
ABSTRACT
Over time international large-scale assessments have grown in terms of number of studies, cycles, and participating countries, many of which are a heterogeneous mix of economies, languages, cultures, and geography. This heterogeneity has meaningful consequences for comparably measuring both achievement and non-achievement constructs, such as social and emotional skills. In this paper we propose one way to directly incorporate country-specific differences into the methods used to construct background scales. We use research that demonstrates data quality issues in international assessment and the degree to which these issues can impact inferences. Our proposed solution incorporates innovations that have been developed for achievement measures but have not been applied to background scales. We demonstrate this possible solution with PISA 2012 data.
Introduction
International large-scale assessments (ILSAs) of educational achievement such as the Progress in International Reading Literacy Study (PIRLS), the Trends in International Mathematics and Science Study (TIMSS), and the Programme for International Student Assessment (PISA) serve multifold purposes. From system monitoring and benchmarking to providing policy makers and researchers with information about what students know and can do, ILSAs offer stakeholders an opportunity for understanding the context and correlates of learning in a number of areas. Certainly, these assessments result in volumes of potentially useful data; however, many policy makers, and particularly the media, place the most attention on educational performance in the content domains (e.g., math, science, and reading). Although the figurative spotlight typically shines on achievement outcomes and rankings, there is a wealth of background information that is gathered in addition. This information includes affective and behavioral measures of students, teacher beliefs and practices, and principal’s perspectives on school safety and resources, for example. This sort of background information is commonly used to contextualize and explain achievement and achievement differences. Increasingly, however, these background measures – such as social and emotional skills – are gaining importance as outcomes in their own right (OECD, Citation2015). Given the historic importance of achievement to educational research and policy conversations, much of the methodological effort and innovation has been concentrated on valid, sufficiently precise achievement measurement (Martin & Mullis, Citation2012; OECD, Citation2014). To that end, considerable work goes into warranting that achievement is minimally impacted by cultural, linguistic, and geographic differences. Further, a number of advances – discussed subsequently – have been proposed and adopted on the achievement side of these surveys to attend to cross-systemFootnote1 differences in measurement. And, at least in the case of PISA, the survey architects have engaged in analytic efforts to understand the degree to which background scales are impacted by cultural differences in measurement. In spite of this, the kinds of innovations that have been adopted on the achievement side of the test have not similarly been considered for background scales. In response to this gap, we discuss issues around cross-cultural measurement differences in international assessments and propose the adoption of some innovations that have been used to good effect in achievement measurement.
We begin by briefly describing the evolution of ILSAs and the way in which the profile of participating educational systems has changed over time. Next, we describe, in a non-technical way, measurement issues that come forth when dealing with heterogeneous populations. As part of this, we also review recent research that highlights the impact of heterogeneity on measurement quality and comparability. We take up this issue in the context of both the achievement part of the study as well as the context or non-achievement part – that segment of the survey commonly referred to as non-cognitive (Klieme & Kuger, Citationn.d.). We then describe a possible solution for better measuring context in a way that directly embraces educational system heterogeneity into the methods used to estimate scale scores on non-cognitive measures. This approach offers the possibility of strengthening model-data consistency and related inferences that are based on these measures.
Evolution and Growth of ILSAs
In the past 20 or so years, international educational assessments have grown in terms of number of studies, cycles, and participating countries, many of which are a heterogeneous mix of economies, languages, cultures, and geography. For example, in 2000, the first cycle of PISA, 43 educational systems, 27 of which were Organisation for Economic Co-operation and Development (OECD) members, were assessed and compared in three content domains: mathematics, science, and reading. In 2012, 67 systems participated in the latest completed PISA cycle that measured achievement in math, science, reading, problem solving, and financial literacy, marking significant growth in terms of the number of participating educational systems and content domains. Of the 67 systems, all 34 OECD member countries (representing the largest economies in the world, excepting China) participated in PISA 2012, with the remaining 33 participants (termed partner systems) comprised of an increasingly heterogeneous mix of economies and cultures, including educational systems such as those of Tunisia, Peru, Singapore, and Shanghai, China. The same sort of growth and development has also been observed in TIMSS and PIRLS. For instance, 45 educational systems participated in the first round of TIMSS in 1995, while in the latest completed cycle in 2011, 77 educational systems participated at eighth or fourth grade, including nine US states. The TIMSS 2011 and PIRLS 2011 assesments were translated into 45 and 49 different languages, respectively (Martin & Mullis, Citation2012). Further, in the case of TIMSS, the geographical and cultural distribution of participating systems has changed in meaningful ways. Between 1995 and 2011, the most striking changes were in terms of the growth in number of Central Asian and Middle Eastern participants (from 3 to 16, respectively) and African participants (from 1 to 5, respectively ). Finally, the addition of benchmarking participantsFootnote2 comprised 14 of 77 educational systems in 2011. On the whole, these facets suggest a high degree of heterogeneity in language, culture, and socioeconomic status across participating educational systems in the three most prominent ILSAs.
Potential methodological challenges associated with such an amalgamation of participants have been highlighted by a number of researchers, who have pointed especially to the achievement estimation model and whether comparisons are sensible and valid when systems differ dramatically (Brown, Micklewright, Schnepf, & Waldmann, Citation2007; Goldstein, Citation2004; Kreiner & Christensen, Citation2014; Mazzeo & von Davier, Citation2009; Oliveri & Ercikan, Citation2011).
