
ABSTRACT
An evaluation of forensic hair analysisbetween experts, novices and the recently developed machine learning platform, HairNet, was conducted to assess accuracy and reliability. Our hypothesis stated experts and the machine learning platform will outperform novices in classifications of hair as human or non-human and suitability for nDNA analysis based on specialist knowledge and from training of the model. Statistically significant differences between novices and experts were found and attributed to training and experience for more complex classifications. For more simplistic classifications, no statistically significant difference between the novice and the experts was found. HairNet proved responses similar to expert responses in all classifications. Encouraging feedback was received regarding the use of technology and machine learning. The utilization of technology undoubtedly holds great promise to become part of the forensic tool kit for improving the efficiency and reliability of forensic hair analysis and in research, education and competency testing.
1. Introduction
Hair is a type of trace evidence, and forensic hair analysis can be described in terms of examinations or comparisons. Hair examinations are conducted to determine if a hair is of human or non-human origin, and if the hair is human, its suitability for routine nDNA analysisCitation1. The origin of human or non-human hair can be determined from the microscopic observations of several features. The medulla is a hair feature that is an air-filled sac located along the mid-section of the hair shaftCitation1. Human hairs can be characterized by the absence of a medulla or a medulla occupying less than one-third of the width of the hair shaftCitation1. In contrast, non-human hairs can be characterized by the medulla occupying more than one-third of the width of the hair shaftCitation1. Suitability of human hair for nDNA analysis is determined from three defined stages of hair growth that correspond to three hair root types: anagen, catagen and telogenCitation1.
Anagen is an active growth stage where roots have a ribbon-like appearance and are viable for nDNA analysisCitation1. Catagen is the resting growth stage where roots are similar to anagen roots and also viable for nDNA analysisCitation1. Telogen is a cessation of growth stage and may be viable for nDNA analysis depending on the appearance of the hair rootCitation1. Telogen type 1 roots have a clubbed appearance and are not viable for nDNA analysis. Telogen type 2 and type 3 roots have follicular cells, potentially rich in nDNA, attached and viability for nDNA analysis is determined from additional analysis, such as nuclear staining of the rootCitation2.
When human hair is considered suitable for nDNA analysis, no further examinations are required for source determination. When a human hair is considered not suitable for nDNA analysis, or a hair is of non-human origin, a comparison can be conducted. Hair comparisons involve microscopic observations and documentation of multiple features of known and questioned hairs. From the comparison of these features, questioned hairs can be excluded or included as a likely source of the known hairs, not individualized or matchedCitation1. Included hairs can be submitted for mtDNA analysis, and opinions on the exclusion or inclusion of a questioned hair can be provided with consideration of context and limitationsCitation1.
Forensic hair analysis can yield valuable information, not only in major crime, and remains a capability within accredited laboratories worldwideCitation3. Within the accredited laboratory, forensic hair analysis is assessed on individual hair analyst’s authorizationsCitation4. In Australia, laboratory accreditation is conducted by the National Association of Testing Authorities (NATA) that assesses contemporary standards of practice against international and national standards such as ISO/IEC 17020 and AS 5388Citation5,Citation6. Irrespective of the value of forensic hair analysis and the stringent laboratory and scene accreditations worldwide, the validity and reliability of hair examinations has been scrutinized.
In 2002, an evaluation of the Federal Bureau of Investigation (FBI) hair comparison casework was publishedCitation7,Citation8. The evaluation highlighted deficiencies in court testimony where comparisons of questioned hairs to known hairs were described as ‘indistinguishable’ and later found, through mtDNA analysis, to be from different individualsCitation8. From this evaluation, a 2009 report reasoned that hair comparisons lacked validity and reliability and attributed to the several wrongful convictions and exonerations from hair comparison testimonyCitation9–11. An independent evaluation of FBI hair comparison casework attributed error, bias and exaggerated opinions in court testimony to a lack of supervision, leadership, management overconfidence and insufficient monitoringCitation8. The importance of validity and reliability of forensic hair analysis and other forensic feature-comparison methods was re-emphasized in a 2016 report that highlighted the need to develop more objective methodologiesCitation12. As a result of external scrutiny and association with wrongful convictions forensic hair analysis value has diminishedCitation4,Citation13. Subsequently, forensic practitioners with limited training and expertise often conduct hair examinations for triage purposes only and fewer laboratories worldwide conduct comparisonsCitation13. In response, more objective methodologies are needed.
