
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Calculating confidence intervals and p-values of edges in networks is useful to decide their presence or absence and it is a natural way to quantify uncertainty. Since lasso estimation is often used to obtain edges in a network, and the underlying distribution of lasso estimates is discontinuous and has probability one at zero when the estimate is zero, obtaining p-values and confidence intervals is problematic. It is also not always desirable to use the lasso to select the edges because there are assumptions required for correct identification of network edges that may not be warranted for the data at hand. Here, we review three methods that either use a modified lasso estimate (desparsified or debiased lasso) or a method that uses the lasso for selection and then determines p-values without the lasso. We compare these three methods with popular methods to estimate Gaussian Graphical Models in simulations and conclude that the desparsified lasso and its bootstrapped version appear to be the best choices for selection and quantifying uncertainty with confidence intervals and p-values.
1. Introduction
Networks are an incredibly versatile tool to model complex systems (Boccaletti, Citation2006). Besides the physical and natural sciences networks have become popular in the social and behavioral sciences (see e.g., Borsboom et al., Citation2011; Cramer et al., Citation2010; De Ron et al., Citation2019). One of the main areas of application is psychopathology (e.g., Cramer et al., Citation2016; Fried et al., Citation2016; Robinaugh et al., Citation2019), but networks have also been applied to personality research (Costantini et al., Citation2015), sleep (Blanken et al., Citation2020) and health psychology (Hevey, Citation2018).
Most networks are currently estimated with the least absolute shrinkage and selection operator (lasso), which shrinks all parameter estimates toward zero and sets very small estimates to exactly zero (e.g., Epskamp et al., Citation2018b; Epskamp & Fried, Citation2018; Haslbeck & Waldorp, Citation2015; Citation2020; van Borkulo et al., Citation2014). The lasso thereby does not only provide parameter estimates but also selects which edges are included in a network. This property makes this estimator very attractive, but it also has downsides. First, due to the shrinkage (bootstrapped) sampling distributions are biased and distorted and do not allow one to compute frequentist confidence intervals (CIs; Bühlmann & Meinshausen, Citation2014; Williams, Citation2021). However, CIs would be a useful and straightforward way to quantify the uncertainty about parameter estimates that is currently missing in frequentist network estimation. Second, the lasso has good properties (i.e., low false and high true positive rates) if its assumptions are met (e.g., Hastie et al., Citation2019). However, when those assumptions are not met, alternative methods might be preferable that have fewer and less strong assumptions, which may be more plausible in empirical situations, such as ridge regression (Bühlmann et al., Citation2013; Hoerl & Kennard, Citation1970) or best subset regression (Bertsimas et al., Citation2016; Brusco et al., Citation2022a; Hastie et al., Citation2017).
In this article, we investigate three methods to perform inference using the lasso, which allow us to obtain unbiased CIs and perform network inference with fewer assumptions than the lasso. Specifically, we will consider the multi-split method (Javanmard & Montanari, Citation2014; Meinshausen et al., Citation2009; Zhang & Zhang, Citation2014), the desparsified lasso (van de Geer et al., Citation2014), and a bootstrap version of the desparsified lasso (Dezeure et al., Citation2015). Although there are other methods to obtain correct inference with the lasso, such methods are either very similar to the ones we selected (Taylor & Tibshirani, Citation2018, extended results from Lee et al., Citation2016 and Lockhart et al., Citation2014), or they appear less appropriate considering the assumptions (Lu et al., Citation2017). We review the assumptions of the multi sample-split and desparsified based approaches, and we evaluate the performance of each of the methods and other popular methods in a simulation study. In the simulation, we recover Gaussian Graphical Models (GGMs), showing that the desparsified lasso performs best. Finally, we provide a fully reproducible R-tutorial on how to use the desparsified lasso to estimate a GGM on a dataset of post-traumatic stress disorder symptoms.
2. Gaussian graphical models
A Gaussian graphical model (GGM) is an undirected graph (network) where the nodes represent the variables and the edges represent conditional dependence, or, what is equivalent for Gaussian random variables, conditional correlation (Maathuis et al., Citation2018). The nodes in the network are labeled by integers and this set of node labels is referred to as V. The edges of the network are denoted by
for nodes i and j. An example of a network is shown in .
To each node j, we associate a random variable for
The edges between the variables in the network indicate conditional independence: if there is no edge between node i and j, then variables
and
are independent given all other remaining variables
which we write as
(Dawid, Citation1979). The combination of the network and a distribution over all random variables
is called a graphical model. When the multivariate distribution over all random variables is Gaussian (normal), we call the network together with the distribution a Gaussian Graphical Model (GGM). In Appendix A, we provide more details on the GGM, including a small example illustrating the relation between the partial covariance and conditional independence. Here, we suffice with a brief summary of the most relevant properties.
It turns out that whenever the correlation between the variables
and
is
then there is a path of edges in the network between nodes i and j (Jones & West, Citation2005). However, we cannot determine what the path is by considering only correlations. We must investigate partial correlations (or partial covariances), i.e., correlations where all other variables are kept fixed (i.e., conditioned on). This way the influence of the other variables is removed, and the correlations between two residuals after regressing out all other variables is considered (Koller & Friedman, Citation2009). The partial covariance between
and
given all other remaining variables is denoted by
Lauritzen (Citation1996, Proposition 5.2) proved that if the partial covariance between variables
and
is 0, i.e.,
then the two variables are independent conditional on all other remaining variables
without
Because the partial correlation is a scaled version of the partial covariance, we may also determine whether the partial correlation is 0 to conclude that two variables are conditionally independent. Consequently, by knowing which two variables have 0 partial covariance (or 0 partial correlation), we know which variables should not be connected in the network. Each of the non-zero partial covariances between two variables will obtain an edge in the network.
3. Estimation of GGM with the lasso
To determine whether the partial covariance is 0, we first need to estimate it from the data. It is convenient to determine the partial covariances nodewise, i.e., estimate the coefficients of the connected nodes for each node separately. This is often referred to as neighborhood or nodewise selection (Hastie et al., Citation2015). The complete network can be considered as a set of neighborhoods, where each neighborhood is the set of nodes that is connected to a particular node. Consider , where node 1 is selected and the neighborhood consists of nodes 2 and 3, and not 4. If we obtain the neighborhoods for all nodes, then we can stitch these together and obtain the entire network. This has the advantage that we can use the linear regression framework. The regression of node i on the remaining nodes
is
where the sum is over all nodes j except i (which is now the dependent variable),
are the regression coefficients, and
is the residual of node i, which we assume to normally distributed with variance
and independent from other variables. We explicitly use the indices ij in the coefficient
to make clear that it is about the relation between nodes i and j in the network. The reason we can use this regression framework is because of the relation between the coefficient
and the partial covariance
which is (Lauritzen, Citation1996; Waldorp & Marsman, Citation2022);
So, if then also
In the example of , we first select variable
as the dependent variable and predict it by
and
If
then we do not draw an edge between
and
If
and
are non-zero, then the edges between
and
between
and
are drawn.
Estimation is often performed by using a penalized form like the least absolute shrinkage and selection operator (lasso, Tibshirani, Citation1996). For regression with the lasso, the coefficients for each node i are obtained by a combination of least squares and a penalty, the sum of absolute values of the coefficients weighted by a penality parameter (see Appendix B for details). A lasso estimate for
is denoted by
The lasso has the advantage that by estimating the coefficients
the coefficients are also selected because some of the estimated coefficients will be exactly 0 (Bühlmann & van de Geer, Citation2011; Tibshirani, Citation1996). Additionally, the lasso has the advantage that it decreases prediction error (i.e., the error between prediction using the estimate and the true parameter, Hastie et al., Citation2015). The lasso penalty parameter, usually denoted by
needs to be determined, and so, an estimate depends on the value
chosen. Specifically, larger values of
result in stronger regularization. Often the value for
is obtained by using cross-validation (see Appendix B).
It has been shown that the lasso obtains few false positives and many true positives (Wainwright, Citation2009), but this requires several assumptions. The assumptions are
the true parameter vector is sparse i.e., the number of non-zero coefficients in the true parameter vector is at most s, which is much smaller than the number of observations n,
the variables are not too highly correlated i.e., the variables are not collinear,
the correlation between connected and not connected variables cannot be 1 (incoherence), and
non-zero coefficients must be at least larger than some small value
Especially the last assumption about small values in the true parameter is problematic because with the lasso we have to assume that these do not exist (Dezeure et al., Citation2015). We review the assumptions in more detail in Appendix B.