Across TIMSS, PIRLS, and PISA, operational procedures acknowledge and account, to some degree, for system-level heterogeneity through all phases of test development, analysis, and reporting. For example, since its inception in the late-1990s, PIRLS development has always involved a careful review of candidate reading passages. Those passages regarded as not culturally or otherwise suitable (e.g., a short story about Easter eggs would not be appropriate in countries with dominant Muslim populations) are removed from further consideration (Martin & Mullis, Citation2012).
A further step in assessing the suitability of test items has involved the analysis and review of all test items following the main survey administration. Where poor psychometric properties are observed, data for those items are either discarded internationally or in educational systems where items are of poor quality. Although the methods differ depending on the assessment, the technical documentation for TIMSS, PIRLS, and PISA has full details (Martin & Mullis, Citation2012; OECD, Citation2014). Outside of standard operational procedures, ILSA programs have developed other accommodations, such as prePIRLS, which is regarded as a “stepping stone” to participating in PIRLS. The test, which also assesses reading, includes the same constructs as PIRLS, but is less difficult (TIMSS & PIRLS International Study Center, Citation2013). Similar accommodations exist for TIMSS. Finally, in 2009, PISA began administering sets of easy test booklets for educational systems with low expected achievement in an effort to better capture the full range of educational achievement (OECD, Citation2010). Although these examples are not comprehensive, they are representative of the types of steps taken to directly deal with the fact that highly heterogeneous educational systems all participate in the same test.
Notable in the preceding description is that these adjustments focus on the achievement side of the assessment; however, extensive data is also collected on student, teacher (in TIMSS and PIRLS), and school contexts. As noted above, these measures are used to describe achievement differences (e.g., across gender) and as covariates in more complex analyses that seek to model or explain achievement variation (e.g., Marsh et al., Citation2014; Rutkowski, Rutkowski, & Engel, Citation2013). And although so-called national options exist whereby individual educational systems can add limited sets of tailored items to the background questionnaires, these additions are generally not used to develop international background scales and indices such as socioeconomic status, student engagement, or school safety, among others. One exception involves the PISA family wealth measure, which includes up to three system-specific items (e.g., an iPad or iPhone in Norway). Given that many domains in education show sensitivity to culture (see He & van de Vijver [Citation2013] for a concise summary of several of these studies), it can be argued that directly comparing constructs across educational systems is not without problems. Further, making comparisons in the absence of comparability evidence raises the risk of inferential errors, as observed differences can be attributed to actual underlying differences on the construct or they may simply be an issue of measurement differences.
Measurement Issues on the Achievement Side
The typical ILSA approach to estimating achievement assumes that item responses adhere to an item response theory (IRT) model (Adams & Wu, Citation2007; Adams, Wu, & Carstensen, Citation2007; Rasch, Citation1980). Under an IRT framework, meaningful cross-cultural comparisons depend on item parameter equivalence (Hambleton & Rogers, Citation1989; Mellenbergh, Citation1982; Meredith, Citation1993; Millsap, Citation2011). This implies that test items are assumed to be equally difficult across the populations under consideration. That is, an item should be equally difficult for students in Norway, Kazakhstan, and Shanghai. As operational procedures rely on this assumption, it is notable that in empirical investigations, the assumption does not hold (e.g., Kreiner & Christensen, Citation2014; Oliveri & von Davier, Citation2011; Rutkowski, Rutkowski, & Zhou, Citation2016). And in a limited investigation (Rutkowski et al., Citation2016), violations were found to have consequences for ranking achievement, especially among middle-performing educational systems. Further, the same study showed that achievement means can be meaningfully biased – in several cases resulting in achievement outside of the original 95 or 99% confidence interval, raising caution in associated inferences that are based on achievement scores. In other words, violating the assumption of equivalent item difficulty across populations has a meaningful impact on achievement estimates overall and on country rankings. Importantly, operational practice assumes equivalently difficult items.
A primary focus of ILSA programs is to summarize information regarding what populations of students know and can do in a number of content areas (e.g., the whole of Denmark; boys vs. girls; immigrant vs. native born students). As a consequence, it is not necessary to administer the entire test to every participating student at each grade level. Instead, a complex rotated booklet design is used. Specifically, cognitive test items are assembled into a non-overlapping set of blocks with several test items per block. For example, the PISA 2009 assessment included 131 reading items, 34 math items, and 53 science items distributed across seven reading clusters and three clusters each for math and science. Under this design, each item cluster (and therefore each item) appears in four booklets with four cognitive clusters in each booklet. These 13 item blocks represent several hours of testing time; however, the booklet design used by PISA reduced individual testing time to 90 min per student (OECD, Citation2012).
