
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Recent technological advances have provided new opportunities for the collection of intensive longitudinal data. Using methods such as dynamic structural equation modeling, these data can provide new insights into moment-to-moment dynamics of psychological and behavioral processes. In intensive longitudinal data (t > 20), researchers often have theories that imply that factors that change from moment to moment within individuals act as moderators. For instance, a person’s level of sleep deprivation may affect how much an external stressor affects mood. Here, we describe how researchers can implement, test, and interpret dynamically changing within-person moderation effects using two-level dynamic structural equation modeling as implemented in the structural equation modeling software Mplus. We illustrate the analysis of within-person moderation effects using an empirical example investigating whether changes in spending time online using social media affect the moment-to-moment effect of loneliness on depressive symptoms, and highlight avenues for future methodological development. We provide annotated Mplus code, enabling researchers to better isolate, estimate, and interpret the complexities of within-person interaction effects.
Introduction
Over the last decade, technological advances have provided new opportunities for the collection of longitudinal data, moving from yearly to hourly measurements, and thus, allowing for new insights into the moment-to-moment dynamics that underly emotional and behavioral processes (Hamaker & Wichers, Citation2017; Jebb et al., Citation2015; Neubauer et al., Citation2022). Alongside changes in data collection methods, statistical models that can adequately capture the complexity of such intensive longitudinal data have also been developed. Among these methods, two-level dynamic structural equation modeling (DSEM) has been gaining in popularity, particularly for the analysis of data collected using ecological momentary assessment techniques. Two-level DSEM combines multilevel modeling, time-series modeling, time varying effects modeling, and structural equation modeling into one framework (Asparouhov et al., Citation2018; Hamaker et al., Citation2018; McNeish & Hamaker, Citation2019). Its popularity derives from the fact that it is well-suited to capture the within-person dynamics (capturing how for instance emotional processes unfold over time within an individual) while also allowing for insights into how between-person differences (capturing factors that differ between people such as gender or genetic predisposition) influence these dynamic processes. It can disaggregate observed data into within- and between-person components, fit a time-series model to the within-person components and further allows for the inclusion of parameters from the within-person component as random effects, as well as random effects of time within a structural equation model (Hamaker et al., Citation2018). These features make it a highly versatile modeling approach.
To date, DSEM has been primarily used within clinical psychology or adjacent research areas, however, as intensive longitudinal data collection is becoming more prominent, so is the use of DSEM in other research areas, for instance in cognitive neuroscience (McCormick & Kievit, Citation2023). DSEM has been used to investigate research questions focusing on directional associations between within-person components (Blanke et al., Citation2021; Metcalf et al., Citation2021), to gain insights into whether between-person factors (such as ADHD traits) moderate within-person effects (Aristodemou et al., Citation2022; Brown et al., Citation2022), to evaluate whether within-person effects (such as stress reactivity) mediate the associations between two between-person factors (Speyer et al., Citation2022) and to investigate mediation effects on the within-person level (McNeish & Mackinnon, Citation2022). For example, Blanke et al. (Citation2021) used a DSEM to investigate the within-person dynamics between rumination and negative affect. They found that within-person increases in rumination were associated with within-person increases in negative affect and vice versa and that individuals who generally tend to ruminate more were more likely to engage in more prolonged rumination. Also using a DSEM, Metcalf et al. (Citation2021) investigated the associations between sleep quality and anger in a daily diary study of veterans, finding that poor sleep quality in the previous night was associated with more frequent anger the next day. Speyer et al. (Citation2022) found that stress reactivity mediated the associations between ADHD traits and internalizing problems, using intensive longitudinal data analyzed within a DSEM framework.
However, DSEM approaches, thus, far have not examined within-person moderation of within-person effects. In other words, it may be that the nature and strength of within-person changes in one repeatedly measured variable or the coupling between two repeatedly measured variables depends on the level of a second or third, repeatedly measured variable. Investigating within-person moderation effects can significantly expand our understanding of the moment-to-moment dynamics underlying emotional and behavioral processes. Such analyses could be used to test a wide range of research questions. This might include, for example, testing whether being in greenspace reduces the association between experiencing stress and later negative affect (Barton & Rogerson, Citation2017). Another question that could be tested would be whether sleep quality on a given day moderates aspects of emotion regulation (Palmer & Alfano, Citation2017). This could for instance give insights into whether an individual is more likely to remain in an emotionally aroused state if getting less than their normal amount of sleep. Thus, investigating within-person moderation effects may be beneficial for the development of interventions by helping identify amenable factors. Such factors may have direct as well as moderating effects as in the aforementioned examples and could include a wide range of within-person varying factors such as engaging in a physical activity, sleep quality or improving dietary behaviors, that can help prevent increases in mental health symptoms in response to encountering momentary stressors.
In the following sections, we will first provide a very brief overview of two-level DSEM, following with a description of how within-person moderation analyses can be investigated within a DSEM framework. We will then illustrate such an analysis using an empirical example investigating whether time spent on social media may mitigate the associations between loneliness and depressive symptoms using an openly accessible data set collected during the COVID-19 pandemic (Fried et al., Citation2021). Specifically, we use DSEM to test whether changes in time spent online using social media affect the strength of the association between loneliness and depressive symptoms in a sample of N = 79 university students taking part in an ecological momentary assessment study collecting information on mental health four times a day over a two-week period. We provide annotated Mplus code (available in full on the Open Science Framework, OSF) to enable researchers to utilize this technique for their own research. Finally, we present the results from a brief simulation study assessing the type I error rate of the here presented analysis technique. We finish with a discussion of how the analysis of within-person moderation effects using intensive longitudinal data can be used to advance behavioral and psychological research and highlight future avenues for methodological research.
A brief introduction to multilevel dynamic structural equation modeling
In multilevel intensive longitudinal data, we have repeatedly measured variables t (usually > 20) that have been obtained from more than one participant. DSEM decomposes the repeatedly measured variables (x and y) measured at t occasions for i persons into their respective within- and between-person components (EquationEquations (1)(1)
(1) and Equation(2)
(2)
(2) for x and y respectively). See for an illustration of a bivariate DSEM model.
Figure 1. Multilevel dynamic structural equation model. (W) represents within-person estimates. Black dots indicate random effects. μ = Means. For simplicity, residual variances were not modeled as random.
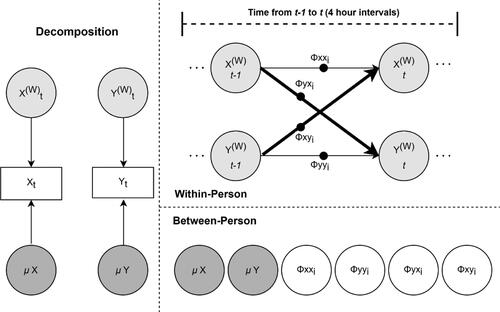
Essentially, within a two-level scenario, the decomposition consists of extracting the person specific means () for each repeatedly measured variable, forming the between-person components. Individual’s deviations from those means at each time point (
), then, form the within-person component (Asparouhov et al., Citation2018) denoted by W:
(1)
(1)
(2)
(2)
Subscripts i and t denote the values for individuals and time, respectively; w indicates the within-person component. For both within and between components, separate equations can then be specified with estimates from the within-person component as well as means treated as random variables in the between-person component.
Within-person component
For the within-person component, a time-series model is used to model the temporal within-person deviations and
from the person-specific means, see EquationEquations (3)
(3)
(3) and Equation(4)
(4)
(4) . This allows us to model autoregressive effects (
and
) and, if we have more than one repeatedly measured variable per participant, cross-lagged effects (
and
Usually, a lag-1 model is used, thus, within-person observations at t is regressed on within-person observations at t-1 (rather than t-2 as in a lag-2 model). Following Hamaker et al.’s (Citation2018) notation,
represent the within-person, time specific residuals for x and y respectively.
(3)
(3)
(4)
(4)
Autoregressive effects give insights into lagged associations between the same variable, that is how within-person changes in one variable affect that same variable at the subsequent time-point, for example, giving insights into negative affect inertia (Blanke et al., Citation2021). A person with high inertia may show a pattern of persisting at a level above, or below, their person specific mean for longer periods/occasions on end than a person with low inertia.
