
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
By introducing a new assumption of linear estimation, we derive a new formulation of the extended cross-section adjustment (EA) method, which minimizes the variance of the design target core parameters. The new formulation is derived on the basis of minimum variance unbiased estimation with no use of the assumption of normal distribution. In this formulation, we found that EA has infinitely many solutions as the adjusted cross-section set. The new formulation of EA can represent all the possible solutions minimizing the variance of the design target core parameters and includes a special case identical to the classical Bayesian EA method, which was derived on the basis of the Bayes theorem under the assumption of normal distribution. Moreover, we prove that the special case minimizes not only the variance of the design target core parameters but also the variance of the nuclear data. Meanwhile, we show that the new assumption of linear estimation is consistent with the Kalman filter and demonstrate that we can formulate similarly the extended bias factor method, the conventional cross-section adjustment method, and the regressive cross-section adjustment method with no use of the assumption of normal distribution.
1. Introduction
As a neutronics design method for an innovative nuclear reactor system, the original cross-section adjustment methodology was established in 1970s–1980s [Citation1–Citation4]. With regard to the cross-section adjustment methodology, a comprehensive and detailed comparison study has been reported in references [Citation5,Citation6]. This methodology enables us to improve the prediction accuracy of neutronic characteristics by reducing uncertainties in nuclear data. In the cross-section adjustment methodology, the nuclear data are modified with the use of integral experimental quantities, such as measurement data acquired in critical experiments; the modified nuclear data are provided as an adjusted cross-section set for predicting the design target core parameters.
On the other hand, a formulation of the extended bias factor (EB) method [Citation7] was proposed in 2007 as an alternative methodology for improving the prediction accuracy of the design target core parameters by using integral experimental quantities. In EB, a bias factor is obtained by a semifictitious experimental value, which is defined by a linear combination of integral experimental quantities; the design prediction value is corrected by the bias factor.
Subsequently, a formulation of the extended cross-section adjustment (EA) method [Citation8] was proposed in 2012; EA can generate an adjusted cross-section set that reproduces the design prediction values and accuracies equivalent to EB. This formulation has revealed that EB minimizes the variance of the design prediction value of the target core parameter by considering cross-correlations in the analysis method error between the integral experimental quantities and the design target core parameters. Hence, in the case that there are strong cross-correlations in the analysis method error, EB can improve the design prediction accuracy more than the original cross-section adjustment methodology. Thus, the advantage of EB has been integrated into the cross-section adjustment methodology. In addition, the formulation of EA has revealed a difference between EA and EB. That is, the assumption of normal distribution required in the derivation of EA is not used in the derivation of EB. To explain this difference, the cross-section adjustment methods based on minimum variance unbiased estimation (MVUE) [Citation9] were proposed in 2016. In reference [Citation9], it has been shown that the MVUE-based rigorous extended cross-section adjustment (MREA) method, which was derived with no use of the assumption of normal distribution, can yield the design prediction values and accuracies equivalent to EB. Thus, it has been confirmed that the design prediction values and accuracies by EA are consistent with those by EB.
Moreover, the derivation of the MVUE-based cross-section adjustment methods [Citation9] has clarified that the original cross-section adjustment methodology minimizes the variance of the nuclear data. This finding led to a formulation of the regressive cross-section adjustment (RA) method [Citation9], which minimizes the variance of the integral experimental quantities. Although RA is unpractical as a neutronics design method, the formulation of RA is useful when we discuss what is optimized, that is, which variance is minimized, in the cross-section adjustment methodology. Thus, there are three variations of the cross-section adjustment methodology depending on the optimization target. In the present paper, we refer to the original cross-section adjustment methodology that minimizes the variance of the nuclear data as the conventional cross-section adjustment (CA) method. In particular, the original CA that was derived on the basis of the Bayes theorem under the assumption of normal distribution is called the classical Bayesian conventional cross-section adjustment (CBCA) method.
At that point in time, there was an unclear difference in the adjusted cross-section set with regard to CA. That is, the adjusted cross-section set by the MVUE-based rigorous conventional cross-section adjustment (MRCA) method [Citation9], which was derived with no use of the assumption of normal distribution, differs from that by CBCA. In reference [Citation9], it has been explained that a hypothetical mathematical operation, called ‘projection simplification,’ permits us to derive the MVUE-based simplified conventional cross-section adjustment (MSCA) method that can yield the adjusted cross-section set equivalent to CBCA. This explanation, however, is insufficient from the mathematical point of view. To explain this inconsistency in the adjusted cross-section sets between MRCA and CBCA, the dimension-reduced conventional cross-section adjustment (DRCA) method [Citation10] was proposed in 2018. The derivation of DRCA has revealed that the formulation for the adjusted cross-section set equivalent to CBCA can be derived with no use of the assumption of normal distribution by introducing a concept of dimensionality reduction. Thus, the difference in the adjusted cross-section set has been explained mathematically with regard to CA.
As for EA, however, there remains a similar problem in the adjusted cross-section set. That is, the adjusted cross-section set by the MREA method [Citation9], which was derived with no use of the assumption of normal distribution, differs from that by the classical Bayesian extended cross-section adjustment (CBEA) method [Citation8], which was derived on the basis of the Bayes theorem under the assumption of normal distribution. Similarly to MSCA, the MVUE-based simplified extended cross-section adjustment (MSEA) method, which was derived by using the projection simplification, was proposed in reference [Citation9] to explain the difference, but this explanation is also insufficient. Thus, it has not been clearly explained yet why this difference in the adjusted cross-section set is occurred with regard to EA.