Although this administration method minimizes testing time for students, it poses currently intractable problems for producing achievement estimates for individual students. In fact, traditional methods of estimating individual achievement introduce an unacceptable level of uncertainty and the possibility of serious aggregate-level (country, region, or sub-population) bias (von Davier, Gonzalez, & Mislevy, Citation2009; Mislevy, Beaton, Kaplan, & Sheehan, Citation1992). To overcome the methodological challenges associated with rotated booklet designs, ILSA programs adopted a population or latent regression modeling approach that generates population- and sub-population-level achievement estimates (Mislevy, Citation1991; Mislevy, Beaton, et al., Citation1992; Mislevy, Johnson, & Muraki, Citation1992). Using information from background questionnaires, other demographic variables of interest, and responses to the cognitive portion of the test, student achievement is estimated via a latent regression, where achievement is treated as a latent or unobserved variable. In other words, data from the student background questionnaire are used in an imputation model (called a “conditioning model”), which is combined with responses to the limited subset of the overall administered cognitive items via a measurement model. This process generates a proficiency distribution for the population (or subpopulation) of interest (von Davier et al., Citation2009; Mislevy, Beaton, et al., Citation1992; Mislevy, Johnson, et al., Citation1992). A simplified abstraction of the conditioning model is a linear regression model where the dependent variable is unobserved achievement for each examinee, which in turn is a function of student background characteristics along with student responses to the assessment. Very simply put:
Unobserved student achievement = f(student attributes, achievement test item responses)
Background Questionnaires
As described earlier, within ILSAs there are two primary types of instruments to help us understand aspects of an educational system: an achievement assessment and background questionnaires. In general, the background questionnaires have two primary uses within ILSAs: (1) to help contextualize the assessed educational system; and (2) to optimize population and sub-population achievement estimation (e.g., all of Norway or Norwegian boys compared to girls, respectively). This section of the paper will deal with the former and, in particular, focus on specific constructs that are being assessed by background questionnaires.
Previous research (Rutkowski & Rutkowski, Citation2010) points to some areas where ILSAs could benefit from increased research and improvement. Examples included three areas of concern: significant missing responses on key reporting variables (e.g., language spoken at home); low correlations between variables that are common across parent and student questionnaires; and low scale reliability on important composite indicators, such as socioeconomic status. Here we would like to update the latter two examples in light of the current discussion. We do this to offer recent empirical evidence that the theoretical objects of interest resulting from background questionnaires can be culturally and context specific, as is well known from cross-cultural research (He & van de Vijver, Citation2013). Consequently, more should be done to better account for these differences when constructing questionnaires and deriving scales from underlying data, particularly as ILSA participating systems grow in number and are increasingly comprised of a highly heterogeneous group of countries.
Inconsistent Response Patterns
The PIRLS assessment provides a unique insight into response consistency, as parents and students answer a few identical questions. Specifically, in PIRLS 2011 both respondents were asked to indicate the approximate number of books they have in their home – a variable that is commonly used as part of a socioeconomic/sociocultural measure in international studies (Martin & Mullis, Citation2012; OECD, Citation2014) – on a scale from one (0 to 11 books) to five (more than 200 books). We would expect that the responses from the parents and children would be highly correlated, if not precisely identical; however, in many educational systems this is not the case. Similar to our earlier findings using PIRLS 2006, there are some discrepancies between parent and child responses. shows the results of our simple analysis, where we can see that the correlations are rather low for a number of participants with the lowest three being Indonesia, Kuwait, and Azerbaijan. Even after correcting for measurement error,Footnote3 many correlations remain low. In particular, Indonesia, Morocco, and Botswana remained essentially unchanged after measurement error correction, suggesting that real differences in understanding exist between parents and their children. In several other countries, corrected correlations were markedly increased, indicating the presence of substantial measurement error (e.g., Bulgaria and Hungary). In sum, either parents, or their children, or both are providing inaccurate information regarding the number of books in their home; however, we have no objective evidence regarding which is the case.
Table 1. Correlation between parent and student report of number of books in the home.
Countries with the lowest agreement, in general, also tend to be lower achievers and less economically wealthy than those with higher correlations. This simple analysis provides some evidence of misclassification by at least one respondent, pointing to a need for improving the measure or the means of measurement. In contrast, correlations are generally reasonable in many high achieving countries and in many countries with greater economic wealth, particularly after the correlations are purged of measurement error. Norway, however, with a raw correlation of .44 and corrected correlation of .62, falls below the international average. More research would be necessary to understand the source of misclassification regarding the number of books in the home. However, this rather low correlation suggests that both policy makers and researchers should use considerable caution when including either the parent or student response in an analysis, particularly as a predictor in a linear model, such as an ordinary least-squares regression.
Socioeconomic Index
Rather than using a single indicator such as books in the home, to gain a better understanding of complex concepts such as family wealth and SES, some programs have created composite indexes with data from the student background questionnaire. A prime example is the PISA index called the economic, social, and cultural status indicator (ESCS).Footnote4 Similar to previous cycles, the PISA 2012 ESCS index was derived from three sub-indices: highest occupational status of parents (HISEI), highest educational level of parents, in years of education according to ISCED, and the home possessions index. The (OECD, Citation2014) reports that “the ESCS scores were obtained as component scores for the first principal component with zero being the score of an average OECD student and one being the standard deviation across equally weighted OECD countries” (p. 352).
shows the standardized principal component weights for each scale included in the ESCS, along with the reliability (Cronbach’s alpha) of ESCS 2012 as reported by the OECD. The Table is sorted by the highest to lowest reliability on the ESCS scale. The Table demonstrates a few notable points. First, we see the factor loadings of home possessions have the lowest median of the three, with four of the five Scandinavian countries having a factor loading below the OECD median. Also notable is the reported scale reliability of the ESCS scale. Scale reliability can be interpreted as the proportion of variance not attributable to measurement error. That is, reliability describes the proportion of variance in a scale that is attributable to variance in the true score, or underlying construct. Both Iceland (.57) and Norway (.56) demonstrate fairly low reliability on this scale, suggesting that nearly half of the variance in this measure is due to error. Finland, Sweden, and Denmark show somewhat higher values at .60, .60, and .67, respectively. Important to note here is that one explanation for these reliability estimates is that there might be very little true variance in the ESCS scores in these countries, pointing to low inequity rather than problems with measurement error.