4. Inference for GGM estimated with the lasso
We are interested in obtaining p-values or confidence intervals after we have selected a particular model with the lasso. Those are useful because they are a natural way to quantify uncertainty about parameter estimates. However, we will also see that selecting edges with p-values can be advantageous if the assumptions of the lasso are violated. In what follows we focus on p-values but we provide details on obtaining confidence intervals in Appendix G.
We first discuss the regular (non-penalized) situation to obtain p-values. An estimate for the parameter
obtained with least squares (see Appendix B) has a normal distribution (if the errors are normally distributed, which we assume here). And so we can use the standard error
(the standard deviation of the distribution of
) to obtain a p-value. The corresponding hypotheses for each parameter j for the ith regression are the null and alternative hypotheses, respectively
(1)
(1)
For each of these hypotheses, we obtain a p-value (see Appendix C). Since a network has many edges to be tested, the family wise error rate increases with the number of tests, i.e., the problem of multiple testing arises. We use the Bonferroni-Holm procedure (Hochberg & Tamhane, Citation1987) for multiple testing correction (see Appendix C for details on calculating corrected p-values with the Bonferroni-Holm procedure).
The problem with inference using the lasso is that, in general, the distribution of the parameter estimates obtained with the lasso is rather difficult (Bühlmann et al., Citation2013; Knight & Fu, Citation2000; Pötscher & Leeb, Citation2009). The issue is that because lasso estimates can be exactly zero, the limiting (as
) distribution is discontinuous and may have probability one at zero whenever the true parameter value is zero (Dezeure et al., Citation2015; Knight & Fu, Citation2000). As a consequence, standard methods for calculating standard errors are not possible (Tibshirani, Citation1996) and also standard bootstrap methods do not work (Chatterjee & Lahiri, Citation2011; Knight & Fu, Citation2000).
We illustrate the issue in with computing confidence intervals based on bootstrap samples from lasso estimates. Here, we considered a GGM with variables and nine nonzero partial correlations
up to
In the top panel of , we display the sampling distributions obtained from the lasso estimates with
and
bootstrap samples for partial correlations of sizes
0.2 and 0.5. Clearly, the sampling distributions are not normally distributed like the ones of the unbiased OLS estimator in the bottom row. For example, for
all estimates are zero and for
a large number of estimates are zero, then there is a gap, and then the rest of the estimates are distributed roughly around 0.1.
A central issue with these biased sampling distributions is that their quantiles do not correspond to frequentist confidence intervals, which have the property that they include the true parameter with probability (i.e., coverage). This probability can be approximated by computing many CIs, but from the top panel of , we can already see that the coverage will be much lower than desired. This is especially a problem for true parameters that are not close to zero. For example, the 95% quantiles of the biased sampling distribution of
are 0.341 and 0.488, which does not include the true parameter 0.5. The lower panel shows sampling distributions of the unbiased least squares estimates (see Appendix G). We see that the sampling distributions are roughly centered around the true estimates, which already suggests a higher coverage rate, and of course for unbiased sampling distributions the expected coverage is exactly
(in the case of a correct GGM). Williams (Citation2021) provides a simulation study that maps out the coverage of confidence intervals based on standard lasso estimates (without thresholding) in the regression and GGM context in more detail.
If we are interested in unbiased sampling distributions, why do we not simply perform inference with the standard OLS estimates? There are two reasons for this. First, we could have approximately the same number of nodes as the number of observations (e.g., 20 nodes and 50 observations). Such cases are found in situations of clinical populations where subjects are not easily obtained. This means that the number of observations is too low for reliable OLS estimates. Second, if the weaker assumptions of the methods we will consider below are satisfied, we would expect them to outperform inference on OLS estimates. In the simulation study in Section 5, we will see that this is indeed the case.
In the remainder of this section, we discuss the three methods to perform inference with the lasso. In the following section, we evaluate the performance of all methods in a simulation study.
4.1. Multi sample-split of the lasso
To circumvent the problem with the biased distribution of the lasso parameter estimates, the multi sample-split method uses a two-step procedure where in the first step the model is selected using the lasso, and in the second step, the p-values are obtained using a regular non-penalized method. The p-values obtained in the second step are obtained using an independent sample (the sample has been split) and using regular estimation (not lasso) and so can be interpreted in the normal way.
In the single split procedure, the sample is split in two subsets of the original sample, such that contains a random subset of the original sample and
contains the remaining subset of the original sample, so that
and
do not share any element and together
and
are the original sample. The number of elements in
referred to as
is about half of the original sample, i.e.,
is of size
and is approximately the same as
the size of the second half
Then the first half
is used to determine which edges should be included in the network. The second half of the sample
is then used to obtain regular p-values using only those edges in
that have been selected using the first half of the sample, and no penalty like the lasso is required to obtain the p-values with the second half of the sample. It is possible to obtain p-values only if the selected number of edges per node is less than the size of the second sample. The fact that each node is allowed up to
edges is so that the coefficients in the regression are identified.
An advantage of the single sample-split method is that the selection of relevant variables using the first half of the sample is often much smaller than the number of nodes p (i.e., is much smaller than p), so that the p-values can be determined with more accuracy (Meinshausen et al., Citation2009). Another advantage is that obtaining corrected p-values for multiple testing is less conservative (i.e., will lead to smaller p-values) with the single sample-split because the correction factor is the number of selected variables in
which is smaller than
For example, in the Bonferroni-Holm procedure (Hochberg & Tamhane, Citation1987, see also Appendix C), the p-values
are sorted in ascending order, and denoted by
Let m be the number of tests to be performed, here
all edges twice. Then, the Bonferroni-Holm correction for the uncorrected p-value
will be for the regular and single sample-split method, respectively,
where
denotes the number of selected regressors in step 1.
For example, if the network has nodes then we need to test for a total of
edges. Suppose that
edges are retained from the first half of the sample (i.e., we selected 12 edges). Using the above equations, we obtain the Bonferroni-Holm correction factor, for the first p-value
which is 378 for the regular method but only 10 for the single sample-split method. Consequently, without the sample-split selection in the first stage, we would be multiplying the first p-value with 378, while with the multi-split method this factor is reduced to 10 in this example. So, if the assumption is that the network is sparse (does not have too many edges), then this method obtains great gains in the probability to correctly detect edges.
The algorithm for the single sample-split is as follows.
Split the sample in two halves,
and
Apply lasso estimation using only
Set the p-values for the edges that were not selected to 1, and using
Correct the p-values using the number of estimated edges in
The single sample-split method has one great disadvantage, and that is that the way the sample split turns out is random. That means that another split could lead to different p-values (Meinshausen et al., Citation2009). This is undesirable because for one split a p-value for an edge could be small, while for another split for the same edge, the p-value could be large. To avoid such undesirable results, Meinshausen et al. (Citation2009) came up with the idea to run multiple splits and then combine these splits in a single p-value.
In the multi sample-split procedure, the single sample-split is performed K times, so that we obtain for each p-value K versions from a different half-split. This gives a distribution of p-values for each
and a criterion to aggregate these p-values is then based on a quantile from the empirical distribution function (Bühlmann et al., Citation2014; Meinshausen et al., Citation2009). Intuitively, the criterion is based on finding a quantile such that a correction factor is obtained that results in an approximately correct false positive rate (see Appendix D for more details). The main advantage of the multi sample-split is that no single sample-split determines the p-values and, hence, the result is approximately reproducible.
The assumptions for the multi sample-split method are all four assumptions (a)-(d) of the lasso in Section 3. The assumptions lead to the so-called screening property, which is well-known in the literature on high-dimensional statistics (see e.g., Bühlmann et al., Citation2013). It refers to the idea that we may obtain some spurious connections but will not miss-out on any relevant edges. It is clear that for the two-step procedure of the multi sample-split this is important: If in the first step some of the connections are missing, then the correct graph will never be obtained.
4.2. Desparsified lasso
The desparsified lasso makes inference with the lasso possible by modifying the original lasso estimate, adding a term depending on the residuals (Javanmard & Montanari, Citation2014; van de Geer et al., Citation2014). The desparsified lasso estimate no longer has exact 0 values in its estimate and hence is desparsified. The term being added is to remove the bias incurred by using the lasso penalty, and hence, the method is also called the debiased lasso (Bühlmann et al., Citation2014; Waldorp, Citation2014; Williams, Citation2020). The upshot of desparsifying the lasso is that the distribution of the estimate is approximately Gaussian and hence standard errors can be computed, which can be used to calculate p-values. The details of the desparsified lasso are given in Appendix E. The assumptions for the desparsified lasso are sparsity (a) and no collinearity (b) from Section 3.