In the present paper, with no use of the assumption of normal distribution, we derive a new formulation that can yield the adjusted cross-section set equivalent to CBEA. To derive the new formulation of EA, we focus attention on a fact that the formulation of the Kalman filter [Citation11,Citation12] can be derived with no use of the assumption of normal distribution. For this reason, we make a review on the derivation of the Kalman filter to clarify the relationship with the cross-section adjustment methodology. In accordance with this review, we introduce a new assumption of linear estimation into the derivation of the cross-section adjustment methods based on the MVUE. In the present paper, we refer to this derivation procedure based on MVUE with the use of the new assumption as minimum variance unbiased linear estimation (MVULE).
First, we derive the formulation of CA based on MVULE, namely, the MVULE-based conventional cross-section adjustment (MLCA) method. Next, we demonstrate that the formulation of EB can be also derived by the same procedure. That is, we formulate the MVULE-based extended bias factor (MLEB) method. Finally, we derive the formulation of the MVULE-based extended cross-section adjustment (MLEA) method and the MVULE-based regressive cross-section adjustment (MLRA) method.
In Section 2, we review the cross-section adjustment methods, the extended bias factor method, and the Kalman filter. In Section 3, the derivations of MLCA, MLEB, MLEA, and MLRA are described. In Section 4, we discuss the derived formulation and conclude in Section 5. The acronyms are described in the Abbreviations section at the end of this article.
2. Review
2.1. Review of cross-section adjustment method
2.1.1. Precondition
To review the formulation for the cross-section adjustment methodology, we first define the following numbers of data used in the methodology:
na: the number of nuclear data to be adjusted;
n(1): the number of integral experimental quantities used for adjustment; and
n(2): the number of the design target core parameters to be considered in adjustment of EA.
In accordance with reference [Citation9], MRCA is equivalent to CBCA under the condition of the overdetermined (well-posed) problem, where (cf. Section 4.1.2 in reference [Citation9]). For this reason, we review the formulation under the condition of the underdetermined (ill-posed) problem, where
. With regard to EAs – including MREA, MSEA, and CBEA, a precondition that
is adopted. As for DRCA, we focus on the special case equivalent to CBCA, namely, DRCA2 [Citation10].
2.1.2. Unified formula
The adjusted cross-section set by the foregoing methods can be expressed in the unified form [Citation9]:
where
and
Here, we have defined as follows:
: the unadjusted cross-section set;
where means that
is an
real matrix. In addition, the superscript of ‘
’ denotes the Moore–Penrose pseudoinverse, and the superscript of ‘
’ represents the matrix transpose. Note that
is the full variance–covariance matrix of the integral experimental quantities and is supposed to be invertible (i.e. nonsingular) since the inverse of
appears in EquationEquation (1)
(1)
(1) . Moreover, it is assumed that
and
have full rank. Then, recalling the precondition that
, we have
where denotes the identity matrix.
In accordance with the formulation of the MVUE-based cross-section adjustment methods (cf. EquationEquations (103)(103)
(103) , Equation(113)
(113)
(113) , and (112) in reference [Citation9]), we can also write the variance-covariance matrix of the adjusted cross-section set, the variance of the calculation values of the integral experimental quantities reanalyzed using the adjusted cross-section set, and the variance of the prediction values of the design target core parameters in the unified forms:
and
respectively, where
and
Here, we have defined as follows:
2.1.3. Detailed definition
In addition, let us define the following symbols:
Then, some symbols can be redefined by
and
Similarly, we can redefine the variance–covariance and cross-correlation matrices by
and
Here, we have defined and
for column vectors
and
by
and
respectively, where denotes the expectation value. Note that when
in EquationEquation (18)
(18)
(18) ,
is reduced to
by definition. Moreover, all of the following variance-covariance matrices are symmetric:
and
On the other hand, a variance–covariance matrix is always nonnegative definite. That is, a variance-covariance matrix is either positive definite or positive semidefinite. Hence, ,
, and
are nonnegative definite. Moreover,
,
, and
are symmetric and nonnegative definite in accordance with the following theorems:
For an
For
For an
For an
2.2. Review of extended bias factor method
Given that the design prediction values by CBEA are equal to those by EB [Citation8], the design prediction values by EB can be defined by
This definition can be obtained by assuming linearity as it is done in EquationEquation (75)(75)
(75) , which is described later, and substituting EquationEquations (1)
(1)
(1) and (Equation2
(2)
(2) ) as follows:
where EquationEquation (5)(5)
(5) is used.
2.3. Review of Kalman filter
Next, we review a derivation of the Kalman filter [Citation14] and examine the relationship with the cross-section adjustment methodology.
2.3.1. Non-linear Kalman filter and its linearization
Let us consider the following equations as a nonlinear discrete-time state model for time series data:
where
It is assumed that an approximate can be determined by some means. When the difference between the actual and the approximate state vectors is defined by
, the actual state vector is written by
To linearize the equations of the discrete-time state model, let us approximate the state transition function and the observation function by the Taylor series expansion around :
and
where the higher-order terms are ignored. Thus, EquationEquation (26)(26)
(26) can be written by
where
Meanwhile, when we need an approximation of the state vector at the next time step, we can adopt a transition of the approximate state vector at the previous time step. That is, can be determined such that
. Thus, EquationEquation (31)
(31)
(31) can be rewritten as
On the other hand, EquationEquation (27)(27)
(27) can be expressed by
where
To simplify the linearized model described by EquationEquations (33)(33)
(33) and (Equation34
(34)
(34) ), we replace the state vector and the observation vector by
and
respectively. Thus, the equations of the discrete-time state model can be rewritten as
This formulation is known as the linear Kalman filter.
