
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Extended redundancy analysis (ERA) combines linear regression with dimension reduction to explore the directional relationships between multiple sets of predictors and outcome variables in a parsimonious manner. It aims to extract a component from each set of predictors in such a way that it accounts for the maximum variance of outcome variables. In this article, we extend ERA into the Bayesian framework, called Bayesian ERA (BERA). The advantages of BERA are threefold. First, BERA enables to make statistical inferences based on samples drawn from the joint posterior distribution of parameters obtained from a Markov chain Monte Carlo algorithm. As such, it does not necessitate any resampling method, which is on the other hand required for (frequentist’s) ordinary ERA to test the statistical significance of parameter estimates. Second, it formally incorporates relevant information obtained from previous research into analyses by specifying informative power prior distributions. Third, BERA handles missing data by implementing multiple imputation using a Markov Chain Monte Carlo algorithm, avoiding the potential bias of parameter estimates due to missing data. We assess the performance of BERA through simulation studies and apply BERA to real data regarding academic achievement.
Introduction
Extended redundancy analysis (ERA; Takane & Hwang, Citation2005) is a statistical tool for exploring the directional relationships between multiple sets of predictors and outcome variables (e.g., DeSarbo, Hwang, Blank, & Kappe, Citation2015; Hwang, Suk, Takane, Lee, & Lim, Citation2015; Lee, Choi, Kim, & Kim, 2016; Lovaglio & Vacca, Citation2016; Lovaglio & Vittadini, Citation2014). It reduces predictors to a smaller number of new variables, called components or weighted composites of the predictors, and at the same time, examines the effects of these components on outcome variables. ERA aims to perform dimension reduction and linear regression simultaneously, and it would be regarded as a special case of structural equation models, in which the outcome variables are always observed and affected by components of the predictors. Other variants of ERA have also been developed, for example, for analyzing functional data (Hwang, Suk, Lee, Moskowitz, & Lim, Citation2012) or for accounting for cluster-level heterogeneity in functional data (Tan, Choi, & Hwang, Citation2015).
There exist two other related techniques that also represent component-based regression models with dimension reduction: principal component regression (PCR; Hotelling, Citation1957; Jolliffe, Citation1982) and partial least squares regression (PLSR; Wold, Citation1966, Citation1973). In PCR, a principal component analysis is first carried out to extract a few principal components of predictors, which account for as much variation of the predictors as possible, and subsequently, outcome variables are regressed on these components (e.g., Wehrens & Mevik, Citation2007). PCR is, however, limited in that the principal components of predictors may not be optimal in explaining the variance of the outcome variables because they are extracted only to account for the maximum variance of the predictors, without considering their associations with the outcome variables (e.g., Abdi, Citation2010; Geladi & Kowalski, Citation1986).
To address this issue inherent to PCR, PLSR aims to extract components of predictors, taking into account the covariances between the components and outcome variables. It utilizes an iterative algorithm to estimate component weights for predictors in such a way that the obtained components are maximally associated with the outcome variables (e.g., Wold, Citation1973, Citation1975; Wold, Ruhe, Wold, & Dunn, Citation1984). Although this algorithm is computationally efficient and seems to converge in practice, it does not involve a single optimization function to be consistently minimized or maximized to estimate parameters including the component weights. This makes it difficult to understand how the algorithm works theoretically and to generalize PLSR to handle a more variety of problems (e.g., missing data, capturing cluster-level heterogeneity, incorporating interaction terms of components, etc.) in a technically coherent manner.
ERA is similar to PLSR in the sense that it also extracts components in such a way that they explain the maximum variation of outcome variables. However, ERA is different from PLSR for two main reasons. First, ERA aims to minimize a single least squares function to estimate all parameters, using an alternating least squares (de Leeuw, Young, & Takane, Citation1976) algorithm (Takane & Hwang, Citation2005). Second, whereas PLSR involves only one set of predictors, ERA considers multiple sets (or blocks) of predictors simultaneously and reduces each set into a component based on some substantive theories or hypotheses about how certain predictors can be grouped into the same block and aggregated into a component. Accordingly, ERA can be regarded as theory-based regression models with dimension reduction.
ERA has been extended to improve its flexibility (e.g., Hwang et al., Citation2012; Tan et al., Citation2015). Nevertheless, these extensions have been thus far developed within the frequentist framework, despite the increasing adoption of Bayesian methods by many disciplines including psychology (Kaplan & Depaoli, Citation2012; van de Schoot, Winter, Ryan, Zondervan-Zwijnenburg, & Depaoli, Citation2017). Therefore, in this article, we propose a Bayesian approach to ERA, called BERA hereinafter, to transfer three appealing advantages of Bayesian inference to ERA. First, while the statistical inference of ordinary ERA requires an additional step of implementing a resampling method such as bootstrapping (Efron, Citation1982) in addition to parameter estimation, that of BERA can be easily conducted based on samples drawn from the joint posterior distribution of parameters via a single Markov chain Monte Carlo (MCMC) algorithm, especially Gibbs sampler (Geman & Geman, Citation1984) in this article. To test statistical significance of a parameter, ordinary ERA typically uses, for example, 500 bootstrapped replications of the data. With the bootstrapped replications, an empirical distribution of the parameter estimate is complied, from which the 95% percentile bootstrap confidence interval is calculated. On the other hand, in BERA, samples simulated directly from the posterior distribution of the parameter is used to compute an interval analogous to, albeit philosophically different from, confidence interval (also called credible interval; Edwards, Lindman, & Savage, Citation1963). Specifically, in the article, we calculate the highest posterior density (HPD), hereinafter also called a credible interval for a parameter, that is, the narrowest interval that contains a 95% probability mass of the posterior density. As a by-product of this Bayesian methodology, the Bayesian credible interval enables to make the true probabilistic statement about the parameter value given a fixed interval, which is frequently made for a frequentist’s confidence interval by mistake.
Second, BERA provides an intrinsic way of combining data at hand with researcher’s belief or results of similar and/or previous studies by specifying prior distributions for the parameters of interest, which is the most remarkable characteristic of Bayesian models that frequentist models do not have. In the article, we demonstrate how to formally incorporate substantial prior information obtained from previous research findings into BERA, via the specification of so-called power prior distributions (Ibrahim & Chen, Citation2000; Ibrahim, Chen, Gwon, & Chen, Citation2015).
Lastly, BERA is capable of handling missingness in outcome variables via data augmentation (van Dyk & Meng, Citation2001), which can be easily integrated into an MCMC algorithm. Missing data are a common issue encountered on a routine basis in the social sciences regardless of their research design (Allison, Citation2003; Little & Rubin, Citation1989; Orme & Reis, Citation1991; Peugh & Enders, Citation2004; Schafer & Graham, Citation2002; Schlomer, Bauman, & Card, Citation2010). To date, ordinary ERA has typically excluded all cases that include any missing responses (i.e., listwise deletion) and then estimated parameters based on the remaining cases. This complete-case analysis, however, may lead to the deletion of a large portion of the original sample, reducing the sample size and thus the power of a test of statistical significance substantially, especially if there exists a mosaic pattern of missingness in the data. This loss of information can become a serious problem particularly when the number of variables is large. The complete-case analysis is also considered very limited as it can produce unbiased estimates only when missing responses on a variable are assumed to be not related to any other variables under study (i.e., missingness occurs completely at random), which is often unlikely to hold in practice (e.g., Baraldi & Enders, Citation2010). As will be discussed in a later section, BERA applies data augmentation to produce multiple imputation for missing responses, which is considered a state-of-the-art method for handling missing data (e.g., Allison, Citation2003; Baraldi & Enders, Citation2010; Schafer & Graham, Citation2002) and is easily incorporated into the proposed MCMC algorithm.