Table 2. Factor loadings of sub-scale and reliability for economic, social, and cultural status indicator.
Findings from a previous study (Rutkowski & Rutkowski, Citation2013) revealed that reliability estimates across the three subscales that make up the home possessions index (wealth possessions, cultural possessions, and home education resources [OECD, Citation2012]) are highly varied by scale and country. Further, despite observing adequate fit on the home possessions subscales in a handful of educational systems, findings indicated that the majority of countries are ill-fit by one or both subscales, suggesting that the factor structure is mis-specified in many educational systems. Additionally, the items hypothesized to measure the constructs that comprise the home possessions scale are likely not adequate for most educational systems. Further, the degree to which the models are mis-specified is highly variable across educational systems and scales, and the findings of poor fit did not appear to be concentrated in either OECD or partner countries (OECD, Citation2014). These findings are in line with Traynor and Raykov (Citation2013), who analyzed PIRLS, PISA, and TIMSS data and found that in Indonesia and Israel the wealth measurements “tend to be imprecise – with between one-third and one-half of the wealth score variability in several of these surveys attributable to measurement error” (p. 681).
One Proposal for Directly Incorporating Heterogeneity Into Background Scales
Design-Based Proposal
Although cross-cultural measurement heterogeneity is often conceptualized as a technical, statistical problem (e.g., Millsap, Citation2011), one reasonable solution relies on both statistical and design aspects that directly embrace heterogeneity in international assessments. We briefly note some limited accommodations that are currently in operation as a natural transition. As noted in a previous section, the IRT models used to estimate achievement in international assessments rely on equivalent measures across populations. Further, as noted earlier, substantial evidence exists regarding cross-system differences in measurement properties. And emerging research indicates the degree to which these differences have an impact on achievement estimates and comparisons (Rutkowski et al., Citation2016). Partly in response to these issues, the PISA project implemented the easy booklet option, discussed earlier, especially targeted toward lower performing participants, whereby booklets are modified to include some clusters of easy items for countries with low expected performance (OECD, Citation2012).
Twenty educational systems, including two OECD-member countries, chose the easy-booklet option in 2009. This effort, incorporated only into the reading portion of the 2009 assessment, was intended to better capture what students in low performing countries know and can do (OECD, Citation2012, p. 30). We propose that a modification of this approach is used in non-cognitive scales to improve comparability and local usefulness. In particular, developing and administering system-specific items for non-cognitive scales could be undertaken in a way that modestly increases the length of the questionnaires and allows for more locally-valid measurement of important constructs. The state-of-the-science in measurement models will readily admit a set of items that are unique to a particular context while ensuring cross-system comparability.
A Model-Based Solution for Estimating Achievement
In addition to design-based solutions that allow for tailoring items to better fit the context of the participating educational system, model-based solutions also exist (Oliveri & von Davier, Citation2011, Citation2014). Essentially, the assumption of strictly equivalent measures is relaxed (Byrne, Shavelson, & Muthén, Citation1989) and through a process of language-based or other kinds of grouping or selection procedures, a limited subset of item parameters are allowed to differ across educational systems; however, the latent variable means remain comparable. This is commonly referred to as partial invariance. An impetus for these approaches rests on the fact that educational systems demonstrate cultural, linguistic, and geographic patterns of item responses (e.g., Olsen, Citation2012). Historically, these sorts of patterns have generally been ignored excepting cases where items function very differently and have been omitted from scoring routines, either for an individual country or internationally. Of course, some items will exhibit poor properties and should be discarded; however, where possible, it is desirable to preserve the information gleaned from these carefully developed and administered test items. As such, we offer a version of tailored item parameters (via partial invariance) as a possible model-based solution.
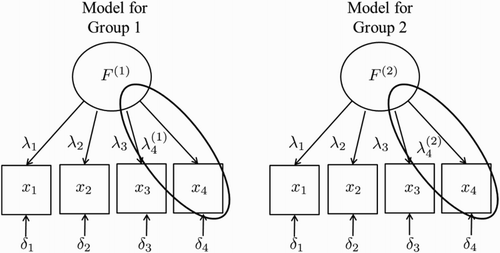
Here, we provide a brief textual and graphical description of the idea behind partial invariance, which should appeal to those familiar with exploratory or confirmatory factor analysis. It is important to note that the model used to estimate achievement is complex and outside the scope of this paper; however, the fundamental idea represented in is the same. In a simple factor model is represented for two groups. In each group, the latent variable or factor is indicated by F, where the superscript (1) and (2) indicate that the parameters describing these factors (e.g., mean and variance) can differ between the two groups. In each group, the factor is measured by four observed variables () and the strength of the relationship between the factor and the observed variable is indicated by the loadings (
) – these are akin to regression coefficients. As in regression, that which is unaccounted for by the factor is expressed as an error term (
). In contrast to the factor loadings for
to
, which are set as equal across the two groups,
is free to vary, as indicated by the superscripts (1) and (2). As noted in a short proof (Steenkamp & Baumgartner, Citation1998), at least two items across all groups should have equal parameters in a standard factor analytic setting to make comparisons on the factor means and variances. When fewer than two items have equivalent parameters, no mean comparisons are possible. As such, this method readily allows for some differences in the factor loadings across participating educational systems, thereby facilitating heterogeneity in the model specification. It is important to note that the tolerance of few common item parameters in an IRT setting for making comparisons across proficiency distributions is an area in need of further research.
