
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Maximum likelihood estimation of a location parameter fails when the density has unbounded mode. An alternative approach is considered by leaving out a data point to avoid the unbounded density in the full likelihood. This modification gives rise to the leave-one-out (LOO) likelihood. We propose an expectation-conditional maximisation (ECM) algorithm to estimate parameters of variance gamma (VG) distribution with unbounded density by maximising the LOO likelihood. VG distribution has normal mean-variance mixtures representation that facilitates ECM algorithm. K Podgórski, J Wallin [Maximizing leave-one-out likelihood for the location parameter of unbounded densities. Ann Inst Stat Math. 2015;67(1):19–38.] showed that the location parameter estimate which maximises the LOO likelihood is consistent and super-efficient. In the case of repeated data, the LOO likelihood is still unbounded and we extend it to Weighted LOO (WLOO) likelihood. We perform simulations to investigate the accuracy of ECM method using WLOO likelihood and compare it with other likelihood methods, including the alternating ECM with fixed and adaptive caps to the unbounded density, the ghyp package using multi-cycle ECM, and the ECM using LOO likelihood. Lastly, we explore the asymptotic properties of the location parameter estimate of VG distribution such as the optimal convergence rate and asymptotic distribution.
1. Introduction
Asymptotic properties of maximum likelihood estimation for location parameters have been studied for the case when the likelihood is non-differentiable but bounded [Citation1]. However, this method breaks down when the likelihood is unbounded at certain points. Alternative methods for the unbounded density case have been considered in Refs [Citation2,Citation3] and in Ref. [Citation4] where they proved consistency of the location estimate using the Bayesian approach.
Under the likelihood approach however, modifications to the full likelihood are necessary since the unbounded points occur at the data points. A possible solution is to leave out a data point closest to the location parameter in the full likelihood. This modification leads to a concept known as the leave-one-out (LOO) likelihood proposed by Podgórski and Wallin [Citation5]. They proved consistency and super-efficiency of the location estimate that maximises the LOO likelihood when the density is unbounded. More precisely, under certain regularity conditions, they found an upper bound for the index of convergence rate for the location parameter estimate (see Section 3.2 for the definition of convergence rate and its index). Currently, there are no theoretical results regarding the optimal convergence rate and the asymptotic distribution of the maximum LOO likelihood estimate for the location parameter when the density is unbounded or with cusp. Since the theoretical derivation of these two asymptotic properties is very challenging, we propose to perform numerical simulations to investigate the properties and obtain some insights for the theoretical development.
To demonstrate the idea, we consider multivariate skewed variance gamma (VG) distributions with unbounded densities when the shape parameters where d is the dimension of the multivariate data. To estimate the parameters of VG distributions with unbounded densities, Nitithumbundit and Chan [Citation6] proposed an expectation-conditional maximisation (ECM) algorithm [Citation7] where they proposed to cap the density within a small interval of the location parameter. Depending on whether the conditional density or actual density is used to estimate the shape parameter, ECM algorithm can be further classified into multi-cycle ECM (MCECM) and ECM either (ECME) [Citation8,Citation9]. In this paper, the ECME algorithm is still called ECM algorithm as the methodological idea of ECME is similar to ECM. However, a drawback to capping the unbounded density is that the size of the interval to cap the density is somewhat arbitrary, and that different intervals can give different results. Podgórski and Wallin [Citation5] established a theoretical framework for using the LOO likelihood in an expectation-maximisation (EM) algorithm to estimate the location parameter of univariate symmetric generalised Laplace distribution (which is equivalent to VG distribution proposed by Madan and Seneta [Citation10]) with fixed shape parameter and unbounded density.
However, when there are data multiplicity (repeated data), the LOO likelihood will still be unbounded even if we leave out one of the data points. If we leave out multiple data points to obtain the leave-multiple-out (LMO) likelihood, this LMO likelihood has varied data size and contribution across the parameter space depending on the data multiplicities. This inconsistent data contribution leads to a discontinuous LMO likelihood. It is necessary to address this data multiplicity issue in the LOO likelihood as the issue is likely to occur for three reasons. Firstly, data rounding is common in practice simply for convenience or for reducing data storage. Secondly, as big data are more prevalence in recent years, the chance of data multiplicity increases with sample size. Lastly, as measurements are made more instantaneously for high-frequency data, the changes between measurements will be minimal and hence measures using these changes such as returns will be extremely small or even zero again giving rise to data multiplicity. Although the chance of data multiplicity is lower when the means for the time series model say change over time and when multi-dimensional models are used, one will never be sure in practice if data multiplicity exists. Hence, it is always advisable to fix the LOO likelihood issues to provide numerically stable estimates.
Following this idea, Nitithumbundit and Chan [Citation11] proposed weighted LOO (WLOO) likelihood to deal with discontinuous LMO likelihood when there are data multiplicities. They applied WLOO likelihood to multivariate data with unbounded densities and derived an ECM algorithm [Citation8] to obtain the maximum WLOO estimate of the location parameters of the vector autoregressive moving average (VARMA) model with multivariate skewed VG distribution when densities are cusped or unbounded with respect to the location parameters. The proposed algorithm is an extension of the EM algorithm. They derive explicit formulae to calculate all parameters in the expectation step (E-step) and conditional maximisation steps (CM-steps). When there are data multiplicities, they applied WLOO likelihood to obtain a continuous likelihood function. However, the paper focuses on the application and did not study the properties of this new method using the ECM algorithm with WLOO likelihood.
The objective of this paper is to fill up this research gap and study the properties of our proposed ECM algorithm with WLOO likelihood. Our first objective assesses the accuracy of the ECM algorithm using LOO likelihood in the case of no data multiplicity and compare the ECM algorithm using the LOO and WLOO likelihoods with other full likelihood methods in the case of data multiplicity due to repetition and rounding. To focus on the properties of the method, we make two modifications to Ref. [Citation11]. We consider a constant mean instead of the ARMA mean and we drop the alternating ECM (AECM) algorithm which aims only to improve the convergence rate of the ECM algorithm. Our second and main objective analyses the asymptotic behaviour including the optimal convergence rate and asymptotic distribution for the maximum LOO likelihood estimate for the location parameter through simulation studies using data simulated from the VG distribution with different sample sizes and shape parameters. Specifically, we investigate how the index of optimal convergence rate in Ref. [Citation5] for the location parameter estimates and its asymptotic distribution change across the shape parameter of VG distribution with unbounded or cusp density. From these studies, we aim to approximate the asymptotic distribution with some distributions to provide standard error for the location parameter estimates.
We choose VG distribution to demonstrate the ability of our proposed methods to deal with unbounded densities for three important reasons. Firstly, VG distribution is an important special case of the more general class, the generalised hyperbolic (GH) distribution [Citation12]. When GH distribution approaches VG distribution, one of its shape parameters will approach the boundary of the parameter space potentially causing the density to become unbounded. Although Protassov [Citation13] proposed an EM algorithm for GH distribution, such algorithm considers only regular shape parameters inside the parameter space and hence it does not truly capture the case of VG distribution with unbounded density when one of the shape parameter approaches the boundary of the parameter space causing unbounded densities. Our proposed ECM algorithm deals with such a case when the density is unbounded. Secondly, VG distribution has a normal mean-variance mixture (NMVM) representation that facilitates the implementation of ECM algorithm. Lastly, VG distribution has applications in many areas such as finance, signal processing and quality control. See Ref. [Citation14] for other applications and further details on generalised Laplace distribution. We remark that the idea of the proposed ECM algorithm can be applied to other distributions in NMVM representation including Student's t and GH distributions with some suitable adjustments in the E-step.
