
ABSTRACT
This paper seeks to identify causal factors constraining the diachronic dynamics of particular morphosyntactic categories of Slavic. It is suggested that the modern inventory of Slavic languages is not a result of accumulation of historically accidental changes and non-changes. Instead, it is argued that macro-areal pressures constrained by the geographic location and the particular language-contact configuration determine the selection of inherited properties for either retention or loss and, subsequently, innovation. I primarily provide evidence from two categories: verbal person-number indexes (subject agreement markers) and partitivity markers and I also briefly discuss some other fusional categories.
0. Introduction
There is a trend in linguistic typology to shift the attention from finding universal properties of language to the understanding of the linguistic diversity around the globe (compare the programmatic “what’s where why?” in Bickel Citation2007; see also Dixon Citation2003; Kusters Citation2003; Trudgill Citation2009, Citation2011). In the same vein, this paper pursues the question: Why are Slavic languages the way they are? While we are not in a position to provide an exhaustive account of the causal factors that have conditioned the development of modern Slavic languages, the modest goal of this paper is to provide evidence for the claim that macro-areal pressures are an important factor that shaped the development of Slavic after its split from Proto-Indo-European.
Despite considerable intragenealogical variation, Slavic languages share a large amount of linguistic material that comprises all domains of grammar and lexicon. Thus, Slavic languages share a number of morphosyntactic properties based on largely etymologically related morphological devices such as derivational aspect, past forms based on the suffix -l (originally participles), verbal person-number inflection, singular-plural distinctions, passive morphology based on the -no-/-to-resultatives, etc. (e.g. Seržant Citation2012; Hansen Citation2014; Wiemer Citation2019). This is, of course, not unexpected given the shallow time depth of this subfamily (ca. 1300 years, cf. Holman et al. Citation2007) and the intensive mutual contacts due to small geographical distances between Slavic languages.
However, the question of why these languages share precisely this specific set of properties is not trivial at all. For example, one may wonder why the old, Indo-European middle morphology was entirely abandoned in Slavic while it is still retained in Modern Greek. Or, why the old Indo-European perfect still found with vĕdĕ [know/see.1perf.sg] ‘I know’ in the earliest Old Church Slavonic documents was entirely lost in modern Slavic while, for example, Germanic languages generalized it as the only past-tense form (cf. Gołąb Citation1992, 65). We do not understand the selectional mechanism which is responsible for the retention vs. loss of inherited properties. Moreover, this common set of properties does not only contain common inheritance (Section 1) but also has a number of common innovations (Section 2). Again, while languages innovate parts of their inventories continuously, one may wonder why Slavic introduced its particular set of innovations and not some other.
This paper explores the selectional mechanism for retention and innovation of particular properties. First, it claims that two factors, namely, the macro-areal pressures and the particular contact configuration – in addition to universal pressures – must be viewed as important components of this mechanism. Secondly, I provide evidence for the claim that retentions of inherited properties need not be historically accidental, inert processes (the null hypothesis) but may be constrained by areal pressures. I show that (macro)areal pressures support the selection of particular inherited properties for retention (Section 1) and the selection of other properties for loss (Section 2). Generally, a clear-cut separation between areal innovations and areal retentions of inherited structures and, thus, the traditional complementary division of labour between historical and areal linguistics (since Jakobson Citation1930, Citation1931; cf. Nichols Citation1992, 163) does not seem to be meaningful.
More specifically, I focus on two phenomena: the retention of the Proto-Indo-European verbal person-number indexes (Section 1), on the one hand, and the innovation of the partitivity markers (Section 2), on the other. Thus, I argue that the quite faithful preservation of person-number indexes from Proto-Indo-European into modern Slavic languages is due to the very conservative dynamics of the neighbouring languages in this domain. Slavic languages occupy a part of the transitional zone that is found between highly conservative languages in the East of Eurasia and the innovative languages in the Northwest of Europe. By contrast, the old, genitive partitivity marker has been innovated in Slavic due to a strong macroareal pressure.
Areal pressures themselves accumulate from a large number of different kinds of contact events involving different transfer mechanisms. In view of the macro-perspective of the paper, I do not discuss these mechanisms in detail here.
Thirdly, I argue that the effect of macro-areal pressures is constrained by the particular contact configuration. Thus, languages normally have mutual contacts with the languages that occupy geographically adjacent territory. However, different local factors such as the time depth of the contacts, the particular historical events, the physical shape of the territory (cf. Nichols Citation1992), and other factors – cumulatively referred to as contact configuration here – may considerably constrain the contact effects and thus the effect produced by the macro-areal pressures (cf. Thomason Citation2001). For example, the abruptness of contact – understood as a high proportion of adult L2 vs. L1 speakers – has been argued to have strong reduction effects (Trudgill Citation2009, Citation2011; Sinnemäkki Citation2020).
Causal explanations in terms of a macro-areal impact for certain – primarily phonetic and phonological patterns of Slavic (such as palatalization) – have already been ventured by a number of scholars in most cases by making reference to the extra-genealogical language contact with Turkic and/or Uralic languages (Kattein Citation1983; Galton Citation1997; Stankiewicz Citation1986; see also Gvozdanović Citation2015 on Celtic and Slavic). While joining this tradition, I focus primarily on morphosyntactic properties of Slavic.
The paper is structured as follows: Section 1 explores the dynamics of verbal person-number indexes in Eurasia and compares the areal trends with the evidence from Slavic. Section 2, by contrast, explores the common Slavic innovation of partitivity markers, replacing the old, inherited possessive marking strategy with the new spatial, separative strategy. Section 3 briefly provides evidence on other morphosyntactic phenomena of Slavic from such categories as fusional case and aspectual inflection. Finally, Section 4 summarizes the conclusions and discusses the results thus achieved and the method.
1. Verbal person-number indexes
In what follows, I avoid the more traditional terms like bound pronouns or agreement markers and follow Lazard (Citation1998) and Haspelmath (Citation2013) and refer to these as (bound person-number) indexes (the term was introduced in Boelaars Citation1950 or even earlier).
In general, Slavic verbal person-number indexes are surprisingly conservative both in terms of the number of segments retained and in terms of the small amount of sound change, as can be observed in .
Table 1. Modern Russian and Serbian vs. Proto-Indo-European (PIE) subject indexes (the thematic conjugation, cf. the discussion in Meier-Brügger Citation2010, 173–84)
Despite some minor differences in the phonetic form of the first singular and third plural (where a nasal has been added and the pre-nasal vowel has been raised from Proto-Slavic *on to Common Slavic ǫ and then to East Slavic u), other forms are strikingly reminiscent of those of Proto-Indo-European, both as to their phonetic realization and as to their lengths (cf., inter alia, Olander Citation2015). Given that Proto-Indo-European was spoken around 5,000–3,000 BC (Anthony Citation1995, 558; Nichols and Warnow Citation2008, 781; Meier-Brügger Citation2010, 194; Holman et al. Citation2011), the approximate age of the Russian indexes is at least 5,000 years.
By contrast, in some other modern Indo-European languages such as Scandinavian languages, French, Hindi or Marathi, the person-number indexes are almost entirely lost. In other words, despite the same prerequisites in the common proto-language (Proto-Indo-European), these languages and language subfamilies underwent other type of developments. In order to explore the variation of different degrees of the decay across Eurasia, a database comprising person-number indexes of six families of Eurasia has been created.
1.1. The database
This study relies on the database of the six person-number indexes of the intransitive (masculine) subject – first singular (1SG), second singular (2SG), 3SG, 1PL, 2PL, 3PL – from 150 modern and 6 proto-languages from 6 families from Eurasia: Indo-European, Tibeto-Burman (Kiranti and Rgyalrongic only), Turkic, Uralic and Semitic. Each language is represented by only one paradigm used in the present tense except for Semitic for which the so-called imperfect paradigm was chosen. Only Dravidian and Semitic distinguish between genders here. For these languages, only the masculine/common forms were taken into account. Irregular verbs and rare forms were excluded.