2.3.2. Linear Kalman filter
Next, we review the state model equations of the linear Kalman filter. The covariance matrices of the system noise and the observation noise are defined by
and
where denotes the zero matrix. Let us denote the prior estimate by
, which is the state vector estimated from the information prior to time
, where the hat
represents an estimate, and the subscript of ‘
’ means an estimate prior to assimilating the measurement at time
.
Let us assume that the covariance matrix of the prior estimate is known. That is, the estimation error is defined explicitly by
then the covariance matrix of the prior estimate can be written by
Next, let us consider improving the prior estimate by using the measurement at time . For this purpose, a linear blending of the measurement
and the prior estimate
is adopted in the form:
where
: the updated estimate of the state vector and
: the linear blending factor.
Meanwhile, the covariance matrix of the updated estimate is expressed by
Substituting EquationEquation (39)(39)
(39) into EquationEquation (45)
(45)
(45) yields
Thus, substituting EquationEquation (47)(47)
(47) in EquationEquation (46)
(46)
(46) and considering that there is no correlation between
and
, we obtain
To derive this equation, we have used that the following equation holds for arbitrary matrices and
:
To determine the blending factor that minimizes the trace of the covariance matrix of the updated estimate, we consider the partial derivative:
where denotes the matrix trace, which is the sum of the diagonal elements. To derive EquationEquation (50)
(50)
(50) , we have used the following equations for arbitrary matrices
and
:
and
Moreover, we have used the following derivative formulas for arbitrary constant matrices ,
,
:
and
To determine the blending factor that minimizes the trace of , we set EquationEquation (50)
(50)
(50) equal to zero and solve for
. The result is
This equation is called the Kalman gain. Substituting this equation into EquationEquation (45)(45)
(45) , we obtain
This equation enables us to estimate the state vector at time .
2.3.3. Relationship with cross-section adjustment method
As defined by EquationEquations (1)(1)
(1) – (Equation3
(3)
(3) ), the adjusted cross-section set by CBCA is written by
Although this equation is similar to EquationEquation (57)(57)
(57) , it differs from EquationEquation (57)
(57)
(57) in that it deals with the nonlinearity of
. To eliminate this difference, let us consider the following correspondence in light of the derivation procedure for linearizing the Kalman filter:
and
Thus, we can understand that EquationEquation (58)(58)
(58) is identical to EquationEquation (57)
(57)
(57) .
Moreover, in light of EquationEquation (64)(64)
(64) , we can find another correspondence:
From this correspondence, we can understand that the cross-section adjustment method is a linearized model of the nonlinear Kalman filter described by the state model equations:
where represents the cross-section set at time
. Although EquationEquation (66)
(66)
(66) is inessential for the cross-section adjustment methodology, the state model described by EquationEquation (67)
(67)
(67) is reasonable as the observation of C/E (calculation/experiment) values for the integral experimental quantities. On the other hand, since the linearization of the nonlinear Kalman filter is known as the extended Kalman filter (EKF), we can understand that the cross-section adjustment methodology is a kind of EKF.
2.4. Discussion on assumption of linear estimation
As described before, the Kalman gain is determined by minimizing the variance with no use of the assumption of normal distribution. This procedure is similar to determining the linear combination factor in the derivation of the MVUE-based cross-section adjustment methods. Hence, we can find yet another correspondence:
Substituting the foregoing correspondence, that is, EquationEquations (59)(59)
(59) – (Equation61
(61)
(61) ), and (Equation68
(68)
(68) ), into EquationEquation (45)
(45)
(45) , we obtain
This equation differs from the following equation that represents the assumption of linear estimation used in the derivation of the MVUE-based cross-section adjustment methods [Citation9]:
In light of the review of the Kalman filter, it is expected that we can formulate a new cross-section adjustment method if we adopt EquationEquation (69)(69)
(69) as the assumption of linear estimation.
On the other hand, we can use another equation as the assumption of linear estimation. That is, if we consider the design target core parameters as the state vector, the assumption of linear estimation can be written by
Since this equation estimates directly the design target core parameters, it is expected that a new formulation corresponding to EB can be derived if EquationEquation (71)(71)
(71) is used as the assumption of linear estimation.
In the following, we derive MLCA with the use of EquationEquation (69)(69)
(69) as the assumption of linear estimation. Subsequently, MLEB is derived by using EquationEquation (71)
(71)
(71) . Finally, we derive MLEA and MLRA with EquationEquation (69)
(69)
(69) .
3. Derivation
3.1. Assumptions
In the present paper, we adopt the same assumptions used in the derivation of the MVUE-based cross-section adjustment methods [Citation9] except for the assumption of linear estimation. However, since these assumptions are essential for the formulation, we summarize them in the following.
3.1.1. Assumptions on number of data
Unlike the foregoing review of the cross-section adjustment methods, we employ no particular assumption (precondition) regarding the relationship between the number of integral experimental quantities and the number of nuclear data:
That is, it is unnecessary to distinguish whether the problem is overdetermined or underdetermined in the present formulation. With regard to EA, it is assumed that the number of design target core parameters is smaller than the number of nuclear data:
In addition, we assume that has full rank:
Note that is a wide matrix and has full row rank in light of EquationEquations (73)
(73)
(73) and (Equation74
(74)
(74) ). By contrast, at this moment, we pay no attention to whether
is of full rank.
3.1.2. Assumption of linearity
Let us assume that the variation of two calculation values obtained by different cross-section sets and
can be evaluated by the first-order approximation in the form:
Then, the difference between the experimental value and the calculation value of integral experimental quantities can be expressed by
where EquationEquations(13)
(13) (Equation12
(12)
(12) )–(Equation14
(14)
(14) ) are used.
