
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Circular data are encountered in a variety of fields. A dataset on music listening behaviour throughout the day motivates development of models for multi-modal circular data where the number of modes is not known a priori. To fit a mixture model with an unknown number of modes, the reversible jump Metropolis-Hastings MCMC algorithm is adapted for circular data and presented. The performance of this sampler is investigated in a simulation study. At small-to-medium sample sizes , the number of components is uncertain. At larger sample sizes
the estimation of the number of components is accurate. Application to the music listening data shows interpretable results that correspond with intuition.
2010 Mathematics Subject Classification:
1. Introduction
Circular data are data that can be represented as angles in two-dimensional space. Examples of measurements that result in circular data include directions on a compass (–
), time of day (0–24 hours) or day of year (0–365 days). These data are encountered across behavioural research [Citation1,Citation2] and many other scientific disciplines.
Analysis of circular data requires special statistical methods due to the periodicity of the sample space. For example, the arithmetic mean of the two time points 00:30h and 23:30h would be 12:00 h, while the circular mean is 00:00 h, which is clearly a preferable central tendency in this case. Several books on circular statistics are available, in particular Pewsey et al. [Citation3], Mardia and Jupp [Citation4], Fisher [Citation5].
This paper will focus on the modelling of multi-modal circular data with mixtures with an unknown number of components. Mixture models often assume the number of mixture components to be known, although this is rarely true in practice. As a solution, the number of mixture components is usually selected by comparing information criteria such as the AIC [Citation6] or BIC [Citation7]. Such an approach allows selection of a mixture model with the best-fitting number of components, but entirely ignores our uncertainty about the parameter determining the number of components.
A more natural and sophisticated approach is to treat the number of modes as unknown, and obtaining the uncertainty around the number of modes jointly with the rest of the analysis. The main contribution of this paper is to provide an algorithm to perform a fully Bayesian mixture model that correctly captures the uncertainty about the number of components, as well as showing its usefulness and interpretability with a real data example.
The motivating example for this paper is a data set on music listening behaviour. The data was provided by music service 22tracks,Footnote1 and consists of the time of day (on the 24-hour clock) at which a user played a particular song. The user is initially presented with a genre of music, which is selected uniformly random over the genres. The aim of our analysis is to determine which genres are listened to most at certain times, so the most relevant genre at a given time can be presented. In addition, a model where parameters can be directly interpreted may allow us to understand what drives music listening behaviour.
The base distribution for our circular mixture model will be the von Mises distribution, which is commonly used for analysis of circular data and can be considered the circular analogue of the Normal distribution. Von Mises mixture models with a fixed number of modes have been developed previously in a frequentist setting [Citation8], for example using the Expectation Maximization (EM) algorithm [Citation9,Citation10]. Beyond fitting, some work has also been done on hypothesis testing for von Mises mixtures [Citation11–13]. Bayesian analysis for this type of model can be performed through Markov chain Monte Carlo (MCMC) sampling [Citation14,Citation15]. In particular, the high-dimensional variant of this mixture model has seen some popularity due to several appealing applications such as text mining, which has led to an R package for this model [Citation16]. Such high-dimensional circular mixtures use the von Mises-Fisher distribution on hyperspheres, with the von Mises as a special case. We will focus on the circular mixture model only.
The core difficulty in employing MCMC samplers in such applications is that the parameter space is of variable dimension. That is, if there are more components in the mixture model, there are more parameters. Therefore, the usual MCMC approaches do not provide a way to explore the whole parameter space, and we must use a solution such as Reversible jump MCMC [Citation17,Citation18]. In a reversible jump MCMC sampler, we allow moves between parameter spaces by use of a special case of the Metropolis-Hastings (MH) acceptance ratio [Citation19]. This paper provides a detailed account of the adaptation of a reversible jump sampler for von Mises mixtures.
Three major contributions are made to the field of mixture modelling for circular data. First, this paper presents the first application of the reversible jump sampler to this setting, which allows us to perform inference on the amount of components in the mixture model. Second, a novel split move, which makes use of the trigonometric properties of the von Mises distribution, allows the sampler to move across the parameter space efficiently. Lastly, a simulation study is performed to show that this method performs well in common research scenarios.
Several alternative approaches for Bayesian modelling of multi-modal circular data could be considered. Most are found in the field of Bayesian non-parametrics, such as Dirichlet process mixture models [Citation20], the Generalized von Mises distribution [Citation21], log-spline distributions [Citation22] or a family of densities based on non-negative trigonometric sums [Citation23]. Such approaches generally have the advantage of making fewer assumptions about the distribution of the data. However, none of these methods provide a way for direct inference on the number of subpopulations (ie. components) making up the mixture, and the parameters in the mixture model with unknown number of components are much more interpretable.
