
Abstract
As digital instrumentation and control (I&C) systems are gradually introduced into nuclear power plants (NPPs), concerns about the I&C systems’ reliability and safety are growing. Fault detection coverage is one of the most critical factors in the probabilistic safety assessment (PSA) of digital I&C systems. To correctly estimate the fault detection coverage, it is first necessary to identify important factors affecting it. From experimental results found in the literature and the authors’ experience in fault injection experiments on digital systems, four system-related factors and four fault-related factors are identified as important factors affecting the fault detection coverage. A fault injection experiment is performed to demonstrate the dependency of fault detection coverage on some of the identified important factors. The implications of the experimental results on the estimation of fault detection coverage for the PSA of digital I&C systems are also explained. The set of four system-related factors and four fault-related factors is expected to provide a framework for systematically comparing and analyzing various fault injection experiments and the resultant estimations on fault detection coverage of digital I&C systems in NPPs.
1. Introduction
As an increasing number of digital instrumentation and control (I&C) systems are being introduced into nuclear power plants (NPPs), concerns about the reliability and safety of digital I&C systems are also growing. Even though digital I&C systems provide many advantages over analog I&C systems, including more flexibility and improved capabilities such as fault tolerance and self-diagnostic features, challenges such as rapidly changing digital technology, increased complexity, and unique failure modes are also emerging [Citation1].
One of the challenges that has received much attention is the development of a consensus method for the probabilistic safety assessment (PSA) of digital I&C systems in NPPs. Lu and Jiang [Citation2] provided an overview of PSA applications in three areas of digital I&C systems in NPPs. Kang et al. [Citation3] provided an overview of the risk quantification issues related to the digitalized safety systems in NPPs. Authen and Holmberg [Citation4] provided an overview of the state-of-the-art of the PSA of digital I&C systems in NPPs.
Based on the mathematical definition of fault coverage given in NUREG/GR-0020 [Citation5], fault detection coverage, Cd, is defined as the probability that a system will detect a fault occurring in the system, as follows:
(1)
It is alternatively denoted as self-diagnostic fault detection rate [Citation6], effectiveness of self-tests [Citation7], and so on. After a sensitivity study on various important factors considered in the PSA of NPPs with digital I&C systems, Kang and Sung [Citation8] identified the fault detection coverage of a digital I&C system as one of the most critical factors in the PSA of digital I&C systems in NPPs. Authen et al. [Citation9] emphasized the importance of fault detection coverage by stating that a seemingly moderate change in the coverage, e.g., from 90% to 80%, will double the frequency of latent failures and severely impact the core damage frequency.
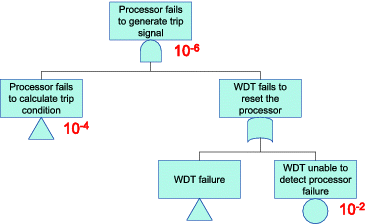
The importance of fault detection coverage can also be demonstrated in . The figure illustrates how the fault detection coverage of a watchdog timer (WDT) is modeled with a processor in the digitalized reactor protection system (RPS) part of a PSA model. Generally, the purpose of a WDT is to monitor the operation of the processor and provide reset signals when it does not receive heartbeat signals from the processor. If the failure probability of the processor is 1E-4, and the fault detection coverage of the WDT is 99%, i.e., the failure probability of the WDT to reset the processor when necessary is 1E-2, the failure probability of the processor to generate a reactor trip signal when necessary becomes 1E-6, which is two orders lower than the original failure probability of the processor.
Figure 1. Modeling of the fault detection coverage of a WDT in a PSA.
In the case of the PSA of an advanced boiling water reactor, 95% was assumed for the fault detection coverage of the integrated self-test provision built into the microprocessors of safety system logic and control [Citation6]. In the case of the AP1000 PSA [Citation7], the fault detection coverage is estimated to be approximately 90%–99% based on extensive, detailed failure mode and effect analysis and functional block analysis performed on the modules of the protection and safety monitoring system. In the case of the PSA study for the new diversified and digital protection function – called the diversified plant section of the Swedish NPP Ringhals 1 [Citation9] – the fault detection coverage is assumed to range between 80% and 90%. As can be seen above, the fault detection coverage in current PSA studies is largely assigned by rough estimations and engineering judgment by experts. Considering its importance in the PSA of digital I&C systems, fault detection coverage must be estimated as accurately as possible.