Machine learning is an innovative approach to forensic methodology that can be applied to a variety of datasets and its use is supported by forensic practitioners and academicsCitation14. Machine learning models have significant potential to form part of a forensic toolkit in training, proficiency testing and rapid forensic intelligence, for several forensic disciplines. Machine learning has been developed for the interpretation of images of hair featuresCitation14. Despite the importance of validity and reliability, and in the light of machine learning developments and validation of quantifiable hair drug detection, there are few recent evaluations of forensic hair analysis methodologyCitation12,Citation14,Citation15.
The aim of this study was to conduct an evaluation of forensic hair analysis in terms of accuracy and reliability of classifications between experts, novices and the recently developed machine learning platform, HairNet. Forensic hair analysis is valid to the extent that it produces accurate results, such as correct classificationsCitation16. Reliability describes result consistency and can be determined from the reproducibility and repeatability of classifications at one timeCitation16. Our hypothesis was experts will outperform novices in classifications of hair as human or non-human and suitability for nDNA analysis based on specialist knowledge. Furthermore, the machine learning platform will perform similarly to experts as the model was trained and tested on the similar images of medullas and hairs as those presented in the study with high accuracy for these classificationsCitation14. This study will evaluate human judgement and the necessity of specialized knowledge, identify limitations and gauge the capacity for machine learning models in forensic hair analysis. Furthermore, as this study was conducted online, the use of technology for web-based studies and web-based competency testing was assessed.
2. Materials and methods
2.1. Hair preparation and imaging
Human and non-human hairs were used that had been collected for forensic hair analysis research (University of Canberra (UC) Ethics Committee Project ID: 1771). Hairs were prepared for imaging by mounting the hair onto a glass slide in glycerol or haematoxylin mounting medium with a glass coverslip or by placing the hair within a clip sealed plastic bag. Human and non-human hair shafts were visualized with a Leica compound microscope at high magnification (up to x400 magnification) and the medulla, where present, or the mid-section of the hair shaft imaged with Leica imaging software and images labelled. Images were labelled as human or non-human hairs based on the features of the medulla or absence of the medulla. Hair roots were similarly visualized with a Leica stereo microscope at low magnification (up to ×40 magnification) and imaged with Leica imaging software and images labelled. Images were labelled as anagen/catagen and telogen types 1, 2 and 3 hair roots. Visualization and imaging of hair features in this way are accepted locally and worldwide by hair analysts for level 1 and level 2 forensic hair analysis and as such the quality of the images used in this research is the same as the quality of images used in case workCitation4. All images and their labels (classifications) were independently verified by three forensic hair analysts and considered to be ground truth.
2.2. Hair analysis study and participants
The hair analysis study was developed as an anonymous online (Typeform) questionnaire that incorporated the images of hairs for participants to classify (see Appendix 1). Participants were sourced through laboratories where forensic hair analysis is performed, through worldwide forensic networks and on social media. An invitation message was sent to each participant that contained information about the study and access to the study via an online link. Consent to participate was obtained in the first question of the study where participants agreed or disagreed with a consent statement (see Appendix 1). Experience in forensic hair analysis was determined in the second question where participants rated their experience on a scale that ranged from having limited or no experience to being a practicing hair analyst. Participants with limited or no experience were considered as novices and practicing hair analysts as experts. Novices were directed to an information sheet through an online link (see Appendix 1). The information sheet contained a description and images of the hair features used to determine whether a hair is human or non-human, and if human, whether the hair is suitable for routine nDNA analysis (see Appendix 2).
