmented information can be ascribed to negative transfer in the anticipatory information groups or a more transfer-appropriate processing in the groups without anticipatory information (Lee, Citation1988). Hence, during practice, learners in the anticipatory information conditions relied on the objective external (augmented) information without being forced to develop all necessary cognitive mechanisms to be able to execute the task autonomously (Marschall, Citation2007; Sigrist et al., Citation2013). However, in the present study, RTs during practice showed the same pattern of shorter RTs in the Without Anticipatory Cues Group than in the With Anticipatory Cues Group. Possibly, the short Response-Stimulus-Intervals (0 ms) did not provide enough time to process both, stimuli and preparation of the upcoming response, with the cues creating a distraction instead.
Retrieval of the Sequence
We tested for explicit sequence knowledge using a free generation test which requires the search and retrieval of information acquired during practice and recognition ratings requiring a familiarity judgment after retrieving previously acquired information (Yonelinas, Citation2002). As expected, participants in the Intentional Instruction Group were able to freely generate more parts of the sequence than those in the Incidental Instruction Group. Similarly, the Recognition Ratings were higher in the Intentional Instruction Group than in the Incidental Instruction Group. This was predictable, as they were not only aware about the existence of a sequence during practice but were also informed about the length and the sequence structure in advance to practice. Such information clearly helped them to retrieve both visual representations and motor representations of the sequence after practice. We would consider the Free Generation Tests rather as explicit retrieval tests. Most likely, participants consciously recreated the sequence by retrieving memorized visual representations of the sequence (Rünger & Frensch, Citation2010). However, in the Free Generation Task based on responses, it was also possible to generate the sequence without consciously focusing on visuospatial aspects.
Considering anticipatory cues during practice, the results showed that only in participants practicing Without Anticipatory Cues both Free Generation Performance as well as recognition performance were higher for motor responses than for visual selections. Most likely, participants had an unspecific implicit feeling about which responses corresponded with the Practice Sequence (Dahm, Weigelt, et al., Citation2023; Dahm & Rieger, Citation2023; Yonelinas, Citation2002) which did not occur in the visual tasks. Interestingly, this effect was not observed in participants practicing With Anticipatory Cues which shows that cues during practice hampered the acquisition of sequence representations necessary for implicit retrieval.
Limitations, Strength, and Perspectives
We did not observe sequence-specific automatization effects. Maybe sequence-specific automatization might occur more likely when sequences have a discrete character and less elements. Discrete and shorter sequences have been shown to enable chunking (Verwey et al., Citation2010) which can be regarded as one possible mechanism to reduce attentional demands for sequence production (Abrahamse et al., Citation2013; Verwey & Abrahamse, Citation2012). Further, one might argue that sequence-specific automatization was not observed because performance was always as fast as possible which led to shorter sequence durations in the Practice Sequence than in the Control Sequence in the Posttest. Future studies may standardize the sequence speed by implementing fixed response-stimulus-intervals such that Practice Sequence and Control Sequence do not differ in absolute speed in the Posttest. Such intervals have been shown to increase Recognition Performance in the SRT in intentional learning (Destrebecqz & Cleeremans, Citation2001; Rünger, Citation2012), although not always in incidental learning (Rünger, Citation2012). Response-Stimulus-Intervals larger than 0 may provide a larger time span for movement preparation which frees cognitive resources for explicit movement preparation processes.
A strength of the current study is the operationalization of learning, as we measured performance in a delayed retention test with at least one night of sleep after the last Practice Block. In general, the distinction of acquisition performance and retention performance is important as acquisition performance might be of low predictive value for long-term retention (Kantak & Winstein, Citation2012). Despite using the term “learning,” studies on sequence learning often use one session paradigms that lack a valid measure for long-term learning (Jongbloed-Pereboom et al., Citation2019; Sanchez & Reber, Citation2013; Schmidtke & Heuer, Citation1997).
The results showed that providing as much information as possible about the sequential structure of a movement in advance to practice is helpful to acquire sequential actions. Further, providing cues during practice is detrimental for the acquisition and subsequent recall without these cues. This could be interesting in the applied setting. For instance - to come back to the music example—for motor sequence learning, it might be best to first memorize the notes by using explicit information and then go on practicing without notes (as the notes usually provide visual information about subsequent movement targets). Future studies may try to replicate the current findings with a respective task.