This study is intended to identify a set of important factors that affects the fault detection coverage of a digital I&C system. In Section 2, four system-related factors and four fault-related factors are identified based on experimental results published in the literature and the authors’ experience in fault injection experiments on digital I&C systems. In Section 3, a fault injection experiment is performed to examine the dependency of fault detection coverage on some of the four system-related factors and four fault-related factors. Section 4 discusses the implications of the experimental results on the estimation of fault detection coverage for the PSA of digital I&C systems and the possible essential role of the set of the four system-related factors and the fault-related factors in the development of a database for the fault detection coverage of digital I&C systems. Section 5 provides the conclusions of this study.
2. Factors affecting fault detection coverage
2.1. System-related factors
The fault detection coverage is affected by system-related factors such as (1) hardware, (2) software, (3) input/system state, and (4) fault detection algorithm.
The dependency of fault detection coverage on hardware is somewhat obvious, while the dependency on software is less straightforward. Many studies have been performed to quantitatively analyze how different software programs result in different fault detection coverage. For example, Rajabzadeh and Miremadi [Citation10] carried out a fault injection experiment with three different software applications: (1) a quick sort program, (2) a linked list program, and (3) a matrix manipulation program, and found that the error detection coverage of each software application is 79.74%, 84.56%, and 83.25%, respectively. This experimental result is, to some degree, consistent with the analysis by Madeira et al. [Citation11], in which the failure distributions vary considerably with each application, possibly due to differing application profiles.
The dependency of fault detection coverage on fault detection algorithms is also somewhat obvious and has been reported in many published studies. For example, Wu et al. [Citation12] performed a fault injection experiment with two different fault detection algorithms: control flow checking by software signatures (CFCSS) and improved CFCSS(ICFCSS). They determined that the average error detection coverage of CFCSS is 92.0%, while that of ICFCSS is 97.5%.
It is generally perceived that the fault detection coverage is unique for a digital system. However, it has been found that the fault detection coverage is even dependent on the input to the system. Experimental evidence on this dependency is given in Section 3.
2.2. Fault-related factors
It is rather obvious that different faults may have different effects on the target system. According to the authors’ experience in fault injection experiments on digital I&C systems, the following four fault-related factors have been identified: (1) fault type, (2) fault location, (3) fault occurrence time, and (4) fault duration. These four factors are in accordance with those factors identified by Constantinescu [Citation13–15] and Smith et al. [Citation16].
The dependency of fault detection coverage on fault duration has been reported in many published studies. Kanawati et al. [Citation17] found that errors due to faults that were active for more than a few instruction cycles were very likely to be detected by one of the error detection mechanisms. They also mentioned that their result is consistent with previous work on permanent faults by Banerjee et al. [Citation18], who reported that permanent faults were detected more efficiently than transient faults. Constantinescu [Citation15] also concluded that fault detection coverage is a function of fault duration; the shorter the transient fault, the lower the coverage.
3. Application to fault injection experiments
3.1. Experimental setup
shows information from the fault injection experiment with respect to the four system-related factors and four fault-related factors provided in Section 2.
Table 1. Information on the important factors in the fault injection experiment.
With the consideration that 32-bit central processing units (CPUs) are widely used in modern digital I&C systems in NPPs, a digital system with a 32-bit CPU is selected as the hardware. The experiment was performed on the same hardware, similar to digital I&C systems in NPPs that are developed on a common hardware platform, but implemented with different software programs.
Three different software programs– (1) quick sort, (2) matrix multiplication, and (3) bubble sort– were used to examine the dependency of fault detection coverage on software. The three software programs were selected because they have been used in many previous fault injection experiments, such as those by Rajabzadeh and Miremadi [Citation10], Nicolescu et al. [Citation19], and Venkatasubramanian et al. [Citation20]; therefore, the results of fault injection experiments can be compared with other experimental results. The use of three software programs is analogous to the use of different software programs in developing different digital I&C systems while using a common hardware platform.