The remaining paper is organised as follows. Section 2 summarises some important properties of the multivariate skewed VG distribution. Section 3 formulates the maximum LOO likelihood framework for estimating the location parameter of distributions with unbounded densities, reports some properties of the estimate and introduces the WLOO likelihood with two examples to explain the weight settings. Section 4 introduces the ECM algorithm using the LOO and WLOO likelihoods to estimate parameters from the VG distribution. Although the methodologies in Sections 3 and 4 were described in Ref. [Citation11], we present them in a slightly different way starting with defining different LOO likelihoods which are the focus and with different emphasis giving more technical details. Moreover, some equations are modified for the different mean structures. Section 5 presents three simulation studies. The first study tests the accuracy of our ECM method using WLOO likelihood while the second study compares the accuracy of the ECM method with other full and LOO likelihood methods in three scenarios, namely, no data multiplicity, data multiplicity due to repetition and data multiplicity due to rounding. The last study analyses the asymptotic behaviour of the maximum LOO likelihood method to estimate the location parameter of VG distribution. Section 6 concludes the paper with further remarks.
2. Variance gamma distribution
The probability density function (pdf) of a d-dimensional VG distribution is given by
(1)
(1) where
,
is the location parameter,
is a
positive definite symmetric scale matrix,
is the skewness parameter,
is the shape parameter,
is the gamma function and
is the modified Bessel function of the second kind with index λ [Citation15].
The VG distribution has a normal mean-variance mixtures representation [Citation12] given by
(2)
(2) where
is a Gamma distribution with shape parameter a>0, rate parameter b>0 and pdf
The mean and covariance matrix of a VG random vector
are given by
respectively. As
, the pdf in (Equation1
(1)
(1) ) is given by
(3)
(3) Hence the density becomes unbounded at
when
. This poses some technical difficulty when working with VG distribution as it is unclear whether the shape parameter will fall into the unbounded range. It is also worth noting that the density is bounded with a cusp when
.
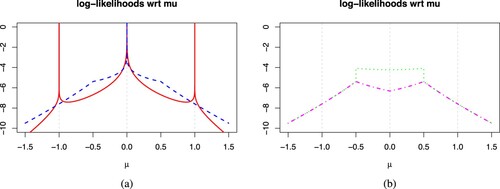
This problem of unbounded density is illustrated in Figure of Ref. [Citation11] with the full log-likelihood and LOO log-likelihood across the location parameter for a data of 10 observations simulated from a standard VG distribution (,
,
) with shape parameter
. Leaving the data point out essentially smooths out the unbounded log-likelihood at data points so the maximum can be well-defined. Additionally, if we zoom in at around
, we observe that cusps tend to occur between data points.
Figure 1. Plots of full (solid red), LOO (striped blue), LMO (dotted green), and WLOO (dot & striped magenta) log-likelihoods of univariate symmetric VG distribution with for data set
represented by light grey vertical strips. (a) Full and LOO log-likelihoods and (b) LMO and WLOO log-likelihoods.
3. Maximum leave-one-out likelihood
Let be observed data from VG distribution with corresponding missing parameters
, and
be parameters from VG distribution in parameter space
. The density of the VG distribution is unbounded at
when
. Consequently the maximum likelihood estimate is not well-defined since there are multiple unbounded points at each data point in the likelihood function. Kawai [Citation16] showed that for the univariate case, the Fisher information matrix with respect to μ is also not well-defined when
. That is if
, then
where Y is a univariate VG random variable with density function f, and the expectation is taken with respect to Y which depends on
.
We aim to provide a methodology to estimate parameters from VG distribution that can also deal with unbounded density. We first redefine the likelihood so that the maximum is well-defined even with the unbounded density.
3.1. Leave-one-out likelihood
Podgórski and Wallin [Citation5] proposed the observed LOO likelihood to be defined as
where the LOO index is defined as
(4)
(4) For the case where there are more than one indices, we choose the smallest index. Note that we slightly modify the convention in Ref. [Citation5]: ‘if there are two indices we take the one for which corresponding
is on the right side of μ’ as it only deals with the univariate case and cannot be easily extended to multivariate setting using this convention. Let the observed LOO log-likelihood be defined as
(5)
(5) We remark that when considering asymmetric distributions, the LOO likelihood function is discontinuous. For the VG distribution with skewness, the discontinuity is not an issue since the density is asymptotically symmetric as
from (Equation3
(3)
(3) ), and so the effect of the discontinuities is minimised for larger sample size. On the other hand, when using other distributions with different skewness behaviour, the LOO index can alternatively be defined as
(6)
(6) In this paper, we adopt the LOO index in (Equation6
(6)
(6) ) and define the maximum LOO likelihood estimate denoted as
(or simply
) to be the estimate that maximises the LOO likelihood with respect to
. This new and more general index definition makes the LOO likelihood continuous and for the symmetric case it would coincide with (Equation4
(4)
(4) ).
3.2. Properties of the maximum leave-one-out likelihood method
For the one-dimensional case, some properties of the location parameter estimate such as consistency and super-efficient rate of convergence are proved by Podgórski and Wallin [Citation5]. We state both the assumptions and theorem relating to these main properties:
| (A1) | The pdf | ||||
| (A2) | There exist | ||||
| (A3) | For all | ||||
Theorem 3.1
Let f satisfies the assumptions (A1) to (A3) and let be the maximizer of
. Then
is consistent estimate of μ and for any
,
where α is defined in (A1) and
means convergence in probability.
This theorem states the lower bound for the convergence rate of the location parameter estimate using maximum LOO likelihood. For univariate VG distribution,
. Hence setting
possibly gives us the index for the optimal convergence rate (or the proposed optimal rate) for
. Additionally,
may converge to some asymptotic distribution for some suitable choice of β. We will investigate the asymptotic properties later in Section 5 using simulations from VG distribution.