CONCLUSION
The current data revealed that explicit information influences sequence learning in a dissociative manner. First, there is a dissociation regarding the type of explicit information (a priori sequence information vs. anticipatory online cues). While explicit information about the sequence structure facilitates learning in terms of reaction times, explicit extrinsic anticipatory cues deteriorate learning in terms of reaction times. The second dissociation is related to the dimension of learning and cognitive effort (sequence production in single-task conditions vs. automaticity). While sequence learning in terms of reaction times in single-task conditions is affected by both types of explicit information (information on sequence structure and anticipatory cues), automaticity of sequence production is not affected by one or the other. The explicit information on sequence structure successfully induced explicit sequence knowledge, while extrinsic anticipatory cues seemed to deteriorate the acquisition of incidental sequence knowledge. The present findings indicate that compared to associative incidental learning, rule-based intentional learning does not only booster sequence knowledge, but also performance in the serial reaction time task.
AUTHOR CONTRIBUTIONS
Individual contributions of authors were as follows: conceptualization, S.D. and D.K.; methodology, S.D. and D.K.; validation, S.D.; formal analysis, S.D.; software, S.D.; investigation, S.D.; resources, S.D. and D.K.; data curation, S.D.; writing—original draft preparation, S.D.; writing—review and editing, S.D., and D.K.; visualization, S.D.; project administration, S.D.; funding acquisition, S.D.
ETHICAL APPROVAL
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional research committee and with the 1964 Helsinki declaration and its later amendments or comparable ethical standards.
INFORMED CONSENT
Informed consent was obtained from all individual participants included in the study.
Supplemental Material
Download PDF (195.3 KB)DISCLOSURE STATEMENT
No potential conflict of interest was reported by the authors.
DATA AVAILABILITY STATEMENT
The author confirms that the data supporting the findings of this study are available within the article and its supplementary materials: https://osf.io/86tgm. Determination of the sample size, all data exclusions, all manipulations, and all measures in the study are reported in the manuscript and its supplemental material. The R packages “tidyverse” (Wickham et al., Citation2019) and “ggplot2” (Wickham, Citation2016) have been used for data restructuring and figure generation.
Additional information
Funding
Notes
1 Note that one participant had missing values in the Free Generation Tests.
REFERENCES
- Abernethy, B., Maxwell, J. P., Masters, R. S. W., Kamp, J. V. D., & Jackson, R. C. (2012). Attentional processes in skill learning and expert performance. In G. Tenenbaum & R. C. Eklund (Hrsg.), Handbook of Sport Psychology (3rd ed., S. 245–263). John Wiley & Sons, Ltd. https://doi.org/10.1002/9781118270011.ch11
- Abrahamse, E. L., Ruitenberg, M. F. L., de Kleine, E., & Verwey, W. B. (2013). Control of automated behavior: Insights from the discrete sequence production task. Frontiers in Human Neuroscience, 7(82), 82. https://doi.org/10.3389/fnhum.2013.00082
- Ariani, G., & Diedrichsen, J. (2019). Sequence learning is driven by improvements in motor planning. Journal of Neurophysiology, 121(6), 2088–2100. https://doi.org/10.1152/jn.00041.2019
- Ariani, G., Kordjazi, N., Pruszynski, J. A., & Diedrichsen, J. (2021). The planning horizon for movement sequences. eNeuro, 8(2), ENEURO.0085-21.2021. https://doi.org/10.1523/ENEURO.0085-21.2021
- Bird, G., & Heyes, C. (2005). Effector-dependent learning by observation of a finger movement sequence. Journal of Experimental Psychology. Human Perception and Performance, 31(2), 262–275. https://doi.org/10.1037/0096-1523.31.2.262
- Broeker, L., Kiesel, A., Aufschnaiter, S., Ewolds, H. E., Gaschler, R., Haider, H., Künzell, S., Raab, M., Röttger, E., Thomaschke, R., & Zhao, F. (2017). Why prediction matters in multitasking and how predictability can improve it. Frontiers in Psychology, 8(2021), 2021. https://doi.org/10.3389/fpsyg.2017.02021
- Chein, J. M., & Schneider, W. (2012). The brain’s learning and control architecture. Current Directions in Psychological Science, 21(2), 78–84. https://doi.org/10.1177/0963721411434977
- Cleeremans, A. (2014). Connecting conscious and unconscious processing. Cognitive Science, 38(6), Article 1286–1315. https://doi.org/10.1111/cogs.12149
- Cleeremans, A., & Jiménez, L. (2002). Chapter 1: Implicit learning and consciousness: A graded, dynamic perspective. In Implicit learning and consciousness. Psychology Press.