The body of the study was comprised of 24 images for participants to classify by selecting a single response from multi-choice options. The classifications were independently verified by three forensic hair analysts and considered to be ground truth. Of the 24 images, 10 were of hair shafts/medullas and 14 were of hair roots. Of the images of hair shafts/medullas, five were human in origin and five were non-human in origin. The options provided to the participants for the classification of these images were as follows: human, non-human or unable to determine. The options provided for the hair root classifications and subsequent suitability for nDNA analysis reflected the labels used in past research machine model classifications and based on suitability for nDNA analysisCitation14. These classifications of hair roots were anagen/catagen, telogen type 1 or telogen type 2/3 and corresponding suitability for nDNA analysis. When presented with each image, participants selected a single option to classify the image or selected the option unable to determine.
Demographic questions and options to provide feedback on online studies and machine learning were included at the end of the study. The study was designed to be minimal, specific and easy to follow and enable participant responses and classifications to be independentCitation16. An option for participants to provide their email for follow-up questions specific to forensic hair analysis methodology was provided to experts only. Ethics approval was obtained prior to the dissemination of the invitation message (UC Ethics Committee Project ID: 11826).
2.3. Machine learning model
The hair analysis platform, HairNet, was used in this researchCitation14. To equal the number of novices and expert participants and detect any variation in the machine learning model classifications, the model was retrained, and new parameters saved 36 times prior to classification of random order of the 24 microscopic images of hairs by the model. Each output was treated as an independent classification of the data. This approach was taken so that each retrained model classifications could be treated as independent, like each human participant. This process was automated through the development of python script and is available on GitHubCitation17. Of note, the option, unable to determine, is not a response the model can provide as machine learning algorithms produce absolute classifications and do not have the capacity to be undecided and as such data analysis was adjusted to accommodate this. Model classifications were analysed to determine any differences between the three independent groups (novice, expert and model), and the option, unable to determine, for novices and experts was excluded from this analysis. Furthermore, data from two of the images was excluded from this analysis as one of these images contained multiple hairs and the other image contained a partly blurred image. As the model had not been trained with images containing multiple hairs or partly unfocused images, it would not be appropriate to use this data when evaluating the model. Three independent groups (novices, experts and model) adjusted percentage responses (correct and incorrect classifications) based on ground truth of the images were determined.
2.4. Statistical analysis
Two independent groups (novices and experts) study responses (correct, incorrect classifications and the unable to determine option) based on the ground truth of the images were determined. To determine any statistically significant difference between novices and experts, study responses for the classification of hair shafts and medullas as non-human or human and the classification of hair roots as anagen/catagen, telogen type 1 or telogen type 2/3 and subsequent suitability for nDNA analysis, statistical analysis was conducted. Chi-squared tests of homogeneity were conducted and post hoc analysis to determine which classifications were statistically different. The post hoc analysis involved pairwise comparisons using multiple z-tests with a Bonferroni correction where statistical acceptance was accepted at p < 0.016667. When all assumptions for the chi-squared test were not met, a Fisher’s exact test was conducted. The machine learning classifications of the 24 hairs were analysed to determine any differences between study and model responses (correct and incorrect classifications) by the three groups (novice, expert and model). The data for unable to determine responses for novices and experts were excluded from this analysis. Chi-squared tests of homogeneity were conducted and post hoc analysis was performed to determine statistically different classifications. Demographic data and feedback were analysed with descriptive statistics and a thematic analysis. Results have been reported as percentages rather than as portions as the number of novices was equal to the number of experts and the study design was therefore balanced.
3. Results
The study was completed by 72 participants. Half of the participants identified as having limited or no experience with forensic hair analysis (novices) and half identified as practicing forensic hair analysts (experts). Participants were from Australia (57%), the USA (28%), the United Kingdom (UK), Mainland Europe and the Republic of Ireland (14%) and one participant preferred not to say. Participants' highest level of education ranged from high/senior school (10%), diploma (8%), degree (17%), honours degree (8%), graduate certificate (1%), graduate diploma (7%) and masters (36%) to doctorate (7%).
3.1. Hair analysis study – human and non-human classifications
For human and non-human classifications, the two multinomial probability distributions were not equal in the population, human classifications, X2(2) = 17.848, p < 0.01 and non-human classifications, X2(2) = 8.962, p < 0.05. There was a statistically significant difference in the multinomial probability distributions between novices and experts for human and non-human classifications. The observed responses and percentage of all responses are shown in and responses in .
Table 1. Human and non-human classification novice and expert responses and percentages. UTD – unable to determine.