Depending on the software programs, appropriate example input sets were selected and used. To examine the effect of different input sets to the system, six sets were provided to the quick sort program. The system was considered to be in the same state after initialization.
To examine the dependency of fault detection coverage on the fault-related factors, different fault locations and two different fault types were used in the fault injection experiment. For the fault location, faults were injected to all bits in the general-purpose registers of the 32-bit CPU. Considering the fact that general-purpose registers are continuously overwritten, it was speculated that the effect of permanent faults would be relatively more significant than that of transient faults. For this reason, we selected the two most widely known permanent fault types, the stuck-at-0 faults and the stuck-at-1 faults. For the fault occurrence time, it is assumed that a fault occurs after the initialization procedure. This is because in many process controllers, the initialization procedure is executed only once, while the main function is executed infinitely; therefore, it is more feasible to assume that a fault occurs while the main function is executed.
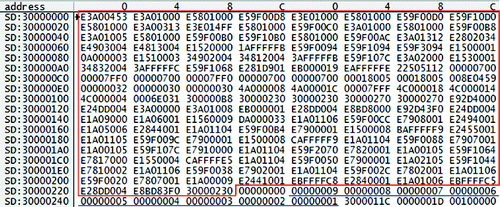
In analyzing the fault effects to a digital system, the binary code (instead of the high-level language code) needs to be clearly specified. The binary code for quick sort used in the fault injection experiment is shown in as an example. The table in the figure illustrates that the binary code is loaded in the memory address range from 0 × 30,000,000 to 0 × 30,000,228. It is also shown that the input data is stored in the memory address range from 0 × 30,000,230 to 0 × 30,000,250.
Figure 2. Binary code of the quick sort program used in the fault injection experiment.
It is assumed that a WDT is installed in the target system and that a heartbeat signal is generated on a regular time basis. Therefore, if the execution of the software programs cannot be finished within a specified time period, which is an indication that unintended software hang has occurred, the WDT might detect such situations. In other words, it is assumed that the WDT can detect unintended software hangs. The time interval for the watchdog timeout is set to be at least six times longer than the expected time interval for one execution of the software program.
3.2. Data acquisition
To gather the experimental data, we first executed the binary code without injecting any faults to obtain the fault-free calculation result. In the case of the quick sort program, the number set {9,8,7,6,5,4,3,2,1} was input into the target system; for this case, it was found that after the execution of 863 steps, the binary code arrived at 0 × 30,000,134, which is the last step of the program, and the calculation result became {1, 2, 3, 4, 5, 6, 7, 8, 9}. For this reason, we regarded 0 × 30,000,134 as the finishing point of the execution for the quick sort program. Similarly, the finishing points of the execution for other software programs were set.
Based on these data, we collected the number of steps executed until the binary code arrived at the finishing points of the software programs, and the calculation results after injecting a fault in the target system. If the number of steps to the finishing point exceeded 10,000, it was interpreted that the target system fell into unintended software hang, and consequently, the WDT would reset the target system.
shows an example of the data gathered when a stuck-at-0 fault is injected into the 0th bit of the R0 register of the CPU in the target system when the quick sort program is running. From , it can be found that when a stuck-at-0 fault is injected into the 0th bit of the R0 register, the calculation finishes after the execution of 1075 steps, instead of 863 steps. The calculation result was {0, 2, 2, 4, 4, 6, 6, 8, 0 × 3,000,011C}, which means that the calculation produced a wrong result. In a similar way, stuck-at-0 faults and stuck-at-1 faults were injected to all 32 bits of R0–R14 registers and the program counter register. The total number of fault injections was 1024 for each software program and each input set.
Table 2. Experimental result for a stuck-at-0 fault injected into the R0 register when quick sort is running.
3.3. Analysis of experimental results
After the injection of a fault into the target system, the effect of a fault was classified into one of three categories: (1) no effect, (2) software hang, and (3) wrong output. The number of faults belonging to each category is denoted as follows:
NNE : the number faults belonging to the ‘no effect’ category.
NSH : the number faults belonging to the ‘software hang’ category.
