
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Performing online monitoring for short horizon data is a challenging, though cost effective benefit. Self-starting methods attempt to address this issue adopting a hybrid scheme that executes calibration and monitoring simultaneously. In this work, we propose a Bayesian alternative that will utilize prior information and possible historical data (via power priors), offering a head-start in online monitoring, putting emphasis on outlier detection. For cases of complete prior ignorance, the objective Bayesian version will be provided. Charting will be based on the predictive distribution and the methodological framework will be derived in a general way, to facilitate discrete and continuous data from any distribution that belongs to the regular exponential family (with Normal, Poisson and Binomial being the most representative). Being in the Bayesian arena, we will be able to not only perform process monitoring, but also draw online inference regarding the unknown process parameter(s). An extended simulation study will evaluate the proposed methodology against frequentist based competitors and it will cover topics regarding prior sensitivity and model misspecification robustness. A continuous and a discrete real data set will illustrate its use in practice. Technical details, algorithms, guidelines on prior elicitation and R-codes are provided in appendices and supplementary material. Short production runs and online phase I monitoring are among the best candidates to benefit from the developed methodology.
1. Introduction
In Statistical Process Control/Monitoring (SPC/M) of either discrete or continuous univariate data, various frequentist based parametric methods have been developed, with the Shewhart type control charts, CUSUM and EWMA being the most dominant representatives. All these methods utilize the information coming from the likelihood to draw control limits, aiming to detect when the process moves from the in control (IC) state, where it runs under random natural variation, to the out of control (OOC) state, where exogenous to the process variation is present (Deming Citation1986). Typically, although not necessarily, in SPC/M the OOC state reflects either transient shifts (of large size) or persistent shifts (of medium/small size) that occurs in the unknown parameter(s), with detection being of main interest. The Shewhart type charts are employed to detect large transient shifts, while CUSUM and EWMA are more effective in identifying small persistent shifts. All these methods require knowledge of the IC process parameter(s), a matter handled in practice by the employment of an offline calibration (phase I) period, prior to the online monitoring of the process (phase II). Phase I estimation requires a relatively long sequence of independent and identically distributed (iid) data points from the IC distribution. Once the phase I data collection completes, the unknown parameter(s) estimation and the chart construction begins. Initially, all the phase I data are analyzed retrospectively and in case of alarms, observations might be removed and control limits might be revised. Next, once the control chart is finalized, online monitoring starts for phase II data, where we test whether the phase II data conform to the control limits established during phase I. It is well established and documented that phase I plays a crucial role, as undetected phase I issues (like masked outlying observations), will contaminate the parameter(s) estimates and the resulting control limits, jeopardizing the phase II performance. Jensen et al. (Citation2006) provided a nice review on the effect of estimation error, while Zhang et al. (Citation2013), Zhang, Megahed, and Woodall (Citation2014), and Lee et al. (Citation2013) showed that an excessively large amount of IC phase I data is required for a similar performance as if the IC parameter(s) were known. More recently, Dasdemir et al. (Citation2016) evaluated the phase I analysis and Atalay et al. (Citation2020) provided guidelines for automating phase I considering the phase II performance.
The phase I/II setup is known to have certain limitations. For example, it is not applicable in short runs, as the data size is too small to allow a phase I procedure (an industrial example of this type is presented in Section 6). Furthermore, it cannot be employed when the process under study requires online and not retrospective monitoring during phase I, as it happens in health type variables (such as the medical laboratory monitoring case that we present in Section 6). Jones-Farmer et al. (Citation2014), presented a detailed overview of methods that could be employed for short runs, with the self-starting methods probably being the ones most often applied in practice. As the name declares, such methods do not require a phase I/II separation and they are able to be up and running soon after the process starts. The idea behind the frequentist-based self-starting methods is to perform calibration and testing simultaneously. Focusing in outlier detection, Quesenberry (Citation1991a, Citation1991b, Citation1991c) introduced the self-starting versions of standard Shewhart type control charts, known as Q-charts. On the other hand, when the aim is in detecting small persistent shifts, self-starting CUSUMs and EWMA were suggested by Hawkins and Olwell (Citation1998) and Qiu (Citation2014) respectively. In more recent studies, a bootstrap based self-starting EWMA monitoring scheme for Poisson count data was proposed by Shen et al. (Citation2016). Within the frequentist-based approach, non-parametric methods, like the recursive segmentation and permutation (RS/P) (Capizzi and Masarotto Citation2013) or the sequential non-parametric tests (Madrid Padilla et al. Citation2019), have been also suggested to handle univariate data. Non-parametric methods are capable to identify small persistent shifts, while for transient shifts they require subgrouped data and/or a relative long sequence of observations. From all the aforementioned start-up frequentist based methods, only the Q-charts are built to identify transient shifts of large size (outliers) in short individual data, while the rest are more powerful in detecting small persistent shifts, like step changes.
The Bayesian approach to SPC/M is rather restricted. Menzefricke (Citation2002) suggested the use of the predictive distribution for constructing a control chart, which was next compared to Shewhart type charts for Normal and Binomial data. Kumar and Chakraborti (Citation2017) along with Ali (Citation2020), presented Bayesian versions of Shewhart type charts for time between events monitoring, while Kadoishi and Kawamura (Citation2020) suggested a hierarchical Bayesian modeling when we have data from a time series model IMA(1,1). Apley (Citation2012), introduced the posterior distribution plots that aim to monitor the process mean during phase II. Regarding phase I analysis, Woodward and Naylor (Citation1993) used Bayesian modeling to handle short runs of Normal data, while Tsiamyrtzis and Hawkins (Citation2005, Citation2010, Citation2019) provided a Bayesian change point approach using a mixture of distributions in modeling Normal or Poisson phase I data.
In this work, we propose a general Bayesian method that intends to provide efficient online monitoring of a process for short runs, without the requirement of a phase I/II separation, focusing on outlier detection. As a self-starting Bayesian method, it will utilize the available prior information (or adopt an objective Bayesian approach in scenarios of complete prior ignorance), providing a sequentially updated scheme that will be based on the predictive distribution. Precisely, we will introduce the Predictive Control Chart (PCC), which will be able to perform online monitoring, directly after the first observable becomes available. PCC will be formed as a sequentially updated region, against which every incoming data will be plotted, providing either conformance of the data with what has been foreseen from the predictive distribution or nonconformance, raising an alarm. PCC will be introduced in a general form, allowing to handle data of any (discrete or continuous) distribution, as long as this distribution is a member of the regular exponential family. The vast majority of the distributions used in SPC/M, with Normal, Poisson and Binomial being the most indicative cases, are members of the regular exponential family. The core idea of PCC, i.e., the sequential testing on the updated predictive distribution, can be extended in other distributions. However, the regular exponential family guarantees a general closed-form predictive distribution.
In Section 2, we provide the PCC derivation, along with the necessary formulas for several discrete and continuous univariate distributions that belong to the regular exponential family. We also present the PCC options that allow the use of possibly available historical data, via a power prior mechanism, and the possibility of employing a Fast Initial Response (FIR) PCC, which enhances its performance during the early stages of the process. Next, in Section 3 we provide the PCC based decision making, where apart from being able to control and monitor the process, we are capable of deriving online inference (in terms of point/interval estimates or hypothesis testing) for the unknown parameter(s) and perform forecasting. In Section 4, we present an extended simulation study, where we evaluate the PCC performance against its frequentist-based alternative, i.e., Q-chart (Quesenberry Citation1991a, Citation1991b, Citation1991c) and we additionally examine issues regarding prior sensitivity. The PCC robustness when we have dependent data or distribution misspecifications is examined in Section 5. The PCC application to real data follows in Section 6, where a continuous (Normal) and a discrete (Poisson) real-data case from a medical lab and an industrial setting respectively, are being explored. Finally, Section 7 provides the concluding remarks. Technical details, algorithms and guidelines regarding choices of prior distributions are provided as appendices along with R-codes as online supplementary material, and via GitHub at https://github.com/BayesianSPCM/BSPCM.
2. Predictive control chart
Being in the Bayesian framework, our goal is to utilize the available prior information and provide a control chart with enhanced performance compared to existing self-starting frequentist-based methods. The proposed Predictive Control Chart (PCC) will be formed by the predictive distribution and it will provide a sequentially updated region against which every new observable will be plotted. Observations falling outside the predictive region will ring an alarm triggering further investigation and potentially some form of corrective action.