Graph 1. Human and non-human classification novice and expert responses.
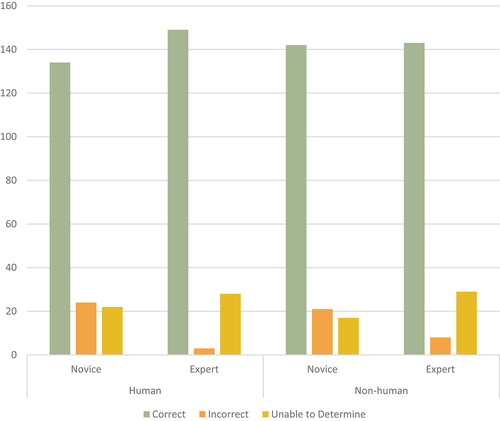
Post hoc analysis found for the human classifications there was statistically significant differences in the percentage of novices with incorrect responses to experts (n = 22, 13.3% versus n = 3, 1.7%), p < 0.01667, whereby novices made more incorrect responses than experts. There was no statistical significance in the percentage of novices with correct responses to experts (n = 134, 74.4% versus n 149, 82.8%) and the percentage of novices with the response unable to determine to experts (n = 22, 12.2% versus n = 28, 15.6%), p > .01667. For the non-human classifications, there were statistically significant differences in the percentage of novices with incorrect responses to experts (n = 21, 11.7% versus n = 8, 4.4%), p < 0.01667, whereby novices again made more incorrect responses than experts. There was no statistical significance in the percentage of novices with correct responses to experts (n = 142, 78.9% versus n 143, 79.4%) and the percentage of novices with the response unable to determine to experts (n = 17, 9.4% versus n = 29, 16.1%), p > .01667.
3.2. Hair analysis study – hair root classifications
For hair root classifications, the two multinomial probability distributions were not equal in the population for the anagen/catagen classifications, XCitation2(2) = 66.805, p < 0.001 and the telogen type 2/3 classifications, XCitation2(2) = 13.492, p = 0.001. There was a statistically significant difference in the multinomial probability distributions between novices and experts for the anagen/catagen and telogen type 2/3 classifications. For the telogen type 1 classifications, the Fisher’s exact test was used to determine statistically significant differences. The two multinomial probability distributions were equal in the population for the telogen type 1 classifications, p = 0.081 and the multinomial probability distributions between novices and experts were not statistically significantly different, p > 0.05. The observed responses and percentage of all responses are shown in and responses in .
Table 2. Hair root classification novice and expert responses – A/C (anagen/catagen), T1 (telogen type 1) and T2/3 (telogen types 2 and 3) responses and percentages. UTD – unable to determine.
Graph 2. Hair root classification novice and expert responses – A/C (anagen/catagen), T1 (telogen type 1) and T2/3 (telogen types 2 and 3).
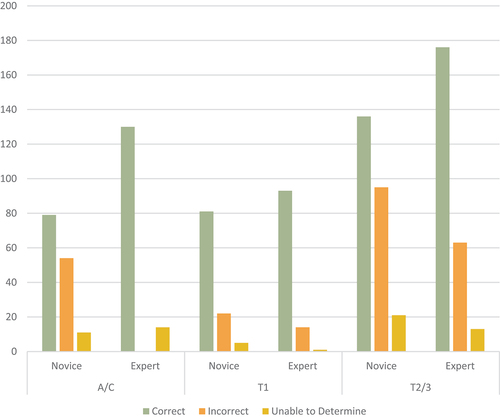
Post hoc analysis found that for the anagen/catagen classifications, there were statistically significant differences in the percentage of novices with correct responses to experts (n = 79, 54.9% versus n = 130, 90.3%), meaning experts made more correct responses than novices, and the percentage of novices with incorrect responses to experts (n = 54, 37.5% versus n = 0), p < .016667. There was no statistical significance in the proportion of novices with the response unable to determine to experts (n = 11, 7.6% versus n = 14, 9.7%), p > .01667. For the telogen type 2/3 classifications, there were statistically significant differences in the percentage of novices with correct responses to experts (n = 136, 54.0% versus n = 176, 69.8%), whereby experts made more correct responses than novices, and the percentage of novices with incorrect responses to experts (n = 95, 37.7% versus n = 63, 25.0%), and the percentage of novices with the response unable to determine to experts (n = 21, 8.3% versus n = 13, 5.2%), p < 0.01667.