NWO : the number faults belonging to the ‘wrong output’ category.
Whether the faults that have no effect on the target system should be included in the estimation of fault detection coverage or not depends on how we define the scope of the faults considered in the analysis. In this analysis, it is decided that only the faults that had actual effect on the target system (those faults resulted in either software hangs or wrong outputs) were in the scope of the faults considered.
Because it is assumed that the WDT can detect unintended software hangs, the fault detection coverage, Cd, can be calculated as
(2)
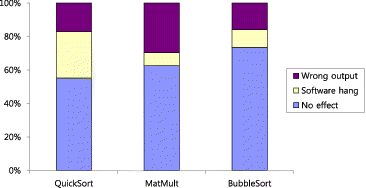
shows the experimental results for the three software programs. Under the assumption that a WDT is installed and able to detect software hangs, the portion of software hang in indicates the fault detection coverage of the target system. The experimental results give us the conclusion that the fault detection coverage is dependent on software programs. After eliminating the faults with no effect, the fault detection coverage of quick sort, matrix multiplication, and bubble sort are calculated as 62%, 21%, and 40%, respectively.
Figure 3. Effect of different software programs on experimental results.
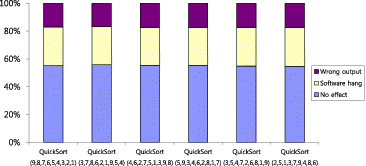
shows the experimental results for six different inputs when the quick sort program was running in the system. Significant differences cannot be found between the experimental results for the six input sets. More detailed analysis on the experimental results for the first two sets of inputs {9,8,7,6,5,4,3,2,1} and {3,7,8,6,2,1,9,5,4} showed that for only 16 cases out of 1024 (1.56%), the effect of the injected faults resulted in a different category. For example, when a stuck-at-1 fault is injected into R0 register, the first input set {9,8,7,6,5,4,3,2,1} resulted in the software hang, while the second input set {3,7,8,6,2,1,9,5,4} resulted in the wrong output. Comparison with other input sets also provided similar results. As far as this experimental result is concerned, the dependency of the fault detection coverage on the system input does exist, but does not seem to be as significant as other factors, such as the software program. Therefore, it is expected that the dependency of fault detection coverage on various input sets to a digital I&C system would not be very significant. However, further investigation would be necessary to make a concrete conclusion.
Figure 4. Effect of different input sets on experimental results while quick sort is running.
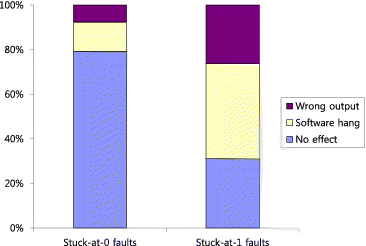
The 1024 experimental results for the quick sort program shown in were divided into stuck-at-0 faults and stuck-at-1 faults, and shows the effect of fault type to the experimental results while the quick sort program was running on the target system. Each fault type in shows the experimental results for 512 injected faults. It is observed that significantly more stuck-at-0 faults resulted in no effect compared to stuck-at-1 faults. The fault detection coverage for each of the stuck-at-0 faults and stuck-at-1 faults while the quick sort program was running is calculated to be 63% and 62%, respectively. Similar calculations were performed for the other two software programs; the percentages calculated from the experimental results were 32% and 19% for matrix multiplication, and 47% and 39% for bubble sort. The different fault detection coverage for the fault type indicates the existence of the dependency of fault detection coverage on the fault type.
Figure 5. Effect of fault type on experimental results while quick sort is running.
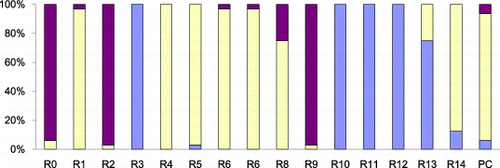
The 512 experimental results for each of the stuck-at-0 faults and stuck-at-1 faults shown in were divided, and and show the effect of fault location to the experimental results while the quick sort program was running on the target system. In , it can be observed that faults injected into different registers produce different results. For example, the 32 faults injected into the R0 register produced 21 no effect, one software hang, and 10 wrong results, while the 32 faults injected into the R1 register produced 26 no effect, three software hangs, and three wrong results. A similar result can also be found in . Due to the relatively small number of experimental results (only 32 cases for each register), the fault detection coverage for each of the registers was not calculated. However, it can be interpreted from the experimental results that fault detection coverage might vary depending on the fault location.