Figure 1. Factor analytic representation of partial measurement invariance where one item is allowed a different factor loading between two groups.
Incorporating Innovations Into Non-Cognitive Scales
The first, and perhaps most obvious, means for addressing cross-cultural differences in non-cognitive constructs is for countries to make better use of the national option that allows for the inclusion of country-specific questions, extending the design-based solutions to background scales. Unfortunately, not all countries that participate in ILSAs include these national options and when they do, country specific items are normally only used sparingly. Because national options can provide insights into educational systems that are not available in the more general international questionnaire, the capacity to explain differences in achievement can be significantly increased by introducing more national options. That said, developing valid and reliable background questionnaire items is a task that should not be taken lightly and can require significant resources. Here we suggest that regions who share many commonalities work together to help develop questions and scales targeted towards their systems. Given relative similarities in economic development, culture, and geography, the Nordic region is a reasonable candidate for such development. Although there are important differences between countries, the region shares a great deal in common that could be exploited for questionnaire development. To that end, these countries could pool resources and work together to develop valid scales that can best grasp the underlying constructs. As we show subsequently, current measures fall short in the Nordic context.
Similar to the achievement part of the test, we can also apply model-based solutions to the background questionnaire scales in an effort to improve model fit. That is, some items can have item parameters that are common across countries, while some item parameters are unique to a particular country or groups of countries. The concept is essentially the same as and allows for limited item parameter differences (e.g., partial invariance) across countries, while maintaining comparability on constructs of interest. As the number of groups and items are very large, a sensible automation strategy is important in this context to choose fixed and freely estimated parameters. One possible means for implementing this automated strategy is via a so-called alignment method that essentially searches for the best common solution to a multiple-group measurement model while also allowing for cross-group differences (Asparouhov & Muthén, Citation2014). An advantage of this method over, for example, exploratory factor analysis, is that there are statistical tests of model fit and the possibility of confirmatory-type analyses.
An Empirical Example
To illustrate our suggested approach in the context of background questionnaires, we demonstrate with the PISA 2012 WEALTH scale across several Nordic countries, including Denmark, Finland, Iceland, Norway, and Sweden. According to the PISA technical report (OECD, Citation2014), this scale is comprised of eight international items asking students about their household possessions (a room of their own, a link to the Internet, a DVD player, and the number of cellular phones, televisions, computers, cars, and bath/shower rooms in their house). There is also the possibility of up to three country-specific items, such as an iPhone or an iPad in Norway. The PISA Technical Report indicates that scale reliabilities on the international items range from .57 in Finland to .62 in Norway.
We proceed with our example by fitting confirmatory factor analysis models to each country, where the items are assumed to follow either a binary distribution (in the case of items that ask about presence or absence of a home possession) or an ordered categorical distribution (for items that ask about quantities of home possessions). In this first set of models, we assume that the item parameters are identical across countries (, Model 1). In other words, the factor loadings and thresholds (the categorical version of intercepts) are held equal across countries. This is the approach typically taken in operational settings. Next, we evaluate the improvement in fit that comes from uniquely estimating the worst fitting items in relevant countries, according to a pre-specified criteria (Model 2; here we use modification indices). This is akin to the model-based solution we described previously. Lastly, we evaluate the degree to which model fit is improved by including country-specific items into the individual country models for the wealth scale – the design-based solution. This is evaluated via three separate models: (1) a model in which international items are commonly held as fixed or known values from the previous step and country-specific item factor loadings are fixed to zero, indicating no relationship between the latent variable and those observed variables (Model 3a to 7a, where the model number indexes the corresponding country – we elaborate on this shortly). This will necessarily produce the worst fit of the three considered models. We refer to it as the baseline model; (2) a model that adds country-specific items to the baseline model (Model 3b to 7b); and (3) a model that allows all possible parameters to be freely estimated (Model 3c to 7c). Models 3c to 7c will produce the best fit but will not allow comparison across countries. It is important to note in this context that we are only considering Nordic countries. And as such, our findings might not generalize to the full international sample.
To begin, we note that we modified the wealth scale for the Nordic context, which involved excluding the first two home possessions items (own room and Internet connection) because more than 95% of students responded yes to these items. This left in the model items that asked about the quantity of home possessions. In the interest of space, we only report fit measures, including the chi-square test of model fit, comparative fit index (CFI), Tucker-Lewis Index (TLI), and the root-mean squared error of approximation (RMSEA). In addition, to determine improvement or decrement in fit across models (e.g., 3a compared to 3b), chi-square difference test results, ΔCFI, and ΔRMSEA values are reported.Footnote5 Readers interested in a full set of results, including item parameters and modification indices are encouraged to contact the first author.