Therefore, the approach taken in this paper can be seen as a useful in-between step between mixture models with a fixed number of components and non-parametric approaches. Compared to fixed-component mixture models, our approach is more realistic in the uncertainty about the amount of components, allows performing inference about the number of components, but also enables leaving the number of components to be uncertain. In particular, while information criteria based methods also allow selection of the most likely number of components, our approach provides a posterior probability distribution around the number of components, and as such acknowledges that the selected number of components can be wrong. Compared to non-parametric approaches, our approach features much more interpretable parameters and inference, at the cost of taking more assumptions about the shape of the distribution. Concluding, if the number of components is known or not of interest, a fixed-component mixture model can be preferred for simplicity, while if density estimation is the goal a fully non-parametric approach may be the best choice. If the number of components is not known, of interest, and interpretation of the parameters of subpopulations is of interest, our method aligns the best with these goals.
The paper is organized as follows. Section 2 describes the model and chosen priors. Section 3 contains the description and implementation of each of the steps involved in sampling the model parameters. In Section 4 the performance of the sampler is investigated in a simulation study. The sampler is applied to the 22tracks data in Section 5. Finally, the results are discussed in Section 6.
2. Von Mises mixture model
In this section, the von Mises-based mixture model will be developed. First, its general form will be given. Second, the likelihoods necessary for inference are discussed. Third, priors for this model are shortly discussed.
2.1. Von Mises mixture density
The von Mises distribution is a symmetric, unimodal distribution commonly used in the analysis of circular data. Its density is given by
(1)
(1) where
is an angle measured in radians,
is the mean direction,
is a non-negative concentration parameter and
is the modified Bessel function of the first kind and order zero.
When data consist of observations from multiple subpopulations for which the labels are not observed, the distribution of the pooled observations can be described by a mixture model. For example, times at which people listen to music are expected to coincide with daily events, such as dinner time or the daily commute, which are clustered around certain time points that show up as modes in the data set.
The density of the pooled observations can be expressed as a mixture
(2)
(2) where
is the number of components in the mixture,
and
are vectors of distribution parameters of each von Mises component and a vector
containing the relative size of each component in the total sample, called the weight vector. Weights, which are also sometimes called mixing probabilities, satisfy the usual constraints to lie on the simplex, that is
and
.
2.2. Likelihood
For a dataset of i.i.d. observations from a mixture of von Mises components, the likelihood is
(3)
(3) where it should be noted that the number of components g is treated as an unknown parameter instead of fixed, and that the lengths of
and
depend on g.
In order to perform inference on (,
,
, g), it will be convenient to include an additional latent vector
that encodes the component to which an observation in
is currently attributed. The probability of being attributed to component j is given by
The reason for introducing this parameter vector is that conditional on
,
is an independent observation from its respective component j. That is,
where inference for
and
is markedly easier than in the mixture likelihood in Equation (Equation3
(3)
(3) ), because the problem reduces to inference for a single von Mises component. The vector
is called the allocation vector and will be updated as part of the MCMC procedure. Conditional on the allocation vector, the expression for the likelihood of the component parameters
is simply
As per usual in the Bayesian framework, inference will be performed on the posterior distribution, which is given by
(4)
(4) where the prior
will be discussed next.
2.3. Prior distributions
Although informative priors could be used in practice, it may be difficult to do so for mixture models with an unknown number of components. That is, not knowing whether a component exists makes it unlikely that there is prior information about this component. However, one situation in which there is prior information is when all components are known to lie close to a certain angle. In that case the algorithm can easily be adapted, but we will focus on uninformative priors for simplicity. We will prioritize priors based on their mathematical and computational simplicity. The joint prior is assumed to factor into several independent priors, which will be discussed in turn.
For the von Mises parameters and
, a conjugate prior [Citation24,Citation25] is used. In principle, one can quite simply include prior information in the hyperparameters of this conjugate prior. However, for the reasons given above, we will focus on uninformative prior hyperparameters. For
, this is the circular uniform distribution, which we will write as
where
is the uniform distribution from a to b.
For this is a constant prior
. Both priors represent a lack of knowledge about these parameters. A more informative prior for
can also be set in the conjugate prior, for example if highly concentrated von Mises distributions are not expected to represent real subpopulations.