Cross-lagged effects allow for insights lagged associations between different repeatedly measure variables (Hamaker et al., Citation2018). This for instance allows for investigate whether experiencing increases in provocation at time 1 are associated with increases in aggressive behaviors at time 2 at the within-person level (Brown et al., Citation2022). Of note, cross-lagged effects (and autoregressive effects if cross-lagged effects are present) represent partial coefficients. That is, the cross-lagged effect for instance, indicates the estimated change in
following a unit increase in
holding the effect of
constant. Importantly, the parameters capturing these lagged associations can be specified as person random effects. This means that they can take on different values for different participants (as indicated by the subscript i for all lagged parameters), which allows for the investigation of individual differences in any observed associations in the between-person part of the model (Hamaker et al., Citation2018).
This person specific parametrization allows us not only to estimate whether people differ in the strength of such a coupling effect but also whether other variables predict or explain these differences. For example, we may want to examine whether ADHD symptom severity moderate the associations between within-person changes in aggressive behaviors in response to perceived provocations (Brown et al., Citation2022). Such random effects across people are usually treated as fixed across time. However, the effect of interest can also be treated as a random effect across time, and thus, modeled as a time-varying effects model, for instance if one expects a given effect to increase or decrease in strength (or some other shape of change) (McNeish & Mackinnon, Citation2022; Shiyko et al., Citation2014).
Between-person component
The person specific (i.e., random) means estimated for the decomposition of repeatedly measured variables into within- and between-person components and the random effects estimated in the within-person component are automatically part of the between-person component. Thus, the between person model now not only consists of but also of the following random lagged parameters
and
(EquationEquations (3)
(3)
(3) and Equation(4)
(4)
(4) ). In the between-person component, we can for instance investigate whether random effects co-vary at the between-person level or whether other between-person factors (or time-invariant factors that cannot be decomposed into within- and between-person components) are associated with individual differences in random effects capturing lagged associations at the within-person level (Hamaker et al., Citation2018). This, for example, has been used in previous research to investigate whether ADHD symptomatology as a covariate of interest is associated with differences in stress-reactivity as captured by autoregressive effects for perceived stress and cross-lagged effects between perceived stress and negative affect (Speyer et al., Citation2022). Further, it has been used to gain insights into the effects of experiencing a respiratory infection on within-person patterns of body temperature change (Gassen et al., Citation2022). For a tutorial on implementing such between-person moderation analyses using DSEM in Mplus, see https://ellenhamaker.github.io/DSEM-book-chapter. For further discussion of two-level DSEM, see Asparouhov et al. (Citation2018), Hamaker et al. (Citation2018), and McNeish and Hamaker (Citation2019).
While moderation analyses using intensive longitudinal data have been conducted in the past, prior research has been limited to between-person moderation even though within-person moderation may also be important for operationalizing research questions. For instance, the analysis of within-person moderation effects could give insights into the effect of changes in medication dosage on the interrelation between psychological and physical symptoms (Evans et al., Citation2001) or to evaluate whether changes in physical activity levels influence how an individual reacts to experiencing a stressor (Gnam et al., Citation2019). For instance, one might imagine that within person fluctuations in sleep quality affect the strength of the effect of social rejection on mood. In the next section, we will discuss how existing DSEM tools can be expanded to investigate whether within-person factors moderate the associations between within-person components.
Analyzing within-person moderation effects using dynamic structural equation modeling
Within-person moderation can be approached from a multiple regression moderation perspective. As in any other regression moderation analysis, moderation can be incorporated by multiplying the predictor by the moderator (m) to form an interaction term and regressing the outcome variable (y) on the interaction term and the predictors (x and m). In the case of within-person moderation effects, the random variables m, x, and y all need to be decomposed into their respective within- and between-person components, and the interaction is then specified purely at the within-person level. Specifically, for a moderated autoregressive effect is regressed on
and
see EquationEquation (5a)
(5a)
(5a) ) where
as specified in EquationEquation (5b)
(5b)
(5b) , captures the interaction between
For a moderated cross-lagged effect, in this case from x to y,
is regressed on
and
(see EquationEquation (6)
(6)
(6) ) where
again captures the interaction as specified in EquationEquation (5a)
(5a)
(5a) .
(5a)
(5a)
(5b)
(5b)
(6)
(6)
Just as for autoregressive and cross-lagged effects, the moderation effect () can be specified as a random effect and can consequently be integrated in the between-person component. This could be used to assess whether the moderation effect varies across people and is associated with other between-person factors, for instance, to investigate whether a within-person moderation effect differs based on gender.
Implementing within-person moderation analyses in Mplus
The practical implementation of the above-described model is, however, subject to some practical challenges related to latent variable centering. These can be demonstrated by first providing an illustration of how moderation analyses based on single-level data can be implemented in Mplus.
In a single level scenario, we may for example be interested in whether age (m) moderates the association between time spent exercising (x) and weight (y). This could be assessed by multiplying age and time spent exercising and regressing weight on both the product term as well as the predictors weight and age. Using Mplus, a single-level linear regression involving an interaction of two continuous variables can be specified as follows:
––––––––––––––––––––––––––––––––– MPLUS CODE
VARIABLE:
!Variables in data set
NAMES = y x m;
y = weight, x = time spent exercising, m = age
!Variables used in the analysis
USEVAR = y x m xm;
DEFINE:
!specify interaction
xm = x*m;
MODEL:
!Regression
y ON x m xm;
–––––––––––––––––––––––––––––––
For the interpretation of interaction terms and to remove nonessential multicollinearity (Shieh, Citation2010), it is advisable to center and/or standardize both the predictor (e.g., time spent exercising) and the moderator (e.g., age) on their respective “grand” means (i.e., the mean of all observations) before calculating the product term in single-level analyses (categorical moderators/predictors do not need to be centered). Of note, while centering the predictor and moderator before calculating the product term is generally considered to be best practice, the calculation of interaction-terms using the uncentred predictor/moderator is statistically identical to including an interaction based on centered variables in a single-level scenario in that model fit and hypotheses test statistics will be the same but parameter estimates are rescaled (Shieh, Citation2011). Variables can be centered in Mplus using the CENTER command within the DEFINE statement. By listing the calculation of the product term after the centering command, the product term is then automatically calculated on the centered data. Of note, in older versions of Mplus (version 7 or older), the product term calculation in Mplus is carried out using the raw data independently of the order the statements are listed in, that is, before the centering. Consequently, if we wanted to use centered variables for the calculation of the product terms, these would have to be centered in a separate step. In Mplus versions 8 and above, the calculation of product terms based on centered data can be accomplished using the following code:
––––––––––––––––––––––––––––––––– MPLUS CODE
DATA:
!Read in data set
File is raw_data.csv;
VARIABLE:
!Variables in data set
NAMES = y x m;
!Variables used in the analysis
USEVAR = y x m xm;
!Variables that are not needed in current! analysis but need to be saved in final data set! for further analyses
AUXILIARY = y;
DEFINE:
!grand mean center predictor and moderator
Center x (grandmean);
Center m (grandmean);
!specify interaction
xm = x*m;
MODEL:
!Regression
y ON x m xm;
In the case of within-person moderation effects modeled within a DSEM framework (used for instance to explore whether increases in social media use relative to a person’s average social media use moderate the association between within-person changes in loneliness and depressive symptoms) the scenario is slightly more complex because the outcome, the predictor and moderator variables will have to be centered at the within-person level. This means that they should be centered so that the mean of each of these variables is zero for every individual. Importantly, in contrast to single-level models, calculating interaction terms using the uncentred predictor/moderator in a multilevel scenario will lead to different and likely biased results, specifically when focusing on interactions on the within-person level, i.e., level-1 interaction effects (Ryu, Citation2015). This is because the raw variables confound between- and within-person effects, thus, centering is an essential step in the analysis of within-person moderation effects. Of note, while centering has been widely discussed in the literature, the relative importance of centering and how to best go about achieving optimal centering remains an open question, especially in intensive modeling. For further discussions on centering in the context of multilevel data see Asparouhov and Muthén (Citation2020a), Zyphur et al. (Citation2019) as well as Ryu (Citation2015) which includes a discussion of centering for cross-level interactions (e.g., a between-person factor moderating the association between two within-person factors).
