?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Qualitative, more specifically, ordinal data generating processes are common in real-world process control implementations. In this study, a survey of control charts for the sample-based monitoring of independent and identically distributed ordinal data is provided together with critical comparisons of the control statistics, for memory-less Shewhart-type and for memory-utilizing exponentially weighted moving average (EWMA) and cumulative-sum types of control charts. New results and proposals are also provided for process monitoring. Using some real-world quality scenarios from the literature, a simulation study for performance comparisons is conducted, covering sixteen different types of control chart. It is shown that demerit-type charts used in combination with EWMA smoothing generally perform better than the other charts, which may rely on quite sophisticated derivations. A real-world data example for monitoring flashes in electric toothbrush manufacturing is discussed to illustrate the application and interpretation of the control charts in the study.
1. Introduction
Control charts are an important tool of statistical process control (SPC), which are used for monitoring quality-related processes. Most of the SPC literature focuses on the case where the relevant quality characteristics are measured on a quantitative scale, such as real-valued measurements or integer-valued counts (Montgomery Citation2009). Recently, there has been increasing interest in monitoring qualitative data (Weiß Citation2021a). In particular, ordinal data can be found in many SPC applications, i.e., data generated by some random variable X, the range of which consists of finitely many categories exhibiting a natural orderFootnote1. We denote the range of X as with some
where
The monitoring of ordinal data is not only relevant in manufacturing (e.g., severity of a defect) and the service industry (e.g., perceived quality of service), but also in non-industrial areas such as health surveillance (e.g., surgical performance) as well as climatological (e.g., wind force) and environmental applications (e.g., air quality). In the following, we focus on control charts applied to independent and identically distributed (i.i.d.) samples of univariate ordinal data. Note that there are also a few contributions concerning multivariate ordinal data, ordinal time series, or continuous monitoring of individual ordinal observations (see Weiß (Citation2021a) for references). However, as the majority of publications consider sample-based monitoring of i.i.d. ordinal data and to keep the scope of the present study manageable, we concentrate on univariate ordinal samples, while recommending more studies on the aforementioned topics for future research in Section 6.
In Section 2, we introduce the required concepts and notations for this research. In Section 3, we survey (and complement by some new proposals) important types of control charts for i.i.d. ordinal samples, which are classified in the following groups: Section 3.1 presents control charts, where the monitored statistic is a quadratic form in the sample frequencies, with weights being derived from ordinal principles. In Section 3.2, the monitored statistic is a weighted class count, where the weights are either determined based on a demerit scheme, or they follow from some probabilistic reasoning. In Section 3.3, statistics from ordinal data analysis are monitored, such as ordinal dispersion, and Section 3.4 concludes the survey with some references on further approaches that have been proposed in the literature so far. Section 4 provides an extensive performance analysis, where the main charts from Section 3 are compared to each other regarding their average run length (ARL) properties. There, we consider both medium- and high-quality scenarios, where the considered in-control models are inspired by real applications that have previously been reported in the literature. The application and interpretation of the control charts in practice are illustrated by a real-world data example in Section 5, where a manufacturing process of electric toothbrushes is monitored. Finally, Section 6 concludes the article and outlines directions for future research.
2. Basic concepts and notations
In this research, we assume the tth sample of size n > 1 (one may also consider time-varying sample sizes nt) to consist of the i.i.d. ordinal random variables with range
and the different samples are assumed to be mutually independent as well. The stochastic properties of
are fully specified by its probability mass function (PMF),
with
In order to account for the natural order among the categories, it is actually more common to consider the cumulative distribution function (CDF) instead (Agresti Citation2010), given by
with
Note that fd is omitted in f as fd = 1 always holds.
2.1. Basics of process monitoring
We declare the monitored process to be in control as long as it follows the specified in-control distribution, given by and
respectively. If the sample at time
is the first one with distribution being different to
then τ is said to be a change point, and the process is called out of control for
In SPC, a control chart is applied to the samples
by sequentially computing a certain statistic for each sampling time
and these statistics are used to decide about the state of the process: if a statistic exceeds the given control limits (CLs), an alarm is triggered and entails an inspection of the process for a possible out-of-control situation. Obviously, we do not wish to intervene in the process if this is in control (false alarm, i.e., if
), while a true change (
) should be detected as soon as possible. A common way of evaluating a control chart’s performance with respect to these two opposing poles is to compute its ARL for a given scenario, i.e., the mean time until the first alarm is triggered. The ARL should be large if the process is in control, whereas it should be small if the process is out of control. For these and further basics on SPC and control charts, see the textbook by Montgomery (Citation2009).
The fundamental idea behind an ordinal control chart is to compare (sequentially) the information provided by the tth sample to the in-control model as given by
The full information on the sample
in turn, is comprised by the corresponding vectors of frequencies and cumulative frequencies,
and
respectively, where
expresses the number of
in the sample, and
the number of
If the distribution of
is given by
we have
and
Thus, the corresponding vectors of relative (cumulative) frequencies,
and
are unbiased estimators of p and f, respectively. For the control charts considered in this article, the tth statistic is either a function of solely
say
then it constitutes a (memory-less) Shewhart chart, or it is a function of the
being available up to time t, say
then we are concerned with a control chart having an inherent memory. Note that by appropriately modifying g, h, we could equivalently use
or
instead of
to express these statistics. Popular examples for constructing memory-type control charts are the cumulative sum (CUSUM) concept dating back to Page (Citation1954), and the exponentially weighted moving-average (EWMA) concept dating back to Roberts (Citation1959). In the ordinal case, a widely-used approach for generating a memory-type chart is to apply EWMA smoothing to the process of frequency vectors, e.g., to
for given smoothing parameter
one computes
[2.1]
[2.1]
Then, the monitored statistic is computed as for
whereas the corresponding Shewhart version monitors
instead, see Li, Tsung, and Zou (Citation2014); Wang, Su, and Xie (Citation2018); Bai and Li (Citation2021) for such examples. Possible adoptions of the CUSUM approach to the case of ordinal data are described later in Section 3.2.
Remark 2.1.1.
The term “ARL” is not uniquely defined in the literature, but there are competing approaches, see Knoth (Citation2006). The default concept is the zero-state ARL, where it is assumed that the possible process change happens with the start of process monitoring, i.e., τ = 1. Other concepts such as the steady-state ARL assume a delayed change point. In this research, we are concerned with independent samples Consequently, if applying a Shewhart-type chart to
then all these ARL concepts coincide. For memory-type control charts, the obtained ARL values usually differ. But, it is widely known that the well-established CUSUM and EWMA charts lead to only modest differences with no practical implications in the independence scenario considered here. Therefore, in what follows, we focus on zero-state ARLs and omit a discussion of further ARL concepts.