In , Model 1, where all parameters are set equal, we see that the results do not fit the data well according to the chi-square test and the RMSEA. In general, the CFI and TLI should be discounted, as they have been found to be insensitive to measurement differences across groups in similar settings; however, poor values are indicative of meaningful problems in model fit. Allowing some poorly-fitting model parameters to have unique estimates in the country exhibiting the most severe misfit results in a statistically significant chi-square difference test, suggesting fit improvement; however, the overall chi-square test for this model remains significant, indicating poor overall fit. Further, improvements in the RMSEA are marginal at best and there was no observed change in the CFI and TLI. Also worth noting is that the model misfit comes primarily from Norway, with a chi-square contribution of 1721.172 in Model 2. As such, we can conclude that there is some improvement in fit when countries are allowed their own unique model parameters on some items; however, this does not completely alleviate the problem of misspecification and poor fit.
Table 3. Comparison of international model to increasingly tailored country-specific models.
Next, we compare country-wise improvement in fit as country-specific items are added to the scales for each country. According to the overall chi-square tests for Models 3a to 7a, the evidence of model misfit is strong and statistically significant in each country. And although the RMSEA values are within the usual cut-off of .05 for Denmark, Iceland, and Sweden, the CFI and TLI values are generally below accepted minimum cut-offs of .90. Taken together, we see that these baseline models fit poorly in all considered countries. Adding country-specific items (Models 3b to 7b) produces significant improvement in fit for all considered countries, as judged by the chi-square difference tests. Further, the change in fit indices (RMSEA and CFI) are also indicative of improved fit (Cheung & Rensvold, Citation2002). That said, the overall chi-square test is significant in all countries, while the overall fit indices indicate at least reasonable fit of the models to the data in Denmark and Sweden. As such, we can conclude that although there are meaningful improvements in model fit that stem from the addition of country-specific items, there is still poor model fit in Finland, Iceland, and Norway.
As a last comparison, we allowed all unique parameters for all items in each country to examine the best possible fit and to determine if much is gained by including unique items and unique item parameters. That is, we compare the partly-tailored international solution and a fully tailored national solution (that is not comparable across countries). Across all countries, the chi-square difference test between Models b and c are statistically significant, indicating improvement in fit. In contrast, we see some mixed evidence from the fit indices and the changes in fit indices. In particular, uniquely estimating all parameters in Denmark produces excellent overall fit according to the fit indices and incremental improvements in both the RMSEA and the CFI; however, only the CFI is improved to a degree that would be regarded as meaningful according to typical criteria (Cheung & Rensvold, Citation2002; Rutkowski & Svetina, Citation2014). The RMSEA values in Finland, Iceland, and Sweden are actually worsened by uniquely estimating all parameters. This pattern is also observed for some fit indices in these countries (e.g., CFI in Iceland and TLI in Finland, Iceland, and Sweden). Although this seems like a paradoxical result, it can be explained by the fact that relatively small improvements in the chi-square are accompanied by relatively large changes in the degrees of freedom, factors that influence each of these measures to some degree (Bollen, Citation1989).
In sum, we can clearly see that the addition of some uniquely estimated parameters across countries as well as some country-specific items has the intended effect of improving model fit across all examined countries. Unfortunately, even in the most flexible, tailored situation, model fit is good in just two of the five analyzed countries, pointing to a real need for a reconsideration of measures of wealth, especially in countries with relatively many resources, such as those considered here.
Discussion
In the current paper, we considered the issue of heterogeneous populations and the degree to which these populations are comparable on typical measures used in international assessments. From both the achievement measures to the non-cognitive measures, international testing programs have historically made efforts, albeit in limited ways, to acknowledge and account for measurement differences that stem from cultural, linguistic, or other differences. But with advances in technology, understanding about the impacts of cultural differences, and knowledge about dealing with measurement heterogeneity, we argue for a step forward in terms of operational procedures for incorporating population heterogeneity directly into the models and methods used to derive non-cognitive scale scores.
In doing so, we would also like to recognize the monumental effort that goes into designing, implementing, and reporting on studies that involves dozens of countries from all over the world and span the spectrum in terms of economic development and capacity. This is clearly no mean feat; however, as discussed throughout this manuscript, there is sufficient evidence to show that the status quo – ignoring or only dealing in very limited ways with heterogeneity – is falling short when it need not. To that end, we offer, as one possible way forward, the active involvement of countries or regions to develop and include more country or regional options into the background questionnaire. As we have shown, even in limited cases, these sorts of tailored item sets do much to improve measurement across countries while preserving comparability of the underlying scales. That said, the success of such an approach also depends on the testing organizations and their willingness to use these tailored options in international scales.
Second, we argue for an approach that relaxes some overly-strict assumptions when developing non-cognitive scales. Specifically, the assumption that all items function in the same way across countries is outmoded and unnecessary. Adequate approaches for relaxing the assumption and allowing for differences in item parameters across countries is possible, reasonable to achieve, and will do much to improve measurement within countries while preserving comparability across countries. Of course, there remains much work to be done in terms of implementing operationally tractable approaches to incorporating uniquely estimated items into background scales; however, there are promising avenues worth pursuing (e.g., Asparouhov & Muthén, Citation2014; Oliveri & von Davier, Citation2014) that will ensure the usefulness of internationally comparative assessments into the future. Finally, we recognize that our proposal is one among many reasonable approaches for attending to the inherent heterogeneity that is part and parcel of international studies. Of course, there may be other, perhaps better, means for dealing with this issue. In taking up this topic, our intention was to foster a dialogue among stakeholders for possible ways to more fully consider the local context in international comparative assessments and to make better use of the resources that go into and the products that come out of ILSAs.