- Cohen, J. R., & Poldrack, R. A. (2008). Automaticity in motor sequence learning does not impair response inhibition. Psychonomic Bulletin & Review, 15(1), 108–115. https://doi.org/10.3758/pbr.15.1.108
- Craik, F. I. M., & Lockhart, R. S. (1972). Levels of processing: A framework for memory research. Journal of Verbal Learning and Verbal Behavior, 11(6), 671–684. https://doi.org/10.1016/S0022-5371(72)80001-X
- Curran, T., & Keele, S. W. (1993). Attentional and nonattentional forms of sequence learning. Journal of Experimental Psychology: Learning, Memory, and Cognition, 19(1), 189–202. https://doi.org/10.1037/0278-7393.19.1.189
- Dahm, S. F., Hyna, H., & Krause, D. (2023). Imagine to automatize: Automatization of stimulus–response coupling after action imagery practice in implicit sequence learning. Psychological Research, 87(7), 2259–2274. https://doi.org/10.1007/s00426-023-01797-w
- Dahm, S. F., Ort, E., Büsel, C., Sachse, P., & Mathot, S. (2023). Implementing multi-session learning studies out of the lab: Tips and tricks using OpenSesame. The Quantitative Methods for Psychology, 19(2), 156–164. https://doi.org/10.20982/tqmp.19.2.p156
- Dahm, S. F., & Rieger, M. (2023). Time course of learning sequence representations in action imagery practice. Human Movement Science, 87, 103050. https://doi.org/10.1016/j.humov.2022.103050
- Dahm, S. F., Weigelt, M., & Rieger, M. (2023). Sequence representations after action-imagery practice of one-finger movements are effector-independent. Psychological Research, 87(1), 210–225. https://doi.org/10.1007/s00426-022-01645-3
- Davoodi, R., & Loeb, G. E. (2012). Real-time animation software for customized training to use motor prosthetic systems. IEEE Transactions on Neural Systems and Rehabilitation Engineering: A Publication of the IEEE Engineering in Medicine and Biology Society, 20(2), 134–142. https://doi.org/10.1109/TNSRE.2011.2178864
- Destrebecqz, A., & Cleeremans, A. (2001). Can sequence learning be implicit? New evidence with the process dissociation procedure. Psychonomic Bulletin & Review, 8(2), 343–350. https://doi.org/10.3758/BF03196171
- Ferdinand, N. K., Mecklinger, A., & Kray, J. (2008). Error and deviance processing in implicit and explicit sequence learning. Journal of Cognitive Neuroscience, 20(4), 629–642. https://doi.org/10.1162/jocn.2008.20046
- Fitts, P. M., & Posner, M. I. (1967). Human performance. Brooks/Cole Publishing Company.
- Frings, C., Hommel, B., Koch, I., Rothermund, K., Dignath, D., Giesen, C., Kiesel, A., Kunde, W., Mayr, S., Moeller, B., Möller, M., Pfister, R., & Philipp, A. (2020). Binding and retrieval in action control (BRAC). Trends in Cognitive Sciences, 24(5), 375–387. https://doi.org/10.1016/j.tics.2020.02.004
- Haggard, P. (1998). Planning of action sequences. Acta Psychologica, 99(2), 201–215. https://doi.org/10.1016/S0001-6918(98)00011-0
- Haith, A. M., Pakpoor, J., & Krakauer, J. W. (2016). Independence of movement preparation and movement initiation. The Journal of Neuroscience, 36(10), Article 3007–3015. https://doi.org/10.1523/JNEUROSCI.3245-15.2016
- Hardwick, R. M., Forrence, A. D., Krakauer, J. W., & Haith, A. M. (2019). Time-dependent competition between goal-directed and habitual response preparation. Nature Human Behaviour, 3(12), 1252–1262. https://doi.org/10.1038/s41562-019-0725-0
- Hikosaka, O., Nakahara, H., Rand, M. K., Sakai, K., Lu, X., Nakamura, K., Miyachi, S., & Doya, K. (1999). Parallel neural networks for learning sequential procedures. Trends in Neurosciences, 22(10), 464–471. https://doi.org/10.1016/s0166-2236(99)01439-3
- Hikosaka, O., Nakamura, K., Sakai, K., & Nakahara, H. (2002). Central mechanisms of motor skill learning. Current Opinion in Neurobiology, 12(2), 217–222. https://doi.org/10.1016/s0959-4388(02)00307-0
- Hommel, B. (2009). Action control according to TEC (theory of event coding). Psychological Research, 73(4), 512–526. https://doi.org/10.1007/s00426-009-0234-2
- Hommel, B., Müsseler, J., Aschersleben, G., & Prinz, W. (2001). the theory of event coding (TEC): A framework for perception and action planning. The Behavioral and Brain Sciences, 24(5), 849–878. https://doi.org/10.1017/S0140525X01000103
- Ilyas, I. F., & Chu, X. (2019). Data Cleaning. Association for Computing Machinery and Morgan & Claypool Publishers.