The conjugate prior for is the Dirichlet distribution. We will use the uninformative
which assigns equal probability to all combinations of weights.
The prior for the number of components g is chosen as . This can be seen to be the geometric distribution raised to the power N, the number of observations, used here as a method for penalizing complexity. While somewhat of a pragmatic choice, this prior performs well in practice. The prior prevents overfitting and can be interpreted as the belief that a parsimonious model is preferred, irrespective of the number of observations.
3. Reversible jump MCMC for von Mises mixtures
Bayesian inference for the von Mises mixture model will proceed by sampling from the posterior in Equation (Equation4(4)
(4) ) using MCMC sampling. As mentioned, standard MCMC will not be able to deal with the changing dimensionality in the parameter space after g changes, and therefore we will resort to reversible jump MCMC to solve this issue.
The reversible jump MCMC algorithm consists of five move types. These moves can be divided into fixed-dimension move types and dimension changing move types. The fixed-dimension moves are the standard moves for MCMC on mixture models. They do not change the component count g and thus do not alter the dimensionality of the parameter space. These moves are
updating the weights
;
updating component parameters (
updating the allocation
When g is known for a mixture of von Mises components, a sampler consisting of just these three moves would be sufficient.
In many cases however, g is not known and should be estimated as part of the MCMC procedure. This can be achieved by including two more move types, which are the reversible jump move types. They are
splitting a component in two, or combining two components;
the birth or death of an empty component.
Both of these move types change g by 1 and update the other parameters (,
,
,
) accordingly. In our implementation, the move types 1–5 are performed in order. One complete pass over each of these moves will be called an iteration and is the time step of the algorithm. The chosen implementations of these move types will be discussed in detail in the following sections.
3.1. Updating the weights w
Weights can be drawn directly from their full conditional distribution
, which is Dirichlet and dependent only on the current allocation
. It is given by
where
is the number of observations allocated to component j, given by
where
is an indicator function.
3.2. Updating component parameters μ and κ
The conditional posterior distribution of each is von Mises and given by
(5)
(5) where
is the vector of observations currently allocated to component j and
and
are respectively the mean direction and the resultant length of
.
The conditional distribution of can be expressed as
It is not straightforward to sample from this distribution. The method proposed by Forbes and Mardia [Citation26] is applied, which uses a rejection sampler to produce a sample from the full conditional distribution.
3.3. Updating the allocation z
Allocation for each observation is sampled based on the relative densities of the components. For observation i this is given by
This is the categorical (sometimes called 'multinouilli') distribution, and is simple to sample from.
3.4. Dimensionality changing moves
For the dimensionality changing moves we make use of reversible jump moves which are a special case of a Metropolis-Hastings step [Citation18]. The goal is to allow the sampler to move from a current state, which we'll denote by , to another state
which has a different size than x. In order to move around the parameter space efficiently, it will be useful to develop several different move types, each moving in a different manner.
In general, each move is implemented by sampling a random vector that is independent of x, the current state of the sampler. The proposal for a new state
can then be expressed as an invertible function
, to be chosen later, which maps x and u jointly to a proposal
. It is required that the move is designed as a pair, such that there also exists the reverse function
, which is why the algorithm is called reversible jump. Essentially, we develop a bridge between two spaces of different dimensions, and as a result are able to change the dimensionality.
Given a random vector u and the invertible function , we can accept or reject the proposal
using a Metropolis-Hastings (MH) acceptance ratio, which can be written as
(6)
(6) where
is the ordinary ratio of posterior probability of states x and
,
is the probabilty of choosing move type m from state x, and
is the density function of
, and the final term
is the Jacobian that arises from the change of parameter space from (x,
) to
. This Jacobian corrects for each state x lying in a space of different dimensionality, and will be 1 if the dimensionality does not change.
The reversible jump moves will dictate how to sample proposals for a new state given a vector
, after which the proposal is accepted or rejected based on the MH ratio just described. The precise form of this MH ratio depends on the move type and the chosen function
. Developing the move types and their associated invertible functions represents a large chunk of the work involved in implementing the reversible jump algorithm for a specific model. Next, some sensible choices for the von Mises model will be discussed.
3.4.1. Split or combine move
The split or combine move is designed as a reversible pair, as is required in the reversible jump framework. That is, any proposed split move is associated with a combine move that would undo it. A split move takes one component and replaces it with two new components. Conversely, a combine move joins two existing components into a single component.