3.3. Extension to weighted LOO likelihood for data multiplicity
Data multiplicity is common when the measurements have limited level of accuracy. In this case, the LOO likelihood is first extended to the leave-multiple-out (LMO) likelihood defined as
where
(7)
(7) represents the LMO indices which correspond to the data points identical to
, and
represents the LOO index defined in (Equation4
(4)
(4) ) in Section 3.1. When there are no data multiplicities, the LMO likelihood reduces to the LOO likelihood with consistent
data contribution. However, when there are varied data multiplicities, the number of data points to leave out is not fixed and so the LMO likelihood has varied data contribution across the parameter space. This inconsistent data contribution throughout the parameter space leads to a discontinuous LMO likelihood. To remedy this, we propose to adjust the LMO likelihood to weighted LOO (WLOO) likelihood defined as
(8)
(8) where we choose the weights to be
(9)
(9)
is defined in (Equation7
(7)
(7) ) such that
represents the cardinality of the set
,
(10)
(10) and
represents the secondary LOO index for VG distribution in NMVM representation. Similarly, the WLOO log-likelihood is defined as
(11)
(11) Clearly, LOO likelihood is the special case of WLOO likelihood when there is no data multiplicity and the weights are chosen to be
. We use two examples with data multiplicity at one and two locations respectively to demonstrate how the weights in (Equation9
(9)
(9) ) are derived to ensure bounded and continuous likelihood as well as consistent weighted data size, that is
, when data with different multiplicities are removed. We call the first example symmetric since there are equal number of data points on each side of the data with multiplicity. The second example is asymmetric as there are different number of data points on each side of the data with multiplicity. In these two examples, the shape parameter
that corresponds to unbounded likelihood. When the density function is skewed, both LOO and WLOO likelihoods are not continuous between data points. Nevertheless, the pdf in (Equation3
(3)
(3) ) is approximately symmetric as
approaches any data point. So by having more data points, the effect of discontinuities due to skewness is negligible.
Example 1: data multiplicity at a single location
The first data have data multiplicity at a single location 0. Figure plots the LOO log-likelihood across μ. In Figure (a), the LOO log-likelihood is unbounded at 0 even after leaving out one data point 0.
Figure 2. Plot of the full (solid red), LOO (striped blue), LMO (dotted green), and WLOO (dot & striped magenta) log-likelihoods of symmetric VG distribution with for data set
represented by light grey vertical strips. (a) Full and LOO log-likelihoods and (b) LMO and WLOO log-likelihoods.
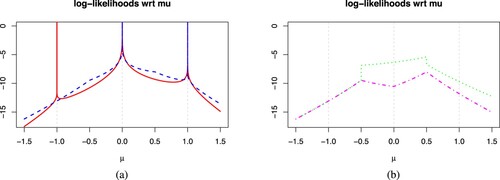
The LMO log-likelihood in Figure (b) is bounded after leaving out multiple data points at 0 but it also produces discontinuities at the midpoints of and 0.5. We aim to choose the weights in the WLOO log-likelihood
(
) to ensure consistent data contribution, that is,
. Since the pdf is assumed to be symmetric, we define
and analyse the WLOO log-likelihood around the small neighbourhood
of the midpoints located at
and 0.5. It is sufficient to look at one of the midpoints.
Midpoint of 0 and 1: At , the data point
is closest to μ. So we leave out
in the WLOO log-likelihood by setting
. This gives us
Since the data point
has a single contribution to the log-likelihood, we set
leaving the other weights
so that
. At
, the data points
is closest to μ so we set
which gives us
Again, we set
leaving
so that
. Choosing these weights gives us a continuous WLOO likelihood at
given by
where
. This shows that after leaving out multiple data points, extra weight is added to the neighbouring data points to compensate for the missing weights.
Example 2: data multiplicities at two locations
The second data have different data multiplicities at 0 and 1. As before we define the WLOO log-likelihood as
Midpoint of -1 and 0: At , we set
giving
whereas at
, we set
giving
. Hence the WLOO log-likelihood is
Midpoint of 0 and 1: Unlike
,
lies between 0 and 1 with different data multiplicities. At
, we set
giving the WLOO log-likelihood
With single contribution of
, we set
and so
. At
, we set
giving the WLOO log-likelihood
Again, we set
and so
. This gives us the WLOO log-likelihood of
where
.
Hence for a general data set in which have data multiplicities
, data points not around the neighbourhood of the midpoint of
have the same contribution to the WLOO likelihood so they always have a weight of 1. For the neighbourhood around the midpoint of
on the side closer to
, the
data points with value
would be left out by setting their weights to be 0. Then the weights for
is set to be
so that
. This gives us the formula for the weights in (Equation9
(9)
(9) ). We note that the ECM algorithm using LOO likelihood in the next section can be extended to the more general WLOO likelihood.
4. ECM algorithm
Finding the maximum LOO likelihood estimate for VG distribution directly can be difficult as the LOO likelihood has many cusps when
, and the LOO index
makes derivatives tedious to work with since the summation and the differential with respect to
cannot simply be interchanged due to the dependence of the summation index on
. Alternatively, we can implement the ECM algorithm to maximise the complete data LOO likelihood conditional on the mixing variables
.
Given the complete data , we use the normal mean-variance mixture representation in (Equation2
(2)
(2) ) to represent the complete data LOO log-likelihood as
(12)
(12) where the LOO log-likelihood of the conditional normal distribution ignoring constants is given by
(13)
(13) and the LOO log-likelihood of the conditional gamma distribution is given by
(14)
(14) The outline of the ECM algorithm of VG distribution using the full likelihood is similar to the ECM algorithm in Ref. [Citation9] for Student-t distribution and in Ref. [Citation6] for VG distribution. However, modifications to the algorithm are necessary when using the LOO likelihood. We will discuss the necessary modifications needed in order to search for the maximum of the LOO likelihood.
4.1. E-step
By analysing the conditional posterior distribution of given
with density
which corresponds to the pdf of a generalised inverse Gaussian distribution [Citation17], we can calculate the following conditional expectations:
(15)
(15)
(16)
(16)
(17)
(17) where
is approximated using the second-order central difference
(18)
(18) and we let
. Numerical problems may occur when
since the pdf
in (Equation1
(1)
(1) ) at
is unbounded. Using the asymptotic property of the modified Bessel function of the second kind,
We can show that as
,
(19)
(19)
(20)
(20)
(21)
(21) Thus for the case when
, the main source of numerical problems comes from calculating
as it diverges to infinity at a hyperbolic rate since the maximum of the likelihood function occurs at the data points. This leads to the overflow problem when calculating the estimates and this problem is explained later in Section 4.2.3. The LOO likelihood avoids the problem by preventing the location parameter estimate to converge towards the data point since the maximum of the LOO likelihood tends to be roughly between data points.
4.2. CM-step
Derivatives of in (Equation13
(13)
(13) ) with respect to
are straight forward to calculate using matrix differentiation. However we encounter two types of difficulties in calculating the derivative with respect to
for the CM-step.
Firstly, even when the LOO likelihood removes the unbounded points from the full likelihood, there still exist cusps in the LOO likelihood. Consequently we cannot completely rely on derivative-based methods to find the maximum of the LOO likelihood with respect to the location parameter .
Secondly, the first-order derivative of the complete-data LOO log-likelihood in (Equation13(13)
(13) ) with respect to
is
(22)
(22) Since the summation index depends on
, the differential and the summation cannot simply be interchanged. Thus the CM-step for
does not have a closed-form solution. To solve these problems, we propose the local mid-point search and local point search algorithm for the first problem, and the approximate CM-step for the second problem.
4.2.1. Local mid-point search (for one-dimensional case)
As seen in Figure , the maximum of the LOO log-likelihood tends to occur at the cusp points which are located between data points for the one-dimensional case. So ideally we would want to search along these mid-points to maximise the LOO log-likelihood with respect to μ. This leads to the local mid-point search. The idea is to search for mid-points around the current iterate and choose the one that maximises the LOO log-likelihood.