To our knowledge, no attempt has been made to develop a Bayesian approach to ERA models as well as examine its compatibility with ordinary ERA. Thus, we will compare BERA with conjugate non-informative or diffuse prior specification with ordinary ERA, focusing not only on similarities but also on distinctions between frequentist and Bayesian approaches to ERA. We highlight BERA by extending its applicability for more various and complicated scenarios, in particular, where (1) external information on parameters are available from previous research findings and (2) the proportion of the missingness in outcome data is considerably large and/or propensity for a response to be missing on a variable is assumed to be not completely at random.
In the reminder of the paper, we present the technical underpinnings of frequenist and Bayesian ERA using a hypothetical example, and explicate how BERA quantifies and constructs prior distributions from any relevant previous research findings. Subsequently, we describe how BERA deals with missing data. We then conduct simulation studies to evaluate the performance of BERA. We also apply BERA to real data concerning the academic performance of children and compare the results of different prior specifications. We finally conclude with a summary and discussion.
Frequentist extended redundancy analysis
Model specification
Let denote the ith value of the qth outcome variable (i = 1,…, N; q = 1, …, Q) and
the ith value of the lth predictor in the kth set (
and
), where pk refers to the number of predictors in the kth set. Let
be the total number of predictors in K sets. Let
denote a component weight assigned to
Let
denote the ith component score for the kth component defined as a linear combination or weighted composite of the predictors in the kth set, that is,
Let
denote the kth regression coefficient connecting the kth component to the outcome variable
and
denote the ith residual value for
Then, as proposed by Takane and Hwang (Citation2005), we can write an ERA model as follows:
(1)
(1)
We can re-express this model in matrix notation as follows:
(2)
(2)
where Y is an N by Q matrix of outcome variables, X is an N by P matrix of predictors, W is a P by K matrix of weights, A is a K by Q matrix of regression coefficients, and E is an N by Q matrix of residuals. For identifiability of F, a standardization constraint is imposed on F such that
displays an exemplary ERA model. In the figure, square boxes are used to indicate observed predictors and outcome variables, and circles are to represent components. This model contains four predictors, two components, and two outcome variables. The two outcome variables (Q = 2) are regressed on two components (K = 2), each of which is a linear combination of two predictors (i.e., pk = 2). For this example, the W and A matrices in (2) are given as
(3)
(3)
Figure 1. A hypothetical example of an ERA model.
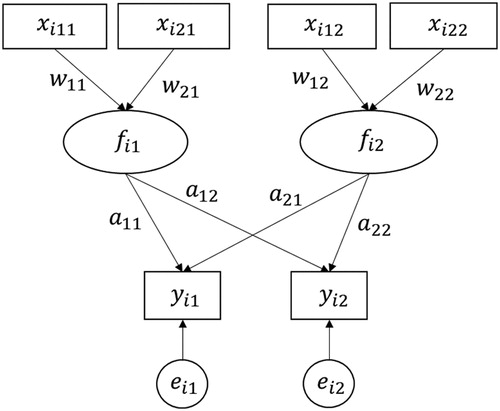
Each weight indicates how a predictor contributes to producing its corresponding component, which is in turn to explain outcome variables. The regression coefficients in A are another set of parameters, each of which indicates the effect of each component on an outcome variable.
Parameter estimation
The ordinary ERA model contains two sets of parameters to be estimated: component weights (W) and loadings (A). These unknown parameters are estimated by minimizing the following sum of squares (SS) objective function:
(4)
(4)
with respect to W and A, subject to the constraint
An alternating least squares algorithm (ALS; de Leeuw et al. Citation1976) is developed to minimize the criterion (Takane & Hwang, Citation2005). The ALS algorithm repeats two main steps until convergence. In the first step, we update W for fixed A. The objective function (4) can be re-written as:
(5)
(5)
where
refers to the Kronecker product and
is the supervector formed by staking the columns of W. Let
denote a column vector formed by eliminating zero elements from
and
denote a matrix formed by eliminating the columns of
corresponding to the zero elements in
The least squares estimate of
is obtained as
(6)
(6)
After reconstructing W from the updated W is multiplied by
to satisfy the constraint
In the second step, we update A for fixed W. Minimizing (4) with respect to A is equivalent to minimizing:
(7)
(7)
where
is a matrix formed by removing the columns in
that correspond to zero elements in
and
is a column vector formed by eliminating zero elements from
The least squares estimate of
is given by
(8)
(8)
Similarly, A is then recovered from
In this algorithm, the signs of the updated parameter estimates can change between iterations without changing their interpretations. For example, if a set of predictors is positively associated with its component (i.e., positive weights) and the component has positive effects on outcome variables (i.e., positive regression coefficients), the interpretation of these relationships still remains the same even if the signs of both the weights and regression coefficients become negative. This is in fact the same in BERA, which will be discussed in the next section. Typically, ERA imposes a sign constraint by either fixing the sign of each component on the basis of empirical/substantive meanings or determining the sign as the sign of the weight estimate that results in the strongest association with outcome variables.
Bayesian extended redundancy analysis
Bayesian analysis treats an unknown parameter as a random variable rather than fixed, and quantifies the uncertainty about the parameter using its probability distribution. The probabilistic statement about the parameter is inferred from updating the so-called posterior distribution, which is a combination of evidence collected from data that is formally expressed by the likelihood function and a prior belief that is specified with a prior distribution. Because the posterior distribution cannot be expressed as a closed form analytically, especially for multiple parameters, an MCMC algorithm is used to approximate the posterior distribution. For example, a Gibbs sampler is one of the most popular MCMC algorithms, which iteratively draws samples from relatively simpler full conditional distributions (Geman & Geman, Citation1984).
In ordinary ERA, there is an implicit assumption of independent residuals with zero means but no form of the likelihood since no error distribution is assumed. For BERA, however, we need to additionally consider a reasonable distribution for vector residuals, which can be a multivariate normal distribution such that
(9)
(9)
for q = 1, …, Q.
Conjugate priors
To make the posterior sampling process efficient, we consider conjugate prior distributions for the parameters. One reason for employing conjugate priors is that the posterior distribution can be derived as the same known family of the prior distribution, while still combining information from the prior and the data. Another reason is that with a large valued variance of the prior distribution, these conjugate priors become non-informative or diffuse priors with no concern of an improper posterior distribution. Last but not least, in a case where a non-conjugate prior is considered, the posterior distributions are known up to the normalizing constant and therefore a general Metropolis-Hastings algorithm (Hastings, Citation1970; Metropolis & Ulam, Citation1949) is implemented instead with some tuning parameter, which is difficult for a researcher with a minimal statistics background to control. With conjugate priors, all the full conditional distributions in a Gibbs sampler, as proposed in this article, are expressed as known distributions and therefore general audience can easily run the algorithm simply by specifying hyperparameters of the conjugate prior distributions.