3.1.3. Assumption of unbiased estimation
Let us assume that the unbiased estimation is valid all for the nuclear data included in the unadjusted cross-section set, the experimental value and the calculation value of the integral experimental quantities, and the calculation value of the design target core parameters. That is, we assume that the expectation value is equal to the true value:
and
Then, in light of EquationEquations (19)(19)
(19) and (Equation20
(20)
(20) ), the foregoing covariance and cross-correlation matrices can be rewritten as
and
3.1.4. Assumption of error independence
Moreover, we assume that the experimental error, the analysis method error, and the cross-section-induced errors with respect to the integral experimental quantities and the design target core parameters are independent of each other:
where
3.2. Derivation of conventional cross-section adjustment method
Let us derive MLCA by using EquationEquation (69)(69)
(69) as the assumption of linear estimation.
3.2.1. Derivation of adjusted cross-section set
In light of EquationEquation (12)(12)
(12) , the estimate of the cross-section set can be written by
Substituting EquationEquations (69)(69)
(69) and (Equation76
(76)
(76) ) in EquationEquation (86)
(86)
(86) , we have
Thus, the variance of can be expressed by
where EquationEquations(84)
(84) (Equation84
(84)
(84) ), (Equation80
(80)
(80) ), (Equation81
(81)
(81) ), (Equation82
(82)
(82) ) and (Equation4
(4)
(4) ) are used. To determine the linear combination factor
that minimizes the variance, let us consider the partial derivative of the trace of this variance with respect to
:
where EquationEquations (51)(51)
(51) –(Equation55
(55)
(55) ) are used. It is possible to determine the linear combination factor matrix
that minimizes the variance by setting EquationEquation (89)
(89)
(89) equal to zero. Let
denote the minimizing factor of
, then we have
Premultiplying both sides of this equation by the inverse of defined by EquationEquation (3)
(3)
(3) , we obtain
Substituting into
in EquationEquation (69)
(69)
(69) and defining
in this case as
, we have
This equation is identical to that for the adjusted cross-section set by CBCA:
In summary, if EquationEquation (69)(69)
(69) is valid as the assumption of linear estimation, we can derive the formula identical to CBCA by using neither the projection simplification nor the concept of dimensionality reduction.
3.2.2. Derivation of variances
Given that EquationEquations (6)(6)
(6) –(Equation8
(8)
(8) ) can be derived with no use of the assumption of linear estimation (cf. Sections 4.2–4.4 in reference [Citation9]), we can adopt these equations also in MLCA. Thus, we can understand that the prediction accuracies by MLCA are also equivalent to CBCA.
3.3. Derivation of extended bias factor method
Next, let us derive MLEB by using EquationEquation (71)(71)
(71) as the assumption of linear estimation.
3.3.1. Derivation of estimate of design target core parameters
The calculation values of the design target core parameters obtained using the unadjusted cross-section set can be written by
where EquationEquations (75)(75)
(75) , (Equation14
(14)
(14) ), and (Equation12
(12)
(12) ) are used. Substituting EquationEquations (94)
(94)
(94) and (Equation76
(76)
(76) ) in EquationEquation (71)
(71)
(71) , we have
Thus, the variance of can be written by
where EquationEquationEquations (84)(84)
(84) , Equation(80)
(80)
(80)
(80)
(80) –(Equation83
(83)
(83) ), and (4) are used. To determine
that minimizes the variance, let us consider the partial derivative:
where EquationEquations (51)(51)
(51) –Equation(55)
(54)
(54) are used. We can determine the linear combination factor matrix that minimizes the variance by setting EquationEquation (97)
(97)
(97) equal to zero. Let
denote the minimizing factor, then we have
Premultiplying both sides of this equation by yields
Substituting of this equation into
of EquationEquation (71)
(71)
(71) and defining
in this case by
, we have
3.3.2. Comparison with original extended bias factor method
From a comparison between EquationEquations (100)(100)
(100) and (Equation24
(24)
(24) ), we obtain
Thus, we can interpret that EB is a kind of the linear Kalman filter in which the design target core parameters are estimated directly as the state vector.
3.4. Derivation of extended cross-section adjustment method
Finally, let us derive MLEA by using EquationEquation (69)(69)
(69) as the assumption of linear estimation.
3.4.1. Minimization of variance of design target core parameters
Similarly to EquationEquation (94)(94)
(94) , the calculation values of the design target core parameters obtained using the estimated cross-section set can be written by
Substituting EquationEquations (69)(69)
(69) and (Equation76
(76)
(76) ) in EquationEquation (102)
(102)
(102) , we have
Thus, the variance of can be written by
where EquationEquations (84)(84)
(84) , (Equation80
(80)
(80) )– (Equation83
(83)
(83) ), and (Equation4
(4)
(4) ) are used. To determine
that minimizes the variance, let us consider the partial derivative:
where EquationEquations (51)(51)
(51) Equation–(55)
(55)
(55) are used. By setting EquationEquation (105)
(105)
(105) equal to zero, we can determine the linear combination factor matrix that minimizes the variance. Let
denote the minimizing factor, then we have
Premultiplying both sides of this equation by yields
Note that is a singular matrix in light of EquationEquation (73)
(73)
(73) . Therefore, EquationEquation (107)
(107)
(107) has infinitely many solutions of
. In other words, we cannot determine uniquely the adjusted cross-section set for MLEA. Although a minimum norm solution was adopted in the derivation of MREA and MSEA to determine a unique solution by using the Moore–Penrose pseudoinverse (cf. EquationEquation (64)
(64)
(64) in reference [Citation9]), this treatment remains open to discussion. In the present derivation, we treat explicitly these numerous solutions.