Constructing split/combine proposals for reversible jump MCMC samplers can be done using moment matching [Citation27], where the moments of a combined component are defined to be the sum of the moments of the split components. In the case of von Mises components, the second (linear) moment of a von Mises distribution ignores the circular geometry of this problem, and is mathematically intractable. Rather, its trigonometric moments should be used. The first trigonometric moments of a von Mises component with parameters μ and κ are given by and
, where the mean resultant length is
and
can be approximated [Citation4, p. 40].
To make sure that the trigonometric moments represent a valid von Mises distributions, the point described by must lie on the unit disc, such that
(7)
(7) This is important for the reversible jump algorithm, because whenever any dimensionality changing move occurs, any new component must also satisfy these constraints.
The constraint of mapping to valid von Mises components, along with the reversibility condition, limit the set of possible moves. However, any move that follows these limitations will be valid in the sense that it will correctly sample from the desired posterior. As long as the limitations are met, we are free to select move types based on computational efficiency, for example. Computational efficiency will be attained when the proposals are likely to be accepted, which in turn is more likely when the proposals are in some sense 'close' to the original components. This will lead the specific choices for the combine and split moves, which will be discussed next.
Combine move
In the combine move, two current components, say and
, are combined into a single new component
. The combine move can be obtained from a simple weighted sum of the trigonometric moments. That is, the new combined component has trigonometric moments that are a weighted average between the two components that it stems from.
The parameters of the new component are defined by their trigonometric moments and component weight, , by computing
(8)
(8) It can be shown that the
correspond to a valid von Mises distribution and weight, due to the convexity of the unit disc (for
) and the convexity of the unit interval for the weight
.
Split move
In the split move, we start from joint component and split it into two components,
and
. The split move must also conform to (Equation8
(8)
(8) ) to fulfill the requirement of reversibility, but we must be more careful than in the combine move to prevent the trigonometric moments falling outside the allowed range. We will solve this by proposing the split components from the largest possible disc that is centred at the trigonometric moments of
, while being covered by the unit disc. This last property ensures that all proposals are valid.
Next we will discuss how exactly we draw the proposals from within this disc. We can do this by drawing vector from
where
is the Beta distribution, where we have chosen a = 2 and b = 1 to more often select proposals close to the current joint component
. Different distributions could be selected here to tune the performance of the method, but these have worked sufficiently in practice.
After drawing the vector , we can obtain our split components by computing
(9)
(9) As discussed, different choices are possible, but these were found to perform well in practice. To aid understanding, this procedure is given a visual representation in Figure , which will be discussed step by step next.
Figure 1. Construction of split proposal. In Step 1, the green vector shows the current mean resultant vector for the von Mises component to be split. In Step 2, the first split component is placed within the grey disc, by moving in direction
. Step 3 shows that the second split component (in blue) follows from a combination of trigonometric moments. (a) Step 1. (b) Step 2 and (b) Step 3.
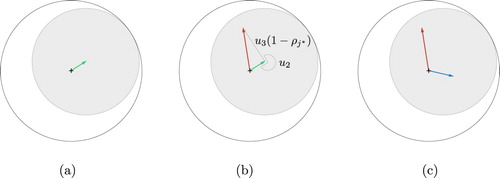
In step 1 (Figure (a), the von Mises component is represented by its trigonometric moments
and
as an arrow. The two new components' trigonometric moments must fall inside the unit circle, as to satisfy constraint (Equation7
(7)
(7) ). To do this, a disc with radius
centred at
is indicated in grey in the figure, from which the split components will be sampled.
In step 2 (Figure (b)), the first new von Mises component is placed relative to the original component. The random direction
is rotated so that
determines the direction in which we will step to obtain a new trigonometric moment of
. The trigonometric moments of the proposal
are then computed, in direction φ and a distance of
away from
.
Step 3 (Figure (c)) places the second new von Mises component. Given the original component and the first new component
, the moments for the second component
are placed. They are found in the opposite direction from
, that is
. The distance is determined depending on the ratio of the two weights. This can be computed as given in (Equation8
(8)
(8) ).
The probability of performing a split move as opposed to a combine move is set to
, independent of the current state of the MCMC sampler. It then follows that the probability of the corresponding combine move
and their ratio
. This can result in an attempted combine move when g = 1, which is immediately rejected.
The Jacobian for the split move is straightforward to derive, but long in form and given by
The inverse of this Jacobian is used for the combine move.
3.4.2. Birth or death move
A birth move introduces a new component into the mixture, without assigning any observations to this component. Its inverse, a death move, removes a component that has no observations.