Local mid-point search algorithm:
Let be our current estimates, and
be the ordered data:
Calculate
for
Update the location estimate by choosing μ out of
Repeat steps 1 and 2 until the location parameter estimate converges.
4.2.2. Local point search (for higher dimensional case)
In general, finding the maximum along the cusps in higher dimensions is more computationally demanding. For 2-dimensional data, these cusps occur at the cusp lines in which is demonstrated in Figure of Ref. [Citation11]. For d-dimensional data, these cusps occur on the
dimensional cusp manifolds in
. So for simplicity, we propose to search for data points around the current iterate
and choose the one that increases the LOO likelihood.
Local point search (LPS) algorithm:
The algorithm is similar to the local mid-point search algorithm in Section 4.2.1 except we search over the data points instead of the mid-points, and replace the Euclidean distance with the Mahalanobis distance between and
for
.
4.2.3. Approximation in CM-step
To evaluate the first-order derivative in (Equation22(22)
(22) ), we propose to approximate the derivative by simply considering the LOO index in (Equation4
(4)
(4) ) to be fixed at the current estimate
at k-th iteration so that we leave out the data point closest to
instead of
. This gives us an approximation to the derivative
(23)
(23) Similarly, applying the approximate derivative to
and
with respect to other parameters and solving the approximate derivatives at zero gives us the following CM-steps.
CM-step for :
Suppose that the current iterate is and
is given. After equating each component of the approximate partial derivatives of
to zero, we obtain the following estimates:
(24)
(24)
(25)
(25)
(26)
(26) where the sufficient statistics are:
(27)
(27) CM-step for
:
Given the mixing parameters , the estimate
can be obtained by numerically maximising
in (Equation14
(14)
(14) ) with respect to ν using Newton-Raphson (NR) algorithm where the approximate derivatives is given by:
where
is the digamma function and
(28)
(28) This algorithm using the conditional log-likelihood
is called MCECM. Alternatively, we can speed up the convergence rate by maximising directly the LOO log-likelihood
with respect to ν given the other parameters. This algorithm is called ECM. Unless otherwise stated, we consider ECM algorithm in the subsequent analyses.
4.2.4. Line search
The estimates in (Equation24(24)
(24) ) to (Equation26
(26)
(26) ) using approximate derivatives will not guarantee the LOO likelihood increase. In this regard, we propose to apply a line search to ensure the LOO likelihood increases after each CM-step. This line search is part of a class of adaptive overrelaxed methods which can improve the efficiency of EM [Citation18]. Denote the current estimate by
and the updated estimate by
after the CM-step in Section 4.2.3, we propose to construct a direct line search by defining
where
and the interval
is chosen so that
remains in the parameter space. Using the optimise function in R, φ is estimated to be
such that it maximises the LOO log-likelihood
Since finding the maximum of a non-smooth likelihood function is difficult, we can alternatively search φ to choose
such that it improves the LOO likelihood over the previous estimate
4.3. ECM algorithm
Combining these steps gives us the ECM algorithm for VG distribution using the LOO likelihood:
Initialisation step: Choose suitable starting values . It is recommended to choose starting values
where
and
denote the sample mean and sample variance-covariance matrix of
respectively. For more leptokurtic data, it is recommended to use more robust measure of location and scale.
ECM algorithm for VG: At the k-th iteration with current estimates :
Local Point Search: Update the estimate to using local point search in Section 4.2.2.
E-step 1: Calculate and
for
in (Equation15
(15)
(15) ) and (Equation16
(16)
(16) ) respectively using
. Calculate also the sufficient statistics
,
,
and
in (Equation27
(27)
(27) ).
CM-step 1: Update the estimates to in (Equation24
(24)
(24) ) and (Equation25
(25)
(25) ) respectively using the sufficient statistics in E-step 1 along with the line search in Section 4.2.4.
CM-step 2: Update the estimate to in (Equation26
(26)
(26) ) using the sufficient statistics in E-step 1 along with the line search.
CM-step 3: Update the estimate to by maximising the actual LOO log-likelihood with respect to ν while keeping the other parameters fixed.
Stopping rule: Repeat the procedures until the relative increment of LOO log-likelihood function is smaller than tolerance level .
We remark that the local mid-point search and local point search ensure the location parameter estimates jump closer towards the maximum whereas the line search in Section 4.2.4 is applied after each CM-step to ensure monotonic convergence of the ECM algorithm. We will numerically verify the accuracy of this algorithm in Section 5.1 using Monte Carlo simulations.
4.4. Convergence of ECM algorithm using LOO likelihood
Let the approximate LOO log-likelihood be defined as
(29)
(29) with LOO index fixed at
. To show the convergence of ECM algorithm using approximate LOO likelihood, we first prove the convergence of the ECM algorithm with one CM-step for approximate LOO log-likelihood, then extend the proof for multiple CM-steps. For the case with one CM-step, we apply the idea in Ref. [Citation19] to the LOO likelihood and state two fundamental results below:
and
where we let
(30)
(30) with
,
, and
with
. These fundamental results are stated by Podgórski and Wallin [Citation5], and the ideas of the proof are exactly the same as in Ref. [Citation20] by replacing the full likelihood with the LOO likelihood. However, choosing
such that
only guarantee that
but not
. For this reason, we need to perform a line search in Section 4.2.4 so that the LOO log-likelihood improves and thus guarantees the monotonic convergence of the algorithm for LOO log-likelihood.
For the case with multiple CM-steps, applying the line search after the CM-step increases the actual LOO log-likelihood rather than the Q-function in Equation (Equation30(30)
(30) ). Liu and Rubin [Citation8] and Meng and van Dyk [Citation21] proved the monotonic convergence of the ECM algorithm only if all the CM-steps applied to Q-functions are performed before the CM-step applied to the actual LOO log-likelihood. Thus for our case, if we applied the line search to the initial CM-step, the line search have to also be applied to the other subsequent CM-steps to ensure that the actual LOO log-likelihood increases after each CM-step. Thus, this guarantees the monotonic convergence of the algorithm in Section 4.3.
5. Simulation studies
5.1. Accuracy of estimates for VG distribution
To demonstrate the accuracy of the proposed ECM algorithm, we simulate n = 1000 bivariate skewed VG samples with parameters
(31)
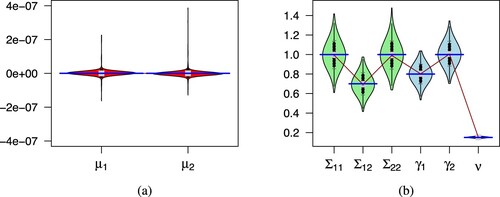
(31) and estimate the parameters using the algorithm specified in Section 4.3. We replicate this experiment r = 1000 times and present the results in Figure . Figure shows the violin plots implemented using the caroline package [Citation22] in R which represents the density estimate of the parameter estimates using normal kernel. The median of the estimates are very close to the true parameters of the model implying that the algorithm gives us consistent estimates for these parameters, even when
leading to unbounded density. We also see the distribution of each component of the parameters in
,
, and ν appear to follow roughly a normal distribution. On the other hand, the distribution of
has high density around
and extreme heavy-tails.