Initially, we need to derive the predictive distribution (Geisser Citation1993), which depends on the likelihood of the observed univariate data. From a process under study, we sequentially obtain the data which we consider to be a random sample from the distribution
where
is univariate, while the unknown parameter
can be either univariate or multivariate, e.g.,
etc. Our main interest is in detecting in an online fashion and without employing a phase I exercise, the presence of large transient shifts on the unknown parameter(s)
We assume that the likelihood, is a member of the univariate k-parameter regular exponential family (denoted from this point on as k-PREF), and by following Bernardo and Smith (Citation2000), it can be written as:
(1)
(1)
where
are real-valued functions of the univariate observation xj that do not depend on
while
and
are real-valued functions of the unknown parameter(s)
that cannot depend on X. PCC will be developed for any likelihood that belongs to the k-PREF, providing a general platform where binary (Binomial), count (Poisson, Negative Binomial) or various continuous (Normal, Gamma, Lognormal etc.) univariate data can be analyzed using the same methodology.
The prior distribution is of key importance in the Bayesian approach. Since in practice, historical data (of the same or a similar process, not to be confused with phase I data) are typically available, we recommend the use of power priors (Ibrahim and Chen Citation2000), which offer a framework to incorporate past data (when available) in the mechanism of forming the prior distribution. The power prior is derived by:
(2)
(2)
where
refers to a vector of historical univariate data (under the same distribution law
that the current data obey),
is a scalar parameter,
is the initial prior for the unknown parameter(s) and
is the vector of the initial prior hyperparameters. The (fixed) parameter, α0, controls the power prior’s tail heaviness and consequently the influence of the historical data on the posterior distribution. Essentially, α0 represents the probability of the historical data being compatible with the current observations and at the extremes
or 1, the historical data will be ignored or taken fully into account (just as the current data) respectively. A typical value for α0 is
which conveys the weight of a single observation to the prior information. In general, α0 should be determined by the relevance of past with current data and how likely is the past data to provide reliable estimates for the unknown parameters (depending on the size n0). For relevant historical data but with small (large) n0 it is recommended to use
It should be noted that the power priors are robust in conflicts of historical and current data, as they use only the sufficient statistic of the past data.
Generalizing the power prior concept, we could either assume α0 is unknown (modeled by a prior distribution) or we could allow the use of multiple historical data: if Y and Z are historical data from different sources weighted by α0 and β0 respectively, then the power prior is proportional to:
(3)
(3)
It is worth mentioning that, Ibrahim, Chen, and Sinha (Citation2003), proved that the power prior is 100% efficient in the sense that the ratio of the output to input information is equal to one, with respect to Zellner’s information rule (see Zellner Citation1988).
In a subjective Bayesian manner, should reflect all available information regarding the unknown parameter(s) before the data become available and its form can be derived from prior knowledge, expert’s opinion etc. From an objective Bayesian point of view and under the scenarios of lacking any prior knowledge, one can adopt a weakly informative or even non-informative initial prior, such as flat (uniform) prior, Jeffreys (Citation1961) or reference (Bernardo Citation1979; Berger, Bernardo, and Sun Citation2009) prior (see also the discussion regarding prior elicitation in Appendix E).
To preserve closed form solutions for all scenarios, when implementing PCC, we will adopt a conjugate prior for which always exists for any likelihood that is a member of the k-PREF (Bernardo and Smith Citation2000) and its form is given by:
(4)
(4)
where
(parameter space) and
is the
-dimensional vector of the initial prior hyperparameters, such that:
(5)
(5)
The conjugate prior, is also a member of the exponential family. The choice of the hyperparameters
will reflect the prior knowledge, ranging from highly informative to vague and even non-informative choices. Non-conjugate choices of the initial prior are allowed, at the cost of not having PCC in closed form but evaluated numerically. A conjugate
will lead to a conjugate power prior of the form (see Appendix A):
(6)
(6)
where
is a
-dimensional vector, with
referring to the vector of historical univariate data. Theorem 1 provides, in closed form, the posterior and predictive distributions of any likelihood that belongs to the k-PREF (proof is given in Appendix A):
Theorem 1.
For any likelihood belonging to the k-PREF (1) and an initial conjugate prior (4) via a power prior (6) mechanism we have:
(i)The posterior distribution of the unknown parameter(s) :
(7)
(7)
where
is a
-dimensional vector, with
being the observed univariate data.
(ii)The predictive distribution of the single future univariate observable :
(8)
(8)
where
is a
-dimensional vector, function of the future observable
PCC construction will be based on the predictive distribution and it can start as soon as n = 2 (except when we have Normal likelihood with both parameters unknown, and we use the reference prior, where PCC starts at n = 3). The exact form of the predictive distribution (under conjugate prior), for various likelihood choices (either discrete or continuous data), used commonly in SPC/M, can be found in . To unify notation in the table, we denote by
the vector of historical and current univariate data,
the vector of weights corresponding to each element dj in D and finally we call
the length of the data vector D.
Table 1. The predictive distribution using an initial conjugate prior in a power prior mechanism for some of the distributions typically used in SPC/M, which also belong to the k-PREF. is the vector of historical and current univariate data,
are the weights corresponding to each element dj of D and
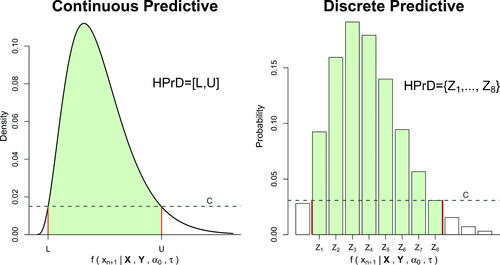
The PCC is based on the sequentially updated form of the predictive distribution, which is used to determine a region (), where the future observable (
) will most likely be, as long as the process is stable (i.e., no changes occurred). The region
will be the
Highest Predictive Density (HPrD) region, which is the unique shortest region, that minimizes the absolute difference with the predetermined coverage. We will adopt the name HPrD, even for cases in which the predictive distribution is discrete, where we derive the Highest Predictive Mass (HPrM) region (see Appendix B for the strict definition of HPrD/M and details in deriving the HPrD region from a continuous or discrete distribution). PCC will plot the sequentially updated HPrD region versus time, providing the “in control” region of the next data point and thus give an alarm if a new observable does not belong to the respective HPrD region. For unimodal predictive distributions, the region
will be an interval for continuous distributions, or a set with consecutive numbers for the discrete case, while for a multimodal predictive,
might be formed as a union of non-overlapping regions.
2.1. On selecting 
The (predetermined) parameter also known as False Alarm Rate (FAR), will reflect our tolerance to false alarms and consequently the detection power. The proposed PCC can be viewed as a sequential (multiple) hypothesis testing procedure, where at each time point n we draw the HPrD region (
) for the future observable, so that if no changes occurred in the process (IC state), the probability to raise an alarm is:
We suggest two metrics in selecting α, depending on whether we know or not in advance the number of data points, N, that PCC will be used for (in short runs or Phase I studies) and/or whether N is large.
If we have a (known) fixed horizon of N data points, for which PCC will be employed and N is not too large (typically up to a few dozens), then we suggest to control the Family Wise Error Rate (FWER), which expresses the probability of raising at least one false alarm out of a pre-determined number of N hypothesis tests. This is identical to the concept of False Alarm Probability (FAP) introduced by Chakraborti, Human, and Graham (Citation2008) for phase I analysis. Among various proposals in controlling FWER, we adopt the Šidák’s correction (Šidák Citation1967), which is slightly more powerful than the popular Bonferroni’s correction (Dunn Citation1961). Šidák’s correction assumes independence across tests and is more conservative in the presence of positive dependence, compared with independent tests. If we define V to be the number of false alarms observed in a PCC, applied on N observations in total, i.e., from the IC state of the distribution (
when PCC starts at n = 2), then the Šidák’s correction (assuming independence) will provide:
(9)
(9)
So, once we know N and we set the desirable FWER, we can obtain the parameter α needed in deriving the HPrD regions, It is evident that as N increases, α decreases and approaches zero, it leads to an extremely conservative decision scheme, that will reduce the OOC detection power.