4.3. Bootstrap of the desparsified lasso
Generally, there are two types of bootstrap in regression: the naive or pairs bootstrap and the residual bootstrap (called resampling cases and model based resampling, respectively, in Davison & Hinkley, Citation1997, Chapter 6). In the pairs (or non-parametric) bootstrap each pair of dependent and independent variables is resampled, with the underlying assumption that these observations have been obtained from a multivariate distribution. In the residual (or parametric) bootstrap, the independent variables are resampled and are then used to create residuals (together with (a model for) the mean). These residuals are, together with the model, used to create resampled versions of the dependent variable. We focus here on the pairs bootstrap, because this fits more with the idea of having obtained data from a network, which clearly assumes an underlying multivariate distribution.
To obtain a bootstrap p-value, an empirical distribution is created by resampling from the original observations with replacement such that for each resample we obtain an estimate. With these estimates, we can create an empirical distribution from which we can obtain a p-value. To estimate the parameters, we use the desparsified lasso because in that case we are assured that an approximate normal distribution underlies the estimates. The pairs bootstrap for a network with n identical observations of all variables is as follows.
Sample randomly from the observations
Perform nodewise regressions using the desparsified lasso to the resampled data
Repeat steps (1) and (2) K times.
Obtain a p-value from the empirical distribution of the K bootstrap versions of
The assumptions of the bootstrap are those required for the desparsified lasso estimates to have a proper distribution. The assumptions of sparsity (a) and no collinearity (b) imply that the estimates have a proper distribution. To obtain accurate p-values, the number of bootstrap resamples should be in the order of at least 500 (Davison & Hinkley, Citation1997, Chapter 2).
4.4. A brief comparison of assumptions
Each of the methods depends on their assumptions, just like the selection of the lasso. In the previous section, assumptions (a)–(d) were mentioned for the lasso to be able to select the correct network. Each of these assumptions is necessary for correct identification of the network edges (see Wainwright, Citation2009, for an excellent discussion on arguments of these assumptions). Except for collinearity, assumption (b), none of the assumptions can be tested empirically. And so, fewer assumptions about the nature of the data generating process are better. provides an overview of the assumptions of each method. It is clear that from the perspective of the number of unwarranted assumptions that the desparsified lasso and the bootstrap based on the desparsified lasso should be preferred.
For reference, we have also included the ordinary least squares (OLS) and graphical lasso (glasso) estimators in . OLS refers to estimation of the edge parameters without constraints (see Appendix B). And glasso refers to estimation of the edge parameters by applying the lasso columnwise to the covariance matrix (Friedman et al., Citation2008a). This is a relatively popular technique, featuring in several R packages like qgraph and huge.
5. Evaluating performance of all methods via simulations
To determine which inference method performs best in determining the structure of GGMs, we evaluated randomly generated networks with 20 nodes and different numbers of observations, i.e., 50, 100, 200, 500, 800 and 1000. Additionally, we varied the number of edges in the network to determine the effect of violating sparsity, and we varied the size of the coefficients of the edges to determine the effect of violating the beta-min assumption.
The edges in the network are randomly placed between two nodes with probability of connection which we set to either
or
Using the common approximation of sparsity
(e.g., Bühlmann et al., Citation2014), we can determine to what extent the sparsity assumption is met on the nodewise level in each simulation condition. For example, for
variables and
only
edges are allowed in the neighborhood of variable i in order for sparsity to be satisfied. For the edge probabilities
or
this implies that the sparsity assumption will on average be violated for 9 and 20 nodes, respectively (for the deails of these calculations see Appendix B). displays for each simulation condition for how many nodes the sparsity assumption is violated.
We learn from the comparison between the sparsity and the number of connections for the nodes that when almost half of the nodes violate the sparsity assumption (a) when
and that all nodes violate the sparsity assumption when
When
the sparsity assumption is not violated in either the network with
or 0.4. These two values of the probability of connection will show the effect of sparsity on the performance of each of the methods.
With this network, we generated partial covariances with coefficients that were randomly drawn from the uniform distribution with values between 0.1 and 0.8. Using the heuristic of the beta-min value
(e.g., Bühlmann et al., Citation2014), we find that for
observations all values are above the heuristic beta-min value of approximately 0.08, while for
the beta-min value is approximately 0.25, indicating that between 70% and 80% of the coefficients are above the beta-min threshold (see ). So, the differences in coefficients allows us to determine the effect of violating the beta-min assumption. With these partial covariances we then generated multivariate normal data (see Appendix H for more details).
We obtained the p-values with one of the three methods: the multi sample-split, the desparsified lasso and the bootstrap (with the desparsified lasso). For each of the three methods, we used the Bonferroni-Holm correction to obtain corrected p-values (see Appendix C) with family wise error rate 0.05. The penalty parameter was obtained with 10-fold cross-validation. In the nodewise regression-based methods, we combined estimates with the and-rule.
In order to evaluate the impact of satisfying different assumptions, we extended the simulation with the lasso with and without additional thresholding (Loh & Wainwright, Citation2012), where we select the nodewise regularization parameter with 10-fold cross-validation (Haslbeck & Waldorp, Citation2020) and a procedure estimating the GGM using standard OLS regression and significance tests with Bonferroni-Holm correction. In addition, we considered the graphical lasso (Friedman et al., 2008b) where we select the global regularization parameter
with the Extended Bayesian Information Criterion (EBIC; Foygel & Drton, Citation2010), due to its popularity in applied research (Epskamp et al., Citation2018a). More details of the settings for the simulation can be found in Appendix H.
We use as measures of performance
and
where
denotes the number of objects with property a. Sensitivity is the same as the true positive rate or recall and measures the proportion of edges correctly identified. Precision is the same as the positive predictive value. Equivalently, precision counts the number of true positives with respect to the number of true and false positives. It, therefore, gives an indication of whether any of the edges that are deemed significant could be false positives. Both measures of accuracy have a value close to 1 to indicate that the method works well. We also consider specificity (#{edge not significant and edge absent}/#{edge absent}), shown in Appendix I.
To determine whether the confidence intervals are accurately estimated, we considered the coverage rate. By investigating the coverage rate, we can determine whether with the specified probability of where we choose
the true parameter is in the confidence interval with probability at least 0.95.
The code to fully reproduce the simulation study and the results below can be found at https://github.com/jmbh/networkinference_reparchive.
5.1. Results
shows the sensitivity (first row) and precision (second row) for the conditions with edge probabilities (left column) and
(right column) for the seven considered estimation methods. With a relatively low number of true edges (
), the ordinary least squares (OLS) and desparsified lasso (Desplasso) both have reasonable sensitivity and high precision. The desparsified lasso has slightly better sensitivity and precision than OLS, especially when the sample size is relatively small. Additionally, the desparsified lasso has less variation in precision than OLS, again especially for the smaller sample sizes. These results are mostly confirmed when considering true absent edges (specificity, see Appendix I). This is to be expected because with OLS smaller coefficients tend to be selected more easily, whereas they are biased toward 0, and hence not selected, with the desparsified lasso.
The bootstrap desparsified lasso is also quite accurate but has slightly lower sensitivity and precision than the desparsified lasso. The multi sample-split has excellent precision but, as a consequence of this excellent precision, has lower sensitivity than the desparsified lasso. The regular lasso has high sensitivity but poor precision. Note that the lasso has a much higher variation in both sensitivity and precision than any of the other methods, which makes it difficult to ascertain in a single dataset if sensitivity is high or not. The lasso will therefore, without thresholding, lead to a high false positive rate. This is to be expected, since the guarantees for the lasso are only obtained when the beta-min assumption is satisfied and, hence, requires thresholding (Wainwright, Citation2009). We performed additional simulations with the lasso and thresholding showing that precision can be much improved upon compared to the lasso without thresholding (lasso thresholded in ). However, applying the Bonferroni-Holm correction to the desparsified lasso has both higher sensitivity and precision than the thresholded lasso. The EBIC glasso has high sensitivity but its precision is relatively low, which drops further as the sample size increases.