In the database, the paradigms within one family are always historically interrelated so that one can meaningfully talk about the dynamics when comparing the paradigms across the modern languages of one family and with the proto-language. The reconstructed paradigms of the proto-languages have been taken from the authoritative literature: Meier-Brügger (Citation2010, 311) for the thematic conjugation of Proto-Indo-European; Janhunen (Citation1982, 35) for Proto-Uralic; Erdal (Citation2004, 233) and Róna-Tas (Citation1998, 74) for Proto-Turkic; Andronov (Citation2009, 224–31) for Proto-Dravidian; Hasselbach (Citation2004, 32), Huehnergard (Citation2000) and Lipiński (Citation2001, 378) for Proto-Semitic; Jacques (Citation2016), DeLancey (Citation2010, 15, Citation2011, 2, 2014) and LaPolla (Citation2003, 30) for Proto-Gyalrongic and Proto-Kiranti (Tibeto-Burman).
In what follows, illustrate the database with some examples and provide the decay factor (discussed in detail below Section 1.2). The entire database has been published at zenodo.org (Seržant Citation2020b).
Table 2. Indo-European indexes (the “thematic conjugation” cf. Meier-Brügger Citation2010, 173–84).
Table 3. Turkic indexes (cf. Erdal Citation2004, 233; Róna-Tas Citation1998, 74).
Table 4. The Proto-Uralic subject indexes and their lengths (Janhunen Citation1982, 35)Footnote6.
In order to compare the dynamics of person-number indexes across the languages of the database, I have computed the decay factor for each language.
1.2. Measuring the decay factor
In this subsection, I present the method for measuring the degree of decay of an index paradigm (henceforth the decay factor). The decay factor has the maximal value of 1 if the erstwhile paradigm has totally disappeared in the course of development. However, in most languages of the database, different kinds of transitional stages are found. In order to measure this variation in the morphological functionality of verbal person-number indexes across Eurasia, I put forward the following metrics based on three indicators. An inflectional paradigm may be considered to have lost its functions if all person-number slots (i) have undergone total length reduction when compared to the proto-language, (ii) are mutually syncretic and (iii) are zeroes by form (phonetically unmarked). In this extreme case, these three factors are tautological, but not otherwise. For example, Scandinavian languages have almost lost the original, present-tense paradigm, all present-tense slots being marked by -r. Thus, while all slots are syncretic (ii) and all slots have been reduced when compared to Proto-Indo-European, these are not zeroes, cf. Norwegian jeg komme-r ‘1sg come-r’ ‘I am coming’, du komme-r ‘2sg come-r’ ‘you are coming’, han komme-r ‘3sg.m come-r’ ‘he is coming’, vi komme-r ‘1pl come-r’ ‘we are coming’. By contrast, Rumanian has first-person singular zero (iii) but is quite conservative with respect to the other two indicators in that it has little reduction (i) and retains all the distinctions with no syncretism (ii).
A paradigm that did not undergo any reduction, syncretism and creation of zeroes counts as maximally preserving, regardless whether the forms have remained the same or have been replaced via analogy, reanalysis or phonetic changes. Such a paradigm has the minimal value of the decay factor, i.e. 0. I also adopt the convention that any kind of lengthening of the forms – in contrast to reductions – cannot decrease the functionality of the index and of the entire set. For example, the analogical lengthening of the Proto-Slavic 1pl index *-mŭ to Old Church Slavic (occasionally) or Polish (obligatorily) 1pl -my from *-mū does not have any effect on the functional load of this index.
In what follows, I explain how these three indicators – (i) the reduction of length, (ii) the degree of syncretism and (iii) the number of zeroes – are measured. The higher the values of these indicators the more the paradigm is functionally impaired and the closer it is on its way to the full decay.
(i) The reduction of the length of the indexes is measured in phonetic segments as the difference between the length of the synchronic form and the length of the respective proto-form for each modern language. For example, a change such as the replacement of the Proto-Indo-European 2sg *-e-si by the Proto-Slavic *-e-šī does not anyhow affect the functionality of the morphological system. By contrast, reduction changes such as the entire loss of the dental consonant in the third-person indexes of many Slavic languages (PIE *-e-ti > Polish -ie-Ø) did affect the morphological system of the person-number inflection because it potentially leads to an unmarked third-singular index, i.e. zero. Thus, while a change containing a phonetic replacement does not affect the morphological structure and the functionality of the inflectional paradigm, a reduction change or even an entire loss may potentially represent traces of an ongoing decay of the indexing system. Accordingly, the loss of the final syllable in Polish (PIE *-e-ti > Polish -ie-Ø) is counted as the reduction from three segments to only one, i.e., as a reduction of 2 (segments). In order to level out the differences between the reduction of long proto-indexes and short proto-indexes, the reduction is divided by the total of the respective proto-index, i.e. 2/3 = 0.67 for the third-person index of Polish. Subsequently, the means of these resulting values is calculated as the reduction value of the language.
Note that since the focus is on the functional capacity of the paradigm, it plays no role whether there is a reduction by sound law (cf. the second singular in Polish -sz from Proto-Indo-European *-esi via Proto-Slavic *-ešī) or due to some other type of reduction (cf. Polish 3sg that dropped the final *-ć < *-ti not by a sound law, contrast it with nouns such as sieć < *s’eti ‘net’ retaining the final -ć).
(ii) The degree of syncretism measured as the maximum number (six) minus the number of distinct morphological strings employed by the paradigm.Footnote7 For example, German has two syncretic pairs: (a) 1pl & 3pl geh-en ‘go-1pl/3pl’ ‘we/they go’ and (b) 3sg & 2pl geh-t ‘go-3sg/2pl’ ‘he/you go(-es)’. The total number of strings used in this paradigm is four. Six minus four yields the value of two. Thus, the degree of syncretism of the German paradigm is 2. The maximum value here is five found in Scandinavian. Scandinavian languages have generalized the affix -r indistinguishably for all person-number slots in the present tense.
(iii) The number of zeroes in the paradigm. Only unequivocal zeroes are counted. For example, in English, all person-number slots except for the third singular are zeroes. By contrast, I did not count the Slavic third-singular forms with the dental loss (e.g. Polish czyt-a ‘(s)he reads’) as zeroes because such an analysis is very much dependent on how one treats the stem-final vowel (-a- in this case). This is not a substantial problem for the approach since the higher degree of reduction in Polish as compared to, for example, Russian (čitaj-et ‘(s)he reads’) is captured by the first indicator (i) above anyway.
I have filled in the values of these indicators for each index in every language of the database. Subsequently, I normalized the values, arranging all values between 0 and 1 along (1):
(1) Minimum-maximum feature scalingFootnote8
Xnorm = X / Xmax
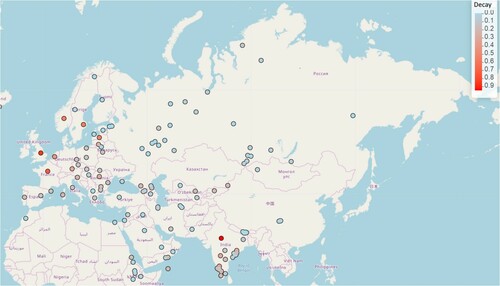
Figure 1. The degree of decay factor across different languages of Eurasia.
1.3. Results and discussion
The decay factors of 154 languages from 6 families (Indo-European, Uralic, Turkic, Semitic, Dravidian, Rgyalrongic + Kiranti) are mapped on :
As one can see in ,Footnote9 there are two decay hotspots (marked by the red dots): (i) the subcontinent Hindustan (cf. Siewierska 2004, 278) where primarily Indo-European (Indo-Aryan), Dravidian and Austroasiatic (Munda) languages are spoken, and (ii) Northwestern Europe with Indo-European (Indo-Aryan) languages. The high degree of decay in Hindustan is not of immediate relevance here and will not be discussed further (see Peterson Citation2017 for an account). Just note that this area is strongly affected by Southeast Asian languages (foremost Austroasiatic) which is the largest area strongly dispreferring indexing in the world (cf. the map in Donohue and Denahm 2020, 455 based on 2378 languagesFootnote10), also diachronically (Bisang Citation2014).