3.3. Machine learning model – human and non-human classifications
For the human and non-human medulla classifications there was a statistically significant difference between the three independent binomial proportions, p < 0.001. The observed percentage of the adjusted responses are shown in and .
Table 3. Human and non-human classification novice and expert percentage responses.
Graph 3. Human and non-human classification novice, expert and model percent responses.
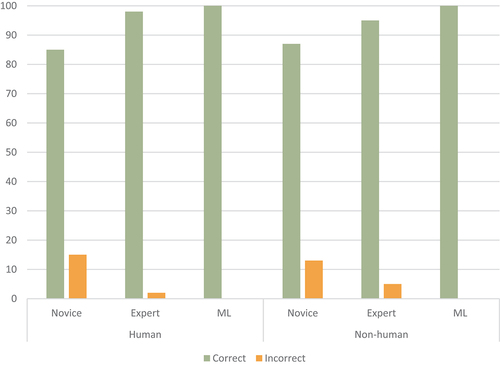
Post hoc analysis found that for human medulla classifications, there is a significant difference between the expert and the model responses to the novice responses, p < 0.05. The expert and model responses were not significantly different. For non-human medulla classifications, there is a significant difference between the novice and the model responses, p < 0.05. The novice and expert responses as well as the model and expert responses were not significantly different.
3.4. Machine learning model – hair root classifications
For the anagen/catagen and telogen type 1 classifications, there was a statistically significant difference between the three independent binomial proportions, p < 0.001. For the telogen type 2/3 classifications, the three independent binomial proportions were not statistically significant, p > 0.05. The observed percentage of the adjusted responses are shown in and .
Table 4. Hair root classification novice, expert and model percentage responses – A/C (anagen/catagen), T1 (telogen type 1) and T2/3 (telogen types 2 and 3).
Graph 4. Hair root classification novice, expert and model percent responses – A/C (anagen/catagen), T1 (telogen type 1) and T2/3 (telogen types 2 and 3).
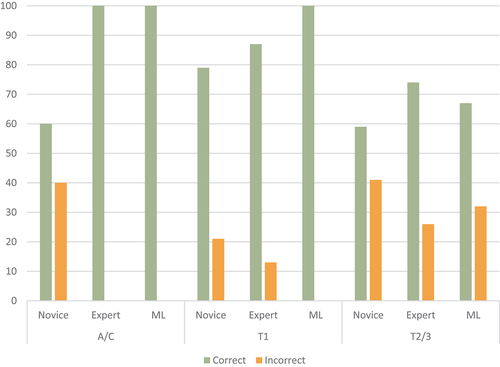
Post hoc analysis found that for the anagen/catagen classifications, there is a significant difference between the expert and the model responses to the novice responses, p < 0.05. The expert and model responses were not significantly different. For the telogen type 1 classifications, there was a significant difference between the novice and the expert responses to the model responses, p < 0.05. The novice and expert responses were not significantly different. For the telogen type 2/3 classifications, the three independent binomial proportions were not statistically significant, p > 0.05.
3.5. Participant feedback
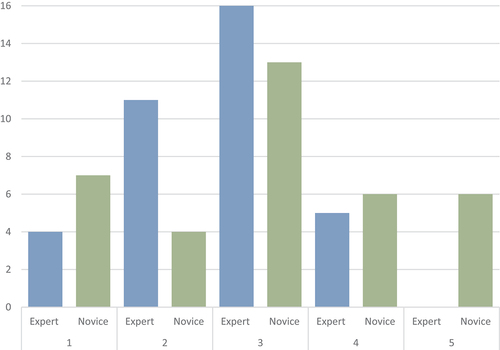
Participants were asked to provide feedback on the use of web-based studies and web-based competency testing and the study. Of the few comments received, the majority were from hair analysts. Feedback from participants with no experience with forensic hair analysis was positive and encouraging towards the use of technology. Feedback from hair analysts questioned the quality of the images and types of classifications. Hair analysts expressed a preference to have the hair they are classifying available for further analysis but encouraged more online studies. Interestingly, despite the critique of the study, hair analysts mostly correctly classified human and non-human hairs and anagen/catagen and telogen type 1 root types. Participants rated their perceived level of difficulty of the study on a five-point scale from easy (1) to hard (5) and the responses are shown in .