Let W[,k] denote a pk by 1 column vector containing the weight estimates for the kth component, and A[,q] denote a K by 1 column vector containing the regression coefficients affecting the qth outcome variable. In BERA, we consider the following conjugate priors:
(10)
(10)
where a scalar constant
(
> 0) for the qth outcome variable is used to determine the dispersion of
If we set
to large values such as
= 100, the prior distribution on
will become a diffuse prior conditional on
Although we can fix
and
to constant values to fully utilize the appealing features of Bayesian inference, we specify a hyperprior for
and a prior for
As one major objective of the paper is to introduce the general usage of BERA, a set of objective priors, that is, diffuse conjugate priors, (e.g., Chen, Bakshi, & Goel, Citation2009; Spiegelhalter, Thomas, Best, & Lunn, Citation2003) are specified with a0 = b0 = 1 and
= 100 for simulated and real data analyses. Any subjective information obtained from previous research findings would also be formulated with power priors, as discussed in the next section.
Power priors
As the capability of incorporating any relevant prior information into a statistical analysis is one of the advantages of Bayesian methodologies, we consider using a power prior, that is, an informative prior constructed from historical data (Ibrahim & Chen, Citation2000; Ibrahim et al., Citation2015) for BERA. Because the accumulation of information occurs from past to future, it is natural to construct a prior from any previous research findings or information from historical data.
Following the notations of Ibrahim and Chen (Citation2000), the power prior distribution for the current study can be expressed as
(11)
(11)
where
indicates the likelihood for the historical data D0 given a set of parameters
and
0(
|
) denotes the initial prior distribution for
and
is a specified hyperparameter for the initial prior. Note that the power parameter
will serve as a weight that controls for the influence of the historical data on the current data, and it is reasonable to restrict the range of
to be between 0 and 1, 0
1. When
= 0, no information from the historical data is incorporated (no borrowing), leading to the usual update through Bayes’ Theorem (or Bayes’ rule) only with the initial prior distribution. On the other hand,
= 1 gives equal weights to
and the likelihood of the current data. In Ibrahim et al. (Citation2015), power priors are extended to accommodate multiple historical datasets, imposing a power parameter
for the mth historical data. With
defined distinctively from past to near past, the priors from the historical data sets can accumulate information. Although we may update
by modeling a hyperprior (e.g., a beta prior, a truncated gamma prior, or a truncated normal prior) as suggested by Ibrahim and Chen (Citation2000), it might be more appealing to consider few possible values of
based on the analytic meaning of the estimated weights and regression coefficients for interpretation purposes. This is common practice in applied research implementing a power prior (Rietbergen, Klugkist, Janssen, Moons, & Hoijtink, Citation2011; Shao Citation2012), which we also follow by evaluating how results would change depending on the values of
as sensitivity analyses.
In this article, we only consider a power prior from the nearest past with the initial prior distribution for in (11) being an improper uniform prior, that is
for simplicity. Even though the proposed method can be extended with many sets of past studies, we consider a simple form of priors for comparisons to ordinary ERA. In BERA, power priors are specified as:
• Power Normal prior on W
where
is a mean vector of weights from the past study for the kth component and
is a diagonal matrix with (
), where
is the variance of
Although it is possible to further consider a hyperprior distribution (e.g., inverse Wishart priors) on
we fix them with the estimated values from the historical data.
• Power Normal prior on component loading A
where
is the qth outcome variable’s mean vector of regression coefficients and
is a diagonal matrix with (
) from the past study.
• An Inverse Gamma prior on
for q = 1, …, Q. For a simpler notation, let
hereinafter.
It is worthy to note two things related to the above formulation of power priors. First, it is common in practice to report maximum-likelihood estimates (MLEs) for parameters of interest and their standard errors, but not the estimated covariance matrix of the parameter estimates as a result of data analysis. Taking this practice into account together with the asymptotic normality of MLEs (Casella & Berger, Citation2002), it is natural to assume that both the prior variance matrices and
of weight W[, k] and regression coefficients
in the conjugate multivariate normal prior distributions are to be a diagonal matrix with diagonal elements being squared standard errors of the corresponding parameter estimates from the past study. In a case where the full data set or the estimated covariance matrix of parameter estimates is available from the past study, the prior variance matrices can be specified to incorporate covariance information of the parameter estimates further. Second, because of the conjugacy of the above power priors, there will be no improper posterior issue even with power parameters.
Dealing with missing data in BERA
For simplicity, we assume that missingness occurs in outcome variables only, which is typically contemplated in a model with missing data (e.g., Asparouhov & Muthén, Citation2010). In this setting, it is reasonable to assume that missing data are classified as missing at random (MAR), that is, missing responses on an outcome variable can depend on predictors and other outcome variables but not on the outcome variable itself (Rubin, Citation1976, Citation1978). Missing completely at random (MCAR), that is, missing responses on an outcome variable is unrelated to any other variables, is another missing pattern that researchers in the social sciences typically assume (Schlomer et al., Citation2010). However, because MAR is a more general assumption than MCAR, we incorporate multiple imputation to handling missing data, which is known to hold well under the assumption of MAR.
In the presence of missing responses, the qth outcome variable vector can be written as Y[,q] = (Yobs[,q], Ymis[,q]), where Yobs and Ymis are vectors of observed and missing responses, respectively. Let
denote a set of all parameters. Then, the likelihood function of
and Ymis, given Yobs, can be written as
(12)
(12)
Based on (10), we implement a Bayesian approach to multiple imputation by generating a Markov chain that iterates the imputation and posterior sampling steps as follows. At the (s + 1)th iteration,
• Imputation step:
• Posterior sampling step:
The imputation step generates new samples from the conditional distribution of Ymis, given Yobs and the current values of the parameters. Then, using the just updated values of Ymis, each set of the parameters is sampled from the posterior distribution based on full-data likelihood The imputation step above is a data augmentation (Tanner & Wong, Citation1987; Schafer, Citation1997; van Dyk & Meng, Citation2001), which enables full-data inference even in the presence of missing responses.
In BERA, the full conditional distribution of Ymis[,q], given all the other parameters in the imputation step, is obtained from a multivariate normal distribution as
(13)
(13)
where N* is the number of observed responses for the qth outcome variable,
is an (N - N*) by P matrix of predictors, and I is the identity matrix of order (N - N*). Then, the posterior sampling step is carried out using the Gibbs sampling with either conjugate or power priors, as discussed earlier. Further details on the sampling scheme with the full conditional distributions are provided in the Appendix.
Other computational issues in BERA
As the same scale indeterminacy between F and A remains in BERA, we impose the same scaling constraint of on each component. Also in BERA, to avoid the potential sign-switching between W and A, we fix signs of W to the sign of a weight estimate that yields the strongest association with outcome variables.