Figure 3. Vioplots to show accuracy of parameter estimates for VG distribution in the first simulation study. The median is displayed as a grey box which is connected by a crimson line. True parameter values represented by the blue lines is drawn for comparison. (a) Vioplot of and (b) Vioplot of
,
, ν.
To illustrate the idea of the local point search and line-search in Sections 4.2.2 and 4.2.4 graphically, readers may refer to Figure of Ref. [Citation11]. The figure shows that a global maximum lies roughly between data points along the cusp lines. These cusp lines make computation more demanding as we cannot purely rely on derivative-based methods (see Equation (Equation23(23)
(23) )). The local point search and then the line search serves as an efficient iterative method to obtain estimates which will converge towards the global maximum approximately. To explain the idea, the local point search takes the estimates
along the black solid line to one of the three data points (red circles) closer to the global maximum point (yellow triangle), while the CM-step and line search improves
along the black dash line to the point in blue square so that they converge closer towards the global maximum point which lies on the cusp line between two of the data points.
5.2. Comparison of WLOO, LOO and full likelihood methods
We assess the performance of WLOO, LOO likelihood relative to other full likelihood methods including the R package called ghyp in a simulation study. Nitithumbundit and Chan [Citation6] proposed an ECM algorithm [Citation7] to estimate parameters for the VG distribution with unbounded density by capping the density within a small interval of the location parameter. Specifically, they bounded the conditional expectations of (Equation19(19)
(19) ) to (Equation21
(21)
(21) ) around
by a region such that if
where Δ is some small fixed positive capping level and
is defined in Equation (Equation18
(18)
(18) ), then the conditional expectations are calculated by replacing
with
. To improve the rate of convergence, they further considered a data augmentation algorithm called the alternating ECM (AECM) by setting
where the positive function
and updated ξ by choosing
using numerical optimisation techniques given the current estimates
. Then they updated the parameters as
and
. Lastly, they showed that the optimal Δ decreases as ν decreases. Hence they proposed an adaptive Δ method by updating
where
is a cubic spline by fitting the median (over repeats) of the optimal Δ across ν and d in a simulation study. The following likelihood methods are considered in this study:
Full likelihood ghyp package: ECM algorithm with Δ set to
Full likelihood fixed Δ : AECM algorithm with the smallest
Full likelihood adaptive Δ: AECM algorithm with adaptive Δ.
LOO likelihood: ECME/AECM algorithm with LPS (Section 4.2.2), line search (Section 4.2.4) and the smallest Δ which is relevant when there is data multiplicity.
WLOO likelihood: ECM algorithm with LPS and line search.
Details of these five likelihood methods are summarised in Table .
Table 1. ghyp, fixed Δ, adaptive Δ, LOO and WLOO likelihood methods.
To conduct the simulation study, we create data multiplicity in two ways: replicate each data point R times or round each data point to D decimal places. The procedure for the simulation study are summarised below:
| Step 1: | Choose | ||||
| Step 2: | Simulate n = 1000 data from the bivariate VG distribution with true parameters | ||||
| Step 3: | Apply the five likelihood methods in Table to the data sets to obtain five sets of estimates. | ||||
| Step 4: | Repeat these steps until we have r = 500 replicates for each method, level of ν, and level of R or D. | ||||
5.2.1. No data multiplicity
The median of the measures of accuracy for the four parameters are reported in Table . Results show that full likelihood methods using ghyp and fixed Δ mostly give the largest biases whereas adaptive Δ full likelihood, LOO likelihood and WLOO likelihood methods perform similarly with lower biases particularly for when the density is unbounded. It is reasonable to see that LOO and WLOO likelihood methods give very similar results for data without data multiplicity. As ν decreases, the bias seems to increase for
and decrease for
but there is no clear trend for
.
Table 2. Median of 500 accuracy measures of parameter estimates across five likelihood methods with no data multiplicity (R = 1). ‘*’ indicates the methods with lowest absolute error.
5.2.2. Data multiplicity due to repetition and rounding
To visualise the differences in performance better, we transform the accuracy measures by ,
,
and
respectively and graph the transformed accuracy measures in Figure for replicated data when R = 1, 3, 5. Since the plot for rounded data is very similar, it is omitted. See Ref. [Citation23], page 95 for this plot. We remark that the transformation
for
is monotonically increasing on
.
Figure 4. Plot of transformed accuracy measures for full ghyp package (red solid line), full fixed Δ (light green striped line), full adaptive Δ (dotted green line), LOO (blue dot & striped line), and WLOO (dash magenta line) likelihoods. The columns from left to right represents the median parameter accuracy measures for respectively. The rows from top to bottom represents R = 1, 3, 5 respectively where R is the number of times each data point is repeated.
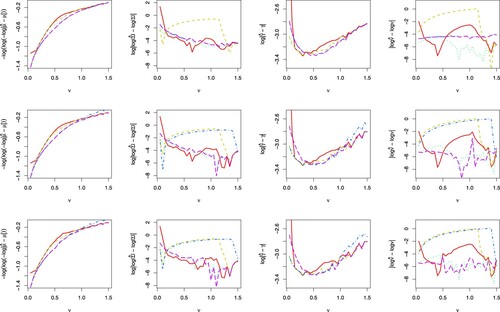
With data repetition, the WLOO likelihood (magenta line) generally performs better than other likelihood methods for all levels of ν in Figure . The full likelihood ghyp with 1.2e-4 (red line) and adaptive Δ (green line) methods provide reasonable accuracy when
but the adaptive Δ method is better and similar to WLOO for
. This result is in agreement with the optimal Δ choice study in Section 4.2 of Ref. [Citation6]. They considered
1.49e-154 and
1.49e-8 and plotted in Figure , the log of the sum of mean absolute errors (MAE) over all the parameters for a
dimensional VG model with
,
and
using the AECM algorithm. Results show that
performs better for much smaller shape parameter at
whereas
performs better for
approximately. Since
is similar to
relative to
, this result explains why full and LOO likelihoods both with
perform worst in Figure for
approximately.
When ν is small, full likelihood ghyp method performs poorly as expected. The fixed Δ full and LOO likelihood methods (light green and blue lines) have the worst performance particularly for and
since they both adopt a fixed capping level Δ. The only difference is that the LOO likelihood leaves out a data point while the full likelihood does not. Nevertheless, as the data multiplicity increases, leaving a data point out becomes insignificant and so the accuracies of the full fixed Δ and LOO likelihood converge. As ν approaches 1.5, the accuracy for
and
for all likelihood method converges.
With data rounding, the results are very similar. The WLOO likelihood is still better for most cases, such as and
when
approximately. For
, the full likelihood ghyp package performs well around
, the full adaptive Δ likelihood performs well in the mid-range at around
and the full fixed Δ likelihood performs well at around
. Again, the ghyp package and adaptive Δ full likelihood perform similarly. For
and
, the full fixed Δ likelihood still performs worse whereas the LOO likelihood is now much better and is similar to WLOO when
but they perform similarly for smaller ν. We remark that for larger ν, the data rounding is insignificant because of the lower peak and hence less data multiplicity around
.