Figure 6. Effects of fault location when stuck-at-0 faults are injected while quick sort is running.
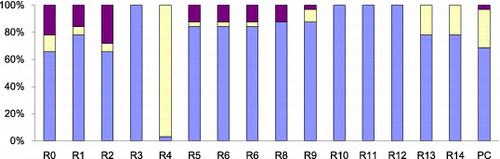
Figure 7. Effects of fault location when stuck-at-1 faults are injected while quick sort is running.
It is noteworthy that significant portions of injected faults did not have any effect on the target system. The injected faults that resulted in no effect include those injected into the unused area of the registers. Screening out such faults with no effect before fault injection experiments can significantly reduce the time and effort involved in fault injection experiments.
4. Discussions
4.1. Implications to digital I&C systems in NPPs
Because the fault detection coverage is dependent on system-related factors, the estimated fault detection coverage in Section 3 cannot be directly applied to digital I&C systems in NPPs. In fact, the intention of the fault injection experiment described in Section 3 was not to estimate the exact fault detection coverage of the target system, but to derive implications from the experimental results on the estimation of the fault detection coverage of digital I&C systems in NPPs.
The fact that the detection coverage is dependent on the fault detection algorithm is rather obvious. However, some explanation is necessary to elucidate that the fault detection coverage is dependent on other system-related factors, such as hardware, software, and input/state.
When the same function is implemented with two different digital I&C hardware platforms, it is generally expected for the fault detection coverage of different hardware platforms to be different, partly because of the different fault detection algorithms used in different hardware platforms. It would be interesting, but rather easily acceptable, that the fault detection coverage would be different even if the same fault detection algorithm was used in different hardware platforms.
From the experimental results, it is expected that various digital I&C systems in NPPs implemented on a common hardware platform with the same fault detection algorithms, but with different software programs, might have different fault detection coverage. In other words, it is highly likely that the RPS and the engineered safety features actuation system – even though they are implemented on the same hardware platform – might have different fault detection coverage. It is difficult to assign unique fault detection coverage on a specific hardware platform, because the fault detection coverage depends on the software running on the hardware platform. Therefore, the fault detection coverage specific to each digital I&C system should be estimated to be used in the PSA.
It is interesting that the fault detection coverage might be different when different input sets are provided to the same digital I&C system that consists of the same hardware, the same software, and the same fault detection algorithm. For example, the fault detection coverage of an RPS would be different depending on whether the plant is in the normal operation state, in an abnormal state, or in an emergency state, because different plant states provide different input sets to the RPS. This is because the control flow of the software in the system changes depending on the input set entered into the system. Fortunately, the experimental results in Section 3 indicate that this dependency does exist, but is relatively weak compared to other factors, such as software programs. Therefore, it is expected that when the fault detection coverage of a digital I&C system is estimated, the plant conditions under consideration (which eventually affect the input to the digital I&C system) do not need to be significantly considered. In other words, the fault detection coverage might not need to be estimated for specific plant conditions considered when developing PSA models.
Even though the same input is provided to the same digital I&C system, the fault detection coverage would be different depending on the state of the system. For example, the same input to an RPS might result in either a reactor trip or a reactor non-trip, depending on the system state. A series of input sets results in a specific system state, and the system outputs due to subsequent input sets are dependent on the system state, i.e., on the series of input sets previous to the specific input. The dependency of fault detection coverage on system state was not covered in the fault injection experiment described in Section 3, and is left as further studies.
After all, it is necessary to recognize that the fault detection coverage is not specific to a hardware platform, but dependent on many other system factors, such as software programs.