The proposal for a birth move consists of drawing parameters ,
,
for a new component. They are chosen from a proposal distribution as
These parameters are then used to construct vector
,
,
. The weights of the other components need to be rescaled such that the sum of weights remains 1. The new weights are
, for
.
Notably, as no observations are allocated to the newly created component, the likelihood of the data is unaltered by the move. Additionally, as with the split or combine move type, the probability of performing a birth move is set equal to the probability of performing the corresponding death move
, independent of the state of the MCMC sampler. Therefore, the acceptance probability (Equation6
(6)
(6) ) can be simplified to
The Jacobian for a birth move is given by
For a death move, vector
is given by the component parameters of the component that is removed
,
. Its MH acceptance ratio is the inverse of the MH acceptance ratio of the corresponding birth move.
3.5. Label switching
When fitting a mixture model with a fixed number of components g, label switching [Citation28] can occur when, for example, the means of two components are close and by random chance switch order. This can also be seen as an identifiability problem. When applying a sampler that can jump between parameter spaces and change the number of components as part of the MCMC chain, label switching is very likely to occur, regardless of the distance between means, because split moves do not define an order for the created components.
A simple method of dealing with label switching is by imposing an identifiability constraint, for example by requiring the means to be ordered. This is a crude method that does not work in the case of circular data, since two means will always be ordered the same way on a circle.
A solution is provided by Stephens [Citation29] in the form of a post-processing step to define the most likely allocation of sampled parameters to individual components and does not rely on constraints. The second post-processing algorithm featured in the paper is applied to the samples belonging to each specific g separately.
4. Simulation study
A simulation study was performed to investigate the relative performance of the MCMC sampler in different scenarios. The sampler was implemented in R [Citation30] using the package [Citation31]. The source code has been made available at https://github.com/pieterjongsma/circular-rjmcmc.
4.1. Simulation scenarios
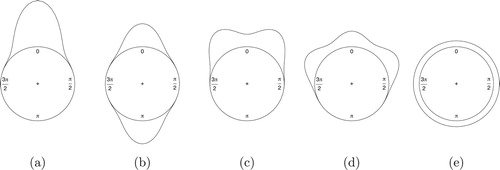
In order to assess the performance in a variety of settings, five true data generating processes were selected to represent either common or particularly difficult mixture datasets to fit. These scenarios are visualized in Figure and consist of ((a)) a single von Mises component where and
, ((b)) two von Mises components where
,
and
, ((c)) two von Mises components where
,
and
, ((d)) three von Mises components where
,
,
and
and ((e)) a uniform von Mises component (
). Each scenario is simulated with 50, 100, 250, 500, 1000, 2500 and 10,000 observations across 1000 replications.
Figure 2. Visualization of simulation scenarios used for investigating sampler performance.
4.2. Starting values
The MCMC sampler is initialized with a single component (g = 1) and parameters for the component drawn analogous to a birth move
The observations are all attributed to this single component by setting the allocation vector as
for
.
4.3. Convergence
The convergence of a reversible jump MCMC algorithm is difficult to assess using conventional methods such as the inspection of the sampled values of a parameter. Due to the changing dimensionality, the posterior distributions of individual component parameters depend on the component count g. The chains for these components are expected to jump with every change of g and would therefore not provide a valid measure of convergence. Instead, the likelihood is calculated for each iteration of the MCMC chain for which convergence of the posterior probability is assessed visually. All chains, regardless of starting value and variation in replicated data, converged within a burn-in of 10,000 iterations. After the burn-in, the next 5,000 iterations are retained and used to describe the posterior properties of the simulated dataset.
4.4. Results
For brevity, this section will be focused on the ability of the sampler to recover the number of components g correctly. In addition, performance of model parameters will be assessed for a subset of simulations.
4.4.1. Number of components g
The results for the number of components g of the simulation study are summarized in Table . It shows the fraction of replications in which the maximum a posteriori (MAP) estimate of g, , which is the posterior mode, was equal to the simulated g,
. Furthermore, the posterior distribution of g is given, averaged over all replications.
Table 1. Simulation results for each of the scenarios in Figure with sample sizes ranging from n = 50 to n = 10000. Each row represents 1000 replications. The fraction of replications where the estimated g was equal to the simulated g is given under . In addition, the posterior distribution is given as the average over all replications.