In the context of within-person moderation effects, in theory, we could center variables at the within-person level by following the same steps as outlined above for the single-level scenario but using person-mean (also referred to as group-mean) centering rather than grand-mean centering (Center x (groupmean)) while also specifying a clustering variable (CLUSTER = ID). This would center variables on the observed means for each person rather than across all individuals. However, observed person mean centering has been found to leave estimates susceptible to different biases in a multilevel scenario, namely Nickell’s and Luedtke’s bias (McNeish & Hamaker, Citation2019). Nickell’s bias refers to a negative bias in autoregressive effects when including lagged covariates that have been observed mean centered (Nickell, Citation1981), whereas Luedtke’s bias refers to a bias in effect estimates due to the fact that observed means are likely not measured with perfect reliability (Lüdtke et al., Citation2008). The DSEM toolbox implemented in Mplus has overcome this issue by using latent, rather than observed, mean centering for variables that need to be disaggregated into within- and between-person effects, thus, accounting for measurement error in means (Asparouhov et al., Citation2018). However, latent mean centering is only carried out in the model estimation step rather than in a “pre-step” as for group-mean and grand-mean centering. This also means that, if calculating the product term using the DEFINE command, it will also be disaggregated during the model estimation. This is not appropriate as disaggregating the product term is not equivalent to calculating the product term based on the disaggregated within-person components of the interacting variables only. Consequently, this means that coefficients derived from specifying the interaction term in such a way may not provide an accurate estimate of a within-person moderation effect, hence, this should be avoided.
One possible work-around to this problem would be to define the interaction using latent variables representing the within-person components as specified in the within-person part of the model rather than as the product of the raw variables. Specifically, we could define latent variables representing the within-person components in the within part of the model and use these components to specify a latent variable interaction. Finally, the outcome can now be regressed onto the latent within-person centered predictor and moderator as well as the interaction.
––––––––––––––––––––––––––––––––––– MPLUS PSEUDO CODE—cannot be run in present form
DATA:
!data should be in long format, i.e., structured as one row per repeatedly measured observation with every participant occupying multiple rows
!Read in data set
File is ‘data.csv’;
VARIABLE:
!Variables in data set
NAMES = id time y x m;
!Variables used in the analysis
USEVAR = y x m;
!Cluster ID indexes rows belonging to the same participant
CLUSTER = id;
!Variables that need to be disaggregated into! within- and between-components
LAGGED = y(1) x(1) m(1);
!time interval that balances missingness with! meaningful interpretation, ensures that! varying length of time intervals is taken into! account
TINTERVAL = time(4);
ANALYSIS:
Estimate two-level model with random effects
TYPE IS TWOLEVEL RANDOM;
!Use Bayesian Estimator
ESTIMATOR = BAYES;
!Iterations doubled after first convergence! (checked using BITER + TECH8) to ensure stable
!convergence
FBITER = 2000;
!number of MCMC chains
chains = 2;
!save every 10th iteration
THIN = 10;
!multiple processors can be used to increase! speed of computing
Processor = 4;
MODEL:
%WITHIN%! Within-person component
! Define Latent Variables capturing within-person
!components
x@0;
x_within BY x@1;
m@0;
m_within BY m@1
! Define Interaction
xm | x_within XWITH m_within
!Random slope for x_t regressed on xm_t-1
p_xxm | x_within ON xm&1;
! Autoregressive effects
!Random slope for y_t regressed on y_t-1
p_yy | y ON y&1;
!Random slope for m_t regressed on m_t-1
p_mm | m_within ON m_within&1;
!Random slope for x_t regressed on x_t-1
p_xx | x_within ON x_within&1;
! Regression—Cross-lagged effects
!Random slope for y_t regressed on x_ within_t-1
p_yx | y ON x_within&1;
!Random slope for y_t regressed on m_ within_t-1
p_ym | y ON m_within&1;
%Between%!Between-person component
!allow all random effects and between-person! components to be correlated
p_xxm-p_ym y x m WITH p_xxm-p_ym y x m;
OUTPUT:
!Request standardized output to get estimates of! within-person effects
STDYX;
–––––––––––––––––––––––––––––––
The problem here is that the product term calculated based on the within-person components of the interacting variables also needs to be person-mean centered, ideally using latent-mean centering. Even if the variables forming the interaction have a mean of zero for each person, the resulting product term does not necessarily also have a mean of zero for each person. Not being centered on 0 is problematic as the analysis of within-person lagged effects relies on the fact that an individual’s observations are rescaled so that 0 represents the average for that individual and values above or below represent deviations from that individual’s mean (Asparouhov et al., Citation2018). In multilevel models estimated in Mplus, latent person-mean centering is carried out for all variables that are not explicitly specified to be BETWEEN or WITHIN variables. This, however, again requires the interaction term to be calculated before the actual analysis is run, that is, using the DEFINE command, which brings us back to the issue of the product term not being composed of the within-person centered components only.
One practical solution to this problem is to extract the within-person components, that is, the latent-mean centered variables involved in an interaction, in a separate step, similarly to extracting centered variables for the calculation of interactions in a one-level scenario. This can be accomplished by specifying a two-level model in which the variables that need to be disaggregated into a within- and a between-person component are specified as latent variables in the within part of the model. These level-one residuals (corresponding to the within-person level) can then be extracted as factor scores:
––––––––––––––––––––––––––––––––––––––––– MPLUS CODE
DATA:
!Read in data set
File is ‘data.csv’;
VARIABLE:
!Variables in data set
NAMES = id time y x m;
!Variables used in the analysis
USEVAR = x m;
!Cluster ID
CLUSTER = id;
!Variables that are not needed in current! analysis but need to be saved in final data set! for further analyses
AUXILIARY = time y;
ANALYSIS:
!Estimate two-level model with random effects
TYPE IS TWOLEVEL RANDOM;
!Use Maximum Likelihood Estimator
ESTIMATOR = MLR;
!Covariances don’t need to be included
MODEL = NOCOVARIANCES;
MODEL:
%WITHIN% Within-person component
! Within-person centering is done by default for
! variables specified here
! Define Latent Variables capturing within-person
!components
x@0;
x_within BY x@1;
m@0;
m_within BY m@1;
%Between%
SAVEDATA:
!Save factor scores for further analysis
FILE IS data_within.csv;
SAVE = FSCORES;
–––––––––––––––––––––––––––––––
The extracted within-person components can now be used to compute a product term that can be specified as an additional lagged parameter in the DSEM. This ensures that the interaction is appropriately centered using latent mean centering. The resulting parameter can further be specified as a random effect and can consequently also be included in the between-person part of the model.
