
Abstract
Theoretical models specifying indirect or mediated effects are common in the social sciences. An indirect effect exists when an independent variable's influence on the dependent variable is mediated through an intervening variable. Classic approaches to assessing such mediational hypotheses (CitationBaron & Kenny, 1986; CitationSobel, 1982) have in recent years been supplemented by computationally intensive methods such as bootstrapping, the distribution of the product methods, and hierarchical Bayesian Markov chain Monte Carlo (MCMC) methods. These different approaches for assessing mediation are illustrated using data from Dunn, Biesanz, Human, and Finn (2007). However, little is known about how these methods perform relative to each other, particularly in more challenging situations, such as with data that are incomplete and/or nonnormal. This article presents an extensive Monte Carlo simulation evaluating a host of approaches for assessing mediation. We examine Type I error rates, power, and coverage. We study normal and nonnormal data as well as complete and incomplete data. In addition, we adapt a method, recently proposed in statistical literature, that does not rely on confidence intervals (CIs) to test the null hypothesis of no indirect effect. The results suggest that the new inferential method—the partial posterior p value—slightly outperforms existing ones in terms of maintaining Type I error rates while maximizing power, especially with incomplete data. Among confidence interval approaches, the bias-corrected accelerated (BC a ) bootstrapping approach often has inflated Type I error rates and inconsistent coverage and is not recommended; In contrast, the bootstrapped percentile confidence interval and the hierarchical Bayesian MCMC method perform best overall, maintaining Type I error rates, exhibiting reasonable power, and producing stable and accurate coverage rates.
Notes
1We treat the predictors in Equations (1) and (2) as random rather than fixed. Even if X is fixed (i.e., as in an experimental design), Equation (2) has a random predictor M, as defined by Equation (1).
2Note that there is a potential dependency due to couples present in this design that had no material impact on the analysis. We ignore it here in the interest of simplicity. All coefficients reported here are unstandardized.
3The prior distribution used to generate this posterior distribution is π(μ
M
,μ
X
,σ
M
,σ
X
,ρ
XM
) ∝ ![]() (see CitationBerger & Sun, 2008, pp. 972–974). Intervals on the posterior distribution generated by Equation (6) exactly correspond to CIs (see CitationBiesanz, 2010). Technically an interval based on the Bayesian perspective is referred to as a credible interval; probability statements under a Bayesian perspective have a different philosophical interpretation as well. For more extensive discussion of the differences between these perspectives see CitationBayarri and Berger (2004).
(see CitationBerger & Sun, 2008, pp. 972–974). Intervals on the posterior distribution generated by Equation (6) exactly correspond to CIs (see CitationBiesanz, 2010). Technically an interval based on the Bayesian perspective is referred to as a credible interval; probability statements under a Bayesian perspective have a different philosophical interpretation as well. For more extensive discussion of the differences between these perspectives see CitationBayarri and Berger (2004).
4All these values were empirically estimated based on 1,000,000 random samples from each population.
5We introduce Pplug
, Ppost
, and Pppost
where the null is referenced with respect to β for didactic purposes to introduce the concepts. Determining p values as presented would require specification of the population variance. Consequently actual estimation and determination of p values is based on test statistics and noncentrality parameters. In other words the indirect effect estimate is ta
* 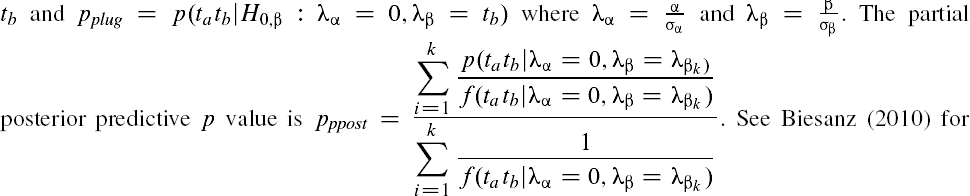 computational formulae for the posterior distribution of the noncentrality parameter based on fixed and random predictors.
computational formulae for the posterior distribution of the noncentrality parameter based on fixed and random predictors.
6R code for each approach is available from Jeremy C. Biesanz upon request.
7We did not employ the strictly statistical criterion of testing whether the observed Type I error rate is significantly different from .05 because the null hypothesis that this is so is a priori false due to the difficult nature of the data (incomplete and/or nonnormal data, small samples) and the fact that all studied methods are approximations.