Graph 5. Expert and novice rating of the level of difficulty of the study from easy (1) to hard (5).
4. Discussion and conclusion
More than 20 years have passed since the 2002 FBI evaluation of hair comparison casework and associated expert testimonyCitation8. The issues raised about the validity and reliability of methodology, error and the persuasiveness of expert testimony remainCitation18–23. The evaluation of forensic hair analysis classifications in terms of accuracy and reliability among experts, novices and the recently developed machine learning platform, HairNet, is presented here in terms of human and non-human classification and suitability for nDNA analysis classification.
The classification of hair as human or non-human is based, among other features, on the judgement of the width of the medulla being greater than or less than a third of the width of the hair shaft and that human hairs may not have a visible medullaCitation1. Forensic hair analysis casework includes the analysis of both human and non-human hair so any incorrect classification could be detrimental to a case. For both human and non-human classifications, statistically significant differences between novices and experts were found for incorrect responses whereby experts made significantly fewer incorrect classifications than novices. Fewer incorrect classifications by experts can be attributed to training and experience for more complex classifications when the medulla is close to one-third of the width of the hair. That there was no statistically significant difference between novices and expert responses and that both novices and experts had high percentages of correct classifications, supports the general straightforwardness of the type of classification when the medulla is distinctly less than or greater than one-third of the width of the hair or is absent.
With the inclusion of the machine learning platform, the classification of hair as human or non-human produced responses similar to expert responses. For human hair classification, the expert and model responses were both significantly different from the novice responses, while the expert and the model responses were not significantly different. The model correctly classified 100%, the expert correctly classified 98% and the novice correctly classified 85% of human hairs. For non-human hair classifications, although statistically significant differences between the novice and model responses were found, differences between model and the expert classifications and differences between the novice and the expert classifications were not significant. The model correctly classified 100%, the expert correctly classified 95% and the novice correctly classified 87% of non-human hairs.
That the model and the expert performed similarly and that the model outperformed the novice for both human and non-human classifications supported our hypothesis. That experts and the model outperformed the novice supports the need for specialized forensic knowledge and training for more complex classifications. The use of specialized forensic knowledge in the formation of opinions can be used to inform court testimony where expertise is questioned. The capacity of machine learning models to human and non-human classifications is evident from the percentage correctly classified; however, in terms of machine learning, 100% accuracy rate can indicate that classification is limited and would benefit from more diverse training and testing dataCitation24.
The classification of hair as suitable for nDNA analysis is based on the judgement of the stage of growth of the hair and the root typeCitation3. The suitability of hair for nDNA analysis is conducted only on human hair. A false-negative classification (type 2 error), of a hair as not suitable for nDNA analysis when it is suitable would have the most negative outcome. In contrast, a false-positive classification (type 1 error) of a hair as suitable when it is not would have a minor impact on the outcomes of a case. Statistically significant differences between novices and experts were found between correct and incorrect responses for anagen/catagen classifications. Notably, the expert made no incorrect classifications of anagen/catagen hair roots. This result can be attributed to training, knowledge and experience. There was no statistical significance between novices and experts with the responses for anagen/catagen classifications for the option, unable to determine. No statistically significant difference between novices and experts was found for telogen type 1 classifications. That both novices and experts had high percentages of correct responses supports the simplicity of this classification as the telogen type 1 hair root resembles a common item, the cotton bud, that is easy to distinguish. Statistically significant differences between novices and experts were found between all responses for telogen two/three classifications whereby experts made significantly more correct classifications and significantly fewer incorrect responses and unable to determine responses than novices. This result can also be attributed to training, knowledge and experience. Notably, experts made the most incorrect classifications for telogen type 2/3 roots than any other root type.