By contrast, the Turkic and Uralic languages are the most conservative here (blue dots, decay factor < 0.1). Slavic languages, in turn, are somewhat intermediate here: these languages generally show quite a low degree of decay (grey dots, < 0.2), albeit not as low as most of the Turkic and Uralic languages.
The following three adjacent areas are of immediate relevance to Slavic: Northwestern Europe, Northeastern Eurasia and the Transitional area. I discuss these in detail in what follows.
First, there is Northwestern Europe. This area is the European hotspot of the indexes decay.Footnote11 It encompasses languages such as French, English, Scandinavian but also to some extent German, Dutch or North Italian varieties. These languages abandon the indexes inherited from Proto-Indo-European to various degrees. For example, Dutch totally abandons person distinctions in the plural, cf. lach-en ‘laugh-1/2/3pl’ ‘we/you/they are laughing’ and French in the singular. English retains the inflection only with one verb (to be) and elsewhere only the 3sg marker -s (cf. he go-es), while Scandinavian does not have any person-number distinctions at all.Footnote12
Second, there is the most conservative, huge area primarily populated by Turkic and Uralic languages, stretching from the Baltic sea to Siberia (henceforth Northeastern Eurasia). A number of other languages of the database belong here as well, e.g. Iranian (Indo-European) Persian or Ossetic (decay factor <0.13 in both).
Finally, there is the Transitional area with conservative Indo-European languages of the Balkans such as Greek (decay factor < 0.14), Albanian (< 0.07), Romanian (< 0.3). Slavic languages (< 0.15) also belong here.
I summarize all three areas in .
Table 5. Decay factors across the three areas (Ø – averaged across languages).Footnote13
A number of observations can be made on the basis of these figures. First, the decay factors map perfectly on the geographical space despite the fact that the decay factors have been computed entirely independently of geography. In other words, the geographical distribution of different degrees of decay in Europe suggests a strong correlation between the geographical position and the decay factor on what I shall refer to the East-West axis (in addition to the North-South axis). In what follows, I refer to this correlation as to the East-West cline. Slavic languages take an intermediate position on this cline: both with regard to their decay factor of ca. 0.15 (which is numerically between 0.61 of Northwestern Europe and 0.05 of Northeastern Eurasia), and with regard to their geographical position (Eastern Europe).
Now that the correlation between the geographical space and the decay factor has been established, it can be reasonably inferred that Slavic languages have retained the morphological functionalityFootnote14 of their inflectional person-number indexing system from Proto-Indo-European into Early and Modern Slavic due to their geographic position on the East-West cline.Footnote15 What is more, the East-West cline may also be observed within Slavic as well. The only indexes that do undergo considerable reduction across Slavic languages are the third-person indexes. Yet, the reduction of these indexes increases from the more conservative Russian in the East to the more innovative Polish in the West, Ukrainian and Belarusian being in between when it comes to the dental segment, as illustrated in .
Compare 3sg: Russian nes-et ‘carry-3sg’, dialectal -et’, Ukrainian čyta-e ‘read-3sg’, Belarusian viedaj-e ‘know-3sg’ (-t’ is present in other conjugations), Polish nies-ie ‘carry-3sg’; 3pl: Russian nes-ut(’) ‘carry-3pl’, Ukrainian čyta-jut’ ‘read-3pl’, Belarusian vodz = jac’ ‘drive=3pl’, Polish nios-ą ‘carry-3pl’. Thus, I conclude that even the internal Slavic variation is constrained by the East-West cline.
Secondly, in what follows, I argue that the method pursued here finds strong support in what we know about the history of Slavic ethnicities. Although the decay factor has been computed entirely independently of the historical facts about the migration and linguistic contacts of Slavic, it strongly correlates with what we know about the particular contact configuration of Slavic.
While the East-West cline roughly explains the intermediate position of the Slavic languages, it fails to explain why the Slavic decay factor (< Ø 0.15) strongly gravitates towards the Transitional area (Ø 0.12) as well as the languages of the conservative Northeastern Eurasia (Ø 0.05) and is considerably more distant from the Northwestern Europe (Ø 0.61). Thus, the East-West cline can only be a part of the explanation. I argue that the particular contact configuration of Slavic is responsible for this skewing: Slavic languages were in much more intensive contact with languages of Northeastern Eurasia and the Transitional area than with the languages of Northwestern Europe.
Thus, different Slavic populations were in intensive contact with a number of Uralic and Turkic tribes, sometimes even leading to a partial or total assimilation of the latter by the Slavs:
| (2) | Turkic (inter alia, Galton Citation1997, 21ff; Gołąb Citation1992, 310, 401ff; Nichols Citation1993; Stachowski Citation2014) Danube Bulgars, Khazars, Pechenegs, Coumans, Tatars, etc. | ||||
| (3) | Uralic (inter alia, Andersen Citation2003, 47–48; Haarmann Citation2014; Rjabinin Citation1997) Ugric Hungarian, Finnic Merya, Muroma, Tver’, partly Karelian (Old Novgorod) | ||||
By contrast, languages of Northwestern Europe were not in such intense contact with Slavic. These were the languages associated with cultural and political prestige and may have had an impact only on particular social subgroups of Slavic population. For example, we know of different kinds of military, political and trade contacts with Normans from Scandinavia – especially with early East Slavs – but this contact did not involve any significant population migration from Scandinavia into the East Slavic territory with a subsequent assimilation or other kinds of situations that would licence intense language contact. Similarly, the latter impact of Low and, subsequently, High German of Hansa on East Slavic, still later, the impact of French and, finally, of English on all Slavic languages was certainly not as intense as to go very much beyond lexical cultural borrowings.
Having said this, Slavic languages (Ø 0.15) are not as conservative as Northeastern Eurasia (Ø 0.05) and do show a minor degree of decay in parallel to the entire Transitional area which, in turn, must have been under some influence of Northwestern Europe. More specifically, German has and has had intense contacts with the languages of the West Slavic branch.Footnote16 Yet, German (0.3) is also the least innovative language in Northwestern Europe. Hence, its effect on the decay factor of West Slavic is moderate.
To sum up, the historical data briefly summarized above evidently point to very different degrees of language contacts of Slavic. Crucially, the degrees of contact intensity strongly correlate with the decay factors. The stronger the contact between two languages the more similar their decay factors are. Generally, the strong numerical association of Slavic with Northeastern Eurasia and the Transitional area correlates with the intensity of linguistic contacts with these areas. To conclude, the pure geographic position on the East-West cline is not the only factor that contributes to the retention of the verbal inflection in Slavic. Another important factor is the particular contact configuration of Slavic.
The claim that the degree of decay of the person-number indexes paradigm is primarily conditioned by the geographic position and the contact configuration also finds support elsewhere. For example, the two languages of the East Baltic branch of Indo-European that are closely related to Slavic show an unexpectedly high decay factor of 0.24 in Lithuanian and 0.55 in Latvian. This is despite the fact that elsewhere these two languages are demonstrably the most conservative among modern Indo-European languages. Both Baltic languages have generalized the singular-plural syncretism across all conjugational paradigms in the third person, cf. Lithuanian neš-a ‘carry-3sg = pl’ ‘(s)he carries / they carry’.Footnote17 Furthermore, Latvian also shows second-third person zero syncretism in the singular of all verbs of the present tense of the first conjugation, cf. ņem-Ø ‘take-2sg/3sg/3pl’.
This high decay factor finds its explanation once one looks closer into the contact configuration of these languages. Lithuanian and Latvian are situated geographically close to Northwestern Europe and, crucially, had much stronger contact with its languages than Slavic, as early as some runic inscriptions that were found in Latvia. Later Low (and subsequently High) German heavily dominated this area: Livonia (of which Latvia was a part) and later also the Duchy of Courland and Semigallia (Courland and Semigallia are parts of modern Latvia) as well as the so-called Minor Lithuania (Mažoji Lietuva) were primarily dominated by German-speaking elite (stemming from the Teutonic Order and, later, from Hansa) for centuries. The impact of Swedish must have been stronger than in Slavic at least during Swedish Livonia (1629–1721). Finally, Polish also played an important role in the East of Latvia (Polish Livonia). Recall that Polish is slightly less conservative in this respect than, for example, Russian.