2.2. Parametric models for ordinal data
For performance analyses of control charts, it is useful to have parametric models for an ordinal random variable X, which allows for modifications of the relevant distributional properties, such as the location or dispersion of X. There are only few “direct” proposals on parametric distributions for the ordinal X; instead, it is more common to derive an ordinal distribution from either an underlying discrete count distribution, or from a continuous real-valued distribution. A tailor-made proposal for the ordinal X is the “λ-μ-distribution” of (Kvålseth Citation2011a, Section 5), which is defined as
[2.2]
[2.2]
for
It comprises the most relevant extreme scenarios for qualitative random variables:
the one-point distribution
λ = 1: the uniform distribution
μ = 1 and λ = 0: the extreme two-point distribution (polarized distribution)
Also, the “Lehmann approach” (Lehmann Citation1953; Klein and Doll Citation2021) should be mentioned as a possibility for achieving parametric ordinal models: starting from some baseline CDF f, one considers the CDF with component-wise exponent
But as mentioned before, it is more common to derive a parametric model for the ordinal X from some underlying quantitative model. One such approach was referred to as rank counts by Weiß (Citation2020), where the probabilities in p are assumed to be equal to those of a chosen parametric distribution for bounded counts with range
such as a binomial (Bin), beta-binomial (BB), or k-inflated binomial (k-IB) distribution with upper bound d. Thus, the shape of p is controlled by one or two parameters. This can be formalized by writing X = sI, where the random rank count I follows a discrete bounded-counts distribution. For example, if
with
and
then this implies that
[2.3]
[2.3]
where
denotes the indicator function, which equals 1 (0) if A is true (false). Note that (2.3) reduces to the PMF of
if ω = 0. As an example, if k = 0 (zero inflation), then we get the one-point distribution
for ω = 1, while
and π = 1 leads to the extreme two-point distribution.
Another approach to derive a parametric model for the ordinal X is the assumption of a real-valued latent variable Q (Agresti Citation2010, p. 11), which follows a specified continuous distribution; let denote the corresponding CDF. Then, threshold parameters
have to be specified, and one defines
[2.4]
[2.4]
Popular choices for FQ are the (standard) logistic (Log) or normal (N) distribution, leading to the ordered logit or probit model, respectively. While Q is typically assumed to exist only virtually (thus “latent”), there are some applications where Q also has a physical meaning, e.g., if grouped data resulting from gauging are used instead of exact measurements, see Steiner, Geyer, and Wesolowsky (Citation1994, Citation1996a,Citation1996b).
3. Control charts for ordinal samples
This section provides a broad survey of existing control charts for i.i.d. ordinal samples, supplemented by a few new results and proposals. Doing this, we identified groups of more general monitoring concepts and classified the control charts into these groups. As the groups are not perfectly disjoint, we shall point out if a control chart could be assigned to another group as well.
3.1. Ordinal quadratic-form statistics
One of the earliest proposals for the monitoring of i.i.d. qualitative samples is a Shewhart-type control chart relying on Pearson’s goodness-of-fit (GoF) statistic
[3.1]
[3.1]
The second representation shows that constitutes a particular type of quadratic form in
or
respectively. The idea of monitoring
can be traced back to (Shewhart Citation1931, p. 329), while the first comprehensive discussion appears to be in Duncan (Citation1950). Ordinal applications of [Equation3.1
[3.1]
[3.1] ] are presented by Marcucci (Citation1985); Wardell and Candia (Citation1996); Edwards, Govindaraju, and Lai (Citation2007); Samimi, Aghaie, and Tarokh (Citation2010). Obviously, [Equation3.1
[3.1]
[3.1] ] is not limited to ordinal data, but can be used for qualitative data in general. However, its application to specifically ordinal data can be justified as detailed in Appendix B. There, it is shown that
can be equivalently expressed as a quadratic form in the CDF
see (B.1), which, as explained in Section 2, accounts for the natural order among the categories through the accumulation. In other words: even if one defines the quadratic-form statistic (B.1) in an explicitly ordinal manner, we end up with the traditional Pearson statistic [Equation3.1
[3.1]
[3.1] ] anyway.
To establish a closer connection to ordinal data, the Pearson statistic [Equation3.1[3.1]
[3.1] ] can be extended to a weighted quadratic-form statistic, where the weights account for the ordering among the categories. This was proposed by Wang, Su, and Xie (Citation2018), whose average cumulative data (ACD) chart relies on
[3.2]
[3.2]
where V denotes a given weight matrix. Obviously, the Pearson statistic [Equation3.1
[3.1]
[3.1] ] follows if choosing
Wang, Su, and Xie (Citation2018) suggest to use
with weight vector w, where L has a triangular structure: the lower (upper) triangle is filled with 2 (0), and the main diagonal with 1. In this case, setting
calculates as
[3.3]
[3.3]
i.e., it is a quadratic form in the average cumulative proportions
the so-called “ridits” (Agresti Citation2010, p. 10). This artificial word was created by Bross (Citation1958) in analogy to “logit” and “probit” (recall Section 2.2), where “rid” expresses “relative to an identified distribution”. The weight vector w might simply be chosen as
(Wang, Su, and Xie Citation2018, p. 119) if there is no reason for a more sophisticated weighting scheme.
Another weighted quadratic-form scheme is the univariate location-scale ordinal (ULSO) control chart recently proposed by Bai and Li (Citation2021), where the weights are derived from the latent-variable approach [Equation2.4[2.4]
[2.4] ]. It can be expressed as that ACD chart [Equation3.2
[3.2]
[3.2] ], where
[3.4]
[3.4]
If using the cumulative logit approach as recommended by (Bai and Li Citation2021, p. 941), the -matrix
has the entries
where
with
Thus, the “location scores”
again rely on ridits, whereas the structure of the “scale scores”
is a consequence of the cumulative logit approach (remind Section 2.2). Note that [Equation3.4
[3.4]
[3.4] ] is well defined only if
and that the ULSO statistic reduces to the ordinary Pearson statistic [Equation3.1
[3.1]
[3.1] ] if d = 2; see Appendix C for details. Thus, non-trivial ULSO charts are only available if
(i.e., if the range of X consists of at least four categories).
Finally, let us recall that the Shewhart versions of the quadratic-form control charts [Equation3.1[3.1]
[3.1] ] to [Equation3.4
[3.4]
[3.4] ] are easily equipped with an inherent memory by substituting the raw frequencies
by the smoothed frequencies
according to [Equation2.1
[2.1]
[2.1] ]. This was suggested by Wang, Su, and Xie (Citation2018); Bai and Li (Citation2021) for their ACD and ULSO charts, respectively, but it can also be applied to the Pearson statistic [Equation3.1
[3.1]
[3.1] ] as well as to the Shewhart-type charts being discussed in later sections.