Results with few observations (n = 50) show high uncertainty about the number of components. For these replications, the mode of the posterior distribution for g was rarely equal to the simulated g. As expected, the estimation of g then improves with the number of observations. Most scenarios show a near 100% correct mode at 1000 observations or more. One exception is scenario (b) for n = 10000. Here, g is overestimated and accuracy is seemingly worse than at a smaller sample size. It should be noted that an overestimation of g does not necessarily indicate a problem with the MCMC method. A model with a higher number of components may have a higher likelihood of the data. The chosen prior for g is intended to counter this effect, such that the simpler model is favoured. The prior is seemingly not powerful enough for scenario (b) where n = 1000 or larger.
For the uniform scenario (e), the column , showing the correspondence between the mode of the posterior distribution and the simulated g, has been omitted. Although this data was simulated as a single component with
, the interpretation of ‘true’ g of this distribution is ambiguous. For larger datasets, the method favours a small number of components, as expected.
4.4.2. Parameter estimates
Results for the recovery of the von Mises parameters and
, are summarized for scenario (d) in Table . To obtain these estimates, only the MCMC states with three components are retained, so that g = 3 as in the data generating process of scenario (d). For each simulated data set, MAP estimates for
and
, are computed by estimating the posterior modes from the MCMC sample. Then, these MAP estimates are averaged over all simulated datasets and presented.
Table 2. Parameter estimates for scenario (d) with parameters , , and .
The estimates of component parameters for scenario (d) show that in general the method is able to recover the true parameter estimates for μ without bias, even with small sample size (n = 50). The concentration parameter is overestimated with small samples, but estimates are reasonable for samples where
. The concentration parameter of the central component,
, is systematically underestimated in this scenario, with
and
slightly overestimated except with very large sample sizes. Most likely, the central component is assigned some observations that belong to its two neighbours, and as a result is estimated as less concentrated than the true data generating process.
5. Illustration
As a motivating example, we will apply the reversible jump MCMC sampler to a dataset of listening behaviour, made available by 22tracks. This data will first be described and visualized in Section 5.1. Then, results from applying the sampler to the data are discussed in Section 5.2.
5.1. Dataset
The data provided by 22tracks contain metrics of all users of the service over the span of one week (January 4–10, 2016). The data consist of the time of day (00:00 h to 23:59 h) at which a user played a particular song, categorized by the genre this song was in. In this paper, a subset of the data is used as an illustration. These consist of all observations categorized under one of three genres that were selected arbitrarily. The genres are Indie Electronic, Relax and Deep House. Figure shows kernel density estimates of each genre. It can be seen that depending on the genre, the data features a different number of modes, although determining the precise number of modes is difficult without running the mixture model.
Figure 3. Kernel density estimates of observations for analysed 22tracks genres, using a von Mises kernel with . The period of the circle is 24 hours. (a) Indie Electronic (n = 11, 393). (b) Relax (n = 10, 657) and (c) Deep House (n = 4, 757).
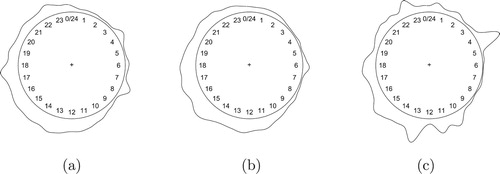
The first goal of this analysis is to estimate the genre that is most likely to be selected at any given time. Supposedly, users listen to the genres available on the 22tracks service at different times of day. For example, Pop might be a genre that users listen to throughout the day while Deep House is preferred during the night. Quantifying this behaviour is valuable for the music service, as it allows them to present the most appropriate genres to users when they visit the site at a particular time.
The second goal is to understand music listening behaviour through the parameters of our mixture components, as the times at which we listen to music are a reflection of life in our society. The mixture components are then interpreted as a subpopulation of observations that correspond to a certain category of music listening, such as listening while working, during transit, or while dancing.
5.2. Results
We apply the mixture model to each genre separately, with starting values as described in Section 4.2, using a burn-in of 10,000 iterations and retaining the next 100,000 iterations for inference. The posterior distributions for component count g are summarized in Table . The posteriors are quite different, with the Deep House genre showing a notably higher estimated component count, which is in accordance with the data as displayed in Figure .
Table 3. Posterior probability of component counts for selected 22tracks genres.
To obtain estimates for the other parameters ,
and
, only the samples for which
are used. For Deep House, these are samples where g = 6, for Indie Electronic g = 2 and for Relax g = 3. The parameters have been summarized in Table , ordered by the weights
.
Table 4. Estimated component parameters for individual genres in 22tracks data. LB and UB indicate the lower and upper bound of the 95% density of the data density of this von Mises component. Components have been ordered according to their respective weights.