2. The marker of the Partitive construction
Above I have explored the retention mechanism on the backdrop of the macro-areal East-West cline. In this section, I examine an innovation in Slavic that is also due to macro-areal pressures, ultimately resulting from language contact. I focus on the marking strategy of partitivity in Slavic. Partitivity is a semantic relation which codes a subset of a superset (“part-whole” relation) (Enç Citation1991; von Heusinger Citation2002, 261–62; Koptjevskaja-Tamm Citation2001, Citation2009; Seržant, Citationforthc.-d):
| (4) | Some of the students of our university / Two of the students of our university | ||||
Proto-Indo-European, Proto-Slavic and Early Slavic employed the possessive strategy to encode this relation, namely, the genitive (the partitive genitive, genetivus partitivus) (Miklosich Citation1883, 449, 473):
In (5), the recipient participant ‘each’ is a member (the subset) of the well-defined superset ‘they’ (scil. the sons of Vladimir) – a proportional part-whole relation that is coded by the genitive case on the superset NP ‘of them’.Footnote18Yet, the genitive can no longer be used in this function in modern Slavic in most instances. Instead, the new periphrastic construction with a separative preposition such as Modern Russian iz ‘from’ has to be used. Thus, (5) cannot be rendered in Modern Russian without the (new) partitive preposition iz ‘from’:
Other Slavic languages are similar, cf. od ‘from’ in Serbian:
One might think that the separative strategy of marking the part-whole relation is just a default strategy to mark partitivity relations. However, partitive markers are very diverse cross-linguistically, ranging from various adpositions and cases (possessive, locative, instrumental, comitative) to verbal clitic partitive particles (cf. Budd Citation2014; Hoeksma, ed., Citation1996; Koptjevskaja-Tamm Citation2001, Citation2009; Seržant, Citationforthc.-d) or just involving no marker at all. The following example from Malayalam features the locative marking (the locative strategy): As a matter of fact, the separative strategy is typical only for Eurasia as I argue in Section 2.2 below.2.1. The database
This study is based on a convenience sample of partitive expressions covering 138 languages, 171 entries (one language may have more than one strategy to encode partitives) from 46 families and all six macro-areas. The sample is biased toward Eurasia (48% of the entries, 82/171) but not for Indo-European. The database is published at zenodo.org (Seržant Citation2020a).
3.2. The separative strategy of partitives as a macro-areal pressure
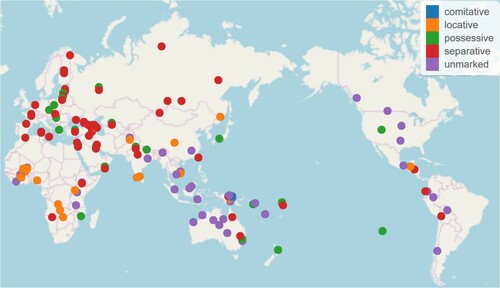
Coding strategies reveal areal biases as suggests.Footnote19 The separative strategy (red dots) is typical only for Eurasia. Other areas prefer other strategies. For example, the locative strategy as in (8) above (orange dots) is more typical for Africa.Footnote20
Figure 2. Distribution of the major coding strategies of partitives (from Seržant, forthc.).
Below, presents the row counts and highlights the outliers. Unfortunately, the sample is not large enough to provide for a more precise picture. However, it is sufficient to argue that the null hypothesis of the coding strategies being normally distributed across all macro-areas can be rejected. To test this I computed the standardized residuals in the chi-square test. The separative strategy in Eurasia reveals itself as a statistically significant outlier (standardized residuals < 2.5).Footnote21 Given that the underlying sample is a convenience sample, I have also computed Fisher’s Exact test in a two-by-two table (p < 0.001) that puts fewer requirements on the distribution of the observed data (Janssen et al. Citation2006, 425), see .
Table 7. Coding strategies across the macro-areas, bold indicates statistical significance (from Seržant, Citationforthc.-d).
Table 8. Contrasting the separative strategy in Eurasia with elsewhere.
The areal bias towards the separative strategy in Eurasia is not only supported statistically by genealogically unrelated languages of this area that select this pattern (e.g. Turkic, Basque, etc.) but also by those languages of the sample that are related. For example, many modern European languages have partitive prepositions that all stem from separative prepositions such as French de, Dutch van or Latvian no but which are nevertheless unrelated among each other etymologically. Thus, French de is not related to German von or Scandinavian av/af. What is more, even within subfamilies we find unrelated prepositions such as German (West Germanic) von vs. Scandinavian (North Germanic) av/af or Lithuanian (East Baltic) iš ‘from’ vs. Latvian (East Baltic) no ‘from’. This is also true for the Slavic languages, cf. Modern Russian (East Slavic) iz ‘from’ in (6) vs. od ‘from’ in (7) in Modern Serbian (South Slavic). This means that the partitive function of these prepositions is recent and not due to common inheritance. At the same time, the fact that all these languages innovate their coding strategies of partitives on the basis of the same locational metaphor, i.e. on the metaphor of separation from the Ground, strongly suggests that this pattern is not selected accidentally by the langauges of Eurasia. Once common inheritence is excluded as an explanation for correlations (even for the genealogically closely related languages), this correlation must be due to an areal pressure. The latter is ultimately grounded in multiple pattern borrowing across Eurasia.Footnote22
To conclude, modern Slavic languages are on their way to abandoning the inherited possessive strategy of encoding part-whole relations which was crucially based on the possessive metaphor. Instead, all Slavic languages tend to adopt a coding strategy that is based on the spatial metaphor of separation. This process is not accidental but is motivated by a strong macro-areal pressure.Footnote23
The emergence of this common Slavic morphosyntactic property is essentially different from person-number indexes discussed above (Section 1): while the former was selected for retention due to the macro-areal pressures, the latter, by contrast, was replaced by the separative strategy that is the dominant strategy in Eurasia.
3. Other morphosyntactic phenomena and macro-areal pressures
In Section 1, I have argued that macro-areal pressures in combination with the specific contact configuration constrain the retention and innovation of morphosyntactic properties. I have argued that the retention of person-number indexes in the Slavic languages can be accounted for in terms of the East-West cline as well as the particular contact configuration of the Transitional area. In this section, I argue that the areal method pursued above may account for other phenomena selected for retention or loss as well. Thus, the macroareal East-West cline in combination with the local contact configuration has a supporting effect in other domains of verbal inflection, e.g., in the languages of the Balkan sprachbund.
For example, the ancient inflectional aspectual distinctions between the aorist (the perfective past) and the imperfect (the imperfective past) have been well-preserved (mutatis mutandis) in South Slavic. There is a cline within Slavic that stretches from East Slavic with no traces of these categories (since at latest the 18th century when the artificial use of the aorist was lost even in the written language), via West Slavic (with some traces of these, e.g., in Upper Sorbian) to South Slavic which has quite faithfully preserved these categories (e.g. Bulgarian). Other Indo-European languages of the Balkans such as Greek and Albanian have also preserved this distinction. More generally, the Balkan Indo-European languages are unique in this respect: all other modern branches of the huge Indo-European family have lost this distinction entirely (except for modern Armenian).
At the same time, Balkan languages underwent a considerable loss of fusional complexity in another domain: very early on, the original case inflection was lost. This loss is also not unexpected given the macro-areal cline from East (many case distinctions) to West (with no cases in languages such as Scandinavian), cf. . This cline is supported by non-Slavic languages. In the South, Greek has lost most of its cases already by the Roman period (cf. Rafiyenko and Seržant Citation2020 on case in Postclassical Greek). Neither Albanian nor Rumanian have preserved much of the Proto-Indo-European or even, in the case of Rumanian, Proto-Romance case system (as observed in Latin).