3.2. Statistics based on weighted class counts
Several control charts rely on a type of weighted class count, i.e., a statistic of the form
[3.5]
[3.5]
which is plotted against a lower and upper CL (LCL and UCL, respectively). Statistic [Equation3.5
[3.5]
[3.5] ] corresponds to taking the sample sum after having transformed the original ordinal range
into a range of numerical scores,
There are two common ways of choosing the scores in practice: one may define the scores based on probabilistic arguments, as detailed below, or one chooses the scores based on “external reasoning”, which is first discussed in the present section. In a quality context, such scores are typically chosen to express the severity of defects, leading to a demerit control chart. Such demerit charts date back to Dodge (Citation1928); Dodge and Torrey (Citation1956) and have been further investigated by, among others, Jones, Woodall, and Conerly (Citation1999) and (Montgomery Citation2009, Section 7.3.3). In the latter two references, the default example refers to
levels of defect, ranging from class D (“not serious”) to A (“very serious”) with corresponding demerit values
Another example is reported by Nembhard and Nembhard (Citation2000), where
classes of nonconformity (minor, major, critical) are assigned the scores 1, 3, 10. Finally, in Wardell and Candia (Citation1996), the scores regarding customer satisfaction are simply chosen as the integers
(Likert scale) — this particular choice shall be discussed again in Section 3.3.
Although common in practice, the approach of choosing numerical scores for ordinal data (and thus implicitly using a metric scale) is criticized by (Agresti Citation2010, p. 10), because “often, an appropriate choice of scores is unclear” and the obtained outcome might be sensitive to the actual choice of the scores. Applied to the context of SPC, the question arises if there is a notable effect of this choice on the ARL performance of the demerit chart [Equation3.5[3.5]
[3.5] ].
Therefore, an alternative approach is to derive the weights in [Equation3.5
[3.5]
[3.5] ] from probabilistic principles. There are several suggestions in the literature on how to choose these scores in this way. The so-called simple ordinal categorical (SOC) chart of Li, Tsung, and Zou (Citation2014) plots the absolute values of [Equation3.5
[3.5]
[3.5] ], where the weights vj are related to the ridits of the in-control distribution:
[3.6]
[3.6]
Obviously, the SOC chart [Equation3.6[3.6]
[3.6] ] is related to the ACD chart [Equation3.3
[3.3]
[3.3] ] and the ULSO chart [Equation3.4
[3.4]
[3.4] ], although these monitor quadratic-form statistics based on weighted class counts. Recall that [Equation3.5
[3.5]
[3.5] ] to [Equation3.6
[3.6]
[3.6] ] are easily combined with the EWMA smoothing [Equation2.1
[2.1]
[2.1] ] as well. Also the (nominal) control chart proposed by Perry (Citation2020) should be mentioned here, where the weights vj in [Equation3.5
[3.5]
[3.5] ] are equal to
for
in analogy to the Pearson statistic [Equation3.1
[3.1]
[3.1] ]. Furthermore, Perry (Citation2020) uses an EWMA approach, where the EWMA smoothing is not applied to the frequency vectors as in [Equation2.1
[2.1]
[2.1] ], but to a standardized version of the weighted class count [Equation3.5
[3.5]
[3.5] ].
Some control charts with probabilistically weighted class counts are inspired by a log-likelihood ratio (log-LR) approach. By contrast to the previous charts, not only the in-control distribution has to be specified, but also a relevant out-of-control scenario, say
Here, one can account for the ordinal nature of the data by choosing
with respect to a parametric ordinal model, recall Section 2.2. In Steiner, Geyer, and Wesolowsky (Citation1994, Citation1996a,Citation1996b), for instance, a latent-variable approach [Equation2.4
[2.4]
[2.4] ] is used. As an example, the threshold parameters
could be chosen such that
arises from a standard normal distribution,
and
is computed from the same
but for
with some anticipated
Analogously, if using a rank-count approach like in [Equation2.3
[2.3]
[2.3] ], one may use
to distinguish
from
Then, Steiner, Geyer, and Wesolowsky (Citation1994, Citation1996a) propose a (one- or two-sided) Shewhart monitoring of the log-LR statistics
[3.7]
[3.7]
while Steiner, Geyer, and Wesolowsky (Citation1996b); Ryan, Wells, and Woodall (Citation2011) consider a corresponding upper-sided CUSUM control chart:
[3.8]
[3.8]
As a related approach, we propose to adapt the concept of the Shiryaev–Roberts (SR) control chart (Shiryaev Citation1961; Roberts Citation1966) to the case of ordinal data. Together with its recursive implementation is given by
[3.9]
[3.9]
where the design recommendations of Ottenstreuer (Citation2022) are useful for the practical implementation of the SR chart.
3.3. Ordinal statistics
For monitoring quantitative real-valued processes, it is common to focus on relevant stochastic properties such as the process’ mean (e.g., -chart) or variance (e.g., S2-chart), see Montgomery (Citation2009). Accordingly, it would be natural to apply analogous approaches also to ordinal samples data. Surprisingly, control charts based on such ordinal statistics have been rarely addressed in the literature so far. Let us start with a brief summary about important properties of an ordinal random variable X. The location of X is typically measured in terms of the mode or median, where only the median accounts for the natural order among the states. The mode, by contrast, which is also well-defined for nominal data, might not even be unique. For the dispersion of X, a large variety of measures have been proposed in the literature, see Kvålseth (Citation2011b) for a survey. As explained in Section 2.2, a crucial requirement for such ordinal dispersion measures is that any one-point distribution is mapped on the minimal value of the measure’s range, and the extreme two-point distribution on the maximal value. Probably the most well-known example is given by the index of ordinal variation,
which has the range
Finally, also measures of ordinal skewness are important for practice (whereas skewness is not meaningful for nominal data), such as those discussed by Klein and Doll (Citation2021). A simple example is given by
with range
where
is attained for a symmetric distribution, i.e., if
for
At first glance, it appears reasonable to simply monitor the sample counterparts of the aforementioned measures on a control chart. However, as the range of X is often quite small (low value of d), it will be difficult in practice to design a control chart based on the sample median or mode. Thus, for monitoring location, alternatives like the SOC chart [Equation3.6[3.6]
[3.6] ] appear to be more promising. Control charts for ordinal dispersion, by contrast, are more easily implemented, and as explained by Weiß (Citation2021a), they are indeed particularly relevant for quality-related applications. Assume, for example, that s0 refers to the best quality, and increasing states
refer to increasing quality deteriorations. For a well-set process, the in-control probability for s0 should be larger than the remaining probabilities (mode s0), and
should be reasonably close to the one-point distribution in s0 (low dispersion). Quality deteriorations will move probability mass from s0 to states
such that the ordinal dispersion increases. Thus, monitoring for increases in dispersion appears to be relevant for many SPC applications. Accordingly, Bashkansky and Gadrich (Citation2011); Weiß (Citation2021a) use the sample IOVs computed as
[3.10]
[3.10]
which can also be combined with the EWMA smoothing [Equation2.1
[2.1]
[2.1] ] for achieving a memory-type chart. The monitoring of alternative (sample) dispersion measures, such as those in Kvålseth (Citation2011b), has not been investigated so far. Also a control chart based on an ordinal skewness measure (Klein and Doll Citation2021), such as
[3.11]
[3.11]
could be a relevant option. If
is close to the one-point distribution in s0, we are concerned with strong positive skewness, and this gets reduced by quality deteriorations. At this point, an important relation to the demerit chart [Equation3.5
[3.5]
[3.5] ] in Section 3.2 should be pointed out. For the rank-count variable I with range
and CDF f, recall the discussion in Section 2.2, it is well known that its mean can be expressed as
This result is commonly referred to as the “alternative expectation formula”; an early reference is (Karlin and Taylor Citation1975, p. 33). It can be used to rewrite [Equation3.11
[3.11]
[3.11] ] as
Hence, the -chart is equivalent to a demerit chart with linear weighting scheme, such as the integer weights
suggested by Wardell and Candia (Citation1996). This, in turn, implies that these particular demerit weights can be justified probabilistically as accounting for the ordinal skewness of X.