3.4.2. Derivation of numerous solutions of adjusted cross-section set
To express the solutions for EquationEquation (107)(107)
(107) , we introduce a generalized inverse for a singular matrix, which includes a rectangular matrix. Note that the generalized inverse of a matrix is not unique. The Moore–Penrose pseudoinverse is a special case of the generalized inverse, and is determined uniquely. By definition, for the generalized inverse of an arbitrary matrix
, we have
where the superscript of ‘’ denotes the generalized inverse. Furthermore, the generalized inverse of a matrix of full row rank is a right inverse, even if it is not the Moore–Penrose pseudoinverse (e.g. Lemma 9.2.8 in reference [Citation13]). That is, for a matrix of full row rank
, we always have
In light of EquationEquations (73)(73)
(73) and (Equation74
(74)
(74) ),
has full row rank. Hence,
is the right inverse of
:
Thus, EquationEquation (107)(107)
(107) can be rewritten as
where is a generalized inverse of
. To indicate that
is a particular one of the numerous generalized inverses of
, we have defined the new symbol of
.
To simplify EquationEquation (111)(111)
(111) , let us define
then EquationEquation (111)(111)
(111) can be rewritten as
Premultiplying both sides of this equation by , we obtain
where EquationEquation (49)(49)
(49) is used. In general, for an arbitrary matrix
, we have
if and only if
(e.g. Corollary 5.3.2 in reference [Citation13]). Hence, EquationEquation (114)
(114)
(114) means that EquationEquation (111)
(111)
(111) is equivalent to the equation:
Meanwhile, all the solutions for can be expressed by
, where
is an arbitrary particular solution for
and
is all the solutions for
(e.g. Theorem 11.2.3 in reference [Citation13]). Moreover, all the solutions for
can be expressed by
, where
is an arbitrary matrix (e.g. Theorem 11.2.1 in reference [Citation13]).
Let us adopt as a particular solution of
for EquationEquation (115)
(115)
(115) , then we obtain the following expression as the all possible solutions for EquationEquation (115)
(115)
(115) :
where the superscript of ‘’ indicates that there are numerous solutions;
is a generalized inverse of
; and
is an arbitrary matrix. Note that the generalized inverse
may differ from the previously defined
. Hence, we have defined the new symbol of
.
Substituting EquationEquation (116)(116)
(116) in EquationEquation (69)
(69)
(69) , we obtain the following equation that represents all the solutions of the adjusted cross-section set in MLEA:
3.4.3. Derivation of variances
Similarly to MLCA, since EquationEquations (6)(6)
(6) – (Equation8
(8)
(8) ) can be derived with no use of the assumption of linear estimation (cf. Sections 4.2–4.4 in reference [Citation9]), we can adopt these equations in MLEA:
and
where
We can use these equations in the application of MLEA to nuclear reactor design. For instance, we can evaluate the variances (i.e. accuracies) of the design target core parameters by using EquationEquation (120)(120)
(120) .
3.5. Derivation of regressive cross-section adjustment method
Although it is known that RA is unpractical as the neutronics design method, we derive MLRA since it is meaningful for understanding the difference of the optimization target in comparison with CA and EA. By following the derivation procedure similar to MLEA, we can derive the formulation of MLRA while taking into account the difference of the optimization target. That is, by replacing the superscript of ‘’ in the derivation of MLEA with the superscript of ‘
’, we can obtain the formula for the adjusted cross-section set in MLRA:
where
and and
are particular ones of the generalized inverses of
. Similarly to MLEA, the following assumptions are required additionally to derive MLRA:
and
Meanwhile, to derive EquationEquation (122)(122)
(122) , we have used that
holds in light of EquationEquations (82)
(82)
(82) and (Equation83
(83)
(83) ).
3.6. Summary of derived results by unified formula
In accordance with EquationEquations (1)(1)
(1) and (Equation2
(2)
(2) ),
for MLCA can be defined by
and for MLEA and MLRA can be defined by
where
: an arbitrary matrix; and
: particular ones of the generalized inverses of
– it is allowed to determine
and
independently.
4. Discussion
4.1. Consistency of MLEA with EB
Let us confirm that MLEA reproduces the design prediction values by EB. Since the design prediction values are obtained using the adjusted cross-section set, we can confirm that the prediction values by MLEA are equal to EquationEquation (24)(24)
(24) :
where EquationEquations (75)(75)
(75) , (Equation1
(1)
(1) ), (Equation127
(127)
(127) ), (Equation112
(112)
(112) ), and (Equation108
(108)
(108) ) are used.
4.2. Quasi-solutions of CA and compensation effect
As an analogy from the foregoing discussion, we can deduce that all the adjusted cross-section sets defined by the following equation can reproduce the calculation values of the integral experimental quantities of CBCA:
That is, for all the adjusted cross-section sets expressed by this equation, we have
where EquationEquations (75)(75)
(75) , (Equation129
(129)
(129) ), (Equation108
(108)
(108) ), (Equation1
(1)
(1) ), and (Equation2
(2)
(2) ) are used. Note that, however, these adjusted cross-section sets are not always the optimal solution that minimizes the variance of the nuclear data.
Thus, we can understand that there are infinitely many solutions of the adjusted cross-section set for solely reproducing the calculation values of the integral experimental quantities. This fact is known as a ‘compensation effect’ [Citation15] in the use of integral experimental benchmarks in nuclear data evaluations.
4.3. Practical solution of MLEA
With regard to MLEA, we have obtained the mathematical formulation representing all the solutions of the adjusted cross-section set that minimize the variance of the design target core parameters. Next, let us consider which solution should be employed in practice. To determine uniquely the solution, we introduce an additional constraint condition. From a practical point of view, we adopt the constraint condition of minimizing the variance of the nuclear data.