Figure 3. Number of cases in languages of Eurasia (Iggesen Citation2013).
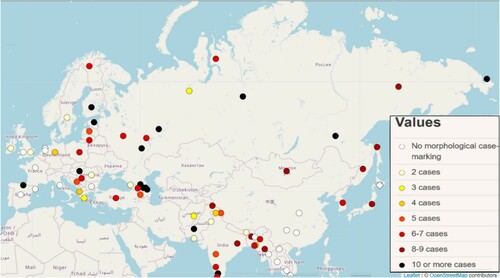
By contrast, Finnic languages of the Uralic stock have not only preserved the Proto-Uralic cases but also developed a number of new cases: the so-called secondary spatial cases and the partitive. Standard and North Russian not only quite faithfully preserved the case system of Proto-Slavic but they even underwent an increase of cases to include the defective partitive and locative cases (Breu Citation1994; Seržant Citation2014, Citation2015, Citationforthc.-a).
To conclude, selection of inherited properties for retention and loss is subject to macroareal properties as well as to specific contact configuration.
4. Discussion and Conclusions
In this paper, I have presented an approach towards causal explanations of the properties of Slavic languages. This approach crucially combines two factors: the particular contact configuration and the macro-areal pressures and clines.
More specifically, I have argued that the preservation of the inherited person-number paradigm in modern Slavic languages is due to the areal pressures constrained by (i) the position of Slavic on the East-West cline and (ii) the contact configuration (Section 1). I have argued that Slavic languages occupy the Transitional area with a minor exposure towards decay. I have also claimed that West and South Slavic languages align with the languages of this area in the degree of retention, while East Slavic, especially Russian is somewhat closer to the languages of Northeastern Eurasia. I have also argued that this match in the degree of retention can hardly be accidental and must be due to the preserving effect of language contact. L2-speakers have less difficulty learning the pattern that they already have in their L1. Therefore, they do not have a strong need to override the L2-system. Since any reduction produced by L2 speakers has also to be adopted by native speakers in order to be established in the language, retention appears to be a more efficient option on the population level when there is a functional and formal match between the relevant L1 and L2 categories.
In parallel, the innovation of the partitivity marker is equally non-accidental and must be explained as the result of the macro-areal pressure to encode partitivity with a separative (ablatival) marker (Section 2). I have also briefly discussed other morphosyntactic phenomena such as inflectional aspect (Section 3). This evidence also points to strong macroareal constraints and to the effect of the particular contact configuration. Thus, the genealogical preconditions and areal pressures conspire to shape the morphosyntax of the Slavic family.
More generally, this study provides evidence against the mutually exclusive separation of genealogical and areal effects (as, for example, in Nichols Citation1992, 163) and claims that inherited patterns too are subject to areal pressures. The effect of areal pressures on inherited patterns may be either loss – optionally with a subsequent innovation (Section 2) – or retention (Section 1). I have claimed that the preservation of person-number indexes in Slavic is a case in point. Similarly, the preservation of inflectional aspectual distinctions between aorist and imperfect (South Slavic) as well as the preservation of inflectional case may also be accounted for by the supporting effect of language contact.Footnote24
Having said this, the studies carried out here rely on different degrees of resolution of the areal variation. In the first study (Section 1), the distribution of indexing systems across Eurasia is treated “under a higher zoom-in factor”. Here, I have taken into account different indicators of decay and worked with averaged measures for each language instead of just relying on the binary distinction of whether or not the languages of the sample have preserved the inherited indexing system. By contrast, with partitives (Section 2), the binary distinction of whether or not the languages code their partitives with the separative strategy was in focus. With respect to both phenomena, I have argued for a strong areal pressure on Slavic. However, only in the first study, I had enough data at disposal to argue that a macro-areal pressure (the East-West cline) may in addition be constrained by the particular contact configuration. More specifically, I have shown that Slavic languages align with the Transitional area (Southeastern Europe) and Northeastern Eurasia and less so with Northwestern Europe. Unfortunately, I do not have comparable representative data on partitives at my disposal that would point in favour (or against) the effects of the particular contact configuration of Slavic. Nevertheless, given the somewhat sporadic evidence at my disposal, contact configuration does seem to play a role here as well. Thus, the functional properties of partitives in East Slavic, especially in North Russian, align with those of Finnic languages (Uralic) much stronger than with those of the languages of Northwestern Europe (Seržant Citation2014, Citation2015). Moreover, there are morphosyntactic properties as well that are primarily determined by the contact configuration. Thus, Russian is the only Slavic language that was on the way to developing a dedicated partitive case similar to the partitive case in the Finnic languages (Breu Citation1994; Seržant Citation2014). Finally, both families align here in another respect. They both have two partitive markers: the recent, separative marker (iz ‘from’ in Russian and the elative case in Finnic) which encodes exclusively part-whole meanings and the old, non-transparent marker (the genitive case in Russian and the partitive case in Finnic), which only rarely denotes part-whole relations and is primarily used for other functions related to pseudo-partitivity.
An additional factor constraining the development towards loss (and innovation) or retention might be the stability of the category itself. Thus, it has been argued that person-number indexes are a stable category: languages do not tend to lose this category unless they come into one of the areas where indexing is dispreferred (Nichols Citation1995, 343; Wichmann and Holman Citation2009; Seržant, Citationforthc.-b). By contrast, partitives very often develop into pseudo-partitives and thus lose their original meaning which is why new partitives emerge again (“Partitivity cycle” in Seržant, Citationforthc.-c).
It is the task of future research to examine how contact situations affect macro-areal clines discussed in this paper. Trudgill argues for a strong correlation between the abruptness of contact and the decay of fusional morphology (Trudgill Citation2009). According to Trudgill (Citation2009, Citation2011), socio-historical factors contribute to the decay vs. retention of fusional morphology (a proxy of complexity adopted in this research) and thereby they affect areal clines. High-contact situations which crucially involve massive adult bilingualism resist the preservation of fusional morphology such as verbal person-number indexes (Trudgill Citation2011, 34ff). This is because adult L2-learners typically do not achieve the level of proficiency that would guarantee faithful transmission of non-transparent fusional morphological structures across generations (cf., inter alia, Clahsen and Muysken Citation1996; Lupyan and Dale Citation2010; Trudgill Citation2011, 39; Kempe and Brooks Citation2018). It is possible that high-contact situations affect areal clines. Thus, we have observed that the Balkan sprachbund is very much conservative when it comes to the verbal morphology while it is innovative when it comes to fusional case. By contrast, Northwestern Europe is innovative in both respects. It is possible that Northwestern Europe underwent even more intensive and abrupt contact situations involving a high proportion of adult L2 speakers than the Balkans. This would explain why not only fusional case but also the cross-linguistically stable category of person-number indexing has been lost here.Footnote25
Finally, I have not discussed universal pressures, which must have also affected Slavic morphosyntax. Thus, the third person singular tends to be shorter and is shortened more drastically across Slavic (cf. in §1.3 above). This tendency is in line with the universal pressure of the third person to be shorter than other persons (Benveniste Citation1971; Koch Citation1995; Bybee Citation1985, 53; Cysouw Citation2003, 61–2; Siewierska Citation2010; Bickel et al. Citation2015). I summarize:
Table 6. Reduction of the third person indexes from East to West. (Brackets mean differential marking, V means vowel).
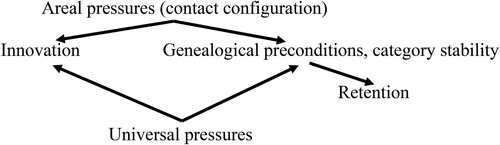
illustrates the relation between retention and innovation, which are both constrained by the areal pressures emerging from contact configuration (and universal pressures).
Figure 4. Schematic ontology of factors constraining language.
Acknowledgements
I cordially thank Ilya Chechuro, Martin Haspelmath, Ivan Levin, George Moroz, Alexandra Samurovic, Ilia Uchitel and Ruprecht von Waldenfels. I have received help from the two anonymous reviews and the editors of this issue. The support of the European Research Council (ERC Advanced Grant 670985) is gratefully acknowledged.