3.4. Miscellaneous approaches
For the sake of completeness, we provide information and references on some further control charts for ordinal data, although these are not considered for our simulation study in Section 4. The “p-tree method” of Duran and Albin (Citation2009), for example, monitors conditional (ordinal) events of the form This is achieved by running d control charts simultaneously, which plot the statistics
[3.12]
[3.12]
But as our focus is on univariate control charts, we do not further consider the p-tree method here.
Tucker, Woodall, and Tsui (Citation2002) assume the ordinal data to follow a latent-variable model, recall (2.4), with location parameter μ. Their control chart plots the statistics where
is the maximum likelihood estimate of μ computed from the tth sample, and
the estimated asymptotic standard error of
While theoretically appealing, the practical implementation is demanding as
is computed by numerical methods.
Franceschini and Romano (Citation1999) consider ordinal variables being evaluated on a linguistic scale. For the tth sample, the so-called “ordered weighted average” is used as a measure of location, and the ordinal range as a measure of dispersion. Then, corresponding Shewhart charts are constructed. But as criticized by Franceschini, Galetto, and Varetto (Citation2005, p. 181), “the dynamics of the charts are poor and little information can be extracted about the process”. Therefore, Franceschini, Galetto, and Varetto (Citation2005) suggested to define an order relation between the ordinal samples according to a specified dominance criterion. Then, the tth sample is ranked according to its position in the ordered sample space, and this information is used for computing the monitored statistic. Here, a finer resolution for the sample statistics is achieved, but the practical difficulty arises from the fact that the size of the sample space (the number of equivalence classes) increases linearly in both d and n. Thus, an implementation appears feasible only for rather low sample sizes.
4. A simulation-based performance analysis
To provide a performance comparison of the control charts [Equation3.1[3.1]
[3.1] ] to [Equation3.11
[3.11]
[3.11] ], where an overview is provided in , we define four different in-control scenarios
for our simulation study that are inspired by real-data examples from the literature; namely from
Table 1. Control charts used in simulation study.
Bashkansky and Gadrich (Citation2011): conditions of patients visiting their Health Maintenance Organization,
Wang, Su, and Xie (Citation2018): quality level of white wine,
Wardell and Candia (Citation1996): patient satisfaction with predischarge information in a hospital,
Li, Tsung, and Zou (Citation2014): quality of manufactured toothbrush heads,
To simplify the subsequent discussion, it is advisable to further classify these scenarios, because some of the control charts [Equation3.1[3.1]
[3.1] ] to [Equation3.11
[3.11]
[3.11] ] implicitly assume a certain shape of the in-control distribution
For example, the IOV chart [Equation3.10
[3.10]
[3.10] ] is tailor-made for detecting increases in dispersion, i.e., it is expected to perform well if quality deteriorations go along with increasing dispersion. This would be the case in a “high-quality situation”, where
is largest among all probabilities in
(i.e., where the mode category corresponds the best quality level; recall that we always arrange the categories in
according to increasing quality deterioration). Also the demerit schemes [Equation3.5
[3.5]
[3.5] ] appear to be well-suited for this case, as they use increasing weights for increasing deterioration. On the other hand, the skew chart [Equation3.11
[3.11]
[3.11] ], for example, might work well also for a roughly symmetrical distribution, i.e., where medium quality levels are most frequent under in-control conditions. We refer to such a case as a “medium-quality situation”, i.e., if the mode category sj satisfies
According to this distinction, the examples of Wardell and Candia (Citation1996) and Li, Tsung, and Zou (Citation2014) are classified as high-quality situations (which are also skewed to the right). The examples of Bashkansky and Gadrich (Citation2011) and Wang, Su, and Xie (Citation2018), by contrast, are medium-quality situations, where the patient data in Bashkansky and Gadrich (Citation2011) are nearly symmetrically distributed, and the wine data of Wang, Su, and Xie (Citation2018) are skewed to the left. Besides simplifying the discussion of the subsequent results, the distinction between high-quality and medium-quality situations is also appealing for practice, as it allows easy entry into the selection of a suitable control chart.