With a larger number of edges in the network ( bottom row ), the sensitivity of all methods drops significantly. But even when the sample size is
then the number of edges to each node is about 12 (see ) and no nodes in the graph violate the sparsity assumption. But it is clear that both unregularised (i.e., OLS) and the desparsified lasso estimates suffer from the number of edges to be selected. The performance of OLS and the desparsified lasso is similar, also in the case of sample size
or
Because in these cases, there are no sparsity or beta-min violations, the drop in performance can be attributed to the large number of parameters to be estimated in the model compared to the number of observations. Precision is quite similar for OLS and the desparsified lasso to the case where sparsity holds. The only difference in precision when sparsity does not hold is that for OLS there are some cases that have nearly 0 precision, so none of the selected edges are correct. The drop in performance of the multi-split method shows that splitting the data and then first selecting and then estimating leads to much lower sensitivity. But precision remains high for the multi-split method. The EBIC glasso shows comparable sensitivity as OLS and the desparsified lasso, but the precision of the EBIC glasso is somewhat lower, especially for larger samples, making it a less attractive option.
The bottom row in shows the coverage of the confidence intervals. We see that nearly all types of confidence intervals are accurate, and especially the two versions of the desparsified lasso and OLS have coverage centered around the desired value of 0.95. In contrast, the multi-split method has low coverage. As shown in Appendix I (two lower rows), we notice that this poor performance of the multi-split method is mainly because this method does not cover true absent edges well. The multi-split method was designed for hypothesis testing, and as a result, it does not perform well on coverage of confidence intervals.
In conclusion, the best balance between sensitivity and precision is obtained with OLS and the desparsified lasso (also bootstrapped) with a bit higher precision (lower false positive rate) for the desparsified lasso, especially at lower sample sizes. This leads to a recommendation for the desparsified lasso in general, but more so in cases where the sample size is similar (in order) to the number of expected edges of the nodes. For instance, with 20 nodes and 100 observations we would recommend using the desparsified lasso.
6. Tutorial: Inference on regularized networks with inet
Here, we show how to use the R-package inet to perform inference on the edges of Gaussian graphical models and how to inspect the confidence intervals associated with each edge. We use cross-sectional data on 17 PTSD symptoms of individuals from the study of McNally et al. (Citation2015). These data are loaded automatically with the inet package, which is available on the The Comprehensive R Archive Network (CRAN).
We use the desparsified lasso to perform inference on the edges of a Gaussian graphical model. To do so we use the function lasso_dsp and provide the data and the desired significance level as input:
library(inet) out <- lasso_dsp(data = ptsd_data, ci. level = 0.95)
The output object consists of the point estimates (out$est), the significant point estimates (out$est.signf), a matrix indicating whether each estimate is significant (out$signf), and the lower and upper bounds of the confidence interval (out$ci.lower and out$ci.upper). Next, we create a network visualization of the significant point estimates in out$est.signf using the R-package qgraph: (see )
library(qgraph) qgraph(out$est.signf, labels = colnames(ptsd_data), layout = "spring", edge.labels = TRUE, theme = "colorblind")
Next, we inspect the confidence intervals. Instead of inspecting them manually, they can be plotted using the generic plot() function. Here, we choose to order the parameters by decreasing absolute value of the point estimate (order = TRUE) and to only display the first 50 parameters in that ordering:
plot(object = out, labels = colnames(ptsd_data), order = TRUE, subset = 1:50)
The resulting plot is shown in .
7. Discussion
We have reviewed and evaluated the performance of three different methods to obtain p-values (and confidence intervals) for network estimates: the multi sample-split, the desparsified lasso and the bootstrap based on the desparsified lasso. For comparison, we also included the lasso (with and without thresholding), the glasso with the extended BIC for the selection of the penalty parameter, and ordinary least squares. The desparsified lasso methods have higher sensitivity than OLS at small samples and similar sensitivity at large samples. Additionally, the desparsified lasso methods have less variation in precision than OLS. The reason is that the assumption of sparsity helps to decrease small coefficients (edges) to 0 that are most likely not true edges. In this evaluation we considered the effects of the different assumptions: (a) sparsity, (b) non-collinearity, (c) incoherence, and (d) beta-min. By increasing sample size, we decreased the level of permitted sparsity and the beta-min threshold. Considering the balance between sensitivity and precision from the simulations and having few assumptions, the best method is obtained with the desparsified lasso.
Here, we focused on the lasso for estimation and then desired to obtain correct inference from the lasso estimate. However, as mentioned in the Introduction, if the assumptions of the lasso (a)–(d) are unrealistic for the application at hand, then it might be prudent to consider alternatives. An excellent alternative is ridge regression (Bühlmann et al., Citation2013; Hoerl & Kennard, Citation1970). In ridge regression, the squares of the parameters are used in the penalty, which makes it easier to obtain correct inference (but does not select coefficients like the lasso). Another alternative is the recently suggested best subset regression, where the penalty is simply the number of allowed non-zero coefficients (Bertsimas et al., Citation2016 and Brusco et al., Citation2022a, but see also Hastie et al., Citation2017, for a comparison with the lasso). The best subset selection, like the lasso, selects the number of non-zero coefficients, but inference is also somewhat involved.
Here, we investigated three options for inference when using the lasso: the multi sample-split, the desparsified lasso and a bootstrap version of the desparsified lasso. We discuss each in turn.
The multi sample-split is an intuitive and straightforward method and, therefore, has great appeal. Compared to other methods, however, it has low sensitivity and, it breaks down rather dramatically when the number of true edges is large compared to the number of observations (i.e., the solution is not sparse). This is because the multi-split method halves the data (repeatedly) to select edges and then estimates the p-values. This halving of the sample size has a significant effect on the sensitivity of the multi-split method compared to all other methods. Also, the assumptions required for the multi sample-split are the four assumptions (a)–(d), precisely those that are required for accurate network estimation with the lasso. Both the incoherence (c) and beta-min (d) assumptions are formidable, in that they cannot be tested in practice, and, they assume particular properties of the underlying distribution that can never be guaranteed. Hence, because of poorer performance compared to other methods and the full set of assumptions required, the multi-split method is not recommended in general.
Using the desparsified lasso means that we do not require the assumptions (c) about incoherence and (d) about the smallest detectible coefficient (beta-min). In contrast, the lasso (normal version) does require these two assumptions for correct network selection. The simulations showed that the desparsified lasso has excellent performance when sparsity holds. It performs similarly to unregularised estimation and selection (OLS), and outperforms OLS for small sample sizes. This implies that in any case, assuming sparsity or not, the desparsified lasso appears to be an attractive method for inference.
The bootstrap based on the desparsified lasso shows similar performance as the desparsified lasso. This is similar to the situation without the lasso, where the bootstrap in standard situations (like Gaussian random variables) performs similarly to the parametric versions. In terms of assumptions, these are the same as the desparsified lasso. The theory of the desparsified lasso mostly carries over to generalized linear models (van de Geer et al., Citation2014, Theorem 3.3). Because the loss function is not always convex, more assumptions are required to guarantee the high recall and precision. These assumptions may affect finite sample behavior differently than for the GGM. Statements about finite sample performance with generalized linear models requires further investigation, but for binary random variables (Ising model), some results have been obtained (Brusco et al., Citation2022b; Waldorp et al., Citation2019).
In conclusion, the desparsified lasso and the bootstrap based on the desparsified lasso seem to be the best option for estimating GGMs. In cases where obtaining p-values or confidence intervals is more problematic, the bootstrap based on the desparsified lasso seems to be best.
Article information
Conflict of interest disclosures: The authors report there are no competing interests to declare.
Ethical principles: The authors affirm having followed professional ethical guidelines in preparing this work. These guidelines include obtaining informed consent from human participants, maintaining ethical treatment and respect for the rights of human or animal participants, and ensuring the privacy of participants and their data, such as ensuring that individual participants cannot be identified in reported results or from publicly available original or archival data.
Funding: This work was supported by Gravity project ‘New Science of Mental Disorders’, the Dutch Research Council and the Dutch Ministry of Education, Culture and Science (NWO), grant number 024.004.016.
Role of the funders/sponsors: None of the funders or sponsors of this research had any role in the design and conduct of the study; collection, management, analysis, and interpretation of data; preparation, review, or approval of the manuscript; or decision to submit the manuscript for publication.
Acknowledgements: We would like to thank the editors and reviewers for their constructive comments on our manuscript. The ideas and opinions expressed herein are those of the authors alone, and endorsement by the University of Amsterdam is not implied.
References
- Bertsimas, D., King, A., & Mazumder, R. (2016). Best subset selection via a modern optimization lens. The Annals of Statistics, 44(2), 813–852. https://doi.org/10.1214/15-AOS1388
- Bilodeau, M., & Brenner, D. (1999). Theory of multivariate statistics. Springer-Verlag.