4.2. Application to a fault detection coverage database
As can be seen in the four system-related factors, fault detection coverage is basically a system-specific quantity, which means that a generic fault detection coverage is not feasible and that the system-specific fault detection coverage has to be estimated for each digital I&C system. A database for the fault detection coverage of digital I&C systems would be helpful for estimating the fault detection coverage of a specific digital I&C system when it is not known, and also for comparing the estimations of fault detection coverage from the results of fault injection experiments.
The above-discussed four system-related factors and four fault-related factors might play an essential role in the development of such a database, an example of which is shown in . For each fault injection experiment, fault detection coverage is given as a function of the four system-related factors and four fault-related factors. The factors are used to characterize fault injection experiments and the resultant fault detection coverage.
Table 3. Example database for fault detection coverage of digital I&C systems.
The effect of different factors on fault detection coverage can be observed in the database. For example, the results of the fault injection experiments described in Section 3 can be compared with the fault injection experiment with quick sort as the application software and WDT as the fault detection algorithm by Miremadi and Torin [Citation21]. It can be determined that the six remaining factors, with the exception of the application software and the fault detection algorithm, are different in the two cases. The differences seem to contribute to the difference in the fault detection coverage. It is also shown in that enhanced fault detection coverage resulted when block entry exit checking (BEEC) and error capturing instruction (ECI) mechanisms were combined with WDT. Nicolescu et al. [Citation19] claimed that their software-implemented error detection mechanism could detect all the transient faults in the system in the fault injection experiment with quick sort as the application software. As the database becomes larger, the effect of each factor on fault detection coverage can become clearer.
In summary, the set of four system-related factors and four fault-related factors provides a framework for systematically comparing and analyzing various fault injection experiments and the resultant estimations on the fault detection coverage of digital I&C systems.
5. Conclusion
In this paper, a set of four system-related factors and four fault-related factors were proposed as important factors that affect the fault detection coverage of digital I&C systems in NPPs based on the experimental results found in the literature and the authors’ experience in fault injection experiments on digital I&C systems. The four system-related factors are (1) hardware, (2) software, (3) input/system state, and (4) fault detection algorithm, while the four fault-related factors are (1) fault type, (2) fault location, (3) fault occurrence time, and (4) fault duration.
A fault injection experiment on a digital system with a 32-bit CPU was performed to demonstrate the dependency of the fault detection coverage on some of the four system-related factors and the fault-related factors. The experimental results show that there exists a significant dependency of the fault detection coverage on the software. The dependency of fault detection coverage on the input is found to exist, but to be less significant compared to other factors, such as software. The experimental results also demonstrated the dependency of fault detection coverage on some of the fault-related factors, such as fault location and fault type.
The implications of the experimental results on the fault detection coverage of digital I&C systems in NPPs are also important. In NPPs, many digital I&C systems are developed on a common hardware platform with different software programs. From the dependency of fault detection coverage on software, it is recommended that the fault detection coverage specific to each digital I&C system in NPPs needs to be estimated in order to be used in the PSA of the NPPs. Because of relatively weak dependency of fault detection coverage on the input, it might not be necessary to estimate the fault detection coverage specific to each of the plant conditions considered in the PSA.
A database on the fault detection coverage of various digital I&C systems might be helpful in estimating the fault detection coverage of a newly developed digital I&C system. The four system-related factors and four fault-related factors can provide a framework for systematically comparing and analyzing various fault injection experiments, and thus play an essential role in the development of such a database.
Currently, it cannot be guaranteed that the set of four system-related factors and four fault-related factors is comprehensive. It is necessary to continuously update the set of factors as the understanding on fault detection coverage is widened. The set of four system-related factors and four fault-related factors is expected to serve as the starting point for continued research efforts on the estimation of fault detection coverage of digital I&C systems to be used in the PSA.
Additional information
Funding
References
- Chapin DM, Dugan JB, Brand DA, Curtiss JR, Damon DL, DeWalt M, Gannon JD, Goble RL, Hill DJ, Katz PE, Leveson NG, Mitchell CM, Rodriguez C, White JD. Digital instrumentation and control systems in nuclear power plants. Washington (DC): National Academy Press; 1997.
- Lu L, Jiang J. Probabilistic safety assessment for instrumentation and control systems in nuclear power plants: an overview. J Nucl Sci Technol. 2004;41:323–330.