––––––––––––––––––––––––––––––––––––––––– MPLUS CODE
DATA:
!Read in data set
File is ‘data_within.csv’;
VARIABLE:
!Variables in data set
NAMES = id time y x m x_within m_within B_x
B_x_SE B_m B_m_SE;
!Variables used in the analysis
USEVAR = y x m;
!Cluster ID
CLUSTER = id;
!Variables that need to be disaggregated into! within- and between-components
LAGGED = y(1) x(1) m(1) xm(1);
!time interval that balances missingness with! meaningful interpretation, ensures that! varying length of time intervals is taken into! account
TINTERVAL = time(4);
DEFINE:
!specify interaction using within-person! components of loneliness and time spent
!on social media
xm = x_within*m_within;
ANALYSIS:
!Estimate two-level model with random effects
TYPE IS TWOLEVEL RANDOM;
!Use Bayesian Estimator
ESTIMATOR = BAYES;
!Iterations doubled after first convergence! (checked using BITER + TECH8) to ensure stable
!convergence
FBITER = 2000;
!number of MCMC chains
chains = 2;
!save every 10th iteration
THIN = 10;
!multiple processors can be used to increase! speed of computing
Processor = 4;
MODEL:
%WITHIN%! Within-person component
! Autoregressive effects
!Random slope for y_t regressed on y_t-1
p_yy | y ON y&1;
!Random slope for m_t regressed on m_t-1
p_mm | m ON m&1;
!Random slope for x_t regressed on x_t-1
p_xx | x ON x&1;
! Regression—Cross-lagged effects
!Random slope for y_t regressed on x_t-1
p_yx | y ON x&1;
!Random slope for y_t regressed on m_t-1
p_ym | y ON m&1;
! Interaction
!Random slope for y_t regressed on xm_t-1
p_yxm | y ON xm&1;
!Autoregressive effect for product term needs to
!be included;
xm ON xm&1;
%Between%! Between-person component
!allow all random effects and between-person! components to be correlated
p_yx-p_yxm y x m WITH p_yx-p_yxm y x m;
!means and variances for random effects are! estimated by default but can be manually! specified
p_yx-p_yxm y x m xm;
[p_yx-p_yxm y x m xm];
OUTPUT:
!Request standardized output to get estimates of! within-person effects
STDYX;
–––––––––––––––––––––––––––––––
Based on this specification, an additional consideration is that the by default calculated means and variances of the disaggregated between-person component of the product term are not particularly meaningful. In particular, the raw product term (xm) is based purely on the within-person components of the moderator and predictor and may, thus, not be an accurate representation of the between-person component of an interaction between the moderator and the predictor. Such a between-person interaction term would have to be composed of the actual between-person components of the predictor and moderator rather than then a disaggregated interaction term that was specified purely based on the within-person components of mediator and predictor. Consequently, while not affecting model results as a whole, random effect co-variances specified between the between-person component of the product term (i.e., the person-specific means of the product term; xm) and, for instance, the between-person component of the outcome (y) may not have meaningful interpretations and as such do not need to be included in the model.
Another important point to consider is that the model estimation in Mplus requires all variables listed as “lagged” variables (via the LAGGED command) to be regressed on their lagged counterparts. In the case of the product term, this would require the estimation of an autoregressive effect for the interaction. As the autoregressive effect for the product term may not necessarily be practically meaningful, it is not necessary to estimate this effect as a random effect and it can in theory be set to zero (xm ON xm&1@0). However, it is advisable to include the autoregressive effect as default (and only set it to zero if required by computational constraints) as otherwise other parameters may absorb some of the autoregressive effect which could affect estimates in other parts of the model, such as inflating autoregressive or cross-lagged parameters. Note, here also that the interaction term functions like a dependent variable within the autoregression. This could lead to (empirical) identification issues in cases where the two variables used to form the interaction are included in the same model. In challenging cases, model simulations (see Chapter 12, Mplus User Guide; Muthén and Muthén (Citation1998–2017) may be able to clarify which models are, in principle, estimable given the properties of the data and model being investigated. In the following section, we illustrate the estimation of within-person moderation effects using intensive longitudinal data in an empirical example.
Empirical example
The COVID-19 pandemic adversely affected social connectedness and mental health around the world (Aknin et al., Citation2022). Loneliness has been associated with a wide range of health problems, ranging from heart disease to anxiety, depression, and cognitive decline (Hodgson et al., Citation2020). In the absence of options to socialize face-to-face during the COVID-19 pandemic, engaging socially online became increasingly more important. An important question is whether spending time online using social media can help reduce the previously observed links between loneliness and depressive symptoms (Erzen & Çikrikci, Citation2018). Importantly, such processes are likely to act over short time-periods, making intensive longitudinal designs valuable information sources. Crucially, such intensive longitudinal data can reveal not only person specific dynamics, but moderators of those dynamics that cause certain processes to unfold differently at different occasions. However, to date, the testing of research questions involving within-person moderation effects has been challenging for two reasons: Suitable intensive longitudinal data was not available and methodological and estimation techniques required for the analysis of such data had not been adequately developed. However, with the implementation of multilevel dynamic structural equation modeling in Mplus (Asparouhov et al., Citation2018), such analyses are now possible. Here we illustrate the implementation of a within-person moderation test within a dynamic structural equation modeling framework reusing openly shared data that was collected by researchers investigating how the COVID-19 pandemic has affected students’ mental health at the University of Leiden (Fried et al., Citation2021). Specifically, we test whether changes in time spent on social media affect the strength of the association between within-person increases in loneliness and within-person increases in depressive symptoms.
Participants
Participants included 79 students at the University of Leiden (60 female, 19 male, mean age = 10.38, SD = 3.68, range = 18–48) taking part in an EMA study investigating the effects of the COVID-19 pandemic on mental health and social contact between 11 March, 2020 and 4 April, 2020. EMA data was collected four times a day over a two-week period (56 measurement points) via a smartphone app (Ethica Data). Detailed information on the study’s procedure, including links to the openly accessible data is available in the original study publication (Fried et al., Citation2021). The study received ethical approval from the Ethics Board of Leiden University, Faculty of Social and Behavioral Sciences.
Measures
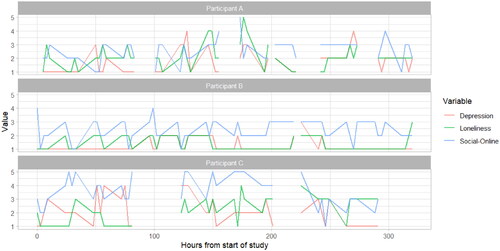
For the current study, we use one question each on loneliness, depression, and time spent on social media. In particular, among other questions, students were asked to indicate how much (1 = not at all, 2 = slightly, 3 = moderately, 4 = very, 5 = extremely) they endorsed the following statements over the previous three hours: “I couldn’t seem to experience any positive feeling at all” and “I felt like I lack companionship, or that I am not close to people” and to indicate how much time they spent using social media to kill/pass the time (1 = 0 min, 2 = 1–15 min, 3 = 15–60 min, 4 = 1–2 h, 5 = over 2 h). Variables were treated as continuous to facilitate estimation (see Rhemtulla et al., Citation2012 for simulations suggesting this can be an adequate approximation). See Supporting Information Figure S1 for distribution of variables and raw correlations, Supporting Information Table S1 for correlations of disaggregated within and between-person components, for mean scores of all included variables across time and for raw data of all included variables across time (for a subset of three randomly selected participants).
Figure 2. Mean scores of variables across time.
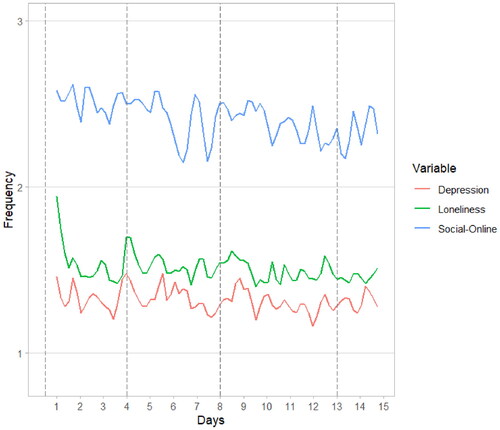
Figure 3. Raw scores of variables across time for three randomply selected participants.
Statistical analysis
Prior to estimating a DSEM, we fit a two-level model to extract the within-person components required for the analysis of within-person interaction effects. Specifically, we specified the level one residuals representing the latent-mean centered within-person components necessary for creating the interaction (loneliness and time spent on social media) as factors and saved them for further analysis as factor scores.