To examine if a sequence of posterior samples obtained from an MCMC method converges to the target distribution after a number of iterations, we check convergence and mixing of a chain by drawing trace plots for the samples simulated. When a lack of convergence and mixing is suspected by showing a systematic or cyclic trend over the iterations (e.g., staying in a certain range of values for a longer period of time rather than traversing up and down), we would increase the number of early iterations to discard in the chain (i.e., a burn-in period) (Lynch, Citation2007) and/or choose every rth posterior sample (i.e., a thinning) to improve the mixing of the chain. To monitor dependency among posterior samples and determine the value of r in the thinning, autocorrelation function (ACF) plots are used to check around what lag the autocorrelations decrease to being not significantly different from zero (decrease towards zero). Additionally, we also check convergence of the proposed MCMC algorithm by running chains multiple times with different initial values for parameters.
Examples
Simulation studies
We conducted two series of simulations studies to investigate how well the proposed method performed in terms of recovering the original underlying structure of the data under different conditions. Across the different conditions, the number of predictors, components, and outcome variables remained the same as shown in : Q = 2, K = 2, and = 2 for k = 1 and 2. The weight and regression coefficient parameters in W and A in (2) were prescribed as
Furthermore, X and Y in (2) were assumed to be generated from
where and
A summary of other model specifications varied at each condition is provided as follows:
• Condition 1: We set the two outcome variables to be continuous without missing values. Four different sample sizes were considered: N = 50, 100, 200, and 1000.
• Condition 2: The data were generated in the same way as in Condition 1 across the sample sizes, except that the proportion of missingness in the outcome variables was also varied. We considered two levels of the proportions of missingness, that is, 30% and 50% of the responses in an outcome variable were set to be missing. Three combinations of these two proportions were then considered for two outcome variables: 30–30%, 30–50%, and 50–50%. Note that the sample size of N = 50 was not considered in this condition, because the combination of 50–50% missingness may result in a too small sample size, which in turn would not be advisable to carry out ordinary ERA with a complete-case analysis.
To analyze simulated data in absence of relevant prior research findings or belief, diffuse conjugate prior distributions were considered first (i.e., without power prior specifications, = 0). In specific, we assigned the conjugate priors as specified in (10) with a hyperprior for
set to follow an inverse-gamma distribution
= 100 for q = 1, …, Q, and a0 = b0 = 1. These specifications were set to ensure a large variance and thus diffuse priors on the parameters of interest. This makes the contribution of the priors the least, while allowing for the comparison with the ordinary ERA.
Both BERA and the ordinary ERA were applied to the simulated data to compare their recovery of the parameters of interest. Moreover, BERA was applied with and without imputation for Condition 2 to compare their relative performance of multiple imputation. For BERA, the total number of iterations were set at 10,000. Fast convergence and good mixing of the MCMC chain was observed for all parameters of interest across all the simulation scenarios considered and the autocorrelations of the posterior samples were kept <0.01 after the lag time of 3 or more (). Based on these observations, the first 1000 iterations were discarded as a burn-in period and every fifth posterior sample was used by applying a thinning approach to calculate the posterior means, standard deviations, and HPD credible intervals (CI) of parameters of interest. For ordinary ERA, the bootstrap method (Efron, Citation1982), with 500 bootstrap samples, was used to obtain the 95% percentile bootstrap confidence intervals of parameter estimates.
Figure 2. Trace and autocorrelation function (ACF) plots of weight element w11 (top row) and regression coefficient a11 (bottom row) in Condition 1 with N = 50. The white horizontal solid line in the trace plot indicates the true value.
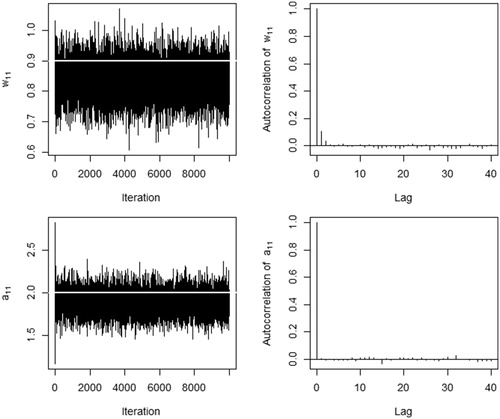
presents the results of analyzing the simulated data under Condition 1. As the sample size increased, posterior mean estimates obtained from BERA became closer to the parameters on average. The posterior standard deviations as well as the width of the credible intervals decreased with the sample size, as expected. This was the case for the bootstrapped confidence intervals obtained from ERA. The similarity between the results of BERA and ERA was not entirely surprising given that the Bayesian estimates here were obtained using diffuse prior distributions. Nevertheless, at a relatively small sample size (N = 100), the width of the bootstrapped confidence intervals from ERA tended to be wider than that of the credible intervals from BERA. This difference in the interval’s width decreased with the sample size. Overall, BERA seemed to recover the prescribed parameters sufficiently well.
Table 1. Results of the simulation study under Condition 1 applying BERA (with diffuse priors) and ordinary ERA.
In addition to the analysis of data from Condition 1 with diffuse priors, we applied power prior distributions to the same condition in order to examine whether the results obtained from BERA were sensitive to different prior specifications. For this, an independent set of samples was generated from the same simulation model with a sample size of 50 and used as historical data, whose obtained posterior means and standard deviations served as the hyperparameter values for specifying the power prior distributions. By fixing the sample size of historical data as N = 50 across the four different sample sizes in Condition 1, we would also investigate how the amount of information in the likelihood overwhelms that in the prior. presents results of Condition 1 with the informative prior distributions while varying across three different values of the power parameter ( = 0.2, 0.34, and 0.5). Results obtained under N = 1000 is provided in the Supplemental materials (refer to Supporting Information Table S1) to improve readability of . Note that the last two rows in the table are the results of the historical data itself with N = 50, which were used as hyperparameters in power priors. Overall, on average, the posterior mean estimates after updating the power prior regardless of the power parameter
were closer to the true parameters, and their posterior standard deviations and their HPD intervals were smaller and narrower, respectively, compared to the results with the same sample size in (Condition1 with diffuse priors). These were shown consistently regardless of different degrees of the power parameter
The accuracy of recovering the true parameter values increased with a better precision as the sample size of current data from Condition 1 increased. In case of analyzing larger sample sizes of current data (e.g., N ≥ 100), it was observed that the posterior was mainly dominated by the likelihood. Because of the small sample size used in the historical data, some estimated parameters were found to be notably deviated from the true parameter value (e.g., the mean of w12 was estimated as 0.337 when its true value was 0.5). When the current data have sufficient number of sample sizes, however, we rather observed stable results, recovering the true values well. This suggested that even with a power prior distribution specified with a less accurate hyperparameter value, BERA would be still able to produce robust results if there are sufficient number of sample size in current data.