From the inclusion of the machine learning platform, HairNet, for the anagen/catagen classifications, the model and the expert were significantly different from the novice responses whereby both the model and the expert correctly classified 100% of anagen/catagen roots and the novice correctly classified 60% of anagen/catagen roots. For the telogen type 1 classifications, the model was statistically different from the novice and the expert whereby the model correctly classified 100% of telogen type 1 roots and the novice and the expert correctly classified 79% and 87% of telogen type 1 roots, respectively. The significance of this result changed from the inclusion of the model; however, that there was no statistically significant difference between the novice and the expert further supports the simplicity of this classification. No statistically significant difference between novices, experts and the model was found between all responses for telogen type 2/3 classifications. That the expert outperformed the novice for anagen/catagen and telogen type 2/3 classifications supports the need for specialized forensic knowledge. The capacity of machine learning models for hair root-type classification is evident from the percentage correctly classified.
The findings of our study support the hypothesis that experts outperformed novices in accurately classifying hair as human or non-human and determining suitability for nDNA analysis. The machine learning platform, HairNet presented comparable accuracy and reliability to experts. Consequently, both the experts and the machine learning platform consistently generated precise results across all classification tasks. This finding highlights the essential role of human judgement and specialized knowledge in forensic hair analysis. Regarding the model, this finding highlights the importance of training and testing data for model accuracy and further emphasizes the importance of human judgement and specialized knowledge whereby the option, unable to determine, could only be made by experts and novices. Although the relevance of forensic hair analysis has been undervalued, the growing incorporation of appropriately trained and tested technology in forensic research, education and testing is promisingCitation25. Feedback from experts and novices was encouraging, with participants perceiving the study as neither too easy nor too hard, although concerns were raised regarding image quality and classifications. To augment the forensic analyst’s toolkit, technology and machine learning can be effectively implemented for triage purposes and developed for comparisons of hair features such as colour and pigment, which lack a standardized approach for inclusion determination hairsCitation26. Furthermore, the creation of a comprehensive database documenting hair features within the population would further enhance the potential benefits of machine learning to forensic hair analysis. Ultimately, the utilization of technology holds immense promise for enhancing the efficiency and dependability of forensic hair analysis in various domains, including research, education and competency testing.
Presentations
This research has been accepted for as an oral presentation at the Australian and New Zealand Forensic Science Society Symposium in 11–15 September 2022.
Appendix 1
Download PDF (415.3 KB)Appendix 2
Download PDF (1.7 MB)Appendix 3
Download PDF (685.9 KB)Disclosure statement
No potential conflict of interest was reported by the author(s).
Supplementary material
Supplemental data for this article can be accessed online at https://doi.org/10.1080/00450618.2023.2254337.
Additional information
Funding
References
- Robertson J, Brooks E. A practical guide to the forensic examination of hair: from crime Scene to court. CRC Press; 2022. https://researchprofiles.canberra.edu.au/en/publications/a-practical-guide-to-the-forensic-examination-of-hair-from-crime-.
- Brooks E, Cullen M, Sztydna T, Walsh S. Nuclear staining of telogen hair roots contributes to successful forensic nDNA analysis. Aust J Forensic Sci. 2010;42(2):115–122. doi:10.1080/00450610903258136.
- Airlie M, Robertson J, Brooks E. Forensic hair analysis – Worldwide survey results. Forensic Sci Int. 2021;327:110966. doi:10.1016/j.forsciint.2021.110966.
- Robertson J. Managing the forensic examination of human hairs in contemporary forensic practice. Aust J Forensic Sci. 2017;49(3):239–260. doi:10.1080/00450618.2017.1279838.
- NATA procedures for accreditation. National association of testing authorities. 2021. [ Online] https://nata.com.au/files/2021/05/NATA-procedures-for-accreditation.pdf.
- Doyle S. A review of the current quality standards framework supporting forensic science: risks and opportunities. WIREs Forensic Sci. 2020;2(3):e1365. doi:10.1002/wfs2.1365.
- Houck M, Budowle B. Correlation of microscopic and mitochondrial DNA hair comparisons. J Forensic Sci. 2002;47(5):964–967. doi:10.1520/JFS15515J.