4.3.1. Conjecture
Let us make a conjecture that the variance of the adjusted cross-section set in MLEA (cf. EquationEquation (127)(127)
(127) ) is minimized when we adopt the case where
(n.b. the term of
vanishes) and
.
Hence, we make the following definitions:
and
Note that is identical to
for CBEA:
In the following, we prove that the trace of has the minimum value among the traces of
:
4.3.2. Proof
The trace of EquationEquation (6)(6)
(6) , which represents the covariance matrix of the adjusted cross-section set, can be expressed by
where EquationEquations (51)(51)
(51) and (Equation52
(52)
(52) ) are used. Thus, the difference between the left-hand side and the right-hand side of EquationEquation (135)
(135)
(135) can be written by
To simplify this equation, let us define
then defined by EquationEquation (127)
(127)
(127) can be rewritten as
Note that is an idempotent matrix:
In addition, with respect to , we have
To derive EquationEquations (140)(140)
(140) and (Equation141
(141)
(141) ), we have used EquationEquation (108)
(108)
(108) .
Substituting EquationEquation (139)(139)
(139) in EquationEquation (137)
(137)
(137) , we obtain
where EquationEquations (52)(52)
(52) and (Equation49
(49)
(49) ) are used. Substituting EquationEquations (112)
(112)
(112) and (Equation134
(134)
(134) ) into EquationEquation (142)
(142)
(142) , we obtain
Note that EquationEquation (143)(143)
(143) is considered as a function of
,
, and
.
Meanwhile, if a specific generalized inverse of an matrix
is given by
, all the generalized inverses of
can be expressed by
where is an
arbitrary matrix (e.g. Theorem 9.2.7 in reference [Citation13]). Since the Moore–Penrose pseudoinverse is a special case of the generalized inverse, we may adopt
as the specific generalized inverse in the above equation. Hence, by using an arbitrary matrix
, we can express all the generalized inverses in the form:
where
To derive EquationEquation (145)(145)
(145) , we have used that
in light of EquationEquation (110)
(110)
(110) . Note that
is symmetric and idempotent:
In addition, with regard to , we have
Similarly to , by using an arbitrary matrix
, all the generalized inverses can be expressed by
Thus, EquationEquation (138)(138)
(138) can be rewritten as
where EquationEquation (146)(146)
(146) is used. Note that
is a function of
as shown in EquationEquation (145)
(145)
(145) , and that
is a function of
as shown in EquationEquation (150)
(150)
(150) . Hence, we can express EquationEquation (143)
(143)
(143) as a function of arbitrary matrices
,
, and
by substituting EquationEquations (145)
(145)
(145) and (Equation150
(150)
(150) ) in EquationEquation (143)
(143)
(143) .
First, substituting EquationEquation (145)(145)
(145) in EquationEquation (143)
(143)
(143) , we obtain
In light of EquationEquation (148)(148)
(148) , the fourth term of the most right-hand side of EquationEquation (151)
(151)
(151) vanishes:
To derive this equation, we have used the following equation for arbitrary matrices ,
, and
:
Second, let us substitute EquationEquation (150)(150)
(150) in EquationEquation (151)
(151)
(151) , then the second term of the most right-hand side of EquationEquation (151)
(151)
(151) can be written by
where EquationEquations (153)(153)
(153) , (Equation49
(49)
(49) ), (Equation148
(148)
(148) ), and (Equation147
(147)
(147) ) are used.
Finally, EquationEquation (151)(151)
(151) is expressed as a function of
,
, and
:
Note that the right-hand side of this equation is in the quadratic form of ,
, and
, and that it can be factorized. That is, we can rewrite EquationEquation (155)
(155)
(155) as
By expanding the right-hand side of EquationEquation (156)(156)
(156) , we can confirm that it is equal to the right-hand side of EquationEquation (155)
(155)
(155) . As mentioned in Section 2.1.3, for an
matrix
and an
matrix
, if
is symmetric and nonnegative definite,
is a symmetric nonnegative definite matrix. Moreover, for an arbitrary symmetric nonnegative definite matrix
,
holds (e.g. Corollary 14.7.3 in reference [Citation13]). Recalling that
is symmetric and nonnegative definite, we find that EquationEquation (135)
(135)
(135) holds for arbitrary matrices
,
, and
. Q.E.D.
4.3.3. Numerical verification
The correctness of EquationEquation (156)(156)
(156) derived in the proof was verified by numerical calculations using a simplified case (
,
,
). In this numerical verification, random numbers were generated to determine the arbitrary matrices
,
, and
; and the right-hand side of EquationEquation (156)
(156)
(156) was evaluated. Subsequently,
and
were determined by using EquationEquations (145)
(145)
(145) and (Equation149
(149)
(149) ); and the left-hand side of EquationEquation (156)
(156)
(156) was obtained by using EquationEquation (6)
(6)
(6) . Finally, we confirmed that the left-hand side of EquationEquation (156)
(156)
(156) agreed well with the right-hand side of EquationEquation (156)
(156)
(156) .
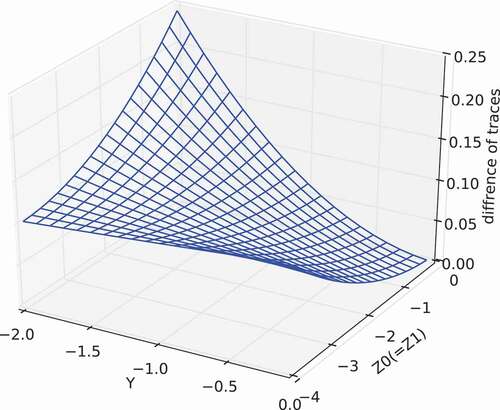
Moreover, and show another calculation result of the difference of traces, namely , for the simplified case. In this calculation, we defined by
and
, where
and
are scalar variables, and
represents the all-ones matrix, in which all elements are unity. Thus, by using
and
, we changed
and
around the zero matrix (i.e. around
). From these figure, we can see that the difference of traces becomes zero when
and
(i.e.