Table 2. Results of the simulation study under Condition 1 applying BERA with informative power priors varying the power parameters (δ = 0.2, 0.34, and 0.5).
and show the results under Condition 2 across different sample sizes. Results with the sample size of N = 1000 are presented in the Supplemental materials at Supporting Information Table S2. The number of complete cases was reported as N* in the corresponding combination of missingness on the outcome variables. For example, at N = 100, there were 22 cases left after removing those containing missing responses (N* = 22). The width of the credible interval tended to become wider as the proportion of missingness increased. This pattern was observed regardless of the sample sizes. BERA with imputation outperformed the other two alternative methods, that is, BERA without imputation and ordinary ERA, across all possible levels of missingness and sample sizes. When the total sample size was not large enough (e.g., N = 100) and N* was less than half of N, the estimates from BERA without imputation and ordinary ERA were less accurate with wider credible/confidence intervals. Thus, when missing responses are present, it can be more useful to apply BERA with imputation, particularly when N* was less than half of N.
Table 3. Results of the simulation study under Condition 2 with N = 100 (N* indicates the number of complete-case sample sizes).
Table 4. Results of the simulation study under Condition 2 with N = 200 (N* indicates the number of complete-case sample sizes)
To further assess the properties of parameter estimates and investigate the relative performance of BERA with imputation, as compared to BERA without imputation and ordinary ERA, we replicated 1000 data sets at each scenario of Condition 2 and implemented all three methods. The biases and root mean square errors (RMSE) of the estimates of the parameters were calculated from each method. displays the results with 1000 replicated data sets when the two proportions of missingness for two outcome variables were 50% each. As shown in the table, the magnitudes of biases and RMSE decreased with increasing sample sizes regardless of the methods. Nonetheless, it was noteworthy that the biases and RMSE estimated from BERA with imputation were always the smallest, indicating that it overall outperformed the alternative methods in recovering the true parameters. The biases obtained from BERA with imputation were quite close to zeros across all sample sizes, whereas those from the alternative methods were somewhat larger when N = 100. Similarly, the RMSE of BERA with imputation were about twice smaller than those of BERA without imputation and ordinary ERA consistently across different sample sizes. As expected, similar overall patterns of the biases and RMSE were observed for Condition 2 with the missing proportions of 30% - 30% combination, which is presented in Table S3 in the Supporting Information.
Table 5. The biases and root mean square errors (RMSE) of the 1000 simulation replicates with 50–50% of missingness across different sample sizes.
A real data example
This section provides an example of applying BERA to analyze real data. The data used here were a subset of the National Longitudinal Survey of Youth 1979-Children (NLSY79-C) data (Center for Human Resource Research, Citation2000), where 440 children (N = 440) responded to nine observed variables in 2000. As displayed in , five of the observed variables were predictors, including: (1) cognitive stimulation (COG), (2) emotional support (EMO), (3) compliance (CMP), (4) insecure attachment (INS), and (5) sociability (SOC). The component home environment was constructed as a linear combination of COG and EMO, measured using the Home Observation for Measurement of the Environment (Bradley & Caldwell, Citation1984). Another component temperament was defined as a linear combination of CMP, INS, and SOC, which were measured by Rothbart’s Infant Behavior Questionnaire (Rothbart, Citation1981) and Campos and Kagan’s Compliance Scale (Campos Joseph, Barrett, Lamb, Goldsmith, & Stenberg, Citation1983). The remaining four observed variables were outcome variables that assessed the performance of the children in mathematics (MATH), reading recognition (RECG), reading comprehension (COMP), and vocabulary (VOCB), using the Peabody Individual Achievement Test battery (Dunn & Markwardt, Citation1970) as well as the revised edition of the Peabody Picture Vocabulary Test (Dunn & Dunn, Citation1981). We assumed that each of the two components affected the outcome variables.
Figure 3. A model specification for the real data example.
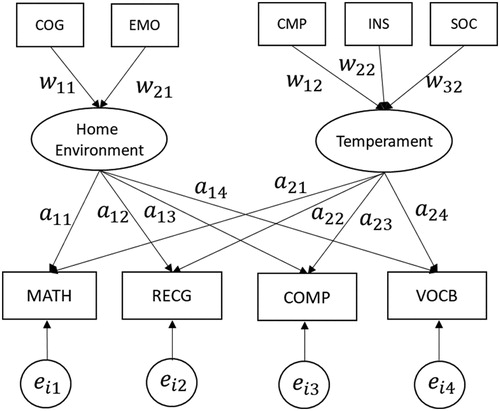
Although the sample size was 440, only three children had responded to all of the four outcome variables, whereas the remaining participants had not responded to at least one of the outcome variables. If we excluded all cases having missing responses in any of the outcome variables, there would be only three cases left, which would be too small to apply ordinary ERA. Hence, we applied BERA with multiple imputation to the data.
The MCMC algorithm converged fast and the mixing looked good (Supporting Information Figure S1). Therefore, in the analysis, the first 2000 iterations were discarded as a burn-in period, after which another set of 8000 iterations were run while saving posterior samples at every fifth iteration from the algorithm for the posterior inferences (i.e., setting the thinning interval = 5). As a summary of the posterior distribution, the posterior mean estimate and standard deviation, and the 95% HPD credible interval were calculated. presents two sets of exemplary posterior densities with their corresponding HPD intervals to make the figure concise. The model fit was satisfactory, since there were no notable patterns observed in residual plots (refer to Supporting Information Figure S2 in the Supplemental materials).
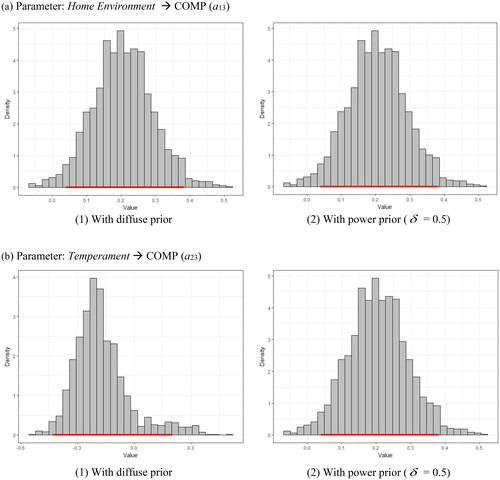
Figure 4. Density plots with highest posterior density (HPD) intervals, comparing posterior estimates results with diffuse and power priors: (a) displays the plots for the posterior regression coefficient estimates of Home Environment on COMP; and (b) displays the plots for regression coefficient estimates of Temperament on COMP. A red colored bar in each plot refers to its HPD interval.
summarizes the results of the posterior distributions for the model parameters with the same diffuse priors specified in the simulation study. As expected, children who received more cognitive simulation (COG) and emotional support (EMO) were positively and statistically significantly associated with home environment, indicating that higher levels of COG (w11 = 1.025, 95%CI = [0.916 1.133]) and EMO (w21 = 0.246, 95%CI = [0.043 0.447]) led to higher scores of home environment. Both predictors contributed well to determining home environment, although the magnitude of COG was larger. With a 95% probability, the weight of COG on defining home environment lies between 0.916 and 1.133, and that of EMO resides between 0.043 and 0.447. On the other hand, insecure attachment (INS) more strongly contributed to constructing temperament than compliance (CMP) and children’s sociability (SOC). INS was also positively and statistically significantly associated with this component (w42 = 0.333, 95%CI = [0.021 0.690]), whereas both CMP and SOC were not statistically significantly related to it. The component home environment had positive and statistically significant effects on all the four outcome variables (a11 = 0.336, 95%CI = [0.225 0.433]; a12 = 0.240, 95%CI = [0.140 0.351]; a13 = 0.205, 95%CI = [0.043 0.385]; and a14 = 0.409, 95%CI = [0.280 0.532]), suggesting that children’s home environment built on both cognitive simulation and emotional support were likely related to their competency on the different performance measures. In contrast, Temperament had no statistically significant impact on all the four outcome variables. This indicates that children’s academic achievements were not strongly related to their temperament that was dominantly determined by how much of the insecure attachment were formed in childhood.