By closely following these real-world applications, we ensure the practical relevance of the considered while their diverse properties shall help to reach a well-founded evaluation of the charts’ performance. To also get meaningful out-of-control situations, we embed these four scenarios into the most common parametric models for ordinal data, recall Section 2.2, namely a rank-counts approach using the
-distribution in [Equation2.3
[2.3]
[2.3] ] as well as the logit and probit latent-variable approaches [Equation2.4
[2.4]
[2.4] ]. While the latter can be adapted to any choice of
(due to having d threshold parameters
), the more parsimonious
-distribution is less flexible. Therefore, the final in-control scenarios are defined by specifying a
-model, namely the medium-quality cases
Scenario 1 (inspired by Bashkansky and Gadrich (Citation2011)):
Scenario 2 (inspired by Wang, Su, and Xie (Citation2018)):
Scenario 3 (inspired by Wardell and Candia (Citation1996)):
Scenario 4 (inspired by Li, Tsung, and Zou (Citation2014)):
The out-of-control choices for p according to the -model are generated by increasing the value of π, see the corresponding blocks in the first column of in Appendix A. In addition, we consider out-of-control p resulting from various (positive) location shifts in the logit and probit implementations of
i.e., where
are chosen to match
for
and
respectively. In this way, we get a variety of out-of-control scenarios (see for an overview), which are not chosen arbitrarily but implied by well-established models for ordinal data. For all four scenarios, the sample size is chosen as n = 100 like in Bai and Li (Citation2021), and we also followed their choice for the EWMA smoothing parameter, namely
Common to all out-of-control p is that they imply a deterioration in quality, such that p is more left-skewed than Thus, the skew chart [Equation3.11
[3.11]
[3.11] ] is designed with a lower control limit, whereas all remaining charts have an upper limit as quality deteriorations lead to an increase in the monitored statistics. Recall that the skew chart is equivalent to a demerit chart with linearly increasing weights
Generally, the idea behind demerit charts is choosing the weights to express the severity of defects, but not according to some probabilistic reasoning. Therefore, we checked the literature for corresponding recommendations (being different from the linear weights behind the skew chart [Equation3.11
[3.11]
[3.11] ] to avoid a duplication of results) to define the charts labeled as “Demerit” in . For d = 2, we found the recommendation of Nembhard and Nembhard (Citation2000) to use 1, 3, 10, and for d = 3 the one of Jones, Woodall, and Conerly (Citation1999); Montgomery (Citation2009) to use
Note that in both cases, the weights increase faster than linearly. For this reason, we also selected super-linear weights for d = 4, namely,
where we did not find a recommendation in the literature. To summarize, while the columns “Skew” in –A.4 refer to demerit schemes with linear weights, the columns “Demerit” are based on super-linear weights.
As the performance measure, we consider the ARL discussed in Section 2.1, which is determined by simulation with 106 replications to ensure a sufficiently good accuracy. The control limits of the charts are adjusted to give an in-control ARL (ARL0) of which is a common target value in the SPC literature. However, due to the discreteness of the observations and, thus, of the monitored statistics, it is usually not possible to meet this value exactly. In a few cases (mainly for the Shewhart version of the skew chart), there are notable deviations from 370, which must be taken into account in the evaluation of the corresponding out-of-control performance. But generally, the actual ARL0-values are very close to 370, see the first segments of . Finally, note that for the CUSUM chart [Equation3.8
[3.8]
[3.8] ] and the SR chart [Equation3.9
[3.9]
[3.9] ], it is also necessary to specify an out-of-control target value
for the PMF, recall Section 3.2. For each scenario, we have chosen
as that PMF p that is implied by a logit model with a small location shift (as both methods are usually used for detecting small changes), namely 0.05 for Scenarios 1–2, 0.04 for 3, and 0.1 for 4.
4.1. ARL performance in medium-quality setting
Let us start our performance analyses with the medium-quality scenarios 1 and 2, where the corresponding ARL values are summarized in . Note that the ARLs of the ULSO chart [Equation3.4[3.4]
[3.4] ] are omitted in , because it is identical to the Pearson statistic [Equation3.1
[3.1]
[3.1] ] for d = 2, recall Appendix C. Furthermore, it is also not surprising that the memory-type charts (EWMA, CUSUM, and SR), all being listed in the lower part (labeled “EWMA”) of , outperform their Shewhart counterparts (upper part).
Recall that the CUSUM and SR charts are designed for according to the logistic distribution with a small location shift. Thus, it is not surprising that the CUSUM chart, due to its known optimality properties, has the lowest ARL at very small deviations from
regardless of the specific generation of p, whereas SR has inferior performance. It is remarkable, however, that the EWMA-type skew chart is most sensitive to changes in every other case of Scenario 1 (and also performs very well in Scenario 2). This can be explained by the fact that
is close to symmetry, and quality deteriorations immediately lead to negative skewness values. Just as clearly, the IOV chart turns out to be the worst choice in Scenario 1, in both the EWMA and Shewhart version. Across all shift types, the chart suffers from the small increase in variation, starting from a symmetric
with already low variation. The performance improves for Scenario 2, although for large changes, the IOV chart still has the worst performance. Thus, the use of the IOV chart for medium-quality settings is not recommended. For small changes, the Shewhart-type ACD chart stands out in , with out-of-control ARLs being larger than the in-control ARL, an unfavorable behavior of a control method. Also X2-, ULSO, and SOC chart most often perform rather poorly. By contrast, the EWMA-type demerit chart (with super-linear scores
) shows very good results for Scenario 2, with similar out-of-control ARLs as the EWMA-skew chart with its linear weights. So it seems that the actual choice of weights is not crucial in Scenario 2, except the fact that the Shewhart version of the demerit chart can be adjusted more closely to the target ARL0. For the perfectly symmetric Scenario 1, the EWMA-skew chart is slightly better than the EWMA demerit one (but the demerit’s Shewhart version again better meets ARL0), which is plausible as its linear weights arise from the measurement of skewness. Generally, the demerit and skew charts do rather well throughout , i.e., the demerit principle proves to be an effective tool for monitoring ordinal medium-quality observations, which is quite striking considering the simplicity of the method and the more or less arbitrary scores. There seems to be only little effect of the actual weighting scheme, as long as the demerit scores increase with increasing quality deterioration. At this point, it is worth noting that the probabilistic weights
used for CUSUM and SR chart, recall [Equation3.7
[3.7]
[3.7] ], are also increasing in j, namely nearly linear in Scenario 1 and super-linear in Scenario 2.
4.2. ARL performance in a high-quality setting
In the medium-quality setting of Section 4.1, we ended up with a surprisingly unique recommendation: although not necessarily being the optimal choice in any shift scenario, both demerit-type charts (especially the EWMA-skew chart) perform very well in any case. Now, let us investigate the ARLs in for the high-quality setting (Scenarios 3–4). First note that still the (EWMA) demerit-type charts are among the best charts in both . This time, however, also the IOV chart turns out to be a strong competitor, which is plausible as a high-quality situation corresponds to low ordinal dispersion, being quickly increased by quality deteriorations. By contrast, the X2-, ACD, ULSO, and SOC charts (especially their EWMA versions) often have clearly larger out-of-control ARLs than the corresponding demerit, skew, and IOV charts. The SR chart is generally worse than the CUSUM chart, and the CUSUM’s performance is quite sensitive to the actual out-of-control scenario: being designed based on logit assumptions (which now leads to sub-linearly increasing weights in both scenarios), it has competing performance under logit and probit specifications, but deteriorates under 0-IB specification. Altogether, the EWMA versions of demerit, skew, and IOV chart perform very well. It is not possible to derive a unique recommendation from this group that is superior in any out-of-control scenario. But it gets clear that any of these charts performs reasonably well in each scenario, even if not being the best choice.