We recommend to use the above approach, as long as even though this can be adjusted depending on the type of process we monitor. However, in the cases where N is either unknown in advance or it is too large, then we suggest to derive α using the metric of IC Average Run Length (ARL0). Following Montgomery (Citation2009), this corresponds to the desired average number of data points that we will plot in the PCC before a false alarm occurs, given that the process is under the IC state. As N increases, the updated posterior distribution gets more informative (offering consistent estimates of the unknown parameters) and thus the resulting hypothesis tests will tend to be nearly independent. Then, the value of the desired (predetermined) ARL0 will be approximately:
(10)
(10)
Based on either (9) or (10), we predetermine the coverage level that the HPrD region (
) will have.
2.2. Fast initial response (FIR) PCC
One of the most serious issues in self-starting methods, is the weak response to early shifts (Goedhart, Schoonhoven, and Does Citation2017; Capizzi and Masarotto Citation2020). The Fast Initial Response (FIR) feature is typically used to improve the performance of the standard charts for early shifts in a process. Lucas and Crosier (Citation1982) were the first to propose a FIR feature for CUSUM, while Steiner (Citation1999) introduced the FIR EWMA by narrowing the control limits. In the latter, the time dependent effect of the FIR adjustment, decreases exponentially with time and becomes negligible after a few observations. Precisely, Steiner’s adjustment is given by:
(11)
(11)
where
is a smoothing parameter, t is the current number of hypotheses tests performed and
represents the proportion of the adjusted limit over the initial test (i.e., t = 1).
As the PCC uses control limits, much like the EWMA, we will adopt Steiner’s adjustment for a time-varying narrowing of the region in the start of the process. Despite the head-start the FIR option can provide to PCC, we should make sure that we do not significantly inflate the false alarms. Thus, the FIR parameters should be selected by taking into account the false alarm behavior of PCC, which depends on the prior settings, especially when the volume of available data is small. If an extremely informative prior (near point mass) is used, then the PCC behavior acts like a typical Shewhart chart, as the resulting
region is not essentially updated by new observations. On the other hand, if a non-informative prior, like the initial reference prior without historical IC data, is selected, then the FAR depends only on the (iid) data. As a result for these two cases, the observed FAR will meet the predetermined standards (even from the very first hypothesis test) and therefore we should avoid the use of a FIR adjustment (or otherwise the observed FAR will be inflated).
However, in the case of a weakly informative prior, the region is quite wide (as we combine prior and likelihood uncertainty), but at the same time the prior distribution provides beneficial information for the IC state. Combining these two facts, the first IC data points are more likely to be plotted within the
region. This will result in a temporarily smaller (from what is anticipated) FAR, especially for the very early tests at the start of a process. Thus, we could use a FIR adjustment without a negative effect on the predetermined expected number of false alarms. We propose to be somewhat conservative and use f = 0.99, i.e., the adjusted
region will be the 99% of the original for the first test and
i.e., the adjusted
region will be the 99.9% of the original at the fifth test. We should note that t is the current number of tests, not the number of observations, as for the first (or the second) observation PCC does not provide a test.
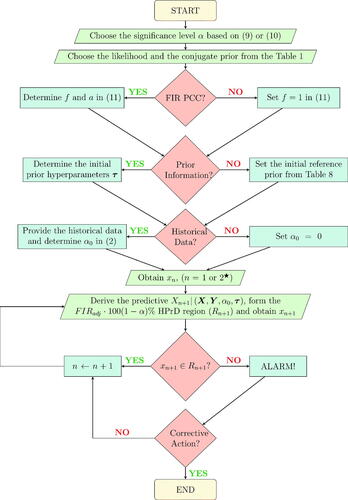
A flowchart in synopsizes the general PCC scheme with all possible options of its implementation, while in Appendix C we present it in a form of an algorithm.
Figure 1. PCC flowchart. A parallelogram corresponds to an input/output information, a decision is represented by a rhombus and a rectangle denotes an operation after a decision making. In addition, the rounded rectangles indicate the beginning and end of the process.
★For the Normal – NIG model using the initial reference prior and we need n = 2 to initiate PCC, while for all other cases PCC starts once x1 becomes available.
3. PCC based decision making
The major role of PCC is to control a process and identify transient large shifts (outliers), in an online fashion and without a phase I exercise. As such, PCC performs a hypothesis test as each new data point becomes available and raises an alarm when
indicating that the new observable is not in agreement with what is anticipated from the predictive distribution (that was built from the previous data and the prior distribution). The endpoints of
formed from the predictive distribution, play the role of the control limits of the chart. The range of these limits reflect the variability of the predictive distribution, which is known to depend on both the length of the available data and the precision of the prior distribution. For a weakly informative prior the range will be wider at the start of the process and as more data become available it will become more narrow and eventually stabilize, washing out the effect of the prior. provides illustrations of PCC for data streams of length 30 that come from a continuous (Normal data with both parameters unknown) and two discrete (Poisson and Binomial) cases, when the process is either IC or has a large isolated shift at location 15 (OOC scenario).
Figure 2. The IC and OOC illustration of PCC for Normal, Poisson and Binomial data. For the IC Normal data and for the OOC case we sample
The initial prior was
For the IC Poisson data
For the OOC case
while
For the IC Binomial data
For the OOC case
while
In all cases, α needed to derive the
HPrD
was selected to satisfy FWER = 0.05 for N = 30 observations.
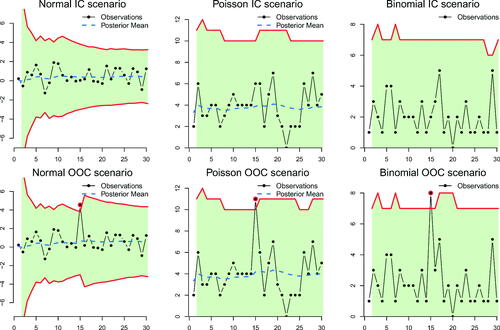
As can be seen in , the limits tend to become more narrow and finally stabilize when the size of the data increases, forming a more informative posterior distribution of the unknown parameter(s). The outlying observations in all scenarios are plotted outside the region, hence raising an alarm. The region
is formed online, after the data point xn becomes available, and so when we get an alarm (i.e.,
), the suggestion is to stop the process, perform some root cause analysis to identify external sources of variation, possibly have an intervention and finally restart the PCC (the posterior we had right before the alarm can act as the new prior, or the previous IC data can be used in the power prior mechanism). However, if we will not react to an alarm, due to the Bayesian dynamic update mechanism, the isolated change detected will be absorbed. As a consequence, the posterior and predictive distribution will have inflated variance leading to wider
regions. In the OOC scenarios in we observe that the
regions are wider at time 16 due to the “no action” policy at the alarm for time 15. This effect is reduced with time but it is still present until observation 30, where the
is wider compared to the respective region of the IC data.
Apart from controlling a process, PCC can be used for monitoring the unknown parameter(s). As we showed in Theorem 1, before deriving the predictive distribution at each time point, we first obtain the posterior distribution for the unknown parameter(s). Decision theory can be used to provide loss function based optimal point/interval estimates and/or hypothesis testing for each parameter. For example, using the squared error loss function, the Bayes rule (optimal point estimate) is known to be the mean of the posterior distribution (Carlin and Louis Citation2009), i.e., we have a (sequentially updated) point estimate of the unknown process parameter(s). To illustrate this option, in , we additionally plot the posterior mean estimate of θ1 for the Normal and θ3 for the Poisson cases.
Finally, PCC summarizes the predictive distribution through a region, but other forecasting options (like point estimates) are straightforward to derive as well using decision theory.
4. Competing methods and sensitivity analysis
The PCC is developed in a general framework, allowing its use for any likelihood that belongs to the k-PREF. In traditional SPC/M, significant amount of work has been dedicated for Normal, Poisson and Binomial data. When the goal is to detect transient large shifts in a short run process of individual univariate data, without employing a phase I calibration stage, the Q-charts developed by Quesenberry (Citation1991a, Citation1991b, Citation1991c) are probably the most prominent representative methods for Normal, Binomial and Poisson data respectively. In absence of phase I parameter estimates, the Q-charts provide a self-starting monitoring method, where calibration and testing happens simultaneously, aiming to detect process disturbances (OOC states) in an online fashion.
In this section we will compare the performance of the proposed PCC methodology against Q-chart for Normal, Poisson and Binomial data, i.e., a Bayesian versus a frequentist parametric approach. For the latter and precisely in the case of Normal data, Quesenberry (Citation1991a) presented three versions of Q-chart (we ignore the scenario that both parameters are known) when either a parameter is known or both unknown, for which we have the following:
Lemma 2.