Table 6. Results obtained from BERA with multiple imputation for the National Longitudinal Survey of Youth 1979-Children (NLSY79-C) data in 2000.
For illustration, we analyzed another subset of the NLSY79-C data collected in an earlier year (i.e., year 1996) so as to use the findings for constructing power prior distributions. This data in 1996 consisted of 902 children who were completely independent of the 440 children measured in 2000. represents the results of the data in 1996 using diffuse or uninformative prior distributions (i.e., the same prior distributions specified in the simulation study). Then, the results in were used for constructing informative power prior distributions; the estimated posterior means and standard deviations of W and A were set as the hyperparemter values of the corresponding prior distributions in analyzing year 2000s data.
Table 7. Results obtained from BERA with multiple imputation for the National Longitudinal Survey of Youth 1979-Children (NLSY79-C) data in 1996.*
shows results with the informative prior distributions while varying across three different values of the power parameter As
determines the relative importance of the past 1996s data in comparison to the current data, compared to , results of are found after placing more importance on the prior information. Substantially, when
= 0.5, it means that two samples in 1996 is accounting for a sample in 2000. Given the difference in the sample sizes across two data (902 children in 1996 vs 440 children in 2000),
= 0.5 is regarded as the case where it exerts an equal weightage on the historical and current data. Also note that the results in .e., with diffuse priors) would be equivalently obtained from the same power prior specifications but with
= 0.
Table 8. Results obtained from BERA with multiple imputation for the National Longitudinal Survey of Youth 1979-Children (NLSY79-C) data in 2000, using the results in 1996 to formulate informative priors: (a) results when δ = 0.2; (b) = 0.34; and (c)
= 0.5.
The results of 1996’s data in showed that both cognitive simulation (COG) and emotional support (EMO) were positively and statistically significantly associated with home environment, indicating that higher levels of COG and EMO led to higher scores of home environment. All three predicators of temperament were found to be statistically significant as well. Based on the positive and negative associations from INS and CMP/SOC on temperament, respectively, the temperament was to represent a tendency to behave in an uncontrolled or bad-tempered way. Children who were in a good home environment were more likely to exhibit better performance on MATH, RECG, and VOCB. In addition, difficult temperament had statistically significant and negative impact on all four outcome variables, suggesting that children with difficult temperament were likely to have poor academic performance.
After including the 1996’s data as prior information in analyzing 2000’s data, the posterior standard deviations in became smaller than those in (regardless of different values of ). Accordingly, credible intervals were all narrower for all of the model parameters, although the width became even much narrower with larger
As an example, consider the posterior regression coefficient estimates of home environment on COMP (a13). Its posterior mean was estimated as 0.205 with a 95% HPD credible interval of [0.043 0.385], using diffuse priors (see ). As the priors become more informative than the settings in , we would find that the posterior estimate of a13 was pulled towards its corresponding prior mean (estimated mean of a13 = 0.152 in ) with a narrower 95% HPD credible interval. For
= 0.2, the resulting posterior mean became 0.183 and its credible interval changed to [0.032 0.361], while for
= 0.5 placing an equal weightage on historical and current data, the corresponding posterior mean became 0.170 (getting closer to the prior mean of 0.152) with a credible interval of [0.045 0.326]. Their posterior densities seemed to be normally distributed (in ), from which their highest posterior density (HPD) intervals were found. In sum, the statistical significance of home environment on the four outcome variables remained unchanged even after adopting different
’s, suggesting that these effects were likely to be the true significance. That is, the effects of home environment on the outcome variables were less likely to be false positive findings.
Similarly, with a stronger weightage on the historical data ( = 0.5), the weight estimate from compliance (CMP) to temperament (w32) shifted toward the mean estimate obtained in 1996’s data, eventually leading to a result similar to that of 1996’s data. Moreover, with informative prior specifications, the regression coefficient estimates of temperament became statistically significant, not including zeros in their credible intervals. This would be due to relatively small posterior standard deviation estimates obtained from the 1996’s data, which were further encompassed in the analysis as small variance hyperparameters. When diffuse priors (i.e., large variances) were used in the analysis, the resultant posterior standard deviations as well as credible intervals were relatively large (e.g., a23’s posterior mean = −0.172, standard deviation = 0.150, and 95%CI = [−0.414 0.305] in ). However, as more prior information was added to the model, the posterior estimates were shifted towards the prior means and their posterior standard deviations and 95% credible intervals became all smaller (e.g., a23’s posterior mean = −0.237, standard deviation = 0.080, 95%CI = [−0.395 − 0.076] with
= 0.5). presents a23’s HPD intervals with (1) diffuse prior and (2) power prior (
= 0.5). Although the mode for the posterior with diffuse prior was on the around −0.2, its posterior distribution was left-skewed containing a zero in its HPD interval. On the other hand, using an informative prior, its distribution became unimodal and symmetric with an HPD interval of [−0.395 − 0.076].
Conclusions
We proposed a Bayesian extension of ERA to combine prior information in a more principled way through Bayes’ Theorem when there exist any relevant previous research findings as well as to deal with missing responses in outcome variables under the MAR assumption. The proposed method integrated multiple imputation into an MCMC algorithm. The simulation studies showed that when there were no missing data, Bayesian and ordinary ERA recovered the parameters sufficiently well across different sample sizes. However, when missing data were present, BERA with multiple imputation outperformed ERA, regardless of the sample sizes. We further explored the usefulness of BERA through the analysis of real data. BERA was useful for examining how each component could be characterized by a given set of predictors and how the component might affect various aspects of children’s academic performance. Moreover, it could formally incorporate past relevant information about the model parameters into our analysis and further update inferences in line with the past information.
Despite these technical and empirical implications, BERA has several limitations. Although this present study analyzed the empirical data just using three different values of the power parameter for an illustrative purpose, it may be still imposing some subjectivity in selecting an optimal value. To minimize such subjectivity, it would be worthwhile to carry out several sensitivity analyses using a wider range of
’s. Alternatively, as mentioned earlier, we may choose an optimal value by modeling another hyperprior for
(Ibrahim & Chen, Citation2000).
In addition, BERA has been thus far applied to continuous variables only. In the social sciences, nevertheless, it is not uncommon to collect other types of variables, such as binary, ordered categorical, and unordered categorical. In regression models, perhaps the most common one is ordered categorical variables (e.g., Anderson, Citation1984; Bollen, Citation2002). Thus, we may extend the proposed method to accommodate various types of variables, for example, in a manner similar to that developed by Albert and Chib (Citation1993).