- Immink, M. A., Verwey, W. B., & Wright, D. L. (2020). The neural basis of cognitive efficiency in motor skill performance from early learning to automatic stages. In C. S. Nam (Hrsg.), Neuroergonomics: Principles and practice (S. 221–249) Springer International Publishing. https://doi.org/10.1007/978-3-030-34784-0_12
- Jiménez, L., Méndez, C., & Cleeremans, A. (1996). Comparing direct and indirect measures of sequence learning. Journal of Experimental Psychology. Learning, Memory, and Cognition, 22(4), Article 948–969. https://doi.org/10.1037/0278-7393.22.4.948
- Jiménez, L., Vaquero, J. M. M., & Lupiáñez, J. (2006). Qualitative differences between implicit and explicit sequence learning. Journal of Experimental Psychology. Learning, Memory, and Cognition, 32(3), 475–490. https://doi.org/10.1037/0278-7393.32.3.475
- Jones, F. W., & McLaren, I. P. L. (2009). Human sequence learning under incidental and intentional conditions. Journal of Experimental Psychology. Animal Behavior Processes, 35(4), 538–553. https://doi.org/10.1037/a0015661
- Jongbloed-Pereboom, M., Nijhuis-van der Sanden, M. W. G., & Steenbergen, B. (2019). Explicit and implicit motor sequence learning in children and adults; the role of age and visual working memory. Human Movement Science, 64, 1–11. https://doi.org/10.1016/j.humov.2018.12.007
- Kantak, S. S., & Winstein, C. J. (2012). Learning–performance distinction and memory processes for motor skills: A focused review and perspective. Behavioural Brain Research, 228(1), 219–231. https://doi.org/10.1016/j.bbr.2011.11.028
- Kassambara, A. (2021). rstatix: Pipe-friendly framework for basic statistical tests (0.7.0) [Software]. https://CRAN.R-project.org/package=rstatix
- Kaufman, M. T., Churchland, M. M., Ryu, S. I., & Shenoy, K. V. (2014). Cortical activity in the null space: Permitting preparation without movement. Nature Neuroscience, 17(3), 440–448. https://doi.org/10.1038/nn.3643
- Keele, S. W., Ivry, R., Mayr, U., Hazeltine, E., & Heuer, H. (2003). The cognitive and neural architecture of sequence representation. Psychological Review, 110(2), 316–339. https://doi.org/10.1037/0033-295X.110.2.316
- Kraeutner, S. N., MacKenzie, L. A., Westwood, D. A., & Boe, S. G. (2016). Characterizing skill acquisition through motor imagery with no prior physical practice. Journal of Experimental Psychology. Human Perception and Performance, 42(2), 257–265. https://doi.org/10.1037/xhp0000148
- Lee, T. D. (1988). Chapter 7 Transfer-appropriate processing: a framework for conceptualizing practice effects in motor learning. In O. G. Meijer & K. Roth (Hrsg.), Advances in psychology (Bd. 50, pp. 201–215). https://doi.org/10.1016/S0166-4115(08)62557-1
- Lohse, K. R., Wadden, K., Boyd, L. A., & Hodges, N. J. (2014). Motor skill acquisition across short and long time scales: A meta-analysis of neuroimaging data. Neuropsychologia, 59, 130–141. https://doi.org/10.1016/j.neuropsychologia.2014.05.001
- Marschall, F. (2007). Does frequent augmented feedback really degrade learning? A meta-analysis. Bewegung Und Training, 1, 75–86.