). That is,
has the minimum value among
.
Figure 1. Difference of the traces of and
as a function of
and
within the ranges of
and
.
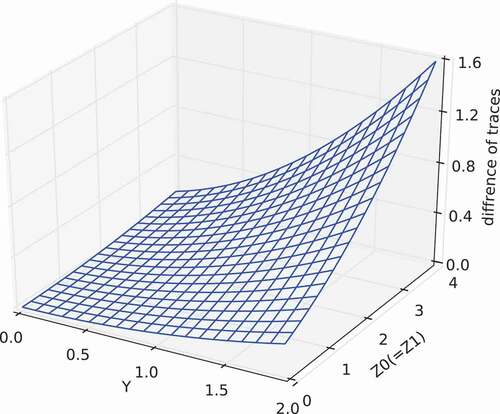
Figure 2. Difference of the traces of and
as a function of
and
within the ranges of
and
.
4.4. Role of assumption of normal distribution
With regard to MLCA, it was found that the formulation equivalent to CBCA can be derived by introducing the assumption of linear estimation expressed by EquationEquation (69)(69)
(69) . Meanwhile, the same formula can be derived by using the other assumptions, that is, MSCA and DRCA. For this reason, we examine these assumptions necessary for deriving the formulation equivalent to CBCA. summarizes the assumptions used in the derivation of CAs – including CBCA, MRCA, DRCA, MLCA, and MRCA.
Note that the assumption of normal distribution includes an assumption that the mean value is equal to the true value. Meanwhile, the mean value of the normal distribution is equal to the expectation value. Hence, we can understand that the assumption of normal distribution includes the assumption of unbiased estimation. Moreover, it should be noted that, when we assume the linear estimation of EquationEquation (70)(70)
(70) , it is necessary to introduce the assumption of minimum norm solution:
Table 1. Assumptions used in the derivation of the conventional cross-section adjustment methods
where is another linear combination factor (cf. EquationEquation (40)
(40)
(40) in reference [Citation9]). Note that the dimension of
differs from that of
used in the present derivation. We can see that both EquationEquations (157)
(157)
(157) and (Equation69
(69)
(69) ) include a concept of dimensionality expansion in the case that
: the former expands the dimension by
, and the latter by
. Thus, we can deduce that either the projection simplification or the dimensionality reduction is required to compensate the dimensionality expansion introduced by the assumption of minimum norm solution.
Moreover, from this table, it is seen that the assumption of normal distribution adopted in CBCA is equivalent to a set of the assumptions of:
unbiased estimation, linear estimation of EquationEquation (70)
unbiased estimation, linear estimation of EquationEquation (70)
unbiased estimation and linear estimation of EquationEquation (69)
In summary, when we apply CBCA under the condition of the underdetermined problem, the assumption of normal distribution plays an important role to expand properly the information of the integral experimental quantities to the adjusted cross-section set.
4.5. Comparison with derivation based on Bayes theorem
From the derivations of MLCA, MLEA, MLRA, and MLEB, we can deduce that the assumptions of linear estimation expressed by EquationEquations (69)(69)
(69) –(Equation71
(71)
(71) ) correspond to conditional probabilities maximized in derivations based on the Bayes theorem:
and
respectively, where denotes the probability distribution of
under the condition that
is given. In fact, EquationEquation (158)
(158)
(158) is used explicitly in the derivation of CBCA [Citation1,Citation4], and EquationEquation (160)
(160)
(160) is utilized in the derivation of CBEA [Citation8] in the modified form:
Besides CBEA, a lot of new techniques based on the Bayes theorem have been recently proposed (e.g. [Citation16–Citation18]). Hence, a detailed comparison with these techniques would be a future task. The foregoing correspondence between the linear estimations and the conditional probabilities, however, will be useful for the comparison of our methodologies with the other techniques based on the Bayes theorem.
5. Conclusions
In comparison with the classical Bayesian conventional cross-section adjustment (CBCA) method, the derivation of the Kalman filter was reviewed. This review revealed that CBCA is equivalent to a linearized model of the nonlinear Kalman filter, while the assumption of linear estimation used in the cross-section adjustment methodology differs from that in the Kalman filter. For this reason, by introducing the assumption used in the Kalman filter, we formulated the conventional, extended, and regressive cross-section adjustment methods (CA, EA, and RA) with no use of the assumption of normal distribution; these methods are called the conventional, extended, and regressive cross-section adjustment methods based on minimum variance unbiased linear estimation (MLCA, MLEA, and MLRA), respectively. Consequently, we found that MLCA has the formulation equivalent to CBCA. From these findings, we discussed the role of the assumption of normal distribution adopted in CBCA. Moreover, we demonstrated that the extended bias factor (EB) method can be formulated with the same procedure; this method is referred to as MLEB. The derivation of MLEB is simple, and would be helpful to understand the difference between EB and EA.
With regard to MLEA, we derived a generalized formulation that can express all the numerous solutions minimizing the variance of the design target core parameters. The formulation of MLEA includes a special case identical to the conventional Bayesian extended cross-section adjustment (CBEA) method; when we adopt the special case, the variance of adjusted cross-section set is also minimized. Thus, we can interpret that CBEA minimizes not only the variance of the design target core parameters but also the variance of the nuclear data. For this reason, we recommend to use the special case of MLEA, which is equivalent to CBEA, from a practical point of view.