Appendix: Sampling scheme of the parameters for missing data in BERA
With the power prior specification described in the section of Power Priors, the full-data joint posterior distribution, from which the full conditional distributions are derived for a Gibbs sampler, has the form of
where R is an N by Q indicator matrix which takes 1 for observed response in Y and 0 elsewhere.
We obtain the posterior samples of the parameters by alternating the following steps:
1. Missing imputation: For q = 1, …, Q, new samples from the conditional distribution of Ymis, given Yobs in (13). Using the just updated values of Ymis, we reconstruct Y[,q] = (Yobs[,q], Ymis[,q]).
2. Conditional posterior distribution based on full-data likelihood
(a) Update W: For k = 1, …, K
where W[,-k] refers to the other columns of W excluding kth column, and
=
where
is the qth column vector of Y.
Thus, the full conditional distribution of W[,k] given W[,-k] and other parameters is
where
Note that to satisfy the standardization constraint of
we need to standardize the weight matrix W such as
where
Let
then
(b) Update A: For q = 1, …, Q.
where
is the qth column vector of A.
Thus, the full conditional distribution of A[,q] is
'where
(c) Update For q = 1, …, Q,
where
is the diagonal variance matrix excluding the variance of the qth variable.
The full conditional distribution of is
Note that in a case, in which there is no missing in the outcome Y, step (1) can be skipped.
Article information
Conflict of interest disclosures: Each author signed a form for disclosure of potential conflicts of interest. No authors reported any financial or other conflicts of interest in relation to the work described.
Ethical principles: The authors affirm having followed professional ethical guidelines in preparing this work. These guidelines include obtaining informed consent from human participants, maintaining ethical treatment and respect for the rights of human or animal participants, and ensuring the privacy of participants and their data, such as ensuring that individual participants cannot be identified in reported results or from publicly available original or archival data.
Funding: This work was supported in part by Grant R-581-000-216-133 from the National University of Singapore, NRF-2018R1D1A1B07050627 and NRF-2013R1A1A1009737 from the National Research Foundation of Korea (NRF) funded by the Ministry of Education and the Ministry of Science, ICT & Future Planning
Role of the funders/sponsors: None of the funders or sponsors of this research had any role in the design and conduct of the study; collection, management, analysis, and interpretation of data; preparation, review, or approval of the manuscript; or decision to submit the manuscript for publication.
Acknowledgments: The authors would like to thank the Editor in Chief Peter C. M. Molenaar, the Associate Editor, and anonymous reviewers for their valuable suggestions and comments on prior versions of this manuscript. The ideas and opinions expressed herein are those of the author alone, and endorsement by the authors' institutions is not intended and should not be inferred.
Supplemental Material
Download MS Word (72.7 KB)Additional information
Funding
Related Research Data
References
- Abdi, H. (2010). Partial least squares regression and projection on latent structure regression (PLS regression). Wiley Interdisciplinary Reviews: Computational Statistics, 2(1), 97–106. doi:10.1002/wics.51
- Albert, J. H., & Chib, S. (1993). Bayesian analysis of binary and polychotomous response data. Journal of the American Statistical Association, 88(422), 669–679. doi:10.1080/01621459.1993.10476321
- Allison, P. D. (2003). Missing data techniques for structural equation modeling. Journal of Abnormal Psychology, 112(4), 545. doi:10.1037/0021-843X.112.4.545
- Anderson, J. A. (1984). Regression and ordered categorical variables. Journal of the Royal Statistical Society. Series B (Methodological), 46(1), 1–30. Retrieved from www.jstor.org/stable/2345457 doi:10.1111/j.2517-6161.1984.tb01270.x
- Asparouhov, T., & Muthén, B. (2010). Weighted least squares estimation with missing data. Mplus Technical Appendix, 2010, 1–10. Retrieved from http://www.statmodel.com/download/GstrucMissingRevision.pdf
- Baraldi, A. N., & Enders, C. K. (2010). An introduction to modern missing data analyses. Journal of School Psychology, 48(1), 5–37. doi:10.1016/j.jsp.2009.10.001
- Bollen, K. A. (2002). Latent variables in psychology and the social sciences. Annual Review of Psychology, 53(1), 605–634. doi:10.1146/annurev.psych.53.100901.135239
- Bradley, R. H., & Caldwell, B. M. (1984). The HOME Inventory and family demographics. Developmental Psychology, 20(2), 315. doi:10.1037/0012-1649.20.2.315
- Campos Joseph, J., Barrett, K. C., Lamb, M. E., Goldsmith, H., & Stenberg, C. (1983). Socioemotional development. In P. Mussen (Ed.), Handbook of child psychology (Vol. 2, 4th ed.) New York: Wiley.
- Casella, G., & Berger, R. L. (2002). Statistical inference (2nd ed.). Pacific Grove, CA: Thomson Learning.
- Center for Human Resource Research. (2000). NLSY79 child and young adult data users guide. Columbus, OH: Ohio State University.
- Chen, H., Bakshi, B. R., & Goel, P. K. (2009). Integrated estimation of measurement error with empirical process modeling—A hierarchical Bayes approach. AIChE Journal, 55(11), 2883–2895. doi:10.1002/aic.11918
- de Leeuw, J., Young, F. W., & Takane, Y. (1976). Additive structure in qualitative data: An alternating least squares method with optimal scaling features. Psychometrika, 41(4), 471–503. doi:10.1007/BF02296971
- DeSarbo, W., Hwang, H., Blank, A. S., & Kappe, E. (2015). Constrained stochastic extended redundancy analysis. Psychometrika, 80(2), 516–534. doi:10.1007/S11336-013-9385-6
- Dunn, L. M., & Dunn, L. M. (1981). Examiner’s manual for the peabody picture vocabulary test – Revised edition. Circle Pines, MN: American Guidance Service.
- Dunn, L. M., & Markwardt, F. C. (1970). Peabody individual achievement test. Circle Pines, MN: American Guidance Service.
- Edwards, W., Lindman, H., & Savage, L. (1963). Bayesian statistical inference for psychological research. Psychological Review, 70(3), 193. doi:10.1037/h0044139
- Efron, B. (1982). The jackknife, the bootstrap, and other resampling plans (Vol. 38). Philadelphia: SIAM.