All three versions of Q-Chart for Normal data are special cases of the respective PCCs, when the initial prior is the reference prior and we do not make use of a power prior option (i.e., ).
Appendix D provides the proof of this lemma, which shows that the Normal Q-charts (in all three cases) are identical to the respective PCC when neither prior information (i.e., use of reference prior) nor historical data are available. What happens though when prior information and/or historical data do exist? In such scenarios, the posterior distribution will be more informative, enhancing the predictive distribution, which will boost the PCC performance. For discrete data (Poisson and Binomial) the Q-charts use the uniform minimum variance unbiased (UMVU) estimation of the cumulative distribution function of the process, thus we lose ability to compare analytically against the respective exact discrete PCC.
In what follows we will perform a simulation study to examine the performance of Q-charts against PCC when we have N = 30 data points from or
distributions. We will design charts to have a FWER = 0.05 at the last observation N = 30 (using Šidák correction). We will compare the running
of Q-charts and PCC at each of the
data points, when we simulate IC sequences from
and
respectively (see Keefe, Woodall, and Jones-Farmer Citation2015 for more details regarding the conditional IC performance of self-starting control charts). To examine the OOC detection power of Q-charts and PCC we will use the IC sequences generated and introduce large isolated shifts at one of the locations: 5 (early), 15 (middle) or 25 (late). The size of the shifts that we will consider are:
Normal mean:
Poisson mean (or variance):
Binomial probability of succes:
For detection, we will record the cases that a chart provides an alarm at the exact time that the shift was introduced. More specifically, these cases will be denoted as the OOC Detection (OOCD), where where
Both
for IC data (at each time 2, …, 30) and
at locations 5, 15, or 25 will be estimated over 100,000 iterations.
PCC will require to define a prior distribution and so within this simulation study we will take advantage to examine the sensitivity of the PCC performance for various prior settings. Precisely, for each setup described above, we will make use of two initial priors (reference and weakly informative) and two values for the α0 parameter (0 or ) representing the absence or presence of n0 historical data Y (we will use
historical data from the IC likelihood). Therefore, for each scenario we will compare the Q-chart against one of the four possible versions of PCC (with/without prior knowledge, with/without historical data). The initial priors
which we will employ are (see ):
Figure 3. The initial reference (i.e., non-informative) and the weakly informative prior distributions used in the simulation study, along with the IC values (as vertical segments) for the parameters and θ4 of the simulation study.
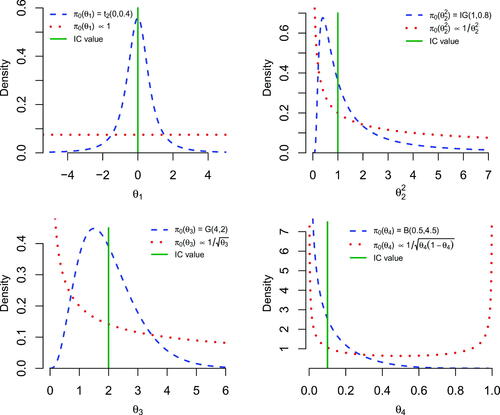
Normal: reference prior
Poisson: reference prior
Binomial: reference prior
The simulation findings are summarized graphically in and analytically in , where we observe that overall PCC outperforms Q-chart. Starting from the false alarms in the case of Normal data, both methods reach the nominal 5% at time N = 30, but at all time points k, the FWER(k) of PCC is always smaller. For both discrete cases, the Q-chart’s FWER(k) becomes unacceptably high, something that is caused from the fact that the true parameter values are near (even though not too close) to the parameter space boundary, which in conjunction with the UMVU estimation, inflates drastically the false alarms (the closer we get to the parameter boundary the worst the performance regarding false alarms). Finally, the extremely small FWER(k) observed for PCC in the first 5 data points motivates the use of the FIR-PCC described in Section 2.2.
Figure 4. The FWER(k) at each time point (top row) and the
at
or 25, of the Q-chart and PCC under a reference prior (PCC1), a reference prior with historical data
a weakly informative prior (PCC3) and a weakly informative prior with historical data
when we have outliers of 2.5 (middle row) or 3 (bottom row) standard deviations. Columns 1 to 3 refer to the Normal, Poisson and Binomial cases respectively.
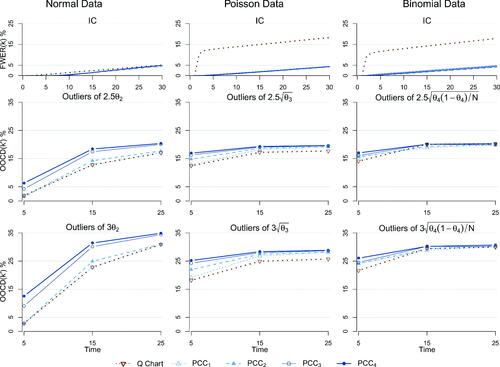
Table 2. The FWER for N = 30 (in parenthesis) and the outlier detection power at of the Q-chart against PCC under a reference prior (PCC1), a reference prior with historical data
a weakly informative prior (PCC3) and a weakly informative prior with historical data
For the Normal data, the simulations verify Lemma 2, as the Q-chart and the PCC with reference prior and no historical data have identical performance. Moving to the detection power, as it is measured by both methods improve as the size of the shift increases (from 2.5 to 3 sd) or the shift delays its appearance (from
to 15 to 25), just as it was expected. Especially for the shifts at time 5, PCC greatly outperforms Q-charts thanks to the head-start from the prior and/or the historical data. Focusing at each location of the shift, we observe that as we move from Q-chart to PCC with reference prior and next to PCC with weakly informative prior the performance improves (quite significantly for some scenarios). When relevant historical data are available, through the power prior mechanism, they further boost the performance. The somewhat competitive performance of Q-chart in one of the Binomial scenarios should be considered in conjunction with its quite high FWER, when compared to the one achieved by PCC (see also , where the FWER of PCCs is increased to align with the one that Q-chart can achieve in the Poisson and Binomial cases, offering a straightforward comparison of detection power). In summary, PCC appears more powerful to the respective Q-charts in detecting isolated shifts in short runs of individual data.
Table 3. The FWER for N = 30 (in parenthesis) and the outlier detection power at of the Q-chart against PCC under a reference prior (PCC1), a reference prior with historical data
a weakly informative prior (PCC3) and a weakly informative prior with historical data
Focusing on the performance of PCC at location we observe that in the Normal scenario we have smaller power compared to the respective setting in Poisson or Binomial (as we move
to higher values, the differences vanish). This is caused from the fact that in the Normal scenario we have two unknown parameters as opposed to the Poisson and Binomial cases where each has only one unknown parameter (a PCC built using four data points for a setting with two unknown parameters will be a lot more challenging, as opposed to a setting with only one unknown parameter). A Normal PCC scheme with either the mean or the variance being known would radically improve the performance reaching (or even overcoming) the levels achieved in the Poisson and Binomial. The effect of the two unknown parameters (Normal) versus the single unknown parameter (Poisson and Binomial) is responsible in the performance of PCC1 to PCC4 in detecting outliers at
With one unknown parameter, the information collected from the 24 in control data points has significantly reduced the posterior (and predictive) uncertainty, shrinking the effect of the prior and providing a near uniform performance. For the Normal case though the posterior (and predictive) uncertainty at
remains non-negligible, allowing the prior setting to play some role and differentiate the performance across the four versions of PCCs (in general the more the data the higher the shrinkage of the prior’s effect).
Regarding the prior sensitivity and its effect on the PCC performance (emphasizing in Normal, Poisson and Binomial data), a more thorough discussion along with certain guidelines on prior elicitation can be found in Appendix E. Wrapping up this section, we should note that PCC was shown to be more powerful in detecting large isolated shifts compared to Q-chart. The relative performance of Q-chart to PCC remains the same when we use medium or small shifts, with detection power dropping as the size of the isolated shift decreases.
5. Robustness
Apart from checking the prior sensitivity that was done in Section 4, we will also examine how robust the suggested PCC performance is to possible model type misspecifications. For the PCC construction we assume that the observed data are iid observations from a specific likelihood. In this section, we will examine how robust is the PCC performance when:
we violate the assumption of independence (i.e., the data are correlated)
the assumed likelihood function is invalid (i.e., data are generated from a different random variable from the one assumed in the PCC construction).