- Blanken, T. F., Borsboom, D., Penninx, B. W., & Van Someren, E. J. (2020). Network outcome analysis identifies difficulty initiating sleep as a primary target for prevention of depression: A 6-year prospective study. Sleep, 43(5), zsz288. https://doi.org/10.1093/sleep/zsz288
- Boccaletti, S., Latora, V., Moreno, Y., Chavez, M., & Hwang, D. (2006). Complex networks: Structure and dynamics. Physics Reports, 424(4-5), 175–308. https://doi.org/10.1016/j.physrep.2005.10.009
- Borsboom, D., Cramer, A. O. J., Schmittmann, V. D., Epskamp, S., & Waldorp, L. J. (2011). The small world of psychopathology. PloS One, 6(11), e27407. https://doi.org/10.1371/journal.pone.0027407
- Brusco, M. J., Steinley, D., & Watts, A. L. (2022b). A comparison of logistic regression methods for ising model estimation. Behavior Research Methods, 55(7), 3566–3584. https://doi.org/10.3758/s13428-022-01976-4
- Brusco, M., Watts, A. L., & Steinley, D. (2022a). A modified approach to fitting relative importance networks. Psychological Methods, https://doi.org/10.1037/met0000496
- Bühlmann, P. (2013). Statistical significance in high-dimensional linear models. Bernoulli, 19(4), 1212–1242. https://doi.org/10.3150/12-BEJSP11
- Bühlmann, P., Kalisch, M., & Meier, L. (2014). High-dimensional statistics with a view toward applications in biology. Annual Review of Statistics and Its Application, 1(1), 255–278. https://doi.org/10.1146/annurev-statistics-022513-115545
- Bühlmann, P., & Meinshausen, N. (2014). Magging: Maximin aggregation for inhomogeneous large-scale data. Technical report. Seminar für Statistik, ETH Zürich.
- Bühlmann, P., & van de Geer, S. (2011). Statistics for high-dimensional data: methods, theory and applications. Springer.
- Chatterjee, A., & Lahiri, S. N. (2011). Bootstrapping lasso estimators. Journal of the American Statistical Association, 106(494), 608–625. https://doi.org/10.1198/jasa.2011.tm10159
- Costantini, G., Epskamp, S., Borsboom, D., Perugini, M., Mõttus, R., Waldorp, L. J., & Cramer, A. O. (2015). State of the art personality research: A tutorial on network analysis of personality data in r. Journal of Research in Personality, 54, 13–29. https://doi.org/10.1016/j.jrp.2014.07.003
- Cramer, A. O. J., van Borkulo, C. D., Giltay, E. J., van der Maas, H. L. J., Kendler, K. S., Scheffer, M., & Borsboom, D. (2016). Major depression as a complex dynamic system. PloS One, 11(12), e0167490. https://doi.org/10.1371/journal.pone.0167490
- Cramer, A. O. J., Waldorp, L. J., van der Maas, H. L. J., & Borsboom, D. (2010). Comorbidity: A network perspective. The Behavioral and Brain Sciences, 33(2-3), 137–150. https://doi.org/10.1017/S0140525X09991567
- Davison, A., & Hinkley, D. (1997). Bootstrap methods and their application. Cambridge University Press.
- Dawid, A. (1979). Conditional independence in statistical theory. Journal of the Royal Statistical Society: Series B (Methodological), 41(1), 1–15. https://doi.org/10.1111/j.2517-6161.1979.tb01052.x
- De Ron, J., Fried, E. I., & Epskamp, S. (2019). Psychological networks in clinical populations: Investigating the consequences of berkson’s bias. Psychological Medicine, 1–9. https://doi.org/10.1017/S0033291719003209
- Dezeure, R., Bühlmann, P., Meier, L., & Meinshausen, N. (2015). High-dimensional inference: Confidence intervals, p-values and r-software hdi. Statistical Science, 30(4), 533–558. https://doi.org/10.1214/15-STS527
- Epskamp, S., Borsboom, D., & Fried, E. I. (2018a). Estimating psychological networks and their accuracy: A tutorial paper. Behavior Research Methods, 50(1), 195–212. https://doi.org/10.3758/s13428-017-0862-1
- Epskamp, S., & Fried, E. I. (2018). A tutorial on regularized partial correlation networks. Psychological Methods, 23(4), 617–634. https://doi.org/10.1037/met0000167
- Epskamp, S., Waldorp, L. J., Mõttus, R., & Borsboom, D. (2018b). The gaussian graphical model in cross-sectional and time-series data. Multivariate Behavioral Research, 53(4), 453–480. https://doi.org/10.1080/00273171.2018.1454823
- Foygel, R., & Drton, M. (2010). Extended bayesian information criteria for gaussian graphical models. Advances in Neural Information Processing Systems, 23.
- Fried, E. I., van Borkulo, C. D., Epskamp, S., Schoevers, R. A., Tuerlinckx, F., & Borsboom, D. (2016). Measuring depression over time… or not? Lack of unidimensionality and longitudinal measurement invariance in four common rating scales of depression. Psychological Assessment, 28(11), 1354–1367. https://doi.org/10.1037/pas0000275
- Friedman, J., Hastie, T., & Tibshirani, R. (2008a). Sparse inverse covariance estimation with the graphical lasso. Biostatistics (Oxford, England), 9(3), 432–441. https://doi.org/10.1093/biostatistics/kxm045
- Haslbeck, J. M. B., & Waldorp, L. J. (2020). mgm: Estimating time-varying mixed graphical models in high-dimensional data. Journal of Statistical Software, 93(8), 1–46. https://doi.org/10.18637/jss.v093.i08
- Haslbeck, J., & Waldorp, L. J. (2015). Structure estimation for mixed graphical models in high-dimensional data. arXiv preprint arXiv:1510.05677
- Hastie, T., Tibshirani, R., & Tibshirani, R. J. (2017). Extended comparisons of best subset selection, forward stepwise selection, and the lasso. arXiv preprint arXiv:1707.08692
- Hastie, T., Tibshirani, R., & Wainwright, M. (2015). Statistical learning with sparsity: The lasso and generalizations. CRC Press.
- Hastie, T., Tibshirani, R., & Wainwright, M. (2019). Statistical learning with sparsity: The lasso and generalizations. Chapman and Hall/CRC.
- Hevey, D. (2018). Network analysis: A brief overview and tutorial. Health Psychology and Behavioral Medicine, 6(1), 301–328. https://doi.org/10.1080/21642850.2018.1521283
- Hochberg, Y., & Tamhane, A. C. (1987). Multiple comparison procedures. John Wiley & Sons, Inc.
- Hoerl, A., & Kennard, R. (1970). Ridge regression: Biased estimation for nonorthogonal problems. Technometrics, 12(1), 55–67. https://doi.org/10.1080/00401706.1970.10488634
- Javanmard, A., Montanari, A. (2014). Confidence intervals and hypothesis testing for high-dimensional regression. Technical report, arXiv:1306.317.
- Jones, B., & West, M. (2005). Covariance decomposition in undirected gaussian graphical models. Biometrika, 92(4), 779–786. https://doi.org/10.1093/biomet/92.4.779
- Knight, K., & Fu, W. (2000). Asymptotics for lasso-type estimators. The Annals of Statistics, 28(5), 1356–1378.
- Koller, D., & Friedman, N. (2009). Probabilistic graphical models: Principles and techniques. MIT Press.
- Lauritzen, S. (1996). Graphical Models. Oxford University Press.
- Lee, J., Sun, D., Sun, Y., & Taylor, J. (2016). Exct post-selection inference, with application to the lasso. The Annals of Statistics, 44(3), 907–927. https://doi.org/10.1214/15-AOS1371
- Lockhart, R., Taylor, J., Tibshirani, R. J., Tibshirani, R., et al. (2014). A significance test for the lasso. The Annals of Statistics, 42(2), 413–468.
- Loh, P.-L., & Wainwright, M. J. (2013). Structure estimation for discrete graphical models: Generalized covariance matrices and their inverses. The Annals of Statistics, 41(6), 3022–3049.
- Lu, S., Liu, Y., Yin, L., & Zhang, K. (2017). Confidence intervals and regions for the lasso by using stochastic variational inequality techniques in optimization. Journal of the Royal Statistical Society Series B: Statistical Methodology, 79(2), 589–611. https://doi.org/10.1111/rssb.12184
- Maathuis, M., Drton, M., Lauritzen, S., & Wainwright, M. (2018). Handbook of graphical models. CRC Press.