Acknowledgements
We would like to thank the editor and reviewers for their thoughtful feedback on this paper. Any remaining errors of omission or commission are the authors’ own.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
Notes
1 Given the complexity and ambiguity in conceptions of the “nation-state,” particularly for city-states, non-national systems, or territories with disputed or ambiguous political status, we refer to PISA participating units as educational systems. Examples of geographic areas with special status include Dubai (an emirate within the United Arab Emirates), Taiwan (a geographic area with a disputed or ambiguous political status), Hong Kong and Macao (special administrative regions of China) and Singapore (a city-state).
2 Benchmarking participants are non-national systems, such as individual US states, Canadian provinces, and United Arab Emirates.
3 Correlations were corrected for attenuation by using a single indicator measurement model where latent variable means were fixed at 0, latent variable variances were fixed at 1, and the single factor loading was fixed at 1. This allowed for estimation of measurement error variance and a correlation between the two variables that was corrected for measurement error.
4 In previous work (see Rutkowski & Rutkowski, Citation2013) we discuss the validation process of this index in detail.
5 We use the following criteria in determining acceptable model fit: non-significant chi-square; CFI/TLI ≥ .95; RMSEA ≤ .05; ΔCFI ≥ −.004; ΔRMSEA ≤ .05 (Rutkowski & Svetina, Citation2017).
References
- Adams, R. J., & Wu, M. L. (2007). The mixed-coefficients multinomial logit model: A generalized form of the Rasch model. In C. H. Carstensen (Ed.), Multivariate and mixture distribution Rasch models (pp. 57–75). New York, NY: Springer. Retrieved from http://link.springer.com/chapter/10.1007/978-0-387-49839-3_4
- Adams, R. J., Wu, M. L., & Carstensen, C. H. (2007). Multivariate and mixture distribution Rasch models: Extensions and applications. In M. von Davier & C. H. Carstensen (Eds.), Application of multivariate Rasch models in international large scale educational assessment (pp. 271–280). New York, NY: Springer. Retrieved from http://www.springerlink.com/content/n33521777w9g0373/
- Asparouhov, T., & Muthén, B. (2014). Multiple-group factor analysis alignment. Structural Equation Modeling: A Multidisciplinary Journal, 21(4), 495–508. https://doi.org/10.1080/10705511.2014.919210
- Bollen, K. (1989). Structural equations with latent variables. New York, NY: Wiley.
- Brown, G., Micklewright, J., Schnepf, S. V., & Waldmann, R. (2007). International surveys of educational achievement: How robust are the findings? Journal of the Royal Statistical Society: Series A (Statistics in Society), 170(3), 623–646. https://doi.org/10.1111/j.1467-985X.2006.00439.x
- Byrne, B. M., Shavelson, R. J., & Muthén, B. (1989). Testing for the equivalence of factor covariance and mean structures: The issue of partial measurement invariance. Psychological Bulletin, 105(3), 456–466. https://doi.org/10.1037/0033-2909.105.3.456
- Cheung, G. W., & Rensvold, R. B. (2002). Evaluating goodness-of-fit indexes for testing measurement invariance. Structural Equation Modeling: A Multidisciplinary Journal, 9(2), 233–255. https://doi.org/10.1207/S15328007SEM0902_5
- von Davier, M., Gonzalez, E., & Mislevy, R. J. (2009). What are plausible values and why are they useful? IERI Mongraph Series, 2, 9–36.
- Goldstein, H. (2004). International comparisons of student attainment: Some issues arising from the PISA study. Assessment in Education: Principles, Policy & Practice, 11(3), 319–330. https://doi.org/10.1080/0969594042000304618
- Hambleton, R. K., & Rogers, H. J. (1989). Detecting potentially biased test items: Comparison of IRT area and Mantel-Haenszel methods. Applied Measurement in Education, 2(4), 313–334. https://doi.org/10.1207/s15324818ame0204_4
- He, J., & van de Vijver, F. J. (2013). Methodological issues in cross-cultural studies in educational psychology. In G. A. D. Liem & A. B. I. Bernardo (Eds.), Advancing cross-cultural perspectives on educational psychology (Vol. Advancing cross-cultural perspectives on educational psychology). Charlotte, NC: Information Age. Retrieved from http://www.researchgate.net/profile/Fons_Van_de_Vijver/publication/259176988_Methodological_Issues_in_Cross-Cultural_Studies_in_Educational_Psychology/links/02e7e52a2175522d1d000000.pdf
- Klieme, E., & Kuger, S. (n.d.). Pisa 2015 draft questionnaire framework. Frankfurt: DIPF. Retrieved from https://www.oecd.org/pisa/pisaproducts/PISA-2015-draft-questionnaire-framework.pdf
- Kreiner, S., & Christensen, K. B. (2014). Analyses of model fit and robustness. A new look at the PISA scaling model underlying ranking of countries according to Reading literacy. Psychometrika, 79(2), 210–231. https://doi.org/10.1007/s11336-013-9347-z
- Marsh, H. W., Abduljabbar, A. S., Parker, P. D., Morin, A. J. S., Abdelfattah, F., & Nagengast, B. (2014). The big-fish-little-pond effect in mathematics: A cross-cultural comparison of US and Saudi Arabian TIMSS responses. Journal of Cross-Cultural Psychology, 45(5), 777–804. https://doi.org/10.1177/0022022113519858
- Martin, M. O., & Mullis, I. V. S. (Eds.). (2012). Methods and procedures in TIMSS and PIRLS 2011. Chestnut Hill, MA: TIMSS & PIRLS International Study Center, Boston College.
