
Abstract
Latent variable models with many categorical items and multiple latent constructs result in many dimensions of numerical integration, and the traditional frequentist estimation approach, such as maximum likelihood (ML), tends to fail due to model complexity. In such cases, Bayesian estimation with diffuse priors can be used as a viable alternative to ML estimation. This study compares the performance of Bayesian estimation with ML estimation in estimating single or multiple ability factors across 2 types of measurement models in the structural equation modeling framework: a multidimensional item response theory (MIRT) model and a multiple-indicator multiple-cause (MIMIC) model. A Monte Carlo simulation study demonstrates that Bayesian estimation with diffuse priors, under various conditions, produces results quite comparable with ML estimation in the single- and multilevel MIRT and MIMIC models. Additionally, an empirical example utilizing the Multistate Bar Examination is provided to compare the practical utility of the MIRT and MIMIC models. Structural relationships among the ability factors, covariates, and a binary outcome variable are investigated through the single- and multilevel measurement models. The article concludes with a summary of the relative advantages of Bayesian estimation over ML estimation in MIRT and MIMIC models and suggests strategies for implementing these methods.
Notes
1The ML estimation of six-dimensional single-level IRT models took more than a month using a modern personal computer with 174 available binary items and approximately 3,000 random participants and resulted in nonconvergence or Heywood cases. In contrast, the Bayesian estimation with diffuse priors took less than a day and produced successful results for the same model.
2There are several alternative algorithms and computer programs, such as IRTPRO (CitationCai, Thissen, & du Toit, 2011) and flexMIRT (CitationCai, 2012), for the ML estimation of MIRT models; however, they are not considered in this study.
3The comparison of structural relationship estimates using the MBE data between the two measurement models was one of the main objectives in this study. By comparing the two models, it would be easier to decide which models are preferable given different circumstances or purposes.
4Mplus reports the threshold in place of the intercept in the link function, logit(p) = ai
(θ
j
– bi
). The threshold and the intercept are the same except that they have opposite signs. That is, threshold = –intercept = −(−ai
bi
) = ai
bi
. Thus, the difficulty parameter bi
= 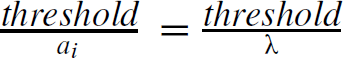 .
.
5The frequentist interpretation is that 100(1 – α)% confidence interval captures the true parameter 100(1 – α) times out of 100. The actual probability that the parameter is in the interval is either zero or one.
6MBE scores typically make up about half of the bar exam score in a given jurisdiction. Most bar examinations are a combination of the MBE (multiple choice), essays, and performance tasks.
7In MCMC sampling, the iterations prior to stabilization are referred to as burn-in phase, and they are generally discarded. The number or the proportion of discarded iterations varies by computer programs. In Mplus 6, the first half of the iterations are considered as a burn-in phase.
8α of 0.01 was used as a Type I error rate in this study because (a) sample size was quite large (n = 3,000), so power was expected to be quite high, and (b) the MBE had been highly elaborated over dozens of years. Thus, we wanted to use somewhat conservative α.
9The covariance matrix (variances and covariances) of individual responses can be decomposed into between-group covariance matrix and pooled within-group covariance matrix (B. Muthén, 1994), which are the sources of the between part of the model and the within part of the model, respectively, in multilevel structural equation modeling.
10Mplus calculates intraclass correlations, not residual intraclass correlations, even with covariates in a model.
11Because no prior information about the parameters in the models was available, diffuse priors, as opposed to informative priors, were used in the Bayesian estimation process.