- Mathôt, S., Schreij, D., & Theeuwes, J. (2012). OpenSesame: An open-source, graphical experiment builder for the social sciences. Behavior Research Methods, 44(2), 314–324. https://doi.org/10.3758/s13428-011-0168-7
- McLaren, I. P. L. (1994). Representation development in associative systems. In Causal mechanisms of behavioural development (pp. 377–402). Cambridge University Press. https://doi.org/10.1017/CBO9780511565120.018
- Nissen, M. J., & Bullemer, P. (1987). Attentional requirements of learning: Evidence from performance measures. Cognitive Psychology, 19(1), 1–32. https://doi.org/10.1016/0010-0285(87)90002-8
- Oldfield, R. C. (1971). The assessment and analysis of handedness: The Edinburgh inventory. Neuropsychologia, 9(1), 97–113. https://doi.org/10.1016/0028-3932(71)90067-4
- Pascual-Leone, A., Grafman, J., & Hallett, M. (1994). Modulation of cortical motor output maps during development of implicit and explicit knowledge. Science (New York, N.Y.), 263(5151), 1287–1289. https://doi.org/10.1126/science.8122113
- Perruchet, P., & Amorim, M. A. (1992). Conscious knowledge and changes in performance in sequence learning: Evidence against dissociation. Journal of Experimental Psychology. Learning, Memory, and Cognition, 18(4), 785–800. https://doi.org/10.1037//0278-7393.18.4.785
- Reber, P. J., & Squire, L. R. (1998). Encapsulation of implicit and explicit memory in sequence learning. Journal of Cognitive Neuroscience, 10(2), 248–263. https://doi.org/10.1162/089892998562681
- Rosenbaum, D. A., Hindorff, V., & Munro, E. M. (1987). Scheduling and programming of rapid finger sequences: Tests and elaborations of the hierarchical editor model. Journal of Experimental Psychology. Human Perception and Performance, 13(2), 193–203. https://doi.org/10.1037/0096-1523.13.2.193
- Rowland, C. A. (2014). The effect of testing versus restudy on retention: A meta-analytic review of the testing effect. Psychological Bulletin, 140(6), 1432–1463. https://doi.org/10.1037/a0037559
- Rünger, D. (2012). How sequence learning creates explicit knowledge: The role of response–stimulus interval. Psychological Research, 76(5), 579–590. https://doi.org/10.1007/s00426-011-0367-y
- Rünger, D., & Frensch, P. A. (2010). Defining consciousness in the context of incidental sequence learning: Theoretical considerations and empirical implications. Psychological Research, 74(2), 121–137. https://doi.org/10.1007/s00426-008-0225-8
- Rüsseler, J., & Rösler, F. (2000). Implicit and explicit learning of event sequences: Evidence for distinct coding of perceptual and motor representations. Acta Psychologica, 104(1), 45–67. https://doi.org/10.1016/s0001-6918(99)00053-0
- Sakai, K., Hikosaka, O., Miyauchi, S., Takino, R., Sasaki, Y., & Pütz, B. (1998). Transition of brain activation from frontal to parietal areas in visuomotor sequence learning. The Journal of Neuroscience: The Official Journal of the Society for Neuroscience, 18(5), 1827–1840. https://doi.org/10.1523/JNEUROSCI.18-05-01827.1998
- Sanchez, D. J., & Reber, P. J. (2013). Explicit pre-training instruction does not improve implicit perceptual-motor sequence learning. Cognition, 126(3), 341–351. https://doi.org/10.1016/j.cognition.2012.11.006
- Schmidtke, V., & Heuer, H. (1997). Task integration as a factor in secondary-task effects on sequence learning. Psychological Research, 60(1-2), 53–71. https://doi.org/10.1007/BF00419680
- Schneider, W., & Shiffrin, R. M. (1977). Controlled and automatic human information processing: I. Detection, search, and attention. Psychological Review, 84(1), 1–66. https://doi.org/10.1037/0033-295X.84.1.1
- Schuck, N. W., Gaschler, R., Keisler, A., & Frensch, P. A. (2012). Position–item associations play a role in the acquisition of order knowledge in an implicit serial reaction time task. Journal of Experimental Psychology: Learning, Memory, and Cognition, 38(2), Article 2. https://doi.org/10.1037/a0025816
- Schwarb, H., & Schumacher, E. H. (2012). Generalized lessons about sequence learning from the study of the serial reaction time task. Advances in Cognitive Psychology, 8(2), 165–178. https://doi.org/10.2478/v10053-008-0113-1