- Mazzeo, J., & von Davier, M. (2009). Review of the Programme for International Student Assessment (PISA) test design: Recommendations for fostering stability in assessment results. Presented at the NCES conference on the Programme for International Student Assessment: What Can We learn from PISA? Washinton, DC.
- Mellenbergh, G. J. (1982). Contingency table models for assessing item bias. Journal of Educational and Behavioral Statistics, 7(2), 105–118. https://doi.org/10.3102/10769986007002105
- Meredith, W. (1993). Measurement invariance, factor analysis and factorial invariance. Psychometrika, 58(4), 525–543. https://doi.org/10.1007/BF02294825
- Millsap, R. E. (2011). Statistical approaches to measurement invariance. New York, NY: Routledge.
- Mislevy, R. J. (1991). Randomization-based inference about latent variables from complex samples. Psychometrika, 56(2), 177–196. doi: 10.1007/BF02294457
- Mislevy, R. J., Beaton, A. E., Kaplan, B., & Sheehan, K. M. (1992). Estimating population characteristics from sparse matrix samples of item responses. Journal of Educational Measurement, 29(2), 133–161. doi: 10.1111/j.1745-3984.1992.tb00371.x
- Mislevy, R. J., Johnson, E. G., & Muraki, E. (1992). Chapter 3: Scaling procedures in NAEP. Journal of Educational and Behavioral Statistics, 17(2), 131–154. https://doi.org/10.3102/10769986017002131
- Muthén, L., & Muthén, B. O. (1998). Mplus user’s guide (7th ed.). Los Angeles, CA: Muthén & Muthén.
- OECD. (2010). Pisa 2009 technical report. Paris: OECD. Retrieved from http://www.oecd.org/edu/preschoolandschool/programmeforinternationalstudentassessmentpisa/pisa2009technicalreport.htm
- OECD. (2012). Pisa 2009 technical report. Paris: OECD Publishing. Retrieved from http://www.oecd.org/edu/preschoolandschool/programmeforinternationalstudentassessmentpisa/pisa2009technicalreport.htm
- OECD. (2014). Pisa 2012 technical report. Paris: OECD Publishing.
- OECD. (2015). Skills for social progress: The power of social and emotional skills. Paris: OECD Publishing.
- Oliveri, M. E., & von Davier, M. (2011). Investigation of model fit and score scale comparability in international assessments. Psychological Test and Assessment Modeling, 53(3), 315–333.
- Oliveri, M. E., & von Davier, M. (2014). Toward increasing fairness in score scale calibrations employed in international large-scale assessments. International Journal of Testing, 14(1), 1–21. https://doi.org/10.1080/15305058.2013.825265
- Oliveri, M. E., & Ercikan, K. (2011). Do different approaches to examining construct comparability in Multilanguage assessments lead to similar conclusions? Applied Measurement in Education, 24(4), 349–366. https://doi.org/10.1080/08957347.2011.607063
- Olsen, R. V. (2012). An exploration of cluster structure in scientific literacy in PISA: Evidence for a Nordic dimension? Nordic Studies in Science Education, 1(1), 81–94. doi: 10.5617/nordina.468
- Rasch, G. (1980). Probabalistic models for intelligence and attainment tests (2nd ed.). Chicago, IL: University of Chicago.
- Rutkowski, D., & Rutkowski, L. (2013). Measuring socioeconomic background in PISA: One size might not fit all. Research in Comparative and International Education, 8(3), 259–278. doi: 10.2304/rcie.2013.8.3.259
- Rutkowski, L., & Rutkowski, D. (2010). Getting it “better”: The importance of improving background questionnaires in international large-scale assessment. Journal of Curriculum Studies, 42(3), 411–430. https://doi.org/10.1080/00220272.2010.487546
- Rutkowski, L., Rutkowski, D., & Engel, L. (2013). Sharp contrasts at the boundaries: School violence and educational outcomes internationally. Comparative Education Review, 57(2), 232–259. https://doi.org/10.1086/669120
- Rutkowski, L., Rutkowski, D., & Zhou, Y. (2016). Item calibration samples and the stability of achievement estimates and system rankings: Another look at the PISA model. International Journal of Testing, 16(1), 1–20. doi: 10.1080/15305058.2015.1036163
- Rutkowski, L., & Svetina, D. (2014). Assessing the hypothesis of measurement invariance in the context of large-scale international surveys. Educational and Psychological Measurement, 74(1), 31–57. https://doi.org/10.1177/0013164413498257
- Rutkowski, L., & Svetina, D. (2017). Examining fit criteria in categorical measurement models with a large number of groups. Applied Measurement in Education, 30(1), 39–51.
- Steenkamp, J.-B. E., & Baumgartner, H. (1998). Assessing measurement invariance in cross-national consumer research. Journal of Consumer Research, 25(1), 78–107. doi: 10.1086/209528
- TIMSS & PIRLS International Study Center. (2013). PrePIRLS information sheet. Retrieved September 18, 2015, from http://timss.bc.edu/pirls2011/prepirls.html
- Traynor, A., & Raykov, T. (2013). Household possessions indices as wealth measures: A validity evaluation. Comparative Education Review, 57(4), 662–688. https://doi.org/10.1086/671423