–––––––––––––––––––––––––––––––––––––––– MPLUS CODE FOR EMPIRICAL EXAMPLE
DATA: file is ema_data.dat;
VARIABLE:
NAMES = X ID Scheduled Issued Response
Duration Stress1 Stress2 Anxiety1 Anxiety2 Dep1 Dep2 fatigue hunger lone anger social online music procr outdoor corona health home time Day beepvar hours;
CLUSTER = ID;
USEVAR = lone online;
MISSING = all(-999);
AUXILIARY = DEP2 hours;
ANALYSIS:
TYPE IS TWOLEVEL RANDOM;
ESTIMATOR = MLR;
MODEL = NOCOVARIANCES;
MODEL:
%WITHIN%
lone@0;
lone_w BY lone@1;
online@0;
online_w BY online@1;
%Between%
SAVEDATA:
FILE IS scores_within.dat;
SAVE = FSCORES;
FORMAT IS free;
–––––––––––––––––––––––––––––––
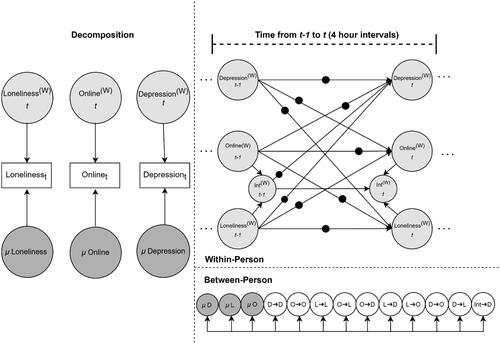
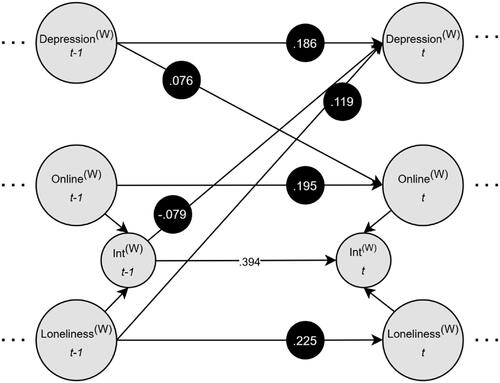
Next, we built a DSEM as follows: Loneliness, time spent on social media and depression were modeled as a multilevel time series model that decomposes the data into latent within- and between-person components. In the within-person component, we included autoregressive and cross-lagged effects for all variables, setting all but the autoregressive effect for the interaction term to be random. That is, loneliness, time spent on social media and depression at any given time-point (t) were predicted by themselves as well as each other at the previous time-point (t – 1). Further, we created an interaction between the within-person component of loneliness and the within-person component of time spent on social media (specified in the DEFINE statement in Mplus). We then regressed depression at time t on the interaction term at time t – 1 to investigate whether within-person changes in time spent on social media affect the strength of the association between within-person increases in depression at time t and increases in loneliness at time t – 1. As all lagged variables need to be regressed on themselves in the within-person component, we also included an autoregression for the interaction term. Finally, we allowed the within-person means of loneliness, time spent on social media and depression to covary and included covariances for all random effects and between-person components, except the product term, in the between-person part of the model. See for an illustration of the model. To examine to what extent fixing this autoregressive effect to zero would impact results, we conducted an additional analysis fixing the autoregressive effect for the interaction term to zero to gain insights into whether doing so may lead to bias in other parameters.
Figure 4. Multilevel dynamic structural equation model. (W) represents within-person estimates. Black dots indicate random effects. μ = Means, D = Depression, L = Loneliness, O = Time spent online using social media, Int = Interaction (L × O).
The DSEM was estimated in Mplus 8.8 (Muthén & Muthén, 1998–2017) using Bayesian estimation with uninformative priors and the Mplus default maximum of 50,000 Markov Chain Monte Carlo (MCMC) iterations. We utilized two independent Markov Chains to reduce the chance of false convergence, saving every 10th MCMC iteration, and set the processor option to 4 to reduce estimation times through making use of parallel computing. Once Potential Scale Reduction (PSR) values indicated that convergence had been achieved (PSR < 1.1), we doubled the number of iterations to check for stable convergence (Asparouhov & Muthén, Citation2020a). We further ensured that estimates only differed by a maximum of 10% between the model based on first convergence and the model based on double the number of iterations (McNeish, Citation2016), that is, we examined the relative bias of parameter estimates. As EMA prompts were not completed within equal intervals, the time-interval option was set to 4 h which forces the time-series intervals to be approximately equidistant with missing values introduced between observations that were further apart. We chose a time-interval of 4 h as this allowed for a meaningful interpretation while ensuring that not too much missing data was introduced. In DSEM, missing data is addressed using a Kalman filter which uses predicted values as an estimate of missing values within a time-series. This ensures that no observations are lost, even if the majority of occasions involve either a missing outcome or a missing predictor (McNeish & Hamaker, Citation2019). Given the Bayesian modeling context, credible intervals (indicating the 95% probability that the true parameter estimate would lie within the estimated interval of the posterior distribution) were used as an indicator of significance of estimates, that is, if the CI did not include 0, the effect was interpreted to be significant. For basic DSEM input syntax, see code section below. Estimates reported in the results sections refer to standardized estimates. Raw estimates as well as full Mplus input and output files are available on OSF: https://osf.io/tv86y/?view_only=194cac839f8c4226af108794e4949d88.
––––––––––––––––––––––––––––––––– MPLUS CODE FOR EMPIRICAL EXAMPLE
DATA:
File is scores_within.dat;
VARIABLE:
NAMES = LONE ONLINE DEP2 HOURS LONE_W ONLINE_W
B_LONE B_LONE_SE B_ONLINE B_ONLINE_SE ID;
CLUSTER = ID;
USEVAR = Dep2 lone online inter;
LAGGED = Dep2(1) lone(1) online(1) inter(1);
TINTERVAL = hours(4);
MISSING = *;
DEFINE:
!specify interaction of within-person components! of loneliness and time spent on social media inter = lone_W * online_W;
ANALYSIS:
TYPE IS TWOLEVEL RANDOM;
ESTIMATOR = BAYES;
FBITER = 2000;
chains = 2;
THIN = 10;
Processor = 4;
MODEL:
%WITHIN%
!Within-person component
!Autoregressive effects
!Random slopes: t regressed on t-1
p_oo | online ON online&1;
p_dd | Dep2 ON Dep2&1;
p_ll | lone ON lone&1;
p_do | Dep2 ON online&1;
p_dl | Dep2 ON lone&1;
p_lo | lone ON online&1;
p_ol | online ON lone&1;
p_ld | lone ON Dep2&1;
p_od | online ON Dep2&1;
p_int | Dep2 ON inter&1;
inter ON inter&1;
!allow within-person residuals to be correlated
online with lone;
online with Dep2;
lone with Dep2;
%BETWEEN%
!allow random effects and between-person! components to be correlated
p_oo-p_int online lone Dep2 WITH p_oo-p_int online lone Dep2;
OUTPUT:
STDYX TECH8;
–––––––––––––––––––––––––––––––
Results
The DSEM showed stable convergence after 500 iterations and suggested little relative bias (<2%) as indicated by nearly identical results (e.g., b = −0.075 vs. b = −0.079 for the moderation effect) between the model estimated using 500 iterations and the model estimated using 2000 iterations. Results of the DSEM suggested that people differed in loneliness, time spent on social media and depression at baseline. Additionally, we observe autoregressive effects for each of the three variables, that differed in strength, suggesting carry-over effects from one moment to the next that differed between people (Fried et al., Citation2021). The DSEM further suggested that momentary increases in depression were associated with increases in time spent online on social media (b = 0.076, 95% CI = [0.012, 0.133]), and increases in loneliness were associated with increases in depression from one moment to the next (b = 0.119, 95% CI = [0.074, 0.161]). This association was significantly moderated by time spent on social media with increasing time spent on social media being associated with a reduction in the strength of the association between momentary loneliness and depression (b = −0.079, 95% CI = [–0.125, −0.028]). Thus, using a within-person DSEM moderation analysis, for the first time, we were able to show that spending more time than usual on social media can to some extent mitigate the negative effect of increases in loneliness on depressive symptoms. Given that the predictors were person-mean centered before calculating the interaction term, an alternative interpretation is that the association between loneliness and depressive symptoms is also reduced for those low in loneliness who spend less time than usual on social media. A summary of significant within-person effects is presented in . For distribution of random effect estimates for the effect of loneliness on depressive symptoms and bivariate associations between random effect estimates for the effect of loneliness on depressive symptoms and the within-person component of time spent on social media, see Supporting Information Figures S2 and S3. Full model results are provided on OSF: https://osf.io/tv86y/?view_only=194cac839f8c4226af108794e4949d88.