Regarding (a) we will use a Normal (with both parameters unknown) PCC implementation, but the actual data will be generated as sequentially dependent Normal data via an autoregressive (AR) model: with c = 0 and
To examine various degrees of dependence we will use
(moderate) or 0.8 (high). For the outlying observations we will set
2.5 or 3, in order to introduce shifts of size of
or
respectively, at one of the locations 5, 15 or 25 (just as we did in Section 4).
For (b) we will examine the following scenarios:
Use a Normal based PCC (both parameters unknown) while the data are generated from a Student t7 distribution, i.e., we have heavier tails (t7 is symmetric, with the same mean but 40% inflated variance compared with the standard Normal).
Use a Normal based PCC (both parameters unknown) while the data are generated from a
Use a Poisson based PCC while the data are generated from a
The aforementioned likelihoods are illustrated in . For this misspecification scenario, we generate the OOC data from the introduced distributions in a manner that the isolated large shifts will correspond to either 2.5 or 3 standard deviations, again at locations 5, 15 or 25 (similar to what we had in Section 4). Precisely:
Figure 5. The various misspecification of the PCC distributional forms regarding the continuous (left panel) and discrete (right panel) data generation mechanisms.
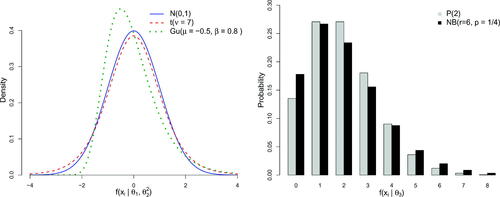
Student t: OOC states come from
Gumbel: OOC states come from
Negative Binomial: OOC states come from
The prior distributions (reference prior and weakly informative) along with the use or not of historical data (power prior with
) will be identical to the ones used in Section 4.
and summarize graphically the results of and , regarding the performance (FWER(k) and are as defined in Section 4) for independence and distributional misspecifications respectively. In the former, we observe that PCC is almost unaffected in the presence of moderate autocorrelation. For highly dependent data (
or larger), PCC is somewhat less robust as it decreases its detection power and slightly increases the FWER percentages, however still achieving noticeable performance, especially at the early stages thanks to the IC prior information.
Figure 6. The FWER(k) at each time point (top row) and the
at
or 25 and size of 2.5 (middle row) or 3 (bottom row) standard deviations for the Normal distribution PCC with both parameters being unknown, when we actually have data from an AR(1) process. A reference or weakly informative prior and the presence or absence of historical data is considered. Columns 1 to 3 refer to the various degrees of autocorrelation.
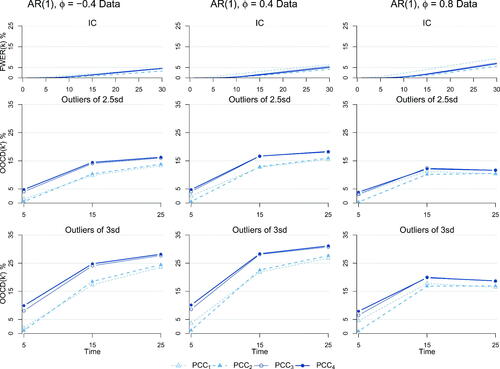
Figure 7. The FWER(k) at each time point (top row) and the
at
or 25, of PCC under a reference or weakly informative prior and in the presence or absence of historical data, when we have outliers of 2.5 (middle row) or 3 (bottom row) standard deviations. Columns 1 and 2 refer to the Normal PCC with both parameters being unknown while the data come from a Student or Gumbel distribution respectively. In column 3 we assume Poisson based PCC while the data are from a Negative Binomial.
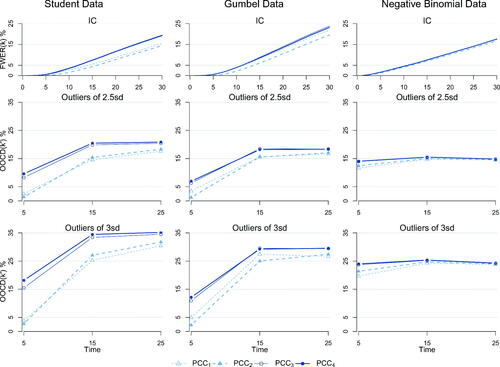
Table 4. The FWER at N = 30 (in parenthesis) and the outlier detection power at for the Normal distribution for PCC with both parameters being unknown, when we actually have data from an AR(1) process.
Table 5. The FWER at N = 30 (in parenthesis) and the outlier detection power at for the Normal distribution for PCC violating the distributional assumption.
In the distributional violation scenarios (), we observe that PCC retains its high detection percentages in all cases. However, the FWER(k) is significantly inflated. This can be explained by considering the shape discrepancies among the assumed and actual likelihood functions, where IC values are somewhat outlying under the misspecified assumed model (a more strict α value in determining the HPrD region would reduce the FWER(k) in such scenarios at the cost of somewhat reducing power).
Finally, for both the violation schemes, it is worth mentioning that PCC detection seems to be stabilized and not necessarily improved when the outliers occur at location 25. This can be attributed to the contaminated estimates of the unknown parameters from the data that violate the PCC assumptions, as well as the fact that the influence of the prior is decreased. Overall, the PCC appears to be robust when we violate the assumptions, as its performance is somewhat reduced but noticeably far from collapsing.
6. Real data application
In this section we will illustrate the use of PCC in practice. Specifically, we will apply the proposed PCC methodology in two real data sets (one for continuous and one for discrete data). Regarding the continuous case, we will use data that come from the daily Internal Quality Control (IQC) routine of a medical laboratory. We are interested in the variable “activated Partial Thromboplastin Time” (aPTT), measured in seconds. APTT is a blood test that characterizes coagulation of the blood. It is a routine clotting time test and can be used as a diagnosis of bleeding risk (e.g., aPTT value is higher in patients with hemophilia or Willebrand disease) or for unfractionated heparin treatment monitoring. We gathered 30 daily normal IQC observations (Xi) from a medical lab (see ), where Notice that these data are based on control samples and in regular practice will become available sequentially. The goal is to accurately detect any transient parameter shift of large size, as this will have an impact on the reported patient results. Thus, it is of major importance to perform on-line monitoring of the process without a phase I exercise. Via available prior information, we elicit the prior
Furthermore, there were
historical data (from a different reagent) available (see ), with
and
We set
and combining these two sources of information we get the power prior
To examine prior sensitivity we will also use as initial prior the reference prior
(to declare a-priori ignorance) and so we will get two versions of PCC (one for each initial prior). provides the two versions of PCC (continuous/dotted limits for weakly informative/reference prior) along with a plot of the historical data and the marginal distributions of the mean (θ1) and variance
at the end of the data collection. Specifically, for each parameter we plot the marginal weakly informative initial,
power,
priors and the posterior distribution,
We should emphasize that despite the fact that we provide the plots at the end of the data sequence, in practice the PCC chart and each of the two posterior distributions will start being plotted at observation 2 and 1 respectively and will be sequentially updated every time a new observable becomes available. PCC provides an alarm at location 16, indicating that there was a transient large shift during that day. This would call for checking the process at that date and if an issue was found then we would take some corrective action, initiate the PCC and reanalyze all the patient samples that were received between days 15 (no alarm) and 16 (alarm). In the present study, no action was taken and the process continued to operate. As a result, the PCC limits were inflated right after the alarm, but this effect was gradually absorbed as more IC data become available. We also note (as expected) that the use of the reference prior provides wider limits, especially at the early stage of the process, making the chart less responsive. Finally, the marginal posterior distributions can be used to draw inference regarding the unknown parameters, at each time point.