- McNally, R. J., Robinaugh, D. J., Wu, G. W., Wang, L., Deserno, M. K., & Borsboom, D. (2015). Mental disorders as causal systems: A network approach to posttraumatic stress disorder. Clinical Psychological Science, 3(6), 836–849. https://doi.org/10.1177/2167702614553230
- Meinshausen, N., & Bühlmann, P. (2006). High-dimensional graphs and variable selection with the lasso. The Annals of Statistics, 34(3), 1436–1462. https://doi.org/10.1214/009053606000000281
- Meinshausen, N., Meier, L., & Bühlmann, P. (2009). values for high-dimensional regression. Journal of the American Statistical Association, 104(488), 1671–1681. https://doi.org/10.1198/jasa.2009.tm08647
- Pötscher, B. M., & Leeb, H. (2009). On the distribution of penalized maximum likelihood estimators: The lasso, scad, and thresholding. Journal of Multivariate Analysis, 100(9), 2065–2082. https://doi.org/10.1016/j.jmva.2009.06.010
- Robinaugh, D., Haslbeck, J., Waldorp, L., Kossakowski, J., Fried, E. I., Millner, A., McNally, R. J., van Nes, E. H., Scheffer, M., Kendler, K. S., et al. (2019). Advancing the network theory of mental disorders: A computational model of panic disorder. Technical report. Harvard Medical School.
- Schott, J. R. (1997). Matrix analysis for statistics. John Wiley & Sons.
- Taylor, J., & Tibshirani, R. (2018). Post-selection inference for-penalized likelihood models. The Canadian Journal of Statistics = Revue Canadienne de Statistique, 46(1), 41–61. https://doi.org/10.1002/cjs.11313
- Tibshirani, R. (1996). Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society: Series B (Methodological), 58(1), 267–288. https://doi.org/10.1111/j.2517-6161.1996.tb02080.x
- van Borkulo, C. D., Borsboom, D., Epskamp, S., Blanken, T. F., Boschloo, L., Schoevers, R. A., & Waldorp, L. J. (2014). A new method for constructing networks from binary data. Scientific Reports, 4(1), 5918. https://doi.org/10.1038/srep05918
- van de Geer, S., Bühlmann, P., Ritov, Y., & Dezeure, R. (2014). On asymptotically optimal confidence regions and tests for high-dimensional models. The Annals of Statistics, 42(3), 1166–1202. https://doi.org/10.1214/14-AOS1221
- Van der Vaart, A. W., Dudoit, S., & van der Laan, M. J. (2006). Oracle inequalities for multi-fold cross validation. Statistics & Decisions, 24(3), 351–371. https://doi.org/10.1524/stnd.2006.24.3.351
- Wainwright, M. J. (2009). Sharp thresholds for high-dimensional and noisy sparsity recovery using-constrained quadratic programming (lasso). IEEE Transactions on Information Theory, 55(5), 2183–2202. https://doi.org/10.1109/TIT.2009.2016018
- Waldorp, L. (2014). Testing for graph differences using the desparsified lasso in high-dimensional data.
- Waldorp, L., & Marsman, M. (2022). Relations between networks, regression, partial correlation, and the latent variable model. Multivariate Behavioral Research, 57(6), 994–1006. https://doi.org/10.1080/00273171.2021.1938959
- Waldorp, L., Marsman, M., & Maris, G. (2019). Logistic regression and ising networks: Prediction and estimation when violating lasso assumptions. Behaviormetrika, 46(1), 49–72. https://doi.org/10.1007/s41237-018-0061-0
- Williams, D. R. (2020). Beyond lasso: A survey of nonconvex regularization in gaussian graphical models.
- Williams, D. R. (2021). The confidence interval that wasn’t: Bootstrapped “confidence intervals” in l1-regularized partial correlation networks.
- Zhang, C.-H., & Zhang, S. S. (2014). Confidence intervals for low dimensional parameters in high dimensional linear models. Journal of the Royal Statistical Society Series B: Statistical Methodology, 76(1), 217–242. https://doi.org/10.1111/rssb.12026
Appendix
A. Gaussian Graphical Models
The Gaussian graphical model (GGM) refers to a network with nodes associated with the random variables
distributed according to a multivariate Gaussian distribution. The edges between nodes i and j in V of the network, denoted by
are associated with the partial covariances, which we explain below. Two variables are independent if the joint distribution
can be written as the product of marginal distributions
this is denoted by
The variables
and
are conditionally independent given an other variable
when the joint probability
can be written as
this is denoted by
The GGM is completely determined by the mean vector and covariance matrix.
The inverse of the covariance matrix, denoted by refers to the relation
where
is the identity matrix with all diagonal elements 1 and all off-diagonal elements 0 (see, e.g., Schott, Citation1997). For the identity matrix
we have that
for any
matrix A. This idea is similar to real numbers in
where for any
there exists a
such that
and we call
With the inverse of the covariance matrix the Gaussian (normal) multivariate distribution over
is (Bilodeau & Brenner, Citation1999, Chapter 5)
where
is the determinant of
(see, e.g., Schott, Citation1997). A component
can be characterized by the correlation between the residuals
and
where the subscript
refers to the ith and jth elements being left out. The correlation between the residuals
and
makes clear the idea that the partial correlation concerns the remaining correlation after all other variables (except k and m) have been removed.
It can be seen from the distribution function above that the 0s in the partial covariance matrix
play a central role in a GGM. In fact, Lauritzen (Citation1996, Proposition 5.2) showed that if the partial covariance
then
and
are independent conditional on all other remaining variables, i.e.,
This means that if then the distribution function can be written in product form, implying conditional independence.
To illustrate the relation between partial correlation and dependence for random variables with a multivariate Gaussian distribution, we provide a small example. Let so that we have two variables, each assumed to have mean
Suppose, furthermore, that the covariance and inverse (partial) covariance matrices are
We immediately see that there is no connection between the two nodes because In this case, there is no path between nodes 1 and 2 (there are no other nodes) and hence, the correlation is 0 (since
). The determinant of
is
Plugging this in the multivariate Gaussian distribution above, we obtain
where we left out
in
because we assumed
We can equivalently write this as
We then see that the multivariate distribution can be written as the product of the individual distributions. Hence, assuming that the partial covariances (or partial correlations) are 0, leads to the variables being independent when the multivariate distribution is Gaussian.
Because correlations are easier to interpret, the partial correlations are often used in GGMs instead of partial covariances. The partial correlation between and
given all remaining other variables is obtained from the partial covariance matrix, very similar to the correlations matrix. The partial correlation between
and
given all remaining other variables is defined by
where
denotes all variables associated with the network except i and j.
B.
Estimation of regression coefficients for the GGM
In nodewise regressions, we obtain estimates of the edges of the network by considering in turn each node as the dependent variable and the other nodes as predictors. We, therefore, preform p regressions with each predictors (the remaining variables), and obtain in total
estimates, so two for each edge.
To obtain the set of connections for each node we use in linear regression, since the mean of a univariate conditional Gaussian is modeled by a linear combination of all other variables. We have data
for
independent observations and
variables or nodes in the network. We perform a regression for each node separately where node i is selected as the dependent variable and the other nodes
are the predictors (see e.g., Bühlmann & van de Geer, Citation2011, Chapter 13; Hastie et al., Citation2015, Chapter 9). Then the least squares minimizes the squared residuals between node i and the predictions based on all nodes
The least squares estimates
for the
remaining nodes
is obtained by minimizing
(B.1)
(B.1)
where the
is the vector of coefficients
so that the coefficient
is not part of it. When
the estimates are unique and this is often the case for psychological data.
When the are collinear or
then the least squares solution is no longer unique (Hastie et al., Citation2015). To render the solution unique a constraint can be implemented, like the least absolute shrinkage and selection operator (lasso, Tibshirani, Citation1996). The lasso can be written in terms of the least squares function and a penalty that sums all the coefficients
Additionally, there is a parameter,
(Lagrange coefficient), associated with the penalty to set the strength of the penalty. The lasso is then
(B.2)
(B.2)
This function can be minimized to obtain the solution (see e.g., Hastie et al., Citation2015, Chapter 5). We often ignore the
in notation for convenience. The
parameter needs to be fixed by the researcher. This is often done by considering several (a 100, say) values of
in a cross-validation procedure, that minimizes the squared prediction error. In cross-validation, the data is divided into k equally sized parts, where
parts (training set) are used to estimate the coefficients, and the remaining part (test set) is used to predict the remaining values. The prediction error is obtained this way for each of the k parts, changing the training and test sets each time, so that an average cross-validation can be obtained for each value
The value
is selected which has the smallest average cross validation error (see e.g., Hastie et al., Citation2015, Chapter 2, for an excellent discussion). Cross-validation has been shown to be lead to the correct value (Van der Vaart et al., Citation2006).