- Geladi, P., & Kowalski, B. R. (1986). Partial least-squares regression: A tutorial. Analytica Chimica Acta, 185, 1–17. doi:10.1016/0003-2670(86)80028-9
- Geman, S., & Geman, D. (1984). Stochastic relaxation, Gibbs distributions, and the Bayesian restoration of images. IEEE Transactions on Pattern Analysis and Machine Intelligence, 6 (6), 721–741. doi:10.1109/TPAMI.1984.4767596
- Hastings, W. K. (1970). Monte Carlo sampling methods using Markov chains and their applications. Biometrika, 57(1), 97–109. doi:10.1093/biomet/57.1.97
- Hotelling, H. (1957). The relations of the newer multivariate statistical methods to factor analysis. British Journal of Statistical Psychology, 10(2), 69–79. doi:10.1111/j.2044-8317.1957.tb00179.x
- Hwang, H., Suk, H. W., Lee, J. H., Moskowitz, D. S., & Lim, J. (2012). Functional extended redundancy analysis. Psychometrika, 77(3), 524–542. doi:10.1007/s11336-012-9268-2
- Hwang, H., Suk, H. W., Takane, Y., Lee, J.-H., & Lim, J. (2015). Generalized functional extended redundancy analysis. Psychometrika, 80(1), 101–125. doi:10.1007/S11336-013-9373-X
- Ibrahim, J. G., & Chen, M. H. (2000). Power prior distributions for regression models. Statistical Science, 46(15), 60.doi:10.1214/ss/1009212673
- Ibrahim, J. G., Chen, M. H., Gwon, Y., & Chen, F. (2015). The power prir: Theory and applications. Statistics in Medicine, 34, 3724–3749, doi:10.1002/sim.6728
- Jolliffe, I. T. (1982). A note on the use of principal components in regression. Applied Statistics, 31(3), 300–303. doi:10.2307/2348005
- Kaplan, D., & Depaoli, S. (2012). Handbook of structural equation modeling. In R. H. Hoyle (Ed.), Bayesian statistical methods (pp. 650–673). New York: Guilford Press.
- Lee, S., Choi, S., Kim, Y. J., Kim, B.-J., T2D-Genes Consortium, Hwang, H., & Park, T. (2016). Pathway-based approach using hierarchical components of collapsed rare variants, Bioinformatics, 32(17), i586–594, doi:10.1093/bioinformatics/btw425
- Little, R. J. A., & Rubin, D. B. (1989). The analysis of social science data with missing values. Sociological Methods & Research, 18(2/3), 292–326. doi:10.1177/0049124189018002004
- Lovaglio, P. G., & Vacca, G. (2016). % ERA: A SAS macro for extended redundancy analysis. Journal of Statistical Software, 74(Code Snippet 1), 1–19. doi:10.18637/jss.v074.c01
- Lovaglio, P. G., & Vittadini, G. (2014). Structural equation models in a redundancy analysis framework with covariates. Multivariate Behavioral Research, 49(5), 486–501. doi:10.1080/00273171.2014.931798
- Lynch, S. M. (2007). Introduction to applied Bayesian statistics and estimation for social, scientists. New York: Springer.
- Metropolis, N., & Ulam, S. (1949). The Monte Carlo method. Journal of American Statistics Association, 44, 335–341. doi:10.1080/01621459.1949.10483310
- Orme, J. G., & Reis, J. (1991). Multiple regression with missing data. Journal of Social Service Research, 15(1/2), 61–91. doi:10.1300/J079v15n01_04
- Peugh, J. L., & Enders, C. K. (2004). Missing data in educational research: A review of reporting practices and suggestions for improvement. Review of Educational Research, 74(4), 525–556. doi:10.3102/00346543074004525
- Rietbergen, C., Klugkist, I., Janssen, K. J., Moons, K. G., & Hoijtink, H. J. (2011). Incorporation of historical data in the analysis of randomized therapeutic trials. Contemporary Clinical Trials, 32(6), 848–855. doi:10.1016/j.cct.2011.06.002
- Rothbart, M. K. (1981). Measurement of temperament in infancy. Child Development, 52(2), 569–578. doi:10.2307/1129176
- Rubin, D. B. (1976). Inference and missing data. Biometrika, 63(3), 581–592. doi:10.1093/biomet/63.3.581
- Rubin, D. B. (1978). Multiple imputations in sample surveys – A phenomenological Bayesian approach & Nonresponse, In Proceedings of the Survey Research Methods Section of the American Statistical Association, 30–34.
- Schafer, J. L. (1997). Analysis of incomplete multivariate data. Boca Raton, FL: Chapman & Hall/CRC.
- Schafer, J. L., & Graham, J. W. (2002). Missing data: Our view of the state of the art. Psychological Methods, 7(2), 147. doi:10.1037/1082-989X.7.2.147
- Schlomer, G. L., Bauman, S., & Card, N. A. (2010). Best practices for missing data management in counseling psychology. Journal of Counseling Psychology, 57(1), 1. doi:10.1037/a0018082
- Shao, K. (2012). A comparison of three methods for integrating historical information for Bayesian model averaged benchmark dose estimation. Environmental Toxicology and Pharmacology, 34(2), 288–296. doi:10.1016/j.etap.2012.05.002
- Spiegelhalter, D. J., Thomas, A., Best, N., & Lunn, D. (2003). WinBUGS Version 1.4. User Manual. Cambridge: Medical Research Council Biostatistics Unit. Retrieved from https://www.mrc-bsu.cam.ac.uk/software/bugs/the-bugs-project-winbugs/.
- Takane, Y., & Hwang, H. (2005). An extended redundancy analysis and its applications to two practical examples. Computational Statistics & Data Analysis, 49(3), 785–808. doi:10.1016/j.csda.2004.06.004
- Tan, T., Choi, J. Y., & Hwang, H. (2015). Fuzzy clusterwise functional extended redundancy analysis. Behaviormetrika, 42(1), 37–62. doi:10.2333/bhmk.42.37
- Tanner, M. A., & Wong, W. H. (1987). The calculation of posterior distributions by data augmentation. Journal of the American Statistical Association, 82(398), 528–540. doi:10.1080/01621459.1987.10478458
- van de Schoot, R., Winter, S. D., Ryan, O., Zondervan-Zwijnenburg, M., & Depaoli, S. (2017). A systematic review of Bayesian articles in psychology: The last 25 years. Psychological Methods, 22(2), 217–239. doi:10.1037/met0000100
- van Dyk, D. A., & Meng, X. L. (2001). The art of data augmentation. Journal of Computational and Graphical Statistics, 10(1), 1–50. doi:10.1198/10618600152418584
- Wehrens, R., & Mevik, B. H. (2007). The Pls package: Principal component and partial least squares regression in R. Journal of Statistical Software, 18(2), 1–18. doi:10.18637/jss.v018.i02
- Wold, H. (1966). Estimation of principal components and related methods by iterative least squares. In P. R. Krishnaiah (Ed.), Multivariate analysis (pp. 391–420). New York: Academic Press.
- Wold, H. (1973). Nonlinear iterative partial least squares (NIPALS) modeling: Some current developments. In P. R. Krishnaiah (Ed.), Multivariate analysis (pp. 383–487). New York: Academic Press. doi:10.1016/B978-0-12-426653-7.50032-6
- Wold, H. (1975). Soft modeling by latent variables: The nonlinear iterative partial least squares approach. Journal of Applied Probability, 12(S1), 117–144. doi:10.1017/S0021900200047604
- Wold, S., Ruhe, A., Wold, H., & Dunn, W. J. (1984). The collinearity problem in linear regression. The partial least squares (PLS) approach to generalized inverses. SIAM Journal on Scientific and Statistical Computing, 5(3), 735–743. doi:10.1137/0905052