The Indie Electronic genre shows two broad components spanning most of the day. One is centred at the middle of the day (14:15 h) and one is centred in the evening (21:13 h), most likely corresponding to listening while working and listening at home during the evening. The components have a small concentration, suggesting only slight preference for these times. Such broad components are necessary, because listening occurs throughout the day. Similarly, the Relax genre is given three components with small concentration.
For the Deep House genre, six components provided the best fit. The first three components are broad and similar to the components found for the other genres. The central times are later in the day, as one might expect for this type of music. The sampler was also able to detect and fit the strong concentrations of observations at 10:41, 04:27 and 12:58 h. It is unlikely that these patterns have been created by actual users. More likely, they indicate a special attribute of the data. For example, a computer bot instead of an actual person could have triggered a large amount of plays in a short time span. Although this does not tell us anything about the behaviour of actual users, it is still an interesting property that the sampler detects quite well. In fact, such a component has direct financial implications for this business, as such plays can be rejected to save costs.
Compared to a kernel density model, this provides a much simpler and more interpretable summary of the data. The posterior distribution also provides uncertainty around all of these estimates, although these are not shown here for brevity.
6. Discussion
We have presented a method for Bayesian inference of von Mises mixture distribution. Previous work has assumed the number of components to be known, which is an assumption we have relaxed by employing the reversible jump MCMC algorithm. The main contributions included a novel set of dimensionality changing moves based on the trigonometric properties of the von Mises distribution. In addition, the performance of the method was investigated in a simulation study. Generally, the method performed well. An illustration was provided on music listening behaviour, showing the interpretation of this method.
Results of the simulation study showed that the estimation of the number of components g was accurate for the majority of the simulated sample sizes, so the proposed split and combine moves successfully move between parameter spaces. In one scenario ((b)), g is overestimated at a very large sample count (n = 10000). In this case the proposed prior for g appears insufficient. A different choice of prior might be able to counter this effect and seems a topic for further investigation. It should be noted that although undesirable, an overfitted mixture is not necessarily problematic in application. The estimation of parameters ,
and
of the individual components is not directly affected and these parameters remain interpretable. Furthermore, the component weights allow us to gauge the relative importance of each component.
Application to the 22tracks data provides an example for the interpretation of reversible jump MCMC sampler output. It should be noted that the observation counts in the 22tracks data were higher than what showed the most accurate estimation of the simulated component count in the simulation study and as such we did not infer much from the estimated g. Because the parametric von Mises model is easy to interpret, one can compare the results with intuition. The estimated component parameters and
in the provided example seem reasonable as they indicate listening to occur during daytime and in the evening.
In conclusion, the method presented in this paper provide a reversible jump MCMC sampler that is shown to perform well on simulated data as well as a real world example.
Disclosure statement
No potential conflict of interest was reported by the author(s).
ORCID
Kees Mulder http://orcid.org/0000-0002-5387-3812
Additional information
Funding
Notes
1 Unfortunately this music service is now defunct. Previously it was found at http://www.22tracks.com/.
References
- Gurtman MB. Exploring personality with the interpersonal circumplex. Soc Personal Psychol Compass. 2009;3(4):601–619. doi: 10.1111/j.1751-9004.2009.00172.x
- Mechsner F, Kerzel D, Knoblich G, et al. Perceptual basis of bimanual coordination. Nature. 2001;414(6859):69–73. doi: 10.1038/35102060
- Pewsey A, Neuhäuser M, Ruxton GD. Circular statistics in R. Oxford University Press; 2013.
- Mardia KV, Jupp PE. Directional statistics. Wiley; 2000.
- Fisher NI. Statistical analysis of circular data. Cambridge: Cambridge University Press; 1995.
- Akaike H. A new look at the statistical model identification. IEEE Trans Automat Contr. 1974;19(6):716–723. doi: 10.1109/TAC.1974.1100705
- Schwarz G. Estimating the dimension of a model estimating the dimension of a model. Ann Stat. 1978;6(2):461–464. doi: 10.1214/aos/1176344136
- A Mooney J, Helms PJ, Jolliffe IT. Fitting mixtures of von Mises distributions: a case study involving sudden infant death syndrome. Comput Stat Data Anal. 2003;41(3–4):505–513. doi: 10.1016/S0167-9473(02)00181-0
- Banerjee A, Dhillon IS, Ghosh J, et al. Clustering on the Unit Hypersphere using von Mises-Fisher distributions. J Mach Learn Res. 2005;6(Sep):1345–1382.