In summary, for both data repetition and rounding cases, we have demonstrated that the full ghyp and fixed Δ likelihood methods using fixed capping levels perform worse and can be improved by providing an adaptive capping level. Moreover, the LOO likelihood method can be extended to the WLOO likelihood to deal with the unbounded likelihood due to data multiplicity. Overall, the WLOO likelihood gives the most stable and accurate results. As the range of ν is uncertain in practice, it is better to use the WLOO likelihood which provides the best overall performance.
5.3. Asymptotic properties for the location parameter of VG distribution
Podgórski and Wallin [Citation5] proved the consistency and super-efficiency of the location parameter estimate using the maximum LOO likelihood as stated in Theorem 3.1 in Section 3.2. They also stated the upper bound for the index of the rate of convergence where
for unbounded univariate VG distribution. The aim of this section is to determine these optimal rates through simulation studies and to analyse the asymptotic distribution of the location parameter estimate for unbounded and cusp densities. In this study, we consider LOO instead of WLOO loglikelihood to investigate the optimal convergence rate of Ref. [Citation5].
We consider univariate case () and set up the simulation as below for
:
Set the sample size n to be one of the 41 sample sizes
For each sample size, set the true shape parameter ν to be one of the 50 shape parameters
For each pair of
For the ith set of 20,000 samples, estimate
This gives us for each pair of the sample
of
estimates which is used to study the optimal convergence rate and asymptotic distribution across sample size n and shape parameter ν.
5.3.1. Optimal convergence rate
Since the scale of asymptotic distribution of changes with n according to the convergence rate
, we can fit a power curve to estimate
in the optimal convergence rate. We choose a robust measure of spread called the median absolute deviation (
) from 0 defined by
For each ν, we fit a power curve to the
against n. In other words, we find parameters
and
such that
. This is equivalent to fitting a simple linear regression model
to obtain the estimates
. Then an estimate of the optimal rate for a given ν is obtained by setting
. We repeat this process for the other ν's.
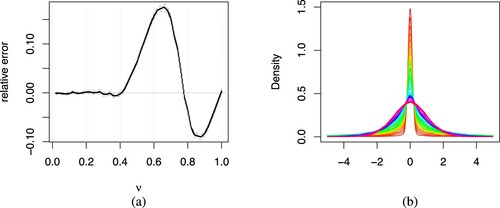
Figure (a) plots the relative error of against ν along with its confidence intervals. From the figure,
appears to follow the proposed optimal rate of
when
. However when
(the density is bounded with a cusp when
),
appears to be slightly different and the relative error follows a sinusoidal pattern. In fact for
,
appears to be greater than the proposed optimal convergence rate index. For
,
appears to be less than the proposed optimal convergence rate index. As ν approaches to 1,
approaches the convergence rate for asymptotic normality. Overall the estimated optimal rate is consistent with Theorem 3.1 in Section 3.2 in the range of
for unbounded density. As for
, more theoretical studies is needed to understand the behaviour of the location parameter estimates
. To investigate this unusual behaviour of
, we further analyse the asymptotic distribution of
across ν when
is large.
Figure 5. (a) Relative error (solid black) against ν. The horizontal solid grey line indicates agreement of
with the proposed optimal rate
. The vertical grey dotted lines represent grid lines for
. We also include the 95% confidence interval for the relative error (dashed grey). (b) Density of estimates
with its scale standardised using
for each ν where n = 100, 000. We use a rainbow colour scheme ranging from red (
) to magenta (
).
5.3.2. Asymptotic distribution
This section explores the distribution of or
in the more appropriate scale and approximate the distribution to allow SE calculation for
.
Analysis 1: preview the distribution of location parameter estimates using normal kernel
We begin with plotting the normal kernel density estimate in Figure (b) for with its scale standardised using
, taking
and representing the density for each ν in rainbow colours. We note that the estimated density exhibits heavier tails and sharper peaks at the expense of intermediate tails as ν decreases (from magenta line to red line) and this feature resembles VG distribution.
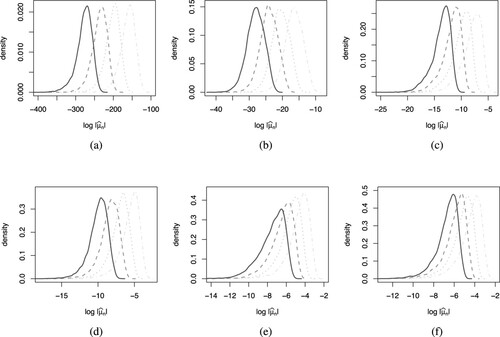
Analysis 2: explore the distribution on the more appropriate log scale
To explore the distributions on a more appropriate scale, we transform to
and plot the kernel density estimates in Figure for
by
. We observe that the location of the distribution shifts to the right in general for each ν as the sample size n increases but the scale and the shape of the distribution remain relatively similar. An exception is when
where the scale gets slightly larger and the shape becomes less left skewed. We remark that these densities resemble the densities of the generalised Gumbel (GG) distribution. Fitting the GG distribution to
corresponds to fitting a double generalised gamma (DGG) distribution to
. See Appendices A and B for details of the two distributions, respectively.
Figure 6. Kernel density estimates of 's for
and n = 1000 (solid black), 5000 (dashed dark grey), 20, 000 (dotted grey), 100, 000 (dash-dotted light grey) with each n being combined into a single plot for comparison. (a) density plots for
(b) density plots for
(c) density plots for
(d) density plots for
(e) density plots for
and (f) density plots for
.
Analysis 3: approximate the distribution on the log scale
This analysis aims to approximate the kernel densities for in Figure with some distributions which should include log-normal as the asymptotic distribution when ν approaches or exceeds 1. In the search for these distributions, we start with VG based on Figure (b) and check the goodness-of-fit using P-P plots by plotting the cumulative distribution function (cdf)
against the ordered sequence
giving one P-P plot for each
and taking n = 100, 000. We also consider stable distribution which, like normal, can model any properly normed sums of independent and identically distributed random variables. If each variable has a finite variance, classical central limit theorem states that the sum will tend toward a normal distribution as the number of variables increases but without the finite variance assumption, the limit may be a stable distribution. These provide some theoretical ground for the trial although it still does not address the unbounded density problem. However, the P-P plots for both log-VG and log-stable distributions argue against adoption. Finally, we try DGG distribution with the flexible generalised gamma distribution on each side and the cdf of GG distribution for fitting
is given by Equation (EquationA2
(A2)
(A2) ) evaluated at the fitted parameters
. As the set of P-P plots for GG distribution shows near-perfect straight lines except some very minimal deviations around the 25th and 75th percentiles for
, we confirm that GG distribution fits
the best amongst the log-VG and log-stable distributions. See Ref. [Citation23], pages 77-78 for these P-P plots. Hence we choose DGG to approximate the distribution for the location parameter estimate μ using maximum LOO likelihood. We declare the limitation of this ad hoc search but based on the P-P plots, we are confident that DGG distribution can provide a reasonably accurate standard error (SE) estimate for
. We will demonstrate the calculation and confirm the accuracy.
