
As members of the Society for Personality Assessment and readers of the Journal of Personality Assessment (JPA), a central focus of our activities is assessment. This naturally implies that much of our work is devoted to developing or using diagnostic tests.Footnote1 The Standards for Educational and Psychological Testing (American Educational Research Association, American Psychological Association, and National Council on Measurement in Education, Citation2014) state that the psychometric properties of tests need to be reported in such a way that users can sufficiently identify whether the test provides evidence of reliability and validity. This naturally implies that the articles about the scales need to give enough information about the way they were developed and evaluated that readers can make this judgment. Whiting et al. (Citation2004) highlighted many potential sources of bias and variation in studies of diagnostic accuracy, including the demographic features of the participants, the severity and prevalence of the disorder, inappropriate choice in the selection of the reference standard, the handling of indeterminate results, and so forth. A later review by the same team found “consistent evidence” for the biasing effects of many of these factors (Whiting, Rutjes, Westwood, Mallet, & the QUADAS-2 Steering Group, Citation2013). However, there is considerable variability among studies in reporting how they were done or what was found (Honest & Khan, Citation2002).
In an attempt to overcome the problem of inadequate reporting of information regarding the development of diagnostic tests, the Cochrane Diagnostic and Screening Test Methods Working Group, consisting of 25 experts, primarily from medical and epidemiology departments, developed the Standards for Reporting of Diagnostic Accuracy (STARD; Bossuyt et al., Citation2003). STARD consists of a checklist of 25 items, tapping such areas as the method of recruiting participants, the order of testing, and the reference standard. This is supplemented with a flow chart providing detailed information about the number of people classified at each stage of the study. The Standards were recommended and published by two dozen of the leading medical journals, including the Journal of the American Medical Association, the British Medical Journal, the Lancet, and others. Meyer (Citation2003) wrote an editorial in this journal strongly recommending that authors of articles about diagnostic tests adhere to the STARD initiative, with some modifications making them more appropriate for psychologists.
The STARD guidelines (see ) have recently been updated, with the aim of making them easier to use, and incorporating recent evidence about sources of bias and the applicability of the results (Bossuyt et al., Citation2013). Most of the items remain unchanged, but some have been reworded, combined, or split, so that there are now 30 items grouped into four sections: introduction, methods, results, and discussion. The additional or changed items, keyed to , include the following:
2. A structured abstract.
3. A description of the intended use and clinical role of the test.
4. An explicit statement of the study hypotheses in order to preclude an overly generous interpretation of the results.
18. A statement of the sample size, and whether the targeted number of participants was achieved.
26–27. A structured discussion that includes the study limitations, bearing in mind the targeted application of the results.
28. Because prospective test accuracy studies are clinical trials, they can be included in a clinical trials registry, such as ClinicalTrials.gov or isrctn.com.
29. Where the full protocol may be obtained.
30. The source of funding.
Table 1. The STARD 2015 checklist for reporting information in diagnostic accuracy studies.
As before, there is also a flow chart (), and both are freely available at http://www.equator-network.org/reporting-guidelines/stard/.
Figure 1. Standards for Reporting Diagnostic Accuracy (STARD) prototype flow diagram.
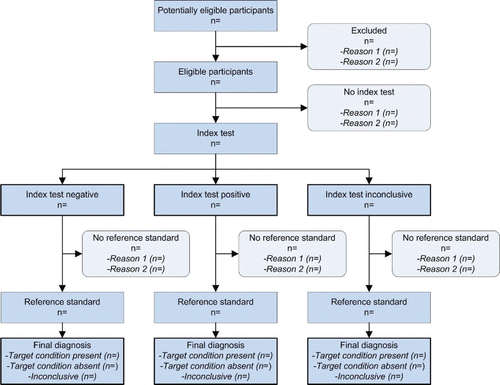
The revision of STARD raises three questions:
Because the initiative was developed primarily by and for physicians, is it appropriate for tests used by psychologists and, if not, what needs to be changed?
Has STARD had any impact on the field?
Are there any alternatives to STARD?
In this first of two editorials, we try to answer these questions. In the second part, we propose our revision to STARD 2015, which we believe will make it more relevant for developers of scales used in psychology and the other social sciences.
With respect to the first question, we believe that some modifications and additions need to be made. To begin with, STARD includes a number of items relating to a description of the target population, but very little about the independent raters who might either interpret the test or determine if the person meets the criteria for group membership: who they were in terms of background, training, special training in the use of the test, or even their number. Interestingly, such information was required in the original version of STARD, but not in the revision. We believe these deletions are unfortunate, as such information is necessary to interpret the study and to determine the usability of the test in other hands. Second, presumably because many medical tests are either derived from laboratory equipment or yield dichotomous results, there is no requirement that the items be described in terms of how they were derived, content relevance and completeness, the scoring format, the number of options, whether any are reverse scored, the existence of subscales, and so forth. In psychology, these are considered crucial pieces of information. Third, if there are subscales, it is important to indicate whether these provide any additional information over and above the full-scale score (Reise, Moore, & Haviland, Citation2010). Fourth, although STARD discusses how missing data were handled, it does not deal with related statistical issues, such as how outliers are dealt with, or the validity of the statistical assumptions. There are other areas that we feel need to be added, and these will be addressed in the next editorial.