The assumptions for the lasso solution to be correct can be divided into two sets, depending on the goal. The goal could be to obtain an estimate such that the difference with the true parameter
is very small. This is called consistency. But consistency does not necessarily lead to correct identification of the non-zero coefficients in the true
It could be that the error
is small, but that there are some (small) non-zero values in the estimate
which are zero in the true parameter
and it could be that for some values in the estimate
the values are large while these values in the true parameter
are small. The second goal for using the lasso, therefore, could be to identify those elements in the estimate
that are zero only when the corresponding elements in the true parameter
are zero. This is often referred to as variable selection consistency or sparsistency.
We say that the estimate is consistent if
tends to 0 in probability as the number of observations
where
is the Euclidean norm. (Convergence in probability means that, for any
as
) For consistency of the lasso problem above the assumptions are that the true parameter vector is sparse and the remaining variables (all except
) are not highly correlated. Sparsity can be defined as the number s of non-zero coefficients in the true parameter vector
In more general settings than we discuss here, where possibly
this assumption is more difficult (see Hastie et al., Citation2015, Chapter 11, for an excellent discussion). In the case where
we basically require that the regressors (all variables except
) are not too highly correlated, i.e., are not collinear. So, we obtain consistency, i.e.,
as
if the following holds:
Sparsity The true parameter
Non-collinearity The correlation between any variables (other than
A conservative sparsity factor can be expressed in terms of the number of observations n and the number of variables p: (Bühlmann et al., Citation2014). This is a heuristic value that can be used as an indication of the sparsity.
To obtain the more subtle result that each element of is close the corresponding element of
(and not just in norm
), i.e., variable selection consistency, two additional assumptions are required. The first is about the correlation between the regressors: the correlation between the variables that have a connection and those that do not have a connection with the dependent variable must be small. This makes sense because two regressors, where one is connected to the dependent variable and the other is not (see with
and
), cannot have a correlation nearly 1 themselves. The final assumption is about the size of the ‘signal’. It assumes that the smallest non-zero value in the true parameter
is (in absolute value) larger than some small value
c. Incoherence The correlation between unconnected variables and connected variables to
d. Beta-min The smallest value in
The beta-min assumption can be characterized giving an indication of the lower bound on the size of the coefficients (Bühlmann et al., Citation2014). With these assumptions and a penalty parameter
it can be shown (Hastie et al., Citation2015, Theorem 11.3) that with high probability the lasso obtains
Few false positives The set of zero coefficients in the estimate
Many true positives The set of non-zero coefficients in the estimate
These results have appeared in the literature in various forms. See for more details, e.g., Meinshausen and Bühlmann (Citation2006), Wainwright (Citation2009), Bühlmann and van de Geer (Citation2011) and Bühlmann et al. (Citation2013).
C.
p-values and the Bonferroni-Holm procedure
For each parameter estimate (the least squares estimate, see Appendix B), we have that the distribution is normal and we have a standard error estimate
(see Appendix G). The null and alternative hypotheses are, respectively,
The statistic to test these hypotheses is Let Z be a random variable from the standard normal distribution. Then the two-sided p-value for
is
To control the false positive rate across multiple hypothesis tests, we use the Bonferroni-Holm procedure for multiple testing correction (Hochberg & Tamhane, Citation1987). The Bonferroni-Holm (BH) procedure is as follows. Set the level and denote by m the number
of tests for all network edges (obtained from nodewise regressions, see Appendix B).
Obtain all required p-values
Order the p-values from small to large, so that
Test the the smallest p-value at the Bonferroni level
If
for
If
A useful way to rewrite the level at which is tested in the above BH-procedure is by setting the level and using corrected p-values (this is done in many R-packages). Then, we have the corrected p-value for the null hypothesis
with
where
the number of all regression coefficients from the nodewise regressions.
D.
Multi sample-split
The procedure identified in Meinshausen et al. (Citation2009) to aggregate the K p-values and make a single decision, uses an original correction for a type of empirical quantile function to upper bound the false positive rate. This quantile function is necessary in order to determine what cutoff to use in the distribution of K obtained p-values so that the decision to reject incorrectly remains at the correct level.
Before defining the empirical -quantile function introduced by Meinshausen et al. (Citation2009), we give some definitions. The empirical distribution function gives the cumulative probability up to some
and the empirical quantile function gives the smallest observed p-value (in this setting) with at least probability
Note that the domain and range of the empirical distribution and quantile functions are the same because we are dealing with p-values. Let
be the empirical distribution function for the jth p-value, based on K half-splits, i.e.,
This represents the proportion of p-values that are not larger than The inverse mapping is the empirical quantile function
which gives the first p-value such that
For example, with
we obtain the median, and with
we obtain the first quartile, usually denoted by
The
-quantile function is defined by Meinshausen et al., (Citation2009)
For example, again with this gives the value two times the median of the p-values obtained over K splits. Meinshausen et al. (Citation2009, Theorem 3.2) show that the corrected p-value is obtained for a lower bound (usually
) with
is correct in the sense that the false positive rate is not exceeded. The correction
with
is approximately 3.996. This corrected p-value, obtained from the set of K p-values, one for each half-split, can be considered as an adaptive control over the K p-values with the function
where
is a value in
and
is the level.
E.
Desparsified lasso
The desparsified lasso modifies the original lasso estimate so that a small value is added or subtracted. This small value is obtained from the residuals. By doing so, the estimated values that are exactly 0 will no longer be exactly 0. Hence, the problem is avoided of the lasso parameter estimate distribution, which is discontinuous and may have probability one on the value 0 (see ).
We follow the desparsified lasso described in van de Geer et al. (Citation2014) and Dezeure et al. (Citation2015). We let be the dependent variables and so require a lasso estimate
which is the vector of coefficients for all
First, we perform a lasso regression on one of the regressors
given the remaining variables, that is, all variables except
and
Then with this lasso estimate
we form the residual
obtained by subtracting the prediction with the lasso estimate
from the variable
We then obtain the desparsified lasso for parameter
as
(E.1)
(E.1)
where
is the lasso estimate,
is the residual of the mth observation of variable i (dependent variable), and
denotes a random variable that tends to 0 in probability at the rate of
van de Geer et al. (Citation2014) have shown that if
is negligible then (E.1) is approximately normally distributed, given certain assumptions. This is because the middle term in (E.1) is a function of the residuals
which are assumed to be normal (see Section 3). Hence, the standard error can be obtained to determine the p-values and confidence intervals. The assumptions required for the desparsified lasso are the first two assumptions (a) and (b) in Appendix B.
F.
Bootstrap of the desparsified lasso
Here, we clarify the steps in the algorithm for the bootstrap in Section 4.3. In step (1), we basically resample the set of labels for the observations and then select those observations
for all
and call the resampled version
for all
In step (2), we obtain a network by applying the desparsified lasso to the resampled observations
The distribution of the estimates
are then guaranteed by the results of the desparsified lasso. Then, finally, after having repeated (1) and (2) K times, in step (4) we find for each parameter
the empirical distribution based on the K bootstrap samples
for all
The empirical distribution function for the K bootstrap samples
is
for some value
The p-value is then calculated by determining with the original sample with estimate
the value
It can be seen that the error for the bootstrap depends on the number of bootstraps K (see Davison & Hinkley, Citation1997, Chapter 2, for an excellent discussion on this). In the order of 500 bootstrap, resamples is generallly considered adequate. The assumptions for the bootstrap are the same as for the desparsified lasso, so, sparsity (a) and no collinearity (b).
G.
Confidence intervals
Two cases will be discussed here, without the lasso penalty (least squares) and with the lasso penalty (see Appendix B), where we use the desparsified lasso described in Appendix E. We first discuss the case without the lasso penalty and where we have so that we have more observations than parameters.
To obtain a confidence interval (and p-values), we require that the distribution of the estimate is normal, from which we obtain the mean (the true value
) and the standard error (the standard deviation of this sampling distribution, see e.g., Bilodeau & Brenner, Citation1999). The distribution of
is normal because the residuals of the linear model are normally distributed. Let
be the matrix with all regressors
predicting variable i. Consider the least squares estimate for all
coefficients simultaneously
We know that the distribution is normal because we know that is normally distributed. For the linear model, we obtain from this the mean (conditional on the remaining variables
)
So that we recover in expectation the true parameters for
We also obtain the covariance matrix
where we assumed that the variable
has residual variance
(see Section 3). The standard error, denoted by
can be obtained from the covariance matrix of the parameter estimates. Taking the square root of the diagonal elements of this matrix gives the standard error. Having obtained the standard errors
we obtain a
confidence interval for parameter
using the normal approximation
(G.1)
(G.1)
such that
(G.2)
(G.2)
Because the estimates are a linear function of the data, we obtain that for multivariate normal random variables that the estimates have a normal distribution. Furthermore, the standard error
the standard deviation of the sampling distribution of
can be calculated.