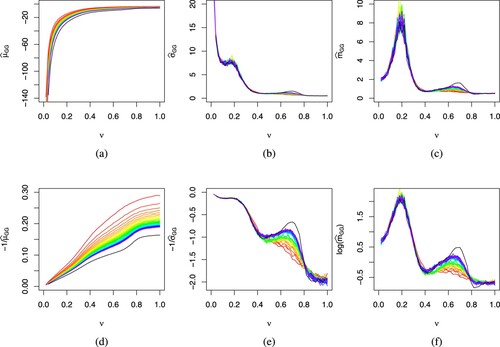
Analysis 4: assess the convergence of DGG distribution to asymptotic distribution
We assess the convergence of DGG distribution as n increases to asymptotic distribution by plotting in Figure the parameter estimates against ν when fitting the
for each
to GG distribution while different n is represented by lines in rainbow colours from red for the lowest n = 500. We also plot the transformed parameter estimates to view the behaviour across ν more clearly. As ν decreases,
in Figure (a,d) appears to drop roughly at a hyperbolic rate with some minor curvature for larger values of ν. This agrees with the observation in Figure that the location of the density shifts to the left as ν decreases. However,
in Figure (b,c) increases at a hyperbolic rate with two bumps as ν decreases. This increase in the spread can also be observed in the densities of Figure . The two bumps occur around
and
with the left one showing more fluctuation and no clear distinction between each n possibly due to sampling error whereas the right one has a clear distinction between each n especially for n = 100, 000. In Figure (c,f),
also has two bumps similar to
but unlike
and
,
tends to some constant value as ν approaches to 0. The right bumps for both
and
suggest that the DGG distribution for
has yet to converge to the asymptotic distribution and it is unclear how large n should be for the convergence for
, the range with cusp density. Adding to the inconsistency of the index for optimal convergence rate as displayed in Figure , the asymptotic properties for this range of ν worth further analyses.
Figure 7. Plot of estimates of generalized Gumbel distribution fitted to the distribution of against ν. Row 1 plots the
against ν, respectively, while row 2 plots the transformation
against ν, respectively, to enlarge certain portion of the plots. A rainbow colour scheme ranging from red (n = 500) to magenta (n = 20, 000) is used to denote sample size and the black line represents n = 100, 000. (a)
vs ν (b)
vs ν (c)
vs ν (d)
vs ν (e)
vs ν and (f)
vs ν.
Demonstration of SE calculation for the location parameter estimate using DGG distribution
Lastly, we demonstrate the SE calculation for (d = 2) using DGG distribution and the true parameters in Section 5.1 as the sample estimates. For each component
, we apply the GG distribution to estimate the variability of
. Specifically, we use
with sample size n = 1000 to extrapolate the values
and
by applying the spline function in R to Figure (d–f). This gives the GG parameter estimates
and
. Applying these estimates to Equation (EquationA5
(A5)
(A5) ) with
and
gives us the MADs
using DGG distribution which are close to the ‘observed’ MAD
by applying
to the simulated sample
with r = 1000 replicates. Hence
estimated from DGG distribution provides reasonably accurate estimates of MAD
, unobserved in practice, for the SE estimate of
using maximum LOO likelihood when the shape parameter
gives unbounded density or
gives cusp density. Using
as SE estimate, we can also construct confidence interval for
.
6. Conclusion
Optimising a non-convex likelihood is always challenging particularly for noisy data with cusped or unbounded likelihood. An obvious example is the estimation of from VG distribution when
. We propose ECM algorithm using hierarchical model via the NMVM representation of VG distribution to avoid the direct maximisation of full likelihood. Conditional on the mixing variable
,
follows a condition normal distribution in (Equation2
(2)
(2) ). In case
and
when the density becomes unbounded in (Equation3
(3)
(3) ),
in (Equation17
(17)
(17) ). Nitithumbundit and Chan [Citation6] proposed to cap the density but we propose to use LOO likelihood. In case of data multiplicity, we extend the LOO likelihood to WLOO likelihood.
To improve the estimation efficiency, we propose local mid-point search (one-dimensional case in Section 4.2.1) and local point search (higher dimensional case in Section 4.2.2) for as well as the line search (Section 4.2.4). The local point searches ensure the location parameter estimates jump closer towards the maximum. Since the derivatives of LOO likelihood in (Equation23
(23)
(23) ) are also approximations, the line search ensures monotonicity along the recurrent updates. The first simulation study confirms the accuracy of the location parameter estimate for the VG distribution even though these search procedures do not necessary guarantee that the path leads to a global maximum.
In the second simulation study, our proposed ECM algorithm using WLOO likelihood is compared to three full likelihood methods, namely, MCECM from the ghyp package, AECM with fixed Δ and AECM with adaptive Δ, and one LOO likelihood method. The comparison is conducted under three scenarios: no data multiplicity, data multiplicity due to repetition and data multiplicity due to rounding. Results show that ECM algorithm using WLOO likelihood performs well in all three scenarios.
Lastly, our third simulation study explores empirically the optimal convergence rate and asymptotic distribution for our proposed location parameter estimate using the maximum LOO likelihood method for symmetric univariate VG data. Results show that the index for optimal convergence rate follows when
. However, when
, the index appears to be slightly different with a sinusoidal pattern for the relative error. As ν approaches 1, the optimal rate approaches the convergence rate for asymptotic normality. Following the result, we propose to approximate the asymptotic distribution using the DGG distribution when
so that we can calculate SE and construct confidence interval for each component of
. In summary, the idea of the proposed ECM algorithm can be applied to other distributions in NMVM representation including Students' t and GH distributions with some suitable adjustments in the E-step.
Our method using hierarchical model in NMVM representation is similar in spirit to Bayesian methods which are sometimes treated as a frequentist method when flat priors are adopted so that the solution could be considered ‘equivalent’ to the solution using the classical likelihood method. This proxy likelihood approach can avoid the optimisation of complicated likelihoods. Further, the empirical Bayesian (EB) method offers procedures for statistical inference in which the prior is estimated from the data, ie
without relying on external input (similar to using flat priors). Hossain, Kozubowski, Podgórski[Citation24] proposed the weighted likelihood estimation for a parameter θ as
(32)
(32) where
is an estimator of θ using the ML principle and observation
, and the last term in (Equation32
(32)
(32) ) is for the location model (LM)
and
is a symmetric and unimodal density. This estimation method has an EB flavour since
can be viewed as the posterior sample mean of
with probability
where the data-driven prior distribution is discrete and supported on the same values
with equal probability 1/n. They showed that the asymptotic normality and efficiency of Bayes estimator using ordinary prior
can be applied to EB estimator using empirical sample prior
. Based on the symmetric gamma (SG) distribution with pdf
which is unbounded when
(
corresponds to symmetric Laplace (SL) distribution), they showed that the location parameter θ in LM has a closed-form expression
using (Equation32
(32)
(32) ) when the estimator
is a LOO estimator such that
is calculated using the sample without
. In a simulation study, they showed that
performs slightly better than
in Tables 5 and 6 for SG and SL distributions in Ref. [Citation24]. This EB method which provides closed-form solution is attractive. Future studies may derive the EB estimates for VG distribution and compare the performance of EB method with our proposed ECM method using WLOO likelihood in several scenarios.