- McLachlan G, Krishnan T. The EM algorithm and extensions. John Wiley & Sons; 2007.
- Chen J, Li P, Fu Y. Testing homogeneity in a mixture of von Mises distributions with a structural parameter. Canadian J Stat. 2008;36(1):129–142. doi: 10.1002/cjs.5550360112
- Fu Y, Chen J, Li P. Modified likelihood ratio test for homogeneity in a mixture of von Mises distributions. J Stat Plan Inference. 2008;138(3):667–681. doi: 10.1016/j.jspi.2007.01.003
- Paindaveine D, Verdebout T. Inference on the mode of weak directional signals: a Le Cam perspective on hypothesis testing near singularities. Ann Stat. 2017;45(2):800–832. doi: 10.1214/16-AOS1468
- Besag J, Green P, Higdon D, et al Bayesian computation and stochastic systems. Stat Sci. 1995;10(1):3–41. doi: 10.1214/ss/1177010123
- Tierney L. Markov chains for exploring posterior distributions. Ann Stat. 1994;22(4):1701–1728. doi: 10.1214/aos/1176325750
- Hornik K, Grün B. movMF: an R package for fitting mixtures of von Mises-Fisher distributions. J Stat Softw. 2014;58(10):1–31. doi: 10.18637/jss.v058.i10
- Green PJ. Reversible jump Markov chain Monte Carlo computation and Bayesian model determination. Biometrika. 1995;82(4):711–732. doi: 10.1093/biomet/82.4.711
- Richardson S, Green P. On Bayesian analysis of mixtures with unknown number of components. J R Stat Soc Ser B (Stat Methodol). 1997;59(4):731–792. doi: 10.1111/1467-9868.00095
- Hastings WK. Monte Carlo sampling methods using Markov chains and their applications. Biometrika. 1970;57(1):97–109. doi: 10.1093/biomet/57.1.97
- Ghosh K, Jammalamadaka R, Tiwari R. Semiparametric Bayesian techniques for problems in circular data. J Appl Stat. 2003;30(2):145–161. doi: 10.1080/0266476022000023712
- Gatto R, Jammalamadaka R. The generalized von Mises distribution. Stat Methodol. 2007;4(3):341–353. doi: 10.1016/j.stamet.2006.11.003
- Ferreira JTAS, Juárez MA, Steel MFJ. Directional log-spline distributions Directional log-spline distributions. Bayesian Anal. 2008;3(2):297–316. doi: 10.1214/08-BA311
- Fernández-Durán JJ, Mercedes Gregorio-Domínguez M. Bayesian analysis of circular distributions based on non-negative trigonometric sums. J Stat Comput Simul. 2016;86(16):3175–3187. doi: 10.1080/00949655.2016.1153641
- Guttorp P, Lockhart RA. Finding the location of a signal: A Bayesian analysis. J Am Stat Assoc. 1988;83(402):322–330. doi: 10.1080/01621459.1988.10478601
- Mardia KV, El-Atoum S. Bayesian inference for the von Mises-Fisher distribution. Biometrika. 1976;63(1):203–206. doi: 10.1093/biomet/63.1.203
- Forbes PGM, Mardia KV. A fast algorithm for sampling from the posterior of a von Mises distribution. J Stat Comput Simul. 2014;85(13):2693–2701. doi: 10.1080/00949655.2014.928711
- Brooks SP, Giudici P, Roberts GO. Efficient construction of reversible-jump Markov chain Monte Carlo proposal distributions. J R Stat Soc Ser B (Stat Methodol). 2003;65(1):3–55. doi: 10.1111/1467-9868.03711
- Jasra A, Holmes CC, Stephens DA. Markov chain Monte Carlo methods and the label switching problem in Bayesian mixture modeling. Stat Sci. 2005;20(1):50–67. doi: 10.1214/088342305000000016
- Stephens M. Dealing with label switching in mixture models. J R Stat Soc Ser B (Stat Methodol). 2000;62(4):795–809. doi: 10.1111/1467-9868.00265
- R Core Team, R: a language and environment for statistical computing [computer software manual]. Vienna, Austria. Available from: https://www.R-project.org/. 2015.
- Agostinelli C, Lund U. R package circular: circular Statistics (version 0.4-7) [computer software manual]. CA: Department of Environmental Sciences, Informatics and Statistics, Ca' Foscari University, Venice, Italy. UL: Department of Statistics, California Polytechnic State University, San Luis Obispo, California, USA. Available from: https://r-forge.r-project.org/projects/circular/. 2013.