To summarize, although some of the control charts [Equation3.1[3.1]
[3.1] ] to [Equation3.11
[3.11]
[3.11] ] rely on quite sophisticated derivations, quality deteriorations appear to be best detected by using quite basic control statistics: a demerit-type chart (including the skew chart) in combination with EWMA smoothing always shows rather good performance, and for high-quality settings, also the (EWMA-)IOV chart is a good choice for process monitoring. Generally, the use of EWMA smoothing for PMF estimation is recommended: for the out-of-control scenarios in , we did not observe any case where the Shewhart ARL would be lower than the EWMA ARL.
5. An illustrative data example
In this section, we demonstrate the application of the control charts studied in Section 4 by means of a real-data example. We use a data set from manufacturing industry that was presented by Li, Tsung, and Zou (Citation2014), and where the corresponding in-control model was taken as an inspiration for the (high-quality) Scenario 4 in Section 4. Now, let us focus on the Phase-II data for illustration.
The data set consists of 30 samples with a unique sample size of n = 64, where each individual observation expresses the quality of a manufactured electric toothbrush head. Here, the quality is measured in terms of the excess plastic (known as “flash”), which may arise on the brush head when its two components are welded together. The extent of flash is classified into the ordinal categories
and
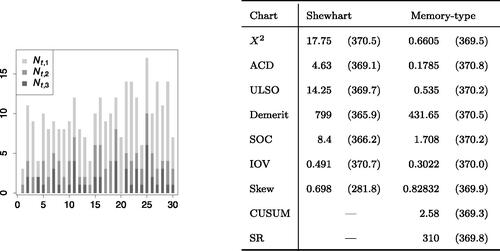
These categories are ordered according to degrading quality, because increasing flash implies a higher risk of injury. (left) shows the sample frequencies
(corresponding to non-optimal quality) as a bar plot, whereas the absolute frequencies
referring to the best quality, result from the difference
On the right-hand side of , the control limits of the charts and their corresponding in-control ARLs are displayed, which are again determined by simulations with 106 replications. This time, the chart designs are based on the exact in-control PMF
as given in Li, Tsung, and Zou (Citation2014) (not on the “smoothed” version used for Scenario 4). Like in Section 4, the Shewhart version of the skew chart is the most inflexible in adjusting its ARL0 to the target value of 370.
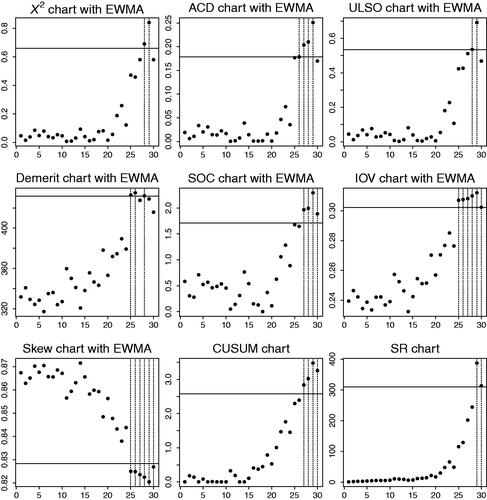
Despite its low ARL0, the skew chart triggers an alarm only at time t = 25, just like the other Shewhart-type charts do, see in Appendix D. In fact, the 25th sample causing the alarm expresses the worst quality among all samples, see (left): the total frequency of non-optimal quality as well as the frequency
of worst quality are maximal for t = 25. However, due to their lack of memory, the Shewhart charts of do not indicate that there seems to be some disturbing trend already before t = 25 (such a trend is also hardly visible from ). This trend gets clear from the memory-type charts in , i.e., if EWMA-smoothing with
is added to the aforementioned charts, or if CUSUM and SR charts are considered (defining
by a logit model with location shift 0.1). The statistics of all memory charts start to gradually increase (or decrease in the case of the skew chart) around t = 20. But unlike the Shewhart charts, only three memory charts, namely demerit, IOV, and skew, signal a change already at t = 25. The remaining memory charts trigger their first alarm with a delay between one and four samples. This illustrates the well-known dilemma of memory-type charts: they are able to detect a gradual deterioration or small shift in the process, but they may be slow in recognizing a sudden large shift (such as for t = 25). Shewhart charts, by contrast, typically show the opposite performance and are, thus, uniquely successful in the present data example. It is therefore all the more remarkable that the EWMA versions of the demerit, IOV, and skew chart are as quick as their Shewhart versions. This outstanding performance of the demerit and skew charts is consistent with our general findings in Section 4, and for the IOV chart, it follows from the fact that we are concerned with a high-quality situation (i.e., maximal in-control probability for the best quality level).
Figure 1. Left: Frequencies of flash types
on toothbrush heads, where
Right: Control limits of considered control charts, simulated ARL0 in parentheses.
6. Conclusions and future research
In this paper, we provided an extensive survey of sample-based control charts for monitoring i.i.d. univariate ordinal data. The control charts in the literature were classified into identified groups of control statistics for comparisons and discussions. Some new results and proposals were given to supplement the existing work. A simulation study of the discussed control charts was completed for evaluating and comparing the performance under four diverse in-control scenarios. These four scenarios were inspired by real-world applications from the literature, and they were embedded into common parametric models for ordinal data to get a variety of out-of-control scenarios. Our simulation results indicate that demerit-type charts perform considerably well for monitoring ordinal medium-quality observations, with little influence from the actual weighting scheme. For the high-quality setting scenarios, again the demerit-type charts are among the best performing charts, with the IOV chart being a strong competitor. In conclusion, the demerit principle proves to be very effective in process monitoring applications with ordinal data, and a demerit-type chart (including the skew chart) in combination with the EWMA smoothing is recommended based on the cases studied.
There are several directions for future research on control charts for ordinal processes. First, ordinal control charts for individual observations (rather than samples taken from the process) should be developed. This would not only be relevant for automated production processes with 100% inspection, but also for a second future research direction, the monitoring of ordinal time series data. We conjecture that serial dependence between individual observations (or within samples taken from the process) will impact the performance of control charts being developed for i.i.d. data, such that a revised chart design or novel types of control charts are necessary in such a case. To our knowledge, Li, Xu, and Zhou (Citation2018); Li and Lu (Citation2022) are the only proposals on sequential methods for ordinal time series up to now. More articles are available on the monitoring of multivariate ordinal data, see Wang, Li, and Su (Citation2017); Bai and Li (Citation2021); Hakimi et al. (Citation2021) and the references therein, but an extensive comparative study is yet missing. Finally, as real-world ordinal time series often exhibit missing data, see Weiß (Citation2021b), it would be interesting to discuss how control charts should be adapted to account for missingness.
Acknowledgments
The authors thank the two referees for their useful comments on an earlier draft of this article. The authors are grateful to Professor Jian Li (Xi’an Jiaotong University, China) for providing the flash data discussed in Section 5.