Figure 5. Multilevel dynamic structural equation model visualizing the within-person associations between loneliness, depression, and online social interactions. Nonsignificant paths, residual variances, co-variances, and factor variances are omitted for clarity. (W) represents within-person estimates. Black dots indicate random effects. μ = Means, D = Depression, L = Loneliness, O = Time spent online using social media.
Additionally, we tested whether fixing the autoregressive effect for the interaction term to zero as it likely is not practically meaningful would lead to changes in parameter estimates. In the model with the autoregressive effect for the interaction term fixed to zero, the pattern of results was essentially the same, however, the estimates for other autoregressive effects were slightly higher, indicating that some of the autoregressive effect of the product term had been absorbed by other parameters. This suggests that fixing the autoregressive effect for the interaction term to zero could potentially lead to slightly inflated effect sizes for other parameters and should only be done if computational constraints make it necessary. Comparisons of Deviance Information Criterion (DIC) also supported the inclusion of the freely estimated autoregressive effect (ΔDIC = 1093.103) Full results of the model with the autoregressive parameter for the product term fixed to zero are available on OSF. https://osf.io/tv86y/?view_only=194cac839f8c4226af108794e4949d88.
Simulation study
We tested whether our proposed analysis technique may lead to the detection of spurious interaction effects in a simulation study. Specifically, we investigated the type I error of our analysis approach under conditions where no true within-person moderation effect was present.
Using an external Monte Carlo procedure in Mplus, we first generated 100 simulated data sets under a population model that did not include a within-person moderation effect. For our approach to be usable in empirical applications, we would want moderation effects to be detected at rates commensurate with the chosen threshold of significance (e.g., 0.05). We set our sample size to be comparable to our empirical example (N = 80; T = 60). Autoregressive effects were set to 0.2, cross-lagged effects to 0.1, and residual covariances between x, y, and m to 0.2 to correspond approximately to the effect sizes observed in the above presented empirical example. In a second step, we fit our analysis model to all simulated data sets, following the steps outlined above for investigating within-person moderation effects in DSEM. To identify type 1 errors, we tested whether the modeled moderation effect was different from zero using Wald tests. The type I error rate was calculated as the proportion of simulated data sets in which the Wald test suggested a significant interaction effect. A type I error rate of below 5% was deemed acceptable.
Results of this simulation study suggested that our analysis approach exhibited a type I error rate in line with our intended significance level of 0.05. Across the 100 simulated data sets, the proportion of cases where the Wald test yielded a significant interaction effect as indicate by chi-square values above 3.841 (critical value based on 1 Degrees of Freedom) was below 5% (observed proportion of significant results: 4%). This suggests that the here proposed method for detecting within-person moderation effects has high specificity. Furthermore, results of the simulation study suggested that the analysis model accurately recovered the simulated autoregressive and cross-lagged parameters (relative bias > 0.9 and <1.1, with 1 indicating no bias), thus, providing evidence for appropriate type I error control and unbiased parameter estimates under a null moderation effect. Full results of our simulation study and simulation code is available on OSF: https://osf.io/tv86y/?view_only=194cac839f8c4226af108794e4949d88.
Discussion
The present article demonstrated how classical use of DSEM can be extended to incorporate the analysis of moderation effects at the within-person level using intensive longitudinal data within a dynamic structural equation modeling framework as implemented in Mplus. To illustrate the implementation procedures for estimating such effects, we used an empirical example investigating whether within-person deviations from time spent engaging with social media moderated the within-person associations between loneliness and depressive symptoms. Empirical results suggested that increasing the time spent on social interactions reduces the strength of the association between increases in loneliness and subsequent increases in depressive symptoms. This suggests that engagement with social media may act as a mitigating factor in reducing the negative effects of increases in loneliness on depressive symptoms. Given the rise in collection of intensive longitudinal data, we believe that the analysis of within-person moderation effects as illustrated here is likely to be of benefit to a range of researchers. Such analyses not only allow for the testing of existing hypotheses but will further encourage the consideration of moderation effects in advancing existing and developing new theories about within-person processes.
When interested in moderation effects, researchers first and foremost need to ensure that they are clear with regards to whether their theories and hypotheses refer to processes unfolding at the between- or at the within-person level. The analysis of moderation effects operating at the between-person level, such as for instance whether gender changes the strength of the associations between the development of symptoms of anxiety in response to experiencing stress, has been illustrated in previous methods papers (Hamaker et al., Citation2018). Here, we focused on the analysis of moderation effects unfolding purely at the within-person level, that is, we illustrated the modeling of how changes in a variable relative to a person’s average affects the associations between within-person changes in two other variables. Such processes may be relevant in a wide variety of different research contexts. For instance, within mental health research, hypotheses may refer to how changes in modifiable factors such as dietary habits or physical activity levels influence the associations between experiencing a stressor and developing symptoms of anxiety or depression. In cognitive neuroscience, hypotheses may refer to how the degree to which specific brain regions communicate with each other relates to changes in other factors such as sleeping behaviors. To allow other researchers to apply such within-person moderation analyses to their own research questions, we have included fully commented code on the Open Science Framework.
While the analysis of within-person moderation effects illustrated here has strong potential for illuminating processes captured by intensive longitudinal data, these analyses currently come with some important limitations. Specifically, the variables involved in the within-person interactions currently have to be extracted as factor scores representing level-one residuals in a separate analysis step to be able to calculate the product term based on the latent-mean centered predictors. We then used the uncentred predictor and moderator (i.e., the raw data rather than extracted factor scores) for the calculation of the main effects in the DSEM model to circumvent limitations surrounding the use of factor scores as much as possible. However, this also means that the analysis overall may be utilizing different latent-means when creating the interaction term (i.e., in the factor score extraction) and when latent-mean centering the predictors for calculating the main effects (i.e., in the final DSEM model). It should be noted that the extraction of factor scores is currently based on a simple multilevel scenario, and as such does not take into account the temporal nature of the included variables and potential unequal spacings between measurement occasions. In cases where differences in intervals and missingness are substantial, researchers should consider the TINTERVAL option in combination with a Kalman filter for addressing missingness (see e.g., McNeish & Hamaker, Citation2019). A crucial line of future research using both simulation studies and empirical applications is to investigate which set of analytical choices ensures best model estimation in terms of convergence, parameter estimation and inference.
With regards to the use of factor scores for calculating the product term, it further needs to be noted that these within-person components are then treated as observed variables, rather than being treated as latent variables. This assumes perfect measurement of an imperfectly estimated variable which is problematic given that measurement error may lead to biased estimates, likely even more so for product terms as these are formed from two imperfectly measured variables, thus, exacerbating measurement error (Sardeshmukh & Vandenberg, Citation2017). Even though this makes it all the more important for measurement error to be addressed appropriately in the analyses of moderation effects, in the literature, using observed rather than latent variables when testing interaction hypotheses is a fairly common practice. A recent study suggested that only 20% of researchers using latent variable models also specify interaction terms as latent variables. This practice has been attributed to researchers having difficulties in operationalizing interaction tests in available statistical software (Cortina et al., Citation2021). Research on implementing latent variable interactions has been rapidly developing, for instance now allowing for a relatively straightforward implementation of latent variable interactions in a single-level scenario in Mplus (Asparouhov & Muthen, Citation2019), or developing new techniques, such as Croon’s bias corrected estimation for addressing measurement error when using factor scores for the analyses of interaction hypotheses (Cox & Kelcey, Citation2021). However, there is still a way to go in the implementation of such techniques in the context of within-person moderation analyses using intensive longitudinal data. Specifically, software limitations prevented us from conducting our analyses in a single step to properly propagate uncertainty. Instead, we used a two-step procedure, analogous to fitting a measurement model prior to a structural model, also called structure-after-measurement approach. Some research has suggested that such an approach may not necessarily perform worse than one-step approaches and may in fact come with some advantages including estimates being more robust against local misspecifications and models exhibiting smaller finite sample biases (see e.g., Rosseel & Loh, Citation2022). Nevertheless, a one-step estimation, i.e., testing the interaction effect in the same step as extracting the within-person components needed for forming the product term, would be beneficial as this would enable users to account for uncertainty in the newly formed product term and would, thus, help reduce potential bias in estimates due to measurement error. Ideally, the DSEM toolbox available in Mplus should be expanded to allow for a one step estimation of within-person interaction effects. Alternatively, research exploring bias correction techniques for latent variable interactions using factor scores in the context of multilevel data, including advancing software to allow for evaluating the quality of factor scores (such as deriving indices for factor score determinacy), may also hold promise as a potential solution for addressing measurement error challenges. Future research may also want to explore alternative means of modeling interaction effects using for instance the flexibilities provided by Residual Dynamic Structural Equation Modeling (RDSEM) (see Asparouhov & Muthén, Citation2020b).