The second issue is whether STARD has had an impact on reporting. Unfortunately, the picture is far from encouraging. Smidt et al. (Citation2005; Smidt et al., Citation2006) compared 124 articles published before STARD with 141 published afterward. Only 41% reported on more than 50% of the STARD items, and none reported more than 80%. There was an increase in 1.81 items after STARD, but the change was not statistically significant, nor was there any difference between journals that had and had not adopted the initiative.
Regarding the last point, alternatives to STARD, there is good news and bad. The good news is that there are other sets of criteria. The Guidelines for Reporting Reliability and Agreement Studies (GRRAS; Kottner et al., Citation2011) is similar to STARD, but goes into more detail and is more appropriate for tests used in the behavioral sciences. However, it is limited to the reliability phase of scale development and has not been formally adopted by any journal. Also, Streiner and Kottner (Citation2014) wrote an article outlining in narrative form how scale development and testing articles should be written, but it does not have a checklist or flow chart.
So where does that leave us? STARD has not (yet) had a major impact on the quality of articles of diagnostic tests, and needs to be modified to accommodate the types of studies used in psychology. However, we believe that it is definitely a worthwhile undertaking and the adoption of a modified STARD, more appropriate for psychologists, would definitely improve the reporting of such studies in this journal.
Notes
1 A diagnostic test is one that is used to classify persons into one of two or more groups, such as normal, borderline, or not normal, or accepted, or not accepted into a graduate program. Scales yielding continuous scores are not usually used as a diagnostic test, unless cut points are used to define diagnostic groups.
References
- American Educational Research Association, American Psychological Association, and National Council on Measurement in Education. (2014). Standards for educational and psychological testing. Washington, DC: American Educational Research Association.
- Bossuyt, P. M., Reitsma, J. B., Bruns, D. E., Gatsonis, C. A., Glasziou, P. P., Irwig, L. M., … Cohen, J. F. (2013). STARD 2015: An updated list of essential items for reporting diagnostic accuracy studies. BMJ, 351, h5527.
- Bossuyt, P. M., Reitsma, J. B., Bruns, D. E., Gatsonis, C. A., Glasziou, P. P., Irwig, L. M., … de Vet, H. C. (2003). Towards complete and accurate reporting of studies of diagnostic accuracy: The STARD initiative. BMJ, 326, 41–44.
- Honest, H., & Khan, K. S. (2002). Reporting of measures of accuracy in systematic reviews of diagnostic literature. BMC Health Services Research, 2, 1–4.
- Kottner, J., Audigé, L., Brorson, S., Donner, A., Gajewski, B. J., Hróbjartsson, A., … Streiner, D. L. (2011). Guidelines for Reporting Reliability and Agreement Studies (GRRAS) were proposed. Journal of Clinical Epidemiology, 64, 96–106.
- Meyer, G. (2003). Guidelines for reporting information in studies of diagnostic test accuracy: The STARD initiative. Journal of Personality Assessment, 81, 191–193.
- Reise, S. P., Moore, T. M., & Haviland, M. G. (2010). Bifactor models and rotations: Exploring the extent to which multidimensional data yield univocal scale scores. Journal of Personality Assessment, 92, 544–559.
- Smidt, N., Rutjes, A. W., van der Windt, D. A., Ostelo, R. W., Bossuyt, P. M., Reitsma, J. B., … de Vet, H. C. (2006). The quality of diagnostic accuracy studies since the STARD statement: Has it improved? Neurology, 67, 792–797. ( Erratum published in 2007, Neurology, 68, 534.)
- Smidt, N., Rutjes, A. W., van der Windt, D. A., Ostelo, R. W., Reitsma, J. B., Bossuyt, P. M., … de Vet, H. C. (2005). Quality of reporting of diagnostic accuracy studies. Radiology, 235, 347–353.
- Streiner, D. L., & Kottner, J. (2014). Recommendations for reporting the results of studies of instrument and scale development and testing. Journal of Advanced Nursing, 70, 1970–1978.
- Whiting, P., Rutjes, A. W. S., Reitsma, J., Glas, A. S., Bossuyt, P. M. M., & Kleijnen, J. (2004). Sources of variation and bias in studies of diagnostic accuracy: A systematic review. Annals of Internal Medicine, 140, 189–202.
- Whiting, P. F., Rutjes, A. W. S., Westwood, M. E., Mallett, S., & the QUADAS-2 Steering Group. (2013). A systematic review classifies sources of bias and variation in diagnostic test accuracy studies. Journal of Clinical Epidemiology, 66, 1093–1104.