Data availability statement
The data that support the findings of this study are available from the corresponding author, C.H. Weiß, upon reasonable request.
Disclosure statement
The authors report no conflict of interest.
Additional information
Funding
Notes
1 Another type of qualitative data, which is not considered here, are nominal data, where we do not have such a natural order; corresponding SPC references can be found in Weiß (Citation2021a).
References
- Agresti, A. 2010. Analysis of Ordinal Categorical Data. 2nd edition. Hoboken, New Jersey: John Wiley & Sons, Inc.
- Bai, K., and J. Li. 2021. Location-scale monitoring of ordinal categorical processes. Naval Research Logistics (NRL) 68 (7):937–50. doi: 10.1002/nav.21973.
- Bashkansky, E., and T. Gadrich. 2011. Statistical quality control for ternary ordinal quality data. Applied Stochastic Models in Business and Industry 27 (6):586–99. doi: 10.1002/asmb.868.
- Bross, I. D. J. 1958. How to use ridit analysis. Biometrics 14 (1):18–38. doi: 10.2307/2527727.
- Dodge, H. F. 1928. A method of rating manufactured product. Bell System Technical Journal 7 (2):350–68. doi: 10.1002/j.1538-7305.1928.tb01229.x.
- Dodge, H.F., Torrey, M.N. 1956. A check inspection and demerit rating plan. Journal of Quality Technology 9(3), 146–153.
- Duncan, A. J. 1950. A chi-square chart for controlling a set of percentages. Industrial Quality Control 7:11–5.
- Duran, R. I., and S. L. Albin. 2009. Monitoring and accurately interpreting service processes with transactions that are classified in multiple categories. IIE Transactions 42 (2):136–45. doi: 10.1080/07408170903074908.
- Edwards, H. P., K. Govindaraju, and C. D. Lai. 2007. A control chart procedure for monitoring university student grading. International Journal of Services Technology and Management 8 (4/5):344–54. doi: 10.1504/IJSTM.2007.013924.
- Franceschini, F., and D. Romano. 1999. Control chart for linguistic variables: A method based on the use of linguistic quantifiers. International Journal of Production Research 37 (16):3791–801. doi: 10.1080/002075499190059.
- Franceschini, F., M. Galetto, and M. Varetto. 2005. Ordered samples control charts for ordinal variables. Quality and Reliability Engineering International 21 (2):177–95. doi: 10.1002/qre.614.
- Hakimi, A., H. Farughi, A. Amiri, and J. Arkat. 2021. Phase II monitoring of the ordinal multivariate categorical processes. Advances in Industrial Engineering 55 (3):249–67.
- Jones, L. A., W. H. Woodall, and M. D. Conerly. 1999. Exact properties of demerit control charts. Journal of Quality Technology 31 (2):207–16. doi: 10.1080/00224065.1999.11979915.
- Karlin, S., and H. M. Taylor. 1975. A First Course in Stochastic Processes. 2nd edition. New York: Academic Press.
- Kiesl, H. 2003. Ordinale Streuungsmaße—Theoretische Fundierung und statistische Anwendungen (in German). Lohmar, Cologne: Josef Eul Verlag.
- Klein, I., and M. Doll. 2021. Tests on asymmetry for ordered categorical variables. Journal of Applied Statistics 48 (7):1180–98. doi: 10.1080/02664763.2020.1757045.
- Knoth, S. 2006. The art of evaluating monitoring schemes—How to measure the performance of control charts?. In Frontiers in Statistical Quality Control 8, eds. H.-J. Lenz & P.-T. Wilrich, 74–99. Heidelberg: Physica-Verlag.
- Kvålseth, T. O. 2011a. The lambda distribution and its applications to categorical summary measures. Advances and Applications in Statistics 24 (2):83–106.
- Kvålseth, T. O. 2011b. Variation for categorical variables. In International Encyclopedia of Statistical Science, ed. M. Lovric, 1642–5. Berlin: Springer.
- Lehmann, E. L. 1953. The power of rank tests. The Annals of Mathematical Statistics 24 (1):23–43. doi: 10.1214/aoms/1177729080.
- Li, M., and Q. Lu. 2022. Changepoint detection in autocorrelated ordinal categorical time series. Environmetrics 33 (7):e2752. doi: 10.1002/env.2752.
- Li, J., F. Tsung, and C. Zou. 2014. A simple categorical chart for detecting location shifts with ordinal information. International Journal of Production Research 52 (2):550–62. doi: 10.1080/00207543.2013.838329.
- Li, J., J. Xu, and Q. Zhou. 2018. Monitoring serially dependent categorical processes with ordinal information. IISE Transactions 50 (7):596–605. doi: 10.1080/24725854.2018.1429695.
- Marcucci, M. 1985. Monitoring multinomial processes. Journal of Quality Technology 17 (2):86–91. doi: 10.1080/00224065.1985.11978941.
- Montgomery, D. C. 2009. Introduction to Statistical Quality Control. 6th edition. New York: John Wiley & Sons, Inc.
- Nembhard, D. A., and H. B. Nembhard. 2000. A demerits control chart for autocorrelated data. Quality Engineering 13 (2):179–90. doi: 10.1080/08982110108918640.
- Ottenstreuer, S. 2022. The Shiryaev–Roberts control chart for Markovian count time series. Quality and Reliability Engineering International 38 (3):1207–25. doi: 10.1002/qre.2945.
- Page, E. 1954. Continuous inspection schemes. Biometrika 41 (1-2):100–15. doi: 10.1093/biomet/41.1-2.100.
- Perry, M. B. 2020. An EWMA control chart for categorical processes with applications to social network monitoring. Journal of Quality Technology 52 (2):182–97. doi: 10.1080/00224065.2019.1571343.
- Roberts, S. W. 1959. Control chart tests based on geometric moving averages. Technometrics 1 (3):239–50. doi: 10.1080/00401706.1959.10489860.
- Roberts, S. W. 1966. A comparison of some control chart procedures. Technometrics 8 (3):411–30. doi: 10.1080/00401706.1966.10490374.
- Ryan, A. G., L. J. Wells, and W. H. Woodall. 2011. Methods for monitoring multiple proportions when inspecting continuously. Journal of Quality Technology 43 (3):237–48. doi: 10.1080/00224065.2011.11917860.
- Samimi, Y., A. Aghaie, and M. J. Tarokh. 2010. Analysis of ordered categorical data to develop control charts for monitoring customer loyalty. Applied Stochastic Models in Business and Industry 26 (6):668–88. doi: 10.1002/asmb.808.
- Shewhart, W. A. 1931. Economic Control of Quality of Manufactured Product. New York: D. Van Nostrand Company, Inc.