With regards to the empirical example, it is important to note that we treated our variables as continuous even though, given their distributions, it may have been more appropriate to treat them as ordinal. However, prior research has suggested that analyses treating ordinal data with at least five levels as continuous is usually sensible if data are approximately normally distributed (Rhemtulla et al., Citation2012), with estimators for ordinal and/or categorical data in fact often performing worse than estimators for continuous data unless sample sizes are very large (Olsson et al., Citation2000; Schermelleh-Engel et al., Citation2003). Also considering the complexity of the analyses, it was deemed infeasible to treat the here used variables as ordinal variables. This is an important area for future research, especially in the context of complex models with small sample sizes.
In this context, it should be noted that, due to software limitations, we were not able to conduct a comprehensive simulation study to evaluate both type I and type II error rates. Results from our present simulation study testing for type I error provide initial validation for the integrity of our approach in scenarios where moderation effects are absent. However, further investigations are warranted to explore whether parameter estimates from the here presented analysis approach are indeed accurately recovering real within-person moderation effects, in parallel with the development of software capabilities to do so.
Future research may also extend the here presented analyses to implement testing for three-way interactions, combine mediation and moderation analyses to test for moderated mediation and work on data visualization tools for within-person interactions. Also, as of now, DSEM models cannot be easily implemented in software other than Mplus. Future methods development should focus on offering readily accessible tools for implementing DSEM models in open-source software such as R. Some work on this is already underway, see Ziedzor (Citation2022) for an implementation of DSEM in RStan.
Finally, it is crucial to highlight that additional research is essential for addressing various unresolved issues in modeling intensive longitudinal data. Among these open areas of investigation are questions regarding the optimal approach to (latent) mean centering of variables, the impact of time intervals, particularly in instances of uneven measurement occasions and potential concurrent effects (see e.g., Muthen & Asparouhov, Citation2023), and the broader challenges associated with uncertainty propagation, within both intensive longitudinal modeling as well as classical SEM (Rosseel & Loh, Citation2022).
Conclusion
The analysis of moderation effects at the within-person level using intensive longitudinal data has great potential for illuminating the moment-to-moment dynamics that underly emotional and behavioral processes. Implemented within a dynamic structural equation modeling framework available in the SEM software Mplus, such analyses enable researchers to better isolate, estimate and interpret the complexities of within-person interaction effects.
Article information
Conflict of interest disclosures: Each author signed a form for disclosure of potential conflicts of interest. No authors reported any financial or other conflicts of interest in relation to the work described.
Ethical principles: The authors affirm having followed professional ethical guidelines in preparing this work. These guidelines include obtaining informed consent from human participants, maintaining ethical treatment and respect for the rights of human or animal participants, and ensuring the privacy of participants and their data, such as ensuring that individual participants cannot be identified in reported results or from publicly available original or archival data. The data collected forming the empirical component of this study received ethical approval from the Ethics Board of Leiden University, Faculty of Social and Behavioral Sciences.
Funding: This work was not supported. Rogier Kievit is funded by a Hypatia fellowship (RadboudUMC). Lydia Speyer and Aja Murray have no funding to declare for this study.
Role of the funders/sponsors: None of the funders or sponsors of this research had any role in the design and conduct of the study; collection, management, analysis, and interpretation of data; preparation, review, or approval of the manuscript; or decision to submit the manuscript for publication.
Acknowledgments: The ideas and opinions expressed herein are those of the authors alone, and endorsement by the author’s institutions is not intended and should not be inferred.
Supplemental Material
Download MS Word (187 KB)Additional information
Funding
References
- Aknin, L. B., De Neve, J.-E., Dunn, E. W., Fancourt, D. E., Goldberg, E., Helliwell, J. F., Jones, S. P., Karam, E., Layard, R., Lyubomirsky, S., Rzepa, A., Saxena, S., Thornton, E. M., VanderWeele, T. J., Whillans, A. V., Zaki, J., Karadag, O., & Ben Amor, Y. (2022). Mental health during the first year of the COVID-19 pandemic: A review and recommendations for moving forward. Perspectives on Psychological Science, 17(4), 915–936. https://doi.org/10.1177/17456916211029964
- Aristodemou, M., Rommelse, N., & Kievit, R. (2022). Attentiveness modulates reaction-time variability: Findings from a population-based sample of 1032 children. PsyArXiv. https://doi.org/10.31234/osf.io/j2n5w
- Asparouhov, T., Hamaker, E. L., & Muthén, B. (2018). Dynamic structural equation models. Structural Equation Modeling, 25(3), 359–388. https://doi.org/10.1080/10705511.2017.1406803
- Asparouhov, T., & Muthen, B. (2019). Latent variable interactions using maximum-likelihood and Bayesian estimation for single- and two-level models. Mplus Web Notes.
- Asparouhov, T., & Muthén, B. (2020a). Bayesian estimation of single and multilevel models with latent variable interactions. Structural Equation Modeling: A Multidisciplinary Journal, 28(2), 314–328. https://doi.org/10.1080/10705511.2020.1761808
- Asparouhov, T., & Muthén, B. (2020b). Comparison of models for the analysis of intensive longitudinal data. Structural Equation Modeling: A Multidisciplinary Journal, 27(2), 275–297. https://doi.org/10.1080/10705511.2019.1626733
- Barton, J., & Rogerson, M. (2017). The importance of greenspace for mental health. BJPsych International, 14(4), 79–81. https://doi.org/10.1192/S2056474000002051
- Blanke, E. S., Neubauer, A. B., Houben, M., Erbas, Y., & Brose, A. (2021). Why do my thoughts feel so bad? Getting at the reciprocal effects of rumination and negative affect using dynamic structural equation modeling. Emotion (Washington, DC), 22(8), 1773–1786. https://doi.org/10.1037/EMO0000946
- Brown, R., Speyer, L. G., Eisner, M., Ribeaud, D., & Murray, A. L. (2022). Exploring the effect of ADHD traits on the moment-to-moment interplay between provocation and aggression: Evidence from dynamic structural equation modelling. 49(5), 469–479. https://doi.org/10.1002/ab.22081
- Cortina, J. M., Markell-Goldstein, H. M., Green, J. P., & Chang, Y. (2021). How are we testing interactions in latent variable models? Surging forward or fighting shy? Organizational Research Methods, 24(1), 26–54. https://doi.org/10.1177/1094428119872531
- Cox, K., & Kelcey, B. (2021). Croon’s bias-corrected estimation of latent interactions. Structural Equation Modeling, 28(6), 863–874. https://doi.org/10.1080/10705511.2021.1922283
- Erzen, E., & Çikrikci, Ö. (2018). The effect of loneliness on depression: A meta-analysis. The International Journal of Social Psychiatry, 64(5), 427–435. https://doi.org/10.1177/0020764018776349