- ABS Group Report. Root and Cultural cause analysis of report and testimony Errors by FBI MHCA Examiners. FBI Vault. [ Online]; 2019. https://vault.fbi.gov/root-cause-analysis-of-microscopic-hair-comparison-analysis/root-cause-analysis-of-microscopic-hair-comparison-analysis-part-01-of-01/view.
- National Academy of Sciences. Strengthening forensic science in the United States. Washington, DC: The National Academies Press; 2009. https://www.ojp.gov/pdffiles1/nij/grants/228091.pdf.
- Laporte G. Wrongful convictions and DNA exonerations: understanding the role of forensic science. National Institute of Justice; 2018. [Online]. https://www.ojp.gov/pdffiles1/nij/250705.pdf.
- Koen W, Bowers M. Forensic science Reform: protecting the Innocent. Academic Press; 2017. doi:10.1016/B978-0-12-802719-6.00002-9.
- President’s Council of Advisors on Science and Technology. Forensic science in the criminal Courts: ensuring scientific validity of feature-comparison Methods; 2016.
- Airlie M, Robertson J, Krosch M, Brooks E. Contemporary issues in forensic science – Worldwide survey results. Forensic Sci Int. 2021;320:110704. doi:10.1016/j.forsciint.2021.110704.
- Airlie M, Robertson J, Wanli M, Airlie D, Brooks E. A novel application of deep learning to forensic hair analysis methodology. Aust J Forensic Sci. 2022;1–12. doi:10.1080/00450618.2022.2159064.
- Mannocchi G, Annagiulia D, Anastasio T, Simona Z, Massimo G, Simona P, Francesco P. Development and validation of fast UHPLC-MS/MS screening method for 87 NPS and 32 other drugs of abuse in hair and nails: application to real cases. Anal Bioanal Chem. 2020;412(21):5125–5145. doi:10.1007/s00216-020-02462-6.
- OSAC. The Organisation of scientific area committees for forensic science [ Online]. https://www.nist.gov/topics/organization-scientific-area-committees-forensic-science.
- Airlie M, GitHub. 2023. Machine Learning Forensic Application. https://github.com.
- Roady J. The PCAST report a review and moving forward - A prosecutor’s perspective. Crim Justice Online. 2017;32. https://forensicresources.org/articles/the-pcast-report-a-review-and-moving-forward-a-prosecutors-perspective/.
- Hunt T. Scientific validity and error rates: A short response to the PCAST report. Fordham Law Rev Online. 86;2017. https://ir.lawnet.fordham.edu/flro/vol86/iss1/14.
- Wilkinson R, Gwinnett C. An international survey into the analysis and interpretation of microscopic hair evidence by hair examiners. Forensic Sci Int. 2020;308:110158. doi:10.1016/j.forsciint.2020.110158.
- Ross A. The reliability and validity of expert evidence: law, science and medicine in summit. The rapporteur’s view. Aust J Forensic Sci. 2020;52(3):246–248. https://doi.org/10.1080/00450618.2019.1711183.
- Van Straalen E, De Poot C, Malsch M, Elffers H. The interpretation of forensic conclusions by criminal justice professionals: the same evidence interpreted differently. Forensic Sci Int. 2020;313:110331. doi:10.1016/j.forsciint.2020.110331.
- Roberts A. Knowledge, reliability, and the admissibility of forensic science evidence. Aust J Forensic Sci. 2020;52(3):269–274. doi:10.1080/00450618.2020.1729238.
- Vallantin L. Why you should not trust only in accuracy to measure machine learning performance [ Online]. 2018. https://medium.com/@limavallantin/why-you-should-not-trust-only-in-accuracy-to-measure-machine-learning-performance-a72cf00b4516.
- Thompson T, Collings A. Forensic undergraduate education during and after the COVID-19 imposed lockdown: strategies and reflections from India and the UK. Forensic Sci Int. 2020;316:110500. doi:10.1016/j.forsciint.2020.110500.
- Hidge S, Holjencin A. A post-mortem review of forensic hair analysis – A technique whose current use in criminal investigations is hanging on by a hair. St Louis Univ Law J. 2020;64(2):Article 5. https://scholarship.law.slu.edu/cgi/viewcontent.cgi?article=1768&context=lj.