On the other hand, in our review, we showed that CBCA is a type of the Kalman filter. Since many enhanced techniques based on the Kalman filter have been proposed in the other fields, we expect that an application of these techniques lead to further improvement in the cross-section adjustment methodology. Moreover, MLEA itself is an enhancement of the Kalman filter. Therefore, MLEA would be applicable in various fields other than nuclear reactor design.
Abbreviations
derivation procedures
CB : classical Bayesian (inference)
MVUE : minimum variance unbiased estimation
MVULE : minimum variance unbiased linear estimation
variations of cross-section adjustment methodology
CA : conventional cross-section adjustment method
EA : extended cross-section adjustment method
RA : regressive cross-section adjustment method
CAs
CBCA : classical Bayesian conventional cross-section adjustment method
MRCA : MVUE-based rigorous conventional cross-section adjustment method
MSCA : MVUE-based simplified conventional cross-section adjustment method
MLCA : MVULE-based conventional cross-section adjustment method
DRCA : dimension-reduced conventional cross-section adjustment method
EAs
CBEA : classical Bayesian extended cross-section adjustment method
MREA : MVUE-based rigorous extended cross-section adjustment method
MSEA : MVUE-based simplified extended cross-section adjustment method
MLEA : MVULE-based extended cross-section adjustment method
RA
MLRA : MVULE-based regressive cross-section adjustment method
extended bias factor methods
EB : (original) extended bias factor method
MLEB : MVULE-based extended bias factor method
Acknowledgments
The authors express their deep gratitude to the coauthors of references [8–10], since the present study is due to discussion with them through the series of studies. The authors are also grateful to Dr S. Takeda of Osaka University for useful comments on the present study. K. Yokoyama wishes to extend his special thanks to Mr M. Ishikawa of JAEA for great encouragement and helpful discussion based on his expertise.
Disclosure statement
No potential conflict of interest was reported by the authors.
Related Research Data
References
- Dragt JB. Statistical considerations on techniques for adjustment of Differential cross sections with measured integral parameters. In: STEK, The fast-thermal coupled facility of RCN at Petten. RCN-122. Petten: Reactor Centrum Nederland; 1970. p. 85–105.
- Gandini A, Petilli M, Salvatores M. Nuclear data and integral measurement correlation for fast reactors. Statistical formulation and analysis of methods. The Consistent Approach. International Symposium of Physics of Fast Reactors, 1973 October 16-19. Tokyo, Japan; Vol. 1. p. 612–628.
- Dragt JB, Dekker JWM, Guppelaar H, et al. Methods of adjustment and error evaluation of neutron capture cross sections; Application to fission product nuclides. Nucl Sci Eng. 1977;62:117–129.
- Takeda T, Yoshimura A, Kamei T. Prediction uncertainty evaluation methods of core performance parameters in large liquid-metal fast breeder reactors. Nucl Sci Eng. 1989;103:157–165.
- Salvatores M, Palmiotti G, Aliberti G, et al. Methods and issues for the combined use of integral experiments and covariance data: results of a NEA International Collaborative Study. Nuclear Data Sheets. 2014;118:38–71.
- de Saint-Jean C, Dupont E, Ishikawa M, et al. Assessment of existing nuclear data adjustment methodologies. Paris: OECD/NEA; 2011. NEA/NSC/WPEC/DOC(2010)429.
- Kugo T, Mori T, Takeda T. Theoretical study on new bias factor methods to effectively use critical experiments for improvement of prediction accuracy of neutronic characteristics. J Nucl Sci Technol. 2007;44(12):1509–1517.
- Yokoyama K, Ishikawa M, Kugo T. Extended cross-section adjustment method to improve the prediction accuracy of core parameters. J Nucl Sci Technol. 2012;49(12):1165–1174.
- Yokoyama K, Yamamoto A. Cross-section adjustment methods based on minimum variance unbiased estimation. J Nucl Sci Technol. 2016;53(10):1622–1638.
- Yokoyama K, Yamamoto A, Kitada T. Dimension-reduced cross-section adjustment methods based on minimum variance unbiased estimation. J Nucl Sci Technol. 2018;55(3):319–334.
- Kalman RE, New A. Approach to linear filtering and prediction problems. Trans ASME J Basic Eng. 1960;82:35–45.
- Kalman RE, Bucy RS. New results in linear filtering and prediction therory. Trans ASME J Basic Eng. 1961;83:95–108.
- Harville DA. Matrix algebra from a statistician’s perspective. 1st ed. New York (NY): Springer; 1997.
- Brown RG, Hwang PYC. Introduction to random signals and applied Kalman filtering. 4th ed. Hoboken (NJ): John Wiley & Sons, Inc; 2012.
- Palmiotti G, Salvatores M, Yokoyama K, et al. Methods and approaches to provide feedback from nuclear and covariance data adjustment for improvement of nuclear data files. Paris: OECD/NEA; 2017. NEA/NSC/WPEC/DOC(2016)6.
- Cacuci DG, Ionescu-Bujor M. Best-estimate model Calibration and Prediction Through Experimental Data Assimilation – I: mathematical Framework. Nucl Sci Eng. 2010;165:18–44.
- Hoefer A, Buss O, Hennebach M, et al. MOCABA: A general Monte Carlo-Bayes pro- cedure for improved predictions of integral functions of nuclear data. Ann Nucl Energy. 2015;77:514–521.
- Endo T, Yamamoto A, Watanabe T. Bias factor method using random sampling technique. J Nucl Sci Technol. 2016;53:1494–1501.