The second case, where we use the lasso penalty to obtain the estimate we use the desparsified lasso. The desparsified lasso is used because we require that the sampling distribution of the estimates
is approximately normal. We know that the desparsified lasso yields estimates with an approximately normal distribution, as discussed in Appendix E. Additionally, the desparsified lasso obtains the standard error, so that we can calculate the confidence interval in the same way as shown above.
H.
Simulation details
To generate the partial covariances we first obtained an adjacency matrix with the function erdos.renyi.game (in the package igraph). The adjacencies
are 0 indicating no edge
in the network and 1 if there is an edge
in the network. Subsequently, we generated
random partial covariance coefficients from a uniform distribution with values between 0.1 and 0.8, and collected these in
Then we defined the partial covariances as
The diagonal elements
were defined as the sum of the row coefficients:
This last step ensured that
was nonsingular.
In the random network generation, we set to 0.2, yielding between 2 and 9 connections for each node, and we set
to 0.4 yielding between 5 and 12 connections for each node. Using the sparsity
(see Appendix B) we get for
a maximum of 4 connections for each node, and for
we obtain a maximum of 12 connections for each node. The number connections for each node in the generated network could violate sparsity s. In , we provide the empirical distribution function for the number of nodes that violate the sparsity assumption.
Using the heuristic of the beta-min value (Bühlmann et al., Citation2014), we can also determine the percentage of edges out of the
edges (190 for our case of
nodes) do not satisfy the beta-0min assumption. shows the percentages of edges that violate the beta-min assumption (d) from Appendix B. For
the percentage is about 30, and for
the percentage is 0.
The multivariate normal data were generated using the eigenvalue decomposition of where
is a diagonal matrix with eigenvalues
all positive, and eigenvectors
as columns of V. A square root of
is then defined as
with
the diagonal matrix with elements
Standard normally distributed data were generated independently and collected in the
matrix Z. To obtain the GGM with the specified structure
we constructed data
The following settings were used for retrieving the p-values with each of the methods. For the multi sample-split, we used the recommended for the number of splits and a split fraction of 0.5 (Dezeure et al., Citation2015; Meinshausen et al., Citation2009). For the desparsified lasso, we selected the penalty parameter
using 10-fold cross-validation; we used 10-fold cross-validation for the lasso without p-values as well. And, finally, for the bootstrap (using the desparsified lasso), we used the same settings as for the desparsified lasso and used
resamples for the bootstrap. For each of the three methods, we used the Bonferroni-Holm correction to obtain corrected p-values. To determine the presence or absence of an edge, we used the and-rule.
I.
Additional simulation results: Specificity and conditional coverage
. displays additional results of the simulation study reported in the main text. The first row shows the specificity, the second row the coverage for absent edges, and the third row the coverage for present edges.
Figure 1. (a) Example of a network with four nodes 1, 2, 3 and 4 with associated variables
and
The edges
and
correspond to the conditional dependence statements, and the absence of edges correspond to conditional independence statements:
and
(b) The variable
is not part of the neighborhood of
while
and
are part of the neighborhood of
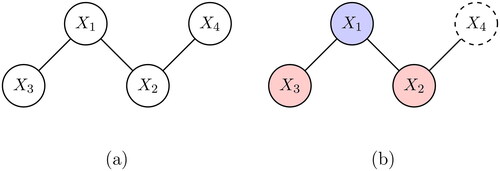
Figure 2. Top panel: bootstrapped sampling distributions of lasso estimates of partial correlations Bottom panel: the corresponding bootstrapped sampling distributions based on unbiased least squares estimates. The dashed vertical line indicates the true parameter.
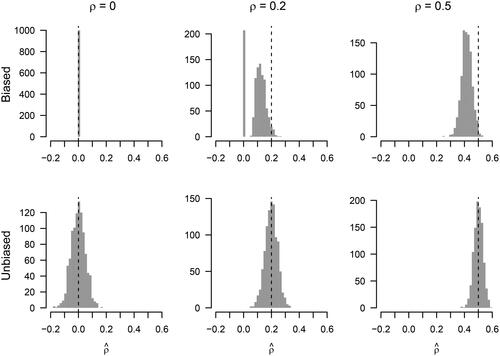
Figure 3. Sensitivity (first row), precision (second row), and coverage (third row) for edge probabilities 0.2 (left column) and 0.4 (right column), as a function of sample size (x-axis). The dashed horizontal line at 0.95 in the last row indicates the desired coverage based on the chosen threshold
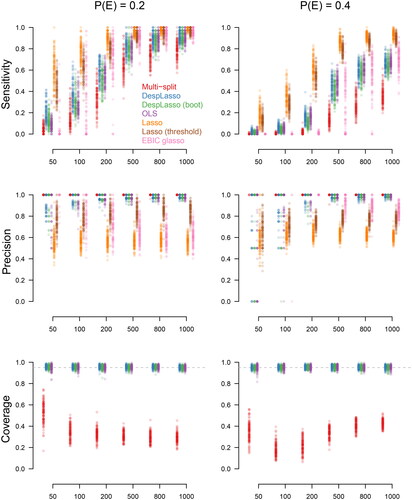
Figure 4. Significant partial correlations in the PTSD data; blue/red edges correspond to positive/negative partial correlations; the width of edges is a function of the absolute value of the associated parameter.
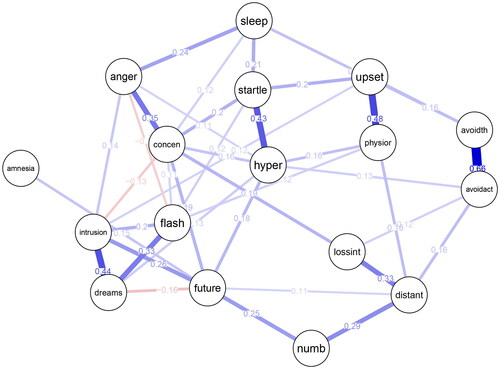
Figure 5. The point estimates and confidence intervals of the 50 partial correlations with the largest point estimate. Hollow points represent estimates whose CIs overlap with zero.
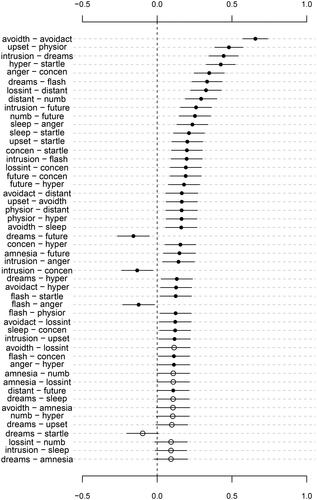
Figure I.1. Specificity (first row), coverage for absent edges (second row), and coverage for present edges (third row) for edge probabilities 0.2 (left column) and 0.4 (right column), as a function of sample size (x-axis).
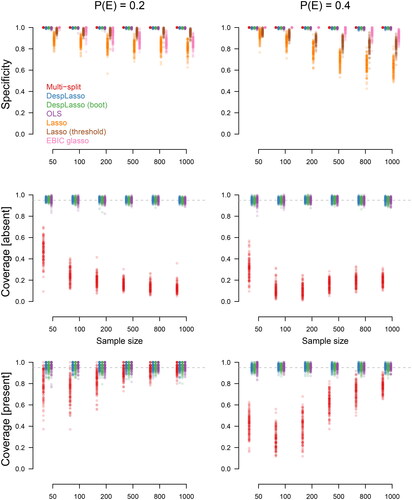
Table 1. The table provides an overview of the assumptions that are required for each of the three methods of obtaining p-values, the lasso, the graphical lasso (glasso) and OLS.
Table 2. Sparsity (for nodewise estimation) and beta-min violations for each of the settings in the simulation with probability of an edge or 0.4. Sparsity is in the second column for each number of observations (from 50 to 500) and
nodes. In the third and fourth columns, the number of nodes in the network that violate the sparsity assumption. In the fifth column, is the heuristic beta-min value for each of the number of observations. Sixth and seventh columns are the percentage of edges that violate the beta-min assumption (i.e., are smaller than the beta-min value).