- Kang HG, Kim MC, Lee SJ, Lee HJ, Eom HS, Choi JG, Jang S-C. An overview of risk quantification issues for digitalized nuclear power plants using a static fault tree. Nucl Eng Technol. 2009;41(6):849–858.
- Authen S, Holmberg J-E. Reliability analysis of digital systems in a probabilistic risk analysis for nuclear power plants. Nucl Eng Technol. 2012;44(5):471–482.
- Kaufman LM, Johnson BW. Embedded digital system reliability and safety analyses, NUREG/GR-0020. Washington (DC): United States Nuclear Regulatory Commission; 1994.
- United States Nuclear Regulatory Commission. Final safety evaluation report related to the certification of the advanced boiling water reactor design. Washington (DC): United States Nuclear Regulatory Commission; 1994.
- AP1000 Probabilistic Risk Assessment. Revision 8, July 2004 ( Revision 0 sent to NRC March 2002).
- Kang HG, Sung T. An analysis of safety-critical digital systems for risk-informed design. Reliab Eng Syst Saf. 2002;78:307–314.
- Authen S, Wallgren E, Eriksson S. Development of the Ringhals 1 PSA with regard to the implementation of a digital reactor protection system. Proceedings of the 10th International Probabilistic Safety Assessment & Management Conference (PSAM 10); 2010 June 7–11; Seattle, Washington (DC), Paper 213.
- Rajabzadeh A. Miremadi SG. CFCET: A hardware-based control flow checking technique in COTS processors using execution tracing. Microelectron Reliab. 2006;46:959–972.
- Madeira H, Some RR, Moreira F, Costa D, Rennels D. Experimental evaluation of a COTS system for space applications. Proceedings of the IEEE/IFIP International Conference on Dependable Systems and Networks (DSN’02); 2002 Jun 23–26; p. 325–330; Bethesda, MD.
- Wu Y-X, Gu G-C, Wang K-H. An improved CFCSS control flow checking algorithm. IEEE International Workshop on Anti-counterfeiting, Security, Identification; 2007 Apr 16–18; p.284–287; Xiamen, Fujian.
- Constantinescu C. Estimation of coverage probabilities for dependability validation of fault-tolerant computing systems. Proceedings of the Ninth Annual Conference on Computer Assurance; 1994 Jun 27–Jul 1; p.101–106; Gaithersburg, MD.
- Constantinescu C. Using multi-stage & stratified sampling for inferring fault coverage probabilities. IEEE Trans Reliab. 1995;44:632–639.
- Constantinescu C. Experimental evaluation of error-detection mechanisms. IEEE Trans Reliab. 2003;52:53–57.
- Smith DT, Johnson BW, Profeta III JA, Bozzolo DG. A method to determine equivalent fault classes for permanent and transient faults. Proceedings of the Annual Reliability and Maintainability Symposium; 1995 Jan 16–19; p.418–424; Washington, DC.
- Kanawati GA, Nair VSS, Krishnamurthy N, Abraham JA. Evaluation of integrated system-level checks for on-line error detection. Proceedings of the Second International Computer Performance and Dependability Symposium (IPDS’96); 1996 Sep 4–6; p.292; Urbana-Champaign, IL.
- Banerjee P, Rahmeh JT, Stunkel C, Nair VS, Roy K, Balasubramanian V, Abraham JA. Algorithm-based fault tolerance on a hypercube multiprocessor. IEEE Trans Comput. 1990;39:1132–1145.
- Nicolescu B, Savaria Y, Velazco R. Software detection mechanisms providing full coverage against single bit-flip faults. IEEE Trans Nucl Sci. 2004;51:3510–3518.
- Venkatasubramanian R, Hayes JP, Murray BT. Low-cost on-line fault detection using control flow assertions. Proceedings of the Ninth IEEE International On-Line Testing Symposium (IOLTS’03); 2003 Jul 7–9; p.137–143; Kos Island, Greece.
- Miremadi G, Torin J. Evaluating processor-behavior and three error-detection mechanisms using physical fault-injection. IEEE Trans Reliab. 1995;44:441–454.