Notes
1 The alternative reconstructed form *o-me-s(i) was not taken into account here.
2 The alternative reconstructed form *o-me-s(i) was not taken into account here.
3 The alternative reconstructed form *o-me-s(i) was not taken into account here.
4 Note that most of the modern Turkic languages employ the nominal plural marker -lar/-ler here. This plural marker stems from the nominal domain (possibly originally only with an animate subject) in Old Turkic (the data presented in Erdal Citation2004, 232).
5 The alternative reconstructed form *o-me-s(i) was not taken into account here.
6 There is some uncertainty about the quality of the second person singular since many Uralic languages point to the original *-t while the Eastern periphery (Komi, Ob-Ugric, Samoyed) point to a nasal *-n (Janhunen Citation1982, 34; Kulonen Citation2001; Honti Citation2010, 21). Furthermore, sometimes it is assumed that the final consonant of the first and second plural is the plural marker -k and not the ancient plural marker -t agglutinatively added to the stems of the first and second person pronouns (cf. Laanest Citation1982 [1975], 229–30 discussing this proposal; Honti Citation2010, 21). Note that these controversies do not affect the study since the quantity remains the same on both alternatives.
7 I thank an anonymous reviewer for helping me to better formulate this measure.
8 This formula looks as follows: Xnorm = (X-Xmin) / (Xmax-Xmin). However, since Xmin is always zero with all three factors I have simplified the formula above.
9 has been created with the lingtypology package of R (Moroz Citation2020).
10 Unfortunately, there was no information on the database that Donohue and Denahm (2020) have used.
11 Note that areas with a high degree of decay may also undergo developments towards new indexes, for example, from cliticization of personal pronouns. This is the case in Non-standard French (Givón Citation1976) or in some North-Italian dialects (Gerlach Citation2002) and in some languages of the Eastern part of Hindustan, e.g., in Munda languages (Peterson Citation2017: 241–42). I do not take these recent developments into account because recent developments are primarily constrained by their grammaticalization sources and paths and not by their target functions.
12 Note that irregular verbs such as English to be were not taken into account.
13 Since the decay factor shows only a small range of variation within these subfamilies, averages are a good approximation here.
14 In this paper, I only focus on the morphological functionality of an indexing paradigm which is solely about the ability of a paradigm to unequivocally express all six person-number indexes but not, for example, whether these indexes may be used as referring expressions on their own or not (the so-called pro-drop), etc.
15 I did not discuss recently emerged indexing structures such as the past-tense paradigm of Polish (and of some western Ukrainian dialects) (Andersen Citation1987) because the young age of these paradigms does not allow estimation of any diachronic trends here. However, I predict that also the new paradigms will follow the areal pressures established above. Finally, note that I do not make any predictions about whether or not such paradigms may emerge because grammaticalization sources and paths are subject to very different constraints from the resulting patterns.
16 Germans assimilated some West Slavic branches, e.g. Sorbian (partly) or Polabian (totally). The lowest decay factor of German within Northwestern must be interpreted as due to the supporting effect of Slavic.
17 This is also somewhat parallel to Finnish which occasionally employs the third-person singular form for the third-person plural (agreement suspension).
18 I distinguish between proportional part-whole relations (such as seven of the students) in which both the subset and the superset belong to the same kind and meronymic part-whole relations (a leave of a tree) (see Seržant, Citationforthc.-d).
19 was created with the lingtypology package of R (Moroz Citation2020). Unfortunately, languages with two different partitivity markers cannot be properly presented on the map for technical reasons. For example, Russian has two strategies – the recessive possessive (marked by the genitive case only) and the innovative separative one (marked by the separative preposition iz ‘from’) – and only the latter is indicated on the map.
20 The locative strategy may also be found elsewhere, for example, in Samoan (Austronesian; not included in the database), cf. the locative preposition i being used as a generalized partitive (cf. Mosel and Hovdhaugen Citation1992, 108).
21 The standardized residuals for the outlier cells in bold were above/below 2.5 in a chi-square test. Despite the fact that the underlying dataset is a convenience sample, the test is a legitimate method because the availability of a good grammatical description does not interfere with particular strategies; the latter can be considered to be picked out randomly.
22 Copying of the separative strategy is also found far beyond Europe, cf., for example, Pakendorf (Citation2010, 727–29) on pattern borrowing of the separative partitive coding in Evenki (Tungusic), Dolgan and Sakha (Turkic).
23 I have no explanation on the origin of the separative bias in Eurasia that so heavily affected Slavic languages.
24 The supporting effect of language contact may also lead to an increase in fusional morphological complexity. For example, the preservation of the suffixal and prefixal actionality derivations due to language contact allowed the Slavic languages to develop an aspectual system that is typologically unusual with regard to its morphological properties (Wiemer and Seržant Citation2017).
25 Another potential explanation for the stronger reduction in Northwestern Europe than in the Balkans might have been an assumption of an unknown isolating substrate language. However, this assumption is ruled out. Thus, the autochthonous population of Scandinavia spoke Proto-Saami, which was certainly not an isolating language. Similarly, the autochthonous population of England and France spoke early Celtic, which was not isolating either.
References
- Andersen, Henning. 1987. “From Auxiliary to Desinence.” In Historical Development of Auxiliaries, edited by Martin Harris and Paolo Ramat, 21–51. Berlin: Mouton de Gruyter.
- Andersen, Henning.. 2003. “Slavic and the Indo-European Migrations.” In Language Contacts in Prehistory: Studies in Stratigraphy, edited by Henning Andersen, 45–76. Amsterdam/Philadelphia: John Benjamins.
- Andronov, Michail S. 2009. A Comparative Grammar of the Dravidian Languages (Beiträge zur Kenntnis südasiatischer Sprachen und Literaturen 7). Wiesbaden: Otto Harrassowitz.
- Anthony, David W. 1995. “Horse, Wagon & Chariot: Indo-European Languages and Archaeology.” Antiquity 69:554–65.
- Asher, R. E. and T. C. Kumari. 1997. Malayalam (Descriptive Grammars Series, Descriptive Grammars). London/New York: Routledge.
- Benveniste, Émil. 1971. Problems in General Linguistics. Translated by Mary Elisabeth Meek. (Miami Linguistics Series 8). Coral Gables (Florida): University of Miami Press.
- Bickel, Balthasar. 2007. “Typology in the 21st Century: Major Current Developments.” Linguistic Typology 11:239–51.
- Bickel, Balthasar, Alena Witzlack-Makarevich, Taras Zakharko and Giorgio Iemmolo. 2015. “Exploring Diachronic Universals of Agreement: Alignment Patterns and Zero Marking Across Person Categories.” In Agreement from a Diachronic Perspective, edited by Jürg Fleischer, Elisabeth Rieken and Paul Widmer, 29–51. Berlin: De Gruyter Mouton.
- Bisang, Walter. 2014. “On the Strength of Morphological Paradigms.” In Paradigm Change: In the Transeurasian Languages and Beyond, edited by Martine Robbeets and Walter Bisang, 23–60. Amsterdam: John Benjamins.
- Boelaars, Jan H. M. C. 1950. The Linguistic Position of South-Western New Guinea (Orientalia Rheno-Traiectina 3). Leiden: E. J. Brill.
- Breu, Walter. 1994. “Der Faktor Sprachkontakt in einer dynamischen Typologie des Slavischen.” In Slavistische Linguistik 1993, edited by Hans-Robert Mehlig, 41–64. Munich: Sagner.
- Budd, Peter. 2014. “Partitives in Oceanic Languages.” In Partitive Cases and Related Categories, edited by Silvia Luraghi and Tuomas Huumo, 523–62. (Empirical Approaches to Language Typology 54). Berlin/Boston: Mouton DeGruyter.
- Bybee, Joan. 1985. Morphology: A Study of the Relations between Meaning and Form. Amsterdam/Philadelphia: John Benjamins.