- Shiryaev, A. N. 1961. The problem of the most rapid detection of a disturbance in a stationary process. Soviet Mathematics: Doklady 2:795–9.
- Steiner, S. H., P. L. Geyer, and G. O. Wesolowsky. 1994. Control charts based on grouped observations. International Journal of Production Research 32 (1):75–91. doi: 10.1080/00207549408956917.
- Steiner, S. H., P. L. Geyer, and G. O. Wesolowsky. 1996a. Shewhart control charts to detect mean and standard deviation shifts based on grouped data. Quality and Reliability Engineering International 12 (5):345–53. doi: 10.1002/(SICI)1099-1638(199609)12:5<345::AID-QRE11>3.0.CO;2-M.
- Steiner, S. H., P. L. Geyer, and G. O. Wesolowsky. 1996b. Grouped data-sequential probability ratio tests and cumulative sum control charts. Technometrics 38 (3):230–7. doi: 10.1080/00401706.1996.10484502.
- Tucker, G. R., W. H. Woodall, and K.-L. Tsui. 2002. A control chart method for ordinal data. American Journal of Mathematical and Management Sciences 22 (1-2):31–48. doi: 10.1080/01966324.2002.10737574.
- Wang, J., J. Li, and Q. Su. 2017. Multivariate ordinal categorical process control based on log-linear modeling. Journal of Quality Technology 49 (2):108–22. doi: 10.1080/00224065.2017.11917983.
- Wang, J., Q. Su, and M. Xie. 2018. A univariate procedure for monitoring location and dispersion with ordered categorical data. Communications in Statistics - Simulation and Computation 47 (1):115–28. doi: 10.1080/03610918.2017.1280159.
- Wardell, D. G., and M. R. Candia. 1996. Statistical process monitoring of customer satisfaction survey data. Quality Management Journal 3 (4):36–50. doi: 10.1080/10686967.1996.11918757.
- Weiß, C. H. 2020. Distance-based analysis of ordinal data and ordinal time series. Journal of the American Statistical Association 115 (531):1189–200. doi: 10.1080/01621459.2019.1604370.
- Weiß, C. H. 2021a. On approaches for monitoring categorical event series. In Control Charts and Machine Learning for Anomaly Detection in Manufacturing, Springer Series in Reliability Engineering, ed. K.P. Tran, 105–29. Cham: Springer Nature Switzerland AG.
- Weiß, C. H. 2021b. Analyzing categorical time series in the presence of missing observations. Statistics in Medicine 40 (21):4675–90. doi: 10.1002/sim.9089.
Appendix A.
Tabulated ARL results of Section 4
Table A.1. Scenario 1: ARL performance of control charts [Equation3.1[3.1]
[3.1] ] to [Equation3.11
[3.11]
[3.11] ].
Table A.2. Scenario 2: ARL performance of control charts [Equation3.1[3.1]
[3.1] ] to [Equation3.11
[3.11]
[3.11] ].
Table A.3. Scenario 3: ARL performance of control charts [Equation3.1[3.1]
[3.1] ] to [Equation3.11
[3.11]
[3.11] ].
Table A.4. Scenario 4: ARL performance of control charts [Equation3.1[3.1]
[3.1] ] to [Equation3.11
[3.11]
[3.11] ].
Table A.5. In-control and out-of-control PMFs for Scenarios 1–4.
Appendix B.
On a CDF-based Pearson-type GoF-Statistic
Let X be an ordinal random variable with PMF p such that for all
(otherwise, the range
could be reduced by removing the categories with probability zero); as before, let f be the corresponding CDF. If the sample CDF
is computed from n i.i.d. replicates of X, then its asymptotic distribution is known from (Kiesl Citation2003, p. 99): we have
where the covariance matrix
has the entries
Thus, a Pearson-type GoF-statistic based on the sample CDF, as well as its asymptotic distribution, are immediately implied as
(B.1)
(B.1)
provided that
exists. In what follows, we show that this CDF-based statistic
is indeed identical to the ordinary Pearson statistic
from (3.1).
Lemma B.1.
If for all
, then the inverse matrix
exists and is symmetric, i.e., sij = sji. Its entries sij for
are given by
Here, it is understood that if d = 1.
Note that is a (symmetric) tridiagonal matrix according to Lemma B.1.
Proof.
We prove Lemma B.1 by showing that the given expression for satisfies
where I denotes the d × d-identity matrix. If d = 1, then
If d = 2, then
For the entries of
namely
for
consist of at most three summands because of the tridiagonal structure of
This happens if
whereas
leads to two summands of the same structure as in the case d = 2. Thus, let us focus on
It remains to distinguish between diagonal (i = j) and non-diagonal () elements:
This completes the proof of Lemma B.1. □
Using Lemma B.1, we can calculate the statistic according to (B.1).
Theorem B.2.
If for all
, then the statistic
according to (B.1) equals
Proof.
Using the notations of Lemma B.1, we compute
Using the index transformation and applying the binomial formula, it follows that
This completes the proof of Theorem B.2. □
Appendix C.
Some notes on the ULSO chart
In what follows, let us abbreviate
Proposition C.1.
If d = 1, then the matrix in (3.4) is not invertible.
Proof.
If d = 1, then and
recall that generally, we have
Hence,
Thus, it follows that
But the latter matrix has determinant 0 and is, thus, not invertible. □
Proposition C.2.
If d = 2, then the ULSO statistic (3.4) agrees with the Pearson statistic (3.1).
Proof.
If d = 2, then and
Thus,
and
This time, equals
and has the non-zero determinant
Defining E as the matrix of ones, after tedious calculations, we can express in (3.4) as
As it follows that
such that
is equal to statistic (3.1). □
Appendix D.
Phase-II control charts of section 5
Figure D.1. Shewhart control charts applied to flash data, where alarm times highlighted by dashed line.
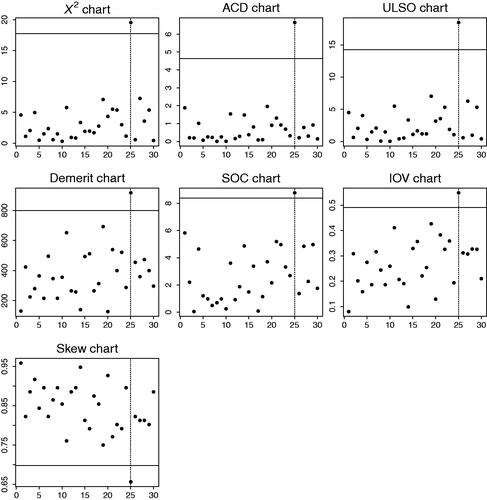
Figure D.2. Memory-type control charts (EWMA version of charts from , or CUSUM and SR) for flash data, where alarm times highlighted by dashed line.