Moreover, our third simulation study for the optimal convergence rate and asymptotic distribution of the location parameter estimate considers only the univariate symmetric case using LOO likelihood. For future work, we will consider multivariate skewed case using WLOO likelihood. Furthermore, in-depth study should be directed to the case of when the density has cusp density as results show inconsistency of the index for the optimal convergence rate and problem of convergence for the asymptotic distribution. Furthermore, the dependence between the location and other parameters of VG distribution should also be considered in the simulation studies. Lastly, it is worth exploring better approximation to the asymptotic distribution from both numerical and theoretical perspectives even though it can be challenging.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Rao B. Estimation of the location of the cusp of a continuous density. Ann Math Stat. 1968;39:76–87.
- Ibragimov IA, Khasminskii RZ. Asymptotic behavior of statistical estimates of the location parameter for samples with unbounded density. J Sov Math. 1981a;16(2):1035–1041.
- Ibragimov IA, Khasminskii RZ. Statistical estimation, volume 16 of Applications of Mathematics. Asymptotic theory, Translated from the Russian by Samuel Kotz. Springer-Verlag: New York-Berlin; 1981b.
- Rao B. Asymptotic distributions in some non-regular statistical problems. PhD diss., Ph. D. Dissertation, Michigan State University; 1966.
- Podgórski K, Wallin J. Maximizing leave-one-out likelihood for the location parameter of unbounded densities. Ann Inst Stat Math. 2015;67(1):19–38.
- Nitithumbundit T, Chan JSK. ECM algorithm for auto-regressive multivariate skewed variance gamma model with unbounded density. Methodol Comput Appl Probab. 2020;22(3):1169–1191.
- Meng X-L, Rubin DB. Maximum likelihood estimation via the ECM algorithm: a general framework. Biometrika. 1993;80(2):267–278.
- Liu C, Rubin DB. The ECME algorithm: a simple extension of EM and ECM with faster monotone convergence. Biometrika. 1994;81(4):633–648.
- Liu C, Rubin DB. ML estimation of the t distribution using EM and its extensions, ECM and ECME. Stat Sin. 1995;5(1):19–39.
- Madan DB, Seneta E. The variance gamma (V.G.) model for share market returns. J Bus. 1990;63(4):511–524.
- Nitithumbundit T, Chan JSK. ECM algorithm for estimating vector ARMA model with variance gamma distribution and possible unbounded density. Aust N Z J Stat. 2021;63(3):485–516.
- Barndorff-Nielsen O, Kent J, Sørensen M. Normal variance-mean mixtures and z distributions. Int Stat Rev. 1982;50(2):145–159.
- Protassov RS. EM-based maximum likelihood parameter estimation for multivariate generalized hyperbolic distributions with fixed λ. Stat Comput. 2004;14(1):67–77.
- Kotz S, Kozubowski TJ, Podgórski K. The Laplace distribution and generalizations : a revisit with applications to communications, economics, engineering, and finance. Boston: Birkhäuser; 2001.
- Gradshteyn IS, Ryzhik IM. Table of integrals, series, and products. 7th ed., Amsterdam: Elsevier/Academic Press; 2007.
- Kawai R. On the likelihood function of small time variance gamma Lévy processes. Statistics. 2015;49(1):63–83.
- Embrechts P. A property of the generalized inverse Gaussian distribution with some applications. J Appl Probab. 1983;20(3):537–544.
- Salakhutdinov R, Roweis S. Adaptive overrelaxed bound optimization methods. In: Proceedings of the International Conference on Machine Learning; 2003; Vol. 20. p. 664–671.
- Dempster AP, Laird NM, Rubin DB. Maximum likelihood from incomplete data via the EM algorithm. J Roy Statist Soc Ser B. 1977;39(1):1–38.With discussion.
- Wu C-FJ. On the convergence properties of the EM algorithm. Ann Stat. 1983;11(1):95–103.
- Meng X-L, van Dyk D. The EM algorithm – an old folk-song sung to a fast new tune. J Roy Statist Soc Ser B. 1997;59(3):511–567.With discussion and a reply by the authors.
- Schruth D. caroline: A Collection of Database, Data Structure, Visualization, and Utility Functions for R. R package version 0.7.6; 2013.
- Nitithumbundit T. EM Algorithms for Multivariate Skewed Variance Gamma Distribution with Unbounded Densities and Applications. PhD thesis. School of Mathematics and Statistics; 2017. The address of the publisher. https://ses.library.usyd.edu.au/handle/2123/18155.
- Hossain MM, Kozubowski TJ, Podgórski K. A novel weighted likelihood estimation with empirical bayes flavor. Commun Stat Simul Comput. 2018;47(2):392–412.
- Adeyemi S. On a generalization of the gumbel distribution. Inter-Stat (London). 2002;11(4):1–7.
- Lin GD, Huang JS. The cube of a logistic distribution is indeterminate. Austral J Statist. 1997;39(3):247–252.
Appendix
A Generalised Gumbel (GG) distribution
The pdf of a GG distribution is given by
(A1)
(A1) where
is the location parameter,
is the scale parameter, and m>0 is the shape parameter. Note that we consider the negative version of the GG distribution given in Ref. [Citation25].
We can easily generate GG random variables based on gamma random variables denoted by using the following theorem.
Theorem A.1
If , then
follows GG distribution with pdf in Equation (EquationA1
(A1)
(A1) ).
Proof.
The idea of the proof is similar to the proof in Ref. [Citation25].
Using this transformation, we can compute the cdf as
(A2)
(A2) and quantile function as
where
and
are cdf and quantile function of
. In other words, we just need to calculate the cdf and quantiles of the gamma distribution. The mean and variance of a GG random variable X is given by
(A3)
(A3)
B Double generalized gamma (DGG) distribution
After fitting to the GG distribution, we can deduce the distribution of
follows DGG [Citation26] using the following theorem.
Theorem A.2
If X follows a symmetric distribution such that follows GG distribution with pdf in Equation (EquationA1
(A1)
(A1) ), then X follows a double generalised gamma distribution with pdf
(A4)
(A4) where
,
, and
.
Proof.
If follows GG distribution, then Y has pdf proportional to
where it is sufficient to consider the functional form. Now applying the transformation of random variable
where
, we get the pdf for W given by
which has the functional form of the generalised gamma distribution. Reverse the transformation
by reflecting the pdf at 0 gives us the result. Setting
,
, and
in (EquationA4
(A4)
(A4) ) gives the standard normal density as a special case. As the simulation results in Section 5.3.2 show that the GG distribution fits the
reasonably well, we can model
using the DGG distribution. Suppose that
is the scale parameter estimate of VG distribution with diagonals
for
. Then the standard error of
can be approximated using the formula
where
,
,
, and
are estimates of GG distribution extrapolated from Figure . Since the standard error is sensitive to outliers, we recommend using the MAD given by
(A5)
(A5) as a robust measure of the spread for
where
represents the quantile function of generalised gamma distribution and the pdf has functional form in (EquationA4
(A4)
(A4) ) with support
.