- Clahsen, Harald and Pieter Muysken. 1996. “How Adult Second Language Learning Differs from Child First Language Development.” Behavioural and Brain Studies 19:721–23.
- Cysouw, Michael. 2003. The Paradigmatic Structure of Person Marking. Oxford: Oxford University Press.
- DeLancey, Scott. 2010. “Towards a History of Verb Agreement in Tibeto-Burman.” Himalayan Linguistics 9 (1):1–38.
- DeLancey, Scott. 2011. “Agreement Prefixes in Tibeto-Burman.” Himalayan Linguistics 10 (1):1–29.
- Dixon, Robert M. W. 2003. “A Program for Linguistics.” Turkic Languages 7:157–80.
- Enç, Mürvet. 1991. “The Semantics of Specificity.” Linguistic Inquiry 22:1–25.
- Erdal, Marcel. 2004. A Grammar of Old-Turkic (Handbook of Oriental Studies. Handbuch der Orientalistik. Section eight. Central Asia. Volume three). Leiden/Boston: Brill.
- Galton, Herbert. 1997. Der Einfluss des Altaischen auf die Entstehung des Slavischen. Wiesbaden: Harrassowitz.
- Gerlach, Birgit. 2002. Clitics Between Syntax and Lexicon. Amsterdam: John Benjamins.
- Givón, Talmy. 1976. “Topic, Pronoun and Grammatical Agreement.” In Subject and Topic, edited by Charles Li, 149–88. London/New York: Academic Press.
- Gołąb, Zbignew. 1992. The Origins of the Slavs: A Linguist’s View. Columbus, Ohio: Slavica Publishers.
- Gvozdanović, Jadranka. 2015. “Evaluating Prehistoric and Early Historic Linguistic Contact.” In Historical Linguistics 2013 (Selected Papers from the 21st International Conference on Historical Linguistics, Oslo, 5–9 August 2013), edited by Dag T. T. Haug, 89–108. Amsterdam, Philadelphia: Benjamins.
- Haarmann, Harald. 2014. “Finnougrisch-slavische Sprachkontakte.” In Die slavischen Sprachen: Ein internationales Handbuch zu ihrer Struktur, ihrer Geschichte und ihrer Erforschung, edited by Karl Gutschmidt, Sebastian Kempgen, Tilman Berger and Peter Kosta, vol. 2, 1181–1198. Berlin: De Gruyter Mouton.
- Hansen, Björn. 2014. “Partial Typologies: Grammatical Categories.” In Die slavischen Sprachen: Ein internationales Handbuch zu ihrer Struktur, ihrer Geschichte und ihrer Erforschung, edited by Karl Gutschmidt, Sebastian Kempgen, Tilman Berger and Peter Kosta, vol. 2, 2202–2221. Berlin: De Gruyter Mouton.
- Haspelmath, Martin. 2013. “Argument Indexing: A Conceptual Framework for the Syntax of Bound Person Forms.” In Languages Across Boundaries: Studies in Memory of Anna Siewierska, edited by Dik Bakker and Martin Haspelmath, 197–226. Berlin: De Gruyter Mouton.
- Hasselbach, Rebecca. 2004. “The Markers of Person, Gender, and Number in the Prefixes of G-Preformative Conjugations in Semitic.” Journal of the American Oriental Society 124 (1):23–35.
- von Heusinger, Klaus. 2002. “Specificity and Definiteness in Sentence and Discourse Structure.” Journal of Semantics 19 (3):245–74.
- Hoeksema, Jacob, ed. 1996. Partitives: Studies on the Syntax and Semantics of Partitive and Related Constructions (Groningen-Amsterdam Studies in Semantics 14). Berlin: De Gruyter.
- Holman, Eric W., Christian Schulze, Dietrich Stauffer and Søren Wichmann. 2007. “On the Relation Between Structural Diversity and Geographical Distance Among Languages: Observations and Computer Simulations.” Linguistic Typology 11:393–421.
- Holman, Eric W., Cecil H. Brown, Søren Wichmann, André Müller, Viveka Velupillai, Harald Hammarström, Sebastian Sauppe, Hagen Jung, Dik Bakker, Pamela Brown, Oleg Belyaev, Matthias Urban, Robert Mailhammer, Johann-Mattis List and Dmitry Egorov. 2011. “Automated Dating of the World’s Language Families Based on Lexical Similarity.” Current Anthropology 52 (6):841–75.
- Honti, László. 2010. “Personae ingratissimae? A 2. személyek jelölése az uráliban.” Nyelvtudományi Közlemények 107:7–57.
- Huehnergard, John. 2000. Comparative Semitic Linguistics. Unpublished. Cambridge, Mass.
- Iggesen, Oliver A. 2013. “Number of Cases.” In The World Atlas of Language Structures Online, edited by Matthew S. Dryer and Martin Haspelmath. Leipzig: Max Planck Institute for Evolutionary Anthropology. http://wals.info/chapter/49.
- Jacques, Guillaume. 2016. “Le sino-tibétain: polysynthétique ou isolant?” Faits de langues 47 (1):61–74.
- Jakobson, Roman. 1930. “K charakteristike evrazijskogo jazykovogo sojuza.” In R. Jakobson, Selected Writings I, Phonological Studies, 144–201. The Hague. 2nd Reprint 1971.
- Jakobson, Roman. 1931. “Über die phonologischen Sprachbünde.” Travaux du cercle linguistique de Prague 4:234–40.
- Janhunen, Juha. 1982. “On the Structure of Proto-Uralic.” Finnisch-ugrische Forschungen 44: 23–42.
- Janssen, Dirk, Balthasar Bickel and Fernando Zúñiga. 2006. “Randomization Tests in Language Typology.” Linguistic Typology 10 (3):419–40.
- Kattein, Rudolf. 1983. Diachrone Typologie der slavischen Sprachen. Frankfurt am Main/Bern/New York: Peter Lang.
- Kempe, Vera and Patricia J. Brooks. 2018. “Linking Adult Second Language Learning and Diachronic Change: A Cautionary Note.” Frontiers in Psychology 9:480.
- Koch, Harold 1995. “The Creation of Morphological Zeros.” In Yearbook of Morphology, edited by Geert Booij, 31–71. Dordrecht: Kluwer.
- Koptjevskaja-Tamm, Maria. 2001. “A Piece of the Cake and a Cup of Tea: Partitive and Pseudo-Partitive Nominal Constructions in the Circum-Baltic Languages.” In The Circum-Baltic Languages: Typology and Contact, vol. 2: Grammar and Typology, edited by Östen Dahl and Maria Koptjevskaja-Tamm, 523–68 (Studies in Language Companion Series). Amsterdam/Philadelphia: John Benjamins.
- Koptjevskaja-Tamm, Maria. 2009. “A Lot of Grammar with a Good Portion of Lexicon: Towards a Typology of Partitive and Pseudopartitive Nominal Constructions.” In Form and Function in Language Research: Papers in Honour of Christian Lehmann, edited by Johannes Helmbrecht, Yoko Nishina, Yong-Min Shin, Stavros Skopeteas and Elisabeth Verhoeven, 329–46. Berlin/New York: Mouton de Gruyter.
- Kulonen, Ulla-Maija. 2001. “Zum n-Element der zweiten Personen besonders im Obugrischen.“ Finnisch-Ugrische Forschungen 56:151–74.
- Kusters, Wouter. 2003. Linguistic Complexity: The Influence of Social Change on Verbal Inflection. Leiden: Leiden University Press.
- Laanest, Arvo. 1982. Einführung in die ostseefinnischen Sprachen. Translated by Hans-Hermann Bartens. Hamburg: Buske.
- LaPolla, Randy. 2003. “Overview of Sino-Tibetan Morphosyntax.” In Linguistics of the Sino-Tibetan area: The State of the Art, edited by Graham Thurgood, James Matisoff and David Bradley, 22–42 (Pacific Linguistics Series C, 87). Canberra: Department of Linguistics, Australian National University.