- Sigrist, R., Rauter, G., Riener, R., & Wolf, P. (2013). Terminal feedback outperforms concurrent visual, auditory, and haptic feedback in learning a complex rowing-type task. Journal of Motor Behavior, 45(6), 455–472. https://doi.org/10.1080/00222895.2013.826169
- Song, S., Howard, J. H., & Howard, D. V. (2007). Implicit probabilistic sequence learning is independent of explicit awareness. Learning & Memory (Cold Spring Harbor, N.Y.), 14(3), 167–176. https://doi.org/10.1101/lm.437407
- Tanaka, K., & Watanabe, K. (2017). Explicit instruction of rules interferes with visuomotor skill transfer. Experimental Brain Research, 235(6), Article 1689–1700. https://doi.org/10.1007/s00221-017-4933-4
- van Abswoude, F., Mombarg, R., de Groot, W., Spruijtenburg, G. E., & Steenbergen, B. (2021). Implicit motor learning in primary school children: A systematic review. Journal of Sports Sciences, 39(22), 2577–2595. https://doi.org/10.1080/02640414.2021.1947010
- Verwey, W. B. (1996). Buffer loading and chunking in sequential keypressing. Journal of Experimental Psychology: Human Perception and Performance, 22(3), 544–562. https://doi.org/10.1037/0096-1523.22.3.544
- Verwey, W. B. (2023). C-SMB 2.0: Integrating over 25 years of motor sequencing research with the Discrete Sequence Production task. Psychonomic Bulletin & Review. https://doi.org/10.3758/s13423-023-02377-0
- Verwey, W. B., & Abrahamse, E. L. (2012). Distinct modes of executing movement sequences: Reacting, associating, and chunking. Acta Psychologica, 140(3), 274–282. https://doi.org/10.1016/j.actpsy.2012.05.007
- Verwey, W. B., Abrahamse, E. L., & de Kleine, E. (2010). Cognitive processing in new and practiced discrete keying sequences. Frontiers in Psychology, 1, 32. https://doi.org/10.3389/fpsyg.2010.00032
- Verwey, W. B., Abrahamse, E. L., De Kleine, E., & Ruitenberg, M. F. L. (2014). Evidence for graded central processing resources in a sequential movement task. Psychological Research, 78(1), 70–83. https://doi.org/10.1007/s00426-013-0484-x
- Verwey, W. B., Shea, C. H., & Wright, D. L. (2015). A cognitive framework for explaining serial processing and sequence execution strategies. Psychonomic Bulletin & Review, 22(1), 54–77. https://doi.org/10.3758/s13423-014-0773-4
- Wickham, H. (2016). ggplot2: Elegant graphics for data analysis. Springer International Publishing. https://ggplot2.tidyverse.org/
- Wickham, H., Averick, M., Bryan, J., Chang, W., McGowan, L., François, R., Grolemund, G., Hayes, A., Henry, L., Hester, J., Kuhn, M., Pedersen, T., Miller, E., Bache, S., Müller, K., Ooms, J., Robinson, D., Seidel, D., Spinu, V., … Yutani, H. (2019). Welcome to the Tidyverse. Journal of Open Source Software, 4(43), 1686. https://doi.org/10.21105/joss.01686
- Willingham, D. B., Greeley, T., & Bardone, A. M. (1993). Dissociation in a serial response time task using a recognition measure: Comment on Perruchet and Amorim (1992). Journal of Experimental Psychology: Learning, Memory, and Cognition, 19(6), 1424–1430. https://doi.org/10.1037/0278-7393.19.6.1424
- Willingham, D. B., Nissen, M. J., & Bullemer, P. (1989). On the development of procedural knowledge. Journal of Experimental Psychology: Learning, Memory, and Cognition, 15(6), Article 1047–1060. https://doi.org/10.1037/0278-7393.15.6.1047
- Wilson, K. M., Helton, W. S., de Joux, N. R., Head, J. R., & Weakley, J. J. S. (2017). Real-time quantitative performance feedback during strength exercise improves motivation, competitiveness, mood, and performance. Proceedings of the Human Factors and Ergonomics Society Annual Meeting, 61(1), 1546–1550. https://doi.org/10.1177/1541931213601750
- Wong, A. L., Haith, A. M., & Krakauer, J. W. (2015). Motor planning. The Neuroscientist: A Review Journal Bringing Neurobiology, Neurology and Psychiatry, 21(4), 385–398. https://doi.org/10.1177/1073858414541484
- Yonelinas, A. P. (2002). The nature of recollection and familiarity: A review of 30 years of research. Journal of Memory and Language, 46(3), 441–517. https://doi.org/10.1006/jmla.2002.2864