Figure 8. The PCC application on Normal data. At the upper panels (left and right), we have the marginal distributions for the mean and the variance respectively. With the dotted, dashed and solid lines we denote the initial prior, the power prior and the posterior after gathering all the current data respectively. At the lower panels, we provide the time series of the historical data (open circles on left) and of the current data (solid points on the right). The solid lines represent the limits of PCC, the dotted lines are the limits of PCC under prior ignorance, i.e., using the initial reference prior and the dash lines correspond to the FIR adjustment, setting f = 0.99 and
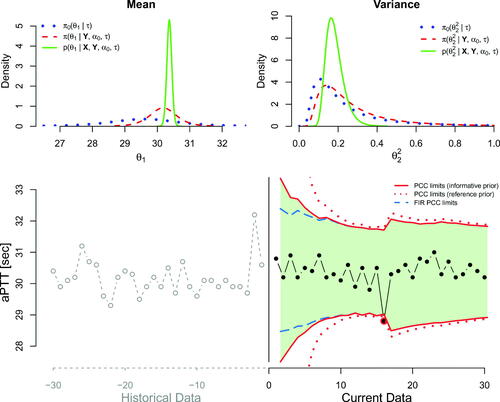
Table 6. The aPTT (in seconds) internal quality control observations of the historical and the current
data.
Next, we provide an illustration of PCC for discrete (Poisson) data. The data come from Hansen and Ghare (Citation1987) and were also analyzed by Bayarri and García-Donato (Citation2005). They refer to the number of defects (xi), per inspected number of units (si), encountered in a complex electrical equipment of an assembly line. We have 25 counts (see ) arriving sequentially that we will model using the Poisson distribution with unknown rate parameter, i.e., In contrast to the previous application, neither prior information regarding the unknown parameter nor historical data exist. Therefore, we use the reference prior as initial prior for θ, i.e.,
and we also set
for the power prior term. In , we provide the initial prior and posterior distributions, the plot of the data, (daily rate of defects i.e., total number of defects per number of inspected units and number of inspected units) and the Poisson based PCC (the wavy form of the limits is caused by the variation in the number of inspected units we have per day). Similarly to what we mentioned earlier, the posterior and the PCC will start from times 1 and 2 respectively and will be updated sequentially, every time a new data point becomes available, offering online inference in controlling the process. PCC raises two alarms, at locations 13 and 25. In the former, the observed rate (30/3 = 10) seems to be higher (process degradation) from what it was expected from the process as it was evolving till that time, while the latter indicates that the observed rate (14/8 = 1.75) was smaller from what PCC was anticipating (process improvement). Similar to the previous application, the fact that the alarms were kept in the process inflated the subsequent limits. At last, online inference regarding the unknown Poisson rate parameter is available via its (sequentially updated) posterior distribution.
Figure 9. The PCC application on Poisson data. At the upper left panel we have the distributions for the rate parameter. With the dashed and solid lines we denote the prior and posterior distributions respectively, after gathering all the available data. At the upper right panel, we provide the number of inspected units si (dashed line) and the number of defects per size i.e the rate of defects (solid line), whereas at the lower panel we present the PCC implementation. Specifically, solid lines correspond to the standard PCC process, while the dashed represent the PCC based on FIR adjustment, setting f = 0.95 and
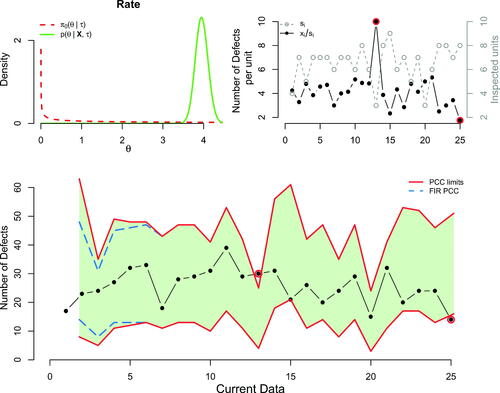
Table 7. Number of defects (xi) and inspected units (si) per time point (), in an assembly line of an electrical equipment.
7. Conclusions
In this work we proposed a new general Bayesian method that permits online process monitoring for various types of data, as long as their distribution belongs to the regular exponential family. The use of initial and/or power prior distribution, offers an axiomatic framework where subjective knowledge and/or historical data can be incorporated in the decision making scheme allowing valid online inference, from the very early start of the process, aborting the need of phase I. It is the use of prior distribution that provides a structural advantage over the non-parametric and self-starting frequentist based methods, especially in shorts runs and phase I data, where only brief IC information is available from the current data. The effect of the prior settings (as long as we avoid extremely informative priors), will decay soon, as more data become available. Furthermore, for users that might not be accustomed to the Bayesian approach, the choice of non-informative (reference or Jeffeys) prior, allows direct PCC implementation, using only the incoming data (and historical data if available).
PCC emphasizes in online outlier detection of short production runs and it does not require a phase I/II split. Traditional phase I studies, where online inference regarding the presence of large transient shifts is of interest, are ideal settings for PCC. Furthermore, it is feasible for a user to switch from standard phase I/II monitoring methods to PCC, as it will not only provide online outlier detection monitoring during the “phase I” segment, but thanks to its sequentially updated nature, it will allow incorporation of the “phase II” data into the monitoring mechanism (something that is not done with typical frequentist methods). Thanks to the Bayesian posterior distribution, we are also able to perform inference regarding each of the unknown parameters.
PCC seems to be ideal for everyone that deals with either short runs or applications that require online monitoring during phase I. However, practitioners that employ a traditional phase I/II protocol in their routine, can benefit from the use of PCC during their phase I. Precisely, they will not only be able to monitor the process online while in phase I, but also obtain the posterior point estimates of the unknown parameters at the end of phase I, that will be necessary to build traditional phase II control charts. The benefits are significant in short runs, where most of the existing methods are unable to have robust performance and reliable estimates of the unknown parameter(s).
Supplemental Material
Download Zip (5.3 KB)Acknowledgments
We are grateful to the editor and the two anonymous referees, whose valuable comments and suggestions improved significantly the manuscript. We would also like to thank Frederic Sobas from Hospices Civils de Lyon, who provided the data set used in the Normal PCC, but more importantly for his invaluable feedback from using the suggested PCC at the daily Internal Quality Control routine in the medical labs of Hospices Civils de Lyon. This research was partially funded by the Research Center of the Athens University of Economics and Business.
Additional information
Funding
Notes on contributors
Konstantinos Bourazas
Konstantinos Bourazas is currently a Ph.D. candidate in the department of Statistics at the Athens University of Economics and Business, Greece. His research interest is mainly focused on Bayesian statistical process control and monitoring and sequential change point models with applications in the bio-medical area.
Dimitrios Kiagias
Dimitrios Kiagias is currently a Research Associate in the School of Mathematics and Statistics at the University of Sheffield. His main research areas are on Bayesian methodologies and applications on quality control schemes, clinical trials and image analysis of biological systems. His email is: [email protected].
Panagiotis Tsiamyrtzis
Panagiotis Tsiamyrtzis is currently an Associate Professor at the Department of Mechanical Engineering, Politecnico di Milano and his email is [email protected].
Related Research Data
References
- Ali, S. 2020. A predictive Bayesian approach to sequential time-between-events monitoring. Quality and Reliability Engineering International 36 (1):365–87. doi: 10.1002/qre.2580.
- Apley, D. W. 2012. Posterior distribution charts: A Bayesian approach for graphically exploring a process mean. Technometrics 54 (3):279–310. doi: 10.1080/00401706.2012.694722.
- Atalay, M., M. Caner Testik, S. Duran, and C. H. Weiß. 2020. Guidelines for automating phase I of control charts by considering effects on phase-II performance of individuals control chart. Quality Engineering 32 (2):223–43. doi:10.1080/08982112.2019.1641208
- Bayarri, M. J., and G. García-Donato. 2005. A Bayesian sequential look at u-control charts. Technometrics 47 (2):142–51. doi: 10.1198/004017005000000085.
- Berger, J. O., J. M. Bernardo, and D. Sun. 2009. The formal definition of reference priors. Annals of Statistics 37:905–38.
- Bernardo, J. M. 1979. Reference posterior distributions for Bayesian inference. Journal of the Royal Statistical Society: Series B (Methodological) 41 (2):113–47. doi: 10.1111/j.2517-6161.1979.tb01066.x.
- Bernardo, J. M., and A. F. M. Smith. 2000. Bayesian theory. 1st ed. New York: Wiley.
- Capizzi, G., and G. Masarotto. 2013. Phase I distribution-free analysis of univariate data. Journal of Quality Technology 45 (3):273–84. doi: 10.1080/00224065.2013.11917938.
- Capizzi, G., and G. Masarotto. 2020. Guaranteed in-control control chart performance with cautious parameter learning. Journal of Quality Technology 52 (4):385–403. doi:10.1080/00224065.2019.1640096
- Carlin, B. P., and T. A. Louis. 2009. Bayesian methods for data analysis. London: Chapman & Hall.