- Lazard, Gilbert. 1998. Actancy. Berlin/New York: De Gruyter Mouton.
- Lipiński, Edward. 2001. Semitic Languages: Outline of a Comparative Grammar. 2ed. Leuven: Peeters.
- Gary Lupyan and Rick Dale. 2010. “Language Structure Is Partly Determined by Social Structure.” PLOS One 5 (1):e8559.
- Meier-Brügger, Michael. 2010. Indogermanische Sprachwissenschaft, 9, revised and supplemented edition, in cooperation with Matthias Fritz und Manfred Mayrhofer. Berlin: De Gruyter.
- Miklosich, Franz. 1883. Vergleichende Grammatik der slavischen Sprachen. Vol 4: Syntax. Vienna: Wilhelm Braumüller.
- Moroz, George. 2020. R Package ‘lingtypology’. Full title: Linguistic Typology and Mapping. Version 1.1.3. URL https://CRAN.R-project.org/package=lingtypology, https://github.com/ropensci/lingtypology/, https://ropensci.github.io/lingtypology/.
- Mosel, Ulrike and Even Hovdhaugen. 1992. Samoan Reference Grammar. Oslo: Scandinavian University Press.
- Nichols, Johanna. 1992. Linguistic Diversity in Space and Time. London/Chicago: University of Chicago Press.
- Nichols, Johanna. 1993. “The Linguistic Geography of the Slavic Expansion.” In American Contributions to the Eleventh International Congress of Slavists, Bratislava, August- September 1993: Literature, Linguistics, Poetics, edited by Robert A. Maguire and Alan Timberlake, 377–91. Columbus: Slavica.
- Nichols, Johanna 1995. “Diachronically Stable Structural Features.” In Historical Linguistics 1993: Selected Papers from the 11th International Conference on Historical Linguistics, Los Angeles 16–20 August 199, edited by Henning Andersen, 337–55. Amsterdam/Philadelphia: John Benjamins.
- Nichols, Johanna and Tandy Warnow. 2008. “Tutorial on Computational Linguistic Phylogeny.” Language and Linguistics Compass 2:760–820.
- Olander, Thomas. 2015. Proto-Slavic Inflectional Morphology: A Comparative Handbook. Leiden/Boston: Brill.
- Pakendorf, Brigitte. 2010. “Contact and Siberian Languages.” In The Handbook of Language Contact, edited by Raymond Hickey, 714–37. Malden: Wiley-Blackwell.
- Peterson, John. 2017. “Fitting the Pieces Together – Towards a Linguistic Prehistory of Eastern-Central South Asia (and Beyond).” JSALL 4 (2):211–57.
- Rafiyenko, Dariya and Ilja A. Seržant. 2020. “Postclassical Greek: An Overview.” In Contemporary Approaches to Postclassical Greek, edited by Dariya Rafiyenko and Ilja A. Seržant (Trends in Linguistics Series), 1–18. Berlin/New York: De Gruyter.
- Rjabinin, E. A. 1997. Finno-ugorskie plemena v sostave drevnej Rusi. St Petersburg: Izdatel′stvo Sankt-Peterburgskogo Universiteta.
- Róna-Tas, András. 1998. “The Reconstruction of Proto-Turkic and the Genetic Question.” In The Turkic Languages, edited by Lars Johanson and Éva Á. Csató, 67–80. London/New York: Routledge.
- Seržant, Ilja A. 2012. “The So-Called Possessive Perfect in North Russian and the Circum-Baltic Area: A Diachronic and Areal Approach.” Lingua 122:356–85.
- Seržant, Ilja A.. 2014. “The Independent Partitive Genitive in North Russian.” In Contemporary Approaches to Dialectology: The Area of North, Northwest Russian and Belarusian Vernaculars, edited by Ilja A. Seržant and Björn Wiemer, (Slavica Bergensia 13), 270–329. Bergen: University of Bergen.
- Seržant, Ilja A.. 2015. “Independent Partitive as a Circum-Baltic Isogloss.” Journal Language Contact 8:341–418.
- Seržant, Ilja A.. 2020a. “Dataset for the Paper ‘Typology of Partitives’, Linguistics [Data set].” Zenodo. https://doi.org/http://doi.org/10.5281/zenodo.4277624.
- Seržant, Ilja A.. 2020b. “Dataset for the Paper ‘Slavic Morphosyntax is Primarily Determined by its Geographic Location and Contact Configuration’, Scando-Slavica [Data set].” Zenodo. https://doi.org/http://doi.org/10.5281/zenodo.4277593.
- Seržant, Ilja A.. forthc.-a. “The Circum-Baltic Area: An Overview.” In Oxford Guides to the World’s Languages: The Slavonic Languages, edited by Jan Fellerer and Neil Bermel. Oxford: Oxford University Press.
- Seržant, Ilja A.. forthc.-b. “Cyclic Changes in Verbal Indexes are Unlikely.” In Diachrony of Individual Person Markers, edited by Andrea Sansò and Linda Konnerth. Special issue of Folia Linguistica Historica.
- Seržant, Ilja A.. forthc.-c. “Towards Diachronic Typology of Partitives.” In Partitive Determiners, Partitive Pronouns and Partitive Case, edited by to Giuliana Giusti and Petra Sleeman. (Linguistiche Arbeiten). Berlin: De Gruyter.
- Seržant, Ilja A.. forthc.-d. “Typology of Partitives.” Linguistics.
- Siewierska, Anna. 2010. “Person Asymmetries in Zero Expression and Grammatical Functions.” In Essais de typologie et de linguistique Générale: Mélanges offerts à Denis Creissels, edited by Franc Floricic. 471–85. Paris: Presses de L’Ecole Normale Supérieure.
- Seržant, Ilja A. 2013. “Verbal Person Marking.” In The World Atlas of Language Structures Online, edited by Matthew S. Dryer and Martin Haspelmath. Leipzig: Max Planck Institute for Evolutionary Anthropology. http://wals.info/chapter/102.
- Sinnemäki, Kaius. 2020. “Linguistic System and Sociolinguistic Environment as Competing Factors in Linguistic Variation: A Typological Approach.” Journal of Historical Sociolinguistics 6 (2):1–39.
- Stachowski, Stanisław. 2014. “Türkischer Einfluss auf den slavischen Wortschatz.” In Die slavischen Sprachen: Ein internationales Handbuch zu ihrer Struktur, ihrer Geschichte und ihrer Erforschung, edited by Karl Gutschmidt, Sebastian Kempgen, Tilman Berger and Peter Kosta, 1198–1210. Berlin: De Gruyter Mouton.
- Stankiewicz, Edward. 1986. The Slavic Languages: Unity and Diversity. Berlin/New York/Amsterdam: Mouton de Gruyter.
- Thomason, Sarah Grey. 2001. Language Contact: An Introduction. Edinburgh: Edinburgh University Press.
- Trudgill, Peter. 2009. “Sociolinguistic Typology and Complexification.” In Language Complexity as an Evolving Variable, edited by Geoffrey Sampson, David Gil and Peter Trudgill, 98–109. Oxford: Oxford University Press.
- Trudgill, Peter 2011. Sociolinguistic Typology: Social Determinants of Linguistic Complexity. Oxford: Oxford University Press.
- Wiemer, Björn. 2019. “Matrëška and Areal Clusters Involving Varieties of Slavic. On Methodology and Data Treatment.” In Slavic on the Language Map of Europe, edited by Andrii Danylenko and Motoki Nomachi, 21–62 (Trends in Linguistics 333). Berlin/Boston: DeGruyter.
- Wiemer, Björn and Ilja A. Seržant. 2017. “Diachrony and Typology of Slavic Aspect: What Does Morphology Tell Us?” In Unity and Diversity in Grammaticalization Scenarios, edited by Walter Bisang and Andrej Malchukov, 239–307 (Studies in Diversity Linguistics 16). Berlin: Language Science Press.
- Wichmann, Søren and Eric W. Holman. 2009. Temporal Stability of Linguistic Typological Features. Munich: Lincom Europe.