- Evans, S. W., Pelham, W. E., Smith, B. H., Bukstein, O., Gnagy, E. M., Greiner, A. R., Altenderfer, L., & Baron-Myak, C. (2001). Dose–response effects of methylphenidate on ecologically valid measures of academic performance and classroom behavior in adolescents with ADHD. Experimental and Clinical Psychopharmacology, 9(2), 163–175. https://doi.org/10.1037/1064-1297.9.2.163
- Fried, E. I., Papanikolaou, F., & Epskamp, S. (2021). Mental health and social contact during the COVID-19 pandemic: An ecological momentary assessment study. Clinical Psychological Science, 10(2), 340–354. https://doi.org/10.1177/21677026211017839
- Gassen, J., Nowak, T. J., Henderson, A. D., & Muehlenbein, M. P. (2022). Dynamics of temperature change during experimental respiratory virus challenge: Relationships with symptoms, stress hormones, and inflammation. Brain, Behavior, and Immunity, 99, 157–165. https://doi.org/10.1016/j.bbi.2021.10.001
- Gnam, J.-P., Loeffler, S.-N., Haertel, S., Engel, F., Hey, S., Boes, K., Woll, A., & Strahler, J. (2019). On the relationship between physical activity, physical fitness, and stress reactivity to a real-life mental stressor. International Journal of Stress Management, 26(4), 344–355. https://doi.org/10.1037/str0000113
- Hamaker, E. L., Asparouhov, T., Brose, A., Schmiedek, F., & Muthén, B. (2018). At the frontiers of modeling intensive longitudinal data: Dynamic structural equation models for the affective measurements from the COGITO Study. Multivariate Behavioral Research, 53(6), 820–841. https://doi.org/10.1080/00273171.2018.1446819
- Hamaker, E. L., & Wichers, M. (2017). No time like the present: Discovering the hidden dynamics in intensive longitudinal data. Current Directions in Psychological Science, 26(1), 10–15. https://doi.org/10.1177/0963721416666518
- Hodgson, S., Watts, I., Fraser, S., Roderick, P., & Dambha-Miller, H. (2020). Loneliness, social isolation, cardiovascular disease and mortality: A of the literature and conceptual framework. Journal of the Royal Society of Medicine, 113(5), 185–192. https://doi.org/10.1177/0141076820918236
- Jebb, A. T., Tay, L., Wang, W., & Huang, Q. (2015). Time series analysis for psychological research: Examining and forecasting change. Frontiers in Psychology, 6(Jun), 727. https://doi.org/10.3389/FPSYG.2015.00727/ABSTRACT
- Lüdtke, O., Marsh, H. W., Robitzsch, A., Trautwein, U., Asparouhov, T., & Muthén, B. (2008). The multilevel latent covariate model: A new, more reliable approach to group-level effects in contextual studies. Psychological Methods, 13(3), 203–229. https://doi.org/10.1037/A0012869
- McCormick, E. M., Cambridge Centre for Ageing and Neuroscience, & Kievit, R. A. (2023). Poorer White Matter Microstructure Predicts Slower and More Variable Reaction Time Performance: Evidence for a Neural Noise Hypothesis in a Large Lifespan Cohort. The Journal of neuroscience : the official journal of the Society for Neuroscience, 43(19), 3557–3566. https://doi.org/10.1523/JNEUROSCI.1042-22.2023
- McNeish, D. (2016). On using Bayesian methods to address small sample problems. Structural Equation Modeling, 23(5), 750–773. https://doi.org/10.1080/10705511.2016.1186549
- McNeish, D., & Hamaker, E. L. (2019). A primer on two-level dynamic structural equation models for intensive longitudinal data in Mplus. Psychological Methods, 25(5), 610–635. https://doi.org/10.1037/met0000250
- McNeish, D., & Mackinnon, D. P. (2022). Intensive longitudinal mediation in Mplus. Psychological methods. Advance online publication. https://doi.org/10.1037/met0000536
- Metcalf, O., Little, J., Cowlishaw, S., Varker, T., Arjmand, H.-A., O'Donnell, M., Phelps, A., Hinton, M., Bryant, R., Hopwood, M., McFarlane, A., & Forbes, D. (2021). Modelling the relationship between poor sleep and problem anger in veterans: A dynamic structural equation modelling approach. Journal of Psychosomatic Research, 150, 110615. https://doi.org/10.1016/j.jpsychores.2021.110615
- Muthen, B., Asparouhov, T. (2023). Can cross-lagged panel modeling be relied on to establish cross-lagged effects? The case of contemporaneous and reciprocal effects. http://www.statmodel.com/download/ReciprocalV3.pdf
- Muthén, L. K., & Muthén, B. (1998–2017). Mplus user’s guide (8th ed.). Muthen & Muthen.
- Neubauer, A. B., Brose, A., & Schmiedek, F. (2022). How within-person effects shape between-person differences: A multilevel structural equation modeling perspective. Psychological Methods, 28(5), 1069–1086. https://doi.org/10.1037/met0000481
- Nickell, S. (1981). Biases in dynamic models with fixed effects. Econometrica, 49(6), 1417. https://doi.org/10.2307/1911408
- Olsson, U. H., Foss, T., Troye, S. V., & Howell, R. D. (2000). The performance of ML, GLS, and WLS estimation in structural equation modeling under conditions of misspecification and nonnormality. Structural Equation Modeling, 7(4), 557–595. https://doi.org/10.1207/S15328007SEM0704_3
- Palmer, C. A., & Alfano, C. A. (2017). Sleep and emotion regulation: An organizing, integrative review. Sleep Medicine Reviews, 31, 6–16. https://doi.org/10.1016/j.smrv.2015.12.006
- Rhemtulla, M., Brosseau-Liard, P. É., & Savalei, V. (2012). When can categorical variables be treated as continuous? A comparison of robust continuous and categorical SEM estimation methods under suboptimal conditions. Psychological Methods, 17(3), 354–373. https://doi.org/10.1037/a0029315
- Rosseel, Y., & Loh, W. W. (2022). A structural after measurement approach to structural equation modeling. Psychological Methods. Advance online publication. https://doi.org/10.1037/met0000503
- Ryu, E. (2015). The role of centering for interaction of level 1 variables in multilevel structural equation models. Structural Equation Modeling, 22(4), 617–630. https://doi.org/10.1080/10705511.2014.936491
- Sardeshmukh, S. R., & Vandenberg, R. J. (2017). Integrating moderation and mediation: A structural equation modeling approach. Organizational Research Methods, 20(4), 721–745. https://doi.org/10.1177/1094428115621609
- Schermelleh-Engel, K., Moosbrugger, H., & Müller, H. (2003). Evaluating the fit of structural equation models: Tests of significance and descriptive goodness-of-fit measures. Methods of Psychological Research, 8(2), 23–74.
- Shieh, G. (2010). Clarifying the role of mean centring in multicollinearity of interaction effects. Multivariate Behavioral Research, 45(3), 483–507. https://doi.org/10.1080/00273171.2010.483393
- Shieh, G. (2011). Clarifying the role of mean centring in multicollinearity of interaction effects. The British Journal of Mathematical and Statistical Psychology, 64(3), 462–477. https://doi.org/10.1111/j.2044-8317.2010.02002.x
- Shiyko, M., Naab, P., Shiffman, S., & Li, R. (2014). Modeling complexity of EMA data: Time-varying lagged effects of negative affect on smoking urges for subgroups of nicotine addiction. Nicotine & Tobacco Research, 16 (Suppl 2), S144–S150. https://doi.org/10.1093/ntr/ntt109
- Speyer, L. G., Brown, R. H., Ribeaud, D., Eisner, M., & Murray, A. L. (2022). The role of moment-to-moment dynamics of perceived stress and negative affect in co-occurring ADHD and internalising symptoms. Journal of Autism and Developmental Disorders, 53(3), 1213–1223. https://doi.org/10.1007/S10803-022-05624-W/TABLES/2
- Ziedzor, R. (2022). Dynamic structural equation modeling with Gaussian processes [PhD]. Southern Illinois University. https://www.proquest.com/docview/2681078493/abstract/97233B62180346ADPQ/1
- Zyphur, M. J., Zhang, Z., Preacher, K. J., & Bird, L. J. (2019). Moderated mediation in multilevel structural equation models: Decomposing effects of race on math achievement within versus between high schools in the United States. In The handbook of multilevel theory, measurement, and analysis (pp. 473–494) American Psychological Association. https://doi.org/10.1037/0000115-021