- Chakraborti, S., S. W. Human, and M. A. Graham. 2008. Phase I statistical process control charts: An overview and some results. Quality Engineering 21 (1):52–62. doi: 10.1080/08982110802445561.
- Dasdemir, E., C. Weiß, M. C. Testik, and S. Knoth. 2016. Evaluation of phase I analysis scenarios on phase II performance of control charts for autocorrelated observations. Quality Engineering 28 (3):293–304. doi: 10.1080/08982112.2015.1104540.
- Deming, W. E. 1986. Out of crisis. Cambridge, MA: The MIT Press.
- Dunn, O. J. 1961. Multiple comparisons among means. Journal of the American Statistical Association 56 (293):52–64. doi: 10.1080/01621459.1961.10482090.
- Geisser, S. 1993. Predictive inference: An introduction. London: Chapman & Hall.
- Goedhart, R., M. Schoonhoven, and R. J. Does. 2017. Guaranteed in-control performance for the Shewhart X and X¯ control charts. Journal of Quality Technology 49 (2):155–71.
- Haldane, J. B. S. 1932. A note on inverse probability. Mathematical Proceedings of the Cambridge Philosophical Society 28 (1):55–61. doi: 10.1017/S0305004100010495.
- Hansen, B., and P. Ghare. 1987. Quality control and application. Englewood Cliffs, NJ: Prentice-Hall.
- Hawkins, D. M., and D. H. Olwell. 1998. Cumulative sum charts and charting for quality improvement. New York: Springer.
- Ibrahim, J., and M. Chen. 2000. Power prior distributions for regression models. Statistical Science 15:46–60.
- Ibrahim, J., M. Chen, and D. Sinha. 2003. On optimality properties of the power prior. Journal of the American Statistical Association 98 (461):204–13. doi: 10.1198/016214503388619229.
- Jeffreys, H. 1961. Theory of probability. 3rd ed. Oxford: Oxford University Press.
- Jensen, W. A., L. A. Jones-Farmer, C. W. Champ, and W. H. Woodall. 2006. Effects of parameter estimation on control chart properties: A literature review. Journal of Quality Technology 38 (4):349–64. doi: 10.1080/00224065.2006.11918623.
- Jones-Farmer, L. A., W. H. Woodall, S. H. Steiner, and C. W. Champ. 2014. An overview of phase I analysis for process improvement and monitoring. Journal of Quality Technology 46 (3):265–80. doi: 10.1080/00224065.2014.11917969.
- Kadoishi, S., and H. Kawamura. 2020. Control charts based on hierarchical Bayesian modeling. Total Quality Science 5 (2):72–80. doi: 10.17929/tqs.5.72.
- Keefe, M. J., W. H. Woodall, and L. A. Jones-Farmer. 2015. The conditional in-control performance of self-starting control charts. Quality Engineering 27 (4):488–99. doi: 10.1080/08982112.2015.1065323.
- Kerman, J. 2011. Neutral noninformative and informative conjugate beta and gamma prior distributions. Electronic Journal of Statistics 5:1450–70. doi: 10.1214/11-EJS648.
- Kumar, N., and S. Chakraborti. 2017. Bayesian monitoring of times between events: The Shewhart tr-chart. Journal of Quality Technology 49 (2):136–54. doi: 10.1080/00224065.2017.11917985.
- Lee, J., N. Wang, L. Xu, A. Schuh, and W. H. Woodall. 2013. The effect of parameter estimation on upper-sided Bernoulli cumulative sum charts. Quality and Reliability Engineering International 29 (5):639–51. doi: 10.1002/qre.1413.
- Lucas, J. M., and R. B. Crosier. 1982. Fast initial response for CUSUM quality-control schemes: Give your CUSUM a head start. Technometrics 24 (3):199–205. doi: 10.1080/00401706.1982.10487759.
- Madrid Padilla, O. H., A. Athey, A. Reinhart, and J. G. Scott. 2019. Sequential nonparametric tests for a change in distribution: An application to detecting radiological anomalies. Journal of the American Statistical Association 114 (526):514–28. doi: 10.1080/01621459.2018.1476245.
- Menzefricke, U. 2002. On the evaluation of control chart limits based on predictive distributions. Communications in Statistics - Theory and Methods 31 (8):1423–40. doi: 10.1081/STA-120006077.
- Montgomery, D. C. 2009. Introduction to statistical quality control. 6th ed. New York: Wiley.
- Qiu, P. 2014. Introduction to statistical process control. London: CRC Press, Chapman & Hall.
- Quesenberry, C. P. 1991a. SPC Q charts for start-up processes and short or long runs. Journal of Quality Technology 23 (3):213–24. doi: 10.1080/00224065.1991.11979327.
- Quesenberry, C. P. 1991b. SPC Q charts for a binomial parameter p: Short or long runs. Journal of Quality Technology 23 (3):239–46. doi: 10.1080/00224065.1991.11979329.
- Quesenberry, C. P. 1991c. SPC Q charts for a Poisson parameter: Short or long runs. Journal of Quality Technology 23 (4):296–303. doi: 10.1080/00224065.1991.11979345.
- Shen, X., K. L. Tsui, C. Zou, and W. H. Woodall. 2016. Self-starting monitoring scheme for Poisson count data with varying population sizes. Technometrics 58 (4):460–71. doi: 10.1080/00401706.2015.1075423.
- Šidák, Z. K. 1967. Rectangular confidence regions for the means of multivariate normal distributions. Journal of the American Statistical Association 62 (318):626–33. doi: 10.1080/01621459.1967.10482935.
- Steiner, S. H. 1999. EWMA control charts with time-varying control limits and fast initial response. Journal of Quality Technology 31 (1):75–86. doi: 10.1080/00224065.1999.11979899.
- Tsiamyrtzis, P., and D. M. Hawkins. 2005. A Bayesian scheme to detect changes in the mean of a short run process. Technometrics 47 (4):446–56. doi: 10.1198/004017005000000346.
- Tsiamyrtzis, P., and D. M. Hawkins. 2010. Bayesian start up phase mean monitoring of an autocorrelated process that is subject to random sized jumps. Technometrics 52 (4) :438–52. doi: 10.1198/TECH.2010.08053.
- Tsiamyrtzis, P., and D. M. Hawkins. 2019. Statistical process control for phase I count type data. Applied Stochastic Models in Business and Industry 35 (3):766–87. doi: 10.1002/asmb.2398.
- Wang, X., D. J. Nott, C. C. Drovandi, K. Mengersen, and M. Evans. 2018. Using history matching for prior choice. Technometrics 60 (4):445–60. doi: 10.1080/00401706.2017.1421587.
- Woodward, P. W., and J. C. Naylor. 1993. An application of Bayesian methods in SPC. The Statistician 42 (4):461–9. doi: 10.2307/2348478.
- Zhang, M., F. M. Megahed, and W. H. Woodall. 2014. Exponential CUSUM charts with estimated control limits. Quality and Reliability Engineering International 30 (2):275–86. doi: 10.1002/qre.1495.
- Zhang, M., Y. Peng, A. Schuh, F. M. Megahed, and W. H. Woodall. 2013. Geometric charts with estimated control limits. Quality and Reliability Engineering International 29 (2):209–23. doi: 10.1002/qre.1304.
- Zellner, A. 1988. Optimal information processing and Bayes’s theorem. The American Statistician 42 (4):278–80.
Appendix A.
Proof of Theorem 1
For a likelihood being a member of the k-PREF, the conjugate prior is (Bernardo and Smith Citation2000):
where
is the
-dimensional vector of the initial prior hyperparameters, such that for the normalizing constant,
it holds:
(for discrete
we replace the integral sign by summation). Then for the historical data
sampled from the same member of the k-PREF as the likelihood,
the power prior will become:
where
is a
-dimensional vector, with
referring to the vector of historical data. Then once the current data
become available, we will be able to derive the posterior distribution of the unknown parameter(s)
using Bayes theorem:
where
is a
-dimensional vector, with
being the observed data. This is a member of exponential family, and specifically of the same distribution form as the initial prior (as expected since we use a conjugate prior).
For (ii) we have that the predictive distribution of a future observable will be given by:
where
a
-dimensional vector, function of the future observable
Note that the vectors
and
refer to the respective sufficient statistics for the power prior and the likelihood.
Q.E.D.
Appendix B.
On HPrD regions
We provide the definition of Highest Predictive Density (HPrD), which is used for the sequential tests of PCC. Assume the set Rc which contains the values of the predictive density (or mass) function, which are greater than a threshold c, i.e.:
(B1)
(B1)
The HPrD region will be given by minimizing the absolute difference of a highest predictive probability from a significance level for all the possible values of c. Specifically:
(B2)
(B2)
for the discrete case, we replace the integral sign by summation.
will be the shortest region with the smallest absolute difference from the probability
In other words, it minimizes the Lebesque measure
for continuous cases or the corresponding measure
for discrete cases, where
represents the Dirac delta function.
For continuous distributions the HPrD region is calculated just like the Highest Posterior Density (HPD) region in Bayesian analysis (see for example Carlin and Louis Citation2009), where instead of the posterior, we use the predictive distribution and the minimum value of the absolute difference will be 0. For discrete predictive distributions, typically we will not be able to obtain a region that has the exact coverage probability In this case the HPrD can be obtained by starting from the mode of the predictive distribution and continue adding sequentially the next most probable values of the predictive distribution, until we get sufficiently close (minimizing the absolute difference) to the predetermined coverage level
Algorithm Citation1 provides the details in how to derive the HPrD region for a discrete predictive distribution and provides an illustration.
Figure B1. The HPrD region for continuous (left panel) and discrete (right panel) data.
Algorithm 1. HPrD algorithm for a discrete distribution
1: Set pi the ith decreasing ordered probability of e.g., p1 is the
2: Set i.e., the argument(s) where pi get their values
3: ⊳ initial values
4:
5:
6:
7:
8: while stop = 0
9:
10: if
11:
12:
13:
14: else
15:
16:
We should also note here that in symmetric discrete predictive distributions (like a Beta Binomial with ), the HPrD region might not be unique, as there might exist two regions that achieve the minimum of absolute difference (we can choose at random).
Appendix C.
PCC algorithm
Algorithm 2. PCC algorithm
1: Select the significance level α, based on FWER or ARL0⊳ FAR
2: Choose the data distribution and the conjugate prior density for ⊳ distributions
3: Is FIR-PCC of interest?⊳ FIR
4: YES
5: Determine the parameters f and
6: NO
7: Set f = 1
8: Is prior information available?⊳ initial prior
9: YES
10: Determine the hyperparameters of the initial prior
11: NO
12: Set the initial reference/Jeffeys prior (see , Appendix E)
Table E1. Initial Reference (R) and Jeffreys (J) prior distributions.
13: Are prior data available?⊳ power prior
14: YES
15: Provide the historical data Y and determine
16: NO
17: Set
18: Once the data point xn () arrives, derive the predictive distribution of next observable
19: Derive the HPrD region, obtain
and draw it⊳
20: if ⊳ test
21:
22: goto 18
23: else⊳ alarm!
24: if you do not make a corrective action
25: then goto 21
26: else
27: end
For the Normal – NIG model using the initial reference prior and
we need n = 2 to initiate PCC, while for all other cases PCC starts at after x1 becomes available.
Appendix D.
Proof of Lemma 2
Following Quesenberry (Citation1991a) the Q-chart in all three cases of the Normal distribution, makes use at each data point of the statistic
For PCC we set
eliminating the power prior part regarding the past data (Y) and in each case we set the hyperparameters
so that we have the respective reference prior for the unknown parameter(s). We will show that controlling
statistic is identical to controlling PCC’s standardized predictive residual:
where,
and
are the mean and standard deviation respectively of the predictive distribution of
Denoting by
the inverse of the standard normal CDF and
the Student-t CDF with ν degrees of freedom we get:
Case I: μ unknown, known.
We have: and the reference prior is
Then the predictive distribution will be:
Case II: μ known, unknown.
We have: and the reference prior is
Then the predictive distribution will be:
Transformating the we get:
Case III: μ unknown and unknown.
We have: and the reference prior is
Then the predictive distribution will be:
Transformating again the we get:
For cases II and III, as the functions and
are injective, it is identical to control
or
Q.E.D.
Appendix E.
Guidelines regarding the initial prior elicitation
The big advantage of PCC is the use of typically available prior information, which allows to decrease the uncertainty of the unknown parameter(s) improving the performance (with respect to false alarms and detection power), especially at the early stages. The speed at which this uncertainty decreases is inversely related to the information that the prior distribution carries. When strong opinion about the unknown parameter(s) is available and located accurately (i.e., we have highly informative initial prior placed at the parameter space where the unknown parameter is), then the PCC performance will be optimal (FWER at the nominal level and quite high detection power). Nevertheless, a highly informative prior miss-placed on the parameter space (with respect to where the true unknown
is), will have as result to get an extremely high FAR (until sufficient information from the data moves the posterior to the area where the true
lies). Thus, a general recommendation is to avoid having a highly informative initial prior distribution (to eliminate the risk of inflated false alarms if miss-placed). Wang et al. (Citation2018) developed effective numerical methods for exploring reasonable choices of an informative prior distribution.
From the above it becomes evident that the elicitation of the hyper-parameters play an important role to PCC. There are two different ways that one can proceed: being subjective or objective. In the latter we use non-informative priors and in a sense we leave the data to carry the information. In the former we use a low/medium (but not high) informative prior distribution. Such a prior will carry more information compared to the objective priors (reducing the posterior variability of
) enhancing the PCC performance, especially at the start of the process. Furthermore, as the size of the data increases, the influence of the low/medium information prior is washing-out.
In the case where no prior information for exists, or a user prefers to follow an objective prior approach, then the hyper-parameters determination should be chosen with caution, especially when we do not have historical data to use in a power prior (i.e.,
). Various classes of non-informative priors exist like:
Flat prior: a uniform prior equally weighting all possible values of the unknown parameter.
Jeffreys prior: a prior that is closed under parameter transformations.
Reference prior: a function that maximizes some measure of distance (e.g., Hellinger) or divergence (e.g., Kullback-Leibler) between the posterior and prior, as data become available.
A list of Jeffreys and reference initial priors that can be used for likelihoods that are members of the k-PREF are given in . When we need to choose an “objective” prior we should aim to satisfy the following properties: have the minimal possible influence in the process, do not decrease the reflexes of PCC and attempt to have stable false alarm performance. Based on this proposal we will next provide more specific details along with some guidelines for the likelihoods that studied in the simulation study (i.e., Normal, Poisson, and Binomial).
For the model, we have to carefully determine the parameters of the Inverse Gamma (i.e., a and b). For example, the prior
(which converges to Jeffreys prior as
) gives higher density at values of
which are close to 0. Thus, it becomes very informative, increasing drastically the false alarms especially for large values of
Similar results hold for
and
where the mean of the marginal posterior of
is the MLE and the unbiased estimator respectively. On the other hand, a flatter prior like
may overestimate
reducing the reflexes of PCC. Generally, we recommend to choose a value for the hyper-parameter a > 2, so that the mean and the variance of the prior Inverse Gamma is defined. In different cases, the prior parameters have to be determined carefully.
For the model, the initial prior
seems not to be a good choice. Despite that the posterior mean is the MLE, this prior may increase the number of false alarms, especially when θ3 is close to 0. In that case, if xn = 0, then the HPrD region
will shrink to a short region. In general we found that small values for both of the hyper-parameters c and d (e.g., less than 1/3) tend to affect
in the same manner, even when the prior mean is correctly located.
For model we propose to avoid
which converges to Haldane’s prior (Haldane Citation1932) as
where the posterior mean is equal to the MLE, as we will have inflated false alarms. Also, choosing small values for both of the hyper-parameters a and b (e.g., less than 1/3), especially if θ4 is close to 0 as we will have inflated false alarms (just as we had in the Poisson-Gamma respective case). In contrary, the flat Beta(1, 1), equally weighting all values of θ4, will have the posterior mode to be the MLE and provide weak information, inflating the predictive. Thus, the detection performance of PCC will be affected.
Generally, reference priors (Bernardo Citation1979) and Neutral priors (Kerman Citation2011) provide a stable start to PCC under a total prior ignorance. Our proposal though, when some information about the unknown parameters exists, is to adopt a medium/low volume information prior which will enhance the PCC performance (compared to non-informative choices) and its effect will be